
Tackling Information Overload: How Global Affairs Canada’s “Document Cracker” AI Application Streamlines Crisis Response Efforts
Prepared by the data science team at Global Affairs Canada
Introduction
When a global crisis hits, government officials often face the challenge of sifting through a flood of new information to find key insights that will help them to manage Canada’s response effectively. For example, following the Russian invasion of Ukraine in February of 2022, a substantial proportion of Canada’s diplomatic missions began filing situation reports (or SitReps) on local developments related to the conflict. With the sheer number of these SitReps, along with related meeting readouts, statements from international meetings and news media reports, it quickly became infeasible for individual decision makers to manually read all the relevant information made available to them.
To help address this challenge, the data science team at Global Affairs Canada (GAC) developed a document search and analysis tool called Document Cracker (hereafter “DocCracker”) that helps officials quickly find the information they need. At its core, DocCracker provides two key features: (1) the ability to search across a large volume of documents using a sophisticated indexing platform; and (2) the ability to automatically monitor new documents for specific topics, emerging trends, and mentions of key people, locations, or organizations. In the context of the Russian invasion, these features of the application are intended to allow Canadian officials to quickly identify pressing issues, formulate a preferred stance on these issues, and track the evolving stances of other countries. By providing such insights, the application can play a key role in helping officials to both design and measure the ongoing impacts of Canada’s response to the crisis.
Importantly, while DocCracker was developed specifically in response to events in Ukraine, it was also designed as a multi-tenant application that can provide separate search and monitoring interfaces for numerous global issues at the same time. For example, the application is currently being extended to support the analysis of geopolitical developments in the Middle East.
Application Overview
From a user’s perspective, the DocCracker interface is comprised of a landing page with a search bar and a variety of content cards that track recent updates involving specific geographical regions and persons of interest. The user can either drill down on these recent updates or submit a search query, which returns a ranked list of documents. Selecting a document provides access to the underlying transcript, along with the set of links to related documents. Users can also access the metadata associated with each document, which includes automatically extracted lists of topics, organizations, persons, locations, and key phrases. At all times, a banner at the top of the application page allows users to access a series of dashboards that highlight global and mission-specific trends concerning a predefined list of ten important topics (e.g., food security, war crimes, energy crisis, etc.).
To enable these user experiences, DocCracker implements a software pipeline that (a) loads newly available documents from a range of internal and external data sources, (b) “cracks” these documents by applying a variety of natural language processing tools to extract structured data, and (c) uses this structured data to create a search index that supports querying and dashboard creation. Figure 1 below provides a visual overview of the pipeline.
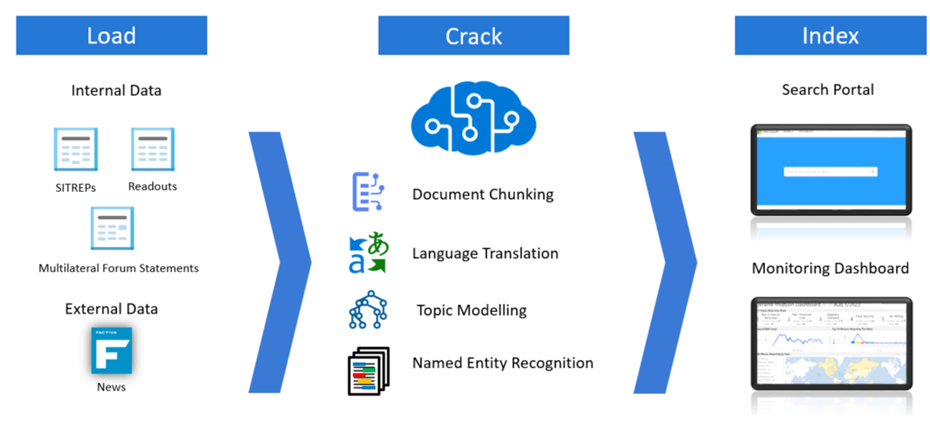
Figure 1: DocCracker processing pipeline
During the “load” stage of the pipeline, internal and external data sources are ingested and preprocessed to extract basic forms of metadata such as report type, report date, source location, title, and web URL. During the “crack” stage of the pipeline, the loaded documents are run through a suite of natural language processing tools to provide topic labels, identify named entities, extract summaries, and translate any non-English text to English. During the final “index” stage of the pipeline, the cracked documents are used to create a search index that support flexible document queries and the creation of dashboards that provide aggregated snapshots of the document attributes used to populate this search index.
Implementation Details
DocCracker is hosted as a web application in Microsoft Azure’s cloud computing environment, and makes use of Azure services to support each stage of processing.
Data Ingestion
During the “load” stage, documents are collected into an Azure storage container either via automated pulls from external sources (e.g., the Factiva news feed, non-protected GAC databases) or manual uploads. Next, a series of Python scripts are executed to eliminate duplicate or erroneous documents and perform some preliminary text cleaning and metadata extraction. Because the documents span a variety of file formats (e.g., .pdf, .txt, .msg, .docx, etc.), different cleaning and extraction methods are applied to different document types. In all cases, however, Python’s regular expression library is used to strip out irrelevant text (e.g., email signatures, BCC lists) and extract relevant metadata (e.g., title or email subject line, date of submission).
Regular expressions provide a powerful syntax for specifying sets of strings to search for within a body of text. In formal terms, a given regular expression defines a set of strings that can all be recognized by a finite state machine that undergoes state transitions upon receiving each character in span of input text; if these state transitions result in the machine entering an “acceptance” state, then the input span is a member of the set of strings being searched for. Upon detection, such a string can either be deleted (i.e., to perform data cleaning) or extracted (i.e., to collect metadata). Almost all programming languages provide support for regular expressions, and they are often a tool of first resort in data cleaning and data engineering projects.
Natural Language Processing
Once the documents have been preprocessed, they are split into chunks of text with at most 5120 characters to satisfy the input length requirements of many of Azure’s natural language processing services. Each text chunk is processed to remove non-linguistic information such as web URLs, empty white space, and bullet points. The chunks are then moved to a new storage container to undergo further processing using a variety of machine learning models.
To identify mentions of persons, organizations, and locations, each text chunk is processed using an Azure service that performs named entity recognition (NER). This service functions by mapping spans of text onto a predefined set of entity types. Next, similar services are used to extract key phrases and a few summary sentences from each document, while also performing inline translations of non-English text. Finally, a sentiment analysis service is used to provide sentiment ratings on specific organizations for display in the application’s landing page. The outputs of each Azure service are saved back to a SQL database as metadata attributes associated with the underlying documents that have been processed.
To augment these results obtained with Azure, GAC’s data science team also developed a customized topic labelling model that identifies the presence of any of ten specific topics of interest in each text chunk. This model uses a technique called “bidirectional encoder representations from transformers” BERT to analyze chunks of text and determine which of the predefined topics are present in the text. The model provides a list of topics found, which can range from zero to ten topic labels.
As shown in Figure 2 below, the model was developed iteratively with increasing amounts of labelled training data. By the third round of model training, highly accurate classification results were obtained for eight of the ten topics, while moderately accurate results were obtained for two of the ten topics. Model testing was carried out using 30% of the labelled data samples, while model training was performed using the other 70% of samples. In total, roughly 2000 labelled samples were used to develop the model.
While this is a small amount of data in context of typical approaches to developing supervised machine learning systems, one of the key advantages of using a BERT architecture is that the model is first pre-trained on a large amount of unlabelled text before being fine-tuned to perform some task of interest. During pre-training, the model simply learns to predict the identities of missing words that have been randomly blanked out of a corpus of text. By performing this task, the model develops highly accurate internal representations of the statistical properties of human language. These representations can then be efficiently repurposed during the fine-tuning stage to learn effective classification decisions from a small number of labelled examples.
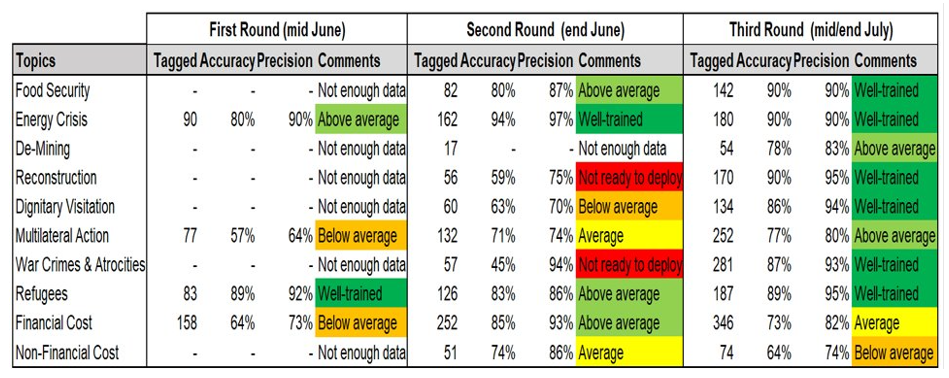
Figure 2: DocCracker AI Model Training Results
Evaluation results are shown following three rounds of training for a customized topic identification model that performs multi-label classification to identify up to ten predefined topics in a chunk of input text. With progressive increases in the amount of training data, the transformer-based neural network model is shownto achieve strong accuracy results for almost all the topics.
Finally, the outputs of the topic model get saved back to the SQL database as additional metadata attributes for each underlying document. This database now contains all the documents that have been ingested along with a rich collection of metadata derived using the natural language processing techniques just described. With this combination of documents and metadata, it is possible to create a search index that allows users to perform flexible document searches and create informative dashboard visualizations.
Indexing
In its simplest form, a search index is a collection of one or more tables that provide links between search terms and sets of documents that match these terms. When a user provides a search query, the query is broken apart into a collection of terms that are used to look up documents in the index. A ranking algorithm is then used to prioritize the documents that are matched by each term so as to return an ordered list of the documents that are most relevant to the search query.
In DocCracker, Azure’s cognitive search service is used to automatically create an index from the SQL database produced during earlier stages of the processing pipeline. Once this index is created, it is straightforward to create a landing page that allows users to enter search queries and obtain relevant documents. The metadata used to create the index can also be exported to CSV files to create dashboards that track a range of time-varying measures of how the situation in Ukraine is unfolding. For example, by selecting the metadata fields for topic labels and dates, it is possible to display the frequency with which different topics have been mentioned over time. Similarly, by selecting on named entities, it is possible to visualize which persons or organizations have been mentioned most often over a given time range. The volume of reporting coming out of different missions can also be easily tracked using a similar method of selection.
Overall, the search index provides a structured representation of the many unstructured SitReps, reports, and news articles that have been ingested into DocCracker. With this structured representation in hand, it becomes possible to enable search and monitoring capabilities that aid the important analytical work being done by the officials at Global Affairs tasked with managing Canada’s response to the Russian invasion.
Next Steps
Given the ever-increasing speed with which international crises are being reported on, it is essential to develop tools like DocCracker that help analysts draw insights from large volumes of text data. To build on the current version of this tool, the GAC data science team is working on several enhancements simultaneously. First, Latent Dirichlet Allocation (LDA) is being assessed to automatically identify novel topics as they emerge amongst incoming documents, thereby alerting analysts to new issues that might require their attention. Second, generative pre-trained transformer (GPT) models are being used to automatically summarize multiple documents, thereby helping analysts produce briefing notes more quickly for senior decision makers. Finally, stance detection models are being developed to automatically identify the positions that individual countries are adopting with respect to specific diplomatic issues (e.g., the issue of providing advanced weapons systems to Ukraine). With such models in hand, analysts should be able to track how countries are adapting their positions on a given issue in response to both diplomatic inducements and changing geopolitical conditions.
Overall, as tools like DocCracker become more widely used, we expect to see a range of new applications for the underlying technology to emerge. To discuss such applications or to learn more about the GAC data science team’s ongoing efforts in this area, please contact datascience.sciencedesdonnees@international.gc.ca.
Meet the Data Scientist

If you have any questions about my article or would like to discuss this further, I invite you to Meet the Data Scientist, an event where authors meet the readers, present their topic and discuss their findings.
Thursday, June 15
1:00 to 4:00 p.m. ET
MS Teams – link will be provided to the registrants by email
Register for the Data Science Network's Meet the Data Scientist Presentation. We hope to see you there!
Subscribe to the Data Science Network for the Federal Public Service newsletter to keep up with the latest data science news.
- Date modified: