4 Study of the mean electricity consumption curve
Hervé Cardot, Alain Dessertaine, Camelia Goga,
Étienne Josserand and Pauline Lardin
Previous | Next
We have a population consisting of electricity consumption curves measured
every half hour during two consecutive weeks. We have measurement points for each week, and
we want to estimate the mean consumption curve for the second week. We denote
by the electricity consumption of individual measured in the second week and , the individual's consumption
during the first week. The mean consumption of each individual during the first week, ,
which is simple piece of information that is inexpensive to transmit, will be
used as auxiliary information. This variable (a real one), which is known for
all units in the population, is strongly related to the
current consumption curve. As Figure 4.1 shows, the current consumption in each
is almost proportional to the mean consumption
for the previous week.
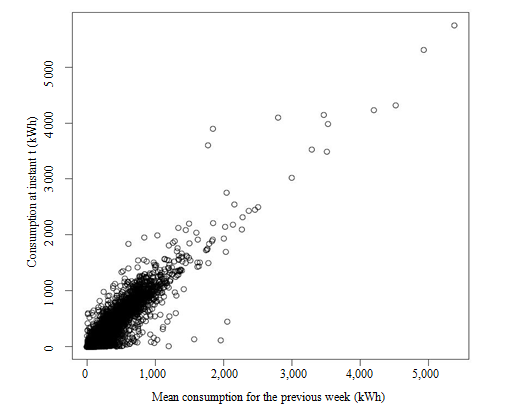
Description for figure 4.1
Figure 4.1 Representation
of consumption at an instant as a function of the mean consumption for the
previous week.
4.1 Description of strategies used
We consider samples of fixed size obtained using different sampling
designs. The strategies presented are repeated times to evaluate and compare their
performance.
1. SRSWOR
sampling and Horvitz-Thompson estimator
This design is simple to implement; the Horvitz-Thompson
estimator of the mean curve is given by (2.6) and the estimator of its
covariance by (2.7).
2.STRAT
stratified design and Horvitz-Thompson estimator
A stratified design is very effective if the strata
are homogenous in relation to the variable of interest. In this study, we used
the means algorithm to create the strata, and we
considered strata. A first stratification (STRAT
1) was carried out using the classification of the discretized trajectories for the previous week. A second
stratification, which uses only the aggregate information was also considered. It is denoted by STRAT 2.
Tables 4.1 and 4.2 show the sizes of the strata yielded using the two stratifications and the
optimal sizes , according to (2.5), of the
samples to be selected in each stratum. In both cases, the strata are numbered
in ascending order in relation to the mean consumption for each stratum. More
specifically, stratum 1 corresponds to small consumers of electricity and
stratum 10 refers to the 10 largest consumers. Note that the first
stratification, which requires knowing the electricity consumption at each
measurement instant requires more information than the second
stratification. The mean curve is constructed using (2.3), and its covariance
is estimated by (2.4).
Table 4.1
STRAT 1: stratification based on curves. The strata are constructed using the curves for week 1. The optimal allocation is calculated using the curves for week 1.
Table summary
This table displays stratification based on curves. The information is grouped by h (appearing as row headers), 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 (appearing as column headers).
|
h
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
N
h
|
3,866
|
4,769
|
623
|
2,690
|
664
|
1,251
|
806
|
328
|
62
|
10
|
|
n
h
|
212
|
345
|
87
|
242
|
117
|
179
|
172
|
101
|
35
|
10
|
Table 4.2
STRAT 2: stratification based on the mean consumption The optimal allocation is calculated using the mean consumption for week 1.
Table summary
This table displays stratification based on the mean consumption The information is grouped by h (appearing as row headers), 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 (appearing as column headers).
|
h
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
N
h
|
3,257
|
4,236
|
3,139
|
1,937
|
1,189
|
731
|
415
|
125
|
30
|
10
|
|
n
h
|
260
|
293
|
248
|
204
|
159
|
133
|
111
|
56
|
26
|
10
|
3.
sampling and Horvitz-Thompson estimator
We used the cube algorithm proposed by Deville and
Tillé (2004) and Chauvet and Tillé (2006), where the inclusion probabilities
are proportional to .
To have a sampling design close to maximum entropy, a random sort of the
population is performed before selection of the sample The covariance of the estimator of the mean is
estimated using Formula (2.9). The cube algorithm is available in R in the sampling package, samplecube function, and a SAS macro is available on the INSEE
website (Institut National de Statistique et des Études Économiques).
4. SRSWOR
sampling and MA estimator
The estimator assisted by the model is constructed using the auxiliary information
given by , where is the mean consumption for the previous week.
In these conditions, is the sum over any population of the values estimated by the model (cf. Formula (2.13)). The covariance of the estimator of the mean is
estimated using Formula (2.15).
4.2 Error of estimation of the mean curve
The error of estimation of the mean curve at instants is evaluated according to the following
criterion:
The results are shown in Table 4.3 for simulations (replications). They
clearly show that for this study, taking account of total consumption for the previous
week substantially improves the precision of the estimate of the mean compared
with simple random sampling without replacement, dividing the mean square error
by 5. Among the different strategies, the best
appear to be those that take account of auxiliary information via inclusion
probabilities (STRAT, and systematic PPS).
Table 4.3
Square error of estimation of the mean with replications
Table summary
This table displays square error of estimation of the mean with replications. The information is grouped by strategy (appearing as row headers), mean, 1st, median, 3rd (appearing as column headers).
|
Strategy
|
Mean
|
1
st quartile
|
Median
|
3
rdquartile
|
|
SRSWOR
|
40.53
|
10.82
|
22.16
|
51.09
|
|
STRAT (1)
|
5.78
|
3.68 |
5.08 |
7.07
|
|
STRAT (2)
|
6.49
|
4.03 |
5.48 |
7.88
|
|
|
7.06 |
3.99 |
5.52 |
8.16
|
|
Systematic
|
6.73 |
3.85 |
5.20 |
8.07
|
|
MA
|
8.29 |
5.24 |
7.14 |
10.16
|
4.3 Coverage rate and width of confidence bands
The construction of confidence bands of level requires calculating quantiles of order of the supremum of Gaussian processes.
So as not to favour one method of constructing
confidence bands over the other, we applied the two algorithms to the same
sample and we considered the same number of processes. This number varies from one estimator to the other owing
to the computation time needed for the bootstrap approaches (see Section 4.4).
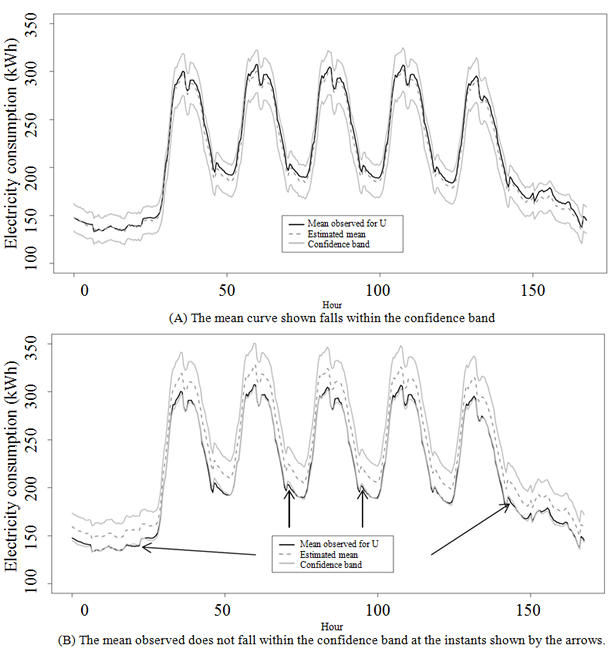
Description for figure 4.2
Figure 4.2 Examples
of confidence bands.
The empirical coverage rate is the proportion of times,
among the replications, where the true mean curve
appears, for all instants within the confidence band constructed using
an estimate Figure 4.2 shows two examples of confidence
bands (continuous grey curves) constructed from estimated curves (dotted grey
curves). Figure 4.2(A) shows that the true mean curve for the population
(continuous black curve) is within the confidence band at every instant.
Conversely, Figure 4.2(B) shows that mean curve for the population is generally
overestimated and there are a few instants (indicated by arrows) where the curve
shown is outside the confidence band. Empirical coverage rates are shown in
Table 4.4.
The two methods of constructing confidence bands yield
coverage rates that are similar and fairly close to the desired nominal rates
(95% and 99%). However, the results seem slightly less satisfactory for the designs and for the MA approach, for which the
variance of the estimator is complex and more difficult to estimate precisely.
Table 4.4
Empirical coverage rate (in %), for replications
Table summary
This table displays empirical coverage rate (in %), for replications. The information is grouped by method (appearing as row headers), Number M of processes, Bootstrap, Gaussian process (appearing as column headers).
|
Method |
Number M of processes
|
Bootstrap
|
Gaussian process
|
|
|
|
|
|
|
SRSWOR
|
5,000 |
94.95
|
98.85
|
94.80
|
98.70
|
|
STRAT (1)
|
5,000
|
93.92
|
98.34
|
94.09
|
98.43
|
|
STRAT (2)
|
5,000
|
94.3
|
98.45
|
94
|
98.55
|
|
|
1,000
|
94.73
|
98.77
|
93.87
|
98.61
|
|
MA
|
5,000
|
94.3
|
98.5
|
92.85
|
98.15
|
Another useful indicator is the mean width of the
confidence band,
the values of which are shown in Table 4.5. The two
methods provide confidence bands of largely similar width. Also note that the
use of the auxiliary variable considerably reduces the mean band width, which
is cut in half if one of the stratified designs is used rather than a SRSWOR
design.
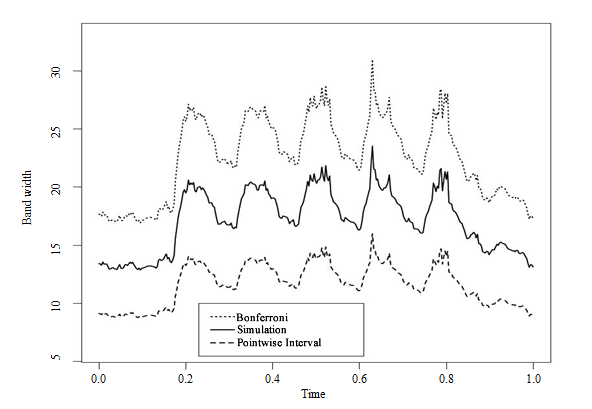
Description for figure 4.3
Figure 4.3 Simple random sampling without replacement. Width of confidence bands - pointwise, overall by process simulations, and with Bonferroni (
).
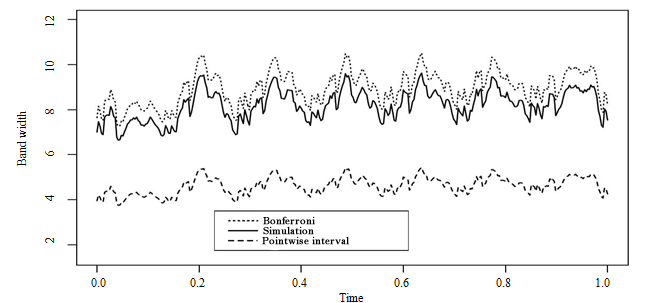
Description for figure 4.4
Figure 4.4 Stratified sampling (STRAT 1). Width of confidence bands - pointwise,
overall by process simulations, and with Bonferroni (with
).
Figures 4.3 and 4.4 show the widths of the confidence
bands for a level
, for each instant, depending on
whether they are pointwise (
), estimated by simulations of Gaussian
processes or obtained using the approach based on the Bonferroni inequality
applied to each measurement point. We then have, in the latter case, , the quantile of order of a distribution
The bands obtained by Bonferroni are
conservative, and they cover what might be considered the worst case in terms
of information, the case of independence of the pointwise intervals. Note that
the simulation approach substantially reduces the mean width of the bands in
comparison with Bonferroni when the design does not allow all temporal
information on the data to be taken into account (Figure 4.3). Conversely, for
the stratified design (Figure 4.4), which provides a precise estimate of the
mean curve, the confidence band constructed by simulation is close to that of
Bonferroni, which can intuitively be interpreted as meaning that almost all the
information was captured by the sampling design.
Table 4.5
Mean width of confidence bands, for replications
Table summary
This table displays mean width of confidence bands, for replications. The information is grouped by method (appearing as row headers), number M of processes, bootstrap, gaussian process (appearing as column headers).
|
Method |
Number M of processes
|
Bootstrap
|
Gaussian process
|
|
|
|
|
|
|
SRSWOR
|
5,000 |
35.98 |
43.35 |
35.99 |
43.19
|
|
STRAT (1)
|
5,000
|
16.64 |
18.92
|
16.62
|
18.88
|
|
STRAT (2)
|
5,000
|
17.58
|
19.99
|
17.55
|
19.94
|
|
|
1,000
|
17.85 |
20.31
|
17.62
|
19.93
|
|
MA
|
5,000
|
19.88
|
22.65
|
19.75
|
22.44
|
4.4 Computation time
Computation times with the bootstrap method are much
greaterby
a factor of approximately 1 to 1,000than
those with the Gaussian processes simulation method (cf. Table 4.6). The reason for this major difference is that
in the bootstrap methods, the entire estimation process (construction of the
fictitious population, drawing of a new sample, calculation of the estimator)
must be repeated for each bootstrapped sample. Also, the designs that introduce
auxiliary information are slower than SRSWOR, even though if used individually
their computation time is entirely reasonable.
Table 4.6
Run time of a simulation in seconds for replications. The SRSWOR, MA and STRAT strategies were programmed with R and with SAS.
Table summary
This table displays run time of a simulation in seconds for replications. The SRSWOR, MA and STRAT strategies were programmed with R and with SAS. The information is grouped by Strategy (appearing as row headers), bootstrap, Gaussian processes (appearing as column headers).
|
Strategy
|
Bootstrap
|
Gaussian processes
|
|
SRSWOR
|
1,170.6
|
1.0
|
|
STRAT
|
1,839.5
|
1.4
|
|
|
5,020.0
|
7.3
|
|
MA
|
3,156
|
1.4
|
Previous | Next
