
Comptes des revenus et dépenses, série technique
Tableaux annuels de répartition des ménages, Estimations provisoires des répartitions des actifs, des passifs et de la valeur nette, 2010 à 2016: Méthodologie technique et rapport sur la qualité
 Consulter la version la plus récente.
Consulter la version la plus récente.
Information archivée dans le Web
L’information dont il est indiqué qu’elle est archivée est fournie à des fins de référence, de recherche ou de tenue de documents. Elle n’est pas assujettie aux normes Web du gouvernement du Canada et elle n’a pas été modifiée ou mise à jour depuis son archivage. Pour obtenir cette information dans un autre format, veuillez communiquer avec nous.
1 Aperçu
L’économie mondiale a connu des changements structurels importants au cours des dernières années, attribuables en partie à la crise financière mondiale de 2008 et à la mondialisation accrue. Les répercussions des changements macroéconomiques sur les ménages constituent dorénavant une priorité pour les décideurs, alors que l’inégalité et la stabilité financière deviennent des thèmes communs sur la scène internationale. Statistique Canada et d’autres organismes statistiques peuvent contribuer à élargir le corpus de recherche sur ce sujet en publiant des données plus complètes, pertinentes et détaillées sur l’inégalité financière à l’échelle nationale.
Statistique Canada a entrepris d’élaborer de nouveaux ensembles de données qui décrivent la valeur nette des ménages répartie selon diverses caractéristiques des ménages en vue de définir plus précisément qui détient la richesse au Canada. Ces nouvelles données fourniront aux décideurs et aux universitaires de nouveaux outils pour examiner l’inégalité et ses répercussions sur notre société. Il s’agit des Tableaux annuels de répartition des ménages (TARM). Les données des TARM réuniront le niveau de détail disponible dans les sources de microdonnées et les concepts du Système de comptabilité nationale (SCN) couverts par les macrodonnées, qui offrent une couverture plus complète et sont comparables à l’échelle internationale. La principale source de microdonnées est l’Enquête sur la sécurité financière (ESF), une enquête auprès des ménages qui permet de recueillir de l’information sur l’actif, l’endettement et le patrimoine (valeur nette). L’ESF n’est pas une enquête annuelle, de sorte qu’une méthodologie différente est nécessaire pour les années avec enquête et les années sans enquête.
Le présent document présente en détail la méthodologie utilisée pour produire des répartitions provisoires de la valeur nette des ménages pour les années de référence 2010 à 2016. Il présente d’abord une description du cadre international du groupe d’experts de l’OCDE sur les disparités à l’intérieur des comptes nationaux (GE DCN), qui fournit des recommandations pour produire des renseignements sur la répartition conformes aux concepts du Système de comptabilité nationale. La mise en œuvre de chaque étape par Statistique Canada est ensuite décrite. Ces étapes comprennent les ajustements aux totaux des comptes nationaux; une description des sources de microdonnées; la méthodologie utilisée pour dériver des indicateurs pour les années avec enquête et les années sans enquête; et une description des sources d’erreur possibles. Une grande partie du document est axée sur la méthodologie utilisée pour les années pour lesquelles des données d’enquête ne sont pas disponibles. Pour ces années, une modélisation est nécessaire pour dériver les répartitions de la richesse. L’approche de modélisation sera décrite, de même que les divers ajustements nécessaires pour assurer la cohérence interne des tableaux et la cohérence avec les totaux macroéconomiques.
Il s’agit là de la première étape en vue d’obtenir un cadre intégré de répartitions comprenant le revenu, la consommation, l’épargne et le patrimoine. Les tableaux produits à l’aide de cette méthodologie sont de nature provisoire et feront l’objet de révisions à mesure que la méthodologie sera peaufinée.
2 Introduction
Statistique Canada publie régulièrement des indicateurs macroéconomiques sur les actifs, les passifs et la valeur nette des ménages dans le cadre des comptes du bilan national (CBN) trimestriels. Ces comptes correspondent aux plus récentes normes internationales et constituent la source des estimations du patrimoine national pour tous les secteurs de l’économie, y compris les ménages, les institutions sans but lucratif, les administrations publiques et les sociétés, de même que la position du Canada en matière de richesse par rapport au reste du monde. Bien que les CBN fournissent des renseignements de grande qualité sur la position globale des ménages relativement aux autres secteurs économiques, ils ne possèdent pas la granularité requise pour comprendre les vulnérabilités de certains groupes particuliers et les conséquences qui en résultent sur le plan du bien-être économique et de la stabilité financière.
On reconnaît de plus en plus, tant au Canada qu’à l’échelle internationale, l’importance croissante d’intégrer les dimensions de répartition dans les indicateurs macroéconomiques des ménages. Lorsque les renseignements sur les disparités entre les ménages sont mis en correspondance avec les indicateurs macroéconomiques, ils permettent de mieux comprendre les développements économiques et de mieux évaluer les risques liés, par exemple, à l’augmentation de la polarisation du revenu, de la consommation, de l’épargne et de la richesse.
De récentes révisions exhaustives du Système canadien des comptes macroéconomiques publiées en 2012 et en 2015 ont permis de mieux positionner le programme des statistiques macroéconomiques pour entreprendre ces travaux. Des changements ont été apportés afin d’harmoniser les mesures aux nouvelles normes internationales, y compris la création d’un secteur distinct pour les institutions sans but lucratif au service des ménages (qui faisait auparavant partie du secteur des ménages) et la mesure des régimes de pension d’employeur selon l’admissibilité. Vous trouverez plus de précisions sur les changements apportés lors des révisions publiées en 2012 et en 2015 en consultant Analyse des révisions – Système de comptabilité nationale du Canada 2012 et Résultats de la révision exhaustive du Système canadien des comptes macroéconomiques de 2015.
Cette documentation donne un aperçu d’une première étape vers un programme plus complet d’estimations des répartitions annuelles pour le secteur des ménages dans les comptes macroéconomiques canadiens. Elle présente également la méthodologie utilisée pour élaborer, dans les tableaux annuels de répartition des ménages (TARM), des répartitions provisoires du patrimoine pour le secteur des ménages des comptes du bilan national (CBN) pour les années de référence 2010 à 2016. Elle décrit les aspects techniques de la méthodologie et comprend un rapport sur la qualité des répartitions estimées. Ces estimations seront détaillées et précisées davantage avant leur publication officielle par Statistique Canada dans le cadre d’un programme statistique permanent. Les versions subséquentes élargiront la suite des estimations de répartition en y ajoutant des indicateurs macroéconomiques du revenu, de la consommation et de l’épargne des ménages.
3 Cadre international
Afin de produire des renseignements sur la répartition qui correspondent aux concepts du Système de comptabilité nationale (SCN), Statistique Canada suit les étapes de base recommandées par le groupe d’experts sur les disparités à l’intérieur des comptes nationaux (GE DCN) de l’Organisation de coopération et de développement économiques (OCDE). Le processus suivi par Statistique Canada pour mettre en œuvre chacune des étapes sera décrit en détail dans les sections suivantes. La troisième étape ne fut pas requise pour la production des TARM. Par contre, des changements d’échelle et d’autres ajustements ont été effectués sur les résultats macros après l’étape 4 et sont décrits aux sections 7.2, 8.2 et 8.4.

Description du Figure 1
Une approche étape par étape aux fins d’estimation des renseignements sur la répartition
Étape 1. Ajuster les totaux des comptes nationaux.
Étape 2. Déterminer les variables pertinentes à partir des sources de microdonnées reliées aux variables des comptes nationaux.
Étape 3. Procéder à une imputation pour les éléments manquants et mettre à l'échelle les microdonnées selon les totaux ajustés des comptes nationaux.
Étape 4. Regrouper les ménages.
Étape 5. Dériver les indicateurs pertinents pour les groupes-ménages.
4 Rajuster les totaux des comptes nationaux
4.1 Comptes du bilan national
Les comptes du bilan national (CBN) sont des états des actifs non financiers qui sont détenus ou utilisés dans l’économie et des créances en cours dans les unités économiques de l’économie. Ils comprennent le bilan national du pays dans son ensemble ainsi que les bilans des secteurs sous-jacents. On trouve, au cœur des CBN, les actifs et les passifs ainsi que les concepts de patrimoine et de valeur nette.
Les TARM mettent précisément l’accent sur le secteur des ménages du bilan national, ce qui comprend les actifs, les passifs et la valeur nette (y compris certaines sous-catégories) de tous les ménages au Canada.
4.2 Rajustements
L’OCDE recommande d’isoler le secteur des ménages aux fins d’analyse de la répartition, un processus qui pourrait exiger une correction du total du secteur des comptes nationaux s’il a été agrégé à celui du secteur des institutions sans but lucratif au service des ménages (ISBLSM).
Avant la révision exhaustive publiée en 2012, le Système de comptabilité nationale (SCN) du Canada comptait trois principaux secteurs institutionnels résidents : le secteur des particuliers et des entreprises individuelles, le secteur des entreprises et le secteur des administrations publiques. Le secteur des particuliers et des entreprises individuelles comprenait les institutions sans but lucratif au service des ménages (ISBLSM), les coopératives de crédit, les sociétés d’assurance-vie, les amicales et les régimes de placement collectifs tels que les caisses de retraite et les fonds communs de placement. En raison des limites des données, ce secteur englobait également les activités des administrations publiques autochtones.
À la suite de la révision exhaustive de 2012, le SCN du Canada a adopté la division fondamentale du SCN en secteurs institutionnels dans toute la séquence des comptes intégrés. L’ancien secteur des particuliers et des entreprises individuelles a ainsi été réparti entre les ménages et les institutions sans but lucratif au service des ménages.
Étant donné que le travail a déjà été fait pour isoler le secteur des ménages, il n’est pas nécessaire d’apporter des corrections aux données actuelles des CBN.
5 Déterminer les sources et les variables de microdonnées
5.1 Enquête sur la sécurité financière
La source de microdonnées choisie pour la répartition de la valeur nette est l’Enquête sur la sécurité financière (ESF). L’objet de cette enquête est de recueillir des renseignements sur les avoirs, les dettes, l’emploi, le revenu et la scolarisation d’un échantillon de familles canadiennes, ce qui aide à comprendre la façon dont les finances des familles évoluent à la suite des pressions économiques. L’ESF dresse un portrait complet de la valeur nette des Canadiens. Des renseignements sont recueillis sur la valeur de l’ensemble des principaux avoirs financiers et non financiers et sur les sommes dues à l’égard des prêts hypothécaires, des véhicules, des cartes de crédit, des prêts étudiants et d’autres dettes. La valeur nette d’une famille est définie comme la valeur des actifs de la famille moins sa dette. Elle peut être considérée comme la somme d’argent que cette famille aurait si elle vendait tous ses actifs et payait la totalité de ses dettes.
L’ESF est une enquête transversale par sondage. Elle a été menée de façon occasionnelle, soit en 1999, en 2005 et en 2012, et sera entreprise tous les trois ans à compter de 2016. Elle porte sur la population vivant dans les 10 provinces du Canada. Certains groupes des provinces, qui représentent 2 % de la population (par exemple, les personnes vivant dans une réserve ou d’autres peuplements autochtones et les personnes souffrant de maladies chroniques et vivant dans les hôpitaux ou un établissement de soins infirmiers), sont exclus de l’enquête.
Au fil du temps, la taille de l’échantillon et le plan d’échantillonnage de l’ESF ont varié. La taille de l’échantillon était d’environ 23 000 logements en 1999, 9 000 logements en 2005 et 20 000 logements en 2012. En 1999 et en 2012, les estimations provinciales ont été ciblées, mais, étant donné la taille très réduite de l’échantillon en 2005 pour des raisons budgétaires, cette itération de l’enquête a plutôt visé la production d’estimations fiables à l’échelle régionale.
Les données sont généralement recueillies directement auprès des répondants, tandis que dans certains cas, des renseignements supplémentaires sont tirés des fichiers administratifs et sont dérivés de diverses enquêtes de Statistique Canada et d’autres sources par appariement des fichiers. On utilise, par exemple, les dossiers de données sur l’impôt des particuliers et les renseignements réglementaires sur les modalités des régimes de pension d’employeur. Les interviews sont menées en utilisant la méthode d’interviews sur place assistées par ordinateur (IPAO); les interviews durent en moyenne environ 45 minutes.
L’enquête n’est pas obligatoire et le taux de réponse en 2012 était de 68,6 %.
Des renseignements supplémentaires sont disponibles sous Définitions, sources de données et méthodes de l’ESF (numéro d’enquête 2620) et au tableau CANSIM 205-0002.
5.2 Mise en correspondance et concordance
Les comptes du bilan national (CBN) sont composés de 102 catégories et sous-catégories qui contiennent tous les types d’actifs, de passifs et de valeur nette de l’économie. Les données provisoires des tableaux annuels de répartition des ménages (TARM) contiendront quant à elles 11 de ces catégories. Le processus visant à condenser l’ensemble des CBN a été mis en place pour de multiples raisons. Notamment, certains types d’actifs et de passifs ne s’appliquent pas au secteur des ménages et l’on doit assurer la qualité des données des répartitions, ce qui sera abordé plus en détail dans les sections subséquentes du présent document.
Selon la Commission économique des Nations Unies pour l’Europe (CEE-ONU), « [...] conceptuellement, les macrostatistiques et les microstatistiques sur le revenu du ménage ont beaucoup en commun. Toutefois, il existe des différences importantes dans les objectifs et les buts des deux ensembles de données, dans leur couverture et les sources de données utilisées pour les compiler, et en raison d’enjeux pratiques concernant les rapports de données ou les estimations pour les ménages individuels » (CEE-ONU 2011). Le processus de concordance permet de déceler des zones de différence conceptuelle entre les microdonnées et les macrodonnées et fournit un indicateur de la pertinence de variables de microdonnées précises en tant que distributeurs de composantes macros.
Les catégories des CBN choisies pour les TARM sont présentées au tableau 1 ci-dessous. Les ratios de couverture sont présentés pour la dernière année où l’ESF a été menée, soit 2012. Ces catégories sont assez détaillées pour analyser le bien-être financier des ménages et sont agrégées à un degré suffisamment élevé pour modéliser les répartitions pour les années pour lesquelles il n’y a pas de microdonnées supplémentaires dans les comptes nationaux (les années où l’enquête n’a pas été menée). Il s’agit des catégories pour lesquelles une variable appropriée (ou une combinaison de variables) de l’Enquête sur la sécurité financière a été choisie. La mise en correspondance se trouve au tableau 1 a été conçu en effectuant la correspondance entre les variables de l’ESF et la version condensée des CBN. Les renseignements sur les variables provenant de chaque source utilisées pour créer ce tableau se trouvent au tableau 2 ci-dessous. Les sections 5.2.1 à 5.2.2 comportent des précisions sur la mise en correspondance présentée dans le tableau 2.
5.2.1 Différences conceptuelles — objets de valeur et de collection
Les objets de valeur et de collection ne sont pas une catégorie observée dans les CBN et ne font actuellement pas partie du domaine des actifs des comptes macroéconomiques. Par conséquent, afin de faire correspondre la microsource à la macrosource, la valeur des objets de valeur et de collection a été retirée du total de l’ESF pour la valeur nette et les actifs non financiers.
5.2.2 Différences conceptuelles — autres passifs
La catégorie qui présente le ratio de couverture le plus faible est « autres éléments de passif ». La principale raison de la sous-représentation de cette catégorie est attribuable à la définition conceptuelle de « dette de carte de crédit », qui correspond à cette catégorie. L’ESF demande aux répondants d’indiquer le montant de la dette de la carte de crédit qui est reporté à une autre période, tandis que les CBN indiquent le total du solde en souffrance à un moment précis. La différence vient du fait que de nombreux ménages utilisent des cartes de crédit aux fins de consommation, mais remboursent leur solde dû à la fin de chaque période.
5.3 Fichier sur la famille T1
Puisque les données de l’ESF ne sont pas disponibles chaque année, la méthodologie adoptée pour produire les tableaux provisoires sur le patrimoine comprend une composante de modélisation. L’information auxiliaire utilisée pour ces modèles est les estimations annuelles du revenu des familles de recensement et des particuliers, communément appelées fichier sur la famille T1 (FFT1), un fichier de données administratives annuel créé par Statistique Canada essentiellement à partir des déclarations de revenus soumises à l’Agence du revenu du Canada (ARC). Ces microdonnées portent sur toutes les personnes ayant rempli une déclaration de revenus T1 pour l’année de référence ou ayant reçu la prestation fiscale canadienne pour enfants (PFCE) ainsi que sur leurs conjoints et enfants. Des renseignements supplémentaires sur les Estimations annuelles du revenu des familles de recensement et des particuliers (Fichier des familles T1) (numéro d’enquête 4105) sont disponibles sous Définitions, sources de données et méthodes.
6 Regrouper les ménages en grappes
6.1 Unité d’analyse : le ménage
L’unité d’analyse choisie pour les tableaux annuels de répartition des ménages (TARM) est le ménage, défini par l’OCDE comme « une personne ou un groupe de personnes qui occupent le même logement et qui décident de pourvoir en commun à leurs besoins alimentaires et éventuellement aux autres besoins essentiels de l’existence » (OCDE 2013). Les données de l’ESF sont disponibles au niveau de l’unité familiale qui comprend les familles économiques, définie comme « un groupe de deux personnes ou plus qui vivent dans le même logement et qui sont apparentées par le sang, par alliance, par union libre, par adoption ou par une relation de famille d’accueil » (Statistique Canada 2014) et les personnes seules. Pour le projet des TARM, les unités familiales ont été agrégées au niveau du ménage en combinant les familles économiques qui résident à la même adresse, ce qui crée une définition de l’unité qui comprend des groupes de personnes qui partagent des ressources, mais qui ne sont pas nécessairement apparentées par le sang, par alliance, par union libre, par adoption ou par une relation de famille d’accueil. Ce faisant, les données de l’ESF s’approchent le plus possible de la définition d’un ménage selon l’OCDE.
Concernant ce concept, la recommandation de l’OCDE est d’estimer les répartitions selon des valeurs de ménage rendues équivalentes. Ce processus tient compte des différences de taille des ménages et des économies d’échelle qui en résultent pour le revenu et la consommation. Les données sur le patrimoine présentées dans les estimations provisoires n’ont pas été rendues équivalentes. Ce constat fera l’objet d’un examen plus approfondi aux fins de publications ultérieures, lorsqu’un tableau intégré des répartitions du revenu, de la consommation et du patrimoine sera élaboré.
6.2 Catégories de répartition
Les tableaux annuels de répartition des ménages provisoires pour les actifs, les passifs et la valeur nette comportent quatre variables de répartition distinctes. Les ménages sont regroupés par province, par quintile de revenu disponible du ménage, par groupe d’âge et par type de ménage (plus d’une personne par rapport à une personne). À l’exception du revenu disponible du ménage, ces regroupements sont fondés sur les définitions utilisées dans l’ESF de 2012.
6.2.1 Province
La province représente celle du domicile principal du ménage. Les membres du ménage qui ont quitté temporairement leur domicile principal, par exemple pour le travail ou les études, sont inclus dans la province de leur domicile principal.
6.2.2 Groupe d’âge
Les ménages sont répartis en groupes d’âge selon l’âge du soutien économique principal. Cela est différent de la définition de l’OCDE de la personne repère pour un ménage, qui exige d’appliquer divers critères caractéristiques à chacun des membres de chaque ménage. Cette approche sera réexaminée au fur et à mesure que la méthodologie est élaborée.
Les catégories de groupes d’âge utilisées sont les suivantes : moins de 35 ans, 35 à 44 ans, 45 à 54 ans, 55 à 64 ans et 65 ans et plus.
6.2.3 Type de ménage
Le regroupement par type de ménage se fait selon une définition simplifiée de la composition du ménage comportant seulement deux catégories : les ménages composés d’une seule personne et les ménages composés de plus d’une personne. Cette version simplifiée est utilisée pour avoir des définitions similaires pour les données de l’ESF et la source de données auxiliaires utilisée afin de modéliser les répartitions pour les années où il n’y a pas eu d’enquête.
6.2.4 Quintile de revenu disponible du ménage
Le concept de revenu disponible du ménage est unique au Système de comptabilité nationale (SCN) et il n’est pas mesuré directement dans l’ESF. Pour attribuer les ménages de l’ESF aux quintiles de revenu disponible, le revenu disponible doit d’abord être estimé pour chaque ménage de l’ESF de 2012 comme suit :
- L’agrégat du revenu disponible du ménage du SCN est ventilé en composantes (par exemple, rémunération des salariés, transferts d’autres secteurs et à d’autres secteurs, etc.) pour lesquelles on trouve des variables ou des indicateurs correspondants dans l’ESF.
- Pour chacune de ces composantes, la valeur agrégée du SCN est répartie entre les ménages de l’ESF selon la valeur de la variable ou de l’indicateur correspondants de l’ESF. On tient compte des poids de sondage de l’ESF lors du calcul de chacune des parts de ménage de la composante.
- Pour chacun des ménages, les composantes réparties sont additionnées afin de calculer le revenu disponible estimatif du ménage.
Le résultat de ce calcul est une nouvelle variable de revenu pour chacun des ménages de l’ESF, qui correspond plus précisément au concept de revenu disponible du ménage du SCN que le fait la mesure disponible du revenu après impôt. Le revenu disponible du ménage est néanmoins hautement corrélé au revenu après impôt excluant les gains en capital; il comporte un coefficient de corrélation de 92,7 %. Il s’agit d’une caractéristique importante pour modéliser les répartitions des revenus disponibles les années où il n’y a pas eu d’enquête. Après que chacun des ménages de l’ESF a reçu un revenu disponible du ménage, ils sont tous regroupés dans des quintiles de revenu disponible du ménage, qui sont calculés en tenant compte à nouveau des poids de sondage de sondage de l’ESF.
7 Déterminer les indicateurs pour les années d’enquête
Les tableaux provisoires sur le patrimoine prennent tous la forme montrée au tableau 3 et affichent, dans la colonne de droite, les totaux des comptes du bilan national (CBN) (indiqués par un C), qui sont répartis dans les différentes catégories de répartition : provinces, quintiles du revenu disponible du ménage, groupes d’âge et types de ménages. Les colonnes de la répartition (indiquées par un A et un B) sont remplies en fonction des microdonnées.
L’Enquête sur la sécurité financière (ESF) constitue la principale source de renseignements sur la répartition du patrimoine pour les tableaux annuels de répartition des ménages (TARM). Toutefois, l’ESF, qui était une enquête occasionnelle dans le passé, sera menée tous les trois ans à compter de 2016. En conséquence, des lacunes doivent être comblées afin de produire une série de tableaux annuels. La méthodologie proposée pour dériver ces tableaux est double, c’est-à-dire qu’on utilise une approche plus simple et plus directe les années où une enquête est menée et une approche plus complexe et fondée sur un modèle les années où il n’y a pas d’enquête. (L’approche de modélisation pour les cellules indiquées par un A et un B diffère et sera décrite à la section 8.) Tout au long de la présente section et de la section suivante, des tableaux seront présentés pour montrer dans quelle mesure chaque étape du processus modifie les estimations.
La présente section décrit la méthodologie utilisée pour remplir les tableaux pour les années où une enquête a été menée. La méthodologie comporte deux étapes : l’obtention des estimations de la répartition de l’ESF, qui sont mises à l’échelle des totaux des CBN, et la réconciliation pour produire des tableaux dans lesquels les totaux des lignes et des colonnes seront cohérents. Pour cette série de tableaux provisoires, cette méthodologie est utilisée uniquement pour 2012. À l’avenir, elle serait utilisée pour chaque année où une enquête a été menée.
7.1 Estimations des répartitions
Pour chacun des quatre tableaux, la valeur totale de la valeur nette et de chaque sous-catégorie d’actifs et de passifs pour chaque catégorie de répartition est estimée directement à partir de l’ESF. Pour ces estimations, des mesures de l’erreur d’échantillonnage sous forme de coefficients de variation (c.v.) se trouvent aux tableaux 10 à 13 de l’annexe. Les c.v. varient de 1,8 % à 12,4 % pour la valeur nette totale, de 1,7 % à 10,9 % pour les actifs totaux et de 2,3 % à 15,6 % pour les passifs totaux.
Les totaux de l’enquête sont mis à l’échelle des totaux des CBN. Le facteur par lequel chaque cellule doit être multipliée varie par ligne et est la réciproque des ratios de couverture indiqués dans le tableau 1 ci-dessus. Le facteur est le même pour l’ensemble des quatre tableaux provisoires.
Le tableau 4 est le premier d’une série de tableaux montrant dans quelle mesure les cellules des tableaux sont modifiées par chacune des étapes de la méthodologie. Dans le cas présent, les facteurs pour mettre à l’échelle sont proches de 1, ce qui indique que les modifications ne sont pas importantes pour la plupart des catégories. Les différences conceptuelles entre les totaux des CBN et l’ESF signifient qu’un facteur plus important est nécessaire pour la ligne « autres éléments de passif », comme on l’a expliqué à la section 5.2.2.
7.2 Réconciliation
Après avoir calculé les estimations de l’enquête mises à l’échelle des totaux des CBN, les sommes des lignes et des colonnes des tableaux qui en découlent ne sont pas cohérentes. La somme des catégories de répartition va égaler les totaux des CBN; en d’autres mots, les sommes le long des lignes seront cohérentes. Cependant, les relations entre les actifs, les passifs et la valeur nette ne seront plus respectées. Ceci est dû aux différents facteurs multiplicatifs qui sont utilisés pour chaque ligne. Un processus de rajustement est nécessaire pour assurer la cohérence dans les tableaux qui en découlent. Ce processus fait en sorte de rétablir les relations entre les actifs, les passifs, la valeur nette, etc. à l’intérieur de chacune des catégories de répartition (les relations le long des colonnes) et de veiller à ce que les sommes de la répartition soient équivalentes au total des CNB (relations le long des lignes) tout en ne touchant pas à la ligne des totaux des CBN et de la valeur nette ou du patrimoine. Ce type de rajustement est désigné par plusieurs termes : réconciliation, équilibrage et étalonnage multivarié. Une caractéristique principale de la réconciliation est qu’elle fait en sorte que les relations précisées soient respectées, tout en minimisant les changements aux cellules individuelles du tableau.
La variante de réconciliation employée pour produire les tableaux provisoires utilise des coefficients d’altérabilité pour permettre à certaines quantités de se déplacer plus que d’autres. En général, il peut être souhaitable de permettre aux estimations réputées être de qualité inférieure de bouger plus. Dans ce cas, les valeurs des lignes dont les ratios de couverture sont plus éloignés de 100 % sont autorisées à varier davantage que celles des lignes ayant un ratio de couverture près de 100 %. Les méthodes de réconciliation utilisées sont dérivées d’une approche basées sur les régressions de Dagum et Cholette (2006) et décrites subséquemment par Quenneville et Fortier (2012). Les procédures sont implémentées par l’entremise de PROC TSRAKING, décrites par Bérubé et Fortier (2009), dans le cadre la série des logiciels G-SERIES de Statistique Canada et peuvent être obtenues en contactant statcan.g-series-g-series.statcan@canada.ca.
Les tableaux 19 à 22 de l’annexe montrent dans quelle mesure la réconciliation modifie les cellules internes des tableaux sur le patrimoine de 2012. Comme pour les ratios d’ajustement pour la mise à l’échelle plus haut, les ratios dans ces tableaux sont généralement proches de 1, ce qui indique que la réconciliation des tableaux n’entraîne pas de changements majeurs dans les répartitions. L’une des raisons pour limiter ces tableaux provisoires à 11 catégories et sous-catégories du patrimoine est de veiller à ce que la réconciliation ne modifie pas trop les cellules.
8 Déterminer les indicateurs pour les années où il n’y a pas d’enquête
Puisque l’Enquête sur la sécurité financière (ESF) n’est pas menée tous les ans, une méthodologie différente est requise afin de dériver les mesures du patrimoine pour les tableaux annuels de répartition des ménages (TARM) les années où aucun renseignement d’enquête n’est disponible. Sans mesure directe de la valeur nette et de ses composantes, les années où il n’y a pas eu d’enquête doivent être modélisées selon l’information auxiliaire. Comme pour les années où une enquête a été menée, chaque tableau est représenté comme au tableau 3, mais, pour les années où il n’y a pas d’enquête, les colonnes de la répartition sont dérivées à partir de modèles. Une approche de modélisation différente est utilisée pour la répartition de la valeur nette (indiquée par un B) et la répartition des catégories et des sous-catégories d’actifs et de passifs (indiquée par un A).
La majeure partie de la présente section (8.1 à 8.4) portera sur la méthodologie élaborée pour estimer les répartitions de la valeur nette pour les années où il n’y a pas d’enquête. Plus particulièrement, elle donne une description des approches de modélisation envisagées pour la valeur nette, de plus amples renseignements sur la méthodologie choisie en fonction des modèles au niveau du domaine, une description de l’étalonnage utilisé pour assurer la cohérence avec les années où une enquête a été menée et l’approche de modélisation de rechange nécessaire pour 2015 et 2016. Par la suite, à la section 8.4, on décrit l’approche pour l’intérieur du tableau. Dans cette section, une approche de modélisation plus simple est utilisée et, comme pour les années où une enquête a été menée, la cohérence des tableaux est assurée par la réconciliation. Finalement, la section 8.5 décrit des approches alternatives pour la modélisation de la valeur nette qui ont été évaluées lors du développement de la méthodologie des TARM et inclut des comparaisons par rapport aux modèles au niveau du domaine. Tout au long de la section, des tableaux sont présentés pour montrer dans quelle mesure chaque étape du processus modifie les estimations.
8.1 Modèles au niveau du domaine
Cette approche pour estimer la valeur nette est basée sur des modèles qui prédisent la valeur nette de groupes ou de « domaines » de ménages. Elle est motivée par les modèles au niveau du domaine qui sont une technique de base de l’estimation pour petits domaines (Rao et Molina 2015). Les unités à partir de lesquelles ce type de modèle est construit sont des domaines d’intérêt, souvent de nature géographique.
Cette méthode fut évaluée comparativement à deux alternatives, une approche au niveau macro et une approche au niveau de l’unité. Ces trois méthodes furent évaluées et comparées ; identifiant le modèle au niveau du domaine comme étant l’approche la plus appropriée basée sur son habileté à prédire les répartitions de la valeur nette. Une description des méthodes alternatives et un sommaire des comparaisons sont présentés à la section 8.5.
8.1.1 Répercussions des sources de données et de leur disponibilité
Comme il a été mentionné ci-dessus, l’ESF a seulement été menée trois fois dans le passé, soit en 1999, en 2005 et en 2012. Conséquemment, la série de données que l’on peut utiliser pour établir les tableaux pour la période de 2010 à 2016 est très courte. En outre, deux des années disponibles de l’ESF, soit 1999 et 2005, ne peuvent pas être considérées comme pertinentes sur le plan temporel, particulièrement en raison de la crise financière de 2008 qui a eu lieu dans l’intervalle, et puisque l’ESF de 2005 a un échantillon beaucoup plus petit et a été conçue pour produire des estimations régionales plutôt que provinciales.
Heureusement, le patrimoine est lié au revenu, et l’on dispose de beaucoup plus de données sur le revenu. Le fichier sur la famille T1 (FFT1) est un choix évident de microdonnées auxiliaires puisqu’il est disponible chaque année et qu’il regroupe les personnes en une famille. Toutefois, le FFT1 est accessible environ un an et demi après la fin de l’année de référence. Ainsi, le FFT1 de 2014 est la dernière version existante pour cette production de tableaux provisoires portant sur les années de référence allant de 2010 à 2016. En conséquence, une méthodologie différente sera utilisée pour 2015 et 2016, par rapport à 2010 à 2014.
8.1.2 Approche de modélisation
On peut utiliser les modèles au niveau du domaine pour estimer les répartitions de la valeur nette pour les années où il n’y a pas eu d’enquête comme suit :
- Le pays est divisé en domaines pour lesquels la variable d’intérêt, la valeur nette totale, est agrégée à partir des données de l’ESF de 2012. Les domaines sont définis en croisant les régions géographiques avec les catégories de répartition d’intérêt.
- Un modèle est créé pour ces domaines afin de prédire la valeur nette totale selon l’information auxiliaire disponible pour ces domaines. Les variables utilisées comme variables explicatives sont les variables du FFT1 agrégées selon les domaines. Cet exercice est effectué au moyen de l’année de référence 2012, tant pour l’ESF que pour le FFT1.
- Ce modèle est ensuite appliqué à toutes les années où des données auxiliaires sont disponibles (de 2010 à 2014), donnant ainsi une valeur nette totale estimée pour chaque domaine tant pour les années où il y a eu enquête que pour celles où il n’y en a pas eu.
- Finalement, on obtient les répartitions modélisées pour les tableaux sur le patrimoine en additionnant la valeur nette totale estimée pour les domaines pertinents.
L’expérience acquise des estimations sur les petits domaines laisse supposer qu’une approche au niveau du domaine peut être appropriée lorsque la couverture de la source de données auxiliaires n’est pas exhaustive ou lorsqu’il existe des différences conceptuelles entre les sources de données. C’est le cas pour le FFT1; la couverture de la population canadienne du FFT1 est assez bonne, mais sans être parfaite et des différences conceptuelles entre les sources de données sont présentes. Pour ce qui est des différences conceptuelles, l’ESF est agrégée au niveau du ménage pour les TARM, tandis que le FFT1 regroupe les déclarants individuels par familles. De même, les TARM utilisent le concept de revenu disponible des ménages du SCN, tandis que le FFT1 comporte des définitions du revenu total fondées sur l’impôt.
Bien que seuls les renseignements tirés du FFT1 ont été inclus dans les modèles à cette étape, les modèles au niveau du domaine peuvent également intégrer l’information auxiliaire disponible uniquement à des niveaux agrégés, ce qui constitue un autre avantage. Cette option sera évaluée à mesure que les méthodes sont perfectionnées aux fins de publication ultérieure des estimations officielles.
Le développement pour déterminer la meilleure mise en application de cette approche est en cours. La mise en œuvre utilisée pour les estimations provisoires du patrimoine est décrite ci bas. Trois modèles furent développés : un pour le revenu disponible des ménages, un pour les groupes d’âge et un pour le type de ménage. Les options choisies pour la mise en œuvre furent déterminés en comparant les répartitions obtenues de chaque modèle aux répartitions de l’ESF pour 2012, 2005 et 1999 (voir section 8.1.7).
8.1.3 Période de modélisation
Tous les modèles ont été construits à partir des données de 2012 seulement. Les ESF de 2005 et de 1999 n’ont pas été jugées suffisamment opportunes pour être utilisées pour la période allant de 2010 à 2016. Ces itérations précédentes de l’ESF ont été utilisées uniquement pour évaluer les modèles ajustés en fonction des données de 2012.
8.1.4 Définition de domaine
Les domaines sont définis en croisant 49 régions géographiques avec les catégories de répartition des tableaux du patrimoine. Les 49 régions géographiques sont déterminées en fonction des régions économiques, certaines régions économiques voisines étant combinées au besoin.
Puisque les domaines sont définis sur deux dimensions, soit la géographie et la catégorie de répartition, les modèles pourraient s’ajuster à tous les domaines dans leur ensemble ou aux 49 régions géographiques pour chacune des catégories de répartition individuellement. La deuxième option a été mise en œuvre, puisqu’elle entraînait de meilleurs résultats. Elle permet d’établir différentes relations entre les covariables de la valeur nette et du revenu dans chaque catégorie de répartition. Lorsqu’on considère les groupes d’âge, on comprend pourquoi cette option est avantageuse. Cela revient à dire que la relation entre les variables de revenu et de la valeur nette est différente selon le groupe d’âge, ce qui est raisonnable puisque la valeur nette est accumulée au courant de la vie d’une personne.
8.1.5 Covariables et fonction de lien
Toutes les covariables du modèle ont été obtenues à partir du FFT1 pour l’année de référence 2012. Le FFT1 contient diverses variables sur le revenu et liées au revenu ainsi que sur la population. De nombreuses façons d’agréger ces variables pour les domaines ont été considérées. Les variables retenues pour la modélisation de la valeur nette au sein de chaque domaine étaient : le revenu total, le total de la valeur absolue des revenus des investissements, le revenu total des personnes de 75 ans et plus. La variable du revenu total était la plus explicative et elle a été utilisée dans tous les modèles. Bien que les variables utilisées sont en fonction du revenu, les tendances démographiques sont également prises en compte par les modèles, puisque les totaux reflètent également la taille de la population.
Les modèles mis en œuvre font usage d’une fonction de lien logarithmique, le logarithme étant appliqué à la fois à la variable d’intérêt, soit la valeur nette totale, et aux covariables. Dans le modèle qui en découle, le logarithme de la valeur nette totale prévu est en quelque sorte une combinaison linéaire du logarithme du revenu total, potentiellement le logarithme des covariables supplémentaires, et d’un terme constant.
L’utilisation d’une fonction de lien logarithmique entraîne un estimateur biaisé. Aucune correction précise du biais n’est mise en place à cette étape puisque l’étalonnage est utilisé pour harmoniser les répartitions modélisées avec celles de l’ESF pour les années où une enquête a été menée.
8.1.6 Modèle pour la province
Comme il a été mentionné précédemment, trois modèles ont été créés : un pour les quintiles de revenu disponible du ménage, un pour les groupes d’âge et un autre pour la composition du ménage. Puisque les régions géographiques utilisées pour définir les domaines sur lesquels les modèles au niveau des domaines ont été créés respectent les limites géographiques provinciales, chacun de ces trois modèles peut être utilisé pour dériver la répartition par province. Chacun des trois modèles a produit des répartitions similaires par province. Pour les tableaux provisoires sur le patrimoine par province, la répartition par province modélisée a été obtenue à partir de la moyenne des trois modèles.
8.1.7 Comparaison des modèles mis en œuvre par rapport aux répartitions de l’Enquête sur la sécurité financière
Les tableaux suivants montrent comment les répartitions modélisées se comparent aux répartitions de l’ESF pour 2012, 2005 et 1999. La somme par catégorie des valeurs absolues de la différence entre les répartitions selon l’ESF et les répartitions modélisées est utilisée pour mesurer la différence entre les répartitions de l’ESF et celles obtenues par la modélisation.
Comme le montrent les tableaux 5 à 8, même en 2012, l’année pour laquelle le modèle a été construit, une différence existe entre la répartition de l’ESF et les données du modèle. Cette divergence, en partie due à l’utilisation d’un modèle logarithmique linéaire, sera résolue grâce à l’étalonnage.
8.2 Étalonnage des estimations de la valeur nette
Par étalonnage, nous entendons des techniques utilisées pour s’assurer de la cohérence entre les séries chronologiques ayant trait à une variable cible mesurée à diverses fréquences. Dans ce cas-ci, la série de répartitions annuelles produite par le modèle est ajustée pour assurer la cohérence avec l’ESF pour les années où une enquête a été menée. Cela consiste à imposer le niveau de l’étalon tout en préservant le plus possible le mouvement dans la série modélisée. Pour les tableaux provisoires, la série modélisée a seulement été étalonnée sur les répartitions de l’ESF de 2012. Lorsque la série sera élargie pour inclure d’autres années d’enquête, les données du modèle seront étalonnées sur chaque année d’enquête. Les méthodes d’étalonnage utilisées sont dérivées d’une approche basée sur les régressions de Dagum et Cholette (2006) et décrites subséquemment par Quenneville et Fortier (2012). Les procédures sont implémentées par l’entremise de PROC BENCHMARKING, décrites par Latendresse, Djona et Fortier (2007), dans le cadre la série des logiciels G-SERIES de Statistique Canada et peuvent être obtenues en contactant statcan.g-series-g-series.statcan@canada.ca.
Dans certaines situations, l’étalonnage peut améliorer l’exactitude du produit statistique. En ce cas, l’étalonnage est utilisé comme moyen de compenser le biais résultant de l’utilisation d’un modèle logarithmique.
Les tableaux 15 à 18 de l’annexe montrent l’ampleur des ajustements d’étalonnage apportés aux répartitions de la valeur nette. Ces ajustements sont appliqués chaque année de 2010 à 2014.
8.3 Estimations de la valeur nette pour 2015 et 2016
La méthodologie de modélisation de la valeur nette décrite aux sections 8.1 et 8.2 peut être appliquée uniquement aux années pour lesquelles le FFT1 est disponible : 2010 à 2014. Pour les années 2015 et 2016, la répartition de l’année 2014 est reprise afin d’obtenir les estimations de la valeur nette. Ainsi, les tableaux provisoires sur le patrimoine montrent la même répartition de la valeur nette en 2014, 2015 et en 2016.
8.4 Inclusion des catégories d’actifs et de passifs pour les années où il n’y a pas eu d’enquête et réconciliation
En plus de la valeur nette, certaines catégories d’actifs et de passifs doivent aussi être modélisées pour les années où il n’y a pas eu d’enquête. Après avoir été modélisées, les répartitions sont mises à l’échelle des totaux des CBN et les tableaux qui en résultent sont réconciliés afin d’assurer la cohérence au sein de chacun des tableaux, comme c’est le cas pour les années où une enquête a été menée. La réconciliation aux marges des tableaux permet de transférer certaines des tendances de répartition détectées par le modèle de la valeur nette à l’intérieur des tableaux. Pour cette raison, un simple modèle pour les catégories d’actifs et de passifs a été jugé acceptable. Les tableaux provisoires sur le patrimoine ont été conçus en reportant tout simplement la répartition de 2012 des actifs, des passifs et de leurs sous-catégories. D’autres options au report seront envisagées, à mesure que les tableaux sur le patrimoine seront perfectionnés et que d’autres sources de données auxiliaires seront repérées.
Ces totaux modélisés pour les catégories d’actif et de passifs ainsi que pour la valeur nette doivent être mis à l’échelle des totaux des CBN, de la même façon que pour les années où une enquête a été menée. Les facteurs, représentés au tableau 14 de l’annexe, selon lequel chaque cellule doit être multipliée, varie par ligne. Pour 2012, il est la réciproque des ratios de couverture. Pour d’autres années, il représente un facteur global d’ajustement à la fois pour le ratio de couverture et pour la croissance. Le facteur est le même pour l’ensemble des quatre tableaux provisoires.
Après avoir mis à l’échelle les estimations de l’enquête aux totaux des CBN, les sommes des lignes et des colonnes des tableaux qui en découlent ne sont pas cohérentes. Le même processus de réconciliation est utilisé pour assurer la cohérence dans les tableaux qui en résultent pour les années où il n’y a pas eu d’enquête et les années où il y en a eu une. Les tableaux 19 à 22 de l’annexe montrent l’ampleur des modifications apportées aux cellules internes des tableaux sur le patrimoine de 2010 à 2016 qui sont introduites par la réconciliation. Les ratios dans ces tableaux sont généralement proches de 1, ce qui indique que la réconciliation des tableaux n’entraîne pas de changements majeurs dans les répartitions comparativement aux changements introduits par l’étalonnage.
8.5 Approche alternative pour la modélisation de la valeur nette
Afin de développer la méthodologie reliée aux tableaux du patrimoine pour la période de 2010 à 2016, deux autres approches furent évaluées, en plus du modèle au niveau du domaine, pour modéliser la valeur nette : modèles au macroniveau et modèles au microniveau. Le modèle au niveau du domaine peut être considéré comme un modèle au niveau intermédiaire. Il y a d’importantes différences dans ces approches, particulièrement en terme de comment ils incorporent des sources de données auxiliaires. Ces deux approches alternatives sont décrites ci-dessous, et une comparaison avec le modèle au niveau du domaine s’en suit.
8.5.1 Approche au macroniveau : interpolation et extrapolation
L’approche de macroniveau pour la modélisation de la valeur nette consiste à estimer les répartitions de la valeur nette directement à partir des répartitions de l’ESF offertes pour les années où une enquête a été menée. Comme on dispose seulement de trois années d’ESF sur une période de 13 ans, les options de modélisation au macroniveau étaient limitées. Deux types d’interpolation et d’extrapolation ont été envisagés : interpolation linéaire et par des splines cubiques naturelles.
Comme il fallait s’y attendre, compte tenu des limites des données de l’ESF, des longs intervalles entre les années d’enquête et de la plus petite taille de l’échantillon en 2005, les résultats ont été jugés insatisfaisants. L’interpolation a donné lieu à des tendances annuelles irréalistes. Elle ne pouvait pas capter des événements tels que la récession de 2008. Par ailleurs, l’année 2005 constituait toujours un tournant, des tendances différentes étant observées avant et après. Ce tournant de 2005 n’est pas le reflet d’une tendance macroéconomique, mais simplement un artefact du faible nombre de points de données de l’ESF. En outre, puisque l’ESF de 2005 était seulement destinée à produire des estimations régionales, les estimations provinciales n’étaient pas stables comparativement aux autres années de l’ESF en raison de la grande variabilité due à l’échantillonnage.
Il a donc été décidé d’utiliser une option de modélisation différente pour la valeur nette qui comprendrait les données provenant de sources autres que l’ESF. Les limites mises en évidence par les résultats d’interpolation sont à retenir et elles influencent le choix de la mise en œuvre de l’étalonnage, décrite ci-desous. Enfin, même si elle a été jugée inadéquate pour la valeur nette, une approche au macroniveau réapparait dans le cadre de la méthodologie sous forme de reports pour d’autres lignes du tableau et pour 2015 et 2016, lorsqu’il n’existe aucune donnée du FFT1.
8.5.2 Approche de microniveau : modèles au niveau de l’unité
L’approche de microniveau est fondée sur des modèles qui permettent de prédire la valeur nette de chaque ménage, d’où le nom « au niveau de l’unité ». Ces modèles reposent principalement sur les données démographiques et les renseignements sur le revenu des membres du ménage.
On peut utiliser les modèles au niveau de l’unité pour estimer les répartitions de la valeur nette pour les années où il n’y a pas eu d’enquête comme suit :
- Un modèle est créé pour les données de l’ESF de 2012 afin de prédire la valeur nette des ménages de l’ESF selon les données démographiques et les renseignements sur le revenu de ces mêmes ménages. Les variables utilisées comme variables explicatives dans le modèle sont choisies parmi les variables qui figurent également dans le FFT1.
- Ce modèle est ensuite appliqué aux familles des fichiers FFT1 pour chaque année, donnant à chaque famille du FFT1 une valeur nette estimée.
- Enfin, les estimations de la répartition sont obtenues en additionnant la valeur nette estimée sur les fichiers FFT1 selon les caractéristiques des familles du FFT1.
Le modèle au niveau de l’unité utilisé pour évaluer cette approche est celui développé pour les stratifications de l’ESF de 2016 et utilisé afin d’assurer un suréchantillonnage des ménages à haut et faible valeur nette (Laferrière et Boulet, 2015). Il s’agit d’un modèle linéaire qui utilise les variables suivantes comme covariables : revenu total des membres du ménage au sein des groupes d’âge 35 à 44 ans, 45 à 54 ans, 55 à 64 ans, 65 à 74 ans et 75 ans et plus (cinq variables); valeur absolue des revenus des investissements; facteur d’équivalence pour les cotisations autorisées à un REER; revenu moyen du ménage de tous les ménages pour un code postal donné. La variable de revenu par groupe d’âge reflète le fait que la relation entre le patrimoine et le revenu varie par groupe d’âge puisque le patrimoine est accumulé au fil du temps. Le revenu moyen pour un code postal ajoute une composante hiérarchique au modèle et capte l’idée que les voisins ont une valeur nette similaire. Ces modèles ont été ajustés en fonction des données de l’ESF de 2012 seulement.
Le rendement de ce modèle au niveau agrégé est présenté à la section 8.5.3 où il est comparé aux résultats obtenus à partir de modèles au niveau du domaine. Bien que les tendances annuelles et les estimations d’ensemble pour le modèle au niveau de l’unité ne semblent pas aussi irréalistes que les résultats obtenus par interpolation, certains défis se posent tout de même pour la modélisation au niveau de l’unité, particulièrement en ce qui concerne les valeurs aberrantes. Tant la valeur nette que le revenu sont des variables hautement asymétriques. En effet, un nombre relativement faible de ménages à valeur nette très élevée détient une part importante du patrimoine global. Ces valeurs aberrantes sont donc très importantes pour le calcul de la valeur nette totale. Par ailleurs, il y a des raisons de croire que la relation entre la valeur nette et le revenu est différente pour ces valeurs aberrantes situées à l’extrémité du spectre des valeurs nettes très élevées par rapport à la majeure partie de la population. En ce qui concerne la modélisation, il est possible qu’un modèle qui est valable pour la plupart des ménages ne s’applique pas aux ménages ayant une valeur nette très élevée, ce qui fait en sorte qu’il est beaucoup plus difficile de prédire leur valeur nette. Cela est particulièrement problématique en raison de l’influence de ces ménages sur la valeur nette totale.
8.5.3 Évaluation et comparaison des approches de modélisation
Afin de déterminer l’approche de modélisation à adopter, des modèles au niveau du domaine et au niveau de l’unité ont été conçus et comparés. Ces comparaisons ont été effectuées sur les premières versions des modèles. En particulier, elles ont été faites en utilisant les quintiles de revenu après impôt, puisque la détermination des indicateurs correspondants appropriés pour dériver le revenu disponible était toujours en cours à ce moment. Les modèles ont été conçus en utilisant seulement les données de 2012 puis comparés à d’autres années pour évaluer leur rendement au fil du temps.
Les approches au niveau de l’unité et du domaine ont été évaluées selon deux éléments : leur capacité à déceler les tendances macroéconomiques du niveau et leur capacité à prédire la répartition de la valeur nette. De ces deux éléments, le deuxième est beaucoup plus important puisque les estimations de la répartition produites par le modèle sont mises à l’échelle des totaux des CBN.
Afin d’évaluer la capacité des modèles à déceler les tendances macroéconomiques du niveau global de la valeur nette, les données des modèles pour la valeur nette globale totale ont été comparées aux totaux de l’ESF de 1999, de 2005 et de 2012 et aux totaux annuels des CBN de 1999 à 2014. Le graphique 1 résume les résultats sous forme graphique.
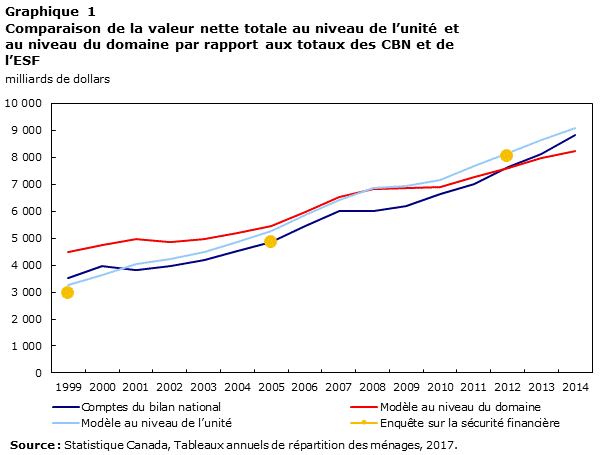
Tableau de données du Graphique 1
| Année | Modèle au niveau du domaine | Comptes du bilan national | Modèle au niveau de l’unité | Enquête sur la sécurité financière |
|---|---|---|---|---|
| milliards de dollars | ||||
| 1999 | 4 485,79 | 3 512,57 | 3 269,05 | 2 947,51 |
| 2000 | 4 738,88 | 3 982,76 | 3 641,16 | Note ...: n'ayant pas lieu de figurer |
| 2001 | 4 950,01 | 3 826,66 | 4 057,02 | Note ...: n'ayant pas lieu de figurer |
| 2002 | 4 844,71 | 3 959,89 | 4 240,02 | Note ...: n'ayant pas lieu de figurer |
| 2003 | 4 975,47 | 4 188,09 | 4 473,15 | Note ...: n'ayant pas lieu de figurer |
| 2004 | 5 193,66 | 4 505,38 | 4 854,62 | Note ...: n'ayant pas lieu de figurer |
| 2005 | 5 462,90 | 4 855,74 | 5 274,48 | 4 817,81 |
| 2006 | 5 957,69 | 5 447,26 | 5 863,78 | Note ...: n'ayant pas lieu de figurer |
| 2007 | 6 505,65 | 6 007,35 | 6 413,86 | Note ...: n'ayant pas lieu de figurer |
| 2008 | 6 830,25 | 5 989,96 | 6 849,38 | Note ...: n'ayant pas lieu de figurer |
| 2009 | 6 869,24 | 6 183,21 | 6 914,02 | Note ...: n'ayant pas lieu de figurer |
| 2010 | 6 887,99 | 6 631,09 | 7 169,11 | Note ...: n'ayant pas lieu de figurer |
| 2011 | 7 255,23 | 7 015,36 | 7 683,84 | Note ...: n'ayant pas lieu de figurer |
| 2012 | 7 587,84 | 7 638,80 | 8 165,61 | 8 030,46 |
| 2013 | 7 964,39 | 8 134,37 | 8 637,96 | Note ...: n'ayant pas lieu de figurer |
| 2014 | 8 215,62 | 8 821,23 | 9 065,66 | Note ...: n'ayant pas lieu de figurer |
|
... n'ayant pas lieu de figurer Source : Statistique Canada, Tableaux annuels de répartition des ménages, 2017. |
||||
Dans l’ensemble, le niveau global de la valeur nette totale prédit par le modèle au niveau de l’unité se rapproche davantage des totaux des CBN que celui du modèle au niveau du domaine. Les deux modèles reflètent certaines tendances macroéconomiques qui sont impossibles à capter par interpolation. Notamment, les récessions de 2000 et de 2008 sont détectées par les modèles, mais une année trop tard. Des méthodes permettant de corriger ce retard seront envisagées au fur et à mesure que la méthodologie est élaborée.
Pour évaluer la capacité du modèle à prédire les répartitions de la valeur nette au fil des années, le modèle, conçu à partir des données de 2012 seulement, a été appliqué aux données de 1999 et de 2005, et les résultats ont été comparés aux répartitions obtenues directement à partir de l’ESF pour ces années. Cette comparaison est présentée au tableau 9, et est similaire à ceux des tableaux 5 à 8. En ce qui concerne les modèles, le rendement du modèle au niveau du domaine est bien meilleur à cet égard que celui au niveau de l’unité.
Le tableau 9 montre également que, même en 2012, l’année pour laquelle le modèle a été conçu, une différence existe entre la répartition de l’ESF et les données du modèle. Comme il a été mentionné ci-dessus, cette divergence sera résolue grâce à l’étalonnage.
9 Sources d’erreurs
Les tableaux annuels de répartition des ménages (TARM) sont conçus en rassemblant des données provenant de sources multiples. Chacune de ces sources, ainsi que la façon dont elles sont utilisées et combinées, constitue une source potentielle d’écarts entre les microdonnées et les macrodonnées. Un aperçu des sources d’erreurs pour les TARM sur le patrimoine est présenté ci-dessous, en fonction de la source :
- Totaux des comptes nationaux
- Données d’enquête
- Modèle
Une classification similaire se trouve dans Zwijnenburg (2016).
9.1 Qualité des données des comptes nationaux
9.1.1 Qualité des totaux des comptes nationaux
Les comptes du bilan national (CBN) sont estimés en utilisant les sources de données les plus complètes et de la plus haute qualité afin d’établir des estimations annuelles de référence. Cela comprend généralement des enquêtes-entreprises annuelles, des fichiers de données administratives de l’Agence du revenu du Canada, des fichiers annuels tirés d’enquêtes-ménages, des données annuelles provenant des fonds de retraite, des institutions financières et des comptes publics du gouvernement et l’établissement d’estimations annuelles. Les données sont analysées en fonction de l’uniformité des séries chronologiques, des liens avec la conjoncture économique, des problèmes liés aux données de base et, enfin, de la cohérence. Il n’est pas possible de produire un équivalent du patrimoine national ou de la valeur nette nationale, pas plus qu’il est possible d’établir un bilan pour le secteur des ménages, sauf de façon périodique à partir des enquêtes-ménages. Toutefois, certains sous-secteurs des CBN sont largement comparables aux estimations produites par les divisions qui fournissent les données de base (par exemple, fonds de retraite, administrations publiques).
Les CBN sont publiés trimestriellement, tandis que les TARM portent sur des données annuelles. Les données des CBN du troisième trimestre de chaque année de référence ont été choisies comme point de données pour représenter chaque année de référence (c.-à-d. que les données du troisième trimestre de 2012 sont utilisées comme total de 2012). Il s’agit du trimestre qui correspond à la période de collecte pour l’ESF, ce qui minimise les problèmes potentiels de qualité liés à la chronologie.
9.1.2 Qualité des rajustements apportés aux totaux des comptes nationaux
Comme il a été mentionné précédemment, les rajustements visant à isoler le secteur des ménages de celui des institutions sans but lucratif au service des ménages (ISBLSM) ont été mis en place en 2012. Les travaux pour créer le secteur des ISBLSM ont commencé avec la création d’un compte satellite plus largement défini des institutions sans but lucratif et du bénévolat, d’abord publié en 2004. La part des institutions sans but lucratif au service des ménages dans ce secteur sans but lucratif élargi a été mise en œuvre dans le Système de comptabilité nationale (SCN) en 2012, avec des estimations établies à partir de diverses sources, dont les fichiers administratifs sur les organismes de bienfaisance et les autres institutions à but non lucratif. Diverses améliorations statistiques visant à mieux définir le contexte et à tenir compte des lacunes dans les mesures ont été entreprises, en plus de changements liés à la sectorisation. Ces améliorations comprennent notamment le fait de délimiter les achats des ménages du secteur des ISBLSM. Des estimations révisées pour l’industrie et la demande finale ont été introduites en conséquence dans le cadre des ressources et des emplois.
9.2 Qualité des données de l’enquête
9.2.1 Erreur d’échantillonnage
Les erreurs d’échantillonnage sont inévitables dans toute enquête par sondage et se produisent parce que des données sont recueillies et des inférences sont faites à partir d’un échantillon plutôt que de l’ensemble de la population. L’erreur d’échantillonnage est mesurée en estimant la mesure dans laquelle les estimations de l’échantillon pourraient varier pour tous les échantillons possibles qui auraient pu être sélectionnés et qui ont le même plan d’échantillonnage et la même taille. L’amplitude de l’erreur d’échantillonnage est affectée par plusieurs facteurs : la variabilité inhérente des caractéristiques mesurées dans la population, la taille de l’échantillon, le plan d’échantillonnage et le taux de réponse. Étant donné sa petite taille, l’ESF de 2005 comporte une plus grande erreur d’échantillonnage que les ESF de 1999 et de 2012.
Le coefficient de variation (c.v.) est une mesure courante de l’erreur d’échantillonnage et peut être utilisé comme indicateur de l’exactitude des estimations. On le définit comme étant le rapport entre l’erreur-type de l’estimation de l’enquête et la valeur de l’estimation elle-même. Dans l’ESF de 2012, le c.v. de la valeur nette totale au niveau national était de 1,7 %. Les c.v. pour la valeur nette totale des provinces variaient de 3,1 à 6,1 % à l’exception de celui de l’Île-du-Prince-Édouard qui était de 12,4 %. Les c.v. pour les estimations des totaux sont présentés aux tableaux 10 à 13 de l’annexe.
9.2.2 Erreur de couverture
Les erreurs de couverture comprennent les omissions, l’inclusion d’unités erronées, les enregistrements en double et les erreurs de classification d’unités dans la base de sondage. Elles peuvent se traduire par des estimations biaisées et les répercussions peuvent varier pour différents sous-groupes de la population.
Pour les TARM, la population ciblée par l’ESF et par les totaux des CBN diffère. En particulier, les territoires sont exclus de l’ESF, comme le sont environ 2 % des personnes dans les provinces qui sont difficiles à sonder pour diverses raisons.
9.2.3 Erreur due à la non-réponse
Il existe deux types de non-réponse : la non-réponse totale, soit le fait de ne pas répondre à l’ensemble de l’enquête, et la non-réponse partielle, soit le fait de ne pas répondre à certaines questions. Dans l’ESF, ce type d’erreur est traité en utilisant des procédures de suivi visant à minimiser les non-réponses, par la pondération qui tient compte de la non-réponse et par imputation.
9.2.4 Erreur de mesure et de traitement
L’erreur de mesure, aussi appelée erreur de réponse, est la différence entre la réponse enregistrée à une question et la valeur « réelle ». L’erreur de mesure peut être causée par une incompréhension de la part du répondant ou de l’intervieweur. Le traitement est requis pour transformer les réponses d’enquête en une forme appropriée aux fins de la tabulation et de l’analyse et peut être une source d’erreur.
9.3 Qualité du modèle utilisé pour les années où il n’y a pas eu d’enquête
Dans les années où il n’y a pas eu d’ESF, les TARM sur le patrimoine dépendent fortement d’un modèle de la valeur nette. En conséquence, leur qualité dépend de la qualité des données auxiliaires à partir desquelles les modèles sont conçus et de la solidité du modèle lui-même. Les travaux d’élaboration du modèle se poursuivront pour les TARM sur le patrimoine et incluront l’évaluation de l’utilisation des autres sources de données auxiliaires.
9.3.1 Qualité des sources de données auxiliaires
La source des données auxiliaires utilisée pour les modèles de la valeur nette permettant de dériver les estimations pour les années où il n’y a pas eu d’enquête est fondée sur le fichier sur la famille T1. D’après des estimations démographiques, le FFT1 rend compte de 95,6 % de la population à l’échelle nationale et de plus de 91 % de la population dans l’ensemble des provinces et des territoires.
Puisque le FFT1 et l’ESF tirent leur information sur le revenu de la même source, leurs variables de revenu entretiennent des liens étroits sur le plan conceptuel, ce qui est utile pour la modélisation. Par ailleurs, le FFT1 utilise le concept de famille de recensement pour grouper les personnes dans une famille de recensement (parents et enfants vivant à la même adresse) ou pour les désigner comme personnes hors d’une famille de recensement. Ce concept ne cadre pas tout à fait avec la définition de ménage utilisée pour concevoir les TARM. Toutefois, les types de modèles utilisées dans les TARM, au niveau du domaine, sont plus résistants à ce type de divergence que d’autres types de modèles.
9.3.2 Qualité du modèle
La capacité du modèle à estimer la valeur nette pour les années où il n’y a pas d’ESF est longuement abordée ci-dessus. Les modèles de la valeur nette sont une composante fondamentale de la méthodologie pour les tableaux sur le patrimoine des TARM. Comme avec tout modèle, ils peuvent uniquement refléter les tendances pour la répartition de la valeur nette qui sont liées à celles observées dans les données auxiliaires, c.-à-d. les tendances de la valeur nette liées au revenu et à la démographie dans le cas présent.
Essentiellement, le modèle de la valeur nette suppose que la relation qui existe entre les données du FFT1 et la valeur nette dans les régions géographiques des données de l’ESF de 2012 se maintient aussi au fil du temps et se reporte à l’ensemble de la période allant de 2010 à 2016. Il s’agit d’une hypothèse d’une importance fondamentale. Elle a été partiellement évaluée en utilisant les données de l’ESF de 1999 et de 2005. Une évaluation plus complète de cette hypothèse pourra être réalisée en 2018 lorsque les données de l’ESF de 2016 et du FFT1 de 2016 seront disponibles.
Les modèles au niveau du domaine sont un choix approprié, car ils résistent mieux aux divergences dans les définitions entre les données d’enquête et les données auxiliaires. Le regroupement des ménages selon des régions géographiques suffisamment importantes fait en sorte que les données sont également moins influencées par les valeurs aberrantes.
9.4 Combinaison des sources
Les TARM rassemblent des données provenant de sources variées qu’il est peu surprenant que les différences conceptuelles entre les sources de microdonnées et de macrodonnées constituent un défi majeur. L’utilisation de la modélisation pour les années où il n’y a pas eu d’ESF ajoute une source supplémentaire de microdonnées devant être rapprochées avec les autres.
La méthodologie mise de l’avant dans le présent document et utilisée pour produire les tableaux provisoires sur le patrimoine des TARM comporte de multiples étapes (rapprochement des microconcepts et des macroconcepts, modélisation, étalonnage, réconciliation). Tout au long de ces étapes, les erreurs peuvent s’accumuler ou s’annuler entre elles. L’une des raisons pour lesquelles on procède à l’étalonnage et à la réconciliation est pour limiter les répercussions des différents types d’erreurs énumérés ci-dessus.
10 Annexe
10.1 Coefficients de variation des erreurs d’échantillonnage pour l’ESF de 2012
10.2 Facteurs pour mettre à l’échelle
Le tableau suivant montre l’ampleur des ajustements apportés pour mettre à l’échelle les catégories d’actifs et de passifs. Ces facteurs correspondent aux différences de couverture en 2012, et les différences de couverture et de croissance pour les autres années.
10.3 Facteurs multiplicatifs reliés à l’étalonnage
Les tableaux suivants montrent l’ampleur des ajustements reliés à l’étalonnage sur les répartitions de la valeur nette. Ces ajustements sont appliqués à chaque année de 2010 à 2014.
10.4 Facteurs d’ajustement relié à la réconciliation
Les tableaux suivants montrent l’ampleur des ajustements reliés à la réconciliation entre les répartitions des variables d’actif et de passif. Ces facteurs sont calculés comme la valeur après la réconciliation divisée par la valeur après la mise à l’échelle. Les répartitions de la valeur nette ne sont pas modifiées par la réconciliation.
11 Bibliographie
Bérubé J. et Fortier S. (2009). PROC TSRAKING: An in-house SAS® procedure for balancing time series. JSM Proceedings, Business and Economic Section. Alexandria, VA: American Statistical Association.
Commission économique des Nations Unies pour l’Europe (CEE-ONU). (2011). Canberra Group Handbook on Household Income Statistics Second Edition. Genève.
Dagum, E. B. et Cholette, P. A. (2006). Benchmarking, Temporal Distribution and Reconciliation Methods for Time Series Data. Springer-Verlag, New York. Lecture Notes in Statistics #186.
Laferrière, D. et Boulet, C. (2015). 2016 Survey of Financial Security (SFS) Net worth model development. Statistics Canada document interne.
Latendresse, E., Djona, M. et Fortier, S. (2007). Benchmarking Sub-Annual Series to Annual Totals – From Concepts to SAS® Procedure and SAS® Enterprise Guide® Custom Task. Proceedings of the SAS Global Forum, April 2007.
OCDE. (2013). OECD Framework for Statistics on the Distribution of Household Income, Consumption and Wealth. Publication de l’OCDE.
OCDE. (2013). OECD Guidelines for Micro Statistics on Household Wealth. Publication de l’OCDE.
Quenneville, B. et Fortier, S. (2012), Restoring accounting constraints in time series – Methods and software for a statistical agency, in Economic Time Series Modeling and Seasonality, ed. By Bell, W.R., Holan, S.H., and McElroy, T.S., Chapman and Hall/CRC, New York, 231–253.
Rao, J. N. K., & Molina, A. (2015). Small Area Estimation, 2nd Edition. Wiley, Hoboken, NJ.
Statistique Canada. (1er oct. 2012). Anaylse des révisions – Système de comptabilité nationale du Canada 2012. Récupéré sur Nouveautés en matière de comptes économiques canadiens.
Statistique Canada. (24 févr. 2014). Enquête sur la sécurité financière (ESF). Récupéré sur CANSIM.
Statistique Canada. (24 févr. 2014). Enquête sur la sécurité financière (ESF). Récupéré sur la Base de métadonnées intégrées (BMDI).
Statistique Canada. (1er déc. 2015). Résultats de la révision exhaustive du Système canadien des comptes macroéconomiques de 2015. Récupéré sur Nouveauté en matière de comptes économiques canadiens.
Statistique Canada. (10 mars 2016). Comptes du bilan national (CBN). Récupéré sur CANSIM.
Statistique Canada. (13 juillet 2016). Estimations annuelles du revenu des familles de recensement et des particuliers (fichier des familles T1). Récupéré sur la Base de métadonnées intégrées (BMDI).
Statistique Canada. (14 sept. 2016). Comptes du bilan national (CBN). Récupéré sur la Base de métadonnées intégrées (BMDI).
Stiglitz, J. E.-P. (2009). Report by the Commission on the Measurement of Economic and Social Progress.
Van Rompaey, C. (2016). Wealth in Canada: Recent Development in Micro and Macro Measurement. Statistique Canada.
Zwijnenburg, J. (2016). Further Enhancing The Work On Household Distributional Data - Techniques for Bridging Gaps Between Micro and Macro Results And Nowcasting Methodologies For Compiling More Timely Results.
Zwijnenburg, J., Bournot, S., & Giovannelli, F. (2016). Expert Group on Disparities within a National Accounts Framework - Results from a recent exercise.
- Date de modification :