
Rapports sur les projets spéciaux sur les entreprises
Un aperçu d’une sélection de programmes internationaux en matière de couplage d’enregistrements entreprises
 Consulter la version la plus récente.
Consulter la version la plus récente.
Information archivée dans le Web
L’information dont il est indiqué qu’elle est archivée est fournie à des fins de référence, de recherche ou de tenue de documents. Elle n’est pas assujettie aux normes Web du gouvernement du Canada et elle n’a pas été modifiée ou mise à jour depuis son archivage. Pour obtenir cette information dans un autre format, veuillez communiquer avec nous.
par Julio Miguel Rosa, Centre des projets spéciaux sur les entreprises
Début de l'encadré
Résumé
Bien que le couplage d’enregistrements des données d’entreprises ne soit pas un sujet complètement nouveau, il n’en demeure pas moins que le grand public et de nombreux utilisateurs de données en méconnaissent les programmes et méthodes générales mises en œuvre par les agences de la statistique à travers le monde.
Ce rapport fait un rapide tour d’horizon des principaux programmes, pratiques d’usages et enjeux sur le couplage d’enregistrements des agences de la statistique à travers le monde ayant répondu à un mini-sondage sur ce sujet. Le document montre que les pratiques d’appariements sont similaires entre agences de la statistique, mais que les principales différences résident dans les processus d’accès aux données et dans les politiques règlementaires qui encadrent les autorisations de couplage d’enregistrements ainsi que leur diffusion.Fin de l'encadré
I. Introduction
Le principal objectif de ce rapport est de faire une revue d’une sélection de programmes et des pratiques communément utilisées par les agences internationales de la statistique en matière de couplage d’enregistrements.
La définition de couplage d’enregistrementsNote 1 qui sera utilisé dans ce rapport est la suivante :
« Le couplage d’enregistrements est défini comme étant la combinaison de deux micro-enregistrements ou plus en vue de former un enregistrement composé comprenant des renseignements au sujet de la même entité. Le produit d’un couplage d’enregistrements doit contenir des renseignements provenant de plus d’un fichier de données qui ont été des intrants dans l’activité de couplage d’enregistrements. Dit autrement, le couplage d’enregistrements est l’intégration de plusieurs sources d’informations sous forme de données indépendantes. Par ailleurs, le couplage d’enregistrements demeure une technique importante pour le développement de données, la production d’information et de base de données, l’analyse et l’évaluation statistique des données. »
Source : Statistique Canada (août 2011). Document interne intitulé : « Directive sur le couplage d’enregistrements ».
L’expérience de Statistique Canada en la matière servira de référence lorsque viendra le temps de décrire les approches adoptées par d’autres agences de la statistique. Ce choix n’est pas anodin, il découle du fait que Statistique Canada possède l’une des plus ancienne et vaste expertise en matière de couplage d’enregistrements. En effet, Statistique Canada est un leader dans le monde pour le développement des méthodes d’appariements avec entre autres, le travail théorique commencé par Fellegi et Sunter (1969) et que Fellegi alors statisticien en chef de Statistique Canada a poursuivi en 1999 [(Fellegi, 1999)]. De nos jours, de nombreuses agences de la statistique à travers le monde s’inspirent du modèle et des pratiques de Statistique Canada en matière de couplage d’enregistrements.
Bien que le couplage d’enregistrements soit largement répandu du côté des données sociales, en particulier dans les données de la santé et en épidémiologie [(Winkler, W. E. (1999); Newcombe et al. (1992)], le présent rapport cible principalement les programmes de couplage d’enregistrements pour les données d’entreprises. Une des raisons de ce choix réside dans le fait que le couplage de données d’entreprises connaît un regain d’attention dans le monde. La nature même des activités des entreprises amène Statistique Canada à prendre des mesures particulières et restrictives sur les questions de la protection de la confidentialité des bases de données entreprises.
Afin de faciliter la comparaison des différentes méthodes et pratiques d’appariements au niveau international, Statistique Canada, en plus de prendre l’information disponible publiquement, a préparé un mini questionnaire destiné à un nombre d’agences de la statistique afin de collecter et de comparer une information uniforme sur leurs méthodes et pratiques en matière de couplage d’enregistrements.
En aucun cas, ce rapport ne constitue une liste exhaustive et détaillée des pratiques internationales, mais il donnera aux lecteurs un aperçu général de ce qui se fait ailleurs en matière de couplage d’enregistrements. Ce document sera d’un intérêt tout particulier pour le lecteur qui cherche à comprendre quelles sont les pratiques et les expériences internationales en matière de couplage d’enregistrements et quels en sont les principaux enjeux pour les agences de la statistique.
Ce rapport est d’organisé comme suit. Dans la prochaine section nous présentons les pratiques courantes en matière de couplage d’enregistrements. La section 3 est dédiée à la revue des informations publiables disponibles sur les pratiques et programmes internationaux en matière de couplage d’enregistrements. Finalement, la quatrième section résume les résultats d’une mini enquête envoyée aux différentes agences de la statistique internationale.
II. Pratiques courantes en matière de couplage d’enregistrements
A. Processus de couplage d’enregistrements
Pour répondre à la demande croissante pour des données de plus en plus complexes et détaillées, les agences statistiques intègrent de plus en plus des informations en provenance de multiples sources tout en combinant les informations dans le but d’en améliorer la qualité, d’augmenter la quantité d’information disponible, de partager ces données et de permettre des analyses plus détaillées [(Christen, P. (2012)]. Les techniques de couplage de l’information sur les individus malades sont abondamment utilisées dans les milieux de la santé. Cette technique permet de faire un meilleur suivi des maladies cardiaques et contagieuses tout en réduisant le coût d’un système de surveillance des maladies non intégré. En dehors du domaine des données sociales, des données d’entreprises et de la santé, le couplage d’enregistrements connaît une forte croissance dans les domaines tels que le développement de sites Internet de recherche [Su, Wang, and Lochovsky (2009)], mais aussi dans des domaines tels que de la criminalité, la prévention de la fraude et du terrorisme. Ce dernier domaine d’application revêt d’une grande importance pour les questions de sécurité nationale et contribue au regain d’intérêt pour ces techniques [Larsen (2006); Jonas and Harper (2006)].
Le couplage d’enregistrements est avant tout un puissant instrument d’aide à la décision pour les gouvernements et autres institutions. Il permet d’accroitre considérablement le potentiel analytique des bases de microdonnées ainsi que leur qualitéNote 2 en particulier lorsqu’il s’agit de couplage de données administratives avec des données d’enquêtes. En plus d’être un outil d’excellence pour l’analyse et la recherche, le couplage d’enregistrements réduit considérablement le fardeau de réponse, le coût et le temps de la collecte d’information.
Il existe principalement deux types de couplage d’enregistrements : le couplage déterministe et le couplage probabiliste.
“Les couplages d’enregistrements déterministe et probabiliste sont des méthodes qui combinent l’information d’enregistrements de différentes bases de données pour former une nouvelle base de données couplée. Le couplage probabiliste a été décrit comme un processus qui tente d’apparier les enregistrements de différents fichiers qui ont la plus grande probabilité de correspondre à la même personne ou entreprise. Tandis que le couplage déterministe utilise un identifiant unique pour coupler les données, le couplage probabiliste utilise la combinaison de plusieurs identifiants pour identifier et évaluer l’appariement.
Le coupage probabiliste est en général utilisé lorsqu’il n’y a pas d’identifiant unique disponible ou que ce dernier est de mauvaise qualité. La méthode dérive son nom du cadre conceptuel probabiliste développé par Fellegi et Sunder (1969) et requiert un logiciel sophistiqué pour exécuter les calculs.”
Source : National Statistical Service. Australian Government (Data linking information series).
B. Couplage d’enregistrements probabiliste
La figure 1 ci-dessous illustre schématiquement le processus de couplage d’enregistrements qui est généralement utilisé par la plupart des agences de la statistique. Cette figure est largement inspirée du modèle présenté dans Christen, P. (2012a). Dans cette illustration on présente à titre d’exemple deux bases de données (A et B) que l’on souhaite coupler. En pratique, on ne se limite pas nécessairement au couplage de deux bases de données on peut bien entendu procéder au couplage de plusieurs bases de données simultanément. Chacune des étapes de ce processus requiert un choix de techniques. Bien que de nombreuses techniques puissent conduire à des résultats équivalents, certaines techniques peuvent s’avérer plus efficaces que d’autres indépendamment des besoins et de la configuration des données. Il y a dans l’application de ce processus une part qui relève du savoir-faire et du jugement du statisticien qui applique la technique. Le statisticien doit juger de la pertinence de chacune des techniques à chaque étape du processus afin d’en optimiser le résultat du couplage. Ainsi, lors d’appariements dont on connait parfaitement les identifiants il n’est pas nécessaire d’utiliser des approches complexes comme le couplage probabiliste qui s’appliquent lorsque les bases de données n’ont pas d’identifiant commun. Par exemple, Statistique Canada ne fait principalement appel qu’à des techniques d’appariement déterministes pour coupler les enquêtes entreprises dans l’environnement de fichiers couplables (EFC) de Statistique Canada. Les méthodes probabilistes ne seront utilisées que lorsqu’il est difficile, voire impossible, d’obtenir un identifiant.
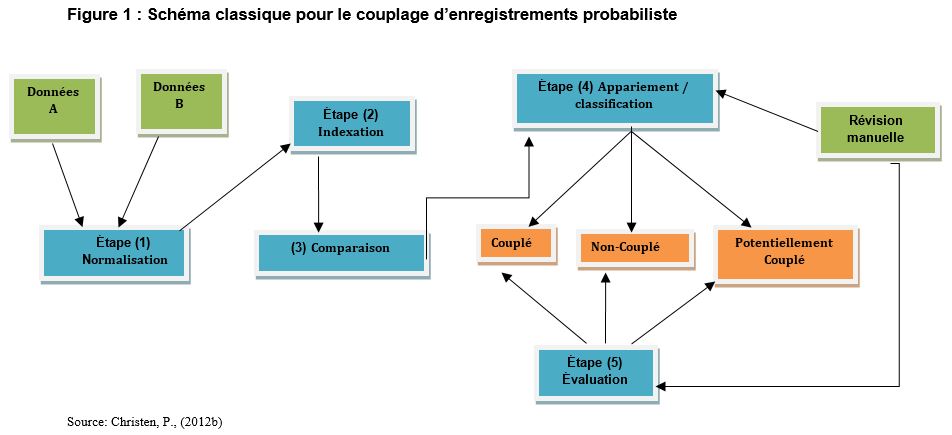
Description de la figure 1
Cette figure illustre le processus général de couplage de deux bases de données (A) et (B). Ce processus comprend cinq étapes : la normalisation, l’indexation, la comparaison, l’appariement / classification et l’évaluation.
Étape (1) – Normalisation : Ce processus de couplage d’enregistrements consiste à normaliser la syntaxe (Standardization); à répartir les caractères en champs identifiables sous une forme et format cohérent afin d’en faciliter le traitement (Parsing); à transformer (Transformation) et corriger (Editing) les données. Par exemple, la normalisation peut consister à attribuer le terme ‘Corporation’ à tous champs de variables indiquant le nom d’une compagnie, ou encore à éditer une date dans un même format. La répartition serait l’opération qui consiste à séparer l’adresse d’une entreprise en des champs facilement identifiables comme le numéro, la rue, le code postal ou la province. La transformation serait par exemple le changement des caractères minuscules en majuscules ou l’inverse, ou encore de changer un caractère numérique en alphanumérique. La correction serait d’exclure une observation qui serait entrée par erreur. Cette étape est donc essentielle à la préparation préalable de la base de données. Cette étape est parfois appelée le prétraitement.
Étape (2) - Indexation : Le processus d’indexation (Indexing) consiste à générer des paires de candidats pour l’appariement. Le but étant de mettre en œuvre une technique qui puisse réduire autant que possible le nombre de paires d’observations à comparer. Le professeur Peter Christen a identifié six méthodes d’indexations, voir les articles [Christen, (2012a); Baxer and al. (2003)] pour plus de détailsNote 3. Dans le cadre de ce rapport on ne décrira que la technique la plus commune, soit le (Blocking). Dans cette technique, seules les unités qui se trouvent dans un bloc commun se comparent entre elles. Si l’on a 1000 observations d’une base de données à comparer avec chacune des 1000 autres observations de l’autre base de données (à supposer qu’il n’y a pas de duplication), on devra comparer un million de paires d’observations pour n’en retenir qu’un seul couple d’observations. Par exemple, une façon plus simple de réaliser le compte d’entreprises serait de séparer les entreprises en blocs communs, ou chaque bloc correspondrait aux entreprises qui ont un nombre équivalent d’employés et puis on procéderait à la comparaison des entreprises qui appartiennent à un même bloc.
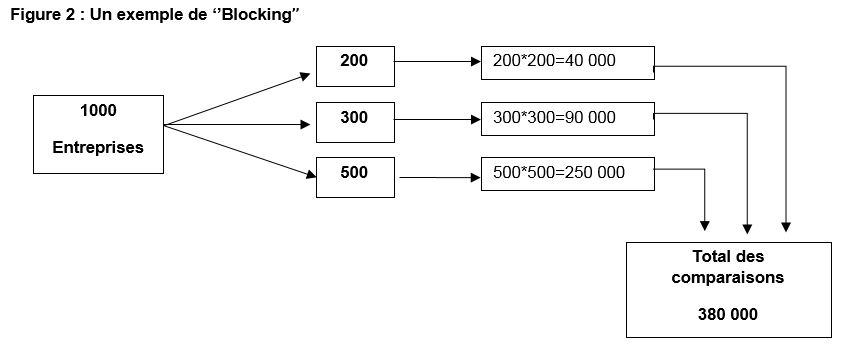
Description de la figure 2
Cette figure illustre le cas où il faudrait comparer 1000 entreprises. Si on crée des blocs d’entreprises de taille commune, disons que l’on obtient trois tailles soit trois blocs de respectivement 200, 300 et 500 entreprises. Il suffira alors de comparer respectivement 40, 000; 90,000 et 250,000 couples d’entreprises à l’intérieur de chaque bloc contre un million si l’on n’avait pas procédé à une telle séparation.
Il existe également de nombreux algorithmes basés sur la phonétique pour former des blocs. Les deux plus connus étant Soundex et le “New York State Identification and Intelligence System” (NYSIIS)Note 4. Ces algorithmes utilisent la reconnaissance phonétique pour encoder les noms et champs alphanumériques. Dans le livre de Peter Christen au chapitre 4, on trouve une explication sur les ces algorithmes et quelques tableaux comparatifs sur la différence des résultats que l’on obtient à partir de ces différents algorithmes lorsqu’on les applique à un même champ alphanumérique. Pour plus de détails sur ces systèmes de codification phonétique, voir [Herzog and al. (2007) Chap. 11 et Part II chap. 4].
Étape (3)- Comparaison : Ce processus consiste à comparer les paires d’observations retenues dans l’étape (2). Il s’agit de comparer les chaînes de caractères entre les paires d’observations en leur attribuant une valeur (score) qui se calcule à partir de fonctions algébriques de comparaison des chaînes de caractères. Ces fonctions permettent de comparer les similarités entre paires d’observations à partir de chaînes de caractères alphanumériques. En effet, les paires d’observations peuvent contenir des différences mineures dans les noms des variables qui servent à la comparaison. Les fonctions algébriques de comparaison des chaînes de caractères tiennent compte à la fois de la longueur des chaînes de caractères, mais aussi des possibles erreurs sur ces caractères. Par exemple, la transposition d’une lettre dans les noms. Les comparateurs de chaînes algébriques les plus communément utilisées sont: Jaro et Winkler String Comparison; Q-gram Based String Comparison; Edit Distance String Comparison (Smith-Waterman edit distance); Monge-Elkan String Comparison; Extended Jaccard comparison; Syllable Alignment Distance. Pour plus de détails sur les algorithmes de ces fonctions algébriques de comparaison des chaines de caractères voir [Christen, (2012b) Part II chap. 5].
Étape (4)- Appariement et classification : Ce processus est l’opération de classification et le couplage des enregistrements. Parfois ces deux opérations sont séparées en deux étapes distinctes. Le but de la classification est de pouvoir placer les paires d’observations selon qu’elles sont couplées, non couplées ou potentiellement couplées. Pour ce faire l’utilisateur décide des règles prioritaires pour définir les concordances entre paires d’observations. Par exemple l’utilisateur peut décider que la règle de concordance sera fondée sur l’adresse, le nom d’entreprise et le nom du propriétaire. Pour ces règles, des probabilités des niveaux de concordance seront calculées (scores) et attribuées à chaque paire d’observations. La décision de classer la paire d’observations dans la catégorie couplée, non couplée ou potentiellement couplée se fonde sur le score de similarité de la concordance. Le score se situe dans un intervalle de valeurs entre M (pour les observations couplées) et U (pour les observations non couplées). La règle de décision peut être déterministe ou probabiliste (voir la section II-A intitulée “Objectifs et type de couplages”). Bien que cette étape de classification soit basée sur une méthode statistique, pour les paires d’observations classées dans la catégorie “potentiellement couplées”, une intervention humaine sera requise pour placer ces paires dans l’une ou l’autre des catégories “couplées; non couplées”.
Étape (5)- Évaluation : Une fois que l’algorithme mathématique a déterminé les paires d’observations qui seront couplées, non couplées ou potentiellement couplées, il faut évaluer la qualité des couplages, c’est-à-dire que cette étape consiste à identifier les vrais des faux couplages et les classer selon le type d’erreur de couplage ou catégorie d’appariement tel qu’indiqué dans le tableau 1 ci-dessous.
| L’observation est associée avec la même unité | L’observation n’est pas associée avec la même unité | |
|---|---|---|
| L’observation est couplée | L’observation est correctement couplée (vrai couplage) (VP) | L’observation est couplée par erreur - Erreur de type I ou faux couplage négatif (FN) |
| L’observation n’est pas couplée | L’observation est non couplée par erreur - Erreur de type II ou faux couplage positif (FP) | L’observation est correctement non couplée (vrai non couplage) (VN) |
Cette étape requière l’intervention humaine pour distinguer les faux couplages négatifs (FN)= l’observation est couplée par erreur- Erreur type I, des “faux couplages positifs (FP)= l’observation est non couplée par erreur – Erreur type II” en minimisant ces deux types d’erreurs. Les deux autres catégories sont les vrais couplages (VP) et les vrais non-couplages (VN). Le tableau 1 illustre les types d’erreurs d’associations possibles. C’est dans cette étape que l’on évalue la qualité de l’appariement. Une revue par le jugement du statisticien peut être requise lorsque l’appariement par les algorithmes connus ne peut s’effectuer ou nécessite un jugement du statisticien [Guiver, (2011)]. À cette étape on fait appel au jugement pour déterminer le couplage le plus approprié. Généralement, que ce soit pour un couplage déterministe ou un couplage probabiliste, la validation manuelle systématique demeure une étape importante qui assure de la qualité du couplage.
III. Un survol des programmes internationaux de couplage d’enregistrements
A. Cadre contextuel du couplage d’enregistrements
Au Canada, les programmes de couplages d’enregistrements existent depuis les années 1970 dans le domaine de la santé. Par exemple, les données canadiennes sur la mortalité, le cancer, les naissances et la mortinatalité ont été combinées afin de permettre de nombreuses études scientifiques et le suivi de maladies graves. Pour les agences de la statistique, les techniques d’appariement sont des techniques importantes à la fois pour la production d’informations autrement impossible à retracer, pour l’analyse, mais aussi pour l’amélioration de la qualité du système statistique en général.
Pour la plupart des agences, le recours au couplage d’enregistrements requiert un cadre éthique et règlementaire (voir annexe A). La plupart des agences de la statistique se sont dotées de politiques et directives visant à encadrer la production et l’utilisation de données couplées. Statistique Canada est principalement gouverné par la Loi de la Statistique fédérale et La Politique sur la protection de la vie privée [Statistique Canada (1985)], ainsi que par la Directive relative au couplage d’enregistrements [Statistique Canada (2011)] afin d’encadrer les pratiques d’enregistrements. Les autres agences statistiques ont leurs propres politiques et lois. On peut citer l’exemple de l’Australie qui a pour équivalent à la législation de Statistique Canada le “Australian Bureau of Statistics Act 1975” et le “Census and Statistics Act 1905”. Par ailleurs, le bureau australien de la statistique peut également s’appuyer sur le “Privacy Act 1988” pour règlementer les activités statistiques relatives à la confidentialité et à la vie privée.
B. Les politiques et directives pour le couplage d’enregistrements au Canada
Statistique Canada a pour mandat de recueillir, compiler, analyser, dépouiller et publier des renseignements statistiques sur les activités et les conditions commerciales, industrielles, financières, sociales, économiques et générales de la population canadienne (Article 3 de la Loi sur la statistique fédérale). Le couplage d’enregistrements fait partie des activités du mandat de Statistique Canada et d’autres agences à travers le monde. Mais, avant de procéder à l’approbation d’un couplage d’enregistrements, la plupart des agences de statistiques nationales imposent des conditions préalables afin de préserver la vie privée des répondants et la confidentialité de l’information sur les entreprises tout en s’assurant que le couplage s’opère dans un cadre législatif et de consentement mutuel. Pour satisfaire ces conditions, Statistique Canada a mis en place depuis 1986 une Directive sur le couplage d’enregistrements ainsi qu’une Politique sur la protection des renseignements personnels et la confidentialité et une Politique sur la protection de la vie privée [Statistique Canada (1985)].
La Directive sur le couplage d’enregistrements impose que chaque proposition de couplage d’enregistrements fasse l’objet d’une demande distincte. La proposition doit comporter un aperçu des plans de recherche proposés et mentionner brièvement les objectifs du projet de recherche ou de l’étude. Il faut également décrire et analyser en détail l’objet du couplage d’enregistrements proposé, y compris les principales raisons de la réalisation du couplage et l’utilisation escomptées des résultats.
La proposition de couplage d’enregistrements est soumise au Conseil exécutif de gestion pour approbation du couplage. Le Conseil exécutif évaluera les avantages du couplage d’enregistrements, comment le couplage sert les intérêts du public et pourquoi le couplage d’enregistrements est la meilleure approche pour répondre aux besoins du public. Le Conseil exécutif considérera également l’efficacité du couplage d’enregistrements en termes de coûts, de temps et du fardeau de réponse. Ce Conseil déterminera également si le couplage permet à la fois de répondre aux besoins de la recherche et de l’analyse tout en respectant la vie privée des individus et de la confidentialité de l’information sur les entreprises. Dans certains cas, le couplage d’enregistrements peut être garantie par un couplage en cours, existant ou omnibus, auquel cas la soumission au Conseil exécutif de gestion pour approbation ne sera pas requise.
Pour réduire l’atteinte à la vie privée que porte le couplage, les identificateurs doivent être supprimés du fichier couplé dès que le couplage est achevé et entreposés séparément. Le Conseil force également la tenue à jour de la gestion et de la conservation de tous les couplages d’enregistrements approuvés. Les couplages autorisés doivent être affichés sur le site web de Statistique Canada. Les données couplées doivent faire mention de la période de conservation. Les divisions responsables du couplage d’enregistrements sont responsables d’évaluer la période de conservation et la date de destruction de ces fichiers.
Statistique Canada s’assure de protéger la vie privée des répondants et la confidentialité de l’information. L'engagement de Statistique Canada visant à protéger les renseignements que lui transmet la population du Canada est garanti par la Loi sur la statistique et par les diverses politiques et pratiques encadrant les activités liées à la collecte, à l'analyse et à la communication de données.
Conformément aux exigences prévues dans le cadre de la Loi sur la statistique, Lois révisées du Canada, 1985, Statistique Canada doit aviser les répondants du couplage prévu de leurs réponses à l’enquête aux données d’autres enquêtes ou fichiers administratifs. L’avis donné peut être précis ou général. Si un répondant à une enquête à participation volontaire déclare qu’il s’oppose au couplage d’enregistrements prévu, aucun couplage de ses réponses à l’enquête ne sera permis.
Par ailleurs, en matière de couplage d’enregistrements, il faut répondre aux conditions énumérées ci-dessous pour pouvoir procéder au couplage.- le couplage d'enregistrements sert à des fins statistiques ou de recherche et est conforme au mandat de Statistique Canada, tel qu'il est décrit dans la Loi sur la statistique;
- la diffusion des produits du couplage d'enregistrements satisfait aux dispositions relatives à la confidentialité de la Loi sur la statistique ainsi qu'aux dispositions pertinentes de la Loi sur la protection des renseignements personnels;
- le couplage d'enregistrements, plus que tout autre moyen, donne lieu à des économies de coût vérifiables ou à un allégement démontrable du fardeau des enquêtes, ou encore il représente la seule option possible;
- le couplage d'enregistrements ne sera pas utilisé à des fins qui serviraient au détriment des répondants visés et il est évident que les avantages en découlant servent l'intérêt public;
- le couplage d'enregistrements n'est pas considéré comme un préjudice à l'exécution future de programmes de Statistique Canada;
- le couplage est conforme à un processus prescrit de révision et d'approbation (ce qui comprend un examen mené par le Comité de la confidentialité et des mesures législatives et le conseil exécutif de gestion de Statistique Canada, de même qu'un examen ministériel des types de couplages qui n'ont pas été préalablement approuvés par le Ministre; les nouveaux types de projets de couplage importants font l'objet de discussions avec le Commissariat à la protection de la vie privée).
- Les fichiers couplés seront détruits lorsque le projet sera achevé conformément à la date prescrite pour la destruction des fichiers.
Sources : Statistique Canada, Manuel des politiques, 4.1, Politique relative au couplage d'enregistrements; Secrétariat du Conseil du Trésor, Politique sur le couplage des données.
C. Quelques exemples d’initiatives de couplage d’enregistrements au niveau international
L’intérêt croissant des agences de la statistique pour le couplage d’enregistrements les poussent de plus en plus à développer, définir et documenter leurs approches méthodologiques ainsi qu’à définir des politiques internes relatives au couplage d’enregistrements. Dans la mesure où les expériences d’intégration de données et les variations dans les procédures d’une institution à l’autre, les sections qui suivent présentent une vue d’ensemble des expériences récentes des agences de la statistique avec le couplage d’enregistrements. La sélection des pays retenus s’est établie uniquement sur la base de la documentation disponible sur Internet. Aussi souvent que possible, on a mis l’accent sur la singularité qui caractérise le système d’intégration des données de chacune des agences.
1. Le Canada
Pour répondre aux besoins croissants en matière d’information économique et avec l’appui des ministères du gouvernement fédéral, Statistique Canada s’est engagé dans un ambitieux projet d’intégration de données dans le secteur des entreprises dont la phase initiale a débuté en 2008. Ce projet désigné sous le nom d’Environnement de Fichiers pouvant être Couplés (EFC) se matérialise par la mise en place d’une base de données relationnelle qui associe de multiples sources d’information (enquêtes et données administratives) au Registre des Entreprises (RE) qui constitue la base de données de référence. Cet environnement intégré comprend plusieurs étapes incluant, le transfert de données en provenance de divers secteurs de Statistique Canada, l’assurance de la qualité du couplage et des variables utilisées, la production d’un rapport sur la qualité du couplage ainsi que les dictionnaires des variables. Dans la grande majorité des cas, l’intégration est relativement simple puisque les identifiants sont connus.
Comme la plupart des sources d’information internes ont un identifiant unique déterminé par le registre des entreprises, Statistique Canada obtient un taux d’appariement proche de 100% (couplage dit déterministe). Cependant, certaines sources d’information externes n’ont pas d’identifiant et doivent faire appel à des techniques probabilistes d’appariement, c’est le cas pour les données sur les brevets. Le taux d’appariement pour ce type de couplage est très variable, car il dépend de la qualité de la source d’information. Sans un identifiant qui provient du registre des entreprises, on doit parfois se servir de l’adresse opérationnelle ou du code postal pour procéder au couplage (couplage dit probabiliste).
L’EFC n’est pas une base longitudinale, mais plutôt une base de données transversale compilée sur une période de quinze années (de 2000 à 2014). L’EFC comprend actuellement une vingtaine de sources de données administratives et d’enquêtes différentes. L’originalité de l’EFC réside dans sa vaste exploitation par les utilisateurs et sa capacité à extraire des bases de données couplées sur mesure pour le chercheur. En effet, depuis sa mise en place un nombre considérable et croissant de projets analytiques ont été réalisés à partir de cet environnement.Statistique Canada a fait de grands efforts ses dernières années pour faciliter l’accès aux microdonnées, en particulier les efforts se poursuivent pour étendre l’accès aux universitaires et aux diverses agences gouvernementales. Le Centre canadien d'élaboration de données et de recherche économique (CDRE) a été mis sur pied afin de permettre aux chercheurs externes d’avoir accès aux micro-données disponibles incluant les bases de données couplées. Les résultats produits par les chercheurs sont soumis à des règles strictes de confidentialité avant que l’on en autorise la diffusion. (Pour plus de détails).
2. La Nouvelle–Zélande
La Nouvelle-Zélande est un des pays pour lequel on dispose d’une importante documentation sur Internet sur le couplage d’enregistrements, en particulier sur le site officiel de la Statistics New Zealand. La singularité du système de couplage d’enregistrements de Nouvelle-Zélande est qu’il s’est développé à partir d’un prototype d’infrastructure pour l’intégration de données (The Integrated Data Infrastructure (IDI) prototype). Cette infrastructure vise à établir un environnement de microdonnées longitudinales couplées incluant à la fois de l’information au niveau des individus, des ménages et des entreprises. Cette information est accessible aux chercheurs dont les projets ont été approuvés par le Statisticien en chef. Les données fiscales sont restreintes aux employés du gouvernement (incluant les employés sous contrat du gouvernement), et l’accès est également soumis à l’approbation du ministère du revenu.
Par ailleurs, la Nouvelle-Zélande possède un système statistique très semblable à celui du Canada. En particulier, en ce qui a trait aux politiques et directives visant l’intégration des données de sources séparées, afin de minimiser les risques relatifs à la confidentialité sur l’information d’individus ou d’entreprises [Statistics New Zealand (2012a) et (2012b)]. L’IDI se rapproche de ce que l’on retrouve à Statistique Canada avec l’EFC, mais il va plus loin puisqu’il intègre également des données sur les individus et les ménages. Cependant, à Statistique Canada une des principales sources pour les données longitudinales est le Programme d'analyse longitudinale de l'emploi (PALE), qui contient de l’information historique sur l’emploi des firmes avec employés.
Le Privacy Act interdit l’usage d’un identifiant universel entre agences, mais n’empêche pas l’agence de la statistique de Nouvelle-Zélande d’utiliser des identifiants uniques des données fournies par les autres ministères afin de coupler ces données avec IDI et de créer un nouvel identifiant longitudinal aux fins de recherche (ce couplage ne se fait qu’à l’intérieur d’un environnement de données sécurisé). Par exemple, l’agence de la Statistique de Nouvelle-Zélande utilise les numéros du ministère du Revenu (IR) pour coupler les données qui sont fournies par les différents ministères. Puis, l’agence de la statistique créée un identifiant longitudinal qui permet aux chercheurs de faire le suivi des unités dans le temps tout en empêchant l’identification des observations par le numéro IR d’origine. Sans la possibilité de créer un identifiant commun aux diverses sources de données, les données ne pourraient alors pas être couplées ni longitudinales.
L’IDI a été créé pour exploiter la puissance des données couplées afin d’appuyer les décideurs. L’agence de la statistique de Nouvelle-Zélande apparaissait comme l’institution désignée pour mener le projet de couplage des données considérant ses antécédents à titre de dépositaire des données; en matière de suivi d’observations ainsi qu’en ce qui concerne la confiance accordée par le public et de son rôle unique assigné par la Loi sur les statistiques.
La politique sur l’intégration des données de l’agence de la statistique de Nouvelle-Zélande contient quatre principes généraux :
- Principe 1: Les avantages du couplage de données pour le public doivent l’emporter sur les inconvénients liés à la confidentialité relativement à l’utilisation des données et sur les risques du couplage de données pour le système officiel de la Statistique, les sources de données collectées et / ou les activités du gouvernement.
- Principe 2: Les données couplées ne seront utilisées que pour des fins statistiques ou pour la recherche.
- Principe 3: Le couplage de données sera mené avec la plus grande transparence.
- Principe 4: Les données ne seront pas couplées lorsqu’un engagement explicite aura été conclu avec un répondant qui ne souhaite pas le couplage de données.
Source: Statistics New Zealand (2012a)
La Nouvelle-Zélande possède déjà une vaste expérience en matière de couplage d’enregistrements. Ces expériences incluent depuis 1997 le couplage de données employeur-employé (Linked Employer-Employee Data- (LEED)); le prototype de base de données entreprise longitudinal (Longitudinal Business Database Prototype- (LBD)); l’enquête de la population active auprès des ménages (Household Labour Force Survey- (HLFS)); l’emploi et revenu de l’enseignement supérieur (Employment Outcomes of Tertiary Education (EOTE)) et la base de données sur les prêts et indemnités aux étudiants (Student Loans and Allowances integrated dataset- (SLA)). L’IDI intègre les données du ministère du Travail de l’immigration et des déplacements internationaux (Department of Labour migration and international movements) avec les données longitudinales d’entreprises (Longitudinal Business Dataset (LBD)), tout en consolidant les données couplées existantes que nous venons de mentionner. Ce programme a reçu des fonds autorisés jusqu’en 2020, dont le but est l’amélioration constante du programme d’intégration des données. Pour obtenir plus de détails sur ce programme, veuillez consulter la référence suivante : Statistics New Zealand (2012a).
3. L’Allemagne
Comme d’autres paysNote 5 l’Allemagne détient un centre de recherche privé uniquement dédié à des services d’intégration de données (German Record Linkage Center). Ce centre mène actuellement une quinzaine de projets de couplage d’enregistrementsNote 6, pour plus d’information.
Les données couplées du gouvernement et du “German Record Linkage Center-GRLC” sont disponibles pour des fins de recherche seulement. Le GRLC en plus d’offrir des services d’information, met à disposition des chercheurs un logiciel d’intégration des données, le “Merge ToolBox-MT”.
En Allemagne il faut le consentement des répondants pour coupler leurs informations, autrement il faut l’accord de l’agence fédérale pour la protection des données. Aussi, afin de préserver la confidentialité des répondants, l’Allemagne explore des avenues méthodologiques permettant de crypter les identifiants [Schnell et al. (2004)].
Un exemple concerne l’intégration des données du registre des entreprises allemand (The Business Registre - URS) avec des données administratives d’institutions telles que l’agence fédérale de l’emploi (Federal Employment Agency) et la Deutsch Bundesbank. Ce programme se nomme “The KombiFi (Kombinierte Firmendaten für Deutschland)”, voir [Konold et Assainato (2009)] pour plus de détails. Dans ce projet on demande à environ 60 000 entreprises la permission de coupler les informations les concernant qui étaient auparavant détenues séparément par diverses institutions distinctes (agences statistiques; les banques et l’agence fédérale de l’emploi). Sur ce 60 000, 16 571 ont accepté (Vogel and Wagner-2012).
Un autre exemple, mentionnons l’expérience allemande visant à coupler les données administratives de l’emploi avec les données de l’enquête ALWA (Arbeiten and Lernen im Wandel-Working and Learning in a changing world)Note 7 qui contient de l’information longitudinale sur l’éducation, lieu de résidence, emploi, l’état civil, mobilité régionale, etc. pour 10,400 individus nés entre 1956 et 1988. Les entrevues pour ces individus ont été menées entre août 2007 et avril 2008. Les résultats de ce couplage ont fait l’objet de deux études détaillées, voir [Antoni (2011) ; Antoni and Seth (2012)]. Les données de ces deux sources d’information ont été uniformisées en procédant à des corrections pour les erreurs de typologie sur l’ensemble des variables. Avec une approche déterministe, 53% des 10,400 répondants ont été couplés. En ayant recours à l’approche probabiliste (Méthode Jaro-Winkler) le pourcentage de succès du couplage est monté à 83%, et avec la vérification manuelle ce pourcentage a atteint 86%. Cette expérience de couplage a permis de palier aux insuffisances d’informations de chacune des sources de données, par exemple les données administratives n’avaient que peu ou pas d’information sur l’éducation, alors que les données d’enquête manquaient de détails sur les revenus. Le développement du couplage de données en Allemagne est récent puisque précédemment, seules deux études [Beste (2011); Hartmann et Krug (2009)] avaient été menées en Allemagne pour des données semblables (données d’emploi et information administrative).
4. L'OCDE
En 2010, Eurostat, le bureau de la statistique de l’union européenne, a financé un projet de grande envergure pour une période de deux ans visant à intégrer les données d’enquêtes et les données administratives de plusieurs pays. Au total, une quinzaine d’agences se sont regroupéesNote 8 pour établir un projet commun et coopératif du nom d’ESSlimitNote 9. Le but de ce projet était d’établir de nouveaux indicateurs sur les caractéristiques des entreprises dans le domaine des technologies de l’information, en innovation et sur leur performance économique [OECD, (2012)]. Ce projet devait être moins axé sur la recherche fondamentale universitaire et plus axé sur le partenariat entre institutions nationales de la statistique (NSIs) pour le développement de données. L’intégration de l’information de plusieurs enquêtesNote 10 de plusieurs pays dont des données administratives a permis de produire des indicateurs au niveau de l’entreprise.
Les informations combinées ont été estimées avec des pondérations communes à tous les pays, ce qui implique que les résultats publiés ne pouvaient se comparer aux chiffres des publications officielles [OECD, (2012)]. L’effort méthodologique a été mis pour produire des indicateurs cohérents entre pays (les données des différents pays ont été traitées selon les mêmes règles), ce qui en fait une source d’information unique pour la comparaison entre pays, par industrie et à travers le temps. Plusieurs méthodes ont été utilisées pour l’intégration des données incluant le couplage d’enregistrements probabiliste. Dans la majorité des cas, l’identifiant unique au niveau de l’entreprise a suffi pour coupler les entreprises à partir des différentes enquêtesNote 11.
Ce projet d’intégration de données est intéressant à plusieurs égards. Conceptuellement, il a permis de compiler des indicateurs identiques et comparables au niveau d’agrégation industrielle pour plusieurs pays et plusieurs années, démontrant ainsi qu’il est possible d’intégrer des caractéristiques d’entreprises en science et technologie de plusieurs pays de manière cohérente.
Par ailleurs, Eurostat a récemment produit un rapport [Eurostat, (2013)] sur les résultats et l’avancement des projets initiés par Essnet (qui intègre également des données sur les individus). Il en résulte une vingtaine de projets réalisés ou en cours de réalisation. Certains de ces projets visent le développement méthodologique de données, par exemple ESeG (European socio-economic classification), un projet coordonné par la France, vise à construire une classification socio-économique regroupant des individus des tous les pays d’Europe aux caractéristiques socio-économiques similaires et ayant un style de vie comparable. Un autre projet coordonné par le Danemark a pour principal objectif la conceptualisation et le renforcement méthodologique visant à mesurer la chaîne de valeur mondiale (GVC). Ce projet a permis de produire des analyses sur la mesure de la globalisation économique et ses impacts pour la création de nouveaux emplois et sur la croissance économique des pays européens. D’autres projets ont été plus orientés sur le développement d’outils informatiques. Par exemple le projet SDMX coordonné par Istat (Italie) vise à développer une infrastructure informatique dont le but est d’intégrer différents outils statistiques existants.
Ces quelques exemples démontrent tout le potentiel et l’attrait pour les données couplées en Europe. Non seulement, les chercheurs ont accès à des microdonnées comparables entre pays, mais aussi pour la première fois ces données permettent d’accéder à un niveau de qualité jamais atteint en matière de comparaison des indicateurs autant pour les données sociales que d’entreprises. La réussite de ce projet permet désormais d’envisager une comparaison d’indicateurs entre nations hors de la communauté européenne.
5. L'Australie
Le système statistique australien est très semblable à celui que l’on retrouve à Statistique Canada. On pourra cependant apprécier le système australien pour sa très grande transparence décisionnelle en matière de collaboration interorganisations en ce qui concerne le processus d’approbation d’intégration des données (“The Census and Statistics Act 1905”). En effet, l’Australie a un Comité décisionnel (“Cross Portfolio Statistical Integration Committee – CPSIC”) pour l’intégration des données qui intègre l’ensemble des départements du gouvernement. Depuis 2009, les agences gouvernementales ont travaillé ensemble afin d’appuyer le gouvernement australien à développer son système statistique de données intégrées aux fins de recherche. Cette collaboration a donné lieu en février 2010 à l’adoption par le CPSICNote 12 (présidé par le Bureau de la Statistique Australien), à sept grands principes sur l’intégration de données impliquant des statistiques du Commonwealth ‘’High level principles for data integration involving Commonwealth data statistical and research purposes”. Ces principes énoncent les lignes directrices auxquels doit répondre tout projet de couplage d’enregistrements. Ces principes sont résumés dans le tableau 2.
| Principe 1: Ressources stratégiques | Les agences responsables devraient traiter, concevoir et gérer les données administratives comme une ressource stratégique afin d’appuyer l’utilisation des statistiques et de la recherche au sens large. |
|---|---|
| Principe 2: Imputabilité | Les organisations responsables des données utilisées dans le couplage d’enregistrements sont individuellement responsables de leur sécurité et de la confidentialité. |
| Principe 3: Responsabilité | Une autorité responsable sera désignée pour chaque proposition de couplage d’enregistrements. |
| Principe 4: Avantage pour le public | Le couplage d’enregistrements ne peut se faire que s’il y a un avantage significatif important pour le public. |
| Principe 5: Pour fins statistiques et de la recherche | L’utilisation des données couplées ne doit se faire que pour des fins statistiques ou des fins de recherche. |
| Principe 6: Préservation de la vie privée et confidentialité | Les politiques et procédures d’usages pour l’intégration des données doivent minimiser tout potentiel impact sur la vie privée et la confidentialité. |
| Principe 7: Transparence | L’intégration de données statistiques doit être menée avec ouverture et impartialité. |
| Source : High Level Principles for Data Integration Involving Commonwealth Data for Statistical and Research Purposes, February 3, 2010. | |
Par ailleurs, en plus d’assurer l’intégrité des sept principes sur l’intégration des données, le Comité sur l’intégration des données est responsable de l’évaluation du risque associé à chaque projet d’intégration de données via le processus d’accréditation (“Accreditation process”). Ce processus d’accréditation du risque lié à l’intégration des données est estimé selon huit éléments résumés dans le tableau 3. Les projets sont alors classés selon qu’ils sont à risque très élevé, modéré ou faible. Il suffit qu’un seul des huit éléments ci-dessous soit considéré comme à risque élevé pour classer immédiatement l’ensemble du projet comme étant à risque élevé.
| Élément 1 : Sensibilité | Par exemple des projets qui touchent des sujets sensibles comme la croyance religieuse, la santé des individus ou les statistiques sur les crimes. |
|---|---|
| Élément 2: Taille | On fait référence au nombre d’observations et de variables de la base de données. Le niveau de risque augmente avec l’étendue de l’information disponible. |
| Élément 3: Complexité technique | Le niveau de risque augmente avec le niveau de complexité du projet. Par exemple, le processus d’appariement peut se complexifier suite à de l’information manquante ou à la duplication d’information. |
| Élément 4: Complexité liée à la gestion | Le niveau de risque augmente lorsque les données à intégrer proviennent de multiples sources, différentes organisations, secteurs ou juridictions. Par exemple, différentes organisations peuvent avoir des chevauchements en ce qui concerne les besoins ou les niveaux d’accès aux données couplées. Par ailleurs, le déplacement des bases de données entre organisations augmente le niveau de risque. |
| Élément 5:Durée du projet | Le niveau de risque augmente lorsque la base de données couplée doit être mise à jour et archivée pour une longue période. À contrario, le niveau de risque diminue si la base couplée est détruite à la fin du projet. |
| Élément 6: Nature des données collectées | Le niveau de risque dépend de l’autorisation sur l’accord de consentement qui est établi entre l’agence statistique et le répondant. Si le répondant est consentant et est informé de l’usage de l’intégration des informations le concernant, le risque d’empiètement sur la vie privée et les risques associés à la confidentialité sont atténués. |
| Élément 7: Méthodologie d’intégration | Le niveau de risque augmente avec la précision de la méthode d’appariement. La méthode d’appariement déterministe et associée à un niveau de risque plus élevé que la méthode probabiliste qui est moins précise. |
| Élément 8: Accès aux données | Le niveau de risque augmente lorsque le couplage d’enregistrements nécessite l’accès à l’identifiant de l’enregistrement. Ce risque augmente avec le nombre d’intervenants et si l’accès se situe entre organisations internationales. |
| Source : “Data integration involving Commonwealth data for Statistical and research purpose: Governance,” October 6, 2010. | |
Le “Australian Privacy Act 1988” est en cours de révision afin d’y inclure les conditions prérequises nécessaires pour aviser l’entité qui fournit les données couplées en ce qui a trait aux institutions qui auront accès à l’information couplée ainsi que l’usage pour lequel ces données ont été couplées.
En Australie, la législation sous laquelle opère le Bureau australien de la Statistique interdit la publication de toute information permettant l’identification des données.
IV. Résumé du mini sondage auprès des agences de statistiques internationales
Afin de collecter de l’information uniforme sur les pratiques internationales en matière de couplage d’enregistrements, Statistique Canada a préparé et envoyé un questionnaire de deux pages à quelques agences internationales de la statistique. Ce questionnaire visait à collecter de l’information très générale sur les pratiques d’appariement des entreprises. Le questionnaire posait des questions sur l’administration ou non d’un processus formel d’approbation pour le couplage de données, sur les techniques d’appariement, les logiciels utilisés, l’usage des bases de données couplées et les enjeux pour l’agence liés au couplage d’enregistrements. Ci-dessous les principales considérations et commentaires reçus par les répondants.
A. Autorisation officielle de couplage d’enregistrements
Début de l'encadré
Question no 1
Votre organisation a-t-elle besoin d’une autorisation officielle pour coupler des bases de données?
Fin de l'encadré
Une seule organisation a répondu qu’elle n’a pas besoin d’une autorisation officielle pour coupler des bases de données. Un certain nombre d’organisations ont fait référence aux lois régissant leur organisation comme étant le cadre officiel en vertu duquel le couplage est permis. Dans un cas en particulier, la loi fournit à l’organisation des conditions ou des exceptions selon lesquelles le couplage d’enregistrements peut être effectué. Dans ce cas, le couplage peut être effectué si l’obtention de renseignements statistiques évite la tenue d’enquêtes statistiques supplémentaires.
Dans certaines organisations, on confie à une personne ou à un organisme la responsabilité d’approuver le couplage, comme un commissaire à la protection de la vie privée, un administrateur de données, une équipe interne chargée du couplage ou, dans le cas du Canada, un conseil de cadres supérieurs, le Conseil exécutif de gestion, qui comprend le statisticien en chef.
Un certain nombre d’organisations doivent recevoir l’accord des répondants ayant fourni les données avant de pouvoir procéder au couplage. Voici quelques autres processus officiels qui ont été mentionnés : informer les directeurs responsables, conclure des ententes sur les niveaux de service avec les parties gouvernementales visées qui acceptent la méthodologie, publier les projets d’intégration dans un site Web de registre national et démontrer clairement le besoin de l’utilisateur.
Pour de plus amples renseignements sur les processus officiels en Australie, y compris sur les principes généraux d’intégration des données et d’évaluation des risques de couplage reportez-vous à l’article III-C-5 ci-dessus.
B. Techniques de couplage d’enregistrements
Début de l'encadré
Question no 2
Quelles sont les techniques de couplage d’enregistrements utilisées par votre organisation?
- Couplage déterministe;
- Couplage probabiliste;
- Couplage non statistique (c.-à-d. un examen administratif);
- Autres.
Fin de l'encadré
Toutes les organisations, sauf une, ont recours à plus d’une technique. Les organisations qui utilisent des techniques déterministes ont mentionné l’utilisation des identificateurs d’entreprise et des numéros de taxe pour l’appariement déterministe. Cette approche est semblable à celle de Statistique Canada qui se fonde sur les identificateurs d’entreprise. Le même numéro d’entreprise est utilisé pour identifier une même entreprise dans toutes les enquêtes et les ensembles de données administratives de Statistique Canada.
Une organisation a largement recours au couplage probabiliste au moyen de la méthode Fellegi-Sunter. Cette règle est complétée par des tâches administratives qui permettent d’établir des seuils d’attribution pour les appariements. Une organisation a précisé qu’elle cherche actuellement des façons d’améliorer son processus d’examen administratif.
C. Applications logicielles
Début de l'encadré
Question no 3
Quelles sont les applications logicielles utilisées par votre organisation pour coupler les bases de données?
Fin de l'encadré
Le logiciel le plus mentionné pour le couplage était SAS en langage SQL, suivi des logiciels développés à l’interne. Parmi les autres logiciels utilisés, on dénote Oracle, SPSS, QualityStage, FEBRL V0.3 et General Clerical Reviewer (GCR). Une organisation explore actuellement l’utilisation de Relais, Fril et G-link.
D. Utilisation des bases de données couplées
Début de l'encadré
Question no 4
À quelles fins les bases de données couplées sont-elles utilisées?
- Pour appuyer la recherche;
- Pour appuyer l’évaluation des programmes (en tant que cohorte et non en tant que seule entité);
- Pour fournir des tableaux descriptifs aux clients;
- Pour fournir des fichiers de microdonnées à grande diffusion (FMGD);
- Pour appuyer la conception, la mise à jour et l’évaluation des processus continus de collecte des données;
- Pour préparer les publications produites par l’organisation;
- Pour d’autres utilisations, veuillez préciser.
Fin de l'encadré
Toutes les organisations ont indiqué que les bases de données couplées sont utilisées aux fins suivantes : pour appuyer la recherche et pour appuyer la conception, la mise à jour et l’évaluation des processus continus de collecte des données. Toutes les organisations, sauf une, ont indiqué que les bases de données couplées sont utilisées pour préparer les publications produites par l’organisation. Deux organisations ont indiqué qu’elles utilisaient les bases de données couplées à toutes les fins énumérées. L’objectif le moins répandu étant de fournir des FMGD. Une organisation a indiqué qu’elle utilise les bases de données couplées à une autre fin, soit pour réduire le fardeau du répondant dans la collecte de données d’enquête.
E. Défis et enjeux du couplage d’enregistrements
Début de l'encadré
Question no 5
Quels sont les principaux défis et enjeux de couplage d’enregistrements pour votre organisation?
- Confidentialité;
- Accès aux données pour les chercheurs externes;
- Couplage des données administratives;
- Couplage des données d’enquête;
- Enjeux liés à la longitudinalité;
- Autres, veuillez préciser.
Fin de l'encadré
La moitié des organisations ont répondu qu’elles faisaient face à tous les enjeux et les défis de la liste ci-dessus. Le couplage des données administratives est un défi et un enjeu pour toutes les organisations. Les autres défis et enjeux qui ont été mentionnés sont le couplage des données anonymes, l’évaluation de la qualité du couplage, la conformité à la législation internationale (c.-à-d. européenne), la nature des sources de données (plus précisément les différences conceptuelles, l’actualité, la fréquence, les retards de communication des données et les exigences de transformation pour les fournisseurs de données) ainsi que la diffusion efficace des ensembles de données couplées.
F. Qualité des bases de données couplées
Début de l'encadré
Question no 6
Veuillez décrire en quelques mots l’approche de votre organisation pour déterminer la qualité de vos bases de données couplées.
Fin de l'encadré
Les organisations ont indiqué différentes approches pour déterminer la qualité des bases de données couplées. Les réponses à cette question ont été groupées de façon thématique :
Évaluation de la qualité par les chercheurs externes
- La qualité des données couplées est évaluée par les chercheurs externes qui les utilisent;
- Dans les deux cas, il incombe aux chercheurs, qui utilisent tant les données que les métadonnées, de déterminer si les données conviennent (sont de qualité suffisante) au contexte particulier de son travail;
- L’organisation collabore avec les chercheurs pour vérifier la qualité de leurs données avant que le couplage ne soit effectué. Une fois couplées, les données sont régulièrement vérifiées afin d’identifier les changements au fil du temps.
- Des activités de couplage des données supplémentaires peuvent avoir lieu au sein de l’organisation dans une unité spécialisée, c.-à-d. un environnement sécurisé où les chercheurs internes et externes autorisés peuvent effectuer des analyses spécialisées sur différents ensembles de données, ce qui comprend le couplage de données lorsque cela est nécessaire.
Taux d’appariement
- Le taux des cas qui n’ont pas pu être couplés est un indicateur de qualité important;
- Le taux d’erreur pour le couplage probabiliste d’enregistrements est fourni.
Indicateurs de qualité pour les données sources
- Les données d’enquête et les données administratives utilisées comme statistiques officielles doivent être conformes aux normes de qualité. Les autres données administratives sont couplées et fournies « telles quelles » aux utilisateurs.
Comparaison des couplages avec les données historiques et les autres données
- La cohérence avec les autres processus de collecte de données (interne et externe) ainsi que le respect des cadres statistiques;
- Les résultats provenant de couplages distincts sont comparés aux fins d’uniformité. Les résultats obtenus aux niveaux méso et macro sont comparés avec d’autres résultats pertinents.
Une approche globale du couplage probabiliste
L’une des organisations adopte une approche très globale du couplage probabiliste. Les détails de cette approche, comme ils sont écrits dans le questionnaire, sont les suivants :
- Le type de variables utilisées dans le couplage sert d’indicateur de qualité – un « couplage or » utilise des noms et des adresses, un « couplage argent » utilise des noms et des adresses chiffrées et un « couplage bronze » n’utilise pas de noms et d’adresses, bien que la géographique statistique soit utilisée.
- On a recours à deux types de comparaisons pour évaluer la qualité du couplage. La première approche est une comparaison entre les données historiques et les couplages actuels. La deuxième approche consiste à comparer les « couplages bronze » et les autres couplages de qualité inférieure avec les normes des « couplages or », si possible. Cette approche présume que le fichier du « couplage or » ne contient pas d’appariements manquants ou faux (meilleure qualité). Les renseignements tirés de l’examen administratif permettent d’établir la qualité du couplage, comme suit :
- la qualité des appariements, en ce qui concerne l’accord sur les champs de couplage;
- le nombre d’appariements examinés;
- la répartition des valeurs de pondération des appariements;
- le nombre d’appariements rejetés ou faux.
- La probabilité d’appariements manquants et faux est évaluée en utilisant le nombre d’autres solutions de couplage possibles et les renseignements contenus dans les probabilités m et u de la règle Fellegi-Sunter.
- Les renseignements sur lesquels les enregistrements convergent ou divergent, c.-à-d. la proportion d’appariements qui sont entièrement en accord avec les champs de couplage comme la date de naissance, le sexe, une petite région géographique, le statut d’autochtone, etc.
- Le nombre d’appariements qui ont des valeurs contradictoires ou illogiques pour les champs de couplage de l’âge, de la date de naissance, du sexe, du nombre d’enfants nés, du pays de naissance, de la religion, de la langue parlée, de l’appartenance ancestrale, etc.
- La qualité de la stratégie de blocage et d’appariement est évaluée en fonction des occasions successives, complètes et stratégiques de couplage d’enregistrements qu’elle fournit et de son impartialité aux fins de diffusion.
V. Conclusion
Ce rapport a trouvé que les agences de la Statistique qui ont été contactées étaient toutes engagées dans des activités de couplage d’enregistrements et utilisaient des approches méthodologiques similaires. Cependant, les règles d’accès et le processus d’approbation pour les couplages d’enregistrements varient d’une agence à l’autre, en particulier en ce qui concerne la condition pour le consentement des répondants (certains pays exigent le consentement pour procéder avec le couplage d’enregistrements, d’autres pas).
Références
Antoni, M. and Seth, S. (2012). ‘’ALWA-ADIAB- Linked Individuel Survey and Administrative Data for Substantive and Methodological Research”. Schmollers Jahrbuch, Journal of Applied Social Science Studies, vol. 132(1), pp. 141-146.
Antoni, M. (2011). “Linking survey data with administrative employment data: The case of the German ALWA survey”. Working paper [http://www.cros-portal.eu/content/linking-survey-data-administrative-employment-data-case-german-alwa-survey-manfred-antoni]
Baldwin, J. R., Dupuy, R, and Penner, W. (1992). “Development of longitudinal panel data from business register: the Canadian Experience”, Statistical Journal of the United Nations, vol. 9, pp. 289-303.
Baxer, R., Christen, P., and Churches, T. (2003). “A Comparison of fast blocking methods for Record Linkage” In ACM SIGKDD’03 workshop on Data Cleaning, Record Linkage and Object Consideration, Washington DC., pp. 25-27.
Beste, J. (2011). Selektivitütsprozesse bei der Verknüpfung von Befragungs- mit Prozessdaten. Record Linkage mit Daten des Panels “Arbeitsmarkt und soziale Sicherung” und administrative Data der Bundesagentur für Arbeit FDZ Methodenreport 09/2011 (DE).
Christen, P. (2012a). “A Survey of Indexing Techniques for Scalable Record Linkage and Deduplication”. IEEE Transactions on Knowledge and Data Engineering, vol. 24, pp.1537-1555.
Christen, P., (2012b). “Data Matching. Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection”, Springer.
Cibella, N., Scannapieco, M., Tosco, L., Tuoto, T. and Valentino, L. (2012). “Record Linkage with RELAIS: Experiences and Challenges.” Estadistica Espanola, vol. 54 (179), pp. 311-328.
Eurostat, (2013). “ESSnet projects, 2013 assessment report”. Methodologies and Working Papers, Cat. No KS-RA-12-019-EN-N; ISBN 978-92-79-29622-2.
Fellegi, I. P. and Sunter, A. B. (1969). “A Theory for Record Linkage” Journal of the American Statistical Association, vol. 64, pp. 1183-1210.
Fellegi, I. P. (1999). ‘’Record Linkage and Public Policy: A Dynamic Evolution” in Record Linkage Techniques 1997, Washington, DC: National Academy Press, pp, 3-12.
Guiver, T., (2011), “Sampling-Based Clerical Review Methods in Probabilistic Linking”, Methodology Research Papers, Cat. no. 1351.0.55.034, Australian Bureau of Statistics, Canberra.
Hagsten, E., Polder, M., Bartelsman, E., Awano, G and Kotnik, P. (2012). “ESSnet on Linking of Microdata on ICT Usage”. November 2012, Final report. Statistiska centralbyran. Statistics Sweden.
Hartmann, J. and Krug, G. (2009). “Verknüpfung von personenbezogenen Prozess- und Befragungsdaten-Selektivität durch fehlende Zustimmung der Belfragen?” In Zeitschrift fur Arbeitsmarkforschung, vol. 42(2), pp. 121-139.
Herzog, T., Scheuren, F. and Winkler, W. (2007). Data Quality and Record Linkage Techniques. Springer.
Jonas, J., and Harper, J. (2006). “ Effective counterterrorism and Limited Role of Perspective Data Mining” Policy Analysis, vol. 584, pp. 1-11.
Konold, M. and Assainato (2009). “Matchning Business Data from Different Sources: The case of the KombiFiD-Project in Germany”, Conference ‘New Techniques and Technologies for Statistics (NTTS 2009), Brussels.
Larsen, M. D. (2006). ‘’Record Linkage, Nondisclosure, Counterterrorism and Statistics”. SSC Annual Meeting.
Newcombe, H., Kennedy, J., Axford, S., James, A. (1959).“Automatic Linkage of Vital Records.” Science, vol. 130(3381), pp. 954-959.
Newcombe, H. and Kennedy, J. (1962).“Record Linkage: Making Maximum Use of the Descriminating Power of Identifying Information” Communications of the ACM vol. 5(11), pp. 563-566.
Newcombe, H., Fair, M. E. and Lalonde, P. (1992).“The Use of Names for Linkaging Personal Records” Journal of the American Statistical Association, vol. 87, pp. 1193-1208.
OECD, (2012). “Unleashing the potential of business microdata. The ESSlimit project and beyond: international cooperation to produce new indicators and analyses”. Working Party Indicators for the Information Society, DSTI/ICCP/IIS (2012)3.
Rollin, A-M. (2013). Developing a longitudinal structure for the National Accounts Longitudinal Microdata File (NALMF). Proceedings of Statistics Canada Symposium 2013.
Schnell, R., Bachteler, T. and Bender, S. (2004). “A Toolbox for Record Linkage”, Australian Journal of Statistics, vol. 33(1&2), pp. 125-133.
Statistique Canada (1985). Loi sur la Statistique (L.R.C.1985, Ch.S-19. Lien site web: (http://laws-lois.justice.gc.ca/fra/lois/S-19/TexteComplet.html)
Statistique Canada (2011). Directives sur le couplage d’enregistrements link1 dans le texteDirectives sur le couplage d’enregistrements. Lien Site web: (http://www.statcan.gc.ca/eng/record/policy4-1)
Statistics New Zealand (2012a). “Data Integration Policy”. Wellington: Statistics New Zealand ISBN 978-0-478-37787-3 (online)
Statistics New Zealand (2012b). “Data Integration Manual”. Wellington: Statistics New Zealand ISBN 0-478-26971-4 (online)
Statistics New Zealand (2012c). “Integrated Data Infrastructure extension: Privacy impact assessment”. Wellington: Statistics New Zealand. ISBN 978-0-478-40840-9 (online)
Su, W., Wang, J. and Lochovsky, F. H. (2009). “ Record Matching Over Query Results from Multiple Web Database” IEEE Transactions on Knowledge and Data Engineering, vol. 22, pp. 579-589.
Vogel, A. and Wagner,J. (2012). “The Quality of the KombiFiD- Sample of Business Services Enterprises: Evidence from a Replication Study”. Working Paper Series in Economics N.226. University of Lüneburg.
Winkler W. E. (1999). “The State of Record Linkage and Current Research Problems”. Statistical Research Division, U.S. Bureau of the Census. Washington, DC.
Annexe A
Définition de vie privée et la confidentialité
Vie privée : droit de se retirer et de ne pas être sujet à une quelconque forme de surveillance ou d’intrusion. Lorsqu’ils choisissent d’« envahir » la vie privée d’une personne, les gouvernements ont des obligations relativement à la collecte, à l’utilisation, à la divulgation et à la conservation des renseignements personnels. Le terme vie privée réfère généralement à des renseignements concernant des particuliers.
Confidentialité : protection contre la divulgation de renseignements personnels identifiables concernant une personne, une entreprise ou une organisation. La confidentialité suppose une relation de « confiance » entre le fournisseur de renseignements et l’organisation qui les recueille; cette relation s’appuie sur l’assurance que ces renseignements ne seront pas divulgués sans l’autorisation de la personne ou sans l’autorité législative appropriée.
Source : Statistique Canada. Politique sur la protection des renseignements personnels et la confidentialité (6 janvier 2012).
- Date de modification :