
Série sur les développements en matière d’apprentissage automatique – premier numéro
Par : Nicholas Denis, Statistique Canada
Note de l'éditeur : Cette série présente des faits nouveaux et intéressants sur les recherches faites en matière d'apprentissage automatique provenant du monde entier. Nous espérons que vous trouverez quelque chose qui vous aidera dans votre travail, ou dans celui de vos collègues.
Les sujets du mois :
- Une approche novatrice de pré-entraînement : Le Contrastive Language-Image Pre-training (CLIP)
- Un réseau neuronal formé grâce à des paramètres de normalisation par lots
- Mesurer des instances de données difficiles à apprendre et voir de quelle façon en tirer parti pour former un réseau neuronal
Révolution : Une nouvelle approche de pré-entraînement d'apprentissage par transfert voit le jour!
Figure 1: Contrastive Language-Image Pre-training (CLIP)
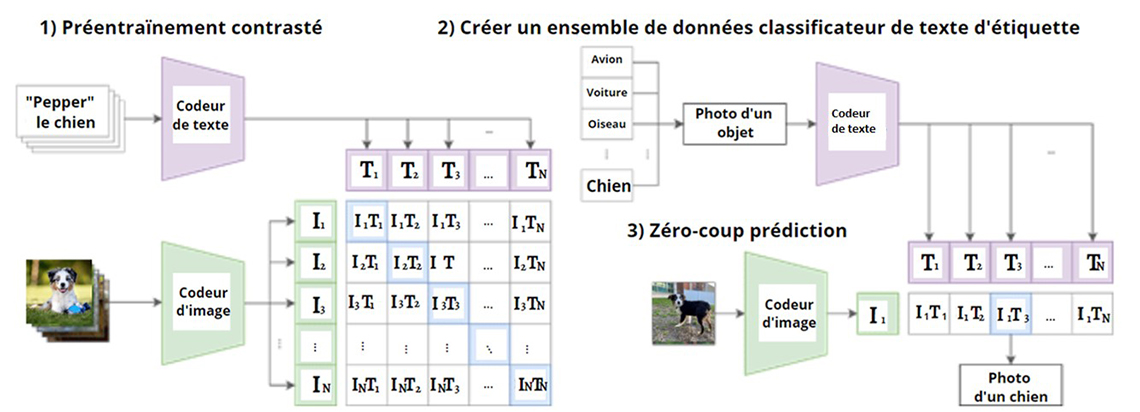
Description - Figure 1
Une image de trois organigrammes. Le premier graphique intitulé "1)Préentraînement contrasté" illustre l'entrée du texte "Pepper le chien" dans un codeur de texte avec les sorties suivantes comme en-têtes de colonne pour le tableau ; T1, T2, T3, ..., et TN. Sous le texte " Pepper le chien" se trouve l'image d'un chien assis sur de l'herbe. L'image est transmise à un codeur d'images dont les sorties sont les suivantes ; I1, I2, I3, I4, I5. Les valeurs de la première ligne de données dans le tableau sont les suivantes ; I1-T1, I1-T2, I1-T3,..., I1-TN. Les valeurs de la deuxième ligne de données sont les suivantes ; I2-T1, I2-T2, I2-T3,..., I2-TN. Les valeurs de la troisième ligne de données sont les suivantes I3-T1, I3-T2, I3-T3,..., I3-TN. Les valeurs de la quatrième ligne de données sont les suivantes ; IN-T1, IN-T2, IN-T3,..., IN-TN
Le deuxième graphique intitulé "2) Créer un ensemble de données classificateur de texte d'étiquette" montre des cases superposées verticalement contenant le texte suivant ; avion, voiture, oiseau,..., chien. Une flèche est dessinée allant du texte "oiseau" directement vers une autre case contenant le texte "Photo d'un objet". Ceci alimente ensuite un processus appelé codeur de texte, qui produit les valeurs suivantes ; T1, T2, T3, ..., et TN.
Le troisième tableau intitulé "3) Zéro-coup prédiction" commence par montrer la photo d'un chien debout sur l'herbe. L'image est introduite dans un codeur d'image qui produit la valeur suivante ; I1.
Les deuxième et troisième graphiques sont ensuite combinés pour produire les valeurs suivantes ; I1-T1, I1-T2, I1-T3,..., I1-TN. La valeur I1-T3 est mise en évidence et une flèche est dessinée allant de la valeur à une boîte contenant le texte "Photo d'un chien".
L'entreprise OpenAI présente une nouvelle approche de pré-entraînement produisant des modèles pré-entraînés de pointe pour la vision par ordinateur
La nouveauté : L'approche CLIP utilise à la fois des entrées sous forme de textes et d'images pour entraîner des modèles de vision par ordinateur, sans aucune étiquette, qui peuvent exécuter une grande variété de tâches à des niveaux de performance de pointe (ou presque) sur 30 ensembles de données différents. Quelques exemples de tâches comprennent la reconnaissance d'objets, la reconnaissance optique de caractères, la reconnaissance d'actions à partir de vidéos, la géolocalisation et la classification d'objets finement détaillés. OpenAI, l'entreprise qui a créé cette nouvelle approche, a mis les modèles à code source libre à la disposition du public.
Comment ça fonctionne : OpenAI a construit un ensemble de données extraites du Web contenant 400 millions d'images associées à des descriptions textuelles. L'entreprise a mis en place l'approche CLIP (Contrastive Language-Image Pre-training), une approche qui prend l'entrée d'une image et la description textuelle de l'image et apprend à intégrer les représentations de l'image et du texte sur la surface d'une (hyper) sphère aussi précisément que possible. C'est tout!
Pourquoi cela fonctionne-t-il? Imaginez que vous puissiez déterminer les descriptions textuelles associées à 400 millions d'images différentes? Il serait juste de dire que vous avez appris la sémantique des objets dans les images, et que vous avez correctement découvert un grand nombre de catégories et de concepts. C'est exactement ce qui se passe avec CLIP. Cette approche présente un nouveau mécanisme d'inférence utilisant des invites textuelles :
- puisque CLIP est entraîné sans aucune étiquette, il n'y a pas de couche de classification;
- pour une image d'entrée donnée, CLIP produit une représentation de l'image;
- pour un ensemble donné de classes pour une application donnée, des invites textuelles entrent dans le modèle sous la forme d'« Une photo d'une <CLASSE> », où CLASSE est remplacé par les classes d'intérêt (p. ex. chat, chien);
- CLIP produit une représentation du texte pour chaque invite, et la classe la plus proche de la représentation de l'image est sélectionnée comme classe inférée.
Résultats : Après avoir pré-entraîné un modèle avec un énorme corpus de données image-texte provenant du Web, les auteurs utilisent plus de 30 ensembles de données de référence en vision par ordinateur et étudient les performances de CLIP sur un grand nombre de tâches de vision par ordinateur. Les auteurs testent les performances du modèle sur l'apprentissage par transfert à zéro coup (aucun apprentissage supplémentaire), ainsi que sur l'évaluation linéaire et la mise au point.
- L'approche CLIP utilisant l'apprentissage à zéro coup (où, au moment de l'inférence, un algorithme d'apprentissage doit effectuer une classification sur des catégories de classes non observées pendant l'entraînement) dépasse un classificateur linéaire entièrement supervisé ajusté aux caractéristiques ResNet-50 sur 16 des 27 ensembles de données, y compris ImageNet.
- L'ajustement d'un classificateur linéaire sur les caractéristiques de CLIP dépasse l'utilisation du Noisy Student EfficientNet-L2 (apprentissage par transfert de pointe à partir de l'ensemble de données ImageNet) sur 21 des 27 ensembles de données (jusqu'à 23,6 % d'amélioration de la précision).
- La performance de CLIP zéro coup était incroyablement résistante aux changements de distribution, y compris les attaques adverses, les images stylisées, l'utilisation de bruit synthétique et l'utilisation d'images synthétiques fournies.
Quel est le contexte? L'entreprise OpenAI a contribué à ouvrir la voie au pré-entraînement des modèles de langage avec la famille de modèles de langage GPT (Generative Pre-trained Transformer) qui sont couramment utilisés. Il est clair que son expertise dans ce domaine l'a aidée à produire cette approche novatrice. Depuis la diffusion de la publication au sujet de cette approche au début de l'année 2021, plusieurs dizaines de travaux ont été menés, ont été analysés et ont utilisé CLIP, ce qui en fait l'ouvrage phare de l'année 2021. Les modèles et le code sont disponibles gratuitement en ligne: openAI/CLIP GitHub (le contenu de cette page est en anglais). Comme indiqué sur leur site web, OpenAI est une enterprise de recherche et de déploiement de l'IA. Sa mission est de faire en sorte que l'intelligence artificielle générale profite à l'ensemble de l'humanité. (le contenu de cette page est en anglais) - des systèmes très autonomes qui surpassent les humains dans la plupart des travaux à valeur économique - qui profite à l'ensemble de l'humanité. Ils tentent de construire directement des IAG sûres et bénéfiques, de mettre leur travail à la disposition d'autres personnes visant le même résultat, et sont régis par le conseil d'administration à but non lucratif d'OpenAI.
Et puis? CLIP a été utilisé pour la recherche d'images et de vidéos à l'aide de texte, de segmentation et de sous-titrage d'images. Bien que CLIP ait d'autres utilités comme faire la mise au point du modèle, les approches traditionnelles d'apprentissage par transfert (qui impliquent de geler le modèle CLIP) ou l'utilisation de ses caractéristiques comme entrées d'un nouveau modèle de réseau neuronal plus petit, l'aspect très important de CLIP réside dans sa capacité de transfert à zéro coup.
Lorsque l'approche a été évaluée sur ImageNet (un ensemble de données d'un million d'images comprenant 1 000 classes), CLIP a atteint une précision de 76,2 %, sans aucune supervision au niveau des classes. CLIP peut agir comme un classificateur à jeu ouvert (open-set) en utilisant les invites textuelles. Plutôt que d'avoir un modèle paramétrique produisant une distribution sur un nombre fixe de classes, au moment de l'inférence, l'approche CLIP est capable d'interroger le modèle avec un nombre quelconque de classes en utilisant la conception novatrice de l'invite, ce qui la rend incroyablement polyvalente et générale.
Une recherche distincte utilisant l'approche CLIP pour la segmentation montre que lorsque l'on fournit une image de zèbres buvant le long de la rivière, l'invite textuelle se lit comme suit : « Le zèbre devant les autres zèbres », ce qui permet au modèle CLIP de segmenter correctement le zèbre qui lui est demandé. De quoi changer la donne!
Notre avis : La littérature parle d'elle-même. Le nombre d'articles de recherche utilisant l'approche CLIP montre le côté novateur et la puissance de cette dernière. CLIP est utile pour un large éventail de tâches de vision par ordinateur. Nous pensons que les approches d'apprentissage profond qui utilisent de multiples modalités de données (c.-à-d. image/texte/audio, etc.) deviendront de plus en plus courantes. Cependant, comme on l'a vu avec le pré-entraînement des modèles de langage, tels que GPT-3 d'OpenAI, il est probable que la taille de ces modèles augmentera. À mesure que les paramètres de ces modèles augmenteront, seules les plus grandes entreprises technologiques seront en mesure d'assumer les coûts pour l'apprentissage de ces modèles, ce qui rendra peu probable leur utilisation par le public et la possibilité de les rendre à code source libre.
La normalisation par lots (BatchNorm) est tout ce dont vous avez besoin
Figure 2 : Relation entre le nombre de paramètres de normalisation par lots et l'exactitude lors de la mise à l'échelle de la profondeur et de la largeur des ResNets; dans CIFAR-10.
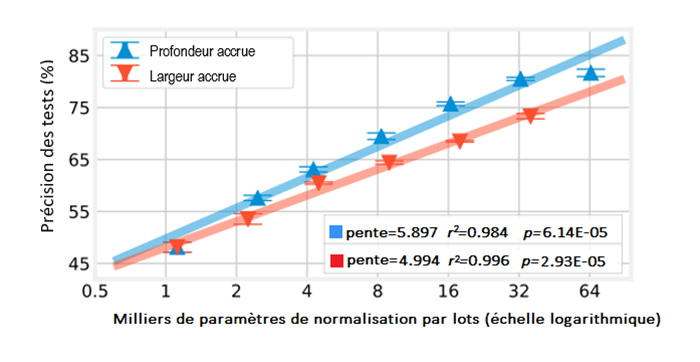
Description - Figure 2
Un graphique linéaire montrant la précision des tests (%) sur l'axe y avec les valeurs 45, 55, 65, 75 et 85. L'axe x est intitulé Milliers de paramètres de normalisation par lots (échelle logarithmique) et contient les valeurs 1, 2, 4, 8, 16, 32 et 64. Le graphique montre que la "profondeur accrue" et la "largeur accrue", ainsi que les "Milliers de paramètres de normalisation par lots (échelle logarithmique)" augmentent en précision. La profondeur accrue affiche les valeurs suivantes : pente=5.897, r2=0.984, p=6.14E-05. La largeur accrue affiche les valeurs suivantes : pente=4.994, r2=0.996, p=2.93E-05.
Figure 3: La distribution de y pour ResNet-110 et ResNet-101 agrégé à partir de cinq (CIFAR-10).
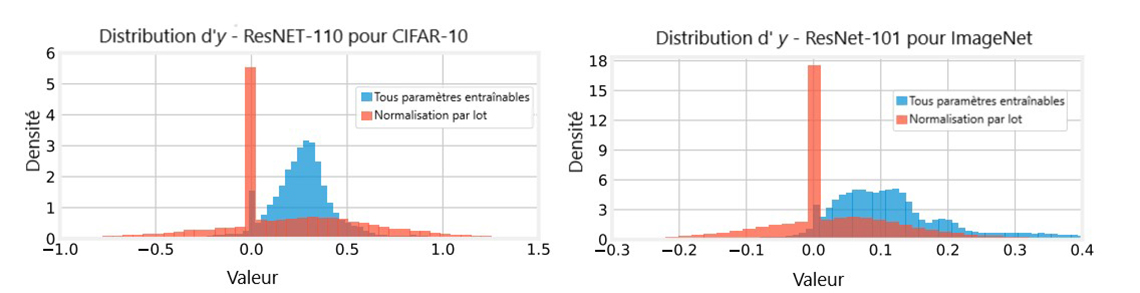
Description - Figure 3
Deux graphiques. Le premier graphique intitulé "Distribution d'y - ResNET-110 pour CIFAR-10" représente un histogramme avec deux valeurs : "Tous paramètres entraînables" et "Normalisation par lot". L'axe y est intitulé Densité, avec des valeurs comprises entre 0 et 6. L'axe x est intitulé Valeur et comporte les valeurs comprises entre -1,0 à 1,5 par incréments de 0,5. Le graphique montre que la densité des valeurs de la Normalisation par lot sont systématiquement inférieures à 1, à l'exception d'un pic important à une densité d'environ 5,5 pour une valeur de 0,0. La densité des valeurs associées à "Tous paramètres entraînables" commence à augmenter progressivement entre -0,5 et 0,0. Il y a un pic considérable à une valeur de 0,0 jusqu'à une densité d'environ 1,5, puis la densité chute à nouveau, mais augmente progressivement jusqu'à une densité maximale supérieure à 3 avec une valeur comprise entre 0,0 et 0,5 avant de retomber progressivement à une densité proche de 0 une fois que les valeurs approchent 1,0.
Le deuxième graphique intitulé "Distribution de y-Reset-101 pour ImageNet" représente un histogramme avec deux valeurs : "Tous paramètres entraînables" et "Normalisation par lot". L'axe y est intitulé Densité, avec des valeurs allant de 0 à 18 par incréments de 3. L'axe x est intitulé Valeur et contient des valeurs allant de -0,3 à 0,4 par incréments de 0,1. Le graphique montre que la densité des valeurs de Normalisation par lot est toujours bien inférieure à une densité de 3, à l'exception d'un pic important à une densité d'environ 18 pour une valeur de 0,0. La densité des valeurs "Tous paramètres entraînables" commence à augmenter progressivement entre -0.1 et 0.0. Il y a un pic considérable à une valeur de 0,0 jusqu'à une densité d'environ 3, puis la densité chute à nouveau, mais augmente progressivement jusqu'à un pic de densité d'environ 5 avec une valeur entre 0,0 et 0,2 avant de retomber progressivement à une densité proche de 0 une fois que les valeurs approchent 0,4.
Des chercheurs du Massachusetts Institute of Technology et de Facebook Research obtiennent une précision de 83 % pour l'apprentissage de CIFAR10 en utilisant uniquement des paramètres de normalisation par lots.
La nouveauté : La normalisation par lots est une technique omniprésente dans l'apprentissage profond. Les auteurs étudient le pouvoir expressif des paramètres de normalisation par lots en entraînant des réseaux de neurones, fournissant la preuve que la normalisation par lots est extrêmement puissante dans l'apprentissage profond, capable d'apprendre à partir de caractéristiques aléatoires.
Comment ça fonctionne : L'écart réduit est une technique courante de prétraitement des données, qui vise à transformer les entrées pour qu'elles soient approximativement normales (0,1). Cependant, dans l'apprentissage profond, lorsque chaque lot de données passe dans le réseau, les données sont transformées à chaque couche et ne suivent plus cette distribution. La normalisation par lots est similaire à l'écart réduit, cependant elle ne vise pas à transformer les données pour qu'elles soient normales (0,1), mais plutôt normales où et sont des paramètres assimilables. Les auteurs forment des réseaux neuronaux où tous les paramètres de poids sont fixes et ne sont pas mis à jour, tandis que les paramètres de la normalisation par lots sont les seuls paramètres mis à jour par apprentissage.
Résultats :
- Les auteurs démontrent d'abord que pour différentes architectures de réseaux neuronaux, l'utilisation de la normalisation par lots est toujours avantageuse et améliore les performances du modèle.
- Lors de l'utilisation d'un ResNet-110 sur CIFAR10, avec l'ensemble des 1,7 million de paramètres assimilables, le modèle atteint une précision de test de 93,3 %, mais lorsqu'il utilise uniquement les 8 300 paramètres de normalisation par lots, le modèle est capable d'atteindre une précision de test de 69,7 %. De plus, un ResNet-866 avec 65 000 paramètres atteint une précision de test de 83 %.
- En utilisant uniquement les paramètres de normalisation par lots pour l'apprentissage, les auteurs ont trouvé une corrélation de Pearson presque parfaite entre les paramètres de normalisation par lots (couches d'un réseau) et la précision du test.
- Une analyse des paramètres appris a montré que le modèle apprend à désactiver efficacement entre un tiers et un quart de toutes les caractéristiques, en élaguant implicitement le réseau.
Quel est le contexte? La normalisation par lots a fait l'objet de nombreuses études visant à faire la lumière sur le pourquoi et le comment de son fonctionnement. Bien qu'aucun praticien de l'apprentissage profond n'ait besoin de plus de preuves pour utiliser la normalisation par lots dans ses modèles, le fait qu'un modèle puisse avoir de bonnes performances en utilisant uniquement la normalisation par lots est assez impressionnant et révélateur. Étant donné que tous les autres paramètres sont initialisés et fixés de manière aléatoire, cela signifie en réalité que les caractéristiques produites à partir des données d'entrée sont aléatoires, et que les paramètres de la normalisation par lots sont capables de transformer de manière itérative les caractéristiques aléatoires en caractéristiques discriminantes pour la classification en aval.
Mais... Bien que le résultat soit très intéressant et puisse donner lieu à d'autres recherches, les auteurs ne suggèrent pas aux praticiens de former uniquement des réseaux à normalisation par lots.
Et puis? Les implications de ce travail fournissent un soutien supplémentaire pour la puissance et l'importance de l'utilisation de la normalisation par lots dans l'apprentissage profond. Un ResNet de 866 couches avec seulement 65 000 paramètres est capable d'obtenir de très bons résultats, alors qu'un réseau à une seule couche avec ce nombre de paramètres échouerait probablement complètement à la même tâche. Ce résultat pourrait très bien ouvrir la voie à de nouvelles conceptions architecturales et à des recherches centrées sur des réseaux plus profonds, mais plus étroits (moins de paramètres par couche).
Notre avis : Cette recherche est intéressante en soi, et est importante pour l'avancement de la recherche sur la normalisation par lots. Comme les poids de chaque couche des réseaux sont initialisés de façon aléatoire, chaque couche agit comme une transformation aléatoire sur les données, produisant des caractéristiques aléatoires. Étant donné que la normalisation par lots apprend uniquement à rééchelonner et à décaler ces caractéristiques aléatoires, ce travail fournit la preuve que cette approche peut être efficace pour les tâches d'apprentissage par transfert utilisant des modèles pré-entraînés. De plus, étant donné qu'une grande partie des paramètres appris ont effectivement élagué ou désactivé des caractéristiques, il pourrait y avoir une certaine pollinisation croisée avec la communauté sur l'élagage des réseaux (le contenu de cette page est en anglais). Pour nos lecteurs, le message à retenir est simple : utilisez la normalisation par lots.
Mesurer des instances de données difficiles à apprendre
Figure 4:Fréquence de sélection humaine par opposition à la dureté visuelle angulaire
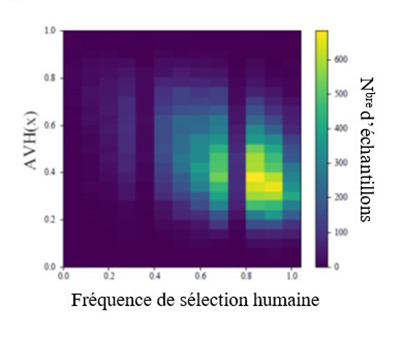
Description - Figure 4
Une carte thermique montrant la relation entre la fréquence à laquelle les instances de données sont sélectionnées par les humains comme étant représentatives d'une classe donnée, et la dureté visuelle angulaire. Les couleurs foncées représentent une relation faible, tandis que les couleurs jaunes plus vives représentent une relation plus forte. L'axe x est intitulé "Fréquence de sélection humaine" et contient les valeurs de 0,0 à 1,0 par incréments de 0,2. L'axe y intitulé AVH(x) contient les valeurs de 0,0 à 1,0 par incréments de 0,2. La carte thermique montre une concentration du nombre d'échantillons en bas à droite représentant une dureté visuelle angulaire plus faible et une fréquence de sélection humaine plus élevée.
Les chercheurs ont établi une mesure de la « difficulté » d'une instance de données à être correctement classée, qui présente une corrélation négative avec la fréquence à laquelle les annotateurs humains sélectionnent les instances comme exemples d'une classe donnée.
La nouveauté : Des chercheurs de l'Université de Toronto, de l'Université Rice, du California Institute of Technology, du Georgia Institute of Technology, de NVIDIA Corporation et du Vector Institute établissent une mesure de la difficulté d'un exemple par rapport à la capacité d'un modèle à classer correctement une instance de données, et forment le modèle en utilisant un programme basé sur cette mesure.
Comment ça fonctionne : La dureté visuelle angulaire calcule l'angle que fait une représentation avec chacun des centres de classe et produit un score où, en gros, les valeurs les plus grandes correspondent aux représentations qui ont des angles plus grands par rapport aux classes de leurs étiquettes identifiant la vérité (et qui sont donc plus éloignées). Ensuite, à l'aide de la dureté visuelle angulaire, l'ensemble de données peut être classé en matière de difficulté des instances, et un sous-ensemble peut être utilisé pour entraîner un modèle à l'aide d'instances d'un niveau de difficulté approprié (apprentissage par programme).
Résultats :
- Les chercheurs ont constaté que la dureté visuelle angulaire présente une forte corrélation (négative) avec la fréquence de sélection humaine, soit la fréquence à laquelle les annotateurs humains sélectionneraient une instance comme exemple d'une classe donnée. Par conséquent, plus l'exemple est facile, plus il est probable qu'un humain le sélectionnera et le reconnaîtra comme un exemple d'une classe donnée.
- Les chercheurs utilisent la dureté visuelle angulaire pour l'auto-formation semi-supervisée dans le cadre de l'adaptation au domaine. En bref, cela implique deux ensembles de données complètement différents, générés à partir de distributions complètement différentes, mais avec les mêmes classes. Avec des étiquettes sur l'ensemble de données « source » et aucune étiquette d'entraînement dans l'ensemble de données « cible », l'objectif est de généraliser à des instances non vues de l'ensemble de données « cible ». Les modèles ont d'abord été formés sur l'ensemble de données « source », puis la dureté visuelle angulaire a été appliquée à l'ensemble de données « cible ». Les instances inférieures à un seuil (instances plus faciles) ont été sélectionnées pour produire des pseudo-étiquettes par les modèles précédemment formés (voir voir Pseudo-Labeling to deal with small datasets - le contenu de cette page est en anglais). Ces instances pseudo-étiquetées ont été ajoutées à l'ensemble de données et le modèle a été entraîné de nouveau. Cette approche a donné de meilleurs résultats que les précédentes approches de pointe d'adaptation au domaine sur différents ensembles de données.
Quel est le contexte? L'apprentissage par programmes est un domaine largement étudié en apprentissage automatique. Les techniques d'extraction d'échantillons durs et semi-durs sont cruciales pour de nombreuses techniques d'apprentissage métrique profond et d'apprentissage auto-supervisé.
Et puis? De l'apprentissage métrique profond à l'apprentissage par programmes, la mesure de la difficulté des instances d'un ensemble de données est de plus en plus importante pour une grande variété de techniques d'apprentissage automatique. De nombreux ensembles de données concrètes comportent des étiquettes approximatives (lisez : incorrectes) et il est probable (lisez : avec un peu de chance) que le modèle ne classifie jamais « correctement » ces instances. Le domaine de l'identification des instances mal étiquetées utilise des exemples difficiles à ajuster, à réétiqueter ou à supprimer de l'ensemble de données afin d'améliorer les performances du modèle. L'apprentissage par programmes bénéficie de la production d'instances correctement séquencées pour que le modèle puisse apprendre, en trouvant un niveau de difficulté « idéal ». Les instances trop faciles sont un gaspillage de puissance informatique et ne produisent pas de gradients utiles pour les mises à jour de l'apprentissage, tandis que les exemples trop difficiles peuvent être aberrants, mal étiquetés ou simplement peu susceptibles d'être classés correctement. Dans un cas comme dans l'autre, les deux peuvent nuire au modèle et représenter un gaspillage de puissance informatique.
Mais... Bien que la dureté visuelle angulaire soit nouvelle dans sa formulation exacte, l'utilisation de l'angle entre une représentation et son centre de classe véritable, ou des variantes de celui-ci, a déjà existé auparavant. Cependant, c'est le premier travail (à notre connaissance) qui montre une corrélation entre une mesure de dureté et la façon dont les humains peuvent juger une instance comme étant facile ou difficile.
Notre avis : Bien qu'il soit peu probable que la dureté visuelle angulaire soit adoptée comme mesure ultime de la dureté des instances, le but du présent article était de souligner le fait qu'il existe un large corpus de littérature visant à mesurer la difficulté des instances d'apprentissage, et d'utiliser ces renseignements pour éclairer l'apprentissage sous la forme de fonctions de perte, de pseudo-étiquetage, de détection d'anomalies et d'apprentissage par programmes.
Tous les projets d'apprentissage automatique à Statistique Canada sont conçus dans le contexte du Cadre pour l'utilisation des processus d'apprentissage automatique de façon responsable de l'organisme, qui vise à proposer des orientations et des conseils pratiques sur la façon responsable d'élaborer ces processus automatisés.
- Date de modification :