
Version Control with Git for Analytics Professionals
By: Collin Brown, Statistics Canada
Analytics and data science workflows are becoming more complex than ever before—there are more data to analyze; computing resources continue to become cheaper; and there has been a surge in the availability of open source software.

For these reasons and more, there has been a significant uptake in programming by analytics professionals who do not have a classical computer science background. These advances have allowed analytics professionals to expand the scope of their work, perform new tasks and leverage these tools to deliver more value.
However, this rapid adoption of programming by analytics professionals introduces new complexities and exasperates old ones. In classical computer science workflows, such as software development, many tools and techniques have been rigorously developed over decades to accommodate this complexity.
As more analytics professionals integrate programming and open source software into their work, they may benefit significantly from also adopting some of the best practices from computer science that allow for the management of complex analytics and workflows.
When should analytics professionals leverage tools and techniques to manage complexity? Consider the problem of source code version control. In particular, how can multiple analytics professionals work on the same code base without conflicting with each other and how can they quickly revert back to previous versions of the code?
Leveraging Git for version control
Even if you are not familiar with the details of Git, the following scenario will demonstrate the benefits of such a tool.
Imagine there is a small team of analytics professionals making use of Git (a powerful tool typically used in software engineering) and GCCode (a Government of Canada internal instance of GitLab).
The three analytics professionals—Jane, John and Janice—create a monthly report that involves producing descriptive statistics and estimating some model parameters. The code they use to implement this analysis is written in Python, and the datasets they perform their analysis on are posted to a shared file system location that they all have access to. They must produce the report on the same day that the new dataset is received and, afterwards, send it to their senior management for review.
The team uses GCCode to centrally manage their source code and documentation written in gitlab flavoured markdown. They use a paired down version of a successful git branching model to ensure there are no conflicts when they each push code to the repository. The team uses a peer review approach to pull requests (PRs), meaning that someone other than the person who submitted the PR must review and approve the changes implemented in the PR.
This month is unusual; with little notice, the team is informed by their supervisor that there will be a change in the format that one of the datasets is received in. This format change is significant and requires non-trivial changes to the team’s codebase. In particular, once the changes are made, the code will support data preprocessing in the new format, but will no longer accommodate the old format.
The three employees quickly delegate responsibilities to incorporate the necessary changes to the codebase:
- Jane will write the new piece of code required to accommodate the new data format
- John will write automated tests that verify the correctness of Jane’s code
- Janice will update the documentation to describe the data format changes.
The team has been following good version control practices, so the main branch of their GCCode repository is up to date and correctly implements the analysis required to produce the previous months’ reports.
Jane, John, and Janice begin by pulling from the GCCode repository to make sure each of their local repositories is up to date. Once this step is done, they each checkout a new branch from the main branch. Since the team is small, they choose to omit much of the overhead presented in a successful branching model and just checkout their own branches directly from the main branch.
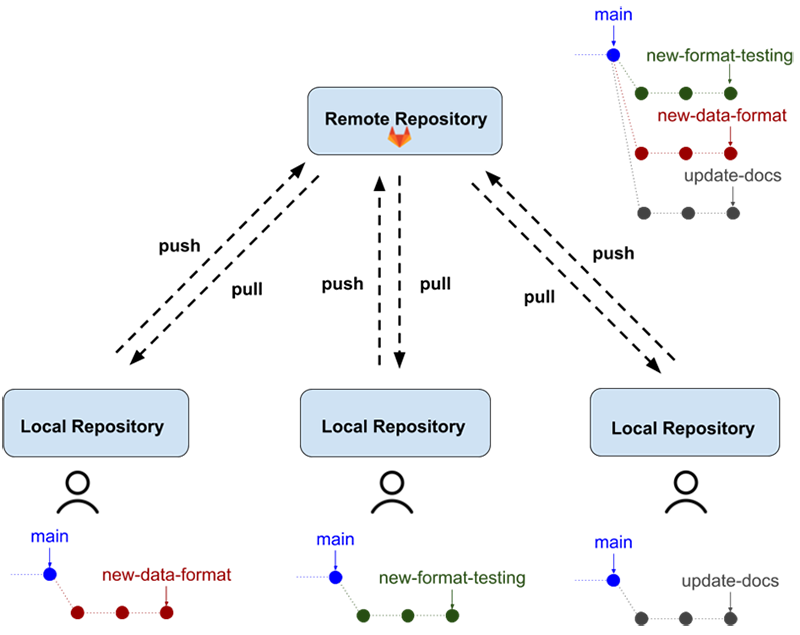
Description - Figure 1
Example of three employees interacting with a remote Git repository. There is a box at the top of the diagram representing a remote repository. Below this, there are three boxes side-by-side representing local repositories of each of the three employees. For each box, there is a figure showing the employees’ branch off of main, which is represented as a series of circles, where each circle is a commit on the employees’ branch. Arrows pointing to/from the remote and local repositories show that employees push to and pull from the remote repository to keep their changes in sync with the remote. Finally, the remote has a figure showing all three employees’ branches off of main put together in a single diagram, indicating that the work of all three employees is happening in parallel and the work of each employee is not conflicting with the work of the others.The three go about their work on their local workstations, committing their changes as they go while following good commit practices. By the end of the business day, they push their branches to the remote repository. At this point, the remote repository has three new branches that are each several commits ahead of the main branch. Each of the three assigns another to be their peer reviewer, and the next day the team approves changes and merges each member’s branch to main.
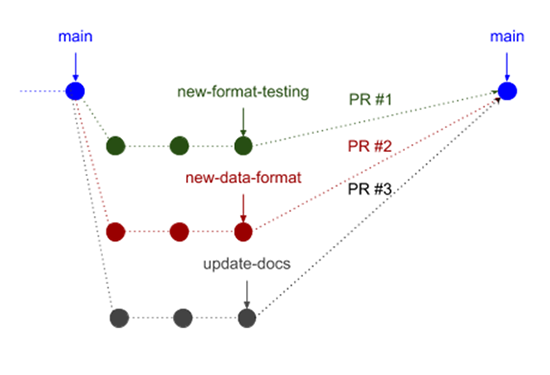
Description - Figure 2
Example of three branches merging back into the main branch via pull request. There is a circle representing the most recent commit of the main branch at the point when each of the three employees’ branches are created off of main. There are now three branches that each employee has worked on in parallel to implement their workflow, without conflicting with the work of the others. Each branch has several consecutive circles representing commits made. At the right side of the figure, the three parallel branches converge into a second circle representing the head of the new main branch after all three employees’ branches have been merged.On the day that the report must be generated, they run their new code and successfully generate and send the report for their senior management using the new data.
Later that day, they receive an urgent request asking them to reproduce the previous three months’ reports for audit purposes. Given that the code has changed to accommodate the new data format, the current code is no longer compatible with the previous datasets.
Git to the rescue!
Fortunately, however, the team is using Git to manage their codebase. Because the team is using Git, they can checkout to the commit just before they made their changes, and temporarily revert the state of the working folder to what it was before their changes. Now that the folder has changed, they can retroactively produce the three reports using the previous three months’ data. Finally, they can then checkout back to the most recent commit of the main branch, so that they can use the new codebase that accommodates the format change going forward.
Even though the team described above is performing an analytics workflow, they were able to leverage Git to prevent a situation that otherwise may have been very inconvenient and time-consuming.
Learn more about Git
Would your work benefit from using the practices described above? Are you unfamiliar with Git? Here are a few resources to get you started:
- The first half of IBM’s How Does Git Work provides a mental model for how Git works, and introduces many of the technical terms of Git and how they relate to that model.
- This article about a successful git branching model provides a guide on how to perform collaborative workflows using a branching model and a framework that can be adjusted to suit particular needs.
- The Git book provides a very detailed review of the mechanics of how Git works. It is broken down by section, so you can review whichever portion(s) are most relevant to your current use case.
What’s next?
Applying version control to one’s source code is just one of many computer science-inspired practices that can be applied to analytics and data science workflows.
In addition to versioning source code, many data science and analytics professionals may find themselves benefiting from data versioning (see Data Version Control for an implementation of this concept) or model versioning (e.g. see MLFlow model versioning).
Outside of versioning, there are many other computer science practices that analytics professionals can make use of such as automated testing, adhering to coding standards (e.g. Python’s PEP 8 style guide and environment and package management tools (e.g. pip and virtual environments in Python).
These resources are a great place to start as you begin to discover how complexity management practices from computer science can be used to improve data science and analytics workflows!
- Date modified: