
Prévisions en matière de consommation d'énergie dans les collectivités éloignées du Nord canadien
Par : Alireza Rahimnejad Yazdi, Lingjun Zhou et Zarrin Langari, l'Accélérateur numérique, Ressources naturelles Canada; Ryan Kilpatrick, CanmetÉNERGIE Ottawa, Ressources naturelles Canada
Introduction
Ressources naturelles Canada (RNCan) aide les collectivités du Nord et des régions éloignées du Canada à effectuer la transition de l'énergie traditionnelle produite à partir de combustibles fossiles à l'énergie renouvelable et verte. La plupart de ces collectivités sont géographiquement isolées et alimentées par des génératrices à combustibles fossiles. Pour appuyer cette initiative, les chercheurs de RNCan devaient prévoir avec précision la consommation d'énergie annuelle de ces collectivités afin de déterminer le type d'énergie renouvelable qui serait le mieux adapté pour soutenir ces collectivités. Pour ce faire, ils ont utilisé des données historiques sur la consommation d'énergie par heure, ainsi que des données démographiques et météorologiques. En établissant un profil horaire type de consommation d'énergie pour n'importe quelle collectivité, nous pouvons raisonnablement estimer la consommation horaire d'énergie pour les collectivités qui ne disposent pas de données historiques.
Grâce aux données accessibles au public fournies par son client, CanmetÉNERGIE Ottawa (CE-O) de RNCan, l'équipe de l'Accélérateur numérique s'est concentrée sur l'analyse des données de consommation d'énergie de 11 collectivités éloignées situées dans la région du Nunavik, dans le nord du Québec. Les données ont été présentées selon un niveau de précision horaire pour les années 2013, 2014 et 2015. Étant donné que cette approche analytique repose sur la consommation d'énergie moyenne pour ces trois années disponibles, les données sur la consommation d'énergie d'une année donnée s'infiltrent donc dans le modèle utilisé pour faire une prédiction pour cette année, et cette fuite de données mine la validité de toute mesure de rendement effectuée.
Nous considérons que la consommation d'électricité dans les collectivités éloignées a une relation non linéaire avec des variables comme la météo, la population, l'âge et l'efficacité des appareils, l'âge du bâtiment et, dans le cas du chauffage électrique, avec les taux d'occupation et les habitudes. Cependant, comme la plupart des méthodes de prédiction traditionnelles ne comportent pas de mécanisme d'apprentissage, il est difficile de décrire la relation non linéaire entre la consommation d'électricité et les variables exerçant une influence, ce qui entraîne des prévisions à faible précision.
Notre analyse permettra de déterminer si les techniques d'apprentissage automatique (AA) peuvent produire une prédiction plus précise des charges électriques dans les collectivités éloignées par rapport à l'approche analytique de CE-O, ainsi que de déterminer quel type de techniques d'AA est le plus approprié pour cette application. Nous espérons également appliquer la technique d'AA choisie pour créer des profils typiques horaires de charge électrique synthétique produite par diesel à l'ensemble des collectivités éloignées pour lesquelles des données granulaires de consommation horaire d'énergie ne sont pas disponibles.
Avant d'effectuer l'analyse, nous avons supposé ce qui suit :
- Les populations des collectivités demeurent constantes tout au long de l'année, ce qui signifie qu'en tout temps, une maison a le même nombre d'occupants et n'abrite pas de voyageurs hivernants, par exemple.
- Il n'y a pas de fluctuations majeures de la température. Compte tenu de l'avènement du changement climatique, des phénomènes météorologiques extrêmes, comme de brèves périodes d'extrême chaleur ou d'extrême froid, pourraient conduire à une modélisation inexacte.
- Il n'y a pas de changements majeurs dans les variables latentes qui pourraient contribuer à la consommation d'énergie qui ne sont pas incluses dans l'ensemble de données. Il s'agit d'une exigence très stricte, étant donné que nous ne savons pas quelles sont ces variables latentes.
Prétraitement des données et analyse exploratoire des données
Une analyse exploratoire des données (AED) a été effectuée pour étudier les données en découvrant des tendances, en repérant des anomalies et en vérifiant l'absence de certaines données à l'aide de statistiques sommaires et de représentations graphiques. Nous avons également cerné les caractéristiques typiques de la consommation d'énergie pour toute collectivité pendant l'AED afin d'aider à estimer la consommation d'énergie granulaire dans les collectivités qui ne disposent que de données sur la consommation d'énergie annuelle ou totale.
Divers modèles, comme la régression linéaire, LightGBM (light gradient-boosting machine), XGBoost, Theta Forecaster, Ensemble Forecaster, Auto-ARIMA, Auto-ETS, la prévision naïve, la transformation de Fourier rapide et les réseaux de neurones, ont été utilisés pour faire des prévisions et leurs performances ont été comparées.
Dans le cadre de la préparation des données, les données sur la population et la consommation d'énergie ont été combinées en calculant la consommation d'énergie par habitant. Ensuite, les données sur la consommation d'énergie par habitant ont été tracées au fil du temps. Les données sur la consommation d'énergie comportent trois composantes : les tendances, la saisonnalité et le bruit. On a supposé que les caractéristiques des données avaient une certaine puissance prédictive et on a donc choisi de les utiliser dans le modèle définitif.
Les renseignements sur la latitude et la longitude variaient trop peu pour fournir une contribution utile et ont été rejetés pour cette étape. Les représentations visuelles ont révélé les renseignements suivants :
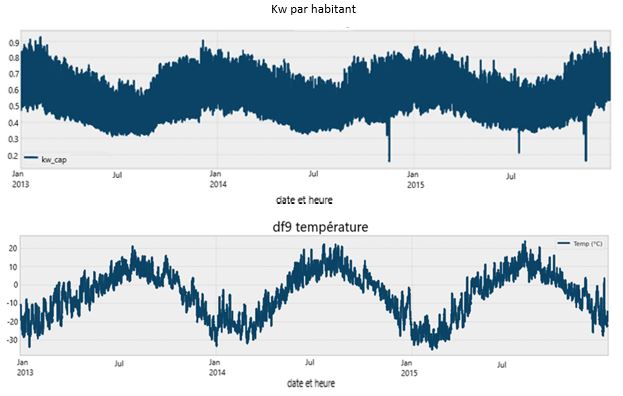
Figure 1. L'axe des x pour les deux tracés ci-dessous correspond à la date et l'heure, la première heure étant minuit en date du 1er janvier 2013
Diagrammes à deux lignes illustrant la consommation d'énergie par habitant par rapport à la date et l'heure ainsi que la température par rapport à la date et l'heure. La consommation d'énergie par habitant connaît une baisse évidente durant les mois les plus chauds, comme le mois de juillet, et des sommets durant les mois les plus froids, comme en janvier. La température et la consommation d'énergie par habitant sont corrélées négativement.
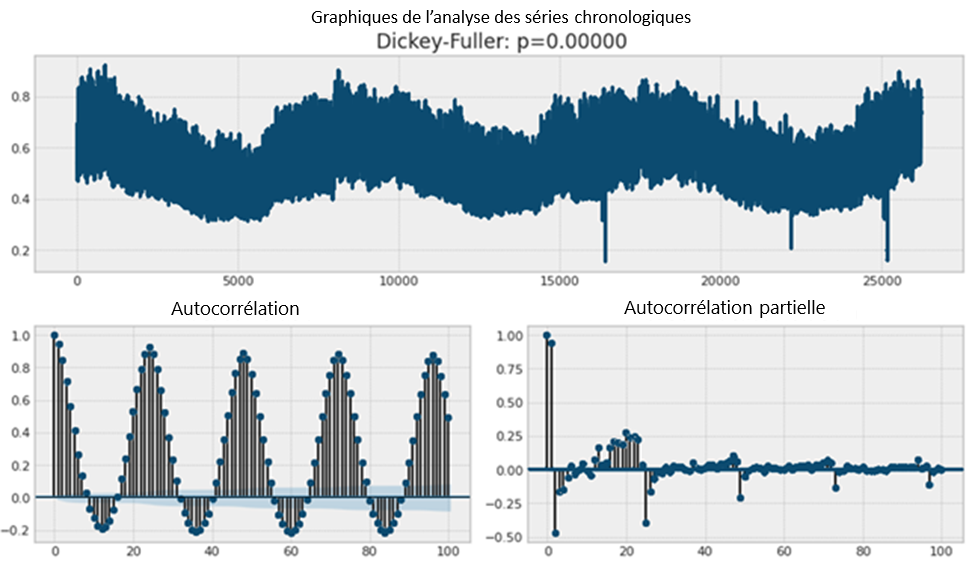
Figure 2. Veuillez prendre note que l'axe des x ci-dessus représente l'heure, où minuit du 1er janvier 2013 est la première heure et 23 h du 31 décembre 2015 est la dernière heure.
Les calculs d'autocorrélation et d'autocorrélation partielle pour les données sur la consommation d'énergie par habitant. Les tracés d'autocorrélation et d'autocorrélation partielle montrent des sommets toutes les 24 heures, ce qui indique une forte corrélation toutes les 24 heures. Cela signifie qu'exactement la même heure d'une journée précédente et celle d'une journée en cours partagent des consommations d'électricité semblables.
Une période de trois ans comprend au total 26 280 heures. Tant l'autocorrélation (ACF) que l'autocorrélation partielle (PACF) montrent qu'il y a une forte corrélation toutes les 24 heures. Cela est logique parce que la consommation quotidienne d'énergie suit généralement une tendance répétitive. La PACF est l'ACF pour laquelle les corrélations intermédiaires ont été supprimées. Par exemple, la PACF du décalage 3 correspond à l'ACF du décalage 3 moins la PACF des décalages 1 et 2. L'autocorrélation et l'autocorrélation partielle dans les données des séries chronologiques (en anglais seulement) produisent une analyse détaillée de leurs différences. Grâce à la PACF, nous pouvons voir clairement que la consommation d'électricité est fortement corrélée avec sa propre valeur enregistrée 24 heures auparavant.
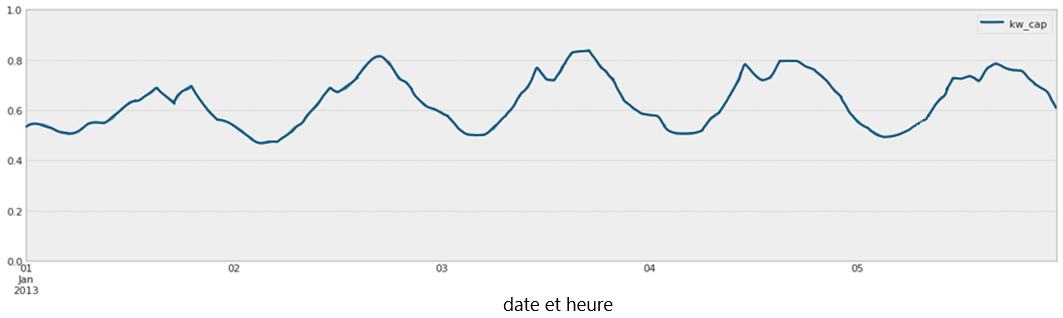
Figure 3. Une version agrandie des données historiques sur la consommation d'énergie. Ici, l'axe des x correspond à la date et l'heure, avec la précision des heures.
Une version agrandie de la consommation d'énergie par habitant par rapport à la date et l'heure. Nous pouvons voir un sommet dans la consommation environ toutes les 24 heures.
Voici un résumé des tendances que nous avons observées dans les images ci-dessus :
- Il existe une relation inverse entre la température normalisée et la consommation d'énergie par habitant.
- Il existe une faible tendance à la hausse de la consommation d'énergie, mais dans l'ensemble, il y a un modèle annuel répétitif.
- En l'espace d'un an, l'utilisation d'électricité augmente pendant les mois froids et diminue pendant les mois chauds. Il convient de mentionner que l'ampleur de l'augmentation de l'électricité consommée pendant les mois froids et de sa diminution pendant les mois chauds diffère d'une collectivité à l'autre.
- En l'espace d'une journée, la consommation d'énergie est plus élevée pendant les heures d'éveil que pendant les heures de sommeil, un sommet étant observé autour de midi. Il convient de mentionner que la valeur de pointe diffère d'une collectivité à l'autre.
Résultats
L'image suivante est une prévision fondée sur les réseaux de neurones. Les prévisions tirées d'autres algorithmes ont des apparences semblables.
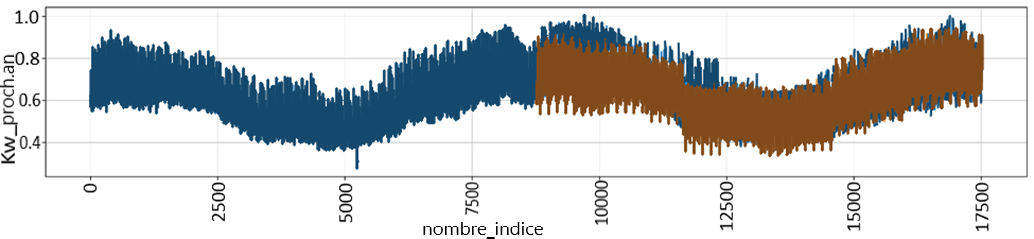
Figure 4. L'axe des x représente les heures, à partir de minuit le 1er janvier 2013.
Une prévision simulée de la consommation d'énergie par habitant pour l'année suivante (en orange) comparée aux données réelles de la consommation d'énergie par habitant de l'année suivante (en bleu). Nous pouvons voir que la consommation d'énergie simulée correspond presque à la consommation d'énergie réelle.
Après avoir comparé le rendement de divers algorithmes avec l'erreur moyenne en pourcentage absolu (EMPA), nous avons obtenu les résultats indiqués dans le tableau ci-dessous.
| Collectivité | EMPA du réseau de neurones | EMPA de LightGBM | EMPA Linéaire | EMPA Linéaire | EMPA naïve | Approche manuelle | ||
|---|---|---|---|---|---|---|---|---|
| 2013 | 2014 | 2015 | ||||||
| Inukjuak | 7,1% | 6,7% | 6,5% | 8,2% | 7,7% | 12,9% | 7,5% | 4,9% |
| Salluit | 6,2% | 6,8% | 6,7% | 6,7% | 6,1% | 7,7% | 6,0% | 5,0% |
| Quaqtaq | 10,7% | 8,8% | 8,3% | 11,5% | 12,2% | 16,1% | 11,7% | 5,7% |
| Aupaluk | 7,9% | 8,8% | 8,8% | 13% | 7,8% | 10,2% | 9,5% | 8,6% |
| Ivujivik | 12,9% | 14,9% | 14,9% | 14,9% | 13,9% | 14,3% | 6,3% | 6,3% |
| Kuujjuaq | 4,4% | 5,3% | 5,4% | 7,4% | 5,4% | 5,0% | 4,7% | 5,4% |
| Kangirsuk | 8,1% | 11,0% | 10,8% | 9,0% | 8,8% | 8,4% | 8,4% | 7,8% |
| Umiujaq | 5,4% | - | - | - | - | 10,9% | 9,3% | 7,1% |
| Kuujjuarapik | 6,6% | 4,8% | 4,8% | 4,9% | 5,2% | 98,9% | 6,6% | 7,4% |
| Kangiqsualujjuaq | 7,9% | 7,4% | 7,5% | 11,7% | 7,1% | 8,1% | 9,0% | 8,4% |
| Puvirnituq | 6,2% | - | - | - | - | 12,5% | 7,5% | 5,5% |
- Toutes les approches ci-dessus ont des procédures similaires. Nous avons d'abord effectué une séparation temporelle des données pour produire un ensemble de données d'essai et de données d'apprentissage. Ensuite, nous avons entraîné les modèles d'apprentissage automatique en utilisant les données d'apprentissage et mesuré le rendement au moyen de trois mesures différentes qui sont couramment utilisées pour les problèmes de régression : l'EMA (l'erreur moyenne absolue), la RCEQM (la racine carrée de l'erreur quadratique moyenne) et l'EMPA. Enfin, nous avons ajusté les hyperparamètres pour atteindre les meilleures performances pour chaque modèle.
- Le modèle de réseau de neurones comporte quatre couches. Les trois premières couches ont 32 unités avec activation RELU (unité linéaire rectifiée) et la dernière couche a une unité avec activation linéaire. La fonction de perte et l'optimiseur sont les propagations EMQ (erreur quadratique moyenne) et RQM (racine quadratique moyenne), respectivement. Lors d'un arrêt anticipé, la perte de validation était utilisée pour arrêter l'entraînement et éviter le surapprentissage. Une EMAP de moins de 10 % a été atteinte dans 9 des 11 collectivités.
- Pour les modèles de prévision LightGBM, linéaire et Theta, nous avons d'abord décomposé les données en supprimant la saisonnalité et la tendance pour arriver au résidu, puis avons entraîné le modèle en utilisant le résidu et inversé le processus pour arriver à une prédiction.
- La différence :
- LightGBM est un modèle basé sur un arbre de décision et permet un apprentissage rapide.
- Le modèle linéaire est un modèle de régression linéaire et sa vitesse d'apprentissage est aussi rapide que celle du LightGBM.
- Theta est un modèle de lissage exponentiel et son apprentissage prend un certain temps.
- La différence :
- Pour les prévisions naïves, nous avons simplement déplacé la consommation d'énergie de l'année précédente et l'avons utilisée comme prédiction de la consommation d'énergie de l'année en cours.
- La dernière colonne montre l'approche manuelle utilisée par CE-O qui illustre la différence entre les consommations d'énergie prévues et celles mesurées pour les années 2013, 2014 et 2015, respectivement. La raison pour laquelle il y a trois valeurs est liée à la façon dont fonctionne l'approche manuelle.
Voici nos observations fondées sur les résultats :
- Dans plusieurs collectivités, les diverses approches et les divers modèles d'apprentissage automatique fournissent une précision semblable. Le modèle complexe de réseau de neurones n'est que légèrement meilleur; il ne donne pas des résultats nettement supérieurs à ceux de modèles plus simples comme LightGBM ou la régression linéaire.
- Les prévisions naïves, c'est-à-dire l'utilisation du dossier de consommation d'énergie de l'année précédente pour la prévision de la consommation d'énergie de l'année en cours, peuvent donner un tout aussi bon résultat que tout autre modèle. Cela ne fonctionnerait pas si la tendance à la hausse était plus forte. Les prévisions naïves sont étonnamment difficiles à devancer. Cela est courant pour la prédiction des séries chronologiques et découle de l'observation qu'il existe une tendance annuelle répétitive évidente dans la consommation d'énergie.
- Il existe d'autres algorithmes potentiellement utiles comme l'analyse de Fourier, MLCT (les réseaux de mémoire à long ou à court terme), Auto-ARIMA, mais ils sont tous inefficaces et coûteux en matière de calcul pour cerner les tendances reproductibles nécessaires pour produire des résultats significatifs. À un moment donné, les auteurs ont essayé d'utiliser Auto-ARIMA pour simuler la série chronologique, mais le processeur graphique de notre poste de travail spécialisé a planté après cinq heures et demie de calcul intense. Il y avait 260 G de mémoire vive qui étaient utilisés alors que l'UCT (unité centrale de traitement) fonctionnait à 100 %.
Ce que nous avons découvert
Comparativement à l'approche manuelle, les prévisions de l'AA et les prévisions naïves peuvent, en moyenne, obtenir des résultats qui sont de 2 % à 3 % supérieurs.
Le risque d'erreurs importantes découlant de l'approche manuelle (16,1 % et 98,9 %) est considérablement réduit. Les approches d'apprentissage automatique semblent être plus stables. Étant donné que les prévisions naïves peuvent être tout aussi efficaces qu'un algorithme d'apprentissage automatique, il serait sans doute plus efficace de considérer l'utilisation de la consommation d'énergie d'une année précédente comme notre prévision pour l'avenir. Cependant, nous devons nous assurer qu'il y a un modèle annuel reproductible dans les données en effectuant une AED approfondie.
L'objectif ultime est de créer un profil horaire « typique » de la consommation d'énergie pour les collectivités dont les seuls antécédents disponibles sont des variables externes, comme l'historique des données météorologiques. Par profil de consommation d'énergie « typique », nous entendons les résultats normalisés une fois que les variables externes sont données. Par exemple, si deux collectivités ont les mêmes données climatiques, elles auraient alors la même consommation d'énergie par habitant pour chaque heure de l'année. Nous n'avons pas pu atteindre cet objectif pour certaines raisons :
- Nous remarquons que la consommation d'énergie par habitant s'affiche dans le même ordre de chiffres (entre 0,5 kW et 1,9 kW). Cependant, une personne moyenne de certaines collectivités utilise encore plus d'énergie que celles d'autres collectivités. Il sera difficile de créer un profil de consommation d'énergie « typique » pour un utilisateur moyen dans une collectivité « typique ». Une certaine normalisation pourrait être nécessaire.
- Dans la collectivité d'Ivujivik, la consommation d'énergie pour l'année 2014 ne correspond pas aux tendances que nous avons déterminées en utilisant l'AED. Elle fluctue considérablement tout au long de l'année et ne correspond pas à la tendance de faible consommation d'énergie pendant les mois plus chauds et de forte consommation d'énergie pendant les mois plus froids. Une attention supplémentaire est nécessaire pour déterminer la raison pour laquelle cette anomalie existe.
L'avenir du présent projet
Le présent projet pourrait être élargi. Si nous décidons d'aller de l'avant, une nouvelle entente sera mise en place afin d'obtenir des données plus récentes auprès de collectivités plus diversifiées provenant d'un plus grand nombre de géolocalisations et de types de climat ou de régions climatiques, ainsi que pour recueillir des données plus détaillées et pour cerner les tendances universelles dans un plus grand nombre d'ensembles de données. Si un ensemble de données plus riche et plus diversifié était possible, nous tenterions d'élaborer de nouveaux modèles qui peuvent prédire la consommation d'énergie pour les collectivités qui ne disposent pas de dossiers sur la consommation d'énergie. Nous pourrions étudier la relation entre la consommation d'énergie et les variables externes.
Rencontre avec le scientifique des données

Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Mardi, 17 janvier
De 14 h à 15 h, HE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données.
À bientôt!
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
- Date de modification :