
Publications
Le Bulletin technique et d'information des Centres de données de recherche
Évaluation de l'effet des observations influentes potentielles dans la régression logistique pondérée
 Consulter la version la plus récente.
Consulter la version la plus récente.
Information archivée dans le Web
L’information dont il est indiqué qu’elle est archivée est fournie à des fins de référence, de recherche ou de tenue de documents. Elle n’est pas assujettie aux normes Web du gouvernement du Canada et elle n’a pas été modifiée ou mise à jour depuis son archivage. Pour obtenir cette information dans un autre format, veuillez communiquer avec nous.
par Bridget L. Ryan, John Koval, Bradley Corbett, Amardeep Thind, M. Karen Campbell, and Moira Stewart.
- Introduction
- Données et méthodes
- Résultats
- Discussion
- Bibliographie
- Annexe 1 – Algorithme pour l'évaluation des observations potentiellement influentes dans la régression logistique pondérée en SAS 9.1
- Annexe 2 – Évaluation des observations potentiellement influentes dans la régression logistique pondérée avec SAS 9.1
- Annexe 3 – Évaluation des observations potentiellement influentes dans la régression logistique pondérée avec SAS – résultats de SAS
Introduction
En régression logistique, les observations influentes peuvent être décrites comme étant celles qui ont un effet notable sur certains aspects de l’adéquation du modèle logistique linéaire, comme les estimations des paramètres ou les statistiques d’ajustement. Collett (2003), ainsi que Hosmer et Lemeshow (2000) expliquent en détail comment déceler les observations influentes dans le cas de la régression logistique classique. D’aucuns considèrent que l’utilisation d’ensembles de données issus d’échantillons de grande taille (p. ex. les données d’enquête de Statistique Canada) atténue les risques d’observations influentes potentielles parce que la contribution de toute observation particulière est minimisée. Cependant, des observations influentes peuvent exister dans ces grands échantillons. Ainsi, des observations risquent d’être influentes si elles ont un poids élevé qui se traduit par un effet important sur les estimations des paramètres (Macnab et coll., 2005). Par conséquent, il est important de repérer les observations influentes potentielles quand on procède à une régression logistique en utilisant les données de Statistique Canada. Les articles contenant des renseignements sur les diagnostics d’influence, particulièrement dans le cas des données d’enquêtes complexes sont rares (celui de Roberts, Rao et Kumar (Roberts et coll., 1987) étant l’un d’entre eux); malheureusement, les tests diagnostiques élaborés dans ces articles ne sont disponibles dans aucun des progiciels utilisés à l’heure actuelle pour l’analyse des données d’enquête complexes. Cependant, Heeringa et coll. (2010, p. 245), par exemple, font la recommandation suivante :
[Traduction] « Utilisez une ou plusieurs des techniques décrites au chapitre 5 de Hosmer et Lemeshow (2000) pour évaluer l’adéquation du modèle pour les structures individuelles de covariables. Si le programme de modélisation par régression logistique pour échantillon complexe implémenté dans le système logiciel que vous avez choisi (p. ex. SAS PROC SURVEYLOGISTIC) n’inclut pas l’ensemble complet de fonctions diagnostiques du programme standard, utilisez le programme standard (p. ex. SAS PROC LOGISTIC) avec une spécification des poids. Comme il est mentionné plus haut, les estimations pondérées des paramètres et les probabilités prédites seront identiques, les défaillances graves du modèle pour des structures de covariables particulières devraient pouvoir être identifiées même si le programme standard ne reflète pas correctement les variances et les covariances des estimations des paramètres étant donné le plan d’échantillonnage complexe. »
Le présent article a pour objectif d’appliquer cette recommandation aux diagnostics de la sensibilité des coefficients en décrivant un algorithme et un code simples pour examiner les observations influentes potentielles dans des données pondérées en utilisant le logiciel SAS (SAS Institute Inc., 2009).
Données et méthodes
Source des données et échantillon
L’algorithme et le code décrits dans le présent article ont été appliqués dans une étude visant à examiner les facteurs associés à l’utilisation des services des médecins de famille par les adolescents au Canada (Ryan et coll., 2011). L’étude a été réalisée selon un plan transversal, en vue de procéder à une analyse secondaire des données fournies par les adolescents et les jeunes adultes qui ont participé à l’Enquête sur la santé dans les collectivités canadiennes (ESCC) de 2005 (cycle 3.1) (Statistique Canada, questionnaire, 2005; Statistique Canada, Guide de l’utilisateur, 2005). Les tailles d’échantillon pour l’étude étaient de 4 985 enquêtés au début de l’adolescence (12 à 14 ans), de 8 718 au milieu de l’adolescence (15 à 19 ans), et de 6 681 au début de l’âge adulte (20 à 24 ans).
Le centre de données de recherche (CDR) de Statistique Canada a autorisé l’accès à ces données à l’Université Western Ontario. L’approbation du comité d’éthique de la recherche en sciences de la santé de l’Université Western Ontario n’était pas nécessaire, parce qu’il s’agissait d’une analyse secondaire de données d’enquête, sans aucune possibilité d’identifier les participants individuels à l’enquête.
Plan d’analyse de l’étude
L’analyse complète, décrite ailleurs (Ryan et coll., 2011) et résumé ici, a été réalisée séparément pour trois groupes d’âge, à savoir le début de l’adolescence, le milieu de l’adolescence et le début de l’âge adulte. Deux régressions logistiques ont été effectuées pour chaque groupe d’âge, ce qui donne un total de six régressions. Le logiciel utilisé pour l’analyse fondé sur le plan de sondage se sert des poids de sondage pour ajuster l’échantillon afin de tenir compte de la probabilité inégale d’être sélectionnée et utilise la méthode bootstrap pour ajuster les intervalles de confiance afin de tenir compte de l’effet de la complexité du plan de sondage. La variable dépendante de la première régression représente l’utilisation ou non des services d’un médecin de famille au cours des 12 derniers mois par l’adolescent. Pour les enquêtés qui avaient utilisé les services, la variable dépendante de la deuxième régression logistique indique si l’adolescent était un utilisateur fréquent (4 visites ou plus) ou peu fréquent (1 à 3 visites) des services. Les variables indépendantes ont été choisies conformément au Behavioral Model of Health Services Use d’Andersen (Andersen, 1995). Dans la mesure du possible, les mêmes variables ont été utilisées pour chacun des trois groupes d’âge afin de faciliter les comparaisons entre groupes, et les variables sans effet significatif ont été gardées dans les modèles pour faciliter la présentation des résultats pour les divers groupes d’âge. Les variables prédisposantes disponibles et utilisées étaient l’âge, le sexe, la fréquentation scolaire et le niveau d’études atteint, le groupe ethnique, l’appartenance à la collectivité, l’état matrimonial (début de l’âge adulte), ainsi que la situation d’emploi (milieu de l’adolescence et début de l’âge adulte). Les variables facilitantes utilisées étaient l’adéquation du revenu du ménage, les modalités de logement (début de l’âge adulte), le fait d’avoir un médecin traitant et la géographie (région urbaine ou rurale). Les variables de besoins perçus étaient la santé générale autoévaluée, la santé mentale autoévaluée, l’opinion quant à son propre poids et le stress (disponible pour les jeunes du milieu de l’adolescence et du début de l’âge adulte seulement). Les variables de besoins évalués étaient la catégorie d’IMC et le nombre de problèmes de santé chroniques. Pour les habitudes ayant une incidence sur la santé, les variables utilisées étaient l’activité physique, l’usage du tabac, l’activité sexuelle (disponible pour les jeunes du milieu de l’adolescence et du début de l’âge adulte seulement) et la consommation d’alcool. L’ESCC ne fournit pas de données sur les variables du système de soins de santé ni de l’environnement externe; toutefois, la province a été utilisée comme mesure contextuelle.
Détection des observations influentes potentielles
Dans l’étude complète, chacun des six modèles de régression logistique a été évalué afin de déterminer, dans chaque ensemble de données, si des observations avaient une influence exagérée sur les estimations des paramètres de la régression logistique. La détection des observations influentes potentielles a été effectuée au moyen du logiciel SAS version 9.1 (SAS Institute Inc., 2009). La procédure SAS PROC LOGISTIC ajuste un modèle logistique en utilisant les poids et peut produire plusieurs des statistiques de diagnostic d’influence décrites dans Hosmer et Lemeshow (2000). Bien que ces statistiques ne tiennent pas compte de façon appropriée de toutes les caractéristiques du plan de sondage (comme la façon dont les estimations de la variance sont calculées) et qu’il soit trop compliqué de représenter graphiquement leurs valeurs pour chaque point de donnée (en raison de la grande taille de l’échantillon), elles sont néanmoins utiles, car elles permettent au chercheur de déceler les cas susceptibles d’exercer une influence exagérée sur les estimations des paramètres en se servant des poids qui figurent dans les données d’enquête de Statistique Canada. Il convient de souligner qu’à l’heure actuelle, la version 9.3 de SAS contient la procédure PROC SURVEY LOGISTIC; cependant, les statistiques de diagnostic requises ne sont pas disponibles.
L’examen des observations influentes potentielles a été axé principalement sur deux statistiques, à savoir le diagnostic de déplacement de l’intervalle de confiance (diagnostic C) et le diagnostic DFbeta proposé par Pregibon (1981). On a calculé ces statistiques, puis groupé les données de sortie en ensembles de données distincts en se servant de certaines commandes après la commande de régression logistique. L’annexe 1 décrit l’algorithme appliqué pour la détection et l’examen des observations influentes potentielles. L’annexe 2 donne le code SAS utilisé pour déceler les observations influentes potentielles. Il convient de souligner que les formules pour le calcul de la statistique C et des DFbeta contiennent chacune des éléments de variance qui, idéalement, devraient être estimés par la méthode du bootstrap. Comme il est mentionné plus haut, SAS estime le modèle en utilisant le bootstrap; par contre, le programme ne peut pas calculer les statistiques susmentionnées en appliquant la méthode du bootstrap.
Le « diagnostic de déplacement de l’intervalle de confiance » fournit des mesures scalaires de l’influence des observations individuelles sur les estimations des paramètres de régression logistique. Une mesure scalaire est une mesure qui donne la grandeur de l’influence exercée sur les estimations, mais non sa direction. On calcule une statistique C pour chacune des observations pour la régression logistique globale. Le diagnostic C est basé sur le même principe que la distance de Cook dans la théorie de la régression linéaire (SAS Institute Inc., 2009). Les observations dont la valeur de la statistique C est plus grande que 1 sont généralement considérées comme des observations influentes potentielles (Hosmer, 2000, p. 180). Cependant, puisque la variance a été estimée sans procédure bootstrap approprié pour tenir compte de l’effet de plan de sondage, les valeurs seuils suggérées doivent être utilisées avec prudence. Il importe d’examiner toute valeur inhabituellement grande comme étant une indication d’une influence possible (Hosmer, 2000). Par conséquent, le code comprend aussi la procédure PROC UNIVARIATE qui imprimera les cinq valeurs les plus faibles et les cinq valeurs les plus élevées, indépendamment de la grandeur absolue.
La formule pour le calcul de la statistique C utilisée par SAS (SAS Institute, 2008) est donnée ci-après. Elle est fondée sur celle élaborée par Pregibon (1981), mais a été modifiée spécialement pour la régression logistique :
(1)
où
(2)
et
(3)
En outre,
rj est la réponse (0 ou 1),
wj est le poids de la je observation,
πj est la probabilité d’une réponse pour la je observation qui est donnée par
πj = F(β0 + βˊ xj), où F(∙ ) est la fonction de lien inverse,
b est l’estimation du maximum de vraisemblance (EMV) de (β0 β1…βs )ˊ,
s est le nombre de variables,
est la matrice de covariance estimée de b,
pj est l’estimation de πj évaluée à b,
et qj = 1- pj.
Une limite de la statistique C tient au fait qu’il s’agit d’une mesure sommaire de la variation sur l’ensemble des coefficients présents dans le modèle. Par conséquent, il est important d’examiner les variations des coefficients individuels (Hosmer, 2000, p. 181). Le DFbeta est la différence standardisée induite dans l’estimation du paramètre par la suppression d’une observation donnée. Les DFbetas sont utiles pour déceler les observations qui entrainent des variations des coefficients (SAS Institute Inc., 2009). Comme la distribution sous-jacente des DFbetas est inconnue, il n’existe aucun moyen sûr de déterminer ce qui constitue une « grande » différence. La convention consiste donc à utiliser la valeur de 2, qui coïncide à peu près avec la valeur critique usuelle de la loi normale (1,96). Donc, pour toute variable donnée, les observations dont le DFbeta est plus grand que 2 sont considérées comme des observations pouvant être influentes. Comme dans le cas de la statistique C, l’erreur-type a été estimée sans recours à la méthode du bootstrap approprié, de sorte que l’utilisation des valeurs seuils suggérées doit de nouveau se faire avec prudence. Il importe d’examiner toutes valeurs inhabituellement grandes comme étant un indice d’une influence possible. Par conséquent, le code SAS comprend aussi la procédure PROC UNIVARIATE qui imprimera les cinq valeurs les plus faibles et les cinq valeurs les plus élevées, indépendamment de la grandeur absolue.
Les observations influentes potentielles ont été décelées en utilisant la formule donnée par SAS (SAS Institute Inc., 2008) (établie par Pregibon, 1981).
(4)
où
σi est l’erreur-type de la ie composante de b,
Δi bj1 est la ie composante de la différence en une étape, et
(5)
Autrement dit, Δbj1 est une approximation de la variation, b - bj1, du vecteur des estimations des paramètres due à l’omission de la je observation.
Évaluation des observations influentes potentielles
Après avoir détecté les observations influentes potentielles, l’étape suivante consistait à exécuter les régressions logistiques en excluant toutes les observations signalées par l’une ou l’autre statistique comme pouvant être influentes. Les estimations des paramètres obtenues en utilisant tous les cas dans la régression ont été comparées à celles obtenues en supprimant les observations influentes potentielles. Les chercheurs doivent décider quelle variation des estimations des paramètres est considérée comme étant importante pour une étude particulière (Rothman, 1998). Dans la présente étude, les variations des estimations des paramètres supérieures à 10 % ont été jugées importantes. En cas de variations importantes des paramètres, les observations doivent être examinées minutieusement afin de déterminer s’il n’existe pas une structure de covariance commune associée aux observations influentes.
Les chercheurs doivent décider si ces observations font partie de la population étudiée ou non. Si elles ne peuvent pas être considérées comme des valeurs aberrantes et qu’elles font effectivement partie de la population étudiée, elles doivent rester dans le modèle.
Résultats
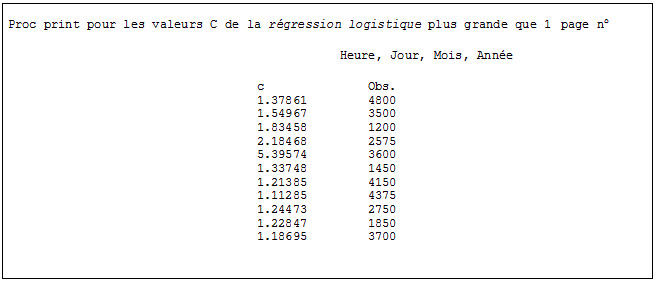
Bien que les six régressions de l’étude complète aient été toutes examinées afin de déceler les observations influentes potentielles, l’une d’entre elles seulement est présentée ici à titre d’illustration, à savoir la régression pour le groupe des jeunes adultes et la variable de résultat correspondant au fait que la personne avait utilisé ou non les services d’un médecin de famille. L’annexe 3 donne un exemple annoté des données de sortie pour la statistique C. Une méthode de perturbation a été utilisée pour modifier les nombres d’observations et les valeurs de la statistique C afin de protéger le caractère confidentiel des données.
Pour la statistique C, onze cas associés à une grande valeur de cette statistique ont été décelés. Cela donnait à penser qu’il s’agissait peut-être d’observations influentes et justifiait un examen plus approfondi. Les DFbetas ont alors été examinés, et aucun cas ne présentait une grande valeur pour aucune variable. L’absence de cas dont la valeur du DFbetas était grande laissait entendre qu’il n’y avait pas d’observations influentes potentielles causant une instabilité excessive des estimations des paramètres. Les onze observations considérées comme potentiellement influentes en se basant sur la statistique C ont été supprimées et la régression logistique a de nouveau été exécutée. Les valeurs de trois paramètres non significatifs ont varié de plus de 10 %; cependant, aucun de ces paramètres n’est passé de l’état non significatif à l’état significatif en raison de cette variation. Par conséquent, il a été décidé d’inclure tous les cas dans le modèle de régression publié.
Discussion
Le présent article fournit un algorithme et un code SAS qui peuvent être appliqués facilement aux analyses portant sur des données d’enquêtes complexes, comme l’Enquête sur la santé dans les collectivités canadiennes, afin de déceler les observations influentes potentielles dans les modèles de régression logistique. Il est recommandé d’utiliser avec prudence les valeurs seuils automatiques pour la détection des observations influentes potentielles. Kleinbaum, Kupper et Muller (1988, p. 201) soulignent que [traduction] « dans chaque échantillon, une observation doit être la plus extrême. Il serait idiot de supprimer automatiquement cette observation la plus extrême, ou un groupe d’observations extrêmes, en se basant sur des tests statistiques. L’objectif des diagnostics de régression pour l’évaluation des valeurs aberrantes est d’avertir l’analyste des données qu’il doit examiner de plus près ces observations extrêmes. Le jugement scientifique devient plus important que les tests statistiques une fois que les observations influentes ont été repérées ». Le chercheur doit plutôt décider de la façon de traiter les observations influentes potentielles en s’appuyant sur sa connaissance de la population étudiée et un examen minutieux des données comme il est décrit ici. Une fois la décision prise, celle-ci doit être énoncée dans la section des résultats du manuscrit et la discussion doit expliquer le raisonnement et les effets possibles de la décision.
Bibliographie
Andersen RM. 1995. “Revisiting the behavioral model and access to medical care: does it matter?”. J Health Soc Behav. Vol. 36. no. 1, 1-10.
Collett D. 2003. Modelling Binary Data. [2nd ed]. Boca Raton, FL: Chapan & Hall/CRC Press.
Gagné, C., Roberts, G., and Keown, L.A. 2014. Estimation pondérée et estimation de la variance bootstrap pour analyser des données d’enquête : Comment les effectuer dans certains logiciels choisis? Le Bulletin technique et d'information des Centres de données de recherche, (hiver) vol. 6 no. 1, 5-70. no 12-002-X au catalogue de Statistique Canada. http://www.statcan.gc.ca/pub/12-002-x/2014001/article/11901-fra.htm (consulté le 17 juillet 2014)
Heeringa S, West B, Berglund P. 2010. Applied Survey Data Analysis. Boca Raton, FL: Chapman and Hall/CRC Press.
Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression. [2nd ed]. New York: Wiley.
Kleinbaum DG, Kupper LL, Muller KE. 1988. Applied Regression Analysis and Other Multivariable Methods. [2nd ed]. Belmont,CA: Duxbury Press.
Macnab JJ, Koval JJ, Speechley KN, Campbell MK. 2005. "Influential observations in weighted analyses: examples from the National Longitudinal Survey of Children and Youth (NLSCY)". Chronic Dis Can 2005; Vol. 26, no. 1, 1-8. See http://www.ncbi.nlm.nih.gov/pubmed/16117839. (accessed January 31, 2012).
Pregibon D. 1981. Logistic Regression Diagnostics. Annals of Statistics. Vol. 9. no. 4, 705-724.
Roberts G, Rao JNK, Kumar S. 1987. "Logistic-Regression Analysis of Sample Survey Data". Biometrika. Vol. 74, no. 1, 1-12. See http://biomet.oxfordjournals.org/content/74/1/1.full.pdf. (accessed January 31, 2012).
Rothman KJ, Greenland S. 1998. Modern Epidemiology. [2nd ed]. Philadelphi, PA: Lippincott Williams & Wilkins.
Ryan BL, Stewart M, Campbell MK, Koval J, Thind A. 2011. "Understanding adolescent and young adult use of family physician services: a cross-sectional analysis of the Canadian Community Health Survey". BMC Family Practice. Vol. 12, no. 118, 1-10.
SAS Institute Inc. 2009. SAS/Stat 9.1 Software. Cary, NC.
SAS Institute Inc. 2008. Regression Diagnostics, SAS 9.1 Online Documentation. (Path - SAS/STAT; SAS/STAT User’s Guide; The Logistic Procedure; Details; Regression Diagnostics).
Statistique Canada. 2005. Enquête sur la santé dans les collectivités canadiennes (ESCC) Cycle 3.1. (questionnaire http://www23.statcan.gc.ca/imdb/p2SV_f.pl?Function=getSurvey&SurvId=1630&InstaId=22642&SDDS=3226 [consulté : URL: http://www23.statcan.gc.ca/imdb-bmdi/instrument/3226_Q1_V3-fra.pdf]
Statistique Canada. 2005. Enquête sur la santé dans les collectivités canadiennes (ESCC) Cycle 3.1. Guide de l'utilisateur. http://www23.statcan.gc.ca/imdb/p2SV_f.pl?Function=getSurvey&SurvId=1630&InstaId=22642&SDDS=3226 [consulté: URL: http://www23.statcan.gc.ca/imdb-bmdi/document/3226_D7_T9_V3-fra.pdf]
Annexe 1 – Algorithme pour l’évaluation des observations potentiellement influentes dans la régression logistique pondérée en SAS 9.1
- Estimer un modèle de régression logistique à l’aide d’une logiciel en utilisant une méthode d’inférence basée sur le plan de sondage (application des poids populationnels et des poids bootstrap).
- Déterminer les observations potentiellement influentes à l’aide de SAS 9.1. (Annexe 2).
- Estimer le modèle de la régression logistique avec les poids normalisés (Gagné, Roberts et Keown, 2014).
- Sauvegarder les résultats de la régression logistique dans un fichier temporaire (Statistique de déplacement de l’intervalle de confiance (statistique C)).
- Utiliser la procédure univariate pour la statistique C. Examiner les valeurs extrêmes. Si les cinq valeurs sont toutes supérieures à 1 (ce qui donne lieu à penser qu’il pourrait y en avoir plus que cinq), utiliser la procédure print pour imprimer tous les cas pour lesquels la statistique C est plus grande que 1.
- Sauvegarder les résultats dans un autre fichier temporaire (Statistique DFbeta provenant de la régression logistique).
- Utiliser la procédure univariate pour la statistique DFbeta. Examiner les valeurs extrêmes. Si les cinq valeurs sont toutes supérieures à 2 (ce qui donne lieu à penser qu’il pourrait y en avoir plus que cinq), utiliser la procédure print pour imprimer tous les cas pour lesquels le DFbeta est plus grand que 2.
- Supprimer les observations influentes et déterminer l’effet sur le modèle.
- Créer une réplique de l’ensemble de données données et supprimer les observations influentes potentiellement repérées au moyen de la statistique C ou des DFbetas.
- Estimer de nouveau la régression logistique en utilisant les poids normalisés1 avec cette réplique de l’ensemble de données.
- Créer un chiffrier Excel avec une colonne pour les estimations des paramètres (tous les cas utilisés) et une deuxième colonne pour les estimations des paramètres (observations potentiellement influentes supprimées). Dans les troisième et quatrième colonnes, pour chaque estimation de paramètre, calculer respectivement la différence absolue et la différence en pourcentage, entre les deux régressions logistiques.
- Déterminer quelle grandeur de la variation des estimations des paramètres est considérée comme influente pour l’étude en question; par exemple, une variation de 10 % de l’estimation d’un paramètre.
- Comparer les différences afin de voir si la suppression des observations potentiellement influentes a eu une incidence sur les estimations des paramètres. Marquer d’un repère les différences en pourcentage supérieures à 10 % comme étant des estimations des paramètres qui ont été modifiés de manière significative par les observations influentes.
- Examiner les raisons des différences, telles que des poids élevés, d’éventuelles erreurs de codage des données ou des structures de covariance unique.
Annexe 2 – Évaluation des observations potentiellement influentes dans la régression logistique pondérée avec SAS 9.1
*Le code écrit en caractères gras se rapporte aux en-têtes;
*Le code écrit en italiques se rapporte au nom de fichiers et de variables qui varieront selon l’ensemble de données et les variables utilisés;


Annexe 3 – Évaluation des observations potentiellement influentes dans la régression logistique pondérée avec SAS – résultats de SAS
Les résultats de la régression logistique apparaîtront d’abord dans leur format habituel, puis seront suivies par les résultats de la procédure « Univariate » et/ou les résultats de la procédure « Print » comme il est illustré ci- dessous.
A. Résultats pour les valeurs extrêmes du déplacement de l’intervalle de confiance

B. Résultats de la procédure « Print » pour les valeurs du déplacement de l’intervalle de confiance plus grandes que 1
- Date de modification :