
4 Exploration des données
4.3 Distribution de fréquences
Début du texte
La fréquence (f) d’une valeur particulière est le nombre de fois que celle-ci se dégage des données. La distribution d’une variable est le profil des valeurs , c’est-à-dire l’ensemble formé de toutes les valeurs possibles et des fréquences associées à ces valeurs. Les distributions de fréquences sont représentées sous forme de tableaux ou de graphiques.
La distribution de fréquences peut indiquer soit le nombre réel d’observations s’inscrivant dans chaque intervalle ou le pourcentage d’observations. Dans le dernier cas, la distribution s’appelle une distribution de fréquences relatives.
Les tableaux de distribution de fréquences servent autant pour les variables catégoriques que pour les variables numériques. On ne devrait utiliser des variables continues qu’avec des intervalles de classe, comme nous l’expliquerons un peu plus loin.
Voyons quelques exemples de distribution de fréquences et de distribution de fréquences relatives à partir de variables discrètes.
Exemple 1 – Construction d’un tableau de distribution de fréquences
On a réalisé une enquête sur l’avenue des Érables. Dans chacune des 20 maisons, on a demandé aux gens d’indiquer le nombre de véhicules immatriculés dans leur ménage. Voici les résultats enregistrés :
1, 2, 1, 0, 3, 4, 0, 1, 1, 1, 2, 2, 3, 2, 3, 2, 1, 4, 0, 0
Suivez les étapes indiquées ci-dessous pour présenter ces données dans un tableau de distribution de fréquences.
- Divisez les résultats (x) en intervalles, puis comptez le nombre de résultats dans chaque intervalle. Dans ce cas, les intervalles seraient le nombre de ménages n’ayant aucun véhicule (0), un véhicule (1), deux véhicules (2) et ainsi de suite.
- Créez un tableau à l’aide de colonnes séparées pour les intervalles (le nombre de véhicules par ménage), les résultats cochés et la fréquence des résultats pour chaque intervalle. Intitulez ces colonnes Nombre de véhicules, Comptage et Fréquence.
- Lisez la liste de données de gauche à droite et mettez une coche dans la rangée appropriée. Par exemple, le premier résultat est un 1; mettez donc une coche dans la rangée 1 de la colonne des intervalles (Nombre de véhicules). Le résultat suivant est un 2; mettez donc une coche dans la rangée 2 de la colonne des intervalles et ainsi de suite. Quand vous arriverez à votre cinquième coche, tracez la coche en travers des quatre coches précédentes pour faciliter la lecture de vos calculs finals de fréquence.
- Additionnez le nombre de coches dans chaque rangée, puis enregistrez-les dans la dernière colonne, intitulée Fréquence.
Votre tableau de distribution de fréquences pour cet exercice devrait ressembler à ce qui suit :
| Nombre de véhicules (x) | Fréquence (f) |
|---|---|
| 0 | 4 |
| 1 | 6 |
| 2 | 5 |
| 3 | 3 |
| 4 | 2 |
| 0 zéro absolu ou valeur arrondie à zéro | |
Si nous examinons rapidement ce tableau de distribution de fréquences, nous pouvons constater que sur les 20 ménages sondés, 4 n’avaient pas de véhicule, 6 en avaient 1, etc.
Exemple 2 – Construction d’un tableau de distribution de fréquences cumulées
Un tableau de distribution de fréquences cumulées est un tableau plus détaillé. Il ressemble presque à un tableau de distribution de fréquences, mais on y ajoute des colonnes qui donnent la fréquence cumulée et le pourcentage cumulé des résultats.
Lors d’un récent tournoi d’échecs, les 10 participants ont rempli un formulaire sur lequel ils devaient indiquer leur nom, leur adresse et leur âge. Voici les âges des participants enregistrés :
36, 48, 54, 92, 57, 63, 66, 76, 66, 80
Suivez les étapes indiquées ci-dessous pour présenter ces données dans un tableau de distribution de fréquences cumulées.
- Divisez les résultats en intervalles, puis comptez le nombre de résultats dans chaque intervalle. Dans ce cas, des intervalles de 10 sont convenables. Puisque 36 est le plus jeune âge et 92, le plus grand âge, commencez avec l’intervalle 35 à 44, puis terminez avec l’intervalle 85 à 94.
- Créez un tableau semblable au tableau de distribution de fréquences, mais ajoutez trois colonnes additionnelles. Dans la première colonne, celle de la Valeur inférieure, indiquez la valeur inférieure des intervalles des résultats. Dans la première rangée, par exemple, vous indiqueriez le nombre 35.
- La colonne suivante est la colonne Valeur supérieure. Indiquez la valeur supérieure des intervalles des résultats. Vous indiqueriez, par exemple, le nombre 44 dans la première rangée.
- La troisième colonne est la colonne Fréquence. Enregistrez le nombre de fois qu’un résultat apparaît entre les valeurs inférieure et supérieure. Indiquez le chiffre 1 dans la première rangée.
- La quatrième colonne est la colonne Fréquence cumulée. Il s’agit ici d’ajouter la fréquence indiquée dans la rangée précédente à la fréquence indiquée dans la rangée courante. Dans la première rangée, la fréquence cumulée est identique à la fréquence. Toutefois, dans la deuxième rangée, il faut ajouter la fréquence de l’intervalle 35 à 44 (1) à la fréquence de l’intervalle 45 à 54 (2). Ainsi, la fréquence cumulée est 3, c’est-à-dire, qu’on dénombre 3 participants dans le groupe d’âge des 34 à 54 ans.
1 + 2 = 3
- La colonne suivante est la colonne Pourcentage. Dans cette colonne, indiquez le pourcentage de la fréquence. Pour ce faire, divisez la fréquence par le nombre total de résultats, puis multipliez par 100. Dans ce cas, la fréquence de la première rangée est 1 et le nombre total de résultats est 10. Le pourcentage serait donc
10,0. (1 ÷ 10) X 100 = 10,0
- La dernière colonne est la colonne Pourcentage cumulé. Dans cette colonne, divisez la fréquence cumulée par le nombre total de résultats, puis multipliez par 100. Notez que le dernier nombre dans cette colonne devrait toujours être égal à 100,0. Dans cet exemple, la fréquence cumulée est 1 et le nombre total de résultats est 10; le pourcentage cumulé de la première rangée est donc
10,0. (1 ÷ 10) X 100 = 10,0
Le tableau de distribution de fréquences cumulées devrait ressembler à ce qui suit :
Tableau 4.3.2
Âges des participants à un tournoi d’échecs
Sommaire du tableau
Le tableau montre les résultats de Âges des participants à un tournoi d’échecs. Les données sont présentées selon Valeur inférieure (titres de rangée) et Valeur supérieure, Fréquence (f), Fréquence cumulée, Pourcentage et Pourcentage cumulé(figurant comme en-tête de colonne).Valeur inférieure Valeur supérieure Fréquence (f) Fréquence cumulée Pourcentage Pourcentage cumulé 35 44 1 1 10,0 10,0 45 54 2 3 20,0 30,0 55 64 2 5 20,0 50,0 65 74 2 7 20,0 70,0 75 84 2 9 20,0 90,0 85 94 1 10 10,0 100,0
Intervalles de classe
Si une variable revêt un plus grand nombre de valeurs, il est alors plus facile de présenter et de manipuler les données en groupant les valeurs dans des intervalles de classe. On présente toujours les variables continues en intervalles de classe, tandis qu’on peut choisir de grouper ou de ne pas grouper les valeurs discrètes dans des intervalles de classe.
Pour illustrer notre propos, supposons que nous définissons des groupes d'âge pour une étude portant sur les jeunes, en tenant compte de la possibilité d’inclure certaines personnes plus âgées.
La fréquence d’un intervalle de classe est le nombre d’observations comprises dans un intervalle prédéfini particulier. Par exemple, si les données de notre étude indiquent que 20 personnes sont âgées de 5 à 9 ans, la fréquence de l’intervalle 5 à 9 sera 20.
Les extrémités d’un intervalle de classe sont les valeurs les plus faibles et les plus élevées qu’une variable peut revêtir. Ainsi, les intervalles dans notre étude sont 0 à 4 ans, 5 à 9 ans, 10 à 14 ans, 15 à 19 ans, 20 à 24 ans et 25 ans et plus. Les extrémités du premier intervalle sont 0 et 4, si la variable est discrète, et 0 et 4,999, si la variable est continue. Les extrémités des autres intervalles de classe seraient déterminées de la même façon.
La longueur d’un intervalle de classe est la différence entre l’extrémité inférieure d’un intervalle et l’extrémité inférieure de l’intervalle suivant. Ainsi, si les intervalles de notre étude sont 0 à 4, 5 à 9, etc., la longueur des cinq premiers intervalles est 5 et le dernier intervalle est ouvert. Les intervalles pourraient aussi être écrits sous la forme 0 à moins de 5, 5 à moins de 10, 10 à moins de 15, 15 à moins de 20, 20 à moins de 25 et 25 et plus.
Règles relatives aux ensembles de données qui renferment un grand nombre d’observations
En résumé, suivez ces règles de base lorsque vous construisez un tableau de distribution de fréquences pour un ensemble de données qui renferme un grand nombre d’observations :
- trouvez la valeur la plus faible et la valeur la plus élevée des variables;
- décidez de la longueur des intervalles de classe;
- incluez toutes les valeurs possibles de la variable.
Lorsqu’on décide de la longueur des intervalles de classe, il faut trouver un compromis afin d'avoir des intervalles assez courts (pour éviter que toutes les observations ne tombent dans le même intervalle) mais assez longs aussi (pour ne pas se retrouver avec une seule observation par intervalle).
Il importe aussi de veiller à ce que les intervalles de classe soient mutuellement exclusifs.
Exemple 3 – Construction d’un tableau de distribution de fréquences pour un grand nombre d’observations
On a testé 30 piles AA pour déterminer combien de temps elles dureraient. Voici les résultats du test, arrondis à la minute :
423, 369, 387, 411, 393, 394, 371, 377, 389, 409, 392, 408, 431, 401, 363, 391, 405, 382, 400, 381, 399, 415, 428, 422, 396, 372, 410, 419, 386, 390
Suivez les étapes indiquées dans l’exemple 1 et les règles ci-dessus pour vous aider à construire un tableau de distribution de fréquences.
Réponse
La valeur la plus faible est 363 et la valeur la plus élevée est 431.
Si l’on utilise les données fournies et un intervalle de classe de 10, l’intervalle de la première classe est 360 à 369 et inclut 363 (la valeur la plus faible). Souvenez-vous qu’il devrait toujours y avoir assez d’intervalles de classe pour que la valeur la plus élevée y soit incluse.
Le tableau de distribution de fréquences, une fois rempli, ressemble à ce qui suit :
| Durée de vie des piles, en minutes (x) | Fréquence (f) |
|---|---|
| 360 à 369 | 2 |
| 370 à 379 | 3 |
| 380 à 389 | 5 |
| 390 à 399 | 7 |
| 400 à 409 | 5 |
| 410 à 419 | 4 |
| 420 à 429 | 3 |
| 430 à 439 | 1 |
| Total | 30 |
Exemple 4 – Construction d’un tableau de fréquence relative et de fréquence en pourcentage
Un analyste qui étudierait les données de l’exemple 3 voudrait peut-être savoir non seulement combien de temps durent les piles, mais également quelle proportion d’entre elles s’inscrit à l’intérieur de chaque intervalle de classe de leur durée de vie.
On trouve la fréquence relative d’une observation particulière ou d’un intervalle de classe particulier en divisant la fréquence (f) par le nombre d’observations (n), c’est-à-dire (f ÷ n). Ainsi :
Fréquence relative = fréquence ÷ nombre d’observations
On trouve la fréquence en pourcentage en multipliant la valeur de chaque fréquence relative par 100. Ainsi :
Fréquence en pourcentage = fréquence relative X 100 = f ÷ n X 100
Utilisez les données fournies dans l’exemple 3 pour créer un tableau qui donnera la fréquence relative et la fréquence en pourcentage de chaque intervalle de classe de la vie des piles.
Voici ce à quoi ressemble ce tableau :
| Durée de vie des piles, en minutes (x) | Fréquence (f) | Fréquence relative | Fréquence en pourcentage |
|---|---|---|---|
| 360 à 369 | 2 | 0,07 | 7 |
| 370 à 379 | 3 | 0,1 | 10 |
| 380 à 389 | 5 | 0,17 | 17 |
| 390 à 399 | 7 | 0,23 | 23 |
| 400 à 409 | 5 | 0,17 | 17 |
| 410 à 419 | 4 | 0,13 | 13 |
| 420 à 429 | 3 | 0,1 | 10 |
| 430 à 439 | 1 | 0,03 | 3 |
| Total | 30 | 1 | 100 |
Un analyste qui examinerait ces données pourrait maintenant dire que :
- 7 % des piles AA ont une durée de vie d’au-moins 360 minutes, mais de moins de 370 minutes;
- la probabilité qu’une pile AA sélectionnée au hasard ait une durée de vie s’inscrivant à l’intérieur de cette plage est d’environ 0,07.
Exemple 5 – Visualisation de la distribution de fréquence relative cumulée
Comme nous l’avons vu à l’exemple 2, la distribution de fréquence cumulée est utilisée pour déterminer le nombre d'observations qui se situent au-dessous d'une valeur particulière dans un ensemble de données. Elle est calculée sur chaque ligne d’un tableau de fréquence en ajoutant à chaque fréquence la somme des fréquences sur les lignes qui précèdent. La dernière valeur sera toujours égale au total des observations, puisque toutes les fréquences auront déjà été ajoutées au total précédent. Voyons un exemple supplémentaire de calcul de la fréquence cumulée.
On a compté et enregistré durant une période de 30 jours le nombre de gens qui faisaient de l'escalade autour du lac Louise, en Alberta. Voici les résultats du décompte :
31, 49, 19, 62, 24, 45, 23, 51, 55, 60, 40, 35 54, 26, 57, 37, 43, 65, 18, 41, 50, 56, 4, 54, 39, 52, 35, 51, 63, 42.
Le nombre de grimpeurs varie de 4 à 65. Pour créer le tableau de fréquences, il vaut mieux grouper les données en intervalles de classe de 10. Chaque intervalle peut être une ligne dans le tableau de fréquence. La colonne Fréquence sert à indiquer le nombre d'observations qui se situent à l'intérieur d'un intervalle de classe. Par exemple, Il n'y a que deux valeurs dans l'intervalle de 10 à 20, alors sa fréquence est de 2 dans le tableau correspondant.
Utilisez la colonne Fréquence pour le calcul de la fréquence cumulée.
- Premièrement, ajoutez le nombre tiré de la colonne Fréquence au nombre précédent. Dans la première ligne, par exemple, nous n'avons qu'une seule observation et aucun nombre qui précède. La fréquence cumulée est donc un.
1 + 0 = 1 - Dans la seconde ligne, cependant, il y a deux observations. Ajoutez ces deux observations à la fréquence cumulée précédente (un) et vous obtiendrez trois.
1 + 2 = 3 - Enregistrez les résultats dans la colonne Fréquence cumulée.
Les autres entrées du tableau peuvent être calculées de manière similaire. Les résultats obtenus sont présentés au tableau 4.3.5.
| Nombre de grimpeurs | Fréquence (f) | Fréquence cumulée |
|---|---|---|
| <10 | 1 | 1 |
| 10 to <20 | 2 | 1 + 2 = 3 |
| 20 to <30 | 3 | 3 + 3 = 6 |
| 30 to <40 | 5 | 6 + 5 = 11 |
| 40 to <50 | 6 | 11 + 6 = 17 |
| 50 to <60 | 9 | 17 + 9 = 26 |
| >= 60 | 4 | 26 + 4 = 30 |
La distribution de fréquence relative cumulée est une autre façon de représenter une distribution de fréquences. Elle consiste à calculer le pourcentage de la fréquence cumulée dans chaque intervalle.
On calcule la fréquence relative cumulée en divisant la fréquence cumulée par le nombre total d'observations (n), qu'on multiplie ensuite par 100 (la dernière valeur est toujours égale à 100 %). Ainsi :
Fréquence relative cumulée = (fréquence cumulée ÷ n) x 100
La quatrième colonne du tableau 4.3.6 illustre le calcul de la fréquence relative cumulée du nombre de grimpeurs par jour au lac Louise.
| Nombre de grimpeurs | Fréquence (f) | Fréquence cumulée | Fréquence relative cumulée (%) |
|---|---|---|---|
| <10 | 1 | 1 | 1 ÷ 30 x 100 = 3 |
| 10 to <20 | 2 | 1 + 2 = 3 | 3 ÷ 30 x 100 = 10 |
| 20 to <30 | 3 | 3 + 3 = 6 | 6 ÷ 30 x 100 = 20 |
| 30 to <40 | 5 | 6 + 5 = 11 | 11 ÷ 30 x 100 = 37 |
| 40 to <50 | 6 | 11 + 6 = 17 | 17 ÷ 30 x 100 = 57 |
| 50 to <60 | 9 | 17 + 9 = 26 | 26 ÷ 30 x 100 = 87 |
| >= 60 | 4 | 26 + 4 = 30 | 30 ÷ 30 x 100 = 100 |
La distribution de fréquence relative cumulée peut être visualisée à l’aide d’un graphique à barres ou d’un graphique linéaire, comme au graphique 4.3.1 ci-dessous. La valeur sur l’axe horizontal correspond à la borne supérieure de l’intervalle de classe.
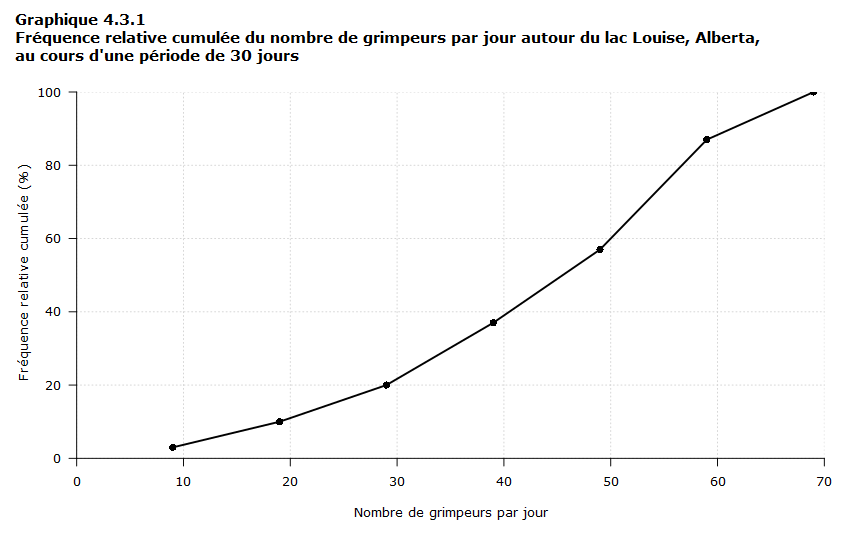
Tableau de données du graphique 4.3.1
| Borne supérieure de l’intervalle de classe du nombre de grimpeurs par jours | Fréquence relative cumulée (%) |
|---|---|
| 9 | 3 |
| 19 | 10 |
| 29 | 20 |
| 39 | 37 |
| 49 | 57 |
| 59 | 87 |
| 69 | 100 |
On peut voir au graphique 4.3.1 qu’au cours de la majorité (57 %) des jours de la période, le nombre de grimpeurs par jour a été inférieur ou égal à 49.
Une distribution de fréquence peut être visualisée à l’aide :
- d’un graphique circulaire (variable nominale),
- d’un graphique à barres (variable nominale ou ordinale),
- d’un graphique linéaire (variable ordinale ou discrète),
- ou d’un histogramme (variable continue ).
Ces types de graphiques seront présentés plus en détail dans la section 5 consacrée à la visualisation des données . Mais d’abord nous verrons d’autres méthodes pour résumer les données à l’aide des mesures de tendance centrale et de dispersion .
- Date de modification :