What you should know

Archived Content
Information identified as archived is provided for reference, research or recordkeeping purposes. It is not subject to the Government of Canada Web Standards and has not been altered or updated since it was archived. Please "contact us" to request a format other than those available.
In addition to provincial detail, many of the tables present estimates for 20 of the largest Census Metropolitan Areas (CMAs), as follows: St. John's N.L., Halifax, Quebec, Montreal, Sherbrooke, Ottawa-Gatineau, Toronto, Oshawa, St. Catharines-Niagara, Hamilton, Kitchener, London, Windsor, Winnipeg, Regina, Saskatoon, Calgary, Edmonton, Vancouver, and Victoria. Due to sample size limitations and sampling variability, estimates for CMAs are less reliable and are subject to larger errors than provincial and national estimates. Given the variability of the annual estimates, users are cautioned against drawing conclusions from comparisons of estimates alone without considering quality indicators.
All income estimates are expressed in constant 2009 dollars to factor in inflation and allow comparisons across time in real terms.
A. Cell suppression and reliability of small data cells
B. SLID population estimates
C. Missing values for characteristics other than income
D. Symbols
E. Low income gaps and other low income statistics
A. Cell suppression and reliability of small data cells
Cell suppression has been applied to the tables as necessary to take into account the lower reliability of data for smaller sample sizes. (Refer to the "Methodology" section for more information on suppression and data quality). In certain cases, particularly where the geographic area covered is small in terms of population or where any other characteristic used to define the population is rare, this results in small sample sizes and as a result, the reliability of the statistic may be too low to publish. Suitable rules of reliability were used to screen the data.
In a few table views, the number of suppressed data points may make the entire table view somewhat unusable. While the tables could have been designed to eliminate certain categories or dimensions from the outset, this would most likely mean simultaneously eliminating some usable content. Instead, the approach has been to include all views of the table (no elimination of any categories of any dimensions), and rely on cell-by-cell data suppression to screen data that are not reliable.
B. SLID population estimates
The 900 series "Background tables" provide SLID population estimates of the number of individuals and economic/census families for Canada, provinces and selected CMAs. Users should be aware that these SLID estimates differ from official Statistics Canada population estimates. Unlike official population estimates, there are many segments of the population that are not included in the SLID survey, including residents of the Yukon, the Northwest Territories and Nunavut, residents of institutions and persons living on Indian reserves. Overall, these exclusions amount to less than three percent of the population.
C. Missing values for characteristics other than income
Both SLID and the SCF have complete data on all respondents for age, sex, family relationships and income characteristics. However, only the SCF has complete data without missing values for all labour market characteristics and education since the SCF was conducted as a supplement to the Labour Force Survey, which provided the base labour data entirely edited and imputed. To the extent that there are missing values in a dimension, identified as the category "unknown", there could be an undercount in any or all of the other categories.
D. Symbols
The following standard symbols are used in Statistics Canada publications:
. not available for any reference period
.. not available for a specific reference period
... not applicable
0 true zero or a value rounded to zero
0s value rounded to 0 (zero) where there is a meaningful distinction between true zero and the value that was rounded
p preliminary
r revised
x suppressed to meet the confidentiality requirements of the Statistics Act
E use with caution
F too unreliable to be published
E. Low income gaps and other low income statistics
Income in Canada was revised in June 2010 in order to present a more comprehensive view of the complex issue of low income. With the release of the 2008 Survey of Labour and Income Dynamics (SLID), important changes were introduced into the methodology behind the calculation of low income statistics. While the rationale for these were provided in the 2008 SLID Overview and other documents (see references at the end of this note), impacts of these changes on various statistics are not obvious.
E.1 Changes and rationale
Statistics on low income are produced based on three complementary measures (Statistics Canada, Low Income Lines, 2008-2009): the Low Income Cut-offs (LICOs), the Low Income Measures (LIMs) and the Market Basket Measure (MBM). (The Market Basket Measure was developed by Human Resources and Skills Development Canada.) Though these measures differ from one another, they give a generally consistent picture of low income status over time (Zhang, 2010). Each measure contributes its own perspective and its own strengths to the study of low income, so that cumulatively, the three provide a more complete picture of the phenomenon of low income.
In addition, the unit of analysis was changed. While, the determination of the low income status is still performed using family income (for the LICOs and the MBM) or household income (for the LIMs), low income statistics are calculated over the population of individuals. Because the various low income lines use different family concepts, it makes sense to perform the analysis at the person level. What is more, this change is directly in line with the recommendations of the Canberra Group on Household Income Statistics and is consistent with Statistics Canada's guidelines regarding analysis of income distribution. Because it is essential to portray the low income situation for the entire population, it is more appropriate to analyze individuals than families. In this way, the statistics are not distorted by variations in the size of families in the various groups of interest. But this new approach does not prevent anyone from studying low income according to family characteristics. For example, instead of talking about the incidence of low income in elderly families, we can talk about the incidence of low income among individuals who live in elderly families.
As a complement, some new statistics were introduced. In addition to the number and percentage of persons below a certain cut-off, users will also find two new measures: a micro-level low income gap expressed as a percentage of a given cut-off, and a macro-level (aggregate) gap expressed as a percentage of a relevant aggregate income. The micro-level measure is calculated for each family or household and is more aligned with international standards set by the Organisation for Economic Co-operation and Development (OECD, 2006). The macro-level one is an index that attempts to link the aggregated gap of low income with the overall population income. It provides a measure of the extent of low income relative to the total income of households, and replaces the similar statistics previously calculated over the population of families. This last point is further discussed later on.
The last change introduced is related to the family equivalence factor used in the MBM and the LIM. From now on, adjusted family income is obtained by dividing family income by the square root of the number of members in the family. The estimates for past years have been revised accordingly. With respect to the LIM, the square root of the number of persons in the household will be used.
E.2 Calculation of low income gaps
For each of the low income lines, five different statistics are presented in Income in Canada:
- Number of persons below the low income line
- Percentage of persons below the low income line
- Average gap ratio
- Median gap ratio
- Aggregate low income gap expressed as a percentage of income
While the first two are fairly straightforward, the measures relating to the gaps are more complex. The gap ratio is defined as follow:
Let J be the total number of families in the population and let ![]() be the income of the jth family1.
be the income of the jth family1.
Let ![]() be the low income line associated with the jth family.
be the low income line associated with the jth family.
The gap ratio for the ith person in the jth family is given by:
![]()
One can see that within a family, every member has the same gap ratio. The average gap ratio is given by:
![]()
Where ![]() is the number of persons in family j and
is the number of persons in family j and ![]() is the total number of persons in the population with family income below the low income line2. This can be interpreted as: on average low income persons have a family income that is 100
is the total number of persons in the population with family income below the low income line2. This can be interpreted as: on average low income persons have a family income that is 100![]() % of the low income line. The median gap ratio is calculated over the same population of individuals with family income below the low income lines.
% of the low income line. The median gap ratio is calculated over the same population of individuals with family income below the low income lines.
Finally, the aggregate gap is the sum of all individual gaps expressed as a percentage of the overall population appropriate total income:
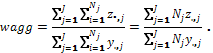
One can see that the average gap ratio, the median gap ratio and the aggregate gap are calculated over the population of individuals rather than families or households.
The aggregate gap is now the ratio of the weighted sum of the family (or household) gap and the weighted sum of the income, where the weight is the size of the family. (This weight has nothing to do with the sample weight which is ignored here for the sake of simplicity.) This approach is consistent with the decision to produce low income statistics at the person level.
In the past, the Income in Canada series provided an aggregated gap in dollar figure and a relative aggregate gap calculated as follows:
![]()
![]()
where ![]() is the family market income.
is the family market income.
There is no simple relation between wagg and the aggregated total income, as well as the relative aggregate gap calculated as before, and here is why. If one applies wagg to the total income to derive the old relative aggregate gap one gets:
![]()
Notice that wagg and relg are the same only in the case of unattached individuals. Because there is no simple relation between wagg and relg, users of Income in Canada cannot derive the relative aggregated gap as previously disseminated. However, relg can be produced on request by the Client Services of Income Statistics Division which can be contacted at income@statcan.gc.ca.
The wagg statistic represents a measure of the individual experience of depth of low income, and as such is comparable across all low income lines. On the other hand, the relg is often interpreted as a measure of how much money would be required to move all persons and families to the low income line, assuming that such an investment would indeed have a perfect impact. Of course, due to the relative nature of low income lines, a perfect impact is not possible. Note that the relative aggregate gaps, in any form, is not a statistic used internationally.
With the redesign of the Survey of Labour and Income Dynamics, the complete 202 Series on CANSIM and Income in Canada will be reviewed. With respect to low income statistics, it is planned to move one final step further toward complete coherence with the OECD standards. To this end, the analysis at the person level will be based on an adjusted family (or household) income that accounts for the size of the family and the economy of scale associated with larger families. Note that such an approach has already been introduced with the release of the 2008 reference year in the calculation of quintiles and gini coefficients. These can be found in Tables 202-0706 to 202-0709.
Reference
Foster, Greer, Thorebecke (1984), "A Class of Decomposable Poverty Measures", Econometrica, Vol. 52, No. 3 (May, 1984), pp. 761-766.
Murphy, Brian, X. Zhang and C. Dionne. (2010) "Revising Statistics Canada's Low Income Measures", Statistics Canada, Income Research Paper Series, 75F0002MIE
Organisation for Economic Co-operation and Development (OECD), 2006. Terms of reference of OECD project on the distribution of household incomes 2005/06 wave.
Podoluk, J. R. (1967), "Income of Canadians", 1961 Census Monograph Program, Dominion Bureau of Statistics.
Skuterud, M., M. Frenette and P. Poon (2004) "Describing the Distribution of Income: Guidelines for Effective Analysis", Statistics Canada, Income Research Paper Series, 75F0002MIE2004010.
Statistics Canada. 2010. "Low Income Lines, 2008–2009". Income Research Paper Series. 75F0002MIE www.statcan.gc.ca/bsolc/olc-cel/olc-cel?catno=75F0002MWE2010005
Survey of Labour and Income Dynamics (SLID) – A 2008 Survey Overview
THE CANBERRA GROUP (2001) Expert Group on Household Income Statistics. Final Report and Recommendations (PDF, 1 Mo), Ottawa : 200 p.
Zhang, Xuelin. 2010. "Low Income Measurement in Canada: What Do Different Lines and Indexes Tell Us?" Statistics Canada. Income Research Paper Series 75F0002MIE
Notes:
1. When the low income line used is the LICO or the LIM before-tax (after-tax), the income concept used is the total income (after-tax income). In the case of the MBM, the concept used is the MBM disposable income. Further, in the case of the before or after-tax LIM, the micro-level of aggregation (j) is the household and not the family.
2. As opposed, the FGT index (Foster, Greer and Thorbeck, 1984) calculates the average over the whole population. With the coming redesign of the Survey of labour and Income Dynamics, the FGT index concept will be used.
- Date modified: