
A Brief Survey of Privacy Preserving Technologies
By: Zachary Zanussi, Statistics Canada
As an organization, StatCan has always strived to adopt new technologies in a timely manner and innovate with methods. Big data technologies such as deep learning have increased the utility of data exponentially, and cloud computing has been an enabling vehicle for this, in particular when working with unclassified data. However, computations of unencrypted sensitive data in a cloud environment may provide exposure to confidentiality threats and cyber-security attacks. Statistics Canada has strict privacy policy measures that have been developed over decades of collecting data and releasing official statistics. To address the new requirements for operating in the cloud, we consider a class of new cryptographic techniques called Privacy Preserving Technologies (PPTs) that might help increase utility by taking greater advantage of technologies such as the cloud or machine learning while continuing to preserve the agency's security posture. This post provides a brief introduction to a number of these PPTs.
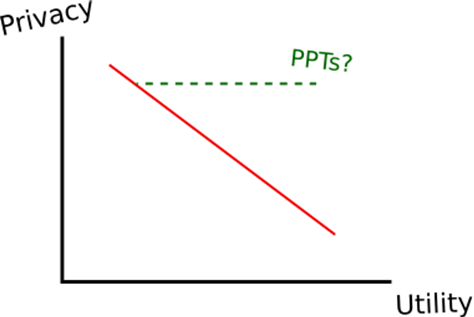
Description - Figure 1
Enhancing utility within the privacy vs. utility equation. The red solid line shows the privacy-utility balance with traditional methods, while the green dotted line shows what we hope to achieve with new privacy preserving technologies.What do we mean by privacy? Privacy is the right of individuals to control or influence what information related to them may be collected, used and stored and by whom, and to whom that information may be disclosed. As Canada's national statistical organization, most of the data used at Statistics Canada are provided by respondents, such as an individual or a business. The confidentiality of the data is safeguarded according to the five safe principles to protect the privacy of these respondents by ensuring that the data they provide can't be traced back to them directly or from statistical outputs. More information on Statistics Canada's approach to privacy can be found in the Statistics Canada Trust Centre.
A breach of information involves an attacker successfully reidentifying a response and attributing it back to a particular respondent; in the case that the respondent is a person, then it is also called a breach of privacy. In this article, we will mainly use the terminology of privacy, while keeping in mind that these technologies, applied correctly, protect the data of any kind of respondent.
The respondents' data are considered as the input to some statistical process that produces an output. If an attacker gains access to the input data, then it's a breach of input privacy, while if the attacker can reverse engineer private data from the output, then it's a breach of output privacy. It is possible to prevent both of these types of breaches using classical statistical methods such as anonymizing, where potentially attributing features of data are removed; or perturbation, where the data values are modified in some way to prevent accurate reidentification. The downside is that these classical methods necessarily sacrifice the utility of the data, in particular sensitive data. Moreover, there are numerous reidentification examples which prove that these traditional techniques do not necessarily provide desired cryptographic security guaranteesNote de bas de page 1, Note de bas de page 2. The goal is to leverage PPTs to maintain strong privacy attributes while preserving as much utility as possible. The end result is effectively enhancing utility in the privacy vs. utility equation.
Differential privacy to preserve output privacy
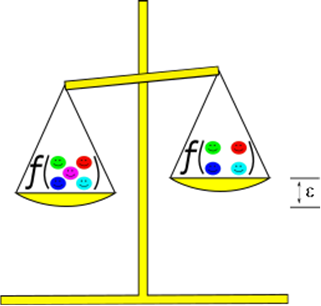
Description - Figure 2
In differential privacy, the outputs of an algorithm on very similar datasets should be within some agreed-upon value known as epsilon. Here, the addition of the central (magenta) respondent changes the output of ƒ by an amount that is bounded by ε.The output privacy of respondents is protected by carefully controlling the results of aggregate statistics. For example, it's possible for an adversary to reconstruct input data through the careful analysis of published statistics. Alternatively, if the public has query access to a secure database, where someone could request simple statistics (mean, max, min, etc.) on subsets of the database, an adversary could abuse this system to extract input data. Differential privacy reduces this risk through the addition of noise to input or output data. At first glance, this is simply an example of the data perturbation that has been employed in official statistics for decades. The innovation is the rigorous mathematical formulation of differential privacy, allowing to precisely gauge exactly where on the "Privacy—Utility" scale an algorithm resides using a parameter ε, called "epsilon."
An algorithm is called ε-differentially private if running the algorithm on two databases that differ by exactly one entry produces results that differ by less than ε. Informally, this means that an adversary querying the same statistic from differing subsets of a database can only infer an amount of information from the database that is bounded by ε. In practice, before releasing statistics, the level of privacy required is determined and used to set ε. Then, random noise is added to the data until the algorithms or statistics to be computed are ε-differentially private. Using differential privacy, better guarantees output privacy while maximizing utility.
Private computation as a means of protecting input privacy
Private computation is a blanket term covering a number of different frameworks for computing on data securely. For example, suppose you hold private data that you'd like to perform some sort of computation on, but you don't have access to a secure computing environment—you might be interested in homomorphic encryption. Or suppose you and several peers would like to perform a shared computation on your data without sharing it amongst yourselves—secure multiparty computation might be just what you are looking for. These two secure computing paradigms will be examined in more detail below.
With recent advances in cloud computing, individuals and organizations have unprecedented access to powerful and affordable cloud computing environments. However, most cloud providers do not guarantee the security of data while they are being processed, which means that the cloud is still out of reach to many organizations in possession of highly sensitive private data. Homomorphic encryption (HE) can change this. While traditional encryption algorithms require data to be decrypted before and after use (encryption-at-rest), in HE computations can be performed directly on encrypted data. The results of the computation can only be revealed after decryption. Thus, a data holder can encrypt their data and send them to the cloud knowing that it is cryptographically protected. The cloud can perform the desired computation homomorphically and return the encrypted result, which only the data holder can decrypt and view. In this way, the client can delegate its computations to the cloud without having to rely on trust that their data will be protected; it is secured by encryption! The downside of HE is increased computational complexity, which can be orders of magnitude larger than the corresponding unencrypted computation.
Suppose a number of hospitals have data about patients with a rare disease. If they pool their data, they could run some computations that would help them with treatment and prevention strategies. Laws in many countries require medical institutions to protect their patients' medical data. In the past, the only solution to this problem would be to have all the hospitals agree on a single trusted authority who would collect the data and run the computation. Today, the hospitals could implement (secure) multiparty computation (MPC). With MPC, the hospitals can collaborate and jointly perform their computations without sharing their input data with any party, dispensing the need for a trusted authority, in such a way that their input privacy is guaranteed even in the face of "dishonest" hospitals. MPC protocols are usually implemented using multiple rounds of "secret sharing," where each party holds a piece of a smaller computation that they use to perform their larger computation. The downside of MPC is increased computational complexity (although, usually not as much as HE) and the fact that the protocols usually entail multiple rounds of interactive communication.
Distributed learning
Neural networks and artificial intelligence may be the two technologies that have thrived the most in the era of big data. Rather than write a program to complete a task, data are fed into a machine and it trains a model to perform the task. This makes data collection the most important part of the process. As discussed above, this collection process can be prohibitive when the data are distributed and sensitive. Distributed learning is a class of MPC protocols that aim to train a model on data that is owned by multiple parties who want to keep their data private. Two protocols that implement this process in slightly different ways, known as Federated Learning and Split Learning will be discussed. The remainder of this section will assume a basic knowledge of how to train a neural network.
Both of these protocols begin with the same setup; multiple parties have access to data that they consider sensitive, and there is a central untrusted authority server who will assist them. The parties agree on a neural network architecture they would like to train, as well as other particulars such as hyperparameters. Here the two ideas diverge.
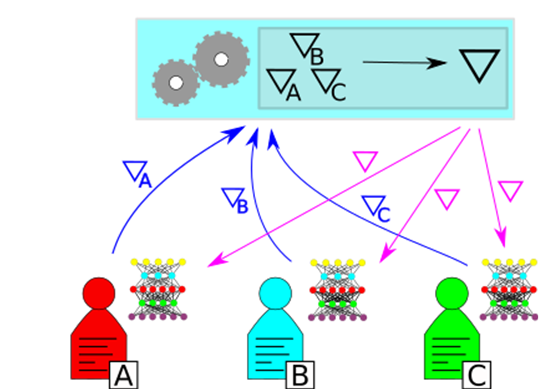
Description - Figure 3
In federated learning, each data holder computes gradients on their data and sends it up to a central authority who computes ∇ and distributes it down to each party. In this way, each party can obtain a neural network that has been trained on the union of their datasets, without sharing their data.In federated learning, each party holds an identical local copy of the network they are training. They each perform one epoch of training on their network and send their gradients to the authority. The authority coordinates these gradients and instructs each of the parties on how to update their local models by combining the insights gained by every party's data. The process then repeats for the desired number of epochs, where finally the authority and every party holds a trained version of the network that they can use however they see fit. The resulting networks are identical, and the process reveals no more about the data than the accumulated gradients computed by each party. This could potentially facilitate an avenue for attack that needs to be considered when implementing a federated learning scheme.
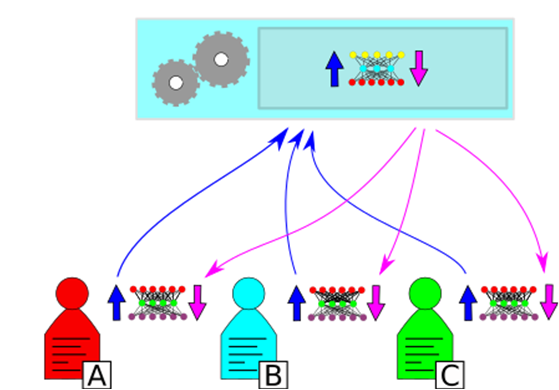
Description - Figure 4
In split learning, the desired network is "split" between the parties and the server. Forward propagation is shown going up in dark blue, and backward propagation goes down in magenta. Each party performs forward propagation up to the split and sends the result to the server, who propagates forward and back again, sending the gradients back to their respective parties who can then update their networks.In split learning, the neural net is split by the authority at a certain layer, and layers after the split are shared with the parties. Each party propagates their data up to the cut, then sends the activations at the cut layer to the server. The server finishes the forward propagation on the rest of the network, performs backward propagation up to the cut, then sends the gradients to the parties who can then each finish back propagation and update their copy of the network. After the desired number of epochs, the authority distributes its half of the network to each of the parties, and then each party has their own copy of the total network, the bottom half of each being explicitly tailored to their data. The only data leaked are those which can be inferred from the activations and gradients exchanged at each epoch. The layers below the split serve to alter the data enough that they are protected (sometimes called "smashing" the data), while still allowing the server to gather insights from it.
This article discussed a number of emerging privacy preserving technologies and how they can improve the utility extracted from data without sacrificing the privacy of those providing it. Future posts will take a more in-depth look at some of these technologies, so stay tuned! Next up is a much closer look at homomorphic encryption, from the mathematics of lattices to applications.
Want to keep in the loop about these emerging technologies, or want to share your work in the field of privacy? Check out our Privacy Preserving Technologies Community of Practice GCConnex page to discuss these DSN privacy posts, connect with peers interested in privacy, and share resources and ideas with the community. You can also give feedback on this post or leave suggestions for future posts in this series.
- Date modified: