
Implementing MLOps with Azure
By: Jules Kuehn, Shared Services Canada
Machine Learning Operations is a variation of DevOps that addresses concerns specific to Machine learning (ML). Like DevOps, MLOps enables the continuous integration and deployment (CI/CD) of Machine learning (ML) models, but it also automates re-training on new data and tracks the results of different training runs (or experiments).
A common issue with ML models is declining performance over time. This is known as a "drift" (visit The Ultimate Guide to Model Retraining for more information on drift). Imagine an ML model that predicts whether a house in Ottawa will sell above its asking price, when given information about the house and the listing price. When the model was deployed five years ago, it was able to make this prediction with 95% accuracy. However, if the model was never re-trained with updated data, its predictions would not reflect Ottawa's current housing market and would therefore be less accurate. To resolve this issue, an MLOps system can automatically re-train and re-deploy models to incorporate more recent data and track the model's performance over time.
Shared Services Canada's (SSC) Data Science and Artificial Intelligence team has developed several ML models as proof-of-concept solutions for SSC business problems. As a starting point in the MLOps journey, the team collaborated with Microsoft to develop a functional MLOps solution entirely within the Azure ecosystem.
The MLOps system spans several components such as source control, experiment tracking, model registries, CI/CD pipelines, Azure ML APIs, Docker and Kubernetes. Using this system enables the team to continuously deliver REST APIs for the best-performing ML models and make them available on the newly developed Government of Canada API Store.
Model development
To speed up implementation, the team used Azure Software as a Service (SaaS) offerings to accomplish the majority of tasks. This included data loading with Azure Data Factory, model development in Azure Databricks notebooks, experiment tracking and model deployment with Azure ML, and source control and CI/CD with Azure DevOps.
Tracking experiments and models
The Databricks notebooks log run metrics and register models in an Azure ML workspace when a model training run is complete (visit Log & view metrics and log files and Model Class for more information). This is useful when runs are initiated manually during model development and when they're executed as a job within CI/CD pipelines. During model development, it is possible to track improvements to metrics, such as accuracy, while adjusting hyper parameters. When run as a pipeline job, you can monitor changes to metrics as new data is used in re-training.
Source control and continuous integration
The source control repository for this model is made up of three folders:
- Notebooks—the Databricks notebooks code
- Pipelines—two pipelines to train and deploy models
- API—the code to wrap the trained model in a REST API.
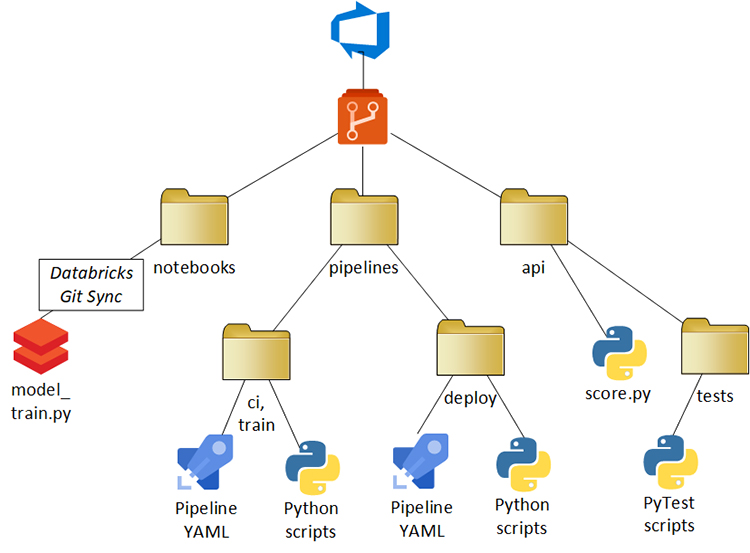
Figure 1 – General source control repository structure
Description - Figure 1
Tree diagram of DevOps repository with 3 top level folders. The first folder is Notebooks, which is connected via Databricks Git Sync to model_train.py. The second folder is pipelines, which contains two subfolders, each containing Pipeline YAML and Python scripts. These subfolders are named "ci / train" and "deploy". The third top level folder is "API", which contains score.py and a tests subfolder, which contains PyTest scripts.
Notebook pull request pipeline
Although literate programming with notebooks (e.g. Jupyter) is common practice for data science, cloud notebook environments do not always integrate effectively with source control. If multiple team members are working on a project, notebooks can become disorganized. The team developed a workflow that incorporates best practices for source control management, such as feature branches and integration tests in pull requests.

Figure 2 – Data science notebooks
Description - Figure 2
A disorderly desk with papers labelled "Data Science Notebooks" scattered all over its surface, on the floor and stuffed into a nearby garbage bin.
Within Databricks, all notebooks in a fixed-location main folder are synchronized to follow the main branch in an Azure DevOps git repository. Before changing the model code, a team member creates a copy of this folder in Databricks and a corresponding new branch in DevOps, then sets up the git sync between them. When they're satisfied with the changes, the team member commits the notebooks in Databricks, then creates a pull request (PR) in DevOps.
Any PR that includes changes to notebook code triggers a CI pipeline that ensures changes to the notebooks will not break. It begins by copying the feature branch notebooks to a fixed-location integration test folder referenced by a Databricks job, which is then triggered by the pipeline through the Databricks API.
To speed up the execution of this test, a parameter is passed to the notebook indicating that this is a test and not a full training job. The model is trained on a 5% sample for one epoch and the resultant model is not registered.
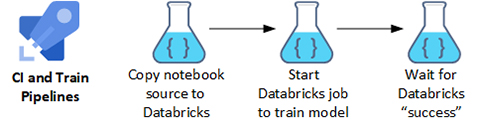
Figure 3 – CI and Train Pipelines with Databricks
Description - Figure 3
Diagram of CI and Train Pipelines. Step 1: Copy notebook source to Databricks. Step 2: Start Databricks job to train model. Step 3: Wait for Databricks "success".
The pipeline continues to poll Databricks until the job is complete. If the notebook executes successfully, merging to the main branch may continue.
Model deployment
Since the SSC team plans to deliver most of their models on the GC API Store, they want to move from notebooks to REST API applications as quickly and reliably as possible.
Containerizing the model
For simple applications, the Azure ML API can deploy a registered model as a containerized application using a few lines of code at the end of a notebook. However, this option does not address many operational requirements such as scaling. More importantly, it doesn't allow much flexibility to pre- and post-process model inputs and outputs. Instead, we use the Model.package() from the Azure ML Software Development Kit function from the Azure ML Software Development Kit (SDK) to create a Docker image. Then, the image is deployed to a previously configured Kubernetes cluster and the endpoint is registered with the GC API Store.
By default, the function pulls the latest registered version of the model, but can also use the experiment logs to dynamically select a model based on any metric that was logged from the notebook (e.g. to minimize loss).
Deployment pipeline
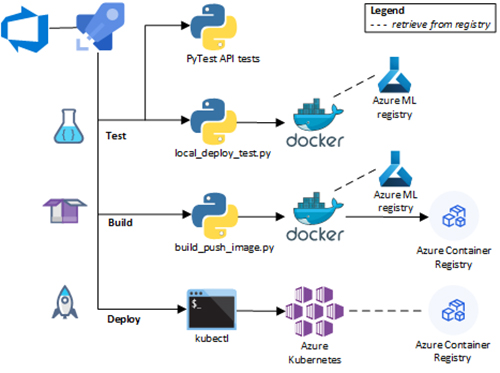
Figure 4 – Deployment Pipeline
Description - Figure 4
Diagram of deployment pipeline with 3 root stages: Test, Build, and Deploy. The Test stage runs PyTest API tests and local_deploy_test.py, which involves Docker retrieving a model from the Azure ML registry. The Build stage runs build_push_image.py, which also involves Docker retrieving a model from the Azure ML registry, but also pushes the Docker container to the Azure Container Registry. The Deploy stage runs the command line application kubectl, which connects to Azure Kubernetes and retrieves the container from the Azure Container Registry.
As its name implies, Azure DevOps offers more than just source control – it can also define pipelines to automate CI and CD tasks. The pipelines are defined by YAML files and leverage Bash and Python scripts.
Unlike the notebook PR pipeline, the deployment pipeline is triggered by any commit to the main branch. It's comprised of three stages:
- Testing the code: Using PyTest, unit test the API with correct and incorrect inputs. As an integration test, Model.deploy() the web service locally on the agent pool VM and run similar tests, but over HTTP.
- Building and registering the Docker container: Build a Docker image with Model.package(), passing in custom API code. Register the container to an Azure Container Registry.
- Deploying to Kubernetes: Using kubectl apply, connect to the previously-configured Azure Kubernetes Service, connect to the previously-configured Azure Kubernetes Service. Pass a manifest file pointing to the new image in the container registry.
This process retains the same API endpoints through redeployments and does not disrupt delivering the application through the GC API Store.
Model re-training pipeline
The model re-training pipeline is similar to the pull request pipeline but it runs a different Databricks job that points to the main branch notebook. The notebook logs the run metrics and registers the new model in Azure ML, then triggers the deployment pipeline.
Model training can be resource intensive. Running the notebook as a job on Databricks gives us the option of selecting a high performance compute cluster (including GPU). The clusters are automatically deallocated when the training run is complete.
Rather than being triggered by a particular event, pipeline runs can also be scheduled (visit Configure schedules for pipelines for more information). Many of the models rely on data from SSC's Enterprise Data Repository (EDR), so the team can schedule the model re-training pipeline to follow the EDR's refresh cycle. This ensures that the deployed model is always based on the most current data.
Conclusion
To provide a repeatable workflow for deploying ML models to the GC API Store, SSC integrated several Azure SaaS offerings to make a functional MLOps solution
- Azure DevOps: Source code repository; CI/CD and re-training pipelines
- Azure Databricks: ML model development in notebooks; synchronized to DevOps git repository
- Azure ML: Experiment tracking and model registration; building Docker images
- Azure Kubernetes Service: Container serving; pointed to by the GC API Store.
Finally, it's worth noting that this approach is just one of many possible solutions. The Azure ML APIs that the SDK relies on are under active development and change frequently. The team is continuing to explore open-source and self-hosted options. The MLOps journey is far from over, but it's well under way!
Please email the SSC Data Science and Artificial Intelligence team: ssc.dsai-sdia.spc@canada.ca, if you have any questions about this implementation or if you just want to chat about machine learning.
- Date modified: