Méthode de perturbation multiniveau pour la protection des données tabulaires
Section 2. Contexte
La stratégie proposée vise à protéger
la confidentialité des tableaux de données quantitatives dans un cadre de
production semi-contrôlée de tableaux personnalisés. Elle a été conçue avant
tout pour des données administratives (s’apparentant à celles du recensement), et
notamment pour les données sur l’impôt des particuliers. À Statistique Canada,
la diffusion de telles données est assujettie à des règles de contrôle de la
divulgation, notamment la définition de tailles minimales de population pour
les régions géographiques identifiables, l’application de règles relatives à la
taille minimale des cellules et de règles de dominance pour supprimer des
cellules sensibles (confidentielles), ou le recours à une suppression de
cellules complémentaires (SCC) pour empêcher toute récupération de valeurs de
cellules sensibles.
Alors que l’utilisation des données
personnelles présente foncièrement moins de dangers que celle des données des
entreprises, les données personnelles font plus fréquemment l’objet de tableaux
personnalisés. Et si ces tableaux deviennent plus accessibles, il sera aussi de
plus en plus difficile de procéder efficacement à des suppressions de cellules
complémentaires. D’autres méthodes doivent donc être envisagées. La méthode que
nous proposons consiste à appliquer indépendamment une technique perturbatrice
à toute cellule non sensible de tout tableau. Seules les cellules sensibles
sont supprimées, bien qu’on puisse envisager d’en diffuser quelques-unes une
fois perturbées. La méthode vise à protéger les cellules sensibles des
tableaux, ainsi qu’à prévenir la divulgation par recoupements découlant de
tableaux multiples, surtout par la prise de différences sur des totaux
imbriqués. Le but dans ce cas est de protéger deux totaux qui diffèrent par
une unité.
Nous supposons l’existence d’un cadre
semi-contrôlé où l’accès est quelque peu restreint, ou du moins jamais anonyme,
et où donc il y a une surveillance et un contrôle quelconques des demandes.
C’est une précaution qui s’impose, puisqu’en offrant sans restriction des
tableaux à des pirates anonymes cherchant à exploiter toute vulnérabilité (en
particulier, en multipliant les demandes pour obtenir des ensembles d’unités
soigneusement choisis), on prête le flanc à une divulgation approximative de
valeurs d’unités dans certaines conditions. Notre méthode est conçue pour des
données s’apparentant à celles du recensement, qui sont plus à risque, mais
elle pourrait sans aucun doute s’adapter à des données-échantillons au besoin.
Notre stratégie convient mieux aux données personnelles, car elles sont moins
susceptibles de dominance que les données des entreprises et les cellules quasi
dominantes sont celles qui sont perturbées le plus. Mais sous réserve d’une
certaine adaptation, les utilisateurs seraient à même de constater dans quelle
mesure la stratégie pourrait répondre à leurs besoins pour d’autres types de données.
Dans la mesure du possible, nous
aimerions employer cette stratégie pour remédier à d’autres problèmes de
divulgation, notamment assurer la protection des rapports et d’autres genres de
données. D’autres avantages seraient la capacité de traiter les zéros et les
valeurs négatives, le maintien de la qualité des données, la préservation de
l’additivité des tableaux, et des aspects opérationnels comme la simplicité de
calcul et le recours à un minimum d’intervention manuelle.
Dans le présent exposé, nous appliquons
une règle du pourcentage
pour reconnaître les totaux
de cellules sensibles, une cellule étant sensible si la contribution globale
des plus petites unités, à partir de la troisième en importance, est inférieure
à tel pourcentage
de la valeur de la plus
grande unité (si
où
est le total de la cellule et
où
est la contribution de sa
unité en importance). Nous
supposons que les cellules non conformes à la règle de la taille minimale de
cellule sont sensibles elles aussi.
Nous désirons préserver la qualité et
la confidentialité des données quantitatives dans un cadre de production de
tableaux personnalisés. Des techniques applicables à des tableaux de données
quantitatives comme la suppression de cellules complémentaires (Cox et Sande 1979)
et l’ajustement tabulaire contrôlé (Cox et Dandekar 2004) ne donnent pas de
très bons résultats dans un tel cadre. Il nous faut résoudre des problèmes
d’optimisation pour dégager des solutions par tableau. Des problèmes commencent
à se poser quand on a à protéger des tableaux vastes, complexes ou liés (couplés);
on sera alors incapable d’en venir à une solution ou bien une démarche
heuristique risquera de créer des incohérences de suppression ou de
perturbation qu’exploiteraient des pirates. Il est bien plus facile de
perturber directement les totaux de cellules, notamment par l’application d’un
bruit aléatoire, mais on aura toujours à s’attacher aux microdonnées pour
assurer une protection suffisante, tout en contrôlant l’effet sur la qualité.
Sans des mesures complémentaires, des incohérences pourraient apparaître dans
et entre les tableaux, et les pirates en profiteraient.
Une perturbation des microdonnées,
c’est-à-dire au niveau des microdonnées, convient mieux à un cadre
multitableaux. Les tableaux sont additifs et habituellement exempts de toute
suppression, et les résultats sont cohérents entre tableaux. Si l’on permet des
tableaux personnalisés, quelqu’un pourrait peut-être récupérer certaines
valeurs perturbées, soit directement, soit par prise de différences. Le degré
de bruit appliqué à chaque unité doit donc être assez élevé pour qu’on réalise
le degré d’ambiguïté recherché, et c’est pourquoi le bruit accumulé risque
d’être ample pour des agrégats donnés. Une méthode de perturbation des
microdonnées conçue et employée au U.S.
Census Bureau s’appelle la méthode EZS (Evans, Zayatz et Slanta 1998). Elle
consiste à multiplier les différentes valeurs
par un poids
où
représente des variables
aléatoires indépendantes et identiquement distribuées (i.i.d.) à moyenne 0 et à
variance
Mentionnons deux distributions
des
d’intérêt, soit la
distribution triangulaire divisée (voir la figure 2.1) et la distribution
uniforme divisée (voir la figure 2.2) où les valeurs correspondantes de
sont
et
respectivement. Les
(ou les
sont attachés en permanence à
leur unité
Comme le même bruit est
appliqué à toutes les variables, il n’y a aucune incidence sur les rapports.
S’il est nécessaire de protéger les rapports, il devrait y avoir des valeurs de
pondération
différentes selon les
variables, ou des poids par unité pourraient être utilisés conjointement avec
des poids par variable d’unité.
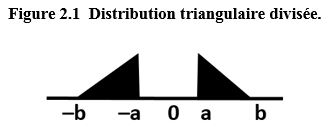
Description de la figure 2.1
Figure illustrant la distribution triangulaire divisée. La distribution est nulle jusqu’à Les valeurs croissent ensuite de façon linéaire de à la distribution formant un triangle. Par la suite, la distribution est nulle. Elle reprend à et décroît linéairement vers la distribution formant un second triangle. Après, la distribution est nulle.

Description de la figure 2.2
Figure illustrant la distribution uniforme divisée. La distribution est non nulle seulement de à et de à formant deux rectangles identiques.
Il existe des moyens d’atténuer l’effet
accumulé de la perturbation des microdonnées sur la qualité. Massell et Funk
(2007) proposent d’équilibrer les bruits aléatoires appliqués aux cellules d’un
tableau primaire pour limiter leur incidence. Dans d’autres méthodes, on
perturbe les microdonnées, mais pas toujours de la même manière et en créant
donc certaines incohérences dans les résultats. Giessing (2011) propose de
multiplier les valeurs d’unités
par
pour
i.i.d.
sauf dans les cellules
sensibles, où la valeur la plus grande serait multipliée par
On choisit la valeur
pour assurer un degré
approprié de protection des cellules sensibles, d’où la possibilité d’utiliser
dans l’ensemble une valeur inférieure de
Il reste que, si
est trop bas, la méthode ne
protège peut-être pas suffisamment contre la divulgation par prise de
différences. L’Australian Bureau of
Statistics a conçu la méthode des principales contributions (Top Contributors Method ou TCM) pour son
application d’accès à distance TableBuilder; celle-ci consiste à perturber les
principaux répondants dans chaque cellule d’une manière semi-cohérente, seule
une partie du bruit étant appliquée uniformément (Thompson, Broadfoot et Elazar
2013). La méthode de perturbation multiniveau fait appel à certains de ces
concepts, mais elle protège davantage contre la prise de différences, comme nous
allons l’expliquer.
D’autres stratégies courantes comme
l’arrondissement, l’échantillonnage (ou le sous-échantillonnage) et l’échange
d’unités, entre régions voisines disons, se prêtent mieux à une protection des
tableaux statistiques.
ISSN : 1712-5685
Politique de rédaction
Techniques d’enquête publie des articles sur les divers aspects des méthodes statistiques qui intéressent un organisme statistique comme, par exemple, les problèmes de conception découlant de contraintes d’ordre pratique, l’utilisation de différentes sources de données et de méthodes de collecte, les erreurs dans les enquêtes, l’évaluation des enquêtes, la recherche sur les méthodes d’enquête, l’analyse des séries chronologiques, la désaisonnalisation, les études démographiques, l’intégration de données statistiques, les méthodes d’estimation et d’analyse de données et le développement de systèmes généralisés. Une importance particulière est accordée à l’élaboration et à l’évaluation de méthodes qui ont été utilisées pour la collecte de données ou appliquées à des données réelles. Tous les articles seront soumis à une critique, mais les auteurs demeurent responsables du contenu de leur texte et les opinions émises dans la revue ne sont pas nécessairement celles du comité de rédaction ni de Statistique Canada.
Présentation de textes pour la revue
Techniques d’enquête est publiée en version électronique deux fois l’an. Les auteurs désirant faire paraître un article sont invités à le faire parvenir en français ou en anglais en format électronique et préférablement en Word au rédacteur en chef, (statcan.smj-rte.statcan@canada.ca, Statistique Canada, 150 Promenade du Pré Tunney, Ottawa, (Ontario), Canada, K1A 0T6). Pour les instructions sur le format, veuillez consulter les directives présentées dans la revue ou sur le site web (www.statcan.gc.ca/Techniquesdenquete).
Note de reconnaissance
Le succès du système statistique du Canada repose sur un partenariat bien établi entre Statistique Canada et la population, les entreprises, les administrations canadiennes et les autres organismes. Sans cette collaboration et cette bonne volonté, il serait impossible de produire des statistiques précises et actuelles.
Normes de service à la clientèle
Statistique Canada s'engage à fournir à ses clients des services rapides, fiables et courtois. À cet égard, notre organisme s'est doté de normes de service à la clientèle qui doivent être observées par les employés lorsqu'ils offrent des services à la clientèle.
Droit d'auteur
Publication autorisée par le ministre responsable de Statistique Canada.
© Ministre de l'Industrie, 2017
L'utilisation de la présente publication est assujettie aux modalités de l'Entente de licence ouverte de Statistique Canada.
N° 12-001-X au catalogue
Périodicité : Semi-annuel
Ottawa
