
Études analytiques : méthodes et références
Cohorte du Recensement du Canada de 2001 couplée avec des données fiscales et des données sur la mortalité : un suivi de 10 ans
 Consulter la version la plus récente.
Consulter la version la plus récente.
Information archivée dans le Web
L’information dont il est indiqué qu’elle est archivée est fournie à des fins de référence, de recherche ou de tenue de documents. Elle n’est pas assujettie aux normes Web du gouvernement du Canada et elle n’a pas été modifiée ou mise à jour depuis son archivage. Pour obtenir cette information dans un autre format, veuillez communiquer avec nous.
par Lauren Pinault,
Philippe Finès,
Michael Tjepkema
Division de l’Analyse de la santé, Statistique Canada
et
Félix Labrecque-Synnott,
Abdelnasser Saidi
Division des Méthodes d’enquêtes auprès des ménages, Statistique Canada
Début de l'encadré
Remerciements
Les auteurs tiennent à souligner l’apport de Saeeda Khan et de Radivoje Bradic lors de la validation manuelle de la cohorte, et ils remercient également Jacques Dubois et Barry Zaid de leur aide en vue d’accéder aux fichiers de microfiches du recensement pour la validation manuelle.
Fin de l'encadré
Résumé
De grandes cohortes de mortalité nationales sont utilisées pour estimer les taux de mortalité de différents groupes socioéconomiques et démographiques ainsi que pour effectuer des recherches dans le domaine de la santé environnementale. En 2008, Statistique Canada a créé une cohorte en couplant des données du Recensement de 1991 avec des données sur la mortalité. La présente étude décrit le couplage des données des répondants âgés de 19 ans et plus ayant rempli le questionnaire détaillé du Recensement de 2001 avec les données du Fichier maître des particuliers T1 et la Base de données combinées sur la mortalité. Ce couplage permet de faire le suivi de tous les décès survenus sur une période de 10,6 ans (pour le moment jusqu’à la fin de 2011). Des statistiques sur la mortalité ont été calculées pour la cohorte, et les résultats correspondent généralement à ce à quoi on s’attendait, si on considère les tables de mortalité du Canada à partir de la valeur médiane de la période de suivi (2005 à 2007) et la cohorte du Recensement de 1991. L’étude a pour but d’informer les utilisateurs de la représentativité de la cohorte par suite des étapes du processus de couplage (c’est-à-dire le couplage avec les fichiers de données fiscales T1).
Mots clés : recensement, cohorte, mortalité, Base de données combinées sur la mortalité, couplage de données, taux de mortalité normalisé selon l’âge, survie
1. Introduction
Dans différents pays, on a eu recours à de vastes cohortes liées à la santé et représentatives de la population nationale afin d’estimer les résultats en matière de mortalité en tenant compte des différences de situation socioéconomique (p. ex., Blakely et coll., 2002; Stringhini et coll., 2012; Lazzarino et coll., 2013; Mishra et coll., 2013; Cho et coll., 2016). En général, des taux de mortalité plus élevés ont été relevés parmi les personnes dont la situation socioéconomique est moins favorable (p. ex., un niveau de scolarité plus faible ou une profession de statut inférieur).
Au Canada, une cohorte de mortalité largement représentative de la population nationale a été créée par couplage des données des répondants ayant rempli le questionnaire détaillé du Recensement de 1991 avec celles de la Base canadienne de données sur la mortalité (BCDM) et des fichiers de données fiscales T1. Cette cohorte a ensuite été utilisée pour estimer les taux de mortalité au Canada au cours de la période allant de 1991 à 2001 (Wilkins et coll., 2008), et le suivi de la mortalité a depuis été prolongé jusqu’à la fin de 2011. La cohorte a aussi fait l’objet d’un couplage spatial avec des ensembles de données environnementales, et on y a eu recours dans le cadre de plusieurs études sur la santé environnementale (p. ex., Crouse et coll., 2012; Crouse et coll., 2015; Weichenthal et coll., 2016). On appelle également cette cohorte la Cohorte santé et environnement du recensement canadien dans les ouvrages publiés.
Bien que la cohorte d’origine fournisse un échantillon largement représentatif pour des études épidémiologiques, elle se compose de personnes qui étaient âgées de 25 ans et plus lors de l’année de référence (1991). La population faisant partie de cette cohorte a vieilli depuis, les répondants les plus jeunes étant âgés de 45 ans à la fin de la période de suivi, en 2011. On constitue donc des ensembles de données environnementales plus récents qui nécessitent une population de référence plus jeune à des fins d’évaluation de l’exposition. Une nouvelle cohorte fondée sur une année de recensement plus récente concorderait davantage avec l’année de ces ensembles de données environnementales. Le Recensement de 2001 a été choisi parce qu’il est plus récent que celui de 1991, mais aussi parce qu’il permet de faire un suivi de la mortalité sur un certain nombre d’années.
L’objet du présent document est de décrire la cohorte constituée par couplage des données du recensement, des données fiscales et des données sur la mortalité, plus précisément le couplage de 3,5 millions de répondants ayant rempli le questionnaire détaillé du Recensement de 2001 avec le Fichier maître des particuliers T1, qui comprend les numéros d’assurance sociale (NAS). Les NAS ont servi à coupler les membres de la cohorte du Recensement de 2001 avec la Base de données combinées sur la mortalité (BDCM); les membres de la cohorte ont fait l’objet d’un suivi de la mortalité jusqu’au 31 décembre 2011 (347 000 décès). La méthodologie de couplage utilisée est similaire à celle employée pour la cohorte du Recensement de 1991 (Statistique Canada, 2015b), à l’exception de certaines différences précisées plus loin. Les résultats obtenus donnent un aperçu des différences connues entre la cohorte et la population générale ainsi que des profils généraux de mortalité qui ressortent de l’ensemble de données selon différents groupes socioéconomiques et démographiques.
2. Données
Le Recensement de la population de 2001, qui a été mené au Canada le 15 mai 2001, a servi à dénombrer l’ensemble de la population du Canada, laquelle est formée des citoyens, des immigrants reçus et des résidents non permanents. Comparativement au questionnaire abrégé de base du recensement (formulaire 2A), qui est transmis à la plupart des ménages, le questionnaire détaillé (formulaires 2B et 2D) permet de recueillir un plus large éventail de données socioéconomiques et démographiques, et il est envoyé à environ 20 % des ménages canadiens. Dans les régions éloignées et les réserves indiennes dénombrées, tous les ménages reçoivent le questionnaire détaillé (cela représente à peu près 2 % de la population canadienne). Le taux de sous-dénombrement brut (c.-à-d. le nombre total de personnes au sein des ménages qui ont été oubliées) lors du Recensement de 2001 est estimé à 3,95 % (soit quelque 1 222 300 personnes). Le sous-dénombrement était plus élevé parmi les jeunes adultes (de 20 à 34 ans), les personnes qui étaient divorcées ou qui n’avaient jamais été mariées, et les personnes dont la langue maternelle était autre que le français ou l’anglais (Statistique Canada, 2003, 2014).
Les fichiers de données fiscales T1 de 2000 et de 2001 (provenant du Fichier maître des particuliers T1) ont été utilisés pour une étape du processus de couplage afin de coupler les répondants au recensement avec les enregistrements sur la mortalité au moyen de leur NAS. Les fichiers de données fiscales T1 ont été fournis par l’Agence du revenu du Canada et ont fait l’objet d’un prétraitement en prévision du couplage par Statistique Canada. Ces fichiers comprennent le NAS, un numéro d’identification temporaire et, le cas échéant, un numéro d’identification des personnes à charge. Les fichiers de données fiscales T1 (du Fichier maître des particuliers T1) ont aussi servi à établir l’historique des codes postaux des déclarants de 1981 à 2011, afin que les chercheurs puissent prendre en compte les changements de lieu de résidence au fil du temps.
Les données sur la mortalité ont été obtenues à partir de la BDCM, version 2014b (Mayer et Charbonneau, 2015). La BDCM est le produit d’un couplage antérieur entre la BCDM et des fichiers fiscaux (dont le fichier T1 décrit précédemment, les fichiers d’impôt sur le revenu T4 et des fichiers relatifs au crédit d’impôt lié à un fonds de travailleurs et à la prestation fiscale pour enfants). La BCDM est le fruit de la fusion des registres provinciaux et territoriaux des décès. Elle comprend les données des hôpitaux sur les décès survenus entre 1950 et 2011 (données disponibles à l’heure actuelle) de même que des données sur la cause initiale de décès et la confirmation de la cause du décès par autopsie; ces renseignements étant requis pour les analyses de la mortalité attribuable à des causes particulières. Sauf quelques exceptions, la BCDM ne comporte pas de données sur les décès survenus à l’extérieur du Canada ni sur ceux qui n’ont pas été confirmés par un professionnel de la santé (ce qui survient parfois dans des régions éloignées). La BDCM est un ensemble de données couplées sur tous les décès créé à partir de la BCDM et des fichiers fiscaux, et elle comprend le NAS (tiré des fichiers de données fiscales T1) ainsi qu’une date de décès « consolidée », où la date enregistrée dans la BCDM prévaut sur celle indiquée dans les fichiers de données fiscales.
3. Méthodes
3.1 Couplage
Le Conseil exécutif de gestion de Statistique Canada a approuvé le couplage d’enregistrements en 2015 (couplage d’enregistrements no 045-2015). La première étape du projet a consisté à coupler les données des répondants au recensement avec les fichiers de données fiscales T1 afin d’associer un NAS aux répondants. La deuxième étape a été d’utiliser les NAS pour apparier les enregistrements avec les décès enregistrés dans la BDCM.
Lors de la première étape du projet de couplage, on a d’abord eu recours à des groupes de couplage déterministe, puis à des groupes de couplage probabiliste. Un premier couplage a été effectué entre tous les répondants au Recensement de 2001 (aussi bien ceux ayant rempli le questionnaire détaillé que ceux ayant rempli le questionnaire abrégé) et les enregistrements fiscaux T1 de 2000 et de 2001 en fonction de trois groupes de couplage déterministe. Dans le premier groupe, les clés de couplage entre les deux ensembles de données étaient le sexe, la date de naissance, le code postal en 2001 et l’état matrimonial. Le deuxième groupe était semblable au premier, sauf qu’il ne comprenait pas l’état matrimonial. Dans le troisième groupe, on utilisait le sexe, la date de naissance et le code postal en 2000. Dans chaque groupe de couplage déterministe, seuls les enregistrements où la combinaison de clés était la même dans les fichiers fiscaux et dans les fichiers du recensement ont été conservés dans la cohorte. Les enregistrements en double et les non-appariements ont été pris en compte dans les groupes de couplage subséquents. Les répondants ayant rempli le questionnaire abrégé du recensement ont été pris en compte à cette étape afin de réduire le nombre d’enregistrements à prendre en considération lors du couplage probabiliste et le nombre d’appariements faussement positifs.
Les enregistrements de tous les répondants ayant rempli le questionnaire détaillé du recensement qui n’ont pas été couplés dans les groupes de couplage déterministe ont ensuite été considérés dans plusieurs groupes assortis des poids de couplage les plus élevés, selon une méthodologie de couplage probabiliste fondée sur la théorie du couplage d’enregistrements de Fellegi-Sunter (Fellegi et Sunter, 1969). Les variables utilisées pour le couplage probabiliste étaient la date de naissance, la date de naissance du conjoint (le cas échéant), le sexe, l’état matrimonial, le code postal et l’appartenance à la population rurale ou urbaine d’après le code postal. On a ainsi examiné séquentiellement huit groupes de couplage probabiliste selon les fourchettes de poids de couplage. Afin de déterminer le seuil de couplage et les groupes à inclure dans la cohorte, l’exactitude du couplage a fait l’objet d’estimations pour tous les groupes de couplage possibles en vérifiant un échantillon aléatoire d’enregistrements couplés par rapport aux originaux numérisés des questionnaires du recensement. Lorsque le nom et la date de naissance d’un répondant concordaient (des différences d’orthographe mineures étant tolérées), on considérait qu’il y avait appariement. Les groupes dont 90 % des enregistrements ne donnaient pas lieu à un appariement n’ont pas été incorporés à la cohorte. De ce fait, six groupes ont fait l’objet du couplage probabiliste final.
La cohorte initiale a été constituée en combinant les couplages déterministes des répondants ayant rempli le questionnaire détaillé et les couplages probabilistes. Les personnes résidant dans des logements collectifs institutionnels ont alors été exclues, parce que les questions sur les caractéristiques socioéconomiques et démographiques ne leur ont pas été posées. La majorité des membres de la cohorte (92,6 %) ont été couplés par voie de couplage déterministe, et 99,9 % des enregistrements étaient considérés comme étant de vrais couplages (n = 169 examens manuels d’enregistrements). Une proportion plus faible de membres de la cohorte (7,4 %) ont été couplés dans les six premiers groupes de couplage probabiliste, et 98,9 % d’entre eux étaient estimés être de vrais couplages (n = 478 examens manuels d’enregistrements). La taille finale de la cohorte aux fins d’analyse comptait 3 537 490 membres, et on estimait que 99,8 % des enregistrements étaient de vrais couplages (c’est-à-dire que le taux d’erreur de résultats faussement positifs était inférieur à 0,2 %).
Au total, 4 500 245 des 6 448 980 répondants ayant rempli le questionnaire détaillé du Recensement de 2001 (formulaire 2B ou 2D) étaient considérées comme faisant partie de la population visée. Cette dernière excluait les personnes vivant en établissement ou résidant à l’étranger ainsi que les personnes qui avaient moins de 19 ans le jour du recensement. Les répondants plus jeunes ont été exclus en raison d’un taux de couplage avec les enregistrements fiscaux T1 beaucoup plus faible (données non présentées). Les tailles d’échantillon de toutes les personnes exclues sont présentées à l’intérieur d’un diagramme à la figure 1.
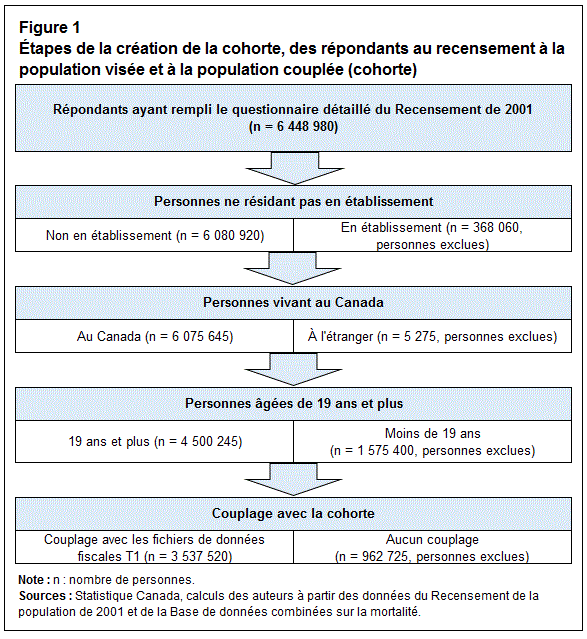
Description du Figure 1
La figure 1 est intitulée « Étapes de la création de la cohorte, des répondants au recensement à la population visée et à la population couplée (cohorte) ».
Il s’agit d’un diagramme qui présente cinq étapes en vue d’établir le nombre de personnes faisant partie de la population couplée (cohorte). Étape 1 – Répondants ayant rempli le questionnaire détaillé du Recensement de 2001 : c’est à cette étape qu’est déterminé le nombre de personnes ayant répondu au questionnaire (6 448 980 personnes). Étape 2 – Personnes ne résidant pas en établissement : les personnes résidant en établissement (368 060) sont exclues de la population, qui compte désormais 6 080 920 personnes (ne résidant pas en établissement). Étape 3 – Personnes vivant au Canada : les personnes vivant à l’étranger (5 275) sont exclues de la population, qui comprend ainsi 6 075 645 personnes (vivant au Canada). Étape 4 – Personnes âgées de 19 ans et plus : les personnes ayant moins de 19 ans (1 575 400) sont exclues de la population, qui s’établit maintenant à 4 500 245 personnes (âgées de 19 ans et plus). Étape 5 – Couplage avec la cohorte : les personnes non couplées avec les fichiers de données fiscales T1 (962 725) sont exclues de la population. Cette dernière, qui était composée au départ de 6 448 980 répondants au questionnaire détaillé du Recensement de 2001, est constituée à la fin du processus de 3 537 520 personnes couplées aux fichiers de données fiscales T1.
Les auteurs ont calculé ces chiffres à partir des données du Recensement de la population de 2001 et de la Base de données combinées sur la mortalité de 2014.
On estime que 78,6 % des répondants au Recensement de 2001 faisant partie de la population visée (n = 3 537 520 ou 15,1 % de la population âgée de 19 ans et plus) ont été couplés avec la cohorte (c’est-à-dire avec les fichiers de données fiscales T1). Ce pourcentage était similaire à celui obtenu pour la cohorte du Recensement de la population de 1991, où il s’était chiffré à 80,0 % (avant l’élimination d’un échantillon aléatoire afin d’obtenir un échantillon correspondant à 15 % de la population canadienne) (Statistique Canada, 2015b). Afin d’examiner les différences éventuelles entre la cohorte couplée et la population visée, le nombre de répondants ayant certaines caractéristiques socioéconomiques et démographiques données a été calculé pour chaque groupe, et les résultats ainsi obtenus ont fait l’objet de comparaisons.
La deuxième étape consistait à coupler la cohorte avec la BDCM au moyen des NAS, qui ont d’abord été incorporés à la cohorte par couplage avec les enregistrements T1. Le couplage des fichiers de données fiscales T1 à la cohorte au moyen des NAS a aussi permis d’obtenir les codes postaux historiques compilés par l’Agence du revenu du Canada. Ces données supplémentaires permettent d’améliorer les estimations de l’exposition à l’environnement en tenant compte des changements de lieu de résidence au fil du temps (de 1981 à 2011).
3.2 Fichier analytique
Le fichier analytique comprenait toutes les variables à propos desquelles des données étaient recueillies dans le questionnaire détaillé du recensement, notamment le contenu portant sur l’emploi, l’éducation, le revenu, la profession, le statut d’immigrant, la taille de la collectivité, l’identité autochtone et l’appartenance à une minorité visible. Il y a quelques différences importantes dans les définitions des variables entre la cohorte de 1991 et celle de 2001. En 1991, l’identité autochtone était déterminée d’après la réponse à la question sur l’origine ethnique. Pour sa part, le Recensement de 2001 comportait une question sur la perception qu’a le répondant de son identité autochtone (Statistique Canada, 2003). De même, l’appartenance à une minorité visible était déterminée au moyen d’une question portant directement sur le sujet en 2001, alors qu’elle était plutôt inférée en 1991 à partir des réponses à d’autres questions, notamment sur l’origine ethnique et les ancêtres (Statistique Canada, 2003).
Plusieurs variables dérivées des variables du recensement ont été créées dans le fichier analytique au moyen de méthodes décrites par Wilkins et coll. (2008). La situation d’emploi a été subdivisée en trois catégories : a un emploi; sans emploi; inactif. Le niveau de scolarité comporte quatre catégories : pas de diplôme d’études secondaires; diplôme d’études secondaires, avec ou sans certificat d’une école de métiers; certificat ou diplôme postsecondaire (non universitaire); diplôme universitaire. Il y a cinq catégories de professions (postes professionnels; postes de gestion; postes spécialisés, techniques ou de supervision; postes de spécialisation moyenne; postes non spécialisés) et une catégorie pour les personnes sans profession, d’après la variable de la Classification nationale des professions et selon les mêmes critères que ceux utilisés en 1991.
Des quintiles (et des déciles) de suffisance du revenu ont été créés au moyen de la méthodologie utilisée par Wilkins et coll. (2008). On a d’abord calculé le ratio du revenu avant impôt des familles économiques (ou des personnes hors famille économique) au seuil de faible revenu de Statistique Canada selon la taille de la famille et de la collectivité. Ce ratio a ensuite servi à déterminer les quintiles et les déciles à l’échelle nationale et à l’intérieur de chaque région métropolitaine de recensement, agglomération de recensement ou région rurale et petite ville. Les ratios de suffisance du revenu établis en fonction des régions prennent en compte les différences régionales en ce qui a trait à la situation économique des familles, comme le coût des logements.
Pour chaque décès survenu durant la période de suivi, l’ensemble de données de la BDCM comprend la date du décès enregistrée dans la BDCM (n = 347 000 décès). Pour chaque décès enregistré dans la BCDM (96,6 % de tous les décès), l’ensemble de données comporte aussi la cause initiale du décès, codée selon la Classification internationale des maladies de l’Organisation mondiale de la Santé, dixième révision (CIM-10) (Organisation mondiale de la Santé 1992). On y trouve en outre une variable indiquant les décès confirmés par autopsie. Il n’y a pas de données sur la cause du décès dans le cas des quelque 11 800 décès qui ont été enregistrés uniquement dans les fichiers de données fiscales T1. Pour un petit nombre de décès (environ 200), soit la date de décès enregistrée dans la BDCM était incomplète, soit le décès s’était produit au tout début de la période de suivi; ces décès n’ont pas été pris en compte dans les analyses de la mortalité. Pour cette raison et aussi à cause de différences dans les limites d’âge utilisées, les sommes des décès diffèrent légèrement des chiffres mentionnés dans l’aperçu de la cohorte.
3.3 Analyses de la mortalité
Pour chaque membre de la cohorte, on a calculé les personnes-années à risque d’après le nombre d’années de la période de suivi à partir du jour du recensement (le 15 mai 2001) jusqu’au décès (d’après la date de décès indiquée dans la BDCM) ou jusqu’à la fin de la période de suivi (le 31 décembre 2011) si la personne n’était pas décédée. Le nombre de personnes-années à risque dans le cas des membres de la cohorte qui n’étaient pas décédés s’établissait à 10,6 ans.
À titre de méthode de validation externe, on a calculé le pourcentage des membres de la cohorte ayant survécu jusqu’à la fin de la période de suivi pour chaque année d’âge (à la date de référence) ainsi que pour chaque sexe. La courbe de survie ainsi obtenue a été comparée au pourcentage de survie prévu en fonction d’une période de 10,6 ans d’après les tables de mortalité du Canada pour 2005 à 2007 (Statistique Canada, 2013).
Des tables de mortalité abrégées ont été élaborées afin d’estimer l’espérance de vie restante à l’âge de 25 ans, selon le sexe ainsi que selon le niveau de scolarité, le quintile de suffisance du revenu, l’identité autochtone et l’appartenance à une minorité visible. Au moyen des méthodes décrites par Chiang (1984), des tables de mortalité ont été déterminées selon des intervalles d’âge de cinq ans à l’égard des membres de la cohorte âgés de 20 à 100 ans.
Les taux de mortalité normalisés selon l’âge (TMNA) ont été calculés en fonction de la population âgée de 20 à 100 ans selon le sexe et l’âge (groupes d’âge par intervalles de cinq ans à la date de référence) pour différents groupes socioéconomiques et démographiques. À partir de la population canadienne type de 1991, on a calculé des poids standard pour la plupart des groupes de population. En ce qui concerne l’identité autochtone, des poids internes ont été calculés d’après la population autochtone à l’intérieur du même ensemble de données, puisque la structure par âge des populations autochtones au Canada diffère de celle de la population générale. Les intervalles de confiance à 95 % ont été calculés de la manière décrite par Carrière et Roos (1997). Des rapports de taux (RT) et des écarts de taux (ET) des TMNA ont été calculés selon une méthode similaire.
Des rapports de risques proportionnels de Cox ont été calculés à l’égard de la mortalité toutes causes confondues, pour les hommes et les femmes pris ensemble ainsi que séparément, selon différents groupes socioéconomiques et démographiques (Cox, 1972). Les rapports de risques ont été corrigés selon l’âge (intervalles de cinq ans) et selon le sexe pour la cohorte dans son ensemble.
Enfin, le nombre de décès à l’intérieur de la cohorte au cours de la période de suivi a été déterminé selon certaines causes de décès suivant les codes de la CIM-10. On a calculé la proportion de chaque cause de décès par rapport aux décès de la BCDM (pour lesquels un code de la CIM-10 était fourni).
Tous les chiffres (y compris ceux présentés à la figure 1 et dans tous les tableaux) ont été arrondis de façon aléatoire à un multiple de cinq afin de préserver la confidentialité dans les travaux d’analyse.4. Résultats
4.1 Caractéristiques de la cohorte
Au total, 3 537 520 personnes (soit 79 % des répondants faisant partie de la population visée qui ont rempli les formulaires 2B et 2D du Recensement de 2001) ont été couplées aux fichiers de données fiscales T1 (pour 2000 et 2001) et ont fait l’objet d’un suivi de la mortalité jusqu’à la fin de la période de suivi (10,6 ans). Le pourcentage de répondants couplés variait selon le groupe démographique et socioéconomique. Le tableau 1 donne un aperçu des répondants faisant partie de la population visée selon certaines caractéristiques, du nombre de personnes dans la cohorte et du pourcentage de la cohorte dans la population visée (selon les mêmes caractéristiques). Le taux de réussite du couplage avec les fichiers de données fiscales (et la cohorte) était plus faible chez les personnes plus jeunes (66 % dans le cas des personnes âgées de 19 à 24 ans) et celles ayant une identité autochtone quelconque (64 %). Comme on pouvait s’y attendre, les pourcentages de couplage étaient plus faibles dans le cas des personnes ayant déménagé au cours de la dernière année (63 %), car ces personnes étaient moins susceptibles d’être appariées selon un code postal, le code postal étant l’une des clés de couplage (tableau 1).
4.2 Analyses de la mortalité
Le graphique 1 présente une mesure servant à valider la survie à l’intérieur de la cohorte. Pour chaque âge à la date de référence et pour chaque sexe, le pourcentage des répondants faisant partie de la cohorte qui ont survécu jusqu’à la fin de la période de suivi (10,6 ans) a été comparé au même pourcentage calculé relativement à la même période d’après les tables de mortalité du Canada pour 2005 à 2007. Les courbes de survie des estimations de la cohorte et des tables de mortalité étaient presque identiques pour les hommes et pour les femmes, si ce n’est quelques différences mineures chez les personnes plus âgées (80 ans et plus). Ces différences tiennent probablement à la taille beaucoup plus petite de la cohorte et à l’exclusion des adultes vivant en établissement, par exemple les personnes âgées résidant dans un établissement de soins infirmiers.
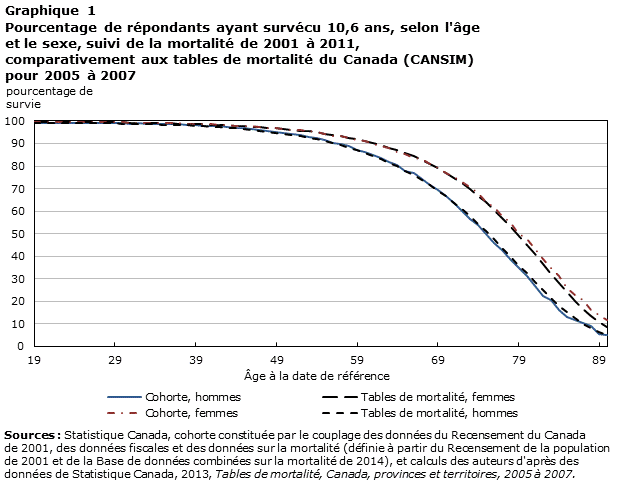
Tableau de données du Graphique 1
| Age | Table de mortalité, hommes | Cohorte, hommes | Tables de mortalité, femmes | Cohorte, femmes |
|---|---|---|---|---|
| pourcentage de survie | ||||
| 19 | 99,13 | 99,04 | 99,67 | 99,56 |
| 20 | 99,12 | 99,10 | 99,66 | 99,58 |
| 21 | 99,12 | 99,04 | 99,66 | 99,60 |
| 22 | 99,12 | 99,05 | 99,65 | 99,53 |
| 23 | 99,12 | 99,02 | 99,63 | 99,55 |
| 24 | 99,11 | 99,16 | 99,61 | 99,61 |
| 25 | 99,09 | 99,10 | 99,59 | 99,47 |
| 26 | 99,06 | 99,00 | 99,56 | 99,50 |
| 27 | 99,02 | 99,07 | 99,52 | 99,39 |
| 28 | 98,98 | 98,97 | 99,48 | 99,41 |
| 29 | 98,92 | 98,99 | 99,43 | 99,49 |
| 30 | 98,86 | 98,92 | 99,38 | 99,39 |
| 31 | 98,79 | 98,88 | 99,32 | 99,22 |
| 32 | 98,71 | 98,91 | 99,26 | 99,24 |
| 33 | 98,62 | 98,74 | 99,20 | 99,16 |
| 34 | 98,53 | 98,75 | 99,12 | 99,07 |
| 35 | 98,42 | 98,59 | 99,04 | 99,10 |
| 36 | 98,30 | 98,57 | 98,95 | 98,92 |
| 37 | 98,17 | 98,44 | 98,86 | 98,89 |
| 38 | 98,02 | 98,26 | 98,75 | 98,69 |
| 39 | 97,86 | 98,10 | 98,64 | 98,72 |
| 40 | 97,68 | 97,94 | 98,52 | 98,65 |
| 41 | 97,48 | 97,64 | 98,38 | 98,46 |
| 42 | 97,25 | 97,59 | 98,24 | 98,03 |
| 43 | 97,00 | 97,18 | 98,08 | 98,00 |
| 44 | 96,72 | 96,93 | 97,90 | 97,89 |
| 45 | 96,41 | 96,75 | 97,71 | 97,68 |
| 46 | 96,07 | 96,32 | 97,51 | 97,62 |
| 47 | 95,69 | 95,97 | 97,28 | 97,20 |
| 48 | 95,28 | 95,74 | 97,03 | 97,00 |
| 49 | 94,82 | 94,94 | 96,75 | 96,78 |
| 50 | 94,32 | 94,67 | 96,45 | 96,54 |
| 51 | 93,77 | 94,21 | 96,11 | 95,98 |
| 52 | 93,17 | 93,61 | 95,75 | 95,83 |
| 53 | 92,51 | 93,07 | 95,34 | 95,53 |
| 54 | 91,78 | 92,29 | 94,90 | 94,92 |
| 55 | 91,00 | 91,47 | 94,41 | 94,26 |
| 56 | 90,13 | 90,42 | 93,87 | 93,44 |
| 57 | 89,19 | 89,73 | 93,27 | 93,14 |
| 58 | 88,16 | 88,98 | 92,61 | 92,46 |
| 59 | 87,04 | 87,32 | 91,89 | 91,60 |
| 60 | 85,82 | 86,38 | 91,09 | 90,92 |
| 61 | 84,50 | 84,78 | 90,21 | 89,59 |
| 62 | 83,05 | 83,57 | 89,24 | 88,98 |
| 63 | 81,49 | 81,91 | 88,18 | 88,00 |
| 64 | 79,79 | 80,49 | 87,00 | 86,39 |
| 65 | 77,96 | 77,99 | 85,71 | 85,37 |
| 66 | 75,98 | 76,76 | 84,28 | 83,66 |
| 67 | 73,85 | 74,46 | 82,72 | 82,95 |
| 68 | 71,57 | 71,78 | 81,01 | 80,76 |
| 69 | 69,12 | 69,29 | 79,13 | 78,94 |
| 70 | 66,50 | 66,88 | 77,08 | 76,74 |
| 71 | 63,72 | 63,53 | 74,84 | 75,00 |
| 72 | 60,76 | 60,19 | 72,41 | 73,08 |
| 73 | 57,65 | 56,63 | 69,76 | 70,49 |
| 74 | 54,38 | 53,80 | 66,90 | 68,18 |
| 75 | 50,96 | 50,03 | 63,81 | 64,10 |
| 76 | 47,40 | 45,67 | 60,50 | 61,60 |
| 77 | 43,74 | 42,71 | 56,96 | 57,82 |
| 78 | 39,99 | 38,60 | 53,21 | 55,16 |
| 79 | 36,19 | 35,30 | 49,26 | 50,35 |
| 80 | 32,37 | 31,12 | 45,12 | 47,62 |
| 81 | 28,58 | 26,61 | 40,85 | 43,13 |
| 82 | 24,88 | 22,14 | 36,51 | 38,69 |
| 83 | 21,35 | 20,71 | 32,17 | 34,62 |
| 84 | 18,05 | 16,06 | 27,94 | 31,10 |
| 85 | 15,05 | 13,12 | 23,87 | 25,65 |
| 86 | 12,38 | 11,64 | 20,06 | 22,82 |
| 87 | 10,03 | 10,11 | 16,57 | 20,35 |
| 88 | 8,01 | 8,81 | 13,45 | 16,00 |
| 89 | 6,30 | 5,29 | 10,73 | 13,97 |
| 90 | 4,89 | 4,90 | 8,41 | 11,64 |
|
Sources : Statistique Canada, cohorte constituée par le couplage des données du Recensement du Canada de 2001, des données fiscales et des données sur la mortalité (définie à partir du Recensement de la population de 2001 et de la Base de données combinées sur la mortalité de 2014), et calculs des auteurs d'après des données de Statistique Canada, 2013, Tables de mortalité, Canada, provinces et territoires, 2005 à 2007. |
||||
L’espérance de vie restante à l’âge de 25 ans était de 56,8 ans pour les deux sexes combinés, de 54,6 ans pour les hommes et de 59,0 ans pour les femmes (tableau 2). Comme on pouvait s’y attendre, l’espérance de vie restante était plus longue dans le cas des personnes ayant un niveau de scolarité plus élevé, des personnes faisant partie d’un quintile de suffisance du revenu plus élevé et de celles appartenant à une minorité visible. Il y avait certains écarts notables dans l’espérance de vie, soit 6,7 ans entre les hommes ayant le niveau de scolarité le plus faible et ceux ayant le niveau de scolarité le plus élevé, et 6,8 ans entre les hommes au revenu le plus faible et ceux au revenu le plus élevé.
Des écarts importants en ce qui a trait à l’espérance de vie restante à l’âge de 25 ans ont été observés entre les personnes autochtones et les autres personnes, soit 5,9 ans pour les hommes et 7,0 ans pour les femmes. Comparativement aux personnes non autochtones, les personnes du groupe des Métis affichaient l’écart le moins important (4,2 ans pour les hommes et 4,1 ans pour les femmes), tandis que le groupe des Inuits était celui où l’écart était le plus marqué (9,7 ans pour les hommes et 11,5 ans pour les femmes. L’espérance de vie restante à l’âge de 25 ans était plus courte pour les Inuits que pour tous les autres groupes examinés, s’établissant à 45,2 ans pour les hommes et à 47,8 ans pour les femmes (tableau 2).
Des TMNA, des RT et des ET ont été calculés pour différents groupes socioéconomiques et démographiques. Les taux de mortalité les plus élevés étaient associés aux personnes qui n’avaient pas d’emploi, à celles dont le niveau de scolarité était peu élevé, à celles dont la profession avait un statut inférieur (ou qui étaient sans profession) et à celles qui avaient un faible revenu. Cette tendance était observée à la fois chez les hommes et chez les femmes (tableaux 3 et 4). Les gradients socioéconomiques de la mortalité étaient plus prononcés chez les hommes que chez les femmes pour la totalité de ces caractéristiques (tableaux 3 et 4).
Les TMNA, les RT et les ET indiquent que les membres de la cohorte ayant une identité autochtone affichaient des taux de mortalité plus élevés, en particulier les répondants inuits (tableaux 3 et 4). Contrairement à ce que l’on a observé pour les indicateurs socioéconomiques, les écarts de mortalité (rapports de taux) entre les personnes non autochtones et les personnes autochtones (y compris les personnes identifiées comme étant uniquement Indiens de l’Amérique du Nord, Métis ou Inuits) étaient plus grands chez les femmes que chez les hommes (tableaux 3 et 4).
Les TMNA, les RT et les ET des personnes appartenant à une minorité visible étaient plus bas que pour les autres personnes, et les écarts de taux étaient similaires pour les hommes et pour les femmes. Les Chinois et les Asiatiques du Sud-Est, tant les hommes que les femmes, étaient ceux dont les taux de mortalité étaient les plus faibles (tableaux 3 et 4). Pour ce groupe de membres de minorités visibles, aucune distinction n’a été établie entre les personnes nées à l’étranger et celles nées au Canada.
Les TMNA, les RT et les ET étaient plus faibles pour les immigrants que pour la population née au Canada, et l’effet de ce facteur était particulièrement marqué pour les hommes et les femmes ayant immigré au cours des années les plus récentes (tableaux 3 et 4).
Les membres de la cohorte vivant en région urbaine avaient le taux de mortalité le plus faible (selon le TMNA, le RT et l’ET), et la mortalité tendait à augmenter à mesure que la taille de la collectivité diminuait. L’écart était légèrement plus important pour les hommes que pour les femmes (tableaux 3 et 4).
Les rapports de risques proportionnels de Cox ont été calculés pour les mêmes groupes socioéconomiques et démographiques que ceux des tableaux 3 et 4, et les profils de mortalité étaient semblables à ceux mentionnés dans les analyses antérieures. Le risque de mortalité était plus élevé dans le cas des personnes qui n’avaient pas d’emploi, qui avaient un niveau de scolarité plus faible, qui faisaient partie des quintiles de revenu les moins élevés ou qui exerçaient une profession de statut inférieur. On notait un risque de mortalité plus élevé chez les personnes autochtones que chez les personnes non autochtones, et un tel risque était également plus élevé chez les personnes n’appartenant pas à une minorité visible que chez celles appartenant à une minorité visible (tableau 5).
Le tableau 6 présente le nombre de décès attribuables à différentes causes. Environ 34,4 % des décès de membres de la cohorte survenus durant la période de suivi et enregistrés dans la BCDM avaient été causés par le cancer (tumeurs), 30,4 %, par des maladies de l’appareil circulatoire et 8,4 %, par des maladies de l’appareil respiratoire, tandis que 5,5 % étaient attribuables à des causes externes, notamment des blessures accidentelles et intentionnelles.
5. Discussion
Les analyses de la mortalité portant sur la cohorte constituée par le couplage des données du Recensement du Canada de 2001, des données fiscales et des données sur la mortalité (cohorte du Recensement de 2001) montrent que les taux de mortalité étaient généralement plus élevés chez les personnes qui n’avaient pas d’emploi, qui exerçaient une profession de statut inférieur, qui avaient un niveau de scolarité peu élevé et qui faisaient partie de quintiles de suffisance du revenu inférieurs (quintiles nationaux et régionaux) Les taux de mortalité étaient plus élevés chez les répondants autochtones (en particulier les Inuits faisant partie la cohorte) et plus faibles chez les personnes appartenant à une minorité visible et les immigrants. Ces résultats concordent avec les analyses de la cohorte du Recensement de 1991 (Wilkins et coll., 2008) et ils sont en gros similaires à ceux portant sur des cohortes d’autres pays (p. ex., Blakely et coll., 2002; Stringhini et coll., 2012).
L’un des points forts associés à la cohorte tient à l’utilisation du questionnaire détaillé du recensement, qui a été envoyé à environ 20 % de la population canadienne, de sorte que l’on dispose d’une cohorte d’analyse de grande taille (3,5 millions de répondants et 347 000 décès). Les résultats du couplage avec la population visée ont été similaires à ceux obtenus avec la cohorte du Recensement de 1991. Selon un examen manuel, le taux d’erreur de résultats faussement positifs est très faible (moins de 0,2 %). On dispose de renseignements détaillés sur la cause du décès pour 96,6 % de tous les décès enregistrés à l’intérieur de la cohorte.
Bien que la cohorte du Recensement de 2001 soit largement représentative des tendances nationales, la comparaison des caractéristiques de cette cohorte avec celles de la population visée a révélé certaines différences importantes, principalement attribuables au couplage avec les enregistrements fiscaux T1, car il est probable que des couplages aient été oubliés. Étant donné que les membres de la cohorte devaient être couplés à un enregistrement fiscal T1 pour que leur NAS puisse servir de clé de couplage avec les données sur la mortalité, la population de la cohorte était différente, puisqu’elle comptait une plus forte proportion de personnes ayant produit des déclarations de revenus T1. La proportion plus faible que prévu de membres de la cohorte qui étaient plus jeunes (19 à 24 ans) ou plus vieux (85 ans et plus), qui n’étaient pas mariés et ne vivaient pas en union libre, qui faisaient partie du quintile de suffisance du revenu le plus bas ou qui ont déclaré une identité autochtone (tableau 1) était probablement attribuable aux taux de déclarants plus faible chez les personnes faisant partie de ces groupes. Les personnes ayant déménagé au cours d’une année précédente étaient elles aussi moins susceptibles d’être couplées à la cohorte, probablement en raison du fait que le code postal du lieu de résidence constituait l’une des clés de couplage.
On observe les mêmes différences lorsqu’on compare la cohorte aux estimations des caractéristiques de la population générale. Par exemple, la cohorte comportait une proportion plus élevée que prévu de répondants mariés ou en union libre (69 %), comparativement aux estimations établies d’après les données du Recensement de 2001 (61,8 %) (Statistique Canada, 2015a). De même, le pourcentage de membres de la cohorte n’ayant pas de diplôme d’études secondaires (28 %) était plus faible que prévu, considérant les estimations fondées sur les données du recensement (33,8 % des personnes âgées de 15 ans et plus) (Statistique Canada, 2009).
Les courbes de survie fondées sur la cohorte et sur les tables de mortalité de 2005 à 2007 étaient presque identiques pour les hommes et les femmes, ce qui est l’indication d’une forte concordance avec des données représentatives à l’échelle nationale. Les différences mineures chez les personnes plus âgées tiennent probablement au nombre plus faible de membres de la cohorte faisant partie de ces groupes d’âge ainsi qu’à l’exclusion des adultes vivant en établissement, comme les personnes âgées résidant dans un établissement de soins infirmiers.
Bien que l’on ait utilisé une méthode d’estimation légèrement différente, l’espérance de vie restante à l’âge de 25 ans était en général similaire à celle calculée pour la cohorte du Recensement de 1991, quoiqu’elle ait été plus élevée pour les hommes (54,6 ans, contre 52,6 ans pour la cohorte du Recensement de 1991) (Wilkins et coll., 2008; Tjepkema et Wilkins, 2011). L’espérance de vie restante à 25 ans pour la cohorte du Recensement de 2001 était d’une année plus longue environ que celle calculée d’après les tables de mortalité de 2005 à 2007 : 53,7 ans pour les hommes, et 58,0 ans pour les femmes (Statistique Canada, 2013). Cette espérance de vie un peu plus longue peut s’expliquer par la situation socioéconomique légèrement meilleure des membres de la cohorte (c’est-à-dire un niveau de scolarité plus élevé) comparativement à la population générale et par le fait que les personnes ayant une situation socioéconomique moins favorable étaient plus susceptibles d’être oubliées dans le cadre du recensement (Statistique Canada, 2014). Cela dit, les écarts d’espérance de vie restante entre les personnes faisant partie du quintile de revenu inférieur et celles du quintile supérieur, entre les personnes ayant le niveau de scolarité le plus faible et celles ayant le niveau de scolarité le plus élevé et entre les répondants autochtones et les autres répondants étaient similaires pour les cohortes de 1991 et de 2001 (Wilkins et coll., 2008; Tjepkema et Wilkins, 2011).
En général, les statistiques sur la mortalité étaient similaires pour les hommes et les femmes des cohortes de 1991 et de 2001, même si les TMNA étaient un peu plus élevés en 2001. Cet écart était probablement attribuable au fait que la nouvelle analyse tenait compte des décès relevés dans la BCDM et dans des données fiscales (à partir de la BDCM), tandis que l’analyse de la cohorte de 1991 comportait uniquement les décès enregistrés dans la BCDM (Wilkins et coll., 2008). Les RT pour les deux cohortes étaient très similaires dans les différents groupes socioéconomiques et démographiques, mais il y avait cependant quelques exceptions importantes. Ainsi, les hommes du quintile de suffisance du revenu le plus bas (déterminé selon la région) avaient un RT plus bas en 2001 (RT = 1.57; intervalle de confiance à 95 % : 1,54 à 1,60) qu’en 1991 (RT = 1,68; intervalle de confiance à 95 % : 1,65 à 1,71). En 1991, les femmes exerçant une profession de statut inférieur et faisant partie des quintiles de suffisance du revenu les plus bas présentaient un rapport de risques plus élevé (c’est-à-dire un gradient de mortalité plus prononcé) que celles dans la même situation en 2001. Les rapports de risques étaient généralement similaires entre les cohortes de 1991 et 2001 en ce qui a trait aux groupes fondés sur le niveau de scolarité, la profession et le quintile de suffisance du revenu (Wilkins et coll., 2008).
La cohorte du Recensement de 2001 est un ensemble de données analytiques pouvant servir à examiner les écarts de mortalité entre différents groupes socioéconomiques et démographiques et à mener des recherches dans le domaine de la santé environnementale. Les résultats des analyses de la mortalité concordent avec ceux fondés sur la cohorte du Recensement de 1991 et sur les tables de mortalité de 2005 à 2007. Il pourrait être utile de mener d’autres analyses afin d’examiner les profils de mortalité associés à d’autres dimensions socioéconomiques. On pourrait peut-être aussi combiner les cohortes de 1991 et de 2001 pour étudier les profils de mortalité associés à des causes particulières pour des causes de décès rares ou chez des groupes de population plus petits.
6. Conclusion
Le présent document décrit le couplage des données relatives aux répondants au questionnaire détaillé du Recensement de 2001 qui étaient âgés de 19 ans et plus et qui résidaient au Canada et ne vivaient pas en établissement avec la Base de données combinées sur la mortalité, laquelle permet un suivi de la mortalité chez les répondants de la cohorte sur une période de 10,6 ans (jusqu’à la fin de 2011). De façon générale, la survie des répondants de la cohorte était similaire à celle calculée à partir des tables de mortalité du Canada, et les statistiques sur la mortalité concordaient avec les attentes, d’après les résultats obtenus pour une cohorte similaire une décennie auparavant. La cohorte était légèrement différente—ses membres étaient plus susceptibles d’être mariés ou de vivre en union libre, d’avoir un revenu et un niveau de scolarité plus élevés et d’avoir un emploi—du fait que la méthodologie de couplage utilisée reposait sur les répondants qui étaient des déclarants.
Références
Blakely, T., A. Woodward, N. Pearce, C. Salmond, C. Kiro et P. Davis. 2002. « Socioeconomic factors and mortality among 25-64 year olds followed from 1991 to 1994: The New Zealand census-mortality study ». The New Zealand Medical Journal 115 (1149) : 93 à 97.
Carrière, K.C., et L. Roos. 1997. « A method of comparison for standard rates of low-incidence events ». Medical Care 35 (1) : 57 à 69.
Chiang, C.L. 1984. The Life Table and Its Applications. R.E. Krieger. Malabar, Floride : Krieger Pub.
Cho, K.H., C.M. Nam, E.J. Lee, Y. Choi, K.-B. Yoo, S.-H. Lee et E.-C. Park. 2016. « Effects of individual and neighbourhood socioeconomic status on the risk of all-cause mortality in chronic obstructive pulmonary disease: A nationwide population-based cohort study, 2002-2013 ». Respiratory Medicine 114 : 9 à 17.
Cox, D.R. 1972. « Regression models and life tables ». Journal of the Royal Statistical Society: Series B 34 (2) : 187 à 220.
Crouse, D.L., P.A. Peters, A. van Donkelaar, M.S. Goldberg, P.J. Villeneuve, O. Brion, S. Khan, D. Odwa Atari, M. Jerrett, C.A. Pope III, M. Brauer, J.R. Brook, R.V. Martin, D. Stieb et R.T. Burnett. 2012. « Risk of nonaccidental and cardiovascular mortality in relation to long-term exposure to low concentrations of fine particulate matter: A Canadian national-level cohort study ». Environmental Health Perspectives 120 (5) : 708 à 714.
Crouse, D.L., P.A. Peters, P.J. Villeneuve, M.O. Proux, H.H. Shin, M.S. Goldberg, M. Johnson, A.J. Wheeler, R.W. Allen, D. Odwa Atari, M. Jerrett, M. Brauer, J.R. Brook, S. Cakmak et R.T. Burnett. 2015. « Within- and between-city contrasts in nitrogen dioxide and mortality in 10 Canadian cities; a subset of the Canadian Census Health and Environment Cohort (CanCHEC) ». Journal of Exposure Science and Environmental Epidemiology 25 (5) : 482 à 489. DOI :10.1038/jes.2014.89.
Fellegi, I.P. et A.B. Sunter. 1969. « A theory for record linkage ». Journal of the American Statistical Association 64 (328) : 1183 à 1210.
Lazzarino, A.I., M. Hamer, E. Stamatakis et A. Steptoe. 2013. « The combined association of psychological distress and socioeconomic status with all-cause mortality: A national cohort study ». JAMA Internal Medicine 173 (1) : 22 à 27.
Mayer, É. et C. Charbonneau. 2015. Amalgamated Mortality Database (AMDB) 2014b. Ottawa : Division des méthodes d’enquêtes auprès des ménages, Statistique Canada. Rapport interne.
Mishra, G.D., F. Chiesa, A. Goodman, B. De Stavola et I. Koupil. 2013. « Socio-economic position over the life course and all-cause and circulatory diseases mortality at age 50-87 years: Results from a Swedish birth cohort ». European Journal of Epidemiology 28 (2) : 139 à 147.
Statistique Canada. 2003. Dictionnaire du Recensement de 2001. Produit no 92-378-X au catalogue de Statistique Canada. Ottawa : Statistique Canada.
Statistique Canada. 2009. Population âgée de 15 ans et plus selon le plus haut grade, certificat ou diplôme, Recensements de 1986 à 2006 (tableau). Recensement de la population (base de données). Dernière mise à jour le 6 octobre 2009. (consulté le 22 mars 2016).
Statistique Canada. 2013. Tables de mortalité, Canada, provinces et territoires 2005 à 2007. Produit no 84-537-X au catalogue de Statistique Canada. Ottawa : Statistique Canada.
Statistique Canada. 2014. Couverture : rapport technique du Recensement de 2001. Produit no 92-394-X au catalogue de Statistique Canada. Ottawa : Statistique Canada.
Statistique Canada. 2015a. Tableau 051-0042 Estimations de la population selon l’état matrimonial ou l’état matrimonial légal, l’âge et le sexe au 1er juillet, Canada, provinces et territoires (tableau). CANSIM (base de données). Dernière mise à jour le 30 octobre 2015. (consulté le 22 mars 2016).
Statistique Canada. 2015b. User Guide: 1991 Canadian Census Cohort: Mortality and Cancer Follow-up. Ottawa : Statistique Canada. Centres de données de recherche, guide de l’utilisateur.
Stringhini, S., L. Berkman, A. Dugravot, J.E. Ferrie, M. Marmot, M. Kivimaki, et A. Singh-Manoux. 2012. « Socioeconomic status, structural and functional measures of social support, and mortality: The British Whitehall II cohort study, 1985-2009 ». American Journal of Epidemiology 175 (12) : 1275 à 1283. DOI :10.1093/aje/kwr461.
Tjepkema, M. et R. Wilkins. 2011. « Espérance de vie restante à l’âge de 25 ans et probabilité de survie jusqu’à l’âge de 75 ans, selon la situation socioéconomique et l’ascendance autochtone ». Rapports sur la santé 22 (4) : 31 à 36. Produit no 82-003-X au catalogue de Statistique Canada.
Weichenthal, S., D.L. Crouse, L. Pinault, K. Godri-Pollitt, E. Lavigne, G. Evans, A. van Donkelaar, R.V. Martin et R.T. Burnett. 2016. « Oxidative burden of fine particulate air pollution and risk of cause-specific mortality in the Canadian Census Health and Environment Cohort (CanCHEC) ». Environment Research 146 : 92 à 99.
Wilkins, R., M. Tjepkema, C. Mustard et R. Choinière. 2008. « Étude canadienne de suivi de la mortalité selon le recensement, 1991 à 2001 ». Rapports sur la santé 19 (3) : 25 à 43. Produit no 82-003-X au catalogue de Statistique Canada.
Organisation mondiale de la Santé. 1992. Classification statistique internationale des maladies et des problèmes connexes, dixième révision. Genève : Organisation mondiale de la Santé.
- Date de modification :