
Data Engineering in Rust
By: Scott Syms, Shared Services Canada
The breadth of the Python ecosystem is invaluable to the data science community. Python's selection of tools allows its users to access expressive environments to explore data, train machine learning models and display results in a self-documenting format. It's even been suggested that Jupyter Notebooks, a popular Python data exploration environment, replace the traditional scientific paper.Footnote 1
However, Python has its issues. The very elements that make it accessible and usable, such as dynamic typing, reference counting, and the global interpreter lock, can prevent programs from making full use of available computing resources. This is most apparent when processing large datasets or computational intensive workloads.
Typically, there are two approaches to large computing workloads in Python. C
For data scientists working with big data or heavy computational workloads, Python provides some work-arounds. Computational accelerators such as Numba,Footnote 2 PyPyFootnote 3 and PystonFootnote 4 use leverage coding optimizations to add speed to single machine development environments. When it's combined with Python's concurrency support,Footnote 5 these libraries can boost the processing capacity of a single machine.
Another approach employs libraries such as DaskFootnote 6 and PySparkFootnote 7 to distribute processing over several machines. There's nothing stopping you from doing both – optimize in place and distribute the load.
Ultimately, the tools you use are defined by implementation constraints. For data scientists with access to managed cloud environments, the ability to spawn hundreds of machines to quickly chew through data is an obvious way to address the computing problem. For users with more modest resources, however, the scalability options may be limited. AI at the edge of the network may not have the same compute capacity available as with cloud environments.
Near the end of 2020, the science publication Nature suggested an alternative to some of the traditional approaches to science data computation.Footnote 8 The author proposed writing scientific software in Rust, an emerging and highly-performant new language.
The Rust programming language made its debut in 2009 as a side project for Mozilla programmer, Graydon Hoare. It offers similar performance to C++, but provides better safeguards around memory use and concurrency. Like C++ and Python, it can be used across a range of platforms – from microcontroller programming, to high capacity asynchronous web applications. Rust applications can be compiled to WebAssembly,Footnote 9 allowing them to run in the browser at near-native speeds.
The combination of speed, safety and interoperability is an ideal mix of features when dealing with a big data engineering problem that comes from the analysis of global ship positional data.
Automatic Identification System
By international agreement, ocean-going vessels must transmit voyage data messages using the Automatic Identification System (AIS).Footnote 10 These messages can be collected from space, aggregated into a global picture of shipping activity and sold to commercial and government organizations. The article Building a Maritime Picture in the Era of Big Data: The Development of the Geospatial Communication Interface+, describes the challenges with collecting vessel position data for global surveillance.Footnote 11
The Canadian Space Agency (CSA) manages Government of Canada contracts for space-sourced global maritime tracking data. On any given day, they distribute millions of positional messages to maritime stakeholders across the government. Over the past decade, the CSA has collected well over 50 billion messages.
National Marine Electronics Association (NMEA) maintains the global AIS standard. A sample of AIS data is provided below.
1569890647\s:VENDOR,q:u,c:1569890555*5F\!AIVDM,1,1,,A,13KG9?10031jQUNRI72jM5?40>@<,0*5C
1569890647\s:VENDOR,q:u,c:1569890555*5F\!AIVDM,1,1,,B,13aEPIPP00PE33dMdJNaegw4R>@<,0*77
1569890647\g:1-2-6056,s:VENDOR,c:1569890555*3A\!AIVDM,2,1,6,A,56:GTg0!03408aHj221<QDr1UD4r3?F22222221A:`>966PW0:TBC`6R3mH8,0*0E
1569890647\g:2-2-6056*58\!AIVDM,2,2,6,A,88888888880,2*22
Each sentence above contains metadata about the position report. They include:
- the time the observation was made by the sensor,
- the source of the detection,
- the time the report was relayed from satellite to a ground station, and
- whether the sentence is a fragment of a group of messages.
Although some of the message is human-readable, important data about ship identity and movement is wrapped in a six-bit ASCII payload near the end of the sentence. Eric Raymond's AIVDM/AIVDO protocol decoding websiteFootnote 12 presents a detailed guide on how ship data is packed within the string.
Decoding AIS with a Rust Application
The goal set for this Rust application is to convert an archive of raw AIS data into a JSON equivalent that can be used for data analysis. The output should preserve the original data for reprocessing, if needed. Reformatting the data as JSON is a valuable step in the data engineering pipeline as it allows the data to be loaded into a DataFrame, a database, or converted into a read-optimized format, such as Apache Parquet.
Below is the desired output when using JSON to packet and preserve original data alongside derived elements.
{
"sentence":"1569888002\\s:VENDOR,q:u,c:1569884202*4F\\!AIVDM,1,1,,B,1:kJS6001UJgA`mV1sFrGHAP0@L;,0*56",
"landfall_time":"1569888002",
"group":"",
"satellite_acquisition_time":"1569884202",
"source":"VENDOR",
"channel":"B",
"raw_payload":"1:kJS6001UJgA`mV1sFrGHAP0@L;",
"message_type":1,
"message_class":"singleline",
"mmsi":"725000984",
"latitude":-45.385661666666664,
"longitude":-73.55857,
"call_sign":"CQ4F3",
"destination":"HALIFAX",
"name":"SS MINNOW",
"ship_type":"23",
"eta":"",
"draught":"",
"imo":"",
"course_over_ground":"86950448",
"position_accuracy":"0",
"speed_over_ground":"101",
"navigation_status":"0"
}
Walking through the RUST program
To extract data from AIS data, each character in the payload must be converted from six-bit ASCII to its binary equivalent and the entire sentence is merged into a long binary string. Pieces of string are converted back into human readable numbers and text.
Figure 1: Extracting data from the payload requires it to be converted to binary.
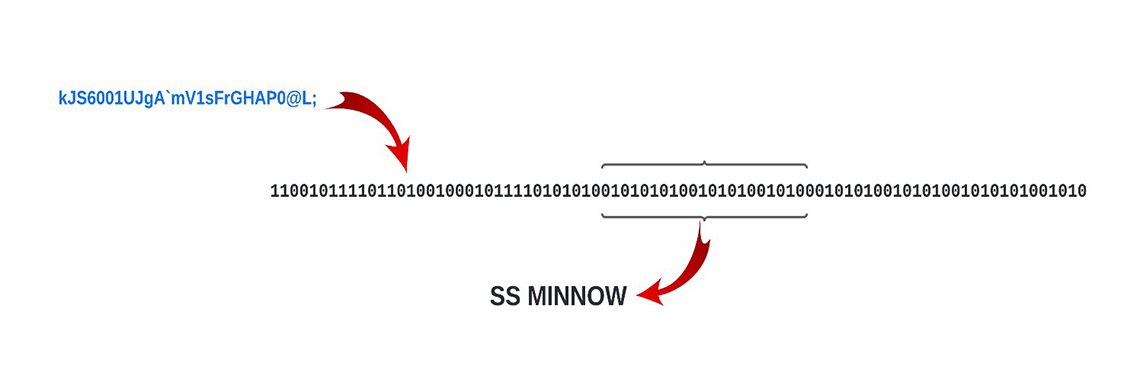
Figure 1: Extracting data from the payload requires it to be converted to binary.
The payload is being converted to binary before the data can be extracted. The process is described in the following section. Image in text: kJS6001UJgA'mV1sFrGHAP0@L; 110010111101101001000101111010101001010101001010100101000101010010101001010101001010 SS MINNOWTo help squeeze all the computing possible from the host machine, Rust offers "fearless concurrency". The workload can be easily distributed across all available computer cores with message-passing channels relaying the data between threads.
The process is divided into three pools. The first is a single-threaded process that reads a source file of AIS data, inserting each line into a struct field, and passes the struct to a pool of threads that does the initial parsing through a channel.
The receiving thread parses the single line position messages, and forwards the results to a file writer as a JSON packet. Multiline sentences are passed to a second pool of threads that cache and reassemble sentence fragments. Again, these results are forwarded to the file writer as a JSON string.
Given that processing is handed off to competing concurrent threads, there are no order guarantees in output. Queuing delays and differences in processing time can ensure the output for each report will not be the same order as the input.
Program highlights
Figure 2: Program process
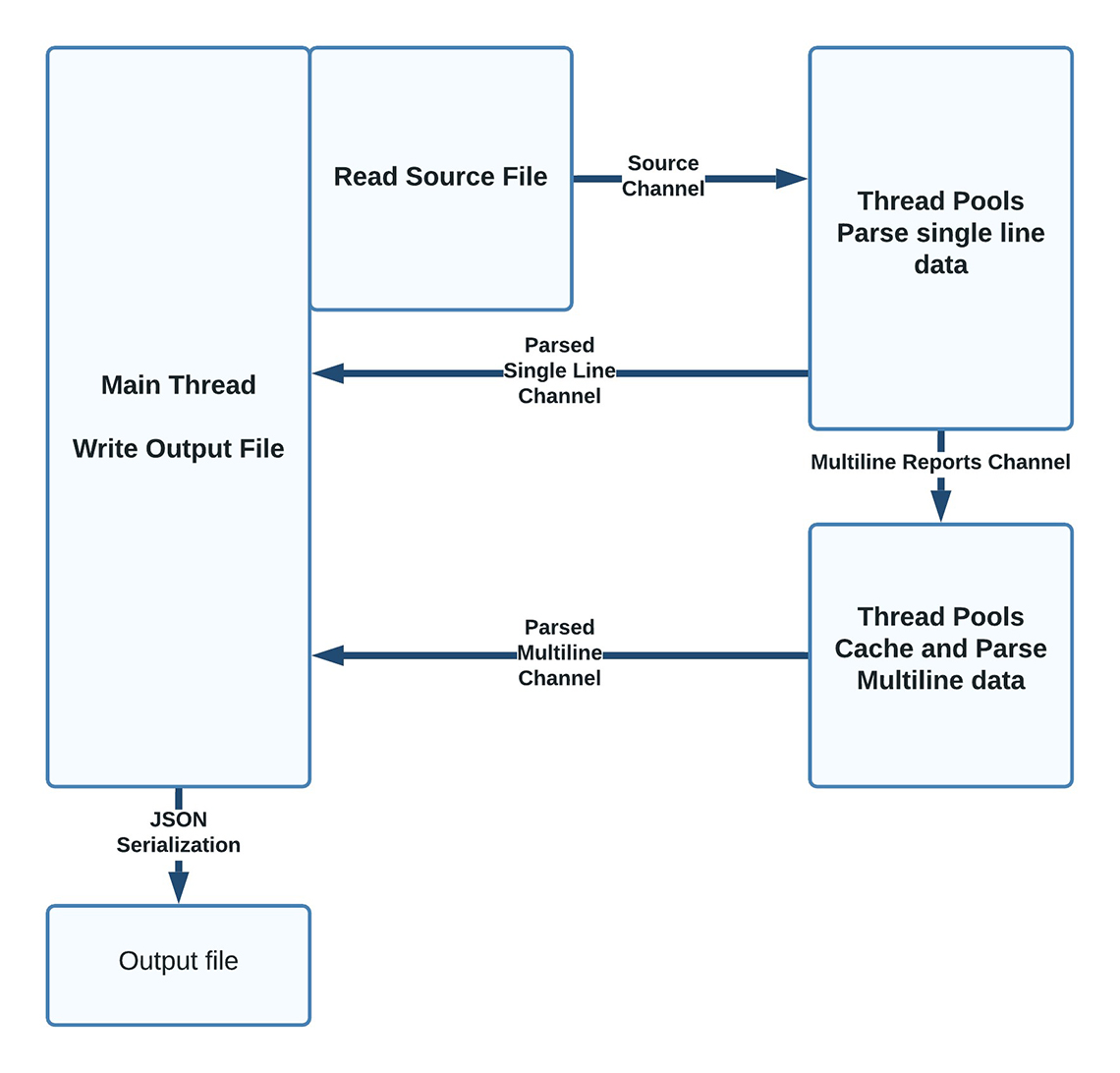
Figure 2: Program process
This program process begins at the Main Thread and the Output File. The Read Source File box is adjacent to it. From there, a Source Channel arrow points to the next step, which is the Thread Pools Parse Single Line Data via the Multiline Reports Channel. From this point, the process can either loop back to the Main Thread again as a Parsed Single Line Channel or down to the Thread Pools Cache and Parse Multiline Data process. From there, it loops back to the Main Thread via the Parsed Multiline Channel. The option is to either continue in the process or via JSON Serialization, it creates the Output File.Regular expression can be used to extract human-readable data in the AIS sentence, but additional work has to be done to convert the data from the six-bit payload to a binary string, take slices of the result and convert these slices back to text, floats and integers.
Cargo and version pinning
Rust makes use of a well-thought build system where package dependencies and build directives can be specified in a definition file.
[package]
name = "rustaise"
version = "0.1.0"
edition = "2021"
[dependencies]
crossbeam-channel = "0.5.2"
threadpool = "1.8.1"
num_cpus = "1.13.1"
hashbrown = "0.12.0"
clap = "3.0.7"
regex = "1.5.4"
bitvec = "1.0.0"
serde = { version = "1.0.136", features = ["derive"] }
serde_json = "1.0.78"
[profile.release]
lto = true
Dependencies called "Crates" can be listed with a specific version. Upgrading to a different release of the crate has to be explicitly done, mitigating errors from moving to different library versions.
The iron fist of variable scoping
One of the methods Rust uses to maintain memory safety, is to tightly control variable scope.
// Let's assign 21 to x
let x = 21;
{
// Now let's assign 12 to x
let x =12;
}
// Since the scope has ended for the previous assignment
// the value of x is still 21
println!("{}", x);
The code snippet above would print the number "21" because the assignment "x = 12" is only valid between the braces.
This is a powerful way to keep your memory in order, but it can be counter-intuitive. For example, the following doesn't work because the variable -x is descoped at the end of the jf block brace pair.
if y == 1 {
let x = 21;
} else {
let x = 0;
}
println!("{}", x);
}
One way to deal with this is to create an anonymous function where the output of the function is assigned to the variable. Variable assignments with nested if and match evaluations are used throughout the program.
let y = 1;
let x = 21;
let x: i8 ={
if y == 1 {
67
}
else {
0
}
};
println!("{}", x);
The rigid control of variable lifetimes and ownership changes the way you structure your program.
Resistance is futile
The compiler is very chatty and will refuse to compile code that transgresses Rust's guard rails.
error[E0308]: mismatched types
--> src/main.rs:8:10
|
8 | 67.0
| ^^^^ expected `i8`, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `playground` due to previous error
While sometimes frustrating, the compiler's messages are helpful in determining the cause of the error. The mantra "work with the compiler" is often seen in online comments.
The software begins by defining a struct that will hold the raw sentences and extracted data as it passes through the workflow.
#[derive(Serialize, Default, Clone, Debug)]
struct PositionReport {
pub sentence: String,
pub landfall_time: String,
pub group: String,
pub satellite_acquisition_time: String,
pub source: String,
pub channel: String,
pub raw_payload: String,
pub message_type: u64,
pub message_class: String,
pub mmsi: String,
pub latitude: f64,
pub longitude: f64,
pub call_sign: String,
pub destination: String,
pub name: String,
pub ship_type: String,
pub eta: String,
pub draught: String,
pub imo: String,
pub course_over_ground: String,
pub position_accuracy: String,
pub speed_over_ground: String,
pub navigation_status: String,
} // end of struct PositionReport
Note the #Derive keyword preceding the struct definition. Although Rust is not an object-oriented language like Java, it allows methods to be shared across structures using a feature called Traits in a way that emulates inheritance.
In the declaration above, the Serialize, Default, Clone and Debug traits are being added to the struct.
Thread Pools
Defining thread pools are quite simple in Rust. The program finds the number of available cores and declares the number of workers for each thread.
For loops are used to launch individual threads.
// Workers are the number of CPUs.
let n_workers = num_cpus::get();
let reading_thread = ThreadPool::new(1);
let extraction_pool = ThreadPool::new(n_workers);
let multiline_assembly_thread = ThreadPool::new(n_workers);
for _a..n_workers: {
multiline_assembly.execute(move || {
// Do stuff
}
}
for _b..n_workers: {
extraction_pool.execute(move || {
// Do stuff
}
}
reading_thread.execute(move || {
// Do stuff
}
For loops control the number of threads launched, while the move keyword passes the current variables to the thread.
Channel Definitions and Flow Control
The relay channels between the threads are defined with a limit to prevent the producing threads from overfilling the channel and exhausting memory. By default, the program sets the upper bound to 500,000 elements, but it can be changed from the command line to best fit the available memory.
Each declaration defines a sending and receiving channel, and the data types that will be running across the message bus.
let (raw_file_tx, raw_file_rx): (Sender<PositionReport>, Receiver<PositionReport>) = bounded(flow_limit);
let (multiline_handling_tx, multiline_handling_rx): ( Sender<PositionReport>, Receiver<PositionReport>) = bounded(flow_limit);
let (ready_for_output_tx, ready_for_output_rx): (Sender<String>, Receiver<String>) =
bounded(flow_limit);
Because of Rust's rules on variable reuse, the channel data type has to be cloned in each thread, but each clone actually refers to the original instance of the message bus.
extraction_pool.execute(move || {
let raw_file_rx = raw_file_rx.clone().clone();
let extract_ready_for_output_tx = extract_ready_for_output_tx.clone();
let multiline_handling_tx = multiline_handling_tx.clone();
}
Matching messages
AIS message types determine how ship information is stored in the six-bit payload, so any parsing task has to begin with carving out the type of the current sentence and casting it as an unsigned INT in the appropriate struct field.
line.message_type = pick_u64(&payload, 0, 6);
From there, the message type can be matched against parsing templates and other fields in the struct populated.
match line.message_type {
1 | 2 | 3 => {
// If the message is class A kinetic.
line.mmsi = format!("{}", pick_u64(&payload, 8, 30));
line.latitude = pick_i64(&payload, 89, 27) as f64 / 600_000.0;
line.longitude = pick_i64(&payload, 61, 28) as f64 / 600_000.0;
...
}
5 => {
// If the message is class A static.
line.mmsi = format!("{}", pick_u64(&payload, 8, 30));
line.call_sign = pick_string(&payload, 70, 42);
line.name = pick_string(&payload, 112, 120);
...
}
Arc Mutexes and Hash maps
Assembling multiline messages in multiple threads requires caching sentence fragments in a way that can be shared. This program uses a shared hash-map wrapped in a mutex to hold sentence fragments.
// Initiate Hashmaps for multisentence AIS messages
// These are wrapped by ARC and Mutexes for use under multithreading.
let mut payload_cache: Arc<Mutex<HashMap<String, String>>> =
Arc::new(Mutex::new(HashMap::new()));
let mut source_cache: Arc<Mutex<HashMap<String, String>>> =
Arc::new(Mutex::new(HashMap::new()));
let mut sat_time_cache: Arc<Mutex<HashMap<String, String>>> =
Arc::new(Mutex::new(HashMap::new()));
Like the interprocess channels, the hash-maps must be cloned in each thread instance.
// Initiate Hashmaps for multisentence AIS messages
let payload_cache = Arc::clone(&mut payload_cache);
let source_cache = Arc::clone(&mut source_cache);
let sat_time_cache = Arc::clone(&mut sat_time_cache);
Each hash-map needs a lock defined in each thread to deconflict the reads and delete from multiple threads.
let mut payload_lock = payload_cache.lock().unwrap();
let mut source_lock = source_cache.lock().unwrap();
let mut sat_time_lock = sat_time_cache.lock().unwrap();
// insert into time cache if struct field is not empty
if line.satellite_acquisition_time.len() > 0 {
sat_time_lock.insert(line.group.clone(), line.satellite_acquisition_time);
}
JSON serialization
The SERDE crate offers a convenient way to serialize a struct to a JSON string. At the end of the parsing cycle, each thread converts the populated struct to JSON for writing to file.
ready_for_output_tx.send(serde_json::to_string(&line).unwrap());
The output of the program can be loaded in Pandas with the following command:
import pandas as pd
df=pd.read_json("output.json", lines=True)
It can also be converted to a compressed Parquet file using use Dominik Moritz's json2parquet program.
json2parquet -c brotli norway.json norway.parquet
Running the program
Executing the program without parameters will output the following:
error: The following required arguments were not provided:
<INPUT>
<OUTPUT>
USAGE:
rustaise <INPUT> <OUTPUT> [FLOW_LIMIT]
For more information try --help
With the --help flag.
AIS parsing program 1.0
Scott Syms <ezrapound1967@gmail.com>
Does selective parsing of a raw AIS stream
USAGE:
rustaise <INPUT> <OUTPUT> [ARGS]
ARGS:
<INPUT> Sets the input file to use
<OUTPUT> Sets a custom output file
<FLOW_LIMIT> Sets a limit on the number of objects in memory at one time (default: 500000)
<PARSE_THREADS> Sets the number of threads to use for parsing (default: number of CPUs)
<MULTILINE_THREADS> Sets the number of threads to use for multiline parsing (default: number of CPUs)
OPTIONS:
-h, --help Print help information
-V, --version Print version information
Uncompressing the norway.7z program and running the following will generate a JSON file with parsed contents.
rustaise norway.nmea norway.json
The FLOW LIMIT parameter allows you to limit the data held in the message channels. In some memory constrained systems, capping in-flight messages prevents out-of-memory issues. The PARSE_THREADS and MULTILINE_THREADS are optional parameters that provide control over the number of threads created for the single and multiple line parsing threads.
Speed results
Rust lives up to its reputation as a blazingly fast language.
The execution results in the timing table below are obtained from a MacBook 2.3 GHz 8-Core Intel i9 with 32Gb of memory. In the timing table, the row indicates the number of lines in the input file. The first column shows the processing time required to process the sample, and the final column forecasts how much data could be processed in a day at the sample rate.
| Sample Size | Timing | Forecasted Volume per Day |
|---|---|---|
| 1 million | 7s | 12,342,857,142 |
| 25 million | 65s | 33,230,769,230 |
| 174 million | 435s | 34,560,000,000 |
These figures suggest that the software would be able to process a 50-billion row AIS archive in just under two days, on a single laptop.
Last thoughts
This is my first attempt to do serious programming in Rust and even from a novice's vantage point, there's room for improvement.
- First, because I have imperfect knowledge of the language, the solution may not be idiomatic, i.e. making the best use of what Rust offers to solve the problem.
- The program largely ignores Rust's error handling framework. Initializing the struct with default values may unnecessarily consume memory. Leveraging struct methods and custom traits may offer some advantages.
- Refactoring the code into Rust's library and module format would be a step toward code readability.
- Finally, Rust offers unit-testing framework that would make the code more maintainable.
Generally, the "juice is worth the squeeze" here. Even with the code's drawbacks, Rust works as advertised and the effort in learning the language is worthwhile in situations where the code will be reused or where execution time is a concern.
Alternatively, developers who want to take advantage of Rust's performance while staying in the
Python ecosystem could use the PyO3Footnote 13 project to create native Python extensions in Rust.
Getting the code
All code is available at Github - ScottSyms/RustAISe.
Please feel free to use it and I'd appreciate any feedback you might have.
Licenses
The software is made available under an Apache 2.0 license.
The archive includes a 7zip compressed sample of AIS data from the government of Norway. It's made available under the Norwegian License for Open Government Data (NLOD) 2.0.Footnote 14
Some of the bitvec manipulation code is taken from Timo Saarinen's nmea-parser packageFootnote 15 which is provided under an Apache 2.0 license.
Scott Syms is a Technical Advisor with Data Science and Artificial Intelligence, a part of SSC's Chief Technology Officer Branch.
- Date modified: