Frequently asked questions—Provisional estimates and excess mortality in Canada
The Canadian Vital Statistics Death (CVSD) database is the authoritative source for cause of death data in Canada. Statistics Canada collaborates with partners at the federal, provincial and territorial levels to provide Canadians with timely data insights on deaths and mortality in Canada. To respond to emergent data needs in the wake of the COVID-19 pandemic, Statistics Canada has begun providing new, provisional estimates on excess deaths and mortality.
To learn more about our data sources, methods and other important information, please explore the answers to some frequently asked questions below.
Data Sources
1.1 How are vital statistics collected?
Canada's national vital statistics system is a complex and decentralized system, based on collaboration between provincial/territorial vital statistics registrars and Statistics Canada.
The Vital Statistics Registry in each province and territory registers all deaths occurring in their province and transmits the information to Statistics Canada. The form for the registration of a death consists of personal information, supplied to the funeral director by an informant (next of kin), and the medical certificate of cause of death, completed by the medical practitioner last in attendance, or by a coroner/ medical examiner.
Provincial and territorial vital statistics agencies share the information they collected through their death registration processes with Statistics Canada, where it is compiled in the Canadian Vital Statistics Deaths (CVSD) database.
The Canadian Vital Statistics system operates under an agreement between the Government of Canada and governments of the provinces and territories. The Vital Statistics Council for Canada is an advisory committee composed of representatives from the provincial and territorial vital statistics offices and Statistics Canada, that oversees the policy and operational matters associated with the collection of vital statistics information.
More information on the data sources for the Canadian Vital Statistics – Death Database is available on the Statistics Canada website.
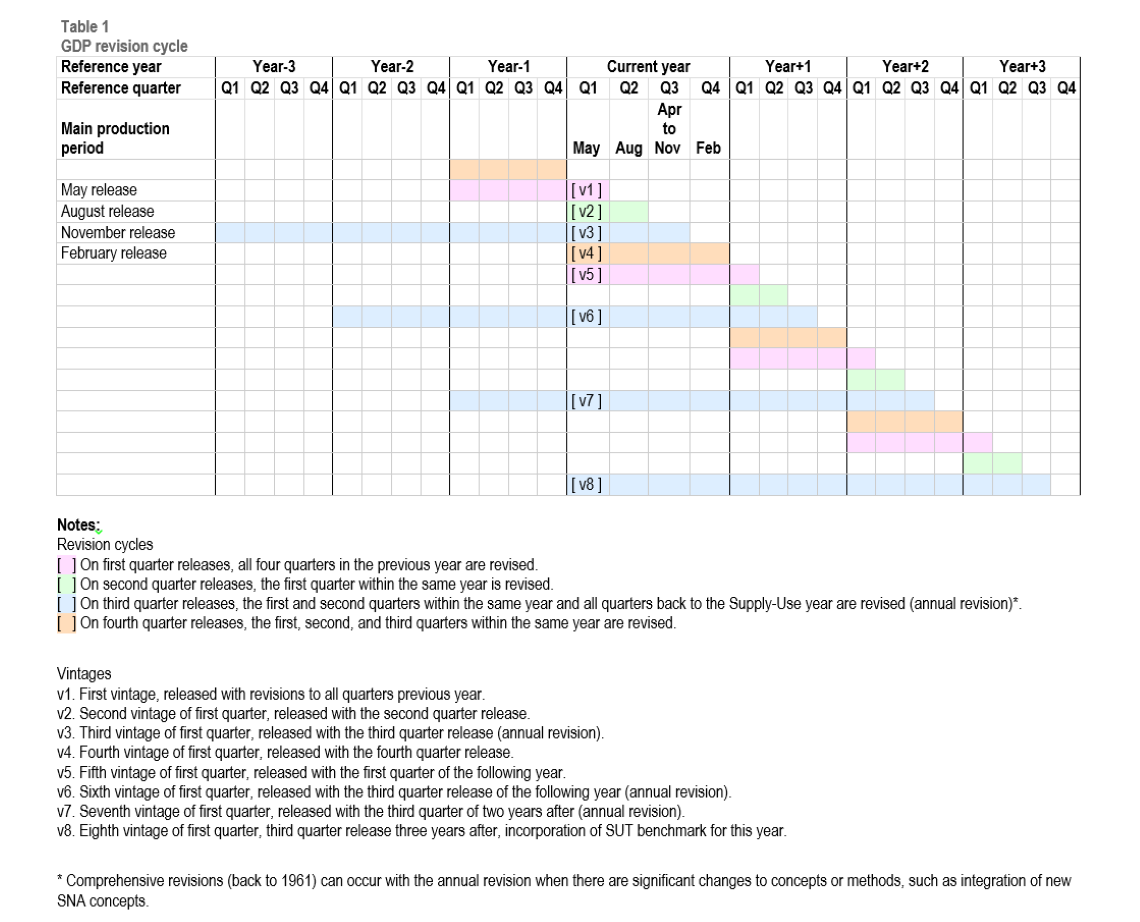
1.2 What does it mean that the Canadian Vital Statistics Deaths (CVSD) data are "provisional"?
Statistics Canada's ability to provide timely information depends on receiving information from the provinces and territories.
The Provincial or Territorial Vital Statistics office submits data to Statistics Canada in 2 steps: the fact of death and the images of the death certificate, which are used to code the causes of death. Typically, the death event (fact of death) will be registered in the system first. For several jurisdictions, this death information is typically sent within 30 days of the death event, while for others it is sent 30 to 60 days, or more, following the death event. There may be a further delay in Statistics Canada's receipt of cause of death information – particularly with unnatural deaths that warrant medical investigation or autopsy.
Provisional death counts and causes of death do not include all deaths occurring in the reference period due to reporting delays. Provisional death estimates are adjusted to account for the incomplete nature of the counts, where possible. These adjustments add to the counts to incorporate deaths not yet reported to Statistics Canada, based on past and current provincial and territorial reporting patterns. The provisional estimates are revised in future releases as more information is reported.
More information on the data sources and methodology for the Canadian Vital Statistics – Death Database is available on the Statistics Canada website.
1.3 What information is contained within the provisional Canadian Vital Statistics Deaths (CVSD) database released each month?
The provisional deaths database contains the following information for each death occurring in Canada:
- Age, sex, marital status, place of residence and birthplace of the deceased
- Date of death
- Underlying cause of death classified to the "World Health Organization International Statistical Classification of Disease and Related Health Problems" (ICD)
- Province or territory of occurrence of death
- Province or territory of residence of the deceased.
There are two interactive tools and four data tables that present the most recently-release provisional data from the Canadian Vital Statistics – Death Database.
2. Timelines
2.1 When are the provisional Canadian Vital Statistics Deaths data released?
In order to better understand the impacts of the pandemic on Canadian families and communities, Statistics Canada has adopted, and continues to adopt, new ways to meet the need for more timely information. As a result, the provisional Canadian Vital Statistics Deaths database is released on a monthly basis for reporting provinces and territories.
Please consult Statistics Canada's The Daily release schedule for scheduled dates of release.
2.2 Why are estimates missing for certain weeks?
The quality of the weekly adjusted counts is largely contingent on the level of completeness of the data, that is, the extent to which all deaths have been reported to Statistics Canada. Missing estimates are more likely for the weeks most recent to the release date, as there is sometimes a lag in reporting. As the information is submitted to Statistics Canada, the data become more complete for subsequent releases.
Only estimates for weeks where the level of completeness reaches 75% or more are shown. This threshold offers a compromise between the robustness and the timeliness of estimates. The level of completeness reaches 90% or more for almost all weeks, with a few exceptions. Although useful to signal potential new recent trends in regard to excess mortality, estimates based on weekly data with a lower level of completeness should be used with caution as they carry more uncertainty and are more sensitive to model assumptions (such as the choice of the reference period). Consequently, these estimates are subject to change noticeably in subsequent releases as the number of reported deaths increase for these weeks.
2.3 Why do the numbers in the most recent release not match the numbers from previous releases?
Statistics Canada receives information from the provinces and territories on a continuous basis. The provisional data and estimates are updated on a monthly basis with the addition of new weeks of data and revisions to those weeks for which data have previously been released.
3. Methodology
3.1 Why are death counts adjusted?
In order to provide more up-to-date information on deaths during the pandemic, recent improvements in methodology and timeliness have been made to our data collection process. As a result, the provisional death counts for the 2020 and 2021 reference years have been adjusted to account for reporting delays, where possible, that would otherwise result in under-coverage within the data. These adjustments add to the counts to incorporate deaths not yet reported to Statistics Canada, based on past provincial and territorial reporting patterns.
During the production of each month's death statistics, data from previous months/years may be revised to reflect any updates or changes that have been received from the provincial and territorial vital statistics offices.
Data from the 2017, 2018, and 2019 reference years are also preliminary, as updates from the vital statistics offices are also recorded.
More information on the data sources and methodology for the Canadian Vital Statistics – Death Database is available on the Statistics Canada website.
3.2 Why are data missing for certain jurisdictions?
Statistics Canada's capacity to provide useful and timely information is dependent on its ability to receive the information from the provinces and territories. For several jurisdictions this information is typically sent within 30 days of the death event, while for others it is sent 30 to 60 or more days following the death event. For this reason, data for certain provinces and territories for certain weeks are suppressed.
3.3 Why do the provisional death counts and estimates that are released by Statistics Canada not match figures from other sources?
The data that are released each month by Statistics Canada are based on the data that are reported by the provincial and territorial vital statistics registries, which are the official source for death statistics in Canada. Statistics Canada adjusts the counts to account for reporting delays. Cause of death information within the Canadian Vital Statistics Deaths (CVSD) database is obtained from the medical certificate of cause of death, which is completed by medical professionals, coroners, or medical examiners.
Data produced by other sources may be collected for surveillance purposes from other organizations, such as the provincial and territorial health authorities or media outlets. These data may be based on confirmed cases of the virus causing COVID-19 only, which means that the data may not always include cases where someone died of COVID-19 before getting tested. In addition, surveillance figures may be based on the date that the death was reported, rather than the date that the death occurred. Lastly, these figures may use cause of death definitions that differ from those applied by the Vital Statistics agencies and registrars using guidelines from the International Classification of Diseases.
From January to August 2020, the official death counts from COVID-19 across Canada were about 5% higher than the surveillance figures for the same period.
3.4 Why are some provisional causes of death listed as unknown?
The more recent reference periods contain a higher number of provisional causes of death that are unknown or pending investigation. Some deaths, such as possible suicides, or accidental deaths require lengthy investigations. What this means is that Statistics Canada has yet to receive definitive cause of death information from the provincial and territorial vital statistics agencies, due to outstanding medical investigations into the decedents' cause of death.
When the number of unknowns is high in these data, the provisional cause of death data should not be used to report on the leading causes of death until the data become more complete.
3.5 Why are some numbers in the provisional data rounded and others are not?
Depending upon the analyses conducted, the cause of death information may contain small counts, which makes it necessary to protect confidentiality through a standard rounding process for the cause of death variable. Only the cause of death information is rounded; rounding is conducted to the base 5. This means that all cause of death information is presented in units of 5 or 10 (e.g., 0, 5, 10, 15, etc.).
Due to the provisional nature of the data, the frequency of provincial and territorial updates of the data, as well as the cause of death rounding practice, more variability may be observed among the cause of death variable – compared to the rest of variables in the database – between monthly releases.
4. Analysis
4.1 What is excess mortality and why are we measuring it?
COVID-19 continues to affect communities and families in Canada and across the world. Beyond deaths attributed to the disease itself, the pandemic could also have indirect consequences that increase or decrease the number of deaths as a result of various factors, including delayed medical procedures or increased substance use.
To understand both the direct and indirect consequences of the pandemic, it is important to measure excess mortality.
Excess mortality occurs when there are more deaths during a period of time than what would be expected for that period. It should be noted that, even without a pandemic, there is always some year-to-year variation in the number of people who die in a given week. This means that the number of expected deaths should fall within a certain range of values. There is evidence of excess mortality when weekly deaths are consistently higher than the number expected, but especially when they exceed the range of what would be expected over consecutive weeks.
Measuring excess mortality requires some way to determine the number of deaths that would be expected if there wasn't a pandemic. There are a number of ways to estimate expected deaths, including comparisons with previous yearly counts or using historical averages—for example, over the previous four years. In the Canadian context, with an aging and growing population, the number of deaths has been steadily increasing over recent years, and so a higher number of deaths would be expected in 2020 (or 2021) regardless of COVID-19. For these reasons, Statistics Canada is using an approach that has also been adopted by other countries to estimate expected deaths, using a statistical model to project forward recent trends in mortality.
More information on estimating excess mortality during the COVID-19 pandemic in Canada is available in the article Excess mortality in Canada during the COVID-19 pandemic.
5. More on mortality
5.1 Where can Canadians find more information on mortality statistics in Canada for 2020?
- The Provisional weekly estimates of the number of deaths, expected number of deaths and excess mortality: Interactive Tool is updated on a monthly basis. This interactive tool helps to identify trends in excess deaths by province and territory.
- The Provisional weekly death counts: Interactive tool is also updated on a monthly basis. This interactive tool helps to identify trends in the number of weekly deaths by age group and sex, and by province and territory. Based on provisional Canadian Vital Statistics Deaths (CVSD) data and subject to change as updates to the data are released.
- Table 13-10-0768-01: Weekly death counts, by age group and sex. This customizable table contains provisional Canadian Vital Statistics Deaths (CVSD) data, updated monthly, to provide national and provincial/territorial counts on the number of deaths, by week and year. Variables include sex and age group at time of death, as well as the province/territory of occurrence, by week and year. To change aspects of the table, click on the add/remove button and click on the different tabs to select the desired variables.
- Table 13-10-0810-01: Selected grouped causes of death, by week. This customizable table contains provisional Canadian Vital Statistics Deaths (CVSD) data, updated monthly, to provide national and provincial/territorial counts on the number of deaths by week and year. The selected causes of death are based on the World Health Organization's "International Statistical Classification of Disease and Related Health Problems" (ICD), version 10. While the Total, all causes of death figures in this table reflects the number of estimated deaths, the individual cause of death categories are not adjusted. Therefore, the number of deaths by cause category may not account for all deaths over the reference period. The unknown cause category reflects deaths where either the cause has yet to be determined or the death has not yet been registered. To change aspects of the table, click the add/remove button and click on the different tabs to select the desired variables.
- Table 13-10-0784-01: Adjusted number of deaths, expected number of deaths and estimates of excess mortality, by week. This customizable table contains provisional Canadian Vital Statistics Deaths (CVSD) data, updated monthly, about national and provincial/territorial excess mortality statistics. To change aspects of the table, click the add/removed button and click the different tabs to select the difference variables.
- Table 13-10-0792-01: Adjusted number of deaths, expected number of deaths and estimates of excess mortality, by week, age group and sex. This customizable table is updated on a monthly basis as new provisional Canadian Vital Statistics Deaths (CVSD) data are released. Variables include sex and age group at time of death, as well as measures used to examine national and provincial/territorial excess mortality. To change aspects of the table, click the add/remove button and click on the different tabs to select the desired variables.
- More information on estimating excess mortality during the COVID-19 pandemic in Canada is available in the article Excess mortality in Canada during the COVID-19 pandemic.
- More information on the certification and classification of COVID-19 deaths can be found in the study COVID-19 death comorbidities in Canada.
- More information on the methods used can be found in the Definitions, data sources and methods for Canadian Vital Statistics - Death Database.