Section 7 : Qualité des données
 Consulter la version la plus récente.
Consulter la version la plus récente.
Information archivée dans le Web
L’information dont il est indiqué qu’elle est archivée est fournie à des fins de référence, de recherche ou de tenue de documents. Elle n’est pas assujettie aux normes Web du gouvernement du Canada et elle n’a pas été modifiée ou mise à jour depuis son archivage. Pour obtenir cette information dans un autre format, veuillez communiquer avec nous.
Erreurs non dues à l'échantillonnage
Des erreurs qui ne sont pas reliées à l'échantillonnage peuvent se produire à presque toutes les étapes des opérations d'enquête. Les intervieweurs peuvent avoir mal compris les instructions, les enquêtés peuvent se tromper en répondant aux questions, les réponses peuvent être saisies de façon incorrecte et des erreurs peuvent être faites au moment du traitement et de la totalisation des données. Il s'agit là d'autant d'erreurs non dues à l'échantillonnage.
Lorsque le nombre d'observations est élevé, les erreurs aléatoires ont peu d'effet sur les estimations calculées à partir des résultats de l'enquête. Toutefois, les erreurs systématiques contribuent à biaiser les estimations. À chacune des étapes du cycle de collecte et de traitement des données, on applique des mesures d'assurance de la qualité pour contrôler la qualité des données. Au nombre de ces mesures figurent le recours à des intervieweurs hautement qualifiés, une formation poussée des intervieweurs concernant les procédures et le questionnaire de l'enquête, l'observation des intervieweurs en vue de cerner les problèmes liés à la conception du questionnaire ou à une mauvaise compréhension des instructions, des contrôles visant à réduire au minimum les erreurs de saisie des données ainsi que des vérifications du codage et des contrôles ayant pour but d'attester de la logique du traitement.
Erreurs d'échantillonnage
L'Enquête sur la population active recueille des renseignements auprès d'un échantillon de ménages. On pourrait obtenir des estimations différentes d'un recensement complet des ménages réalisé dans un environnement identique à celui de l'Enquête sur la population active, c'est-à-dire basé sur les mêmes questionnaires, intervieweurs, méthodes de traitement, etc. L'écart entre les estimations découlant de l'échantillon et celles que donnerait un dénombrement exhaustif réalisé dans des conditions comparables est appelé erreur d'échantillonnage de l'estimation, ou variabilité d'échantillonnage. Les produits de l'Enquête sur la population active sont assortis de mesures approximatives de l'erreur d'échantillonnage; nous recommandons vivement aux utilisateurs d'en tenir compte au moment d'analyser les données.
Les utilisateurs peuvent recourir à trois méthodes d'interprétation pour évaluer la précision de l'estimation : l'interprétation directement à l'aide de l'erreur-type, et deux autres méthodes elles aussi fondées sur l'erreur-type, soit l'interprétation à l'aide de l'intervalle de confiance, et l'interprétation à l'aide des coefficients de variation.
Interprétation à l'aide de l'erreur-type
L'erreur d'échantillonnage, ou erreur-type, est une mesure permettant de quantifier l'écart entre une estimation fondée sur un échantillon et la valeur tirée d'un recensement. Elle se base sur la notion du prélèvement de plusieurs échantillons, bien que, dans une enquête, on ne prélève qu'un seul échantillon et qu'on ne recueille que des renseignements se rapportant aux unités de cet échantillon. Le prélèvement d'un grand nombre d'échantillons à partir d'une population donnée, selon le même plan d'échantillonnage, produirait une estimation située à une erreur-type de la valeur censitaire dans environ 68 % des échantillons et à deux erreurs-type de la valeur censitaire dans environ 95 % des échantillons.
Ainsi quand on examine des variations, par exemple d'un mois à l'autre, dans les deux tiers des cas (68 %), une variation supérieure à l'erreur d'échantillonnage indique une variation réelle. Plus la variation est importante relativement à l'erreur-type, plus la probabilité qu'elle indique une variation réelle, plutôt qu'une variation attribuable à la variabilité d'échantillonnage, est grande. À un niveau de confiance de 95 %, la variation de l'estimation doit être supérieure au double de l'erreur d'échantillonnage pour indiquer une variation réelle.
Les variations des estimations qui sont inférieures à l'erreur d'échantillonnage sont moins susceptibles d'indiquer une variation réelle et plus susceptibles de refléter la variabilité d'échantillonnage. Si ces observations s'appliquent aux variations mensuelles, une série de variations consécutives dans la même direction est plus digne de confiance, même si certaines des variations mensuelles sont inférieures à l'erreur d'échantillonnage.
Supposons pour illustrer que, entre deux mois, l'estimation publiée de l'emploi total augmente de 40 000, et que l'erreur-type associée à l'estimation de la variation se chiffre à 27 200. Puisque la hausse est plus grande qu'une fois l'erreur-type, il y a au moins 2 chances sur 3 (68 %) que l'augmentation de l'emploi de 40 000 représente réellement une hausse. Pour être assuré à 95 % de la véracité de l'affirmation, il faut doubler la valeur de l'erreur-type. Puisque la hausse de l'emploi de 40 000 est plus petite que le double de l'erreur-type (54 400), il est impossible d'affirmer à un niveau de confiance de 95 % qu'il y a eu hausse de l'emploi.
Interprétation à l'aide de l'intervalle de confiance
On peut aussi examiner la variabilité inhérente aux estimations tirées d'enquêtes-échantillons sous l'angle des intervalles de confiance. Supposons pour illustrer le calcul d'un intervalle de confiance que, au cours d'un mois donné, l'estimation publiée de l'emploi total augmente de 16 000 pour atteindre 16 500 000. L'erreur-type associée à l'estimation de la variation se chiffre à 27 200. En utilisant l'erreur-type pour construire les intervalles de confiance, on peut dire que :
- Dans environ deux cas sur trois (68 %), la valeur réelle de la variation d'un mois à l'autre se situera dans la fourchette allant de -11 200 à +43 200 (c'est-à-dire 16 000 + ou – une erreur-type).
- Dans environ neuf cas sur dix (90 %), la valeur réelle de la variation d'un mois à l'autre se situera dans la fourchette allant de -27 520 à +59 520 (c'est-à-dire 16 000 + ou – 1,6 fois l'erreur-type).
- Dans environ dix-neuf cas sur vingt (95 %), la valeur réelle de la variation d'un mois à l'autre se situera dans la fourchette allant de -38 400 à +70 400 (16 000 + ou – deux fois l'erreur-type).
Interprétation à l'aide du coefficient de variation
On peut aussi exprimer la variabilité d'échantillonnage en fonction de l'estimation. Le coefficient de variation (CV) est une mesure de l'erreur d'échantillonnage définie en pourcentage de l'estimation. En fait, il s'agit d'une erreur-type relative. Le CV donne un aperçu du degré d'incertitude associé aux estimations. Par exemple, avec un CV de 7 %, on peut dire que dans 68 % des échantillons, la valeur censitaire se trouvera au maximum à plus ou moins 7 % (la valeur du CV) de l'estimation alors que dans 95 % des échantillons, elle se situera au maximum à plus ou moins 14 % (le double du CV) de l'estimation.
Il est préférable d'obtenir des CV peu élevés puisque de tels CV indiquent que la variabilité d'échantillonnage est faible par rapport à l'estimation. Le CV dépend de la valeur des estimations, de la taille de l'échantillon à partir duquel l'estimation est établie, de la répartition de l'échantillon et de l'utilisation d'information auxiliaire dans la procédure d'estimation. La valeur des estimations est importante parce que le CV représente l'erreur d'échantillonnage exprimée en pourcentage de l'estimation. Plus la valeur de l'estimation est faible, plus le CV est élevé (toutes choses étant égales par ailleurs). Par exemple, lorsque le taux de chômage est élevé, le CV peut être faible. Si le taux de chômage baisse en raison de l'amélioration de la situation économique, le CV correspondant augmentera. Normalement, dans le cas d'estimations similaires, l'estimation fondée sur l'échantillon le plus grand est associée au CV le plus bas, car l'erreur d'échantillonnage est plus petite.
Par ailleurs, les estimations se rapportant à des caractéristiques plus groupées donnent lieu à un CV plus élevé. Ainsi, les personnes employées dans les secteurs de la foresterie, de la pêche, de l'exploitation minière et de l'exploitation pétrolière et gazière au Canada sont plus regroupées sur le plan géographique que les femmes de 55 à 64 ans employées en Ontario. La variabilité d'échantillonnage correspondant à ce dernier groupe sera plus faible, même si la valeur des estimations est similaire.
Enfin, les estimations se rapportant à l'âge et au sexe sont généralement plus fiables que d'autres estimations analogues parce que, dans le cas des estimations de l'EPA, l'échantillon est calibré en fonction des projections postcensitaires de la population selon diverses catégories d'âge et de sexe. Pour poursuivre l'exemple précédent, les personnes employées à temps partiel en Alberta seront associées à une variabilité d'échantillonnage plus forte que les hommes de 35 à 44 ans employés en Colombie-Britannique, même si la valeur des estimations est similaire.
Variabilité des estimations mensuelles
Pour déterminer le CV approximatif d'une estimation mensuelle, veuillez consulter le tableau 7.1, lequel présente l'estimation en fonction de la région géographique et du CV. Les lignes correspondent à la région géographique à laquelle l'estimation est associée et les colonnes, au degré de précision exprimé en CV, selon la grandeur de l'estimation. Pour déterminer le CV d'une estimation X dans la région A, suivez la ligne de la région A jusqu'à la première estimation la plus proche de X sans la dépasser. Le titre de la colonne indiquera le CV approximatif. Par exemple, pour connaître l'erreur d'échantillonnage d'une estimation de 36 000 chômeurs à Terre-Neuve-et-Labrador en août 2010, on constate que l'estimation inférieure la plus proche, de 25 700, donne un CV de 5 %. L'estimation de 36 000 chômeurs à Terre-Neuve-et-Labrador aura donc un CV d'environ 5 %.
Le tableau 7.1 donne une idée approximative de la variabilité d'échantillonnage. Cette dernière est modélisée pour que le CV réel de l'estimation soit inférieur ou égal au CV du tableau dans environ 75 % des cas. Néanmoins, dans 25 % des cas, le CV réel de l'estimation sera plus élevé que celui indiqué par le tableau.
Le tableau 7.1 peut aussi être utilisé avec des estimations désaisonnalisées ou des estimations non désaisonnalisées. Des études ont démontré que les erreurs-types de l'EPA, dans le cas des données désaisonnalisées, se rapprochent de celles des données non corrigées.
Les valeurs de CV qui apparaissent au tableau 7.1 sont dérivées d'un modèle établi à partir des données de l'échantillon de l'EPA pour la période de 47 mois de janvier 2007 à novembre 2010 inclusivement. Il faut bien se rappeler que ces valeurs ne sont que des approximations.
Variabilité des estimations annuelles
Pour déterminer le CV approximatif d'une estimation d'une moyenne annuelle, veuillez consulter le tableau 7.2, lequel présente l'estimation en fonction de la région géographique et du CV. Les lignes correspondent à la région géographique à laquelle l'estimation est associée et les colonnes, au degré de précision exprimé en CV, selon la grandeur de l'estimation. Pour déterminer le CV d'une estimation X dans la région A, suivez la ligne de la région A jusqu'à la première estimation la plus proche de X sans la dépasser. Le titre de la colonne indiquera le CV approximatif. Par exemple, pour connaître l'erreur d'échantillonnage d'une estimation annuelle de 51 200 chômeurs à Terre-Neuve-et-Labrador en 2010, on constate que l'estimation inférieure la plus proche, de 16 300, donne un CV de 2,5 %. L'estimation de 51 200 chômeurs à Terre-Neuve-et-Labrador aura donc un CV d'environ 2,5 %.
Le tableau 7.2 donne une idée approximative de la variabilité d'échantillonnage. Cette dernière est modélisée pour que le CV réel de l'estimation soit inférieur ou égal au CV du tableau dans environ 75 % des cas. Néanmoins, dans 25 % des cas, le CV réel de l'estimation sera plus élevé que celui indiqué par le tableau.
Les valeurs de CV qui apparaissent au tableau 7.2 sont dérivées d'un modèle établi à partir des données de l'échantillon de l'EPA pour la période de 5 ans de décembre 2005 à novembre 2010 inclusivement. Il faut bien se rappeler que ces valeurs ne sont que des approximations.
Tableaux de variabilité de l'échantillonnage pour les territoires
Les valeurs de CV qui apparaissent au tableau 7.3 pour le Yukon et les territoires du Nord-Ouest sont dérivées d'un modèle établi à partir des données de l'échantillon de l'EPA pour la période de 48 mois de décembre 2006 à novembre 2010 inclusivement. Pour le Nunavut sont dérivées d'un modèle établi à partir des données de l'échantillon de l'EPA pour la période de 35 mois de janvier 2008 à novembre 2010 inclusivement.
Pour une mesure plus précise de la variabilité, veuillez composer notre numéro sans frais 1 866 873-8788 ou communiquez avec nous par courriel à travail@statcan.gc.ca.
Variabilité des taux
Pour les estimations exprimées sous forme de taux ou de pourcentages, la variabilité d'échantillonnage dépend de la variabilité du numérateur et du dénominateur du rapport. Les divers taux donnés sont traités différemment, car certains dénominateurs sont des valeurs étalonnées pour lesquelles il n'y a pas de variabilité d'échantillonnage.
Taux de chômage
Dans un groupe de personnes, le taux de chômage est défini comme le rapport du nombre de chômeurs, soit X, sur le nombre total de personnes dans la population active, soit Y. Le groupe peut désigner une province ou une RMR et (ou) un groupe d'âge-sexe. Par exemple, en septembre 2009, on dénombrait environ 39 100 chômeurs à Terre-Neuve-et-Labrador, tandis que la population active de la province comptait 252 300 personnes, ce qui donnait un taux de chômage de 15,5 %.
Le CV du taux de chômage peut être estimé au moyen de la formule suivante :
[CV(X/Y)]2 = [CV(X)] 2 + [CV(Y)] 2– 2p[CV(X)] [CV(Y)]
où CV(X) correspond au CV du nombre total de chômeurs d'un sous-groupe géographique ou démographique particulier et CV(Y), au CV du nombre total de personnes faisant partie de la population active dans le même sous-groupe. Le coefficient de corrélation, désigné par p, rend compte de l'ampleur de l'association linéaire entre X et Y (respectivement, le nombre de chômeurs et le nombre de personnes faisant partie de la population active dans le même sous-groupe). La valeur de p se situe entre -1 et 1. Par exemple, une forte association linéaire positive indiquerait que le nombre de chômeurs augmente généralement en même temps que le nombre total de personnes faisant partie de la population active. À noter que nous pouvons nous attendre à un CV plus important pour le taux de chômage lorsque p est négatif, étant donné que dans ce cas, le troisième terme du côté droit de l'équation ci-dessus devient positif.
Lorsque p n'est pas disponible, l'approche la plus conservatrice consiste à utiliser p = -1, ce qui mène à la formule simplifiée suivante :
CV(X/Y) = CV(X) + CV(Y)
À noter que cela entraînera probablement une surestimation de CV(X/Y).
Dans l'exemple qui précède, les CV des estimations mensuelles du nombre de chômeurs et du nombre total de personnes faisant partie de la population active à Terre-Neuve-et-Labrador sont respectivement de 5 % et 2,5 % à partir du tableau 7.1. Une approximation du CV du taux de chômage de 15,5 %, à partir de la formule qui précède, serait la suivante :
5,0 % + 2,5 % = 7,5 %
Taux d'activité et taux d'emploi
Le taux d'activité représente la population active exprimée en pourcentage de la population totale. Le taux d'emploi est le nombre total de personnes occupées divisé par la population totale. Le numérateur et le dénominateur de ces deux rapports se rapportent au même groupe régional et démographique.
Les estimations de la population de l'EPA à l'échelle du Canada, des provinces, des RMR et de certains groupes d'âge-sexe ne sont pas sujettes à la variabilité d'échantillonnage, car elles sont étalonnées selon des sources indépendantes. Par conséquent, le CV correspondant du taux d'activité et du taux d'emploi est équivalent au CV du numérateur.
On appelle « domaine » les sous-groupes se trouvant à l'intérieur du Canada, des provinces et des groupes d'âge-sexe. Ainsi, les personnes occupées dans le secteur de l'agriculture au Manitoba forment un domaine. Pour déterminer le CV des taux se rapportant à un domaine, on doit tenir compte de la variabilité du numérateur et du dénominateur, car le dénominateur n'est plus un total contrôlé. Il est donc sujet à la variabilité d'échantillonnage. On peut calculer le CV associé au taux d'activité et au taux d'emploi dans un domaine de la même façon que celle montrée précédemment pour le taux de chômage. Les totaux figurant au numérateur et au dénominateur d'un taux en particulier devraient se rapporter au même domaine ou au même sous-groupe.
Variabilité de l'estimation d'un changement
La différence entre des estimations provenant de deux périodes différentes donne une estimation du changement, laquelle est sujette aussi à la variabilité d'échantillonnage. L'estimation d'un changement entre deux années ou entre deux mois repose sur deux échantillons qui peuvent avoir des ménages en commun. Ainsi, le CV du changement dépend à la fois du CV des estimations observées à chacune des deux périodes et du chevauchement entre les échantillons des deux périodes (p).
La formule qui suit peut être utilisée pour calculer le CV de l'estimation du changement :
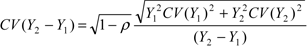 où Y1 et Y2 correspondent à l'estimation respective des deux périodes. La valeur de p correspond au coefficient de corrélation entre Y1 et Y2. La valeur de p va de -1 à 1, 1 correspondant à une association linéaire positive parfaite. On peut généralement utiliser le chevauchement d'échantillon pour produire une approximation du coefficient de corrélation de la façon suivante :
où Y1 et Y2 correspondent à l'estimation respective des deux périodes. La valeur de p correspond au coefficient de corrélation entre Y1 et Y2. La valeur de p va de -1 à 1, 1 correspondant à une association linéaire positive parfaite. On peut généralement utiliser le chevauchement d'échantillon pour produire une approximation du coefficient de corrélation de la façon suivante :
- Pour les provinces : utiliser p = 5/6 pour les variations d'un mois à l'autre, et p = 0 pour les variations d'une année à l'autre.
Des études empiriques à Statistique Canada ont montré que, pour les provinces, une valeur de p égale à 5/6 représente une bonne approximation des estimations de l'emploi, mais que pour les estimations du chômage, une valeur p de 0,45 produira une meilleure approximation des variations d'un mois à l'autre.
Lorsqu'on compare les moyennes annuelles de deux années, les CV des estimations annuelles devraient être dérivées à partir du tableau 7.2. Pour un changement entre deux mois, les estimations désaisonnalisées devraient être utilisées, conjointement avec les CV des estimations mensuelles dérivées à partir du tableau 7.1. Veuillez prendre note que la formule ci-dessus produit des estimations approximatives de la variabilité de l'échantillonnage associées à l'estimation d'un changement.
Lignes directrices concernant la fiabilité des données
Les Enquêtes-ménages de Statistique Canada utilisent généralement les lignes directrices et les catégories de fiabilité suivantes pour interpréter les valeurs de CV pour l'exactitude des données et pour la diffusion de l'information statistique.
Catégorie 1 - Si le CV est ≤ 16,5 % - Aucune restriction de diffusion : les données sont suffisamment exactes, si bien qu'un avertissement particulier aux utilisateurs ou d'autres restrictions ne sont pas nécessaires.
Catégorie 2 - Si le CV est > 16,5 % et ≤ 33,3 % - Diffusion avec mise en garde : les données sont potentiellement utiles pour certaines fins, mais devraient être accompagnées d'un avertissement aux utilisateurs concernant leur exactitude.
Catégorie 3 - Si le CV est > 33,3 % - Diffusion déconseillée : les données contiennent un niveau d'erreur élevé au point qu'elles ne devraient pas être diffusées dans la plupart des circonstances afin d'éviter de tromper les utilisateurs. Si les utilisateurs insistent pour inclure les données de la catégorie 3 dans un produit non normalisé, même après avoir été informés de leur exactitude, les données devraient être accompagnées d'un avis de non-responsabilité. L'utilisateur devrait reconnaître les mises en garde reçues et s'engager à ne pas diffuser, présenter ni déclarer les données, directement ou indirectement, sans cet avis de non-responsabilité.
Critères de diffusion
La Loi interdit à Statistique Canada de rendre publique toute donnée susceptible de révéler de l'information obtenue en vertu de la Loi sur la statistique et se rapportant à toute personne, entreprise ou organisation reconnaissable sans que cette personne, entreprise ou organisation le sache ou y consente par écrit. Diverses règles de confidentialité s'appliquent à toutes les données diffusées ou publiées afin d'empêcher la publication ou la divulgation de toute information jugée confidentielle. Au besoin, des données sont supprimées pour empêcher la divulgation directe ou par recoupement de données reconnaissables.
L'EPA permet de produire une vaste gamme de résultats donnant des estimations pour diverses caractéristiques de la population active. La plupart de ces résultats sont des estimations présentées sous la forme de tableaux de tri croisé. Les estimations sont arrondies à la centaine la plus proche, et un ensemble de règles de suppression est appliqué pour qu'aucune estimation inférieure à un seuil minimum ne soit diffusée.
Les estimations de l'EPA inférieures aux seuils présentés au tableau 7.4 sont supprimées.
- Date de modification :