
Unlocking the power of data synthesis with the starter guide on synthetic data for official statistics
By: Kenza Sallier and Kate Burnett-Isaacs, Statistics Canada
Introduction
In recent years, particularly in response to the data revolution, national statistical organizations (NSOs) have prioritized data access, transparency and openness in their modernization initiatives. The challenge is to find safe and sustainable ways to provide faster and easier access to timely and integrated data compiled from ever-growing sources of increased complexity, along with protecting commitment to confidentiality. Data synthesis is one option that give users' easier access to analytically rich data while making sure that integrity and confidentiality imperatives are respected. Theory on the generation of analytically rich synthetic data is not new; its roots are in imputation methods. However, in terms of implementation, production of synthetic data files, especially from complex data sources, is still a new avenue for most NSOs. With an increasing number of new methods and tools related to the generation and evaluation of synthetic datasets, standardized guidance on utility and risk is needed. More specifically, for synthetic data to become a viable microdata access solution, NSOs need a full picture of existing methods, tools and direction on how to measure their analytical power and potential disclosure risks.
In response to this, the Synthetic Data for Official Statistics - A Starter Guide was published in 2023 by the High-Level Group on the Modernization of Official Statistics (HLG-MOS), a network under the United Nations Economic Commission of Europe (UNECE). This guide provides a place to start for statistical organizations to learn, think and understand about the generations and uses of synthetic data to share data openly while keeping data integrity and confidentiality at the forefront. It also helps readers determine if synthetic data is the right solution to their problem, help them on the right path for synthesis and provides evaluation methods to solve data disclosure problems.
This article will highlight the gaps that synthetic data files can fill, showcase deep learning methods to generate synthetic data and discuss the importance of clear standards when creating and using synthetic data as provided by the HLG-MOS starter guide.
What is synthetic data?
The HLG-MOS starter guide defines synthetic data as being stochastically generated data that has analytical value and maintains high levels of disclosure control. The concept of synthetic data originally started in the field of data editing and imputation, but the field of synthetic data has evolved with developments in computing and data science methods. To generate synthetic data, a modelling process that targets both the preservation of analytical value and confidentiality is used. Confidentiality refers to the unwarranted disclosure of personal data entrusted to a NSO that may occur when statistical information is released.
Generally speaking, the goal of data synthesis is the following general idea. Assume there's a dataset, , on which users, or researchers would like to perform a set of statistical analyses that would result in a set of statistical conclusions , but, for confidentiality reasons, you cannot provide access to D to users. The synthesizer can then use a data synthesis process to generate a synthetic version of , that we will call . The intent behind data synthesis is to generate in such a way that , set of the statistical conclusions of the same analyses now performed on , is as close as possible to .
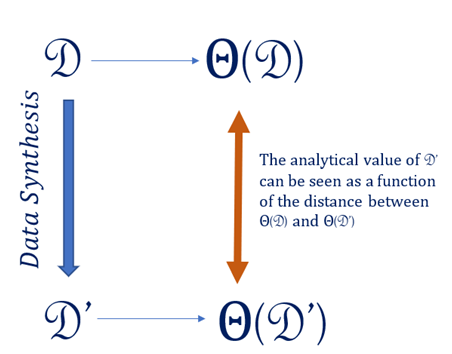
Figure 1: Illustration of synthetic data generation. Source: Sallier (2020).
Data synthesis architecture. The analyses using the synthetic dataset would provide similar statistical conclusions as the original dataset.
Text: The analytical value of can be seen as a function of the distance between and .
To discuss synthetic data, we must first define and understand utility and disclosure risks. Utility, in the context of synthetic data is the analytical value or usefulness of the synthetic dataset to the user. Generally speaking, the analytical value is related to how closely the results from the synthetic dataset are to those generated by the original data. Therefore, the analytical value of can be seen as a function of the distance between and .
While data synthesis aims to increase the analytical value, it also aims to decrease as much disclosure risk as possible. Disclosure risk can be defined as the risk of inappropriate release of data or attribute information (OECD, 2003), and applies to the dissemination of any aggregate statistic or micro dataset, including synthetic data.
Recommended uses for synthetic data
Synthetic data is a useful tool for certain problems or use cases faced by NSOs. With each problem, comes a necessary balance between utility and disclosure risk. The HLG-MOS starter guide outlines four categories of use cases:
- Releasing to the public
- Testing analysis
- Education; and
- Testing software.
Releasing to the public: This use case usually stems from the desire to provide valuable data to stakeholders. The main challenge with this use case is that the NSO doesn't know and doesn't have any control on how the data will be used (and therefore doesn't know analyses will be performed) and who will be using or sharing it (which entails a high disclosure risk).
Testing analysis: Testing analytical value is currently the most common use case for NSOs. Many NSOs will provide confidential microdata to trusted parties such as researchers or partnering departments, but this is governed by strict data access agreements as well as background and security checks. Security checks and procedures involved with this transaction can be time-consuming and burdensome. Synthetic data can be a more efficient option to get valuable data into the hands of trusted stakeholders. In this use case, NSOs may know what analysis will be done with the synthetic data and can customize the generation method to the analysis, thereby increasing utility. This use case is often most useful to data scientists looking for faster access to training data for their machine learning models.
Education: A third use case in the context of NSOs, is to provide high-quality data for students, academics, and users in general. Particularly, training in complex methods such as machine learning requires data that will yield realistic results. The balance between utility and disclosure risk in this use case is that NSOs may be aware of the specific topic being studied and so can preserve the specific distributions in question. However, synthetic data could be reused for different educational purposes, therefore in the end, the NSO may not be able to identify all uses of the data, nor all users.
Testing software: Dummy data is often used to test new software and technology. However, with the advent of more complex technologies, NSOs and stakeholders are looking for more realistic data so systems can be assessed and verified properly.
| Use Case | Key Considerations | Confidentiality/Utility Balance |
|---|---|---|
| Releasing microdata to the public | The synthesizer doesn’t know who or how the data will be used. | High confidentiality and high utility are required. |
| Testing analysis | Specific analysis or variables distributions that must be maintained may be known at time of synthesis. | High confidentiality and high utility are required. |
| Education | Synthesizers may know the analysis to be conducted and users may have security clearance or agreement with the NSO, however the opposite may also be true. | High utility with possible varying levels of confidentiality. |
| Testing technology | The value of synthetic data is dependent on how complex the system is and how sophisticated the test data needs to be. Many methods to generate synthetic data may be too computationally heavy to make the effort worthwhile. | Medium utility and medium confidentiality. |
Methods for generating synthetic data
There are an increasing number of methods that generate synthetic data, and the method you choose depends on your use case. When creating synthetic data, you need to consider the target analytical value as well as the disclosure risk for your use case.
The HLG-MOS starter guide presents the common methods used in NSOs today. These methods fall into three categories:
- Sequential modelling
- Simulated data; and
- Deep learning methods.
All methods are presented in the HLG-MOS starter guide but for this article, we'll mainly expand on the recent deep learning methods to generate synthetic data. Deep learning methods have become more popular in the field of synthetic data because synthesizers are increasingly dealing with large and unstructured datasets. At this time, the only deep learning method that is used by NSOs to generate synthetic data are the generative adversarial networks.
To learn more about all three categories of synthesis methods, their pros and cons and their suitability for each of the four use cases of synthetic data for official statistics, read Chapter 3 in the Synthetic Data for Official Statistics: A Starter Guide.
Generative adversarial networks to generate synthetic data
Generative adversarial network (GAN) (Goodfellow et al., 2014) is a prominent generative model used to produce synthetic data. The model tries to learn the underlying structure of the original data by generating new data (more specifically, new samples) from the same statistical distribution as the original data, with two neural networks, competing with each other in a game. Given that the theory and implementation of processes related to deep learning and neural networks can be technically challenging, we will mainly explain the overall concepts, as more information can be found in the references. Because the GAN relies on neural networks, that means that the approach can be used to generate discrete, continuous or text synthetic data.
In a GAN, there are two competing neural network models:
- the generator takes noise or random values as input and generates samples.
- the discriminator receives samples from both the generator and the training data and attempts to distinguish between the two sources.
The discriminator is similar to a binary classifier, as it takes both real (or original) data as input, as well as generated (or synthetic) data and would compute a pseudo-probability value that would be compared to a fixed threshold value in order to classify the input from the generator as either generated or real.
As shown in Figure 2, the training process is an iterative one, during which the two networks play an ongoing game where the generator is learning to produce more realistic samples, while the discriminator is learning to get better at distinguishing generated data from real data. This interaction between the two networks is required for the success of GAN as they both learn at the expense of each other, eventually attaining a balance.
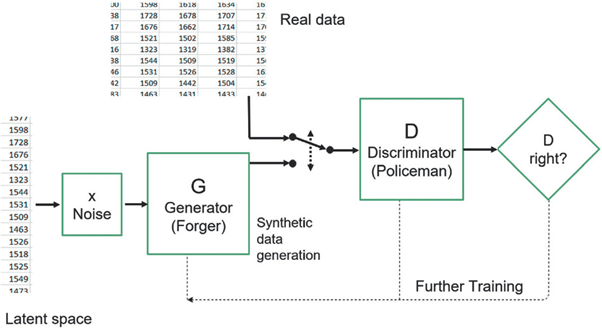
Figure 2: Illustration of training of a GAN in the context of data synthesis. Source: Kaloskampis et al. (2020).
The model is made of two networks: the generator is learning to produce more realistic samples and the discriminator is learning to get better at classifying the generated data as ‘real' of ‘synthetic'. This is an iterative process where both learn at the expense of each other, until a balance is reached.
All synthetic data methods have their benefits and considerations. Table 2 outlines the pros, cons and considerations of using GANs to generate synthetic data.
| Pros | Cons |
|---|---|
|
GANs have been used in NSOs to generate continuous, discrete and textual datasets, while ensuring that the underlying distribution and patterns of the original data are preserved.
|
GANs can be seen as too complex to understand, explain or implement where there is only a minimal knowledge of neural networks. There is often a criticism associated with neural networks as lacking in transparency. The method is time consuming and has a high demand for computational resources. GANs may suffer from mode collapse, and lack of diversity, although newer variations of the algorithm seem to remedy these issues. Modelling discrete data can be difficult for GAN models. |
Other deep learning methods
There are other deep learning synthetic data generation methods gaining traction in the research and development communities that some NSOs could benefit from.
Autoencoders, for example, are feed-forward deep neural networks, used to compress and then decompress the original data. This is somewhat comparable to saving an image file at a lower resolution and then trying to reconstruct the higher resolution image from the lower resolution version.
The first part of the process is performed by a neural network of its own, called the encoder, which restricts the amount of information that travels through the network using a convolution. Autoencoders use a second deep learning network, called the decoder, which tries to reverse the effect of the encoder by attempting to reconstruct the original input, with the reconstruction being synthetic data (Kaloskampis et al., 2020). Figure 3 illustrates the architecture of an autoencoder.
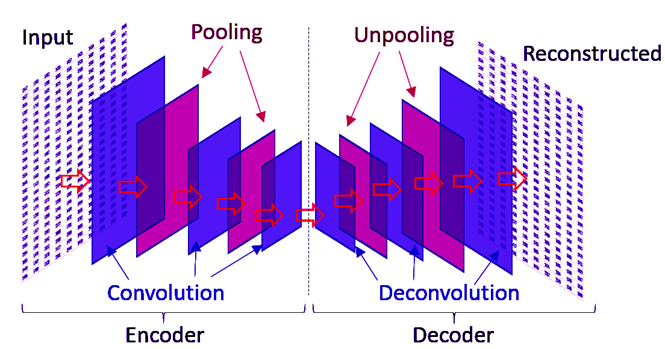
Figure 3: Illustration of autoencoder architecture. Source: Kaloskampis et al. (2020).
Autoencoders use forward deep neural networks to compress (via convolutional layers and pooling layers) and then decompress (via deconvulation layers and unpooling layers) the original data. This is somewhat comparable to saving an image file at a lower resolution and then trying to reconstruct the higher resolution image from the lower resolution version.
Autoregressive models are being explored to improve on some of the shortcomings of GANs models (Leduc and Grislain, 2021). Autoregressive models use a variant of a regression formula, that allows for the prediction of the next point of a sequence, based on previous observations of that sequence.
Other methods of note are Synthetic Minority Oversampling Technique (SMOTE) methods, which create synthetic data instances based on existing instances from the original data (Chawla et al., 2002). Many of these deep learning methods are being used to create differentially private synthetic data. To learn more about differential privacy, and differentially private synthetic data, refer to Chapter 4 of the Synthetic Data for Official Statistics: A Starter Guide.
With improvements in technology and computational capacity, implementation of machine learning processes has become easier and more accessible. Thus, it is natural that machine learning approaches have increasingly been used to generate synthetic datasets. More specifically, the use of deep learning models has become appealing because of their capacity to develop powerful predictive models based on large datasets.
The balance between disclosure risk and utility
Disclosure risk considerations: The Organization of Economic Cooperation and Development (OECD, 2003) defines disclosure as the inappropriate release of data or attribute information of an individual or an organization. When we talk about disclosure risk, we refer to the possibility of disclosure occurring. Disclosure risk applies to any data released – aggregate, microdata or synthetic data.
There are two main types of disclosure – identity disclosure and attribute disclosure. Identity disclosure occurs when a record in the released data is recognized as matching to an individual for whom the attacker (someone who deliberately seeks to disclose or breach confidentiality rules) knows values of the released data from another source. Attribute disclosure is a scenario where an attacker observes an individual in the data that appears to be a unique match to a known individual. An attacker may use the released information in data to obtain more information for the individual.
Although no record in a fully synthetic data file corresponds to a real person or household, in the sense that all values were generated, there is a concern that attribute, and identification disclosure risk could still be present as well as perceived disclosure risk. These situations could impact the reputation for the data holders and put respondents' willingness to participate in surveys or census, at risk. Therefore, NSOs may still decide to add disclosure control layers by using more traditional statistical disclosure control measures on top of the data synthesis's generation process.
In the end, it is important to realize that NSOs should choose whether to implement additional disclosure control methods on their synthetic data, as well as any specific privacy preserving techniques, based on their own legislative and operational frameworks. Chapter 4 of the HLG-MOS starter guide presents common privacy preserving techniques and other statistical disclosure control measures, including differential privacy.
Utility: The utility, or analytical value, of a synthetic dataset reflects how useful that dataset is to the purpose or the use case. Most often, the utility of synthetic data is based on how similar the conclusions are between the synthetic data and the original confidential data.
The HLG-MOS starter guide presents two broad categories of utility measures. They are "general" and "specific" measures. Specific measures are useful when evaluating a specified analysis. General utility measures are used in two main scenarios:
- To compare different synthesis methods for the same dataset in order to generate the most useful synthetic dataset for the user.
- To diagnose where the original and synthetic data distributions differ and thus tune the synthesis methods to improve the utility of the synthetic data.
Chapter 5 will guide you through which utility measure is right for your purpose and help you evaluate the results. When evaluating synthetic data based on utility, start simple. Methods such as comparing distributions or whether your synthetic data can carry out a targeted task can determine a primary utility baseline. Then, ask yourself why you want to measure utility. Is it to compare synthesis methods and select the best one or is it to improve your synthesis process, often referred to as tuning? Is it to assess the quality of your synthetic file in terms of its analytical value? After you have determined why you want to measure utility, it is important to keep your end-user and the requirements of your final synthetic data file in mind.
Balance between disclosure risk and utility
When evaluating the quality of your synthetic data, we evaluate the results in terms of the trade-off between disclosure risk and utility. This is often presented graphically as shown in Figure 4.
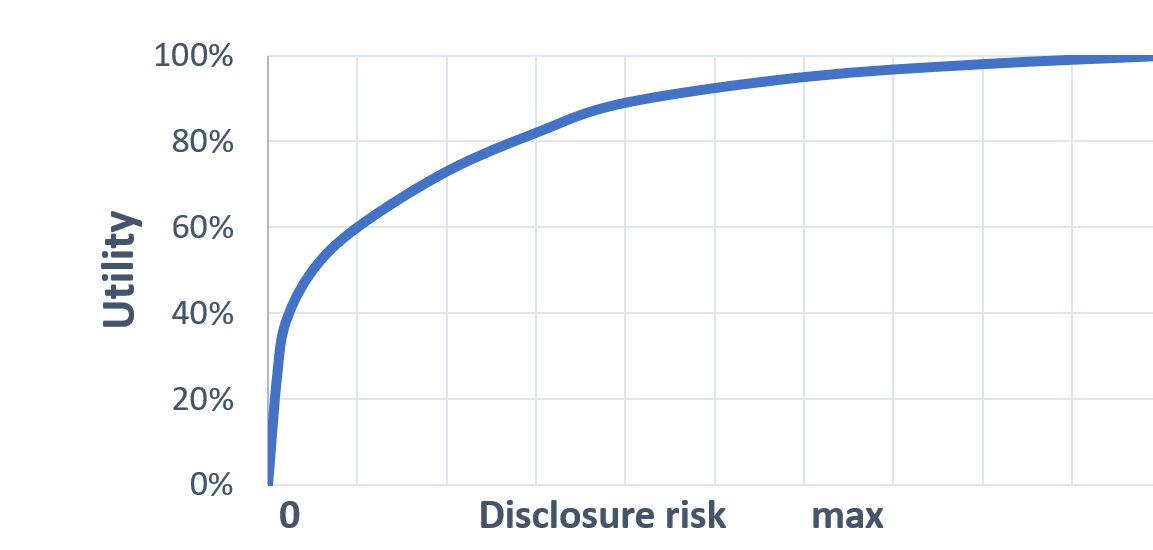
Figure 4: The trade-off between utility and disclosure risk.
The graph describes the link between the disclosure risk and the utility. The disclosure risk associated to the dataset in on the x-axis and the utility is on the y-axis. The curve is concave down, increasing, connecting the lower left corner to the upper right corner. It means that no datasets can score very high on utility and low on disclosure risk at the same time.
Remember, in the context of synthetic data, utility is a measure of the closeness of results from the synthetic data compared to the original data. Data where all the records had identical values might have a utility of zero, and a disclosure risk of zero, while the original data will have a utility of 100 percent. Disclosure risk for synthetic data is at a maximum when the original data are unaltered. The ideal position on this graph is at the top left corner, with perfect utility and no disclosure risk. However, this state is never attainable because altering the data to protect against disclosure risk will always change data values. Most importantly, when generating and evaluating synthetic data, always consider both utility and disclosure risk.
Conclusion
The Synthetic Data for Official Statistics: A Starter Guide is a result of an international collaboration of synthetic data experts that provides recommendations on when and how to use, generate and validate synthetic data in the context of official statistics. This guide provides recommendations and insights on how synthetic data can expand the reach and value of data holdings of NSOs.
Though synthetic data cannot solve all disclosure problems faced by statistical organizations, it can provide the solution to expanding data use amongst the general public, academia, stakeholders and even our own employees. With the advent of deep learning methods, NSOs now have the tools to create synthetic data of large and unstructured datasets. Regardless of how you generate your synthetic data, the utility of the outputs and the disclosure risks must be balanced. Read the Synthetic Data for Official Statistics: A Starter Guide to help guide your synthetic data project.
Meet the Data Scientist

If you have any questions about my article or would like to discuss this further, I invite you to Meet the Data Scientist, an event where authors meet the readers, present their topic and discuss their findings.
Thursday, March 16
2:00 to 3:30 p.m. ET
MS Teams – link will be provided to the registrants by email
Register for the Data Science Network's Meet the Data Scientist Presentation. We hope to see you there!
Subscribe to the Data Science Network for the Federal Public Service newsletter to keep up with the latest data science news.
References
Chawla, N. V., Bowyer, K. W., Hall, L. O. and Kegelmeyer, W. P. (2002). SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research, 16, 321–357.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A. and Bengio, Y. (2014). Generative Adversarial Networks. Advances in Neural Information Processing Systems. 3. 10.1145/3422622.
Kaloskampis, I., Joshi, C., Cheung, C., Pugh, D. and Nolan, L. (2020). Synthetic data in the civil service. Significance, 17: 18-23.
Leduc, J. and Grislain, N. (2021). Composable Generative Models. arXiv: 2102.09249v1.
OECD (2003). The OECD Glossary of Statistical Terms. Retrieved August 21, 2022.
Sallier, K. (2020). Toward More User-centric Data Access Solutions: Producing Synthetic Data of High Analytical Value by Data Synthesis. Statistical Journal of the IAOS, vol. 36, no. 4, pp. 1059-1066.
- Date modified: