2. Composite optimal regression estimation for design (c)
Takis Merkouris
Previous | Next
A
general estimation method for matrix sampling is illustrated for design (c)
through the simplest setting involving three samples
and
with arbitrary
designs and sizes
which may be
subsamples of an initial sample of size
from a
population labeled
or may be drawn
independently from
A
dimensional
vector of variables
and a
dimensional
vector of variables
are surveyed in
and
respectively,
and both vectors are surveyed in
These two modes
of matrix sampling, depicted in Figure 2.1, will henceforth be referred to as
nested and non-nested matrix sampling, respectively, in analogy with the nested
and non-nested two-phase sampling (Hidiroglou 2001).
Figure 2.1 Nested and non-nested matrix sampling design (c)
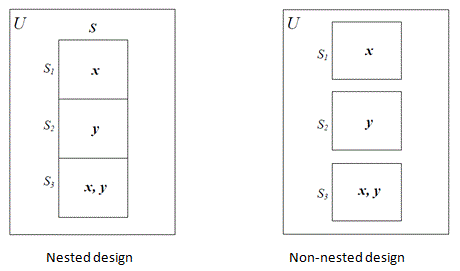
Description for Figure 2.1
We
denote by
the vector of
design weights for sample
and by
and
the sample
matrices of
and
the subscripts
indicating the sample. We obtain simple Horvitz-Thompson (HT) estimators
and
of the
population total
of
using
and
respectively,
and HT estimators
and
of the total
of
using
and
For more
efficient estimation of the totals
and
we seek
composite estimators that combine all the available information on
and
in the three
samples. Such composite estimators that are best linear unbiased estimators
(BLUE), i.e., minimum-variance linear unbiased combinations of the four
estimators
and
are denoted by
and
and given in
matrix form by
where
the matrix
satisfies
and has entries
and
and
is the
variance-covariance matrix of
This estimation
method was proposed by Chipperfield and Steel (2009), who provided analytical
expressions of the BLUE for scalars
and
in non-nested
matrix sampling, assuming simple random sampling and known
Such an approach
to composite estimation has been explored also in a different context of survey
sampling; see Wolter (1979), Jones (1980) and Fuller (1990). In general,
computation of the BLUE given by (2.1) is not at all practical, as the
computation of an estimated matrix
(and its
inverse) in
would be quite
laborious, especially if the number of variables or the sizes of the samples
were large; it would be prohibitive if estimates for subpopulations were also
required. Of course, the problem would become more difficult with more samples
involved.
A
more practical formulation of this estimation procedure is as follows. First,
we express the composite estimators in (2.1) explicitly as linear combinations
of the HT estimators
and
i.e.,
The
condition of unbiasedness,
and
implies that
and
Thus,
and
can be expressed
as
respectively, and the two composite estimators have necessarily the
regression form
Then writing
in obvious
notation for matrix
we can express (2.1)
as
the right-hand side of (2.3) being the matrix form of (2.2). The problem
of finding the optimal (variance-minimizing)
of the BLUE in (2.1)
reduces then to that of finding the optimal matrix
in (2.3). The
estimated optimal
is given by
and when the three samples are independent it reduces to
In view of (2.3), with such optimal
the estimated
BLUE in (2.1) (involving the estimated
and with
is a special
type of optimal multivariate regression estimator. For the form of the ordinary
(single-sample) optimal regression estimator and relevant discussion, see
Montanari (1987) and Rao (1994).
Expressing
the estimated variance of the HT estimator of a total (see, for example, Särndal,
Swensson and Wretman (1992), page 43) as a quadratic form with associated
non-negative definite matrix
where
are
first-and-second order inclusion probabilities, it can be shown after some
matrix algebra that
where
is the
design matrix
corresponding to the regression estimator (2.3),
is the matrix
with the first
two rows set equal to zero, and
is associated
with the combined sample
reducing in the
non-nested sampling to the block-diagonal matrix
with
associated with
the sample
For the nested
design, the probabilities defining
are products of
the probabilities of inclusion in
and the
conditional (on
) subsampling
probabilities. With this estimated
the estimated
BLUE in (2.3), called composite optimal regression estimator (COR) and denoted
by
is written
compactly as
where
is the vector of
design weights of the combined sample
It transpires
that the COR estimator is in fact the sum of weighted sample regression
residuals, and
minimizes the
quadratic form
in these
residuals, which is the estimated approximate (large-sample) variance of
Now,
upon writing
as
it appears that
the COR estimator has the form of a calibration estimator (with vector of
calibration totals
of dimension
whose components
satisfy the constraints
and
i.e., calibrated
estimates of the same total from two different samples are equal. Indeed, the
vector
is the vector of calibrated weights that minimizes the generalized
least-squares distance
while satisfying
the constraints
and
where the
subcector
corresponds to
sample
This follows
from a general result for the single-sample case, according to which
calibration with the generalized least-squares distance measure may involve an
arbitrary
positive
definite matrix
instead of
see Andersson
and Thorburn (2005).
We
may now write the COR estimator formally as a calibration estimator,
and using the
subvector of calibrated weights
for sample
only, we obtain
the components of
directly in the
simple linear forms
as in common survey practice. Yet, a decomposition of the vector
based on the
following general lemma on calibration gives an analytic expression of
and
of the form (2.2),
which provides insight into the structure and the efficiency of the COR
estimator. The proof of the lemma is given in the Appendix.
Lemma 1 Let
be a design matrix of dimension
and of full rank and written in partition form
with corresponding vector of calibration
totals
and let
be any positive definite matrix of dimension
Then the vector of calibrated weights
obtained from the calibration procedure
involving the distance measure
and the constraint
can be decomposed as
where
with
and
with
The vector
can be written as
where the vector
is generated by calibration of
the design weights involving only
and
By symmetry,
where
Now,
if
is as in (2.7),
with corresponding vector of calibration totals
and if
then it follows
from (2.9) that (2.8) can be written in the form
and thus
in obvious notation for
and
A similar
expression is obtained for
It is seen from
(2.12) that the COR estimator
of
is approximately
(for large samples) unbiased, and derives its efficiency from combining the two
elementary estimators
and
(pooling
information from samples
and
and from
borrowing strength from sample
through the
correlation between
and
In view of (2.10),
the estimator
takes the
alternative forms
where
are optimal
regression (OR) estimators incorporating the regression effect of the last term
in (2.12).
In
non-nested matrix sampling,
having estimated
approximate variance
and
is the
coefficient that minimizes the variance
From the
explicit form
it is then clear
that the stronger the correlation between
and
the larger the
and more weight
is given to the less variable component
In this
connection, it can be easily shown that
satisfies
These inequalities hold also for any linear combination of the components
of each of the estimators involved. The optimal composite regression estimator
is more
efficient than each of its two components
and
by the shown
quantities, with the efficiency depending on the strength of the correlation
between
and
The estimator
is also more
efficient than the estimator
with
which does not
incorporate the information on
(does not borrow
strength from sample
and has
estimated variance
Indeed, writing
the variance
as
where
with
and
and noticing
that
it follows that
that is, borrowing strength from
reduces the
variance of the composite estimator of
by the factor
which depends on
the strength of the correlation between
and
It can be easily
verified that for two scalar variables
and
and simple
random sampling this result reduces to the analogous analytical result on the
efficiency of BLUE given in Chipperfield and Steel (2009, page 231). In this
simple case
where
is the
correlation between
and
As an
illustration, assuming equal sample sizes and correlation
the efficiency
gain is 13.96%.
In
nested matrix sampling, the two estimators in (2.13) are
and
where AC denotes
approximate covariance. In this case, in addition to the correlation
between
and
in sample
the efficiency
of
depends on the
estimators' correlations
due to the
dependence of the subsamples. For univariate
and
and with the
simplifying assumption of identical designs for the three subsamples (as in
equal splitting of the full sample), we obtain some insight through the simple
expressions
and
Clearly, the
estimator
which ignores
information on
is more
efficient than the simple average of single-sample estimators of
only when there
is negative correlation
The efficiency
of
relative to
depends on the sign and size of
and the size of
Although
the calibration procedure, with vector of calibrated weights (2.8),
substantially facilitates the computation of the composite optimal regression
estimator for any total of interest, the matrix
makes the
calculations exceedingly demanding, particularly in nested sampling where the
subsamples are dependent and thus
is not diag
Besides, the
probabilities
are not known
for most sampling designs. An alternative composite regression estimator that
is computationally very efficient is developed in the next section.
Previous | Next
