
Série sur les développements en matière d'apprentissage automatique : numéro deux
Par : Nicholas Denis, Statistique Canada
Les sujets du mois :
- Générer des images réalistes à partir de textes
- Fait de la place pour la réduction des dimensions
- Les machines apprennent à coder !
Générer des images réalistes à partir de textes

Figure 1 : Quatre images générés à partir de textes provenant d’utilisateurs
Quatre images côte à côte comme exemples d'images réalistes générées par les chercheurs.
- La première image représente un chat noir qui touche des pions ronds sur un damier. La légende indique "une peinture à l'huile surréaliste et onirique de Salvador Dali représentant un chat jouant aux dames".
- La deuxième image représente un coucher de soleil derrière des canyons désertiques. Légende : "Une photo professionnelle d'un coucher de soleil derrière le Grand Canyon".
- La troisième image représente le portrait d'un hamster vert et bleu avec des ailes de dragon sur un fond rouge. Légende : "Une peinture à l'huile de haute qualité d'un dragon hamster psychédélique".
- La quatrième image représente un portrait d'Albert Einstein dans un costume de Superman. Légende : "une illustration d'Albert Einstein portant un costume de super-héros".
Les chercheurs génèrent des images photo réalistes à partir de textes provenant d'utilisateurs à l'aide d'un modèle de 3,5 milliards de paramètres.
Quoi de neuf? : OpenAI a tiré parti du succès récent de son modèle populaire CLIP (Contrastive Language-Image Pre-training) pour entraîner un modèle de diffusion gaussien capable de générer des images réalistes et nuancées à partir d'un texte décrivant l'image à générer. Le modèle GLIDE (Guided Language to Image Diffusion for generation and Editing), est accessible via Google CoLab.
Comment ça fonctionne : À partir d'une entrée de texte et d'un vecteur de bruit initialement échantillonné de façon aléatoire, , le modèle est capable de « dé-bruiter » séquentiellement l'échantillon à l'étape , conditionné par le texte en entrée et l'échantillon dé-bruité à l'étape précédente . L'image finale dé-bruitée, , est l'image générée finale qui tente de capturer la sémantique du texte fourni par l'utilisateur.
Pourquoi cela fonctionne-t-il ? : Les modèles de diffusion gaussiens sont des processus de bruit additif qui commencent avec une image et produisent une chaîne de Markov d'images de plus en plus bruyantes, où l'image au temps t,
c'est-à-dire que la distribution des images suivantes, conditionnellement à l'image précédente, est normalement distribuée, où est un paramètre de bruit. Le résultat final est une image totalement aléatoire. Sous des conditions modérées, la postérieure est bien définie, et peut donc être approximée avec des réseaux de neurones profonds. Brièvement,
- Le processus inverse représente une manière de supprimer séquentiellement le bruit d'une image, pour arriver à une image photo réaliste et naturelle.
- En partant d'une image naturelle et en y ajoutant un bruit gaussien, ils sont capables d'entraîner un modèle pour estimer le bruit ajouté.
- Les auteurs utilisent d'autres techniques et astuces provenant de diffusion guidée en utilisant la sémantique du texte d'un modèle CLIP.
Résultats : L'évaluation quantitative des modèles génératifs est difficile et reste un problème ouvert. Cependant, la recherche inclut des mesures de performance de pointe. Sur le plan qualitatif, le modèle est capable de produire des images incroyablement nuancées et spécifiques, comme "un dessin au crayon d'un ascenseur spatial" et "un vitrail d'un panda mangeant du bambou". En outre, les auteurs ont demandé à des évaluateurs humains d'examiner les images générées par GLIDE et par d'autres modèles génératifs de pointe. Les humains ont jugé que les images produites par GLIDE étaient plus réalistes que les autres modèles dans 66% à 91% des cas.
Mais... : Il est courant dans les publications sur les modèles génératifs que les auteurs sélectionnent les meilleures données générées à présenter, mais il est également fréquent que les auteurs incluent aussi un échantillon suffisamment grand d'instances sélectionnées au hasard. Cet article aurait pu inclure une galerie beaucoup plus grande d'images sélectionnées au hasard à partager. De plus, le modèle compte 3,5 milliards de paramètres et nécessite un temps considérable (20 secondes) pour générer une seule image, ce qui rend cette approche peu susceptible d'être déployée à grande échelle.
Notre avis : Les modèles génératifs sont de plus en plus puissants et produisent des images de haute qualité qui trompent les humains quant à leur authenticité, et leur qualité ne fera qu'augmenter avec le temps. Voyez si vous pouvez voir la différence ici : which face is real (le contenu de cette page est en anglais). Avec des techniques telles que GLIDE qui peuvent prendre des données et des instructions spécifiques de l'humain pour produire des images arbitraires de haute qualité (et bientôt des vidéos), les questions juridiques, éthiques et de nature probatoire devront être abordées immédiatement.
Tasse-toi l'analyse en composantes principales, fait de la place pour l'apprentissage de la réduction des dimensions
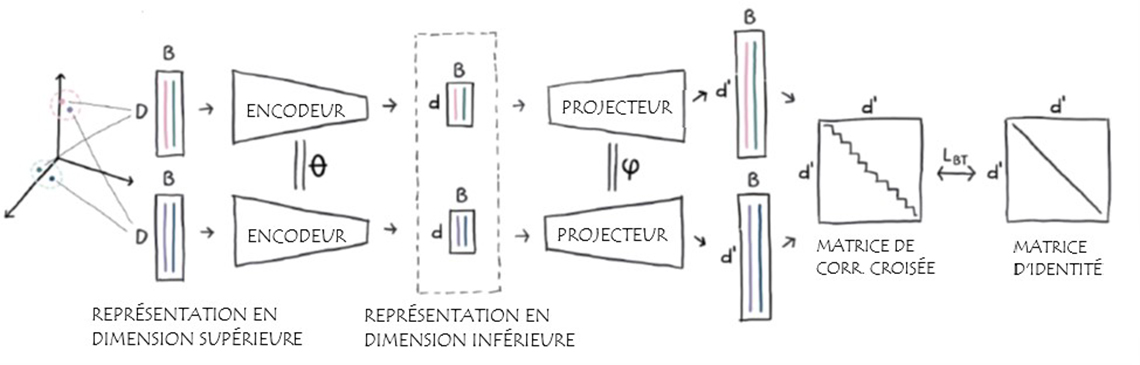
Figure 2 : Représentation en dimension supérieure et inférieure
Étant donné un ensemble de vecteurs dans un espace d'entrée générique, nous utilisons les voisins les plus proches pour définir un ensemble de paires avec une proximité nous voulons préserver. Ensuite, nous apprenons ensuite une fonction de la réduction des dimensions (les encodeurs) qui pousse les voisins les plus proches dans l'espace d'entrée à être représenté similairement. Nous l'apprenons conjointement avec des projecteurs auxiliaires qui produisent des représentations de dimension supérieure, où nous calculons la perte de Barlow Twins sur la matrice de corrélation croisée (d '× d') moyennée sur le lot. (source : Twin Learning for Dimensionality Reduction - le contenu de cette page est en anglais)
TLDR (Twin Learning for Dimensionality Reduction (le contenu de cette page est en anglais)) bat l'analyse en composantes principales (ACP) dans les cas de dimensions de petites et moyennes tailles (8 à 128 dimensions).
Quoi de neuf : Naver Labs a publié TLDR, une technique générale qui utilise un codeur de réduction de dimensionnalité linéaire d'une manière qui pousse les voisins les plus proches dans l'espace d'entrée à être similaires dans l'espace plus petit de représentation.
Comment ça fonctionne ?:
- Pendant l'entraînement, une instance de données particulière dans un des espaces d'entrée de haute dimension est échantillonné et on calcule quels sont ses k voisins les plus proches.
- Une matrice de représentation linéaire fait correspondre l'instance de données et ses voisins à l'espace de dimension inférieure par le biais de la matrice de représentation.
- Les représentations de dimension inférieure sont projetées (via un réseau de projecteurs) dans un espace de dimension beaucoup plus élevée où leur matrice de corrélation croisée est calculée.
- La fonction de perte Barlow Twins récemment proposée est utilisée, ce qui pousse la matrice de corrélation croisée à devenir la matrice d'identité.
- Après l'entraînement, le réseau de projecteurs est éliminé et l'encodeur linéaire est utilisé pour réduire la dimensionnalité.
Pourquoi cela fonctionne-t-il?
- La fonction de perte de Barlow Twins est minimisée lorsque la matrice de corrélation croisée entre les vecteurs est la matrice d'identité. Cela équivaut à une représentation factorisée, où chaque dimension des données est complètement indépendante.
- En minimisant la corrélation croisée entre les dimensions, l'information redondante codée est minimisée, ce qui est une propriété souhaitable pour la réduction de la dimensionnalité.
- En calculant cette perte sur des paires d'entrées qui sont des voisins proches dans l'espace d'entrée, la fonction de représentation linéaire apprend quelque chose de similaire à l'apprentissage des manifolds (voir: Manifold Learning – le contenu de cette page est seulement en anglais), où les points localement proches sont invariants (similaires) dans l'espace de représentation de dimension inférieure.
Résultats : Les auteurs se concentrent sur les tâches de récupération. Étant donné une image ou un document texte en entrée, la tâche de récupération essaie de trouver l'instance ou les instances les plus similaires au texte d'entrée dans un ensemble de données particulier. Notez que pour les images, TLDR a été appliqué aux sorties produites par un modèle de vision pré-entraîné, et pour le texte, TLDR a été appliqué aux sorties produites par un modèle de langage BERT pré-entraîné.
- Sur les ensembles de données de récupération d'images, TLDR a amélioré l'ACP en termes de précision moyenne de 6 à 10%, à travers différentes dimensions de sortie.
- Sur des tâches de récupération test, TLDR a amélioré l'ACP en termes de score de rappel jusqu'à 27%, avec une amélioration de plus en plus spectaculaire à mesure que la taille de la dimension de sortie diminue.
- Comparé à d'autres techniques de réduction de la dimensionnalité, y compris les techniques basées sur les collecteurs, TLDR a constamment surpassé toutes les autres approches pour les dimensions de sortie de huit et plus, mais a été moins performant pour les dimensions de tailles deux et quatre.
Notre avis : Les techniques de réduction de la dimensionnalité sont généralement discutées dans le contexte des ensembles de données tabulaires et pour l'utilisation des techniques classiques d'apprentissage automatique, mais elles ne sont souvent pas utiles pour les données à très haute dimension, comme les images et le texte. TLDR est une technique générale de réduction linéaire de la dimensionnalité qui peut être appliquée à des données tabulaires ou complexes. Cette technique pourrait être utile pour des tâches telles que :
- Tâches de récupération
- Stratégies de sélection d'étiquettes dans l'apprentissage actif
- Exploration des groupements (clustering) et des données
- Utilisation pour des modèles d'apprentissage automatique explicables
Aidez-nous ! Les machines apprennent à coder !
Google DeepMind présente AlphaCode, qui obtient des résultats supérieurs au 50e percentile dans les compétitions de codage.
Quoi de neuf : DeepMind a construit un nouveau jeu de données de programmation compétitive utilisé pour entraîner un modèle de 41 milliards de paramètres qui peut prendre une description textuelle en langage naturel d'un défi de codage (voir figure ci-dessus) et produire un code fonctionnel pour résoudre le défi. C'est de la folie !
Comment ça fonctionne : Les compétitions de codage sont assez courantes. DeepMind a construit plusieurs ensembles de données pour former de manière itérative un réseau neuronal profond capable de prendre un texte en langage naturel décrivant un défi de programmation, comme illustré ci-dessus, et de produire du code, caractère par caractère. Pour ce faire, ils ont d'abord échantillonné un grand nombre de solutions potentielles, puis ils ont procédé à un filtrage et à un regroupement pour éliminer les solutions candidates faibles. Enfin, 10 solutions diverses ont été soumises à un concours réel. Nous détaillons ci-dessous quelques étapes importantes :
- Ils ont construit un ensemble de données de pré-entraînement basé sur un instantané public des dépôts GitHub utilisant le code de 12 langages de programmation populaires, ce qui représente 715 Go de données.
- Ils utilisent un modèle de transformateurs à 41 milliards de paramètres avec une architecture d'encodeur et de décodeur, qui, étant donné une séquence de texte, produira une séquence de texte.
- Le pré-entraînement du modèle consiste à prédire le prochain token (caractère/mot dans le code) en fonction de l'entrée et de la sortie produites jusqu'à présent.
- Une perte standard de modèle de langage masqué (comme dans BERT) a été utilisée, où, étant donné une séquence d'entrées (description du problème en langage naturel), 15% du texte est effacé de manière aléatoire et le modèle doit déduire le texte manquant.
- Le modèle pré-entraîné est affiné sur leur ensemble de données de programmation compétitive. Des objectifs d'entraînement similaires à ceux du pré-entraînement sont utilisés ici.
- Leur modèle est capable d'échantillonner des millions de solutions possibles pour chaque défi soumis en entrée.
- L'apprentissage par renforcement a été utilisé pour augmenter la diversité des solutions échantillonnées par le modèle.
- Étant donné que seules 10 solutions peuvent être soumises par défi, les auteurs filtrent leurs millions de solutions potentielles à travers un certain nombre de tests, fournis dans chaque défi, puis regroupent leurs solutions en fonction du comportement du programme. Une solution parmi les 10 plus grandes grappes a été échantillonnée et soumise comme solution au défi.
Résultats : Le modèle a été appliqué à 10 défis de codage distincts.
- Les auteurs ont constaté que lorsqu'ils échantillonnent 1 million de solutions possibles et soumettent les 10 (estimées comme étant les) meilleures, le code résout avec succès le défi de codage dans plus de 30 % des cas. De plus, le taux de réussite évolue positivement en fonction du nombre de solutions échantillonnées produites ainsi que de la taille du modèle. De plus, les performances en fonction du temps d'entraînement du modèle sont linéaires et aucun plateau n'a été observé, ce qui signifie que si l'entraînement était plus long, le modèle serait plus performant.
- Les auteurs estiment que le modèle, en moyenne, s'est classé dans le 54e percentile supérieur des solutions aux problèmes à coder, juste au-dessus du programmeur médian.
Quel est le contexte? : Bien que cette tâche soit incroyablement difficile et qu'il soit tout simplement stupéfiant qu'un modèle puisse résoudre ne serait-ce qu'une seule tâche, ces résultats ne devraient pas être une surprise. Copilot de Github peut suggérer automatiquement des lignes ou même des fonctions complètes de code. Copilot est construit par OpenAI, qui réalise de nombreux travaux similaires à ceux de cet article. Tout le monde peut utiliser ce service, dès aujourd'hui.
Tout comme certains craignent que la science des données et l'apprentissage automatique n'entraînent l'automatisation des emplois, le code généré automatiquement et l'AutoML pourraient faire craindre aux scientifiques des données eux-mêmes d'être éliminés par l'automatisation !
Notre avis : Il semble que ce n'était qu'hier que le monde s'émerveillait de la capacité des modèles d'AA à déduire la présence d'objets tels que des chats et des chiens dans une image donnée. Aujourd'hui, nous assistons à l'avancée continue de modèles d'AA capables d'extraire et d'abstraire un contenu sémantique incroyablement complexe de longs blocs de texte décrivant des tâches compliquées, puis de produire une syntaxe longue et spécifiquement structurée qui est un code de programmation fonctionnel résolvant la tâche donnée.
Bien que les résultats soient prometteurs et puissent encore être améliorés, ce domaine n'en est qu'à ses débuts et on peut certainement s'attendre à ce que les résultats s'améliorent. Les préoccupations éthiques entrent alors en jeu à différents niveaux. D'une part, quelle est la responsabilité d'un développeur, qui utilise cette technologie pour écrire un code qu'il est incapable de construire lui-même ? Un tel développeur peut-il être en mesure de déboguer ou de s'assurer que le code fait bien ce qu'il est censé faire ?
Figure 3 : Texte en langage naturel généré automatiquement à partir d'un extrait de code
Retour arrière
On vous donne deux séries de caractères s et t, toutes deux composées de lettres minuscules en anglais. Vous allez taper la lettre s caractère par caractère, du premier au dernier.
Lorsque vous tapez un caractère, au lieu d'appuyer sur le bouton qui lui correspond, vous pouvez appuyer sur le bouton « Retour arrière ». Il supprime le dernier caractère que vous avez tapé parmi ceux qui ne sont pas encore supprimés (ou ne fait rien s'il n'y a aucun caractère dans la séquence actuelle). Par exemple, si s est « abcbd » et que vous appuyez sur le bouton « Retour arrière » au lieu de taper le premier et le quatrième caractère, vous obtiendrez la séquence « bd » (la première pression sur le bouton « Retour arrière » ne supprime aucun caractère, et la seconde pression supprime le caractère c). Autre exemple, si s est « abcaa » et que vous appuyez sur Retour arrière au lieu des deux dernières lettres les moins importantes, le texte obtenu est a.
Votre tâche consiste à déterminer si vous pouvez obtenir la lettre t, si vous tapez la lettre s et appuyez sur « Retour arrière » au lieu de taper plusieurs (peut-être zéro) caractères de s.
Entrée
La première ligne contient un seul entier le nombre de cas de test. La première ligne de chaque cas de test contient la lettre . Chaque caractère de est une lettre minuscule en anglais.
La deuxième ligne de chaque scénario de test contient la série . Chaque caractère de est une lettre minuscule anglais.
Il est garanti que le nombre total de caractères dans les séries sur tous les cas de test ne dépasse pas .
Sortie
Pour chaque cas de test, affichez « OUI » si vous pouvez obtenir la lettre t en tapant la lettre s et en remplaçant certains caractères par des appuis sur le bouton « Retour arrière », ou « NON » si vous ne pouvez pas. Vous pouvez afficher chaque lettre dans n'importe quel format (YES, yes, Yes, seront tous reconnus comme réponse positive, NO, no, nO seront tous reconnus comme réponse négative).
1 1=int(input( ) )
2 for i in range(t):
3 s=input( )
4 t=input( )
5 a=[ ]
6 b=[ ]
7 for j in s:
8 a.append(j)
9 for j in t:
10 b.append(j)
11 a.reverse( )
12 b.reverse( )
13 c=[ ]
14 while len(b) !=0 and len(a) !=0
15 if a [0]==b[0]:
16 c.append(b.pop(0))
17 a.pop(0)
18 elif a[0] !=b[0] and len (a) !=1:
19 a.pop(0)
20 a.pop(0)
21 elif a[0] !=b[0] and len(a) ==1:
22 a.pop(0)
23 if len (b) ==0:
24 print ("YES")
25 else:
26 print ("NO")
- Date de modification :