
Collecte par approche participative des données des reçus d’épicerie dans les communautés autochtones à l’aide de la reconnaissance optique de caractères
Par : Shannon Lo, Joanne Yoon et Kimberley Flak
Tout le monde mérite d’avoir accès à des aliments sains et abordables, peu importe où l’on vit. Cependant, de nombreux Canadiens qui vivent dans des communautés nordiques et isolées doivent faire face à des coûts accrus liés aux tarifs d’expédition et aux défis sur le plan des chaînes d’approvisionnement. En réaction aux préoccupations relatives à la sécurité alimentaire dans le Nord, le gouvernement du Canada a créé le programme de subventions Nutrition Nord Canada (NNC). Géré par Relations Couronne-Autochtones et Affaires du Nord Canada (RCAANC), ce programme aide à rendre les aliments nutritifs, comme la viande, le lait, les céréales, les fruits et les légumes, plus abordables et accessibles. Pour mieux comprendre les défis associés à la sécurité alimentaire, il faut disposer de meilleures données sur les prix.
Pour le compte de RCAANC et en collaboration avec le Centre des projets spéciaux sur les entreprises (CPSE), la Division de la science des données de Statistique Canada a réalisé un projet de validation de principe afin d’évaluer si l’approche participative constitue une solution potentielle pour combler les lacunes en matière de données. Ce projet a permis d’évaluer s’il était possible d’utiliser la reconnaissance optique de caractères (ROC) et le traitement du langage naturel (TLN) pour extraire et totaliser des renseignements sur les prix à partir d’images de reçus d’épicerie, en plus de créer une application Web pour téléverser et traiter les images de reçus. Le présent article met l’accent sur un algorithme de détermination et d’extraction de texte. Il ne présente pas le volet réservé à l’application Web.
Données
Les données d’entrée du projet comprenaient des images de reçus d’épicerie pour des achats faits dans des régions autochtones isolées, y compris des photos prises avec un appareil photo et des images numérisées. Le format et le contenu des reçus variaient selon les détaillants. À partir de ces reçus, nous avons cherché à extraire des renseignements sur les prix des produits, ainsi que des renseignements sur les reçus, comme la date et l’emplacement de l’achat, qui fournissent un contexte important en vue d’une analyse subséquente. Les données extraites ont été compilées dans une base de données afin de soutenir les fonctions de validation, d’analyse et de recherche.
Conception générale
La figure 1 illustre le flux de données, de la soumission du reçu à la numérisation, au stockage et à l’affichage. Le présent article se concentre sur le processus de numérisation.
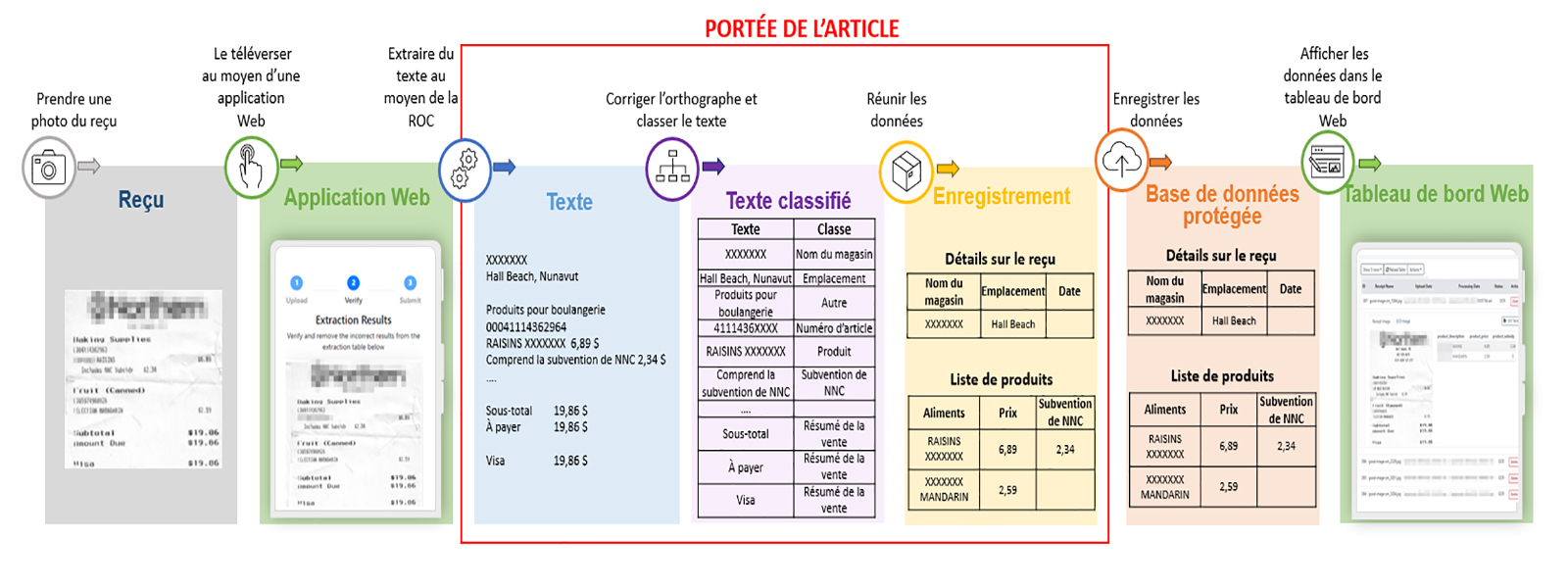
Figure 1: Flux de données
Il s’agit d’un diagramme de processus représentant le flux de données entre les différents processus du projet. Il met en évidence les trois processus de numérisation sur lesquels le présent article sera axé : extraire du texte au moyen de la reconnaissance optique de caractères, corriger l’orthographe et classer le texte, et compiler les données.
- Reçu : prendre une photo du reçu
- Transférer vers « Application Web » : télécharger à l’aide d’une application Web
- Application Web : télécharger à l’aide d’une application Web
- Transférer vers « Texte » : extraire du texte au moyen de la reconnaissance optique de caractères
- Texte : extraire du texte au moyen de la reconnaissance optique de caractères
- Transférer vers « Texte classifié » : corriger l’orthographe et classer le texte
- Texte classifié : corriger l’orthographe et classer le texte
- Transférer vers « Enregistrement » : compiler les données
- Enregistrer : compiler les données
- Transférer vers « Base de données protégée » : enregistrer les données
- Base de données protégée : enregistrer les données
- Transférer vers « Tableau de bord Web » : afficher les données dans le tableau de bord Web
- Tableau de bord Web : afficher les données dans le tableau de bord Web
Extraction de texte au moyen de la reconnaissance optique de caractères
Nous avons extrait du texte à partir de reçus en détectant tout d’abord les zones de texte au moyen de la méthode « Character-Region Awareness For Text detection (CRAFT) », puis par la reconnaissance de caractères au moyen de Tesseract, le moteur de ROC de Google. Nous avons choisi CRAFT au lieu d’autres modèles de détection de texte, puisqu’il détecte efficacement du texte dans des zones floues à faible résolution ou dans celles où il manque des points d’encre. Pour en savoir davantage sur CRAFT et Tesseract, voir l’article Comparaison des outils de reconnaissance optique de caractères pour les documents à forte densité de texte et les textes provenant de scènes du Réseau de la science des données.
Tesseract reconnaissait du texte à partir des zones de texte détectées. De manière générale, Tesseract cherchait les alphabets, les chiffres et la ponctuation en français et en anglais. Cependant, dans le cas des zones de texte qui commençaient à l’extrême droite (c.-à-d. celles ayant une coordonnée x à gauche au moins aux trois quarts de la coordonnée x maximale de la zone en question), Tesseract ne cherchait que les chiffres, la ponctuation et certains caractères simples servant à indiquer le type de taxe pour le produit, en supposant que la zone de texte renfermait des renseignements sur le prix. En limitant les caractères à reconnaître, nous évitions que les zéros soient reconnus comme des « O ».
Si Tesseract ne reconnaissait pas de texte dans la zone de texte ou si le niveau de confiance de la reconnaissance était inférieur à 50 %, nous avons d’abord essayé de nettoyer l’image. Les parties de texte qui présentaient une noirceur inégale ou des zones sans encre ont été comblées au moyen de l’égalisation adaptative d’histogramme à contraste limité (CLAHE en anglais). Cette méthode a permis d’améliorer le contraste global de l’image, en calculant l’histogramme de l’intensité des pixels et en répartissant ces pixels dans des plages ayant moins de pixels. La luminosité et le contraste de l’image ont été ajustés pour que le texte noir se démarque encore plus. Ces méthodes de nettoyage ont permis à Tesseract de mieux reconnaître le texte. Cependant, il n’était pas recommandé d’appliquer cette méthode de traitement préalable des images à toutes les zones de texte, puisqu’elle empêchait Tesseract de traiter certaines images prises dans des conditions différentes. Après cette méthode de traitement préalable des images, la reconnaissance de texte n’était utilisée que si la probabilité de reconnaissance de texte augmentait. Lorsque Tesseract échouait même après un traitement préalable des images, le programme utilisait le modèle « Scene Text Recognition (STR) » d’EasyOCR. Cet autre modèle de reconnaissance de texte offrait un meilleur rendement en présence d’images plus bruyantes, lorsque le texte était imprimé avec une quantité d’encre irrégulière ou que l’image était floue.
Vérification de l’orthographe
SymSpell a été entraîné au moyen de noms de produits individuels tirés de la base de données de l’Enquête sur les dépenses des ménages (EDM) de 2019. Pour améliorer la qualité de la correction, le correcteur d’orthographe sélectionnait le mot le plus courant en fonction des mots les plus semblables. Par exemple, si la ligne reconnue était « suo dried tomatoes », le correcteur d’orthographe pouvait corriger le premier mot en utilisant « sub », « sun » et « sum ». Cependant, il choisissait « sun » puisqu’il reconnaissait le digramme « sun dried », mais pas « sub dried ». D’autre part, si la ROC prévoyait que la ligne serait « sub dried tomatoes », aucun mot n’était corrigé, puisque chaque mot était une entrée valide dans la base de données. Nous avons cherché à éviter autant que possible les fausses corrections. Si un caractère n’était pas détecté en raison de la présence de lignes verticales ou du manque d’encre, le caractère manquant était aussi récupéré au moyen de la correction de l’orthographe. Par exemple, si la ligne reconnue était « sun dri d tomatoes », le correcteur d’orthographe corrigeait la ligne pour afficher « sun dried tomatoes ».
Un correcteur d’orthographe distinct corrigeait l’orthographe des noms de magasin et des noms de collectivités.
Classification de texte
Pour déterminer ce que décrivait chaque ligne de texte extrait, un classificateur d’entités au niveau du reçu et un classificateur d’entités au niveau du produit ont été créés. Les sections suivantes décrivent les entités pertinentes, les sources de données d’entraînement, les modèles envisagés et leur rendement.
Entités
Chaque rangée de texte qui était extraite a été classée dans l’un des 11 groupes présentés dans le tableau 1. Cette étape permet de caviarder des renseignements de nature délicate et d’utiliser de manière significative le reste des renseignements.
| Entités au niveau du reçu | Entités au niveau du produit | Autres entités |
|---|---|---|
|
Date Nom du magasin Emplacement du magasin Sommaire de la vente |
Produit Prix par quantité Subvention Réduction Dépôt |
Renseignements de nature délicate (comprend l’adresse du client, le numéro de téléphone et le nom) Autre |
Données d’entraînement du classificateur d’entités
Des données d’entraînement ont été recueillies à partir des reçus étiquetés, de la base de données de l’EDM et de sources publiques, comme les données accessibles dans GitHub. Voir le tableau 2 pour obtenir des renseignements détaillés sur chaque source de données d’entraînement.
| Données | Enregistrements | Source | Détails supplémentaires |
|---|---|---|---|
| Détails supplémentaires | 1,803 | RCAANC | ROC utilisée pour extraire des renseignements à partir des images de reçus qui ont ensuite été étiquetés par les analystes. |
| Produits | 76,392 | Base de données de l’EDM | 2 occurrences et plus |
| Nom de magasins | 8,804 | Base de données de l’EDM | 2 occurrences et plus |
| Villes canadiennes | 3,427 | GitHub | |
| Provinces canadiennes | 26 | GitHub | Communautés admissibles au programme NNC |
| Collectivités | 131 | Nutrition Nord Canada | Communautés admissibles au programme NNC |
| Collectivités | 87,960 | GitHub | Considérés comme des renseignements de nature délicate. |
Sélection de modèles et réglage des hyperparamètres
Deux classificateurs à classes multiples ont été utilisés, un pour classer les entités au niveau du reçu (c.-à-d. le nom et l’emplacement des magasins), et l’autre pour classer les entités au niveau du produit (c.-à-d. la description du produit, la subvention, le prix par quantité, la réduction et le dépôt). Le tableau 3 décrit les différents modèles utilisés lors de l’expérience, afin de classer les entités au niveau du reçu et au niveau du produit. Le score F1 des macros correspondantes pour les deux différents classificateurs est également fourni.
| Modèles mis à l’essai | Description | Score F1 selon la macro du classificateur de reçus | Score F1 selon la macro du classificateur de produits |
|---|---|---|---|
| Modèle bayésien naïf multinomial | Le classificateur bayésien naïf multinomial est idéal pour assurer une classification avec des fonctions discrètes (p. ex. nombre de mots pour la classification de texte). [1] | 0.602 | 0.188 |
| Machine à vecteurs de support linéaire avec entraînement au moyen de la descente par gradient stochastique | Cet estimateur met en application des modèles linéaires standardisés (p. ex. machine à vecteurs de support (SVM), régression logistique, etc.) avec entraînement au moyen de la descente par gradient stochastique : le gradient de la perte est évalué pour chaque échantillon à la fois, et le modèle est mis à jour pendant le processus, avec une courbe de force à la baisse (c.-à-d. le taux d’apprentissage). [2] | 0.828 | 0.899 |
| Classification à vecteurs de support linéaire | Semblable à la classification à vecteurs de support avec paramètre kernel = « linéaire », mais mis en œuvre en termes de liblinear plutôt que libsvm, ce modèle offre davantage de souplesse quand vient le temps de choisir des pénalités et des fonctions de perte. Il devrait mieux s’adapter à un grand nombre d’échantillons. Cette classe soutient les données denses et à faible densité. Le support à classes multiples est traité en fonction d’un régime axé sur le principe un contre les autres. [3] | 0.834 | 0.900 |
| Arbre décisionnel | Les arbres décisionnels sont une méthode d’apprentissage supervisé non paramétrique utilisée pour la classification et la régression. [4] | 0.634 | 0.398 |
| Forêt aléatoire | Une forêt aléatoire est un méta-estimateur qui correspond à un certain nombre de classificateurs d’arbres décisionnels pour différents sous-échantillons de l’ensemble de données, et qui utilise le calcul d’une moyenne pour améliorer l’exactitude des prédictions et contrôler le surajustement. [5] | 0.269 | 0.206 |
| XGBoost | XGBoost est une bibliothèque d’amplification de gradient réparti optimisée conçue pour être très efficace, souple et transférable. Elle met en œuvre des algorithmes d’apprentissage automatique dans le cadre d’amplification de gradient. [6] | 0.812 | 0.841 |
Avant de choisir les modèles, on a réalisé un réglage des hyperparamètres au moyen d’une recherche par quadrillage. Nous avons ensuite utilisé la validation croisée K-Folds stratifiée pour entraîner les modèles et les mettre à l’essai, tenant compte des défis associés au déséquilibre des classes dans l’ensemble de données d’entraînement, qui comprenait principalement des renseignements de nature délicate (49 %) et le nom ou le prix des produits (44 %). La proportion restante de l’ensemble de données (7 %) comprenait des renseignements comme le nom du magasin, l’emplacement, la subvention, la réduction, la date et le prix par quantité. Après les tests et l’entraînement, les modèles affichant le meilleur rendement pour les entités au niveau du reçu et du produit ont été choisis en fonction du score F1 de la macro. Le score F1 de la macro a été utilisé comme déterminant du rendement, parce qu’il évalue l’importance de chaque classe de façon égale. Cela signifie que, même si une classe comporte très peu d’exemples parmi les données d’entraînement, la qualité des prédictions pour cette classe est tout aussi importante que celle d’une classe qui comporte de nombreux exemples. Cette situation se produit souvent dans le cadre d’un projet où l’ensemble des données d’entraînement est déséquilibré, c’est-à-dire que certaines classes ont peu d’exemples, alors que d’autres en ont plusieurs.
Une approche fondée sur les règles a été utilisée pour déterminer les dates, car les formats de dates normalisées font en sorte qu’il s’agit d’une méthode plus robuste.
Le classificateur de classification à vecteurs de support linéaire a été retenu comme le meilleur modèle pour les classificateurs de reçus et de produits en fonction de son score F1 des macros de 0,834 (reçus) et de 0,900 (produits), qui était plus élevé que dans tous les autres modèles mis à l’essai. Même s’il s’agissait du modèle affichant le meilleur rendement, il convient de souligner que l’entraînement des classificateurs de la classification à vecteurs de support prend habituellement plus de temps que les classificateurs bayésiens naïfs multinomiaux.
Coupler du texte ayant fait l’objet d’une reconnaissance optique de caractères à l’enregistrement d’un reçu
Nous avons utilisé les classificateurs entraînés d’entités au niveau du reçu et d’entités au niveau du produit sur différentes parties du reçu. Si nous supposons que le reçu était présenté comme indiqué dans la figure 2, le classificateur d’entités au niveau du reçu prédisait la classe de toutes les lignes extraites du reçu, à l’exception de la section 3 : Produits. Le classificateur d’entités au niveau du produit n’a été utilisé qu’avec la section 3 : Produits. Cette présentation fonctionnait pour tous les reçus de notre ensemble de données. Si un élément, comme le nom d’un magasin, avait été coupé de la photo, ce champ était laissé vide dans le résultat final.

Figure 2 : Présentation du reçu
Cette image d’un reçu montre un exemple des différentes sections d’un reçu.
- Nom et adresse du magasin
- Relevé de transaction
- Produits (description, numéro d’article, prix, réduction, subvention et prix par quantité)
- Sous-total, taxes et total
- Relevé de transaction
Le début du reçu, où l’on trouve les sections 1) Nom et adresse du magasin et 2) Relevé de transaction, comprend des lignes de texte qui précèdent la ligne qui, selon les prédictions du classificateur de produits, affiche un produit et une valeur en dollars. Nous n’obtenions aucun nom et aucun emplacement de magasin si cette partie était vide et si la première ligne décrivait directement un produit. De l’ensemble du texte reconnu dans cette section, le texte prédit par le classificateur de reçus comme étant le nom du magasin avec la probabilité de prédiction la plus élevée a été attribué comme étant le nom du magasin. Un nom valide de communauté a été extrait des lignes qui, selon les prédictions, représentaient un emplacement. Les lignes qui, selon les prédictions du classificateur de reçus, comprenaient des renseignements de nature délicate dans cette section ont été caviardées.
La partie principale d’un reçu comprenait la section 3) Produits. Chaque ligne qui, selon le classificateur de produits, était un produit et affichait une valeur en dollars était considérée comme un nouveau produit. Toutes les lignes de texte qui suivaient ce produit et qui, selon les prédictions, étaient une subvention, une réduction, un dépôt ou le prix par quantité ont été ajoutées comme renseignements auxiliaires pour le produit. Les subventions ont ensuite été réparties entre la subvention de Nutrition Nord Canada (NNC) et la subvention pour le coût de la vie au Nunavik, en fonction de la description du texte.
La fin du reçu comprenait les sections 4) Sous-total, taxes et total et 5) Relevé de transaction. Aucune donnée ne devait être extraite de ces deux sections. Cependant, les lignes qui, selon les prédictions du classificateur de reçu, comprenaient des renseignements de nature délicate dans cette section ont été caviardées.
La date d’achat figurait au début ou à la fin du reçu. Les données ont donc été analysées en cherchant des tendances connues d’expression habituelle du format de la date dans ces sections du reçu.
Résultats
Nous avons évalué l’algorithme au moyen des photos des reçus d’épicerie de détaillants d’alimentation du Nord se trouvant dans des communautés autochtones éloignées. Des analystes du Centre des projets spéciaux sur les entreprises de Statistique Canada ont étiqueté les produits et les renseignements sur les ventes figurant dans chaque image.
Les textes extraits, notamment le nom des magasins, le nom des communautés, la description des produits et les dates, ont été évalués en fonction d’un score de similarité. La similarité entre les deux textes a été calculée en multipliant par deux le nombre total de caractères correspondants et en divisant le tout par le nombre total de caractères dans les deux descriptions. Les chiffres extraits, comme le prix du produit, la subvention, la réduction et le dépôt, ont été évalués de manière à établir une correspondance (1) ou aucune correspondance (0).
Dans le cas des champs simples, comme le nom des magasins, il était facile de comparer la valeur prédite à la valeur réelle. Néanmoins, il n’a pas été possible de réaliser une simple comparaison univoque entre les multiples éléments saisis manuellement et les multiples éléments prédits par l’algorithme de ROC. Ainsi, chaque élément saisi manuellement a été tout d’abord comparé à l’élément le plus similaire extrait par l’algorithme de ROC. Les éléments correspondants de deux sources devaient afficher un degré de similarité d’au moins 50 %. Les éléments saisis manuellement, mais non saisis par l’algorithme, étaient considérés comme des « éléments manquants ». Les éléments saisis par l’algorithme, mais non saisis manuellement, étaient considérés comme des « éléments supplémentaires ». Une fois les éléments communs appariés, la moyenne des scores de similarité pour toutes les paires a été calculée, afin d’obtenir un score de similarité global pour tous les éléments communs se trouvant sur les reçus.
L’algorithme de ROC excellait quand venait le temps de repérer des produits sur les reçus. Parmi les 1 637 produits figurant sur les reçus, 1 633 (99,76 %) ont été saisis (tableau 4). Le taux de similarité moyen de la description du produit atteignait 96,85 % (tableau 5). L’algorithme échouait lorsque le texte dans l’image était coupé, flou ou plissé, ou s’il manquait d’encre. C’est pourquoi nous avons recommandé que les extractions par ROC soient suivies par une vérification humaine réalisée au moyen de l’interface Web. Dans le cas des produits communs, les prix ont été extraits avec exactitude dans 95,47 % des cas, dans 99,14 % des cas pour les subventions de NNC, dans 99,76 % des cas pour la subvention pour le coût de la vie au Nunavik, dans 100,00 % des cas pour les réductions, dans 99,76 % des cas pour les dépôts, dans 95,71 % des cas pour le prix par quantité, et dans 95,22 % des cas pour les numéros d’article (tableau 5).
Même si la description des produits et les prix étaient toujours présents, d’autres champs, comme la subvention de NNC, n’étaient présents que lorsque c’était approprié. C’est pourquoi le tableau 5 fait aussi état des exactitudes limitées aux champs non manquants, afin d’évaluer uniquement le rendement de la ROC. Aucune entrée sur les réductions ne figurait dans ce lot de reçus. Nous avons donc utilisé un autre lot pour évaluer l’exactitude de l’extraction des réductions, qui l’ont été 98,53 % du temps. Le score de similarité du texte pour les champs observés et ayant fait l’objet d’une ROC était de 87,1 %.
| Nombre de reçus | Nombre d’éléments | Nombre d’éléments extraits | Nombre d’éléments en commun | Nombre d’éléments en commun | Pourcentage d’éléments supplémentaires |
|---|---|---|---|---|---|
| 182 | 1,637 | 1,634 | 1,633 | 0.24% (4/1,637) | 0.06% (1/1,630) |
|
Description du produit |
Prix (% d’exactitude) |
Subvention de NNC (% d’exactitude) |
Subvention pour le coût de la vie au Nunavik (% d’exactitude) |
Réduction (% d’exactitude) |
Dépôt (% d’exactitude) |
Numéro d’article (% d’exactitude) |
Numéro d’article (% d’exactitude) |
|
|---|---|---|---|---|---|---|---|---|
| Exactitude des éléments en commun | 96.85% | 95.47% (1,559/1,633) | 99.14% (1,619/1,633) | 99.76% (1,629/1,633) | 100.0% (1,633/1633) | 99.76% (1,629/1,633) | 95.71% (1,563/1,633) | 95.22% (1,555/1,633) |
| Exactitude des éléments en présence de champs | 96.85% | 95.47% (1,559/1,633) | 99.08% (647/653) | 100.0% (282/282) | Not available. No actual occurrence | 97.56% (160/164) | 72.97% (81/111) | 95.52% (1,555/1,628) |
Les renseignements sur les reçus ont été extraits de façon efficace sans qu’aucune communauté, aucun nom de magasin ou aucune date n’ait été complètement omis ou faussement assigné. Le score moyen de similarité du texte était constamment élevé : 99,12 % pour la communauté, 98,23 % pour les noms de magasins, et 99,89 % pour les dates. L’utilisation de l’algorithme de ROC et du classificateur d’entités de reçu pour traiter les reçus semble prometteuse.
En outre, 88,00 % des renseignements de nature délicate ont été caviardés correctement. Parmi les renseignements qui n’ont pas été caviardés, il s’agissait en grande partie des numéros d’identification des caissiers. Ces données n’ont pas été caviardées, car le classificateur d’entités n’avait jamais vu ce type de renseignement de nature délicate. Un nouvel entraînement du classificateur d’entités au moyen d’exemples de numéros d’identification de caissiers permettra d’améliorer les résultats, comme cela se produit dans le cas du nom des caissiers, alors que le classificateur reconnaît que les noms des caissiers sont des renseignements de nature délicate, en raison d’exemples comme « <Nom du caissier> était votre caissier aujourd’hui » dans ses données d’entraînement.
| Nombre de reçus | Nom du magasin (Score moyen de similarité du texte) |
Nom du magasin (Score moyen de similarité du texte) |
Nom du magasin (Score moyen de similarité du texte) |
Renseignements de nature délicate (% de rappel) |
|
|---|---|---|---|---|---|
| Évaluation | 182 | 98.23% | 99.12% | 99.89% | 88.80 |
| Évaluation en présence de champs | 164 | 99.02% | 99.88% | 98.03% | Not applicable |
Conclusion
Ce projet a montré qu’une classification d’entités et un algorithme de ROC peuvent saisir, avec exactitude, différentes composantes des reçus d’épicerie des détaillants du Nord. L’automatisation de ce processus facilite la collecte de données sur le coût de la vie dans le Nord. Si cette solution est mise de l’avant, l’automatisation devrait être suivie par un processus de validation avec intervention humaine, par l’intermédiaire d’une interface Web, afin de s’assurer que les reçus soient numérisés correctement et que les corrections soient utilisées, de manière itérative, pour réaliser un nouvel entraînement. Cette fonction de validation a été mise en œuvre, mais n’est pas abordée dans le présent article.
Les données anonymisées agrégées qui sont recueillies dans le cadre d’une approche participative pourraient fournir de meilleures explications associées au coût élevé des aliments dans les communautés autochtones isolées, en plus d’accroître la transparence et la reddition de comptes des bénéficiaires de la subvention Nutrition Nord Canada auprès des résidents de ces communautés. Si vous souhaitez en apprendre davantage sur le volet de l’application Web, veuillez envoyer un courriel, à datascience@statcan.gc.ca.
Rencontre avec le scientifique des données

Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Jeudi, le 15 juin
De 13 00 h à 16 00 h, HE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données.
À bientôt!
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
Références (en anglais seulement)
- sklearn.naive_bayes.MultinomialNB — scikit-learn 1.2.0 documentation
- sklearn.linear_model.SGDClassifier — scikit-learn 1.2.0 documentation
- sklearn.svm.LinearSVC — scikit-learn 1.2.2 documentation
- 1.10. Decision Trees — scikit-learn 1.2.0 documentation
- sklearn.ensemble.RandomForestClassifier — scikit-learn 1.2.0 documentation
- XGBoost Documentation — xgboost 1.7.2 documentation
- Date de modification :