
Non-Pharmaceutical Intervention and Reinforcement Learning
By: Nicholas Denis, Statistics Canada
COVID-19 has impacted the lives of Canadians in profound ways, including many of our behaviours. Across Canada, provinces and territories have imposed restrictions and limitations on the population with the aim of producing behaviours that reduce the spread of COVID-19, and reduce hospitalizations and deaths resulting from such infections. These measures seek to enforce various Non-Pharmaceutical Intervention (NPI) strategies, which are behavioural changes that a population can make to reduce the spread of an infection. One of the many factors that play into the selection of NPIs is the use of epidemiological modelling, which has traditionally been used to simulate, model and/or forecast the effect of a set of specific scenarios (e.g. school closures, physical distancing and closure of non-essential businesses). Rather than modelling specific scenarios with fixed assumptions concerning scenario-specific population dynamics, recent work produced by data scientists at Statistics Canada developed a novel epidemiological modelling framework that allows researchers to optimize over the space of NPIs to determine the optimal set of population behaviours that minimize the spread of an infection within simulations. This approach was made possible by the use of Reinforcement Learning (RL), and was carried out in collaboration with partners at the Public Health Agency of Canada.
What is Reinforcement Learning?
Reinforcement Learning (RL) is a sub-field of machine learning (ML) that has seen impressive results in recent years: from algorithms that learn to play video games, to the strategy board game GO, from automating drug design to reducing energy usage. But what is RL? The notions of an agent and an environment are at the heart of RL. An agent has the ability to make decisions in the form of taking actions. At any given time, the agent and the environment can be described by the current state. At each time-step the agent selects an action and, after taking an action, the environment will transition to a new state, and in doing so, will produce a notion of utility, called a reward, which the agent receives as a form of feedback. The goal of RL is for the agent to learn from its interactions with the environment and learn an action selection strategy, called a policy, which maximizes the expected sum of rewards the agent will receive while following that policy in its environment. Formally, RL uses the mathematical framework of Markov Decision Processes Footnote 1 to employ its learning algorithms.
The simulation environment
All traditional epidemiological modelling approaches represent a population and the dynamics between agents or population subsets, called compartments, within the population. For this work, a simulation environment was built using open data from Statistics Canada (census and social surveys) and the Canadian Institute of Health Information Footnote 2. These data were used to build a population of agents that accurately represents Canadians in terms of key demographic information, such as age, household attributes, employment data and health attributes (e.g. presence of comorbidities, senior living centres, etc.). Agents are either employed, unemployed or full-time students. Epidemiological parameters were provided by the Public Health Agency of Canada Footnote 3, which include empirically derived parameters for all aspects related to infection events and infection progression.
Once a population of agents are constructed through a generative sampling process, the simulation runs for a set number of simulated days (e.g. 120 days). Briefly, for each waking hour, each agent must take an available action based on its current state, according to its policy. Some logical rules are enforced, such as if an agent is employed and it is currently time for work, the set of actions available to that agent are restricted to work-related actions. Actions are generally related to work, school, social activity, economic activity (i.e. going to a food-related store), home activity and the ability to get tested for COVID-19. In the event of a positive test result, agents self-isolate at home for two weeks, and a contact tracing mechanism takes place. Each agent uses their current state and their policy to select actions. The state of an agent thus provides all the information that the agent currently has to inform its choice of action. Here, information such as age, health status, whether the agent is symptomatic or not and the agent's current location are combined as a vector to represent each agent's current state. After each agent has selected their actions, the simulation environment is updated so that agents move to their selected destinations. If an infected agent interacts with a susceptible agent, an infection event determines whether an infection takes place.
Finally, after every action is taken, each agent receives a numeric reward which is used by the RL algorithm to perform learning updates to improve each agent's policy. Any time an agent becomes infected or infects a susceptible agent, it receives a reward of -1, otherwise all rewards are 0. By only providing negative rewards to infection events, and combining RL solution strategies that converge on policies (behaviours) that maximize the expected sum of rewards, the optimal policy is equivalent to the one that minimizes the spread of COVID-19. It is important to note that the agents' behaviours are not encoded whatsoever and that by iteratively interacting with the environment from simulation to simulation, the agents learn behaviours that minimize the spread of COVID-19 through a process akin to trial and error. By giving the agents the 'freedom' to explore a wide range of actions and behaviours, this framework allows researchers to optimize over a vast solution space, freeing researchers from the more traditional approach of modelling a small set of specific scenarios.
Learning to reduce infections

Description - Figure 1
Agents learn to reduce infections over time. A plot showing the cumulative number of infections as a percentage of the population size over each RL training and testing epoch. Each epoch is plotted slightly darker in colour, leaving the darkest plot for the best performing epoch.
A population of 50,000 agents was built and 100 simulations were run while applying Reinforcement Learning. Figure 1 plots the history of the cumulative number of infections from simulation (epoch) to simulation. In early simulations, a large proportion of the agent population became infected; however, as they improved their policies over time, the agents learned to minimize the spread of COVID-19.
Once the agents have learned policies that minimize the spread of infection, their behaviours can be analyzed. Figure 2 demonstrates the distribution over actions essential worker agents make during work hours (left) and student agents make during school hours (right), both in the presence or absence of symptoms. A common trend emerged: when agents were asymptomatic, they strongly preferred to take 'physically distanced' versions of any particular action (wearing a mask and keeping a two meter distance from others). However, in the presence of symptoms, agents learned to get tested for COVID-19 (>38%, >57%; essential employees and students, respectively), despite not being provided any positive reward to do so. Additionally, employees and students learned to stay home when symptomatic (~43%, >42%; essential employees and students, respectively). In this way, behaviours can be mined and shared with policymakers to inform NPIs, for example, as these results suggest advocating to the public the importance of testing for COVID-19 when feel symptomatic, as well as the importance of staying home from work or school when symptomatic.
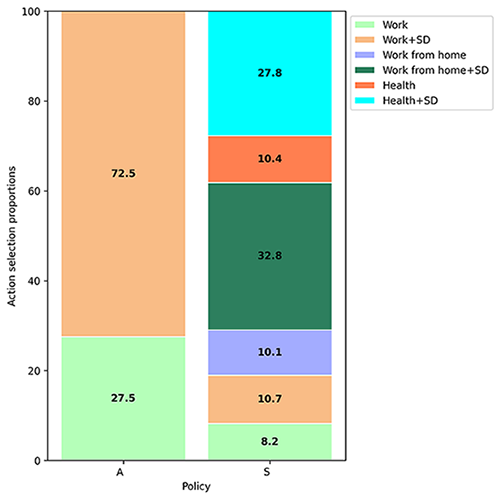

Description - Figure 2
Analysis of learned agent behaviours for work and school related states. A stacked bar chart demonstrating the learned policies for essential workers (left) and for students (right), depending on presence of symptoms.
Comparison to baselines
The learned behaviours of the RL agents were then compared against several agent population baselines. Baseline 1 involved agents selecting actions uniformly at random, without access to 'physically distanced' action variants, while baseline 2 employed a similar action selection approach, but with access to 'physically distanced' action variants. Baseline 3 expanded upon baseline 2 by employing the contact tracing and mandatory self-isolation mechanisms following a positive COVID-19 test result.
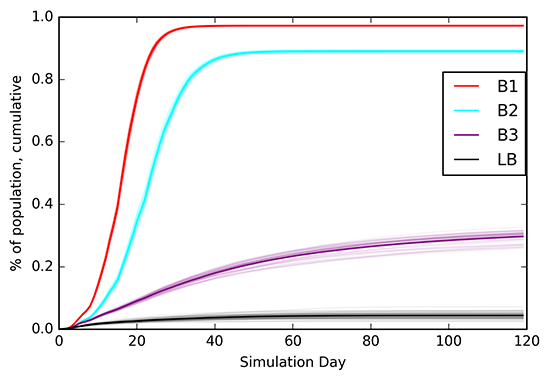
Description - Figure 3
A plot comparing the cumulative number of infection between baseline 1 (B1), baseline 2 (B2), baseline 3 (B3), and learned behaviours (LB). Each experiment is run with 50 repeats and plotted in light colour, with the mean plotted in dark color.
Figure 3 demonstrates the cumulative infections for each experiment, showing that when agents have access to physical distancing actions and self-isolation/contact tracing, the number of infections that occur within a simulation dramatically decreases. Moreover, the learned behaviours of the RL agents improve significantly over each of the baselines. An analysis of the infection events within each experiment demonstrated a significant decrease in social, work, school and public (economic) related infection events by the RL agents. However, >60% of infection events for the RL agents occurred when an infected agent was self-isolating at home with a susceptible cohabitant following a positive test. This demonstrates the importance of recommendations and guidelines on how to safely self-isolate at home with others.
Representing non-compliance within the model
An important factor to consider when modelling NPIs is the existence of compliance fatigue, or attrition, which are the terms used to describe the observation that, over time, members of the population gradually become less inclined to follow NPIs. As well, there is a distribution over how compliant members of a given population may be with respect to NPIs. Including non-compliance into the modelling framework was important to collaborators at the Public Health Agency of Canada. For this reason, we included experiments with variants of the RL agents described earlier: wildcards and attrition. In the wildcards experiments, each agent samples a probability that it is 'compliant' and follows the RL policy, otherwise the agent follows a default agent behaviour. In the attrition experiments, each agent begins fully compliant, but after each day, each agent's probability of following the RL policy decreases stochastically, thus producing a population that eventually returns to their default behaviours.
Figure 4 demonstrates the daily and cumulative infection plots for the RL agents, RL + wildcards and RL + attrition experiments. It is interesting to note that in the presence of wildcard agents, the population is still able to eventually approach zero daily infections, though delayed with respect to the RL agents. However, the attrition experiment demonstrates the importance of maintaining compliance with NPIs—if these restrictions are relaxed too soon, infections never plateau and continue to increase. Though simulations only ran for 120 days, it is expected that longer durations would have seen a 'second wave' for the attrition experiment.
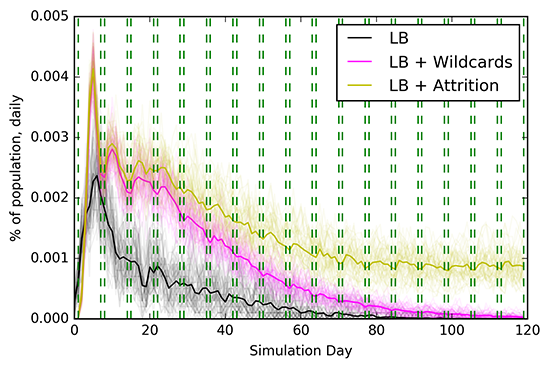
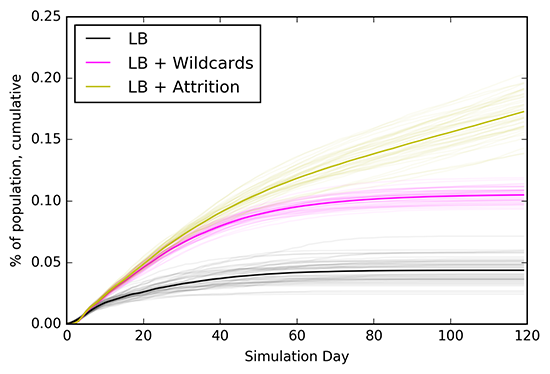
Description - Figure 4
Plots comparing the daily (top) and cumulative (bottom) infection events between LB, LB +WC and LB + attrition. Saturdays and Sundays within the 50 simulation runs are marked in green.
Further analysis demonstrated a periodicity in the daily infections for each of these experiments (Figure 4, % of population, daily). It was found that for the RL agents, weekdays saw a decrease in infections, with weekends resulting in small increases in infections. However, in the presence of wildcards or attrition, the reverse was noticed. Weekdays saw increases in infections and weekends resulted in slight decreases in infections. An analysis revealed that this phenomena was linked to school-related infections, demonstrating that with full compliance (RL agents) schools resulted in less infections and were relatively safe, while with decreasing compliance (RL agents + wildcards/attrition) schools became hot spots for community infection.
One defining characteristic of COVID-19 is the prevalence of asymptomatic individuals being infectious and unknowingly spreading the virus. An analysis revealed that relative to the RL agents, RL agents in the presence of attrition resulted in 5.5x more asymptomatic infection events, demonstrating the importance of maintaining NPI compliance even in the absence of any symptoms.
Further application of agent-based simulation
With the onset of COVID-19 came the need for modelling approaches to inform health-related policy. The Data Science Division within Statistics Canada developed a novel modelling framework that employs Reinforcement Learning to learn agent behaviours that minimize the spread of community infection within simulated populations. RL provided a mechanism to search over a vast solution space of possible behaviours and scenarios, and positions researchers to discover novel scenarios to reduce the spread of infections, rather than being limited to modelling a small fixed number of specific scenarios. A manuscript detailing this research was recently accepted for publication as a chapter in an upcoming book on the mathematical modelling of COVID-19 by the Fields Institute for Research in Mathematical Sciences. The agent-based simulation environment was built using openly available data on the Canadian population; however, this approach could be applied to more local populations, as well as other countries. Moreover, the approach is not specific to COVID-19, but can be applied to any infectious disease with community transmission. Any questions or further information on this work can be directed to the Artificial Intelligence Practitioners and Users Network (sign in to GCcollab and copy the link into your browser).
- Date modified: