
Applied Machine Learning for Text Analysis Community of Practice: 2021 in review
The Applied Machine Learning for Text Analysis Community of Practice (CoP) is an interdepartmental group of Government of Canada (GoC) employees who share and discuss high-quality machine learning (ML) solutions on text data. The group was formed in 2018 as a small group of data science practitioners at Statistics Canada and rapidly grew to become an interdepartmental CoP with representation from over 15 federal departments who meet virtually on a monthly basis.
The CoP's main goal is to increase ML capacity across multiple disciplines within the public service. Members do not need previous ML experience to attend these meetings and discussions are welcome from all disciplines and departments.
The CoP achieves its goal by:
- collaborating via discussions on various aspects of ML on text data,
- sharing presentations and other materials for text analysis,
- providing updates on questions and issues encountered while applying machine learning on text data; and
- establishing best practices based on various expertise across the government.
Throughout 2021, the CoP hosted thirteen presentations from various departments. Each presentation either illustrated a concrete ML solution on text data, or a use-case that required an ML text application to be developed.
Presentations in 2021
Below are descriptions of each presentation that took place in the past year. Please contact the Applied Machine Learning Text CoP if you'd like to access or obtain more information about the presentations: statcan.appliedmltextcop-cdpaaappliquetexte.statcan@statcan.gc.ca.
2021 Census Comment Classification at Statistics Canada

In an effort to improve comment analysis from the 2021 Census of Population, Statistics Canada's Data Science Division worked in collaboration with the Census Subject Matter Secretariat to create a proof-of-concept on the use of ML techniques to quickly and objectively classify census comments. In addition to classifying comments by subject matter area, the models also classified comments regarding technical issues and privacy concerns.
From Data to Insight: Using client feedback to inform innovation and make decisions at Immigration, Refugees & Citizenship Canada (IRCC)

The IRCC has collected client feedback about their services since 2014. The IRCC Client Experience Branch planned to launch a ML project to analyze the feedback in more detail. The analysis would help the department gain insight into their services, better align their innovation projects and inform their decision-making process. The presenter discussed with the CoP members about the appropriate approaches to demonstrate the added value of ML to senior management.
Data Analytics for Assurance and Advisory Services at Canada Revenue Agency (CRA)

The Data Analysis section within the CRA's Audit, Evaluation, and Risk Branch created a data museum in 2016. The data museum enabled:
- the delivery of descriptive and diagnostic data analytics for multiple assurance and advisory engagements,
- the use of ML for better pattern recognition, classification, and outlier detection, and
- the development of data privacy and protection standard operating procedures.
The Data Analysis section has seen first hand how natural language processing (NLP) methods and techniques are underused across the internal audit industry, and has taken the opportunity to apply NLP in various stages of the internal audit process. For example, NLP has helped internal audit teams to:
- analyze large volumes of unstructured textual data, such as interview notes, 400-page Government Accountability Office reports, and web pages when auto-generating risk summaries from the socio-economic environment,
- visualize risk interconnectivity,
- measure tons of reports using sentiment analysis, and
- leverage a natural language question and answer search engine.
Data Engineering with R, R Markdown, Shiny and Algorithms

This presentation provided an overview of the challenges and solutions related to data engineering and the domain that deals with the automation of data processing and analysis. The presenter discussed the taxonomy of data engineering tasks and the tools to address them, and also described the efforts to build the Data Engineering Toolkit and the Data Engineering Community of Practice. They also displayed the Shiny Apps for linking and deduplicating noisy data and the NLP analysis of the Open Canada database of Completed Access to Information Requests.
Dynamic Topic Modelling at Statistics Canada

This presentation gave a technical overview of the methodology behind topic modelling, explained the basis of Latent Dirichlet Allocation, and introduced a temporal dimension into the topic modelling analysis. This was done in the context of event detection using data from the Canadian Coroner and Medical Examiner Database.
Occurrence Analytics Using Situation Centre Structures (OASIS) at Transport Canada

The Emergency Preparedness Branch sends text notifications on occurrences (i.e. traffic accidents, etc.) affecting Canada's air, marine and surface transportation infrastructure, on a 24/7 basis to email subscribers. The presenter's team engineered bilingual notifications to produce analytical datasets in order to mine intelligence, enable text analytics, and detect patterns for similar occurring events.
Social Media Analytics in Real Time (SMART) at Transport Canada
This proof-of-concept web application mined social media data in real-time and provided geo-spatial insights and text analytics using NLP. The aim of the application was to help analysts determine to what extent safety and security occurrences could be extracted from social media. In addition, a sentiment-scoring component was added to enable sentiment analysis based on topics or organizational handles. While never operationalized, the proof-of-concept permitted rapid analysis for emerging issues for a subpopulation of social media users including individuals, news providers and national police.
Quantum Machine Learning for Text Classification by Statistics Canada, Institut quantique at Université de Sherbrooke and Bank of Canada

Quantum technologies are set to disrupt common tasks in ML, including text classification. The presenters provided a review of three approaches to quantum ML in the noisy intermediate scale quantum device age, with the goal of introducing these methods to existing researchers and data scientists in the field.
From Curing Cancer to Grabbing Gossip - Applied Natural Language Processing for Health Science at Public Health Agency of Canada (PHAC)

The presenter shared his brief journey through practical applications of NLP to problems in health sciences research. This included using rule-based NLP to extract drug-disease interactions from medical research abstracts, or using ML to analyze tweets about vaccinations to predict disease outbreaks. He also discussed his lessons learned and mistakes he made along the way.
Automating Population, Intervention, Control, Outcomes (PICO) Extraction from Systematic Reviews at Public Health Agency of Canada (PHAC)

PHAC (with Xtract AI in Vancouver, BC) was examining the automation of different stages of evidence synthesis to increase efficiencies. The presenter shared an overview of an initial version of a novel ML-based system that was powered by recent advances in NLP, such as BioBERT, with further optimizations completed using a new immunization-specific document database. The resulting optimized NLP model at the core of this system was able to identify and extract Population, Intervention, Control, Outcomes (PICO) and PICO-related fields from publications on immunization with 88% average accuracy, across five classes of text.
Building Data Visualization Dashboards using Open Source Python Frameworks at Statistics Canada

Building dashboards have proven to be useful in the field of data science. With the current advancements in this field, there are emerging open source tools that are powerful, highly customizable and free to use. The presenter shared the python tools suitable for building dashboards, showed examples of relevant work the Data Science Division has done and presented a brief overview of how to get started with the two most popular tools – Dash and Django.
Automation of Information Extraction from Financial Statements in the System for Electronic Document Analysis and Retrieval (SEDAR) using Spatial Layout based Techniques at Statistics Canada

Portable Document Format (PDF) documents are commonly used by companies for financial reporting. The absence of an effective way to extract data from unstructured PDF files into a tabular format caused significant challenges for financial analysts to efficiently analyze and process information in a timely manner. Spatial Layout based Information and Content Extraction (SLICE) is a unique computer vision algorithm that simultaneously uses textual, visual, and layout information to segment several data points into a tabular structure. This proposed solution significantly reduces the manual hours spent in identifying and capturing required information by automating the financial variable extraction process for close to 70 000 PDFs per year in near real-time. It also includes the development of a robust metadata management system that indexes close to 150 variables for each financial document as well as a web application that allows users to interact with the extracted data points. Check out the recent Data Science Network article on Document Intelligence: The art of PDF information extraction.
Innovation, Science and Economic Development Canada (ISED) Business Assistant Chatbot
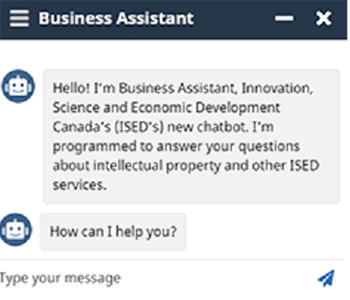
Description - ISED's Business Assistant
ISED's Business Assistant. Text in image: Hello! I'm Business Assistant, Innovation Science and Economic Development Canada’s (ISED’s) new chatbot. I'm programmed to answer your questions about intellectual property and other ISED services. How can I help you?
In 2019, ISED began implementing a Virtual Assistant Technology with a product called a chatbot. Virtual Assistant is a communication channel Canadians can currently use when visiting ISED's webpages and mobile application. The Canadian Intellectual Property Office, Corporations Canada, Strategic Communication and Marketing Sector, and Canada Business App are using a web and mobile chatbot to help reduce calls to call centres and offer enhanced service when providing information to Canadians who visit their websites or applications. The current chatbot is built on a Microsoft architecture leveraging Microsoft Azure and Microsoft's Language Understanding AI, called LUIS. A similar presentation was held at the DSN's Chatbot Workshop, as the presenters explained the background and purpose of their Virtual Assistant technology. See Chatting About Chatbots: A review of the Chatbot Workshop.
Conclusion
Throughout 2021, presenters from various GoC departments shared their diverse applications of ML techniques on text data. We covered various stages of the data pipeline starting from preprocessing to visualization. By leveraging each other's experiences and lessons-learned, our members can build ML products more efficiently.
In 2022, the CoP will continue to be a hub for public servants to share their passion for applying ML techniques to answer concrete business problems. The CoP is led by Statistics Canada and benefits from active participation from all federal public service departments. Presentations are encouraged from all departments and we look forward to continuing to cover the fast growing number of NLP applications across departments.
For more information on the CoP, or if you are a GoC employee and you would like to join, please contact the Applied Machine Learning Text CoP: statcan.appliedmltextcop-cdpaaappliquetexte.statcan@statcan.gc.ca. GoC employees can also join our GCExchange group for the Applied ML for text analysis CoP.
- Date modified: