Appendix C
Multivariate modeling of properties of trajectories of transition to retirement

Archived Content
Information identified as archived is provided for reference, research or recordkeeping purposes. It is not subject to the Government of Canada Web Standards and has not been altered or updated since it was archived. Please "contact us" to request a format other than those available.
Introduction
The dependent variable
The underlying theory about processes generating the speed of closure of a trajectory
Structure of the models used
Selected predictor variables
Results
Bibliography
Introduction
Eight properties of trajectories of transition to retirement were introduced in Appendix A. For each property an indicator can be devised to measure the level or position of a trajectory relative to the property. Using this indicator it is possible to generate a distribution of trajectories over the levels of the property. Based on hypotheses concerning the forces that shape that distribution, it is possible to model the probability that a person's trajectory will be within a given subset of the levels of the indicator. For example, it is possible to model the probability that speed of closure will be fast.1
In developing Chapters 15 and 16 we modeled predicted probabilities for four of the eight properties of trajectories: speed of closure, fl exibility of the work-to-retirement transition, exposure to events that increase vulnerability to reduced standard of living in retirement, and propensity to return to the labour market after leaving it. Data are presented in these chapters only for categories of the predictor variable that was the focus of attention in each chapter. The purpose of this appendix is to present some of the models that generated those results, and provide data for some of the other predictor variables.
An important point about the purpose and context of development of these models needs to be indicated here. The context is that of the quasi-experiment where there is a focus of interest in the association of a specifi c variable upon a deemed dependent variable. In this context, other variables in the models should be regarded as being there because of the experimenter's effort to create statistical controls. As a result several issues that must be addressed in a serious effort to understand why the distribution of a dependent variable takes on a specific shape can be acknowledged as relevant for this study; but not of such priority as to require being addressed now. Also, because of the said context, we can avoid a systematic effort to formulate and underlying theory about the forces that shape that distribution. It is sufficient to have good reason for including a variable in the model, for the purposes of statistical control, without having fi rst articulated at a theoretical level what that reason happens to be. We can, for example, simply point to the work of other researchers as support for inclusion of specifi c variables in the model.2
Originally it was planned to organize this appendix into four sections, each one devoted to one of the specifi c properties of trajectories listed above. However, shortage of space and time lead to the necessity to present the modeling work for only one property that received greatest focus in the main text - speed of closure. For this property, the text below presents information concerning aspects of the underlying theory about the processes that determine a respondent's speed of closure, the mathematical structure of the model, defi nitions of key variables used, a review of goodness of fit and of the relative importance of the predictor variables as contributors to the goodness of fit, and these predictor variables' patterns of association with the dependent variables (more properly called "predictands" in the context of prediction logic, which is that of our work - see Hildebrand, Laing and Rosenthal 1977). However, the presentation on each sub-topic will need to be brief, due to space limitations.
In presenting the defi nitions of variables, we will not repeat information already provided carefully in Chapters 15 and 16 or Appendix B. The text below will provide only additional information needed for reasonable completeness in presenting the models.
The dependent variable
Initially speed of closure is measured in terms of 16 categories based on the four quarters of each year, covering the period 1998 to 2001 (see Appendix A). Later these were collapsed into four broad categories, and these four have been used in the multivariate analysis. They are:
- closure during or before the first three quarters of 1998 is termed "fast" closure,
- closure between the last quarter of 1998 and the first quarter of 2000 is termed "moderately fast",
- closure between the second quarter of 2000 and the third quarter of 2001 is termed "slow",
- unclosed trajectories are termed "very slow".
The underlying theory about processes generating the speed of closure of a trajectory
At the individual level we postulate that the speed of closure is the outcome of three processes. These apply to individuals with probabilities that vary from one person to the next. They are:
- constrained choosing to reach goals (for example, see Parker and Rougier 2004),
- negotiating or adjusting in response to behaviour changes made by significant others in the person's social network (see Rasmusen 1995, Lin 2003), and
- coping with major intrusive events and their consequences (see Ma and Zhang 2004, Clark et al. 2004).
Processes in class A have been the subject of much theoretical literature and mathematical models, mostly dealing with the maximization of a lifetime consumption utility function subject to budget constraints. Essentially, the models predict that individuals will choose to retire at the age where the function is maximized.
It is possible to write down a mathematical model that takes into account all the three processes A, B and C. However, the component that applies to each process needs to include the probability that a person will be exposed to that process. Such an individual-level probability is essentially not estimable, since it requires multiple observations of behaviours by the same person.
A practical model is estimable only for a sample of persons. In demography, we would regard the distribution that it generates as a set of group-specific rates. In the case of this work, the model would predict how a cohort of persons will be distributed among a set of alternative speeds of closure. The cohort would be limited to those judged to have begun their transitions to retirement in time period t. Their distribution over alternative speeds of closure would be assessed at a later time period t + n.
Structure of the models used
Since these speeds comprise a discrete variable with rankordered categories, ordinal regression is an appropriate strategy. From the alternative formulations of ordinal regression models (see Hosmer and Lemshow 2003:288 to 292), we initially chose one readily available in SAS with a wide variety of outputs useful for interpreting the results - the proportional odds model. However, because a key assumption of this model is violated seriously with our data, we supplement this model with a set of nested submodels, each of which is an ordinary binary logistic model. This set is so defined that aggregating across its log-likelihood and chisquare statistics produces the values very similar to those shown from the proportional (or cumulative logit) odds model (see Friendly 1991 for related discussion).
Suppose there are N + 1 categories of the response variable (in the case of speed of closure N + 1 = 4). Let "P(Y<=j|x)" mean the probability that the response will be at level j or lower. The logit for the proportional odds model is defi ned as ln[ P(Y<=j|x) / P(Y>j|x) ]; a ratio of two conditional probabilities, where x represents a vector of conditions.
The model is specified as a set of equations:
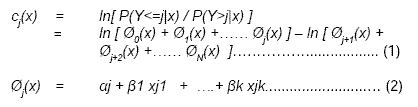
where j = 1,2,.,N
Notice that in equation (2) it is assumed that the coefficient ß is independent of j -- this is the proportional odds assumption. The explanatory variables (xj1, xj2, ., xjk, where j represents the jth category of the response variable ) along with their estimated parameter values predict the logit defi ned in expression (1), and from it conditional probabilities are derived. The model is estimated by the maximum likelihood method in the SAS PROC LOGISTIC procedure, using the "clogit" option on the MODEL command.
Notice also that j ranges over a set of values, each one representing a level of the response variable. It may be useful to visualize that what we really have is a set of logits, as defined by equation (1):
{ cj(x) } j = 1, 2, ., N
Assuming that the parameters are independent of the response level (the proportional odds assumption) may lead to misleading parameter estimates, or at least they may hide a lot of valuable information and be very hard to interpret. Thus a test of this assumption has been devised - called the "Score test" and its value is generated in SAS's PROC LOGISTIC procedure.
The Score test of the proportional odds assumption is a test of the null hypothesis that the corresponding coeffi cients at each level of response are equal. When the p-value associated with the Score statistic is very low, e.g. < 0.05 or less, the proportional odds assumption is untenable. Our models consistently had p-values far below 0.05.
Because SAS PROC LOGISTIC has a wide array of useful output tables (unlike SAS CATMOD, for example) we decided to continue using the proportional odds model (called the "full model" in the tables below). To gain information about patterns of values of parameter estimates at different levels of the response variable j, information that is not available under the proportional odds assumption, we added a set of nested binary models. Aggregates of chi-square statistics for the nested models are very similar to corresponding statistics in the full model; while individual nested models give us parameters and odds ratios that are sensitive to the pertinent response levels, and are much more easily interpreted than those of the full model.
A good way to exposit our augmentation of the proportional odds model (a procedure outlined by Friendly 1991) using nested binary models is with a concrete example. In the case of speed of closure there are three nested models. The logits for these models, each of which is a standard binary logistic model, are as follows (the numbers within the parentheses represent levels of the speedof-closure variable):
1 ln[ P( Y=2|x ) / P( Y=(1 or 3 or 4)|x) ]
2 ln[ P( Y=3|x ) / P( Y=(1or 4)|x) ]
3 ln[ P( Y=1|x ) / P( Y=(4)|x) ]
They are said to be "nested" because of their applicable network of sub-samples
- for no. 1, it is the whole sample
- for no. 2, it is the whole sample less those who have level 2 of speed of closure
- for no. 3, it is only those who have either level 1 or level 4 of speed of closure.
Here we have chosen the logits so that there is one that compares two very important response categories - fast closure versus no closure, the third logit listed above. This is called the "key nested model" in the main text, and a review of the tables for the sub-models confi rm that the vast bulk of 'explanatory power' in the overall model is coming from that key nested sub-model.
In short, our overall model is comprised of an augmented proportional odds ordinal regression model, with the augmentation comprising a set of nested sub-models whose chi-squares aggregate to values very similar to those of the full model.
Selected predictor variables
Due to space limitation, the text that follows covers only a selection of the full set of predictor variables. Readers who need more details concerning the defi nitions of the variables are invited to contact the authors.
Two-year class of worker
As the reader will recall, two separate two-year class-ofworker variables were the primary focuses of attention in the chapters 15 and 16where small portions of the results of modeling effort are presented. These variables have already been defined at a conceptual level in detail in those chapters. We add below only a few remarks about their usage in the context of the modeling work.
In the model that focused on self-employment (Chapter 15), we used one dummy variable. It has the value 1 for those that were self-employed during 1996 and 1997 or those who moved from that category into being employed in 1997, instead of being limited to those who were self-employed in both years. This was done to increase sub-sample size and thereby improve the reliability of parameter estimates. It was a reasonable step because those who switched from being self-employed in 1996 to being employed in 1997 showed patterns of association with speed of closure that were very similar to those that were self-employed in both years.
In the model focused on the public sector (Chapter 16) a five-level categorical variable was used. All levels take into account respondents' statuses in both 1996 and 1997. These levels have already been defi ned in Chapter 16 (see Table 16.1). The reference category for the multivariate analysis comprised those who were in the labour force in 1996 but were outside of it in 1997.
As noted above, the class-of-worker variable was the 'experimental variable', all others being treated as control variables. Below we present some of the latter, the ones that entailed notable conceptual innovation undertaken for this study. Some of these have complex defi nitions at the level of programming, and readers who would like to study these defi nitions are invited to contact the authors.
Caring responsibility
Family caring responsibilities, especially their sudden increase, is considered a key factor in explaining timing of retirement, notably among women, as Chapters 10 to 13 have emphasized. SLID does not provide information to allow direct measurement of the presence and level of those responsibilities. However, a rough indirect indicator is possible. For the model, we used the indicator to identify whether there was such an increase in the year just before the person began closing her trajectory.
A number of SLID variables refl ect the presence of the said responsibilities. We combined them into one indicator using judgment-based weights as follows:
- If a person's major activity is caring for other family members then a value of 2 was added to the person's score for the caring variable.
- If a person had a disabled member in the family then the caring variable was increased by a value of 0.5.
- If a person was living with one or more of his children then the caring variable is assigned a value of 0.5.
- If a person's parent joined the family then the person was assigned a value of 0.025 for the caring variable.
We then defi ned a dummy variable that refl ects increase in care burden. It has the value 1 if the person's score on the care variable increased over two consecutive years just before the year when she began closing her trajectory. The technical definitions of these variables are in Appendix B.
Index of spousal retirement
The retirement-related behaviour of the spouse or partner is increasingly being recognized to be a powerful factor in explaining persons' retirement timing, as Chapter 11 and 12 have emphasized. SLID does not identify the spouse/partner or her attributes directly. However, there are a number of variables that allow one to make inferences about employment and income reception by a second member of a household, and we have only to ascertain that there is an economic family in that household to be able to infer with high probability that the person is a spouse/partner.
For our model, we constructed a variable that, in effect, makes an inference as to whether, over a two-year period, there has been an increase in the number of household members receiving retirement-related income. Such an increase would point to spouse/partner having taken a key retirement-related decision.
We defi ned a dummy variable in this connection, and its value is 1 only when that increase took place in the year just before the respondent began closing her trajectory. The technical definitions of all these variables are in Appendix B.
Cultural group
Cultural background can be expected to have some influence on the timing of retirement in terms of its influence upon tastes and of the presence of a family tradition concerning retirement-related behaviour. Also, it may be an important index of broad social or institutional forces that create different retirement related opportunities or incentives for persons, depending on the perceived cultural heritage. However, there is little effort to measure this variable in retirement-related studies, though some in the USA have featured a break-down of their samples into White, Black and Hispanic.
For our model, we use a fi ve-level categorical variable. Its detailed definition has already been given in Appendix B.
Health
The impact of health status upon the timing of retirement has been the subject of several articles - see, for example, Bound et al. 1998. It has been found important to distinguish between the possible influence of health status at a point in time, and changes (especially deterioration) between two time points. A severe setback in health could lead an individual to retire. If there is a gradual deterioration in an individual's health then the individual might choose to retire.
The measurement of health, however, presents a number of issues. The common health measures that have been used to model retirement are self-reported health status, presence of acute or chronic health condition, activities of daily living. Their relative merits have been discussed in the literature (e.g., Bound et al. 1998), and research findings suggest that the key factor here, as regards retirement timing, is a change of health status.
In our model, we focus on change of health status, based upon five categories of self-reported health status: excellent, very good, good, fair and poor. We ascertained whether from one year to the next there was a self-reported deterioration of health status. However, we constructed a dummy variable whose value is 1 only when the deterioration took place in or just before the year that the person began closing her trajectory.
Wealth
Theoretical work and model fitting about the timing of retirement are perhaps most extensively focused on two aspects of wealth - wealth accumulated at a point in time (including the value of pension rights, if they exist), and the potential accrual to wealth from working for pay one additional year. Several key articles on these variables and related theories have been published - see especially Stock and Wise 1990, Samwich 1998, Parker and Rougier 2004, Hatcher 2002, Quinn 1977, Burtless and Moffit 1985, Gustman and Steinmeier 2002.
Various aspects of wealth at a point of time have been the subject of attention - for example, fi nancial wealth (Burtless and Moffit 1985), and pension and social security wealth (Quinn 1977).
Parker and Rougier (2004) compute a comprehensive measure of lifetime wealth to estimate its impact on retirement. They used the data from the British Retirement Survey. The components of this variable are: housing and fi nancial wealth, capitalized values of state pension, private and occupational pension entitlements, future expected earnings, expected future business resale values.
Such sophisticated measurement of wealth is not possible from the data in SLID. The best that can be done is to devise a proxy for wealth ranking in broad categories, rather than an estimated of wealth level. Also, our index implies dividing the population into two broad classes - homeowners versus others. Each class then has its own ranking. Putting these rankings together into one categorical variable implies that we have created a partially ranked set of wealth-related classes. Drawing upon these categories, we have created two dummy variables for use in the model.
The first is an indicator of high wealth rank among homeowners. It has the value 1 when all of the following are true: the home is owned, the level of household income is in the highest quartile, and income sources include one or more of wages and salaries, investment income or private pension income.
The second dummy variable focuses on non-homeowners, and is in fact a household-income index. It is valued 1 when household income is above the fi rst quartile. Its primary function is to isolate the non-homeowners that have very low income, and thus probably low wealth.
As noted above, perhaps more important (for explaining the timing of retirement) than wealth at a point in time is the issue of whether one more year of work will add to wealth sufficiently to make work worthwhile from a fi nancial viewpoint. Much effort has been placed on modeling the retirement decision as if people retire when the marginal benefit of working another year equals marginal cost (Hatcher 2002). This notion leads to focus upon a widely discussed "accrual variable" - the incremental value from deferring retirement for another period (see Stock and Wise 1990, Samwich 1998, Gustman and Steinmeier 2002). Measuring this variable correctly requires knowing details of the pertinent pension and social security program rules as they apply to each survey respondent - data not collected in SLID.
It should be noted that for the self-employed and for others where pension-income rights are not major, focusing on accruals arising from social security and pension rules may not be especially useful. There is a growing consensus that there will be a strong rise over future years in the proportion of pre-retirees who have no or negligible rights to employment pension-income (see Chapters 6, 19 and 20). Increasingly, retirement research must address the situations of people without claims to substantial work-related pensions or conventionally defined career jobs.
In any event, we are forced, based on data from SLID, to construct a very crude proxy for the accrual variable. It is a dummy variable based on reported personal-income change in the year just before the one in which the person closed her trajectory. The variable is valued at 1 when there was at least a 10% increase in personal income after taxes over the two-year period that preceded the one in which closure began.
Our underlying hypothesis, in devising this variable, is that such increases in income tend to be absent when trajectories are being closed. However, this is probably a meaningful variable primarily for workers with pension plans whose benefits are minor or with no pension plans. For those with pension plans, both theory and research fi ndings indicate that what matters is the accrual of pension wealth that would come from working an additional year. As noted above, there is no way to measure this important variable with SLID data.
Pension eligibility
There is considerable evidence that pension eligibility is a key factor in the timing of retirement. For related discussion, see Honig and Hanoc 1985, Burtless and Mofitt 1985, and Fuchs 1982. Our model measures pension eligibility with a dummy variable. This is valued at 1 when the person either has a pension plan in her main job for the year in question, or is employed in the public administration industry, or has one of the following occupations: Senior Management Occupations, Natural and Applied Sciences and Related Occupations, Professional Occupations in Health, Nurse Supervisors and Registered Nurses, Occupations in Social Science, Government Service and Religion, Teachers and Professors, and Machine Operators and Assemblers in Manufacturing, including Supervisors.
Clearly, this variable does not measure the onset of eligibility to receive income from a pension scheme, which involves a change variable of some kind. Our measure considers only the presence of pension eligibility at a point of time. As noted above in connection with the wealth accrual variable, this change variable may be much more pertinent in studies of the timing of retirement decisions.
However, because pension eligibility is greatly determined by one's sector of employment, we really require a more sophisticated model than that whose results are shown below. In those results, the dependence of pension eligibility upon class of worker is not taken into account. Ideally, we would design two- or-more steps of computations so to allow this and other causal interdependences among the predictor variables to be taken into account.
Work history
The literature contains some focus on the issue of whether a person's work history has been marked by disruptions, especially where women's retirement is being studied. It is thought that as women tend to have disrupted work history, this will have an impact on their speeds of closure.
Our focus in dealing with work history is on a measure of how standard it was. A 'fully standard' work history is one where close to 100% of the jobs held were full-time jobs. As one moves away from this degree of commitment of working time to full-time jobs, we consider work history to have been less and less standard.
Our work history variable involves defi ning a work history ratio. This is the ratio of (a) the number of years a person has worked for full-time for at least six months within the year to (b) the total number of years since she fi rst worked full time.
Values for this ratio were then grouped into four classes, based on studying its distribution among women. For about 25 per cent of women transiting to retirement the work history ratio was below 0.85, while for another 25 per cent it was below 1.00. Based on this distribution a three-level categorical variable was devised: those with work history ratio below 0.85, those with work history ratio between 0.85 and below 1.00, and those for whom the ratio was 1.00 or more. For the detailed defi nition see Appendix B.
Results
The goodness of fit of the adopted model is adequate. It achieves a nearly 20% reduction in the error of prediction of the null hypothesis model. (100 * (3118.71 - 2515.35) / 3118.71) - see Table C.1). Another measure of goodness of fit is the value of 0.35 for tau-a, a pseudo R-square statistic.
Table C.1
Goodness of fit of models that predict speed of closure of trajectories of transition to retirement, Canada, 1998 to 2001
However, the reasonably good fit is the result of the presence of age among the predictor variables, as Table C.2 shows. If the variables in Table C.2 had been mutually independent, the relative size of each Wald statistic to the total would be a good index of the relative statistical importance of each variable in accounting for the overall goodness of fit.
However, in these data the relative sizes of the Wald statistics are only approximate indicators; because there is intercorrelation among some of the predictor variables. A more accurate gauge of the variables' relative importance would involve proposing a theory of the network of causal links among the predictor variables, and a related redesign of the computational steps so as to respect the hierarchy of causal priority among the predictor variables. (See the foregoing comments about the causal link flowing from class of worker to pension eligibility.)
Thus the network of numbers shown here is essentially provisional relative to an approach that involves specifying the structural equations that would correspond to a suitable causal model. Let us review some of these provisional results, keeping in mind the context of a quasi-experiment cited above. The data in the first two columns arose when we were examining whether the difference between being self-employed and being employed had a substantial statistical impact on the odds of having an unclosed trajectory (Chapter 15). The data in the last two columns arose when we were examining whether the corresponding difference between public sector and private sector employment (Chapter 16). The pertinent variables are shown on the last two lines of Table C.2.
Table C.2
Relative contributions of predictor variables to goodness of fit of models that predict speed of closure of trajectories, Canada, 1998 to 2001
The variable that reflects class of worker (for Chapter 15 see the second-to-last line of Table C.2, and for Chapter 16 see the last line of Table C.2) is the second most important (statistically) of the predictors, after age. And this is so even though we failed to allow its parameter to refl ect the variable's causal linkage and priority relative to pension eligibility, work history and wealth. However, the consequent defl ation of its statistical impact may be offset by the fact that this variable is causally posterior to education and occupation. Most of these variables have substantial Wald chi-squares and have been found to be useful as explanatory factors in other studies of the timing of retirement.
Also important, in terms of contribution to the model's goodness of fit, are cultural group, and whether another economic family member began receiving retirement related income in the year before closure of the trajectory began. These are also variables found to be useful as explanatory factors in other studies of retirement patterns.
It is notable that the indicated relative contribution of sex to the model is negligible. This could be a result of having several variables in the model that are causally posterior to sex, and our failure to take these causal links into account by way of structural equation model.
The dominance of age is worthy of a further comment. Several articles reporting similar dominance of age in the timing of retirement leave the reader with the image that this is a pure "demographic effect" flowing from chronological age. On the contrary, we must not forget that systemic forces arising from culture and institutional rules target specifi c chronological ages in such a way that it is inevitable that this age variable is partially reflecting them, as well as any pure demographic effect. It is, therefore, important to do a good deal of the modeling within more narrow age groups (as was illustrated in Chapter 16), unless the model contains variables that allow one to remove from age the influence of these "environment and policy factors".
The data in Table C.2 arise from the full model described above. As already noted, when its proportional odds assumption fails the parameter estimates are very hard to interpret, and consequently we added a set of nested binary models where this problem does not exist. Table C.3 provides the same kind of information as Table C.2; but for the three nested sub-models in the case of the work done for Chapter 15 (where class of worker is represented by the dummy variable named "Self-employed"). The 2-log-likelihood statistics and chi-squares from these sub-models should add, except for rounding, to those of the full model, which we just showed (Table C.2).
Table C.3
Odds ratios for predictor variables in the key sub-model pertaining to speed of closure, Canada, 1998 to 2001
Among the sub-model, one is dominant in the sense that its Wald chi-squares are the major contributors to those of the full model (shown in Table C.2 ). We call this the "key sub-model", and here it is the one in column D. This column is based upon a logit that contrasts fast closure with non-closure. After the hugely dominant statistical effect of age, strong contributions are coming from class of worker (represented by the dummy variable "Self-employed in 1996"), occupation, work history, wealth, cultural group, education, and whether another economic family member began receiving retirement-related income in the year before closure began.
Tables C.2 and C.3 allow us to address the relative statistical importance of the different predictors in the model's goodness of fit. What about the patterns of partial association3 of specific categories of these variables with speed of closure? This kind of information is given in the odds ratios shown in Table C.4.
Table C.4 allows us to see the directions of partial association for the categories of variables in the key sub-model. In this model we instructed PROC LOGISTIC to predict the probability of having an unclosed trajectory, relative to that of closing rapidly (that is, in or before the fi rst three of the 16 quarters of observation). For example, persons aged 45 to 54 in 1996 were many times more likely than those aged 60 to 69 to have such trajectories. However, at the level of detail shown in this table, careful attention to the Wald chi-squares is in order (see note 2 to the table).
Table C.4
Odds ratios for predictor variables in teh key sub-model pertaining to speed of closure, Canada, 1998 to 2001
Those with a high value on the scale of home-ownerbased wealth are much less likely than average to have unclosed trajectories - far more likely to have closed their trajectories. In contrast, those with only moderate levels of non-homeowner wealth (they are not home owners) are far more likely than average to have unclosed trajectories - i.e., delayed retirement. This pattern is consistent with the widely reported wealth effect on the timing of retirement, although we recall that our wealth measures are crude proxies.
Relative to immigrants who arrived before 1959, all the other cultural groups are much less likely to have unclosed trajectories, and especially the native-born Francophone group. However, only for the Francophone group (defined in Appendix B) is the Wald chisquare substantial, indicating a stable estimate.
Finally, among the categories of the class of worker variable, the one that stands out is being self-employed. The self-employed are far more likely than the reference category to have unclosed trajectories - i.e., to have delayed retirement.
It is tempting to close this review with a discussion of what this network of patterns implies about predicting speed of closure. However, it is best to await the use of a structural equation model that suitably takes into account the causal linkages among the predictor variables.
Bibliography
Bound, J., M. Schoenbaum , T.R. Stinebrickner et T. Waidman. 1998. The Dynamic Effects of Health on the Labor Force Transitions on Older Workers. Working Paper 6777.
Burtless, G. et R. Moffitt. 1985. "The joint choice of retirement age and post retirement hours of work." Journal of Labor Economics. 3, 2:209 to 236.
Clark, P.M. et al. 2004. "A model to estimate the lifetime health outcomes of patients with Type 2 diabetes: The United Kingdom Prospective Diabetes Study (UKPDS) Outcomes Model (UKPDSno. 68)." Diabetologia. 47, 10:1747 to 1759.
Friendly, M. 1991. Visualizing Categorical Data. Cary, NC. SAS Institute Inc.
Fuchs, V. R. 1982. "Self-employment and labor force participation of older males." The Journal of Human Resources. 17, 3: 339 to 357.
Gustman, A.L. et T.L. Steinmeier. 2002. The Social Security Early Entitlement Age in a Structure Model of Retirement and Wealth. Working paper 9183. Cambridge, MA. National Bureau of Economic Research.
Hatcher, C.B. 2002. "Wealth, reservation wealth, and the decision to retire." Journal of Family and Economic Issues. 23, 2:167 to 187.
Hildebrand, David K., James D. Laing et Howard Rosenthal. 1977. Prediction Analysis of Cross Classifications. New York. Wiley.
Honig, M. et G. Hanoch. 1985. "Partial retirement a separate mode of retirement behaviour." Journal of Human Resources. 20:21-46.
Hosmer, D.W. et S. Lemeshow. 2003. Applied Logistic Regression. Hoboken, NJ. Wiley & Sons, Inc.
Lin, Raymund J. 2003. Bilateral Multi-Issue Negotiation.
Ma, Xin et Yanhong Zhang. 2004. A National Assessment of Effects of School Experiences on Health Outcomes and Behaviours of Children: Technical Report.
Parker S. C. et J. Rougier. 2004. The Retirement Behaviour of the Self-Employed in Britain. Working paper in Economics and Finance No. 04/08. Durham. University of Durham, School of Economics, Finance and Business.
Quinn, J. F. 1977. "Microeconomic determinants of early retirement: A cross-sectional view of white married men." The Journal of Human Resources. 12, 3, Summer: 329 to 346.
Rasmusen, Eric. 1995. A Model of Negotiation, Not Bargaining.
Samwick, A.A. 1998. "New evidence on pensions, social security, and the timing of retirement." Journal of Public Economics. 70:207 to 236.
Stock, J.H. et D.A. Wise. 1990. "Pensions, the option value of work, and retirement." Econometrica. 58:1151 to 1180.
Notes
- The phrase "model the probability" means that the probability is represented as a function of a selection of predictor variables (also called "explanatory variables" and "independent variables") and associated coefficients (also called "parameters). When we have estimates for the parameters, we can identify combinations of values of the predictor variables where the probability of fast closure is above a chosen value, such as 0.25.
- It is notable that the vast majority of articles that present modeling results concerning aspects of retirement are lacking in comprehensive theories that rationalize their selections of more than a small subset of variables, and use very brief and informal argumentation and references to the work of other researchers when they attempt to justify the inclusion of particular variables in a model. Moreover, it is common to fi nd no justifi cation given for including any more than a small fraction of the variables used in a model.
- "Partial association" refers to the fact that several variables are held constant statistically in the process of measuring the association, via the odds ratios.
- Date modified: