
Document Intelligence: The art of PDF information extraction
Author: Anurag Bejju, Statistics Canada
Portable Document Format, or PDF documents, are one of the most popular and commonly used file formats. As the world rapidly moves to a digital economy, PDFs have become an environmentally-friendly alternative to paper, allowing creators to easily share, print and view a file in its intended layout on multiple platforms. They hold a wealth of important information for organizations, businesses and institutions in a format that reflects the paper it replaced.
Although PDFs are a reliable way to format and store data, attempting to scrape, parse or extract their data can be a challenging task. Statistics Canada has been leveraging the power of responsible artificial intelligence (AI) technologies and applying data science solutions to research and build solutions that can mine valuable insights from unstructured sources like PDFs and scanned images. Applying these solutions saves costs, as well as ensures information is provided in a more timely, accurate and secure manner to Canadians. By obtaining and extracting data from PDF documents, we can devise ways to generate high-quality meaningful statistics in a timely manner. This saves a significant amount of time in capturing the data and allows researchers to focus their time on more meaningful analysis.
What is document intelligence?
Working with unstructured documents is complex and can lead to a waste of valuable resources. Many financial services, government agencies and other large companies work with printed and electronic documents that must be transformed and stored in a searchable/query-able data format (e.g. JSON or CSV). The process of extracting and transforming data from PDFs is often done manually and can be resource intensive, requiring members to copy portions of relevant information and format it into a tabular structure. This process can be cumbersome, lead to errors and cause long turnover times. Even with multiple resources for data retrieval, it can take days or weeks to get actionable information.
In response to these challenges, tech companies are creating automation tools that capture, extract and process data from various document formats. Artificial intelligence technologies such as natural language processing, computer vision, deep learning, and machine learning, are creating open-sourced solutions that transform unstructured and semi-structured information into usable data. These document intelligence technologies are called intelligent document processing.
What are the benefits of intelligent document processing?
Intelligent document processing has six key benefits:
- Time: Takes less time to process and build structured data sources.
- Money: Saves costs by reducing manual extraction work.
- Efficiency: Removes repetitive tasks in the workplace and boosts productivity.
- Reliability: Increases accuracy of the information extracted and reduces human error.
- Scalability: Has the potential to scale a large volume of documents with relatively low cost.
- Versatility: Handles structured, semi-structured and unstructured documents in most formats.
Types of PDF documents
The three most common types of PDF documents are:
- Structured PDFs: The underlying layout and structure of these documents remain fixed throughout the dataset. Creating segments and tagging them with appropriate labels, builds automation pipelines to extract and structure values into a tabular format. These can be replicated for forms with similar layouts.
- Text-based unstructured PDFs: If you can click-and-drag to select text in a PDF viewer, then your PDF document is a text-based document. Extracting free text from these documents can be fairly simple but doing so in a layout or context-aware manner can be extremely challenging. The System for Electronic Document Analysis and Retrieval (SEDAR) database used by Statistics Canada (which will be explained in more detail later in the article) has millions of text-based unstructured PDFs that require advanced intelligent document processing techniques to create structured datasets.
- Scanned unstructured PDFs: Scanned PDF documents contain information in multiple shapes and sizes. Additional steps help to localize text components and perform optical character recognition to extract textual tokens. Once the PDF is converted to text and the location for these tokens are identified, you can deploy similar methods used for text-based PDFs to extract information. The latest research in this area will be discussed in the upcoming articles in this series.
Open-source libraries available for PDF extraction
Package 1: PyPDF2
PyPDF2 is a pure-python PDF toolkit originating from the PyPDF project. It can extract data from PDF files or manipulate existing PDFs to produce a new file. This allows the developer to harvest, split, transform and merge PDFs, as well as extract associated metadata for the PDF. As demonstrated in the image, the text extraction accuracy is lower in comparison to other packages and you cannot extract images, bounding boxes, charts, or other media from these documents. This is a good tool if the only objective is to extract free text independent of its layout.
Code Snippet
import PyPDF2
with open(pdf_path, "rb") as f:
reader = PyPDF2.PdfFileReader(f)
page = reader.getPage(1)
output = page.extractText()
Sample PDF

Output

Description - PyPDF2 Sample PDF and Output
An image of a sample PDF with a tabular structure consisting of a header, subheader, line items and a notes column on the right. The output box showing the text extraction has the correct text but is independent of the original layout or details deciphering between subheaders and regular text.
Package 2: PyMuPDF
PyMuPDF (also known as Fitz) is a Python binding for MuPDF—a lightweight PDF, XPS, and E-book viewer, renderer and toolkit, which is maintained and developed by Artifex Software, Inc. It does allow the developer to get much more advanced layout-based features with rendering capability and high-processing speed. Programmers get access to many important functions of MuPDF from within a Python environment. Like PDFMiner (described in Package 3), this package provides only layout information and the developer has to build processes to structure and format it.
Code Snippet
import fitz
import pandas as pd
doc = fitz.open(good_pdf_path)
page = doc[4]
_, _, p_width, p_height = page.MediaBox
text = page.getText("blocks")
output = pd.DataFrame(text, columns=["block_xMin", "block_yMin", "block_xMax", "block_yMax", "block_text", "block_id", "page" ])
Sample PDF

Output
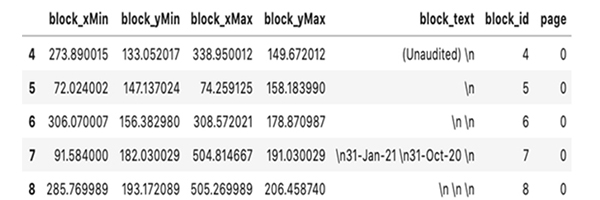
Description - PyMuPDF Sample PDF and Output
An image of a sample PDF with a tabular structure consisting of a header, subheader, line items and a date column on the right. The output box showing the data extraction has the correct layout but the text consists of formulas ready for formatting by the user.
Package 3: PDFMiner
The PDFMiner package allows you to parse all objects from a PDF document into Python objects and analyze, group and extract text or images into a human-readable way. It also supports languages like Chinese, Japanese and Korean CJK, as well as vertical writing. As demonstrated in the image, you can obtain information like the exact bounding box for each text token as a string, as well as other layout information (fonts, etc.). Although this package can be great to localize elements within the document, the developer has to build processes to structure and format it.
Code Snippet
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams, LTTextBox, LTTextLine, LTFigure
import pandas as pd
output = []
def parse_layout(layout):
"""Function to recursively parse the layout tree."""
for lt_obj in layout:
if isinstance(lt_obj, LTTextBox) or isinstance(lt_obj, LTTextLine):
output.append([lt_obj.__class__.__name__, lt_obj.bbox, lt_obj.get_text()])
elif isinstance(lt_obj, LTFigure):
parse_layout(lt_obj) # Recursive
with open(pdf_path, "rb") as f:
parser = PDFParser(f)
doc = PDFDocument(parser)
page = list(PDFPage.create_pages(doc))[1] # Page Number
rsrcmgr = PDFResourceManager()
device = PDFPageAggregator(rsrcmgr, laparams=LAParams())
interpreter = PDFPageInterpreter(rsrcmgr, device)
interpreter.process_page(page)
layout = device.get_result()
_, _, width, height = page.mediabox
parse_layout(layout)
output = pd.DataFrame(output, columns=["bbox_type", "coords", "token"])
output[["word_xMin", "word_yMin", "word_xMax", "word_yMax"]] = output["coords"].to_list()
Sample PDF

Output
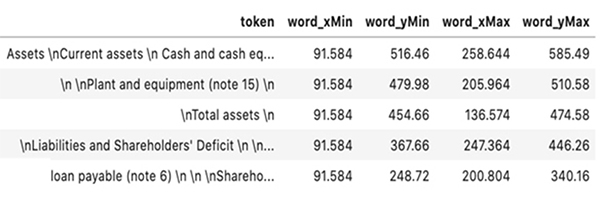
Description - PDFMiner Sample PDF and Output
An image of a sample PDF with a tabular structure consisting of a header, subheader, line items and date columns on the right. The output box showing the data extraction has a similar text and layout with the exact bounding box for each text token as a string, as well font and other layout information. The user must still build processes for structure to complete the table.
Package 4: Tabula-py
Tabula-py is a simple Python wrapper of tabula-java, which can read a table from PDF and convert it into a pandas' DataFrame. It also allows you to convert it into CSV/TSV/JSON file and use advanced features like lattice, which works well for lines separating cells in the table. There may be challenges in extracting and correctly detecting table contents for more complex PDFs.
Code Snippet
import tabula
import pandas as pd
output = tabula.read_pdf(pdf_path, lattice=False, pages=4)[0]
Sample PDF

Output
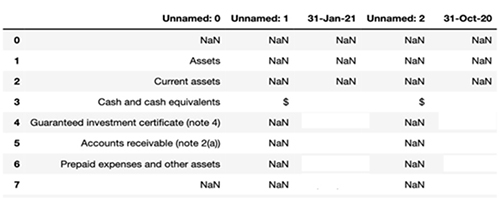
Description - Tabula-py Sample PDF and Output
An image of a sample PDF with a tabular structure consisting of a header, sub header, line items and date columns on the right. The output box showing the data extraction has a similar layout with the exact bounding box for each text token as a string, as well font and other layout information.
Package 5: Camelot
Just like Tabula-py, Camelot is also a Python library that can help you extract tables from PDF documents. This is the most effective and advanced package giving you control over the table extraction process. It also provides accuracy and whitespace metrics for quality control, as well as page segmentation methods to improve the extraction.
Code Snippet
import camelot
tables = camelot.read_pdf(good_pdf_path)
output = tables[0].df
Sample PDF

Output
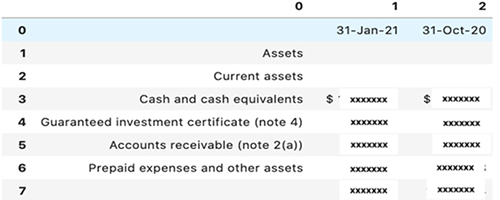
Description - Camelot Sample PDF and Output
An image of a sample PDF with a tabular structure consisting of a header, subheader, line items and date columns on the right. The output box showing the data extraction has a similar text layout with the exact bounding box.
Use of intelligent document processing in the SEDAR project
Statistics Canada is doing experimental work with the historical dataset from the SEDAR filing system, providing analysts at Statistics Canada with an alternative data source that allows them to gain valuable insights and provide information in a timelier manner. SEDAR is a system used by publicly-traded Canadian companies to file securities documents (such as financial statements, annual reports and annual information forms) to various Canadian securities commissions. Statistics Canada employees use the SEDAR database for research, data confrontation, validation, frame maintenance process, and more. However, data extraction from public securities documents is done manually and is time-consuming.
To increase efficiency, the team of data scientists developed an AI-enabled document intelligence pipeline that correctly identifies and extracts key financial variables from the correct tables in a PDF document. This resulted in the transformation of a large amount of unstructured public documents from SEDAR into structured datasets. This transformation allows the automation and extraction of economic information related to Canadian companies.
The first part of the automation process involves identifying required pages from the PDF document. This is done using methodology developed at Statistics Canada. A subsection of the document with high density of tables is first identified, this subsection of pages is then further processed to extract key features which are used by a trained machine learning classification model to identify correct pages. The second part of the automation process involves table extraction. The pages identified in the first step are provided as input to a table extraction algorithm called Spatial Layout based Information and Content Extraction (SLICE). This algorithm was developed in-house to extract all the information into a table in digital format. This data is displayed on an interactive web application and can be downloaded in CSV format.
This robust process automates the financial variable extraction process for up to 70,000 PDFs per year in near real-time. This significantly reduces the hours spent manually identifying and capturing the required information and reduces data redundancy.
Hoping to learn more about document intelligence?
Open-source tools work for simple PDF extraction processes but will not work well for complex, unstructured and varying sources of PDF documents. In upcoming articles, we will discuss the latest research in machine learning and artificial intelligence within the realm of document intelligence. We will also discuss SLICE in more detail. As mentioned, SLICE is a novel computer vision algorithm designed and developed by Statistics Canada. This algorithm has the ability to simultaneously use textual, visual and layout information to segment several data points into a tabular structure. This modular solution works with unstructured tables and performs financial variable extraction from a variety of PDF documents.
- Date modified: