
Demographic Documents
Comparison of Place of Residence between the T1 Family File and the Census: Evaluation using record linkage

Archived Content
Information identified as archived is provided for reference, research or recordkeeping purposes. It is not subject to the Government of Canada Web Standards and has not been altered or updated since it was archived. Please "contact us" to request a format other than those available.
by Julien Bérard-Chagnon
Highlights
- Consistency of place of residence between tax data and census data is relatively high:
- The province or territory of residence is the same in the tax data and in the census for more than 99% of the persons matched.
- However, the level of consistency decreases for smaller geographic levels:
- The postal code is the same in the tax data and in the census for 92.9% of the persons matched.
- Consistency of postal code also varies from one region to another:
- In census metropolitan areas, it tends to be lower in central areas and higher in outlying areas.
- Several characteristics are closely associated with lower consistency of postal code:
- People who live in a collective dwelling, people who reported having moved in the 2011 National Household Survey, young adults, very elderly people, and people whose tax return was prepared by a third party (according to box 490 of the tax form), are especially likely not to have their postal code correspond with their tax-data postal code.
- The difference between the reference date for tax data and that for the census is likely to affect consistency of postal code.
Introduction
Home is where the heart is.
- -Pliny the Elder
Tax data are being used increasingly to measure and analyze the population and its characteristics. These data serve not only to support statistical processes such as surveys, but also to develop statistical and analytical products. For example, tax data are used to produce estimates of internal migration, which, in turn, are used calculate official population estimates. Tax data are also used to construct two databases commonly used by analysts and researchers, the Longitudinal Administrative Databank (LAD) and the Longitudinal Immigration Database (IMDB).
While this approach considerably reduces data production costs and Canadians’ response burden, it also poses a number of challenges. One of the main challenges concerns differences in how place of residence is defined. Various statistical programs, including the census and population estimates and projections, use the concept of usual place of residence, whereas tax data give the mailing address of taxfilers.
The concept of place of residence is fundamental to the study of demography. Most of the statistical indicators used to shed light on key socioeconomic issues rely on the ability of data sources to put people in the “right place”. A number of studies address the problems of determining the place of residence with certainty for particular segments of the population, including children in joint custody, residents of collective dwellings, interprovincial workers, and students who alternate between their place of study and the family home (National Research Council 2006; Laporte et al. 2012; Turcotte 2013). Conceptual differences in the place of residence can substantially affect the comparability of files and, as a result, impact the consistency of statistics and the interpretation of results.
The use of tax data to study the population is likely to continue increasing in the future given the expanded use of record linkages and the higher volume of statistical information made available to Statistics Canada.Note 1 At the same time, social trajectories are becoming more complex, which is making it more difficult to determine the place of residence for a number of demographic groups. In these circumstances, comparing tax data with other sources of demographic data is increasingly relevant. Using record linkage, this study examines the effect of differences in how place of residence is defined in tax data and census data.
The main objectives of this study are to:
- compare the concept of residence in tax data and in census data;
- examine consistency of place of residence between tax data and census data for a few geographic levels of interest;
- identify the main characteristics associated with consistency of place of residence.
1. Concepts of place of residence
While it may appear simple at first glance, the concept of place of residence is highly complex. Although most of the population is able to determine its place of residence with a high degree of certainty, this information is more difficult to establish for persons who have more than one residence. For example, some students and children in joint custody have more than one home and regularly alternate between them. Homeless persons by definition have no place of residence. Some individuals may see their place of residence not as the place where they spend the most time, but rather as the place with which they maintain the strongest economic or social ties. This can apply to workers who, for professional reasons, reside elsewhere than in the family home for much of the year.
Conceptual differences in how various sources of demographic data treat the place of residence were brought to the fore in the United States in the context of creating the American Community Survey (ACS), which replaced the long form of the U.S. census in the mid-2000s. The U.S. census uses the usual place of residence for enumerating the population. The ACS adds the condition that the person must live in that place for at least two months for it to be considered the usual place of residence. This additional condition can affect the comparability of the data calculated through the ACS, especially for highly mobile populations (Scardamalia 2014). While the U.S. Census Bureau noted these conceptual differences (U.S. Census Bureau 2004), the committee of experts, responsible for studying the rules of residence for the U.S. census, recommended that a question on usual place of residence be included in the ACS. This would allow for further exploration of the effect of conceptual differences between that survey and the census (National Research Council 2006: 265).
In Canada, a number of studies have compared tax data with census data at aggregated levels. They showed, among other things, that the coverage provided by tax data could vary, sometimes considerably, according to the characteristics of taxfilers (Bérard‑Chagnon 2008; He and Michalowski 2005). A comparison of several data sources used for the study of mobility also highlighted the probable effect of different definitions of migration on the numbers of migrants calculated on the basis of these sources (Vamderkamp and Grant 1988).
However, to our knowledge, very few Canadian studies have dealt directly with the issue of the consistency of the place of residence between these two data sources. Using record linkage, Bérard-Chagnon and Brennan (2014) found that more than 85% of linked persons had the same postal code in data from the Canada Child Tax Benefit (CCTB)Note 2 program and the census data. That study also highlighted the much lower level of consistency for CCTB recipients who had moved during the year, as well as a lag of a few months in updating postal codes for the CCTB. In general, that analysis suggests that there could be sizable differences between tax data and census data regarding place of residence.
1.1. Concept of usual place of residence in the census
There is no standard definition of place of residence. This concept changes from one source to another according to the main use of the data. These conceptual differences can mean that a given individual is not listed as having the same place of residence from one source to another. This is especially likely to be the case for individuals whose place of residence is more difficult to determine.
The section of the 2011 Census questionnaire on place of residence is shown in the figure below.

Description for Figure 1
This figures shows the section of the 2A questionnaire for the 2011 Census on usual place of residence.
Canadian censuses use a de jure concept of residence.Note 3 Consequently, the address refers to the usual place of residence, which is defined as the dwelling in Canada in which a person lives most of the time.Note 4 This approach is necessary for the proper planning of community services, such as schools and public transit, for the allocation of funds to the different levels of government, and for the redistribution of electoral districts.
However, the concept of residence is not clear for all situations in life. The census form includes rules for cases in which the usual place of residence is harder to determine.Note 5 For example, students who come back to live with their parents during school breaks must be enumerated in the family home, even if they spend much of the year elsewhere. These specifications make it clear that determining the place of residence can be complex for some groups. In fact, the problems encountered in accurately determining the place of residence are one of the main sources of coverage error in censuses (Statistics Canada 2015b).
1.2. Concept of mailing address in tax data
The figure below shows the sections of the T1 tax return dealing with the place of residence. In the tax data, taxfilers must report three things in connection with their place of residence: their mailing address, their province or territory of residence on December 31 of the taxation year, and their province or territory of residence at the time of filing if it is different from the one in the mailing address. The mailing address is required so that the Canada Revenue Agency (CRA) can contact the taxfiler. Accordingly, the address is not intended to determine where the taxfiler lives most of the time, but rather the place at which to reach him or her efficiently. Taxfilers can even give a mailing address that is not their place of residence. This could, for example, be the case with a young adult who has just left the parental home and for whom the family home continues to be the anchor for managing his or her tax returns.
Also, some situations specific to taxation can affect taxfilers’ place of residence. Some taxfilers have their tax return prepared by an accountant or a family member, who might give his or her own mailing address instead of the taxfiler’s. Similarly, the method of creating the T1 Family File (T1FF), the fiscal file used in this study, puts CCTB children in the home of the taxfiler who is receiving the benefits,Note 6 which is not necessarily the child’s actual place of residence.

Description for Figure 2
This figure shows the sections of the 2014 T1 tax form on the taxfiler’s address.
2. Data used
A number of studies have compared tax data with census data. However, since these studies use mostly aggregated totals, many factors, including the coverage of the files, can interact together to explain the differences observed between the different sources. The innovative aspect of the present study is that it uses record linkage between the 2010 T1FF tax data, sent by taxfilers in the spring of 2011, and the 2011 Census to directly compare individuals’ place of residence in the two sources. Instead of the T1 tax data, the T1FF was used for the linkage for two reasons. First, the more extensive coverage of the entire population in the T1FF provides a more complete picture of consistency with respect to place of residence. Second, different researchers and analysts already use the T1FF file extensively, especially for calculating official estimates of internal migration, constructing the LAD and the IMDB, and establishing economic dependency profiles at very fine geographic levels. Data from the 2011 National Household Survey were then added using existing linkage keys for this database and the census to take advantage of the characteristics of the population available in the NHS.
This chapter describes the data used in the present study. It begins with a brief introduction to the files that were linked. Next, it describes the linkage method used. It ends by providing the definition of place of residence followed in this study and describing the characteristics examined.
2.1. T1 Family File
The Income Statistics Division (ISD) has produced the T1FF annually at Statistics Canada since 1982, for the purpose of recreating Canada’s population and family universe. The ISD constructs the file by taking data on individuals who completed a T1 return of income for the reference year and combining those data with information on non-filing spouses and data on children from the CCTB, vital statistics, and a historical file. It then groups individuals into census families by means of a complex methodology.Note 7 This approach serves to create an annual file that covers approximately 95% of the Canadian population and contains basic tax and demographic information on the Canadian population (Bérard-Chagnon 2008).
2.2. Census and National Household Survey
Statistics Canada conducts the census of population in May every five years to develop a statistical portrait of Canada. The data are used not only to meet the requirements of various laws, but also to support decision making in a wide variety of very different fields, ranging from the planning of community services to the conduct of market studies. The short form, which collects basic demographic and linguistic data, is sent to all Canadian households. In 2011, the census long form was replaced by the NHS. This voluntary survey collected more detailed socioeconomic data, such as level of schooling, employment status, and place of birth. The NHS was administered to roughly 30% of households, targeted only private households, and obtained an unweighted response rate of 68.6%.
2.3. Record linkage
The study used proven techniques to link the T1FF data and the census data deterministically in five successive waves. The linkage was based on name, date of birth, sex, and family information.Note 8 Note that the study did not use geographic information as a linkage key so as not to bias the matching.Note 9 The following table shows the five waves and the numbers matched in each.
| Linkage wave | Persons linked | |
|---|---|---|
| number | percent | |
| 1) Exact match on sex, date of birth, and name for more than one family member |
12,697,283 | 68.2 |
| 2) Relaxed match on name | 542,169 | 2.9 |
| 3) Match on given name using Mix Match | 361,126 | 1.9 |
| 4) Match for at least three family members | 2,543,298 | 13.7 |
| 5) Unattached persons added | 2,656,730 | 14.3 |
| Duplicates removed | -177,125 | -1.0 |
| Total | 18,623,481 | 100.0 |
| Source : House, Georgina. 2014. The Linking Process, working document, Household Survey Methods Division, Statistics Canada, 1 page. | ||
The first wave consists of individuals for whom an exact match on sex, place of birth, and name is established for more than one family member. The majority of the linked individuals are from the first wave. Subsequently, in the second wave, the study uses SAS’s COMPGED function to relax linkage rules for the name.Note 10 Only individuals for whom a match was established for more than one family member are retained. The third wave uses Mix MatchNote 11 to establish a match on the given name. The rules in the fourth wave establish a match for families in which the sex and date of birth correspond for at least three members. Lastly, the fifth, and final, wave includes the matches made in the previous waves for unattached persons.
The matched file contains a total of 18,623,481 individuals, for a linkage rate of 57.0% of the population in the 2010 T1FF. This linkage rate is similar to the rates obtained for other linkages between tax data and census data when one excludes links created from geographical information. A comparison with another linkage between the 2010 T1FF and the 2011 Census, also conducted at Statistics Canada, showed a correspondence of approximately 97% in the matches created by the two linkages. Most of the unsuccessful matches were due to links created for twins where the linkage created a match with a different twin. This situation has a negligible effect, since it is quite reasonable to assume that twins live in the same place.
The matched T1FF–census file includes 3,991,431 observations after the NHS data are added.
The following table gives an overview of the quality of the match, showing the distributions for the T1FF, the census and the matched file on a few basic characteristics.
| Characteristic | 2010 T1FF | 2011 Census | Linkage |
|---|---|---|---|
| percent | |||
| Type of record in the T1FF | |||
| Living taxfiler | 78.0 | Note ...: not applicable | 75.7 |
| Imputed child / spouse | 21.8 | Note ...: not applicable | 24.1 |
| OtherTable 2 Note 1 | 0.3 | Note ...: not applicable | 0.2 |
| Age group | |||
| 0 to 17 years | 21.4 | 20.5 | 25.3 |
| 18 to 24 years | 8.9 | 9.1 | 8.5 |
| 25 to 39 years | 19.8 | 19.2 | 20.3 |
| 40 to 64 years | 35.5 | 35.6 | 35.7 |
| 65 years and older | 14.6 | 14.5 | 10.3 |
| MissingTable 2 Note 2 | 0.0 | 1.2 | 0.0 |
| Composition of census family | |||
| Married couple | 58.5 | Note ...: not applicable | 64.2 |
| Common-law couple | 13.9 | Note ...: not applicable | 13.9 |
| Lone-parent family | 10.8 | Note ...: not applicable | 7.7 |
| Person not in family | 16.9 | Note ...: not applicable | 14.3 |
... not applicable
|
|||
In general, the distributions of the characteristics studied here and observed in the matched file are, on the whole, faithful to those in the T1FF and the census. The matched file includes a slightly higher proportion of imputed children and spouses than the 2010 T1FF. This is because the linkage technique uses the relationships between family members to maximize the number of matched records. For the same reason, the matched file also includes a higher proportion of married couples and a lower proportion of persons aged 65 and older.
Of course, when interpreting the results of the linkage and making inferences to the population as a whole, one must keep in mind that the population in the matched file depends not only on the linkage rate but also on the presence of individuals in each of the two source files. Several studies have drawn attention to census undercoverage (Statistics Canada 2015b) and the incompleteness of tax data (Bérard-Chagnon 2008; Aydemir and Robinson 2006). In both cases, males in their twenties and immigrants are especially likely to not be enumerated or to not have completed a tax return. Therefore, the results presented in this study reflect only the situation of matched individuals and not that of the Canadian population as a whole. One should exercise great caution when making an inference to the entire population.
2.4. Definition of place of residence for the study
In this study, place of residence is defined according to the postal code. This decision is based on both the fact that a postal code is a very detailed geographic unit that approximates an individual’s actual place of residence, primarily in urban areas where most of the population resides,Note 12 and on the fact that there are problems involved in processing individuals’ complete addresses. A list of postal codes from the Postal Code Conversion Files (PCCF) were used to clean up postal codes in the matched file. According to this criterion, the postal codes of 95.9% of matched individuals are valid and could, therefore, be used in this study.Note 13 There is a match on place of residence when the postal code (or any other geographic level examined) in the T1FF is identical to the one in the census.
2.4.1. Difference in reference dates
An important point to consider is that there is a time lag between the reference date for T1FF tax data and the census reference date. Whereas Census Day in 2011 was May 10,Note 14 tax returns for the year 2010 contain taxfilers’ information dating from March or April 2011.Note 15 Furthermore, the geographic information that the CRA sent to Statistics Canada for purposes of constructing the T1FF was the most current information available to the CRA on December 31, 2011. That difference is likely to account for some of the inconsistencies observed in this report between the postal codes in the tax data and those in the census. For example, individuals who moved between Census Day and December 31, 2011, would naturally have a different place of residence in the two sources if they reported their move to the CRA, and if the CRA updated their mailing address in its databanks.
2.5. Characteristics used
When the information available in the T1FF, census and NHS files is combined, the result is a very rich database. Three criteria guided the search for characteristics likely to be associated with consistency of place of residence.Note 16
First, a number of individuals are in a situation in which their place of residence is more difficult to determine. Essentially, this can result from two factors: foremost, for some subpopulations, the place of residence is especially difficult to identify, both in the tax data and in the census. This is the case, for example, with persons who have a thirty party prepare their tax return. Additionally, some individuals maintain economic and social ties with more than one place of residence. This can mean that their mailing address differs from their usual place of residence. To target the characteristics associated with these situations, both the literatureNote 17 and experts at Statistics Canada were consulted. This criterion includes interprovincial workers, couples not living in the same household, and children in joint custody.
Second, Canadians are highly mobile. The NHS data show that more than one Canadian in ten changed his or her usual place of residence between 2010 and 2011. It is important to examine the effect of mobility on the consistency of one’s place of residence, for two reasons. While most of these moves are over a fairly short distance, they may nevertheless reflect a major transition in the mover’s life that involves creating and maintaining major ties with more than one place of residence for a given time. Given the difference between the reference dates for the two files examined in this study, and the extent to which the tax data are able to adequately capture moves, mobility is likely to be a major correlate of consistency of place of residence.Note 18 In addition to the NHS question that deals explicitly with mobility, this group of characteristics includes age, immigrant status, and being a renter.Note 19
Third, the methodology for constructing the T1FF and the linkage, as well as the choice of the postal code to approximate the place of residence, may also affect the consistency of the place of residence. Therefore, a few methodological variables, such as the wave in which the individual was added to the linkage, were also targeted for this study.
Examining these characteristics will make it possible to both identify the demographic groups for which the consistency of the postal code is lower and to better understand the mechanisms that underlie this situation.
3. Consistency of place of residence by geographic level
This chapter examines the consistency of place of residence in the T1FF and the census for different geographic levels of interest, namely postal code, forward sortation area (FSA),Note 20 census subdivision (CSD),Note 21 census division (CD),Note 22 census metropolitan area (CMA),Note 23 and province or territory. These geographic levels are obtained by geocoding postal codes by means of the PCCF for the T1FF and by going directly into the census databases.
The following chart illustrates the consistency between the T1FF and the census for different geographic levels.
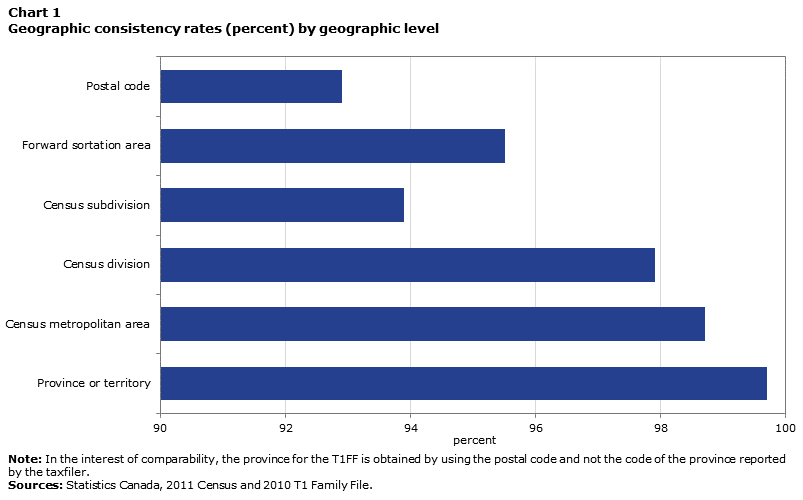
Description for Chart 1
| Geographic level | Percentage |
|---|---|
| Postal code | 92.9 |
| Forward sortation area | 95.5 |
| Census subdivision | 93.9 |
| Census division | 97.9 |
| Census metropolitan area | 98.7 |
| Province or territory | 99.7 |
|
Note: In the interest of comparability, the province for the T1FF is obtained by using the postal code and not the code of the province reported by the taxfiler. Sources: Statistics Canada, 2011 Census and 2010 T1 Family File. |
|
In general, the consistency of the place of residence between the tax data and the census data is relatively high: 92.9% of matched individuals have the same postal code in the T1FF and the census. The rate climbs to 95.5% for FSAs and to 93.9% for CSDs. The slightly lower consistency for CSDs than for FSAs may be explained by the fact that, while FSAs are a very fine geographic level in highly urban areas, they can extend over much larger areas than CSDs in the rest of Canada. Consistency is even greater for more aggregated geographic levels, approaching 98% for CDs and exceeding 99% at the provincial/territorial level. This means that practically all matched individuals indicated the same province or territory of residence in the two databases examined in this study.
These results suggest, then, that, while the place of residence recorded in the tax data may differ from the one reported in the census, the difference is evident mainly at very fine geographic levels. However, the fairly high levels of consistency seen here should not obscure two points. First, although 92.9% of matched individuals have the same postal code in the two sources, the corollary is that the postal codes do not match for 7.1% of the individuals in the linkage. If the matching results can be inferred to the population as a whole, nearly 2.5 million persons would not have indicated the same postal code in the census and the tax data. This number is equivalent to the population of the Vancouver CMA, the third-largest in Canada.
Second, there are sizable regional variations as to the consistency of the place of residence. The following chart shows these variations for the provinces and territories.
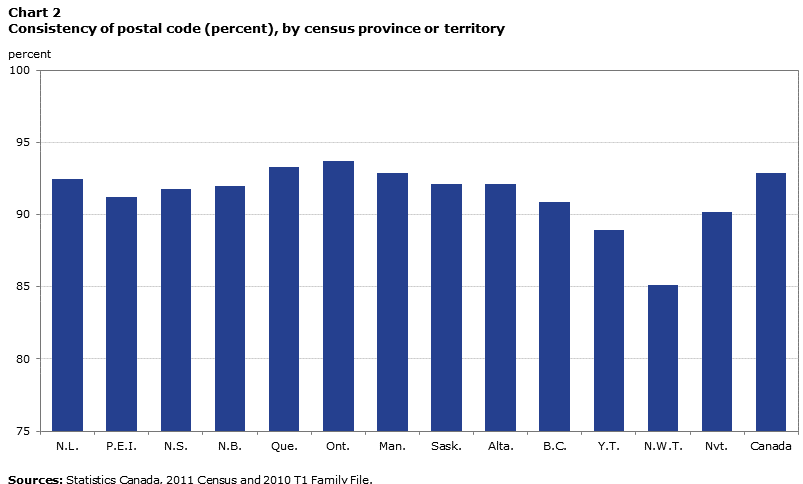
Description for Chart 2
| Region | Percentage |
|---|---|
| N.L. | 92.5 |
| P.E.I. | 91.2 |
| N.S. | 91.8 |
| N.B. | 92.0 |
| Que. | 93.3 |
| Ont. | 93.7 |
| Man. | 92.9 |
| Sask. | 92.1 |
| Alta. | 92.1 |
| B.C. | 90.9 |
| Y.T. | 88.9 |
| N.W.T. | 85.1 |
| Nvt. | 90.2 |
| Canada | 92.9 |
| Sources: Statistics Canada, 2011 Census and 2010 T1 Family File. | |
The consistency of the postal code is generally lower in the territories. It reaches a low of 85.1% in the Northwest Territories. This means that, for that territory, the postal codes of nearly 15 matched individuals in 100 are not the same in the census and the T1FF. In addition to being much less populous than the provinces, all three territories have a population that is generally more mobileNote 24 (Willbond 2014). In contrast, postal code consistency exceeds 93% in Ontario and Quebec.
Regional variations in consistency can also be seen at finer geographic levels. This is illustrated in Map 1, which shows the rates of consistency of postal code by census division.
Consistency of postal code ranges from 81.9% (Region 6 [N.W.T.]) to 96.9% (La Haute-Côte-Nord [Que.]). A total of 5 of the 293 CDs have a consistency rate below 85%, while 24 CDs have a rate exceeding 95%. Some CDs in rural areas tend to have lower consistency of postal code. In particular, the three CDs that show the lowest postal code consistency are Region 6 (N.W.T.), Stikine (B.C.), and Division No. 19 (Man.). In contrast, the CDs in some more urbanized areas generally have consistency levels exceeding 90%. Of course, some CDs with very low populations also have very high consistency levels that result from the effects associated with their small numbers of residents.
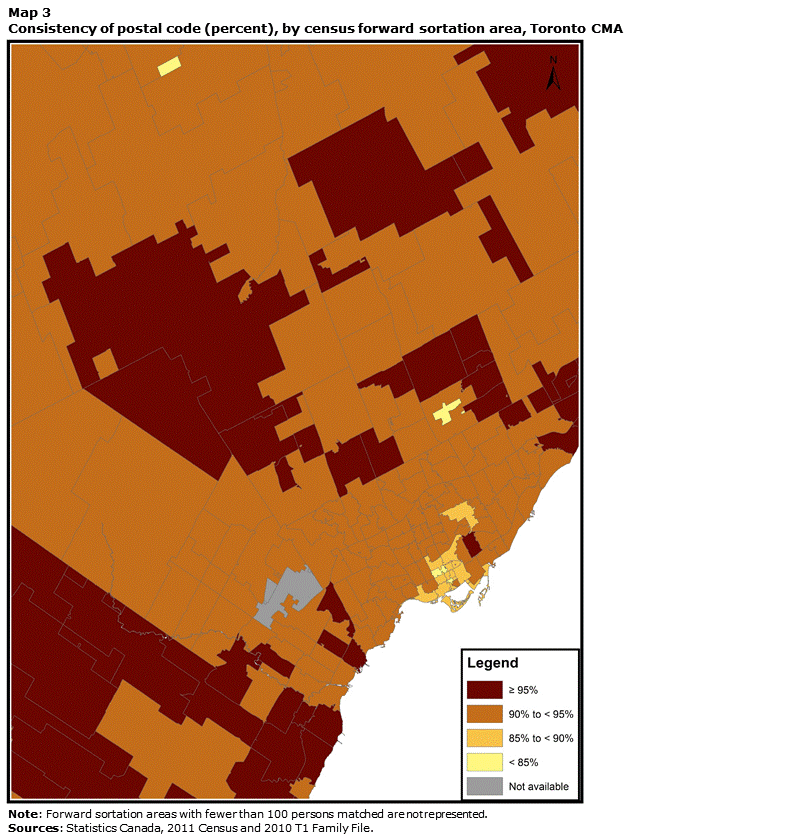
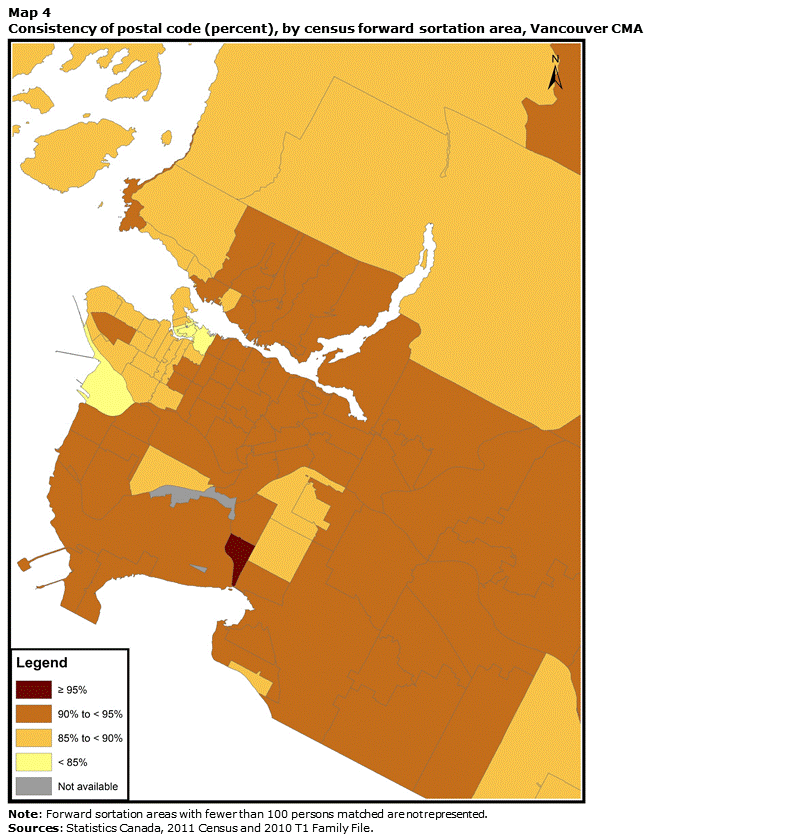
An examination of postal code consistency at the FSA level reveals a divide between metropolitan cores and outlying areas. Maps 2, 3 and 4 highlight this situation for Canada’s three most populous CMAs: Montréal, Toronto and Vancouver. For these three CMAs, consistency levels for linked individuals who live in the central FSAs tend to be below 90% and even reach 85%. Conversely, for the population living in a number of outlying FSAs, consistency levels exceed 95%. These differences may result from two phenomena. First, urban FSAs are generally much smaller in area than rural FSAs. Consequently, moving is very likely to involve a change of FSA. In the suburbs and in more rural areas, moving a short distance might not involve a change of FSA. Second, the characteristics of the population of central districts differ from those of the population of peripheral and rural areas: individuals living in highly urban settings tend to be younger and more mobile, and these two characteristics are closely associated with lower postal code consistency.Note 25
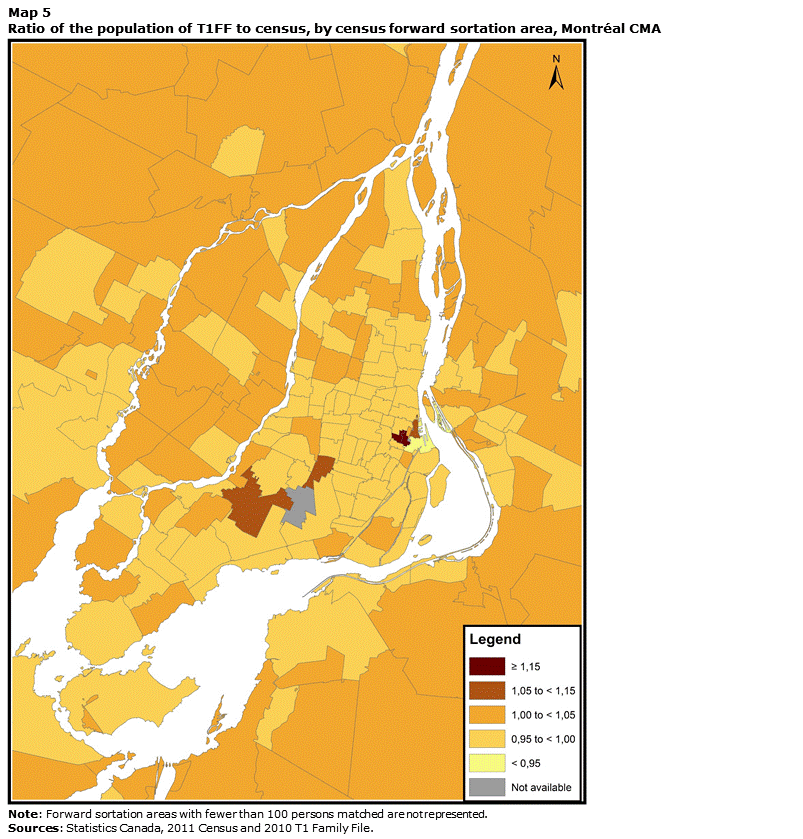
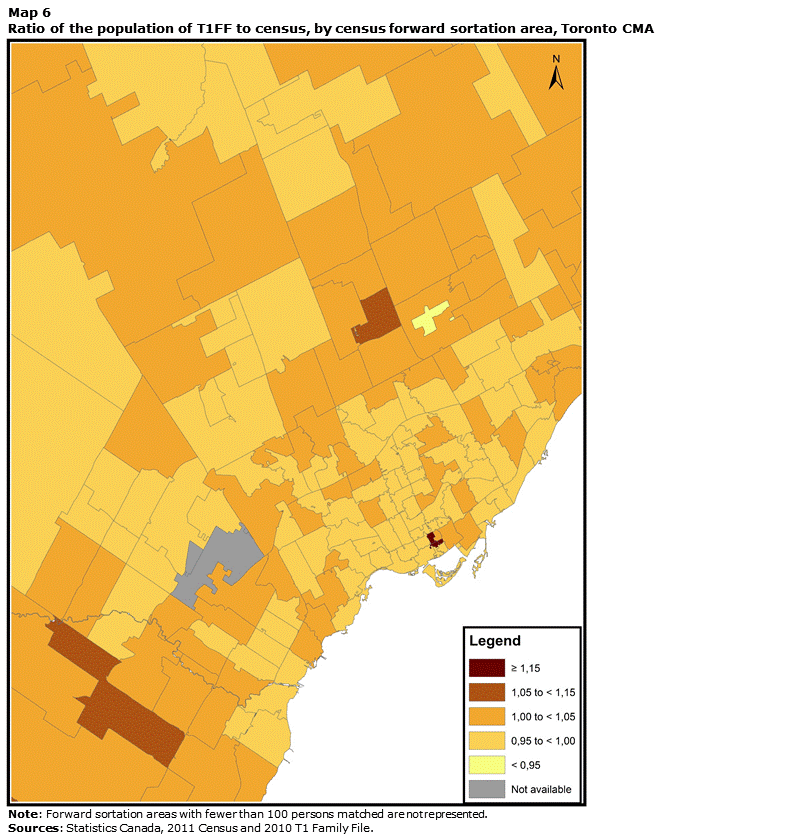
The main consequence of the differences in consistency levels is that the population of some FSAs varies considerably depending on the source examined. While the T1FF population ranges between 96% and 112% of the census population for 95% of FSAs, it is sometimes much higher or lower than the census population. Maps 5, 6 and 7 illustrate this situation. They show the ratio between the T1FF population and the census population for the Montréal, Toronto and Vancouver CMAs. In all three cases, the T1FF figure is very close to the census figure in the suburbs. However, in some central areas, the T1FF has much larger numbers than the census. In the Montréal CMA, the H3A and H3B FSAs are noteworthy. These two areas are located in downtown Montréal and have many office towers and financial institutions. Some tax filers might have a postal code that falls within these areas on their tax return because they have the return prepared by an accountant.Note 26 The H3B FSA also includes the headquarters of the Curateur public du Québec, which administers the tax files of some filers who are under curatorship. As a result, the T1FF contains more than 6,000 persons who reported a postal code in this FSA, whereas in the census this was the usual place of residence of barely more than 100 people.
The M5H, M5G and M5C FSAs, located in the Toronto CMA, as well as the V6C and V6E FSAs in Vancouver, also have a much larger population in the T1FF than in the census. The T1FF includes nearly three times as many individuals under the M5G FSA and more than four times the number of individuals within the M5H FSA. These FSAs are also located in downtown Toronto or Vancouver in districts that include a number of office towers.
Some sources yield contrasting numbers for some FSAs outside these CMAs as well. The FSAs of V8W (Victoria) and T5J (Edmonton) have a substantially higher population in the T1FF than in the census. Once again, both these FSAs are in downtown neighbourhoods. This confirms that the match between the numbers in the T1FF and those in the census is weaker in the downtowns of large cities.
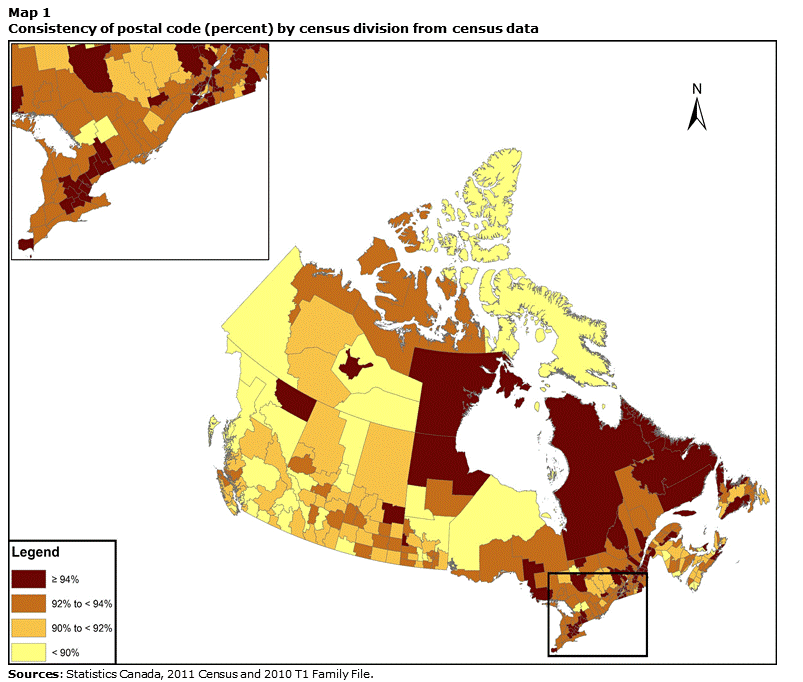
Description for Map 1
This map shows the consistency rate of postal code by census division for Canada. Consistency rates range from 81.9% in Region 6 (N.W.T.) to 96.9% in La-Haute-Côte-Nord (Que.). A total of 5 of the 293 CDs have a consistency rate below 85%, while 24 CDs have a rate exceeding 95%.
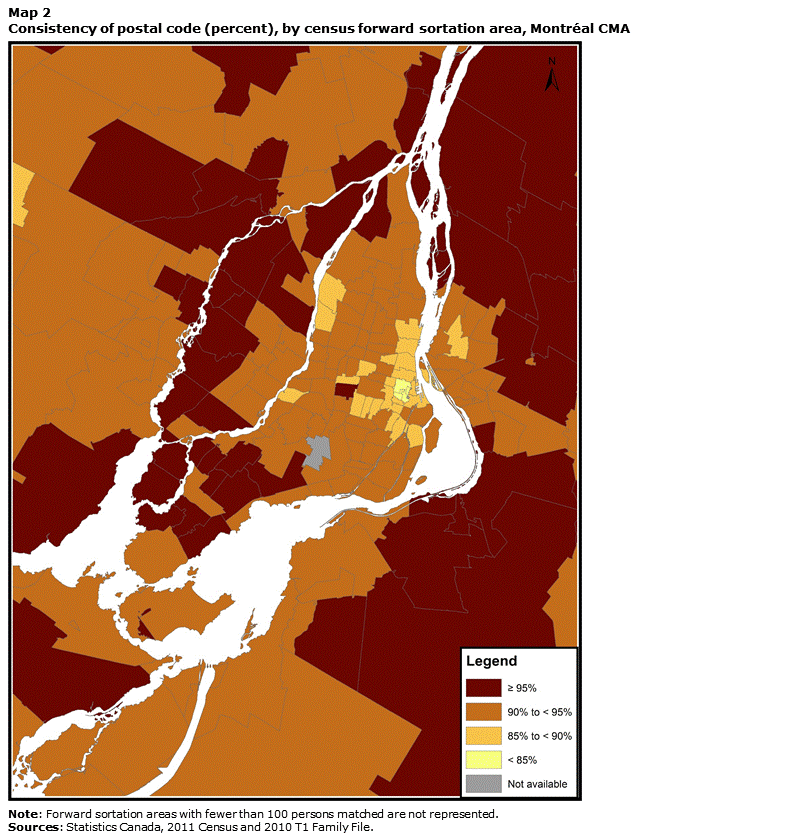
Description for Map 2
This map shows the consistency rate of postal code by forward sortation area for the Montréal census metropolitan area. Consistency levels for linked individuals who live in the central FSAs tend to be below 90% and even reach 85%. Conversely, for the population living in a number of outlying FSAs, consistency levels exceed 95%.
Description for Map 3
This map shows the consistency rate of postal code by forward sortation area for the Toronto census metropolitan area. Consistency levels for linked individuals who live in the central FSAs tend to be below 90% and even reach 85%. Conversely, for the population living in a number of outlying FSAs, consistency levels exceed 95%.
Description for Map 4
This map shows the consistency rate of postal code by forward sortation area for the Vancouver census metropolitan area. Consistency levels for linked individuals who live in the central FSAs tend to be below 90% and even reach 85%. Conversely, for the population living in a number of outlying FSAs, consistency levels exceed 95%.
Description for Map 5
This map shows the ratio of the population of T1FF to census by forward sortation area for the Montréal census metropolitan area. The T1FF figure is very close to the census figure in the suburbs. However, in some central areas, the T1FF has much larger numbers than the census. This is notably true for the H3A and H3B FSAs.
Description for Map 6
This map shows the ratio of the population of T1FF to census by forward sortation area for the Toronto census metropolitan area. The T1FF figure is very close to the census figure in the suburbs. However, in some central areas, the T1FF has much larger numbers than the census. This is notably true for the M5H, M5G and M5C FSAs.
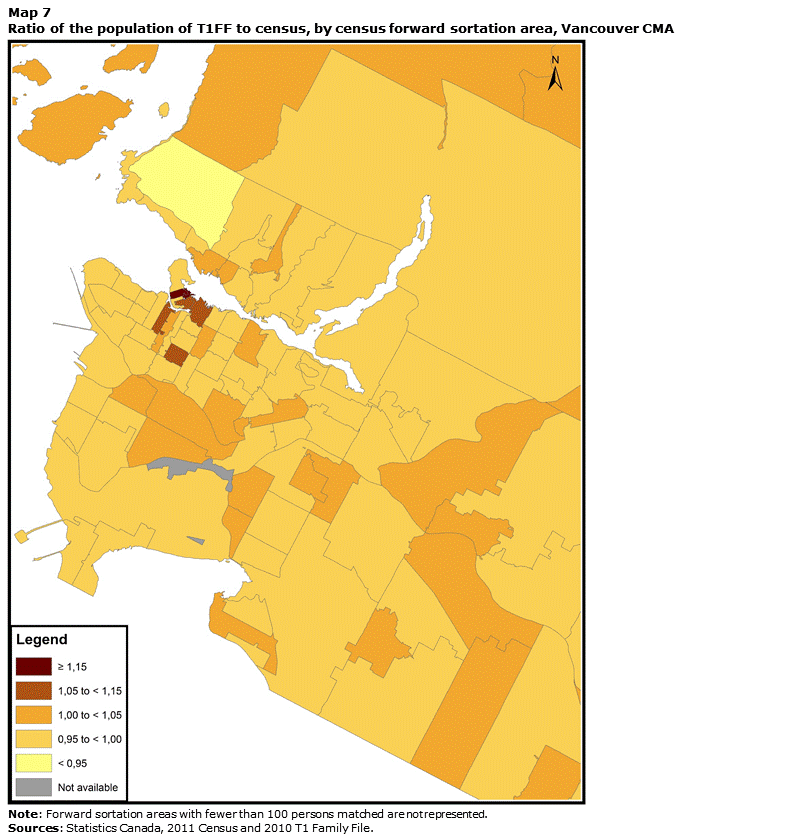
Description for Map 7
This map shows the ratio of the population of T1FF to census by forward sortation area for the Vancouver census metropolitan area. The T1FF figure is very close to the census figure in the suburbs. However, in some central areas, the T1FF has much larger numbers than the census. This is notably true for the V6C and V6E FSAs.
4. Consistency of postal code by individuals’ characteristics
The results examined in Chapter 3 revealed differences in the place of residence identified in tax data and the census. In some instances, they also showed substantial variations in the consistency of place of residence for different geographic levels. This chapter continues the evaluation, presenting levels of postal code consistency according to various characteristics of individuals. It gives the results for characteristics associated with more complex situations related to the usual place of residence, for characteristics relating to high mobility, and for methodological characteristics.
Start of text boxThis section incorporates the results from the National Household Survey (NHS), a voluntary survey that replaced the census long-form questionnaire in 2011. Three aspects of the NHS are relevant here: it was administered to roughly 30% of households; it did not cover collective dwellings; and its unweighted response rate was 68.6%. In comparison, the census was sent to all Canadian households, including collective dwellings, and covered more than 97% of the Canadian population. However, although these methodological differences affect postal code consistency, the effect is fairly small. The overall postal code consistency rate based on census data was 92.9%, and the rate based on the NHS was 94.1% the NHS. This difference is cut by half when the census figures are limited to private households (93.4%).
Given the study’s objectives and the linkage rate, the results drawn from the NHS presented are not weighted. It was considered more appropriate for each person included in the matched file to have the same weight for purposes of comparing postal codes.
To make the results easier to interpret, the study set the threshold for lower postal code consistency at 90%. Results for the characteristics not included here are provided in Table A.3 in the Appendix.
4.1. Consistency of postal code: Results for characteristics associated with the concept of place of residence
The following table shows the characteristics related to the concept of place of residence associated with lower postal code consistency.
| Characteristic | Distribution in matched file |
Consistency rate |
|---|---|---|
| percent | ||
| Overall | 100.0 | 92.9 |
| Return prepared by third party (box 490)Table 3 Note 1 | ||
| No | 99.4 | 93.2 |
| Yes | 0.6 | 32.8 |
| Living in a collective dwelling | ||
| Not living in a collective dwelling | 99.1 | 93.4 |
| Living in a collective dwelling | 0.9 | 31.4 |
| Province or territory of workTable 3 Note 2 | ||
| Same province or territory | 99.4 | 94.5 |
| Other province or territory | 0.6 | 89.4 |
| Presence of spouse in household | ||
| Spouse present | 99.5 | 95.0 |
| Spouse absent | 0.5 | 89.0 |
| Household on-reserve | ||
| No | 98.9 | 94.2 |
| Yes | 1.1 | 87.6 |
| Aboriginal identity | ||
| No Aboriginal identity | 96.3 | 94.2 |
| First Nations | 2.2 | 89.0 |
| Métis | 1.2 | 91.8 |
| Inuit | 0.2 | 93.9 |
| More than one Aboriginal identity | 0.1 | 92.6 |
|
||
An examination of the data in this table reveals several situations where conceptual differences between the postal code in the census and in the tax files could affect postal code consistency. First, consistency is very low (32.8%) for linked persons who had their tax return prepared by a third party (according to box 490). This is likely because tax preparers tend to put their own mailing address on the tax return, rather than that of the taxfiler. These people are usually very elderly: approximately 30% of persons who had their return prepared by a third party (according to box 490) were aged 80 and older, compared with less than 3% of the linked population.
Matched persons who live in a collective dwellingNote 27 also have a much lower consistency rate than the rest of the population (31.4%). The majority of people residing in collective dwellings are very elderly individuals who are living in a residence that offers specialized care and services. Such individuals constitute a segment of the population for which it is often harder to determine the place of residence with certainty (National Research Council 2006). Also, because of their age, they may be more likely to have their tax return prepared either by someone close to them or by a professional.
Interprovincial workers—workers whose job is in a province other than their province of residenceNote 28 (89.4%)—and individuals who do not live with their spouse (89.0%) have slightly lower consistency levels. In both cases, these persons are especially likely to maintain ties with more than one place of residence, for members of the first group because of their distance from their workplace and for members of the second group because of their connection with more than one home.
The rate postal code consistency is also lower for persons living on an Indian reserve (87.6%) and members of First Nations (89.0%). Reserves are not only mostly located in rural areas but they are also places with very different social and political dynamics than the rest of the country.
4.1.1. Children in joint custody
Children in joint custody regularly alternate between their parents’ homes. In the census, they must be enumerated in the home in which they spend the most time. If they divide their time equally between their two parents, they must be enumerated in the home they are in on Census Day. However, in the tax data, a child is generally included with the taxfiler who is receiving the tax benefits associated with that child, and the taxfiler’s mailing address is not always identical with the child’s usual place of residence. As a result, this group is especially likely to have a different place of residence in the two sources.
Individuals in this group are more difficult to identify based on the data available in the linkage. We have therefore tried to identify them indirectly using census information on the individual’s status within his or her family. This information serves to identify children who live in a lone-parent family or who are the biological or adopted child of only one of the two members of the couple. Such children are especially likely to be in joint custody; based on the definition used here, one child in five aged 0 to 17 is in this situation.Note 29
Linked children who are identified as being likely to be in joint custody have a postal code consistency rate of 86.3%, compared with 94.0% for other children; this represents a gap of nearly 8 percentage points. Of course, this gap is quite probably underestimated, since not all children identified by this approach are necessarily in joint custody. On this subject, the NLSCY data show that 27.9% of children aged 0 to 9 in a custody arrangement were in joint custody. In any case, the more complex situation with respect to determining the place of residence of children in joint custody appears to have a sizable impact on the consistency of the postal code.
4.2. Consistency of postal code: Results for characteristics associated with mobility
Mobility is a factor closely associated with the consistency of the postal code. The following chart shows consistency rates based on migrant status and type of migration.
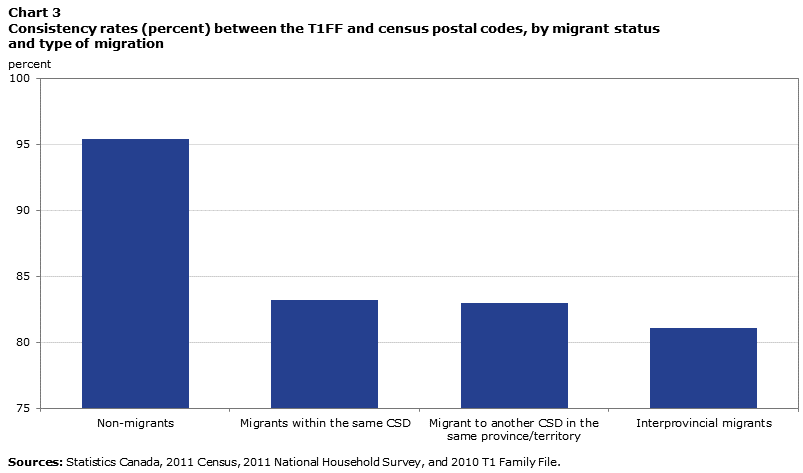
Description for Chart 3
| Type of migration | Percent |
|---|---|
| Non-migrants | 95.4 |
| Migrants within the same CSD | 83.2 |
| Migrant to another CSD in the same province/territory | 83.0 |
| Interprovincial migrants | 81.1 |
| Sources: Statistics Canada, 2011 Census, 2011 National Household Survey, and 2010 T1 Family File. | |
From an examination of this chart, two main findings emerge. First, the fact of having moved during the past year, either to a location within the same municipality or to elsewhere in Canada, is closely related to postal code consistency. Linked individuals who moved have a consistency level of less than 85%, compared with 95.4% for those who remained at the same address. Second, the consistency level varies only slightly according to the type of migration. This suggests that it is the fact of having moved, not the type of migration, which is associated with the consistency of the postal code.
While these results may be explained by the difference between the reference dates for the two files,Note 30 it is also possible that some of the gap may be due to migratory movements that are not adequately captured by the tax data. As mentioned earlier, highly mobile individuals such as some young adults might give the mailing address for the parental home as long as their place-of-residence situation is fairly unstable. On this subject, Morissette and Bérard-Chagnon (2014) showed that for measuring interprovincial migration, the differences between tax data and NHS data can be quite substantial. Since migration is essentially a change in the place of residence, these results tend to reaffirm the limitations of tax data for identifying the usual place of residence.
The following table shows the differences in postal code consistency for a few characteristics related to mobility. These data serve to identify particular segments of the population that have lower postal code consistency, largely because of their greater mobility.
| Characteristic | Distribution in matched file | Consistency rate |
|---|---|---|
| percent | ||
| General | 100.0 | 92.9 |
| Age group | ||
| 0 to 9 years | 14.1 | 91.5 |
| 10 to 19 years | 14.0 | 93.6 |
| 20 to 24 years | 5.8 | 91.0 |
| 25 to 29 years | 6.0 | 89.2 |
| 30 to 39 years | 14.5 | 92.0 |
| 40 to 49 years | 16.5 | 94.7 |
| 50 to 59 years | 14.2 | 95.4 |
| 60 to 69 years | 8.6 | 94.9 |
| 70 to 79 years | 4.2 | 93.1 |
| 80 years and older | 2.3 | 79.9 |
| Immigrant status and period of immigration | ||
| Individual born in Canada | 79.2 | 94.2 |
| Immigrant | 20.4 | 93.8 |
| Landed between 2006 and 2011 | 3.4 | 88.7 |
| Landed between 2001 and 2005 | 3.4 | 92.9 |
| Landed between 1996 and 2000 | 2.5 | 94.3 |
| Landed prior to 1996 | 11.1 | 95.6 |
| Non-permanent resident | 0.5 | 86.9 |
| Total household income | ||
| Under $25,000 | 7.6 | 89.9 |
| Between $25,000 and $ 74,999 | 32.9 | 92.8 |
| Between $75,000 and $149,999 | 41.1 | 95.2 |
| $150,000 and over | 18.4 | 95.6 |
| Renter status | ||
| Owner | 81.2 | 95.7 |
| Renter | 18.2 | 87.1 |
| Band housing | 0.6 | 87.8 |
| Sources: Statistics Canada, 2011 Census, 2011 National Household Survey, and 2010 T1 Family File. | ||
An examination of the consistency of the postal code by age reveals two things. First, the consistency rate declines moderately starting in the early twenties, falls below 90% between ages 25 and 29 and then begins rising at around age 30. This period in the life cycle is generally marked by several moves, motivated by leaving the parental home, attending a postsecondary educational institution, entering the labour market or purchasing a first property. In fact, the propensity to move peaks at between ages 25 and 29 (Dion and Coulombe 2008). Young adults who move are especially likely to maintain ties with another residence because of the often temporary nature of their moves. Furthermore, the process of leaving the parental home is becoming more complex, largely because of the democratization and lengthening of postsecondary education. It appears that increasingly, young adults’ accession to residential independence involves periods of dependence and semi-autonomy (Billette et al. 2006), during which they might continue to put the mailing address of the family home on their tax return while being enumerated in their “independent” home.
Second, postal code consistency drops considerably among very elderly persons, falling below the 80% threshold starting at age 80 and even reaching close to 60% for persons aged 90 and older. This drop is due to the combined effect of the above-mentioned lower consistency rate for very elderly people who live in a collective dwelling and the fact that very elderly persons are much more likely to live in a collective dwelling than the rest of the population. When only persons who live in a private dwelling are considered, postal code consistency for very elderly persons remains around 90%. Very elderly persons are also more likely to have their tax return prepared by an accountant or a family member, which is another factor closely associated with lower postal code consistency.
While the consistency level for matched immigrants is similar to that for the Canadian-born population, it follows a gradient clearly defined by the period in which the immigrant has landed. For recent immigrants who landed between 2006 and 2011, the consistency level is 88.7%, and it gradually increases for earlier cohorts of immigrants. This is mainly because recent immigrants are more mobile, seemingly because the process of settling in a new country is a gradual process (Houle 2007; Okonny-Myers 2010). Moreover, the study of Houle (2007) revealed that more than one recent immigrant in ten had moved to another CSD in the 24 months after settling in Canada. Non-permanent residentsNote 31 also had a consistency level below 90%. This is due to both a greater propensity to migrate and the fact than non-permanent residents are more likely to have been matched in the fifth linkage wave.Note 32
The level of consistency is also correlated with household income. Persons with a total household income below $25,000 are less likely to have indicated the same postal code in the census and the tax data. Clearly, this characteristic is related to renter status, which is also linked with consistency. Renters and individuals who live in band housingNote 33 have a consistency level below 90%. The links between being a renter and the greater propensity to move are obvious.
4.3. Consistency of postal code: Results for methodological characteristics
The following table shows two methodological characteristics that are correlated with the consistency of the postal code.
| Characteristic | Distribution in matched file | Consistency rate |
|---|---|---|
| percent | ||
| Overall | 100.0 | 92.9 |
| Linkage wave | ||
| 1) Exact match | 69.0 | 94.6 |
| 2) More relaxed constraint on name | 2.9 | 93.3 |
| 3) Mix Match | 2.0 | 93.1 |
| 4) At least three family members with match on sex and date of birth | 12.3 | 92.3 |
| 5) Unattached persons added | 13.8 | 84.8 |
| Type of record in T1FF | ||
| Living taxfiler | 75.7 | 93.1 |
| Imputed child/spouse | 24.1 | 92.2 |
| Living taxfiler linked with a deceased taxfiler | 0.2 | 87.1 |
| Sources: Statistics Canada, 2011 Census and 2010 T1 Family File. | ||
As can be seen from the data in this table, the methods used to construct the T1FF and the linkage are likely to affect postal code consistency.
The level of consistency is lower for persons matched in the fifth and final linkage wave (84.8%). Because of the approach used to construct the linkage, the links created in the last waves are thought to be slightly less robust, and therefore the chances of having a false matchNote 34 are greater. Of course, postal codes are less likely to correspond for a false match. Also, persons matched in the final wave have different characteristics from those matched in the previous waves, especially as regards their propensity to move and their living in a collective dwelling. As seen above, these situations can play a role in explaining the lower consistency for persons matched in the fifth wave.
Although living taxfilers who are linked with a deceased taxfiler constitute only a small proportion of taxfilers, they have a lower level of postal code consistency (87.1%). These taxfilers tend to be considerably older, and nearly 80% of them were matched in the final wave. These factors might explain the lower consistency for this group.
5. Determinants of postal code consistency
Chapter 4 highlighted several characteristics associated with lower postal code consistency. Those characteristics indicate that different segments of the population appear to be especially likely not to have the same place of residence in the census and in the T1FF tax data. This chapter pursues that analysis, identifying the main factors that are correlated with the consistency of the postal code using a multivariate logistic regression model.
Start of text boxThe matched file includes nearly 4 million records for NHS respondents. Because of the very large number of observations, the usual thresholds of statistical significance are less appropriate (Lin et al. 2013; Sullivan and Feinn 2012).
We therefore drew partially on Ferguson (2009) in determining the characteristics for which the association with postal code consistency is statistically significant. The results shown here are considered statistically significant if the 95% confidence interval for the odds ratio is either totally greater than 1.50 or totally less than 0.67. Although Ferguson proposes a threshold of 2.00 (or 0.50) for determining that an odds ratio is statistically significant in the social sciences, we have opted for a slightly less restrictive threshold. This decision, which is subjective, is based in part on the assumption that the noise caused by the difference between the reference dates for the two sources examined could weaken the relationships between the characteristics and postal code consistency. Also, we added a second criterion, namely that the chi-square statistic must be greater than 100 (which corresponds to a p-value considerably less than 1%). This criterion was chosen so as to include a measure that is well tested in the social sciences, the p-value, while establishing a subjective threshold which, according to our experience, properly takes account of the very large number of observations.
This combined approach makes it possible to target characteristics of interest in that not only are 1.they closely related to the consistency of the postal code but the association is also fairly strong. For more information on the main limitations in using p-values for determining statistical significance thresholds, see for example Wasserstein and Lazar (2016). Although only the results that are statistically significant according to the criteria established here are reported, Table A.4 in the Appendix includes the results for all the characteristics included in the model.
The NHS was administered only to the population living in private households. Therefore it is not possible to include the effect of living in a collective dwelling in the multidimensional analysis.
The variable constructed to identify children potentially living in joint custody was omitted from the analyses in this chapter because of the more approximate nature of its construction.
Lastly, the statistical significance thresholds used here do not refer to the relationships that unite the characteristics in the context of a superpopulation. Instead, they serve as tools for evaluating differences in postal code consistency among various demographic groups. Accordingly, the results represent only the linkage data and not the Canadian population as a whole. Any inference to the Canadian population should be made with great caution.
The following table shows the main results of this modelling.
| Characteristic | Odds ratio |
|---|---|
| Migrant status | |
| Non-migrant | Reference |
| Migrant within the same CSD | 0.39 [0.39 to 0.40] |
| Migrant to another CSD in the same province/territory | 0.34 [0.33 to 0.35] |
| Interprovincial migrant | 0.36 [0.35 to 0.38] |
| Aboriginal identity | |
| No identity | Reference |
| Inuit | 2.19 [1.92 to 2.50] |
| Age group | |
| 0 to 9 years | 0.51 [0.49 to 0.53] |
| 10 to 19 years | 0.58 [0.56 to 0.61] |
| 20 to 29 years | 0.60 [0.59 to 0.62] |
| 40 to 49 years | Reference |
| Census metropolitan area of residence | |
| Toronto | Reference |
| British Columbia (non-CMA) | 0.58 [0.56 to 0.59] |
| Yukon | 0.47 [0.42 to 0.54] |
| Northwest Territories | 0.33 [0.29 to 0.37] |
| Nunavut | 0.23 [0.19 to 0.28] |
| Renter status | |
| Owner | Reference |
| Renter | 0.46 [0.46 to 0.47] |
| Household size | |
| 1 person | 2.11 [2.04 to 2.18] |
| 4 persons | Reference |
| Status of person within census family | |
| Married spouse or common-law partner | Reference |
| Child | 2.23 [2.15 to 2.31] |
| Lone-parent family status | |
| Not a lone-parent family | Reference |
| Lone-parent family | 0.65 [0.64 to 0.66] |
| Type of record in the T1FF | |
| Living taxfiler | Reference |
| Imputed child/spouse | 0.57 [0.55 to 0.59] |
| Linkage wave | |
| 1) Exact match | Reference |
| 5) Unattached persons added | 0.31 [0.30 to 0.31] |
| Return prepared by a third party (box 490) | |
| No | Reference |
| Yes | 0.05 [0.05 to 0.06] |
| Number of observations | 3,991,353 |
| Cox and Snell R-squared (percent) | 4.4 |
|
Notes: Only categories that are statistically significant based on the established thresholds are shown here. Table A.4 in the Appendix includes results for all the characteristics included in the model. Sources: Statistics Canada, 2011 Census, 2011 National Household Survey, and 2010 T1 Family File. |
|
The data in this table show, firstly, that even when controls for the effect of different characteristics were applied, a number of them remain strongly associated with the level of postal code consistency. Also, while the regression model confirms several results described in Chapter 4, it also brings out links that were less obvious at the descriptive stage.
The fact of having moved during the year preceding the NHS remains highly correlated with postal code consistency. Individuals who moved still exhibit considerably lower consistency than those who did not. This applies to movers regardless of the type of move they made, and could be due to the difference in the reference dates for the two files.
Despite controlling for the effect of mobility, children, young adults and individuals who rent their dwelling still exhibit lower consistency. This suggests that mobility does not totally explain these groups’ lower consistency levels, which were identified earlier.
While the effect of age on consistency continues to be statistically significant for young adults according to our criteria, the effect seen in the descriptive stage for elderly persons aged 80 and older tends to fade in light of the possible effect of other factors. This appears to result mainly from the exclusion of persons living in collective dwellings for the multivariate model because the NHS data were used. The descriptive analysis showed that the consistency level for very elderly persons living in private dwellings remains high.
Taxfilers who had their return prepared by a third party according to box 490 continue to have a lower consistency level, even when the effect of age is taken into account.
The Inuit, who exhibited a slightly lower level of consistency than that of the population with no aboriginal identity, now have a significantly higher level. This population’s lower consistency level would therefore seem to be attributable to its specific characteristics, such as its younger age structure and its geographic location in northern Canada. Since these characteristics are also related to lower consistency, taking them into account in the model serves to isolate the effect of having reported an Inuit identity in the NHS.
The results of the regression analysis shed more light on the correlations between some family characteristics and the consistency of the postal code. When other factors are taken into account, children in a census familyNote 35 are more likely to have the same postal code in the two sources. Also, the level of postal code consistency is lower for persons living in a lone-parent situation. This could reflect the sometimes ambiguous situation of children in joint custody with regard to their place of residence.
It is worth noting that the descriptive analysis revealed that persons living alone were only slightly less likely to have the same postal code in the census and in the T1FF than were four-person households.Note 36 However, this situation changes when the other characteristics are taken into account, with the result that living alone is now associated with a higher level of consistency. This result is mainly due to the fact that persons living alone are not only more mobile but are also more likely to have been matched in the final linkage wave. Controlling for these characteristics brings out the real links between postal code consistency and household size.
Some regional effects are associated with postal code consistency. Persons who live in the territories or in non-CMA areas in British Columbia have lower consistency than those who live in the Toronto CMA.
The type of record in the T1FF and the linkage wave continue to be correlated with the consistency of the postal code even when controlling for other factors. Imputed children and spouses exhibit significantly lower consistency than living taxfilers. The geographic information for imputed persons is obtained indirectly from that of the taxfiler to whom they are attached.Note 37 This information is therefore slightly more likely not to reflect the imputed person’s real place of residence, such as in the case of a child in joint custody. Since the majority of imputed persons are children, controlling for the effect of age yields a better picture of the association between the consistency of the postal code and the type of record. For example, taxfilers 18 years of age have a consistency rate of 95.1%, compared with 91.2% for imputed persons of the same age.
Individuals matched in the fifth linkage wave continue to exhibit much lower consistency than those matched in the initial wave. These results suggest that this situation is not solely due to the particular characteristics of the persons matched in this wave. Consequently, it is possible that the greater propensity to have a false match in this wave is a factor that helps to explain this situation.
Finally, while the regression analysis shed light on a number of factors associated with postal code consistency, the relatively low level of the adjustment statistic in the Cox and Snell modelNote 38 (4.4%) indicates that these characteristics explain only a small part of the differences in postal code consistency levels. Other factors could be associated with place of residence consistency. The difference in the reference dates of the two files might also contribute significantly to variations in consistency levels. However, it is not possible at this time to adjust the data to take account of this difference.
Conclusion
Tax data are used increasingly to measure the population and its characteristics as well as to shed light on different demographic and social issues. This trend raises a number of challenges, including differences in the concept of place of residence. While the census enumerates the population at its usual place of residence, tax data collect taxfilers’ mailing address. This study examines the issue using a record linkage between data from the 2011 Census, the NHS and the 2010 T1FF.
First, this study found that 92.9% of the matched individuals had the same postal code in the census and in the T1FF tax data. This proportion climbs to more than 99% when more aggregated geographic levels are considered. However, consistency is lower, sometimes substantially, for some segments of the population. Persons who live in a collective dwelling, migrants, young adults, very elderly people and persons who had their tax return prepared by a third party (according to box 490 of the tax return form) are especially likely to have lower consistency. In general, these include demographic groups for which it is more difficult to determine the place of residence. These individuals seem to be more likely to report a different place of residence in the census and in the tax data, largely because of the different definitions of residence in the two sources. The variety of characteristics associated with lower consistency is also indicative of the diversity of the life paths that can lead to ambiguity when it comes to determining the usual place of residence and the mailing address reported on the tax return.
While the results of this study are enlightening, they also raise several questions. A number of taxfilers have their return prepared by an accountant or someone close to them, which can definitely influence the consistency of the place of residence. If the preparer did not fill in box 490, it is impossible to determine whether the taxfiler completed the return himself or herself.
The difference between the reference dates for the two sources may explain much of the variations in consistency for particular groups, especially those whose characteristics are associated with mobility. However, the effect of this difference cannot be isolated at this time. Furthermore, several characteristics likely to be associated with lower consistency of the place of residence cannot be observed directly through the data used in this study. These characteristics include postsecondary students who alternate between their place of study and the family home, children in joint custody, the shadow populationNote 39 and individuals who have just separated or divorced.
One of the main uses of tax data in demography is for estimating internal migration. This demographic phenomenon is defined as a change in the usual place of residence, and therefore a rigorous measurement of migration depends on a good measurement of the place of residence. The consistency levels calculated in this study, especially for persons who moved according to the NHS, point to various limitations in the tax data for the purposes of measuring migration. The tax data appear to be somewhat less appropriate for measuring migration of highly mobile groups, such as young adults. Therefore, it would be very worthwhile to determine the extent to which tax data lend themselves to calculating precise estimates of migration by examining the consistency of migration data using the record linkage used here.
A final point is that more generally, issues regarding the place of residence reflect the growing diversity of social trajectories. Although joint custody of children and the increase in the number of people residing in collective dwellings as a result of population aging tend to be relatively recent social phenomena, they are likely to be enduring features of Canadian society in the 21st century. In conjunction with the growing use of administrative data in demography, these changes will likely lead researchers to conduct more data comparison studies such as the one described here. Such studies will not only provide a better understanding of the possible uses of a growing number of files available, but also a better grasp of the demographic dynamics that characterize the Canadian population.
Appendix
Bibliography
AYDEMIR, Abdurrahman and Chris ROBINSON. 2006. “Return and Onward Migration Among Working Age Men”, Analytical Studies Branch Research Paper Series, no. 273, Statistics Canada Catalogue no. 11F0019M, 49 pages.
AYLWARD, Mary Joan. 2006. Shadow Populations in Northern Alberta, Northern Alberta Development Council, July 2006, 53 pages.
BÉRARD-CHAGNON, Julien. 2008. Analyse de la couverture du fichier T1FF de 2005, working document, Demography Division, Statistics Canada, June 2008, 60 pages.
BÉRARD-CHAGNON, Julien and James BRENNAN. 2014. “Évaluation du fichier de la Prestation fiscale canadienne pour enfants à l’aide d’un couplage de données”, Acte de conférence du Symposium 2010 de méthodologie de Statistique Canada, Ottawa, 6 pages.
BILLETTE, Jean-Michel, Céline LE BOURDAIS and Benoît LAPLANTE. 2006. “Le contexte de l’indépendance résidentielle au Canada”, Cahiers québécois de démographie, volume 35, no. 1. spring 2006, pages 83 to 121.
DION, Patrice and Simon COULOMBE. 2008. “Portrait of the mobility of Canadians in 2006: Trajectories and characteristics of migrants”, Report on the Demographic Situation in Canada: 2005 and 2006, Statistics Canada Catalogue no. 91-209-X, pages 78 to 108.
FERGUSON, Christopher J. 2009. “An Effect Size Primer: A Guide for Clinicians and Researchers”, American Psychological Association, volume 40, no. 5, pages 532 to 538.
FINNIE, Ross. 2000. “Who Moves? A Panel Logit Model Analysis of Inter-Provincial Migration in Canada”, Analytical Studies Branch Research Paper Series, no. 142, Statistics Canada Catalogue no. 11F0019M, 33 pages.
HE, Jiaosheng and Margaret MICHALOWSKI. 2005. “Research on Modifications to the Method of Preliminary Estimates of Interprovincial Migration”, Demographic Documents, no. 7, Statistics Canada Catalogue no. 91F0015M, 64 pages.
HOULE, René. 2007. “Secondary Migration of New Immigrants to Canada”, Our diverse cities, no. 3, summer 2007, pages 16 to 24.
HOUSE, Georgina. 2014. The Linking Process, working document, Household Survey Methods Division, Statistics Canada, 1 page.
LAPORTE Christine, Yuqian LU and Grand SCHELLENBERG. 2012. “Inter-provincial Employees in Alberta”, Analytical Studies Branch Research Paper Series, no. 350, Statistics Canada Catalogue no. 11F0019M, 57 pages.
LESSARD, Martin. 2011. Création du T1FF, presentation given during Demography Division lunch-time seminars, Statistics Canada, Ottawa, March 2011.
LIN, Mingfeng, Henry C. LUCAS and Galit SHMUELI Jr. 2013. “Too Big to Fail: Large Samples and the p-Value Problem”, Information Systems Research, pages 1 to 12.
MORISSETTE, Denis and Julien BÉRARD-CHAGNON. 2014. Evaluation of the 2011 Errors of Closure for Canada, Provinces and Territories, working document, Demography Division, Statistics Canada, July 2014, 65 pages.
NATIONAL RESEARCH COUNCIL. 2006. Once, Only Once, and in the Right Place: Residence Rules in the Decennial Census, Panel on Residence Rules in the Decennial Census, Daniel L. CORK and Paul R. VOSS, editors, Committee on National Statistics, Division of Behavioral and Social Sciences and Education, Washington, DC, The National Academies Press, 355 pages.
OKONNY-MYERS, Ima. 2010. The Interprovincial Mobility of Immigrants in Canada, Citizenship and Immigration Canada, Ci4‑47, 29 pages.
SCARDAMALIA, Robert L. 2014. Aging in America, County and City Extra Series, Bernan Press, 416 pages.
STATISTICS CANADA. 2012. Overview of the Census, 2011 Census, Catalogue no. 98-302-X, 49 pages.
STATISTICS CANADA. 2015a. Corporate Business Plan – Statistics Canada – 2015/2016 to 2017/2018, http://www.statcan.gc.ca/eng/about/bp, accessed December 14, 2015.
STATISTICS CANADA. 2015b. Census Technical Report: Coverage, 2011 Census, Catalogue no. 98-303-X, 152 pages.
STATISTICS CANADA. 2015c. Postal CodeOM Conversion File (PCCF), Reference Guide, April 2015, http://www.statcan.gc.ca/pub/92-154-g/92-154-g2015001-eng.htm, accessed November 6, 2015.
SULLIVAN, Gail M. and Richard FEINN. 2012. “Using Effect Size-or Why the P Value Is Not Enough”, Journal of Graduate Medical Education, September 2012, pages 279 to 282.
TURCOTTE, Martin and Mireille VÉZINA. 2010. “Migration from central to surrounding municipalities in Toronto, Montréal and Vancouver”, Canadian Social Trends, winter 2010, no. 90, Statistics Canada Catalogue no. 11-008-X, 24 pages.
TURCOTTE, Martin. 2013. “Living apart together”, Insights on Canadian Society, March 5, 2013, Statistics Canada Catalogue no. 75‑006‑X, 11 pages.
U.S. CENSUS BUREAU. 2004. Meeting the 21st Century Demographic Data Needs-Implementing the American Community Survey, Report 4: Comparing General Demographic and Housing Characteristics with Census 2000, May 2004, 87 pages.
VAMDERKAMP, John and Kenneth E. GRANT. 1988. “Canadian Internal Migration Statistics: Some Comparisons and Evaluations”, Canadian Journal of Regional Science, volume 11, no. 1, spring 1988, pages 9 to 32.
WASSERSTEIN, Ronald L. and Nicole A. LAZAR. 2016. “The ASA’s Statement on p-Values: Context, Process, and Purpose”, The American Statistician, volume 70, no. 2, pages 129 to 133.
WILLBOND, Stephanie. 2014. “Migration: Interprovincial, 2011/2012”, Report on the Demographic Situation in Canada, Statistics Canada Catalogue no. 91-209-X.
- Date modified: