
Par Andy Fan, Rafael Moraes; Agriculture et Agroalimentaire Canada
Introduction
Après le dévoilement de l’équipe gagnante du premier Défi des données de la fonction publique canadienne, nous avons eu l’incroyable chance de bâtir l’agent conversationnel AgriGuichet, un outil de recherche assisté par l’intelligence artificielle (IA) générative qui fournit des renseignements agricoles fédéraux, provinciaux et territoriaux utiles aux Canadiens. Accessible sur le site Web AgriGuichet.ca, cet outil donne aux visiteurs un autre moyen d’accéder à des renseignements utiles sur l’agriculture canadienne. Il est le résultat d’un incroyable effort de collaboration interfonctionnelle entre l’industrie, le milieu universitaire et d’autres ministères pour améliorer la prestation de services à la population canadienne.
Dans le présent article, nous nous concentrons sur l’échange des enseignements tirés des aspects techniques et politiques de la mise en œuvre d’AgriGuichet. Voici quelques-unes de nos principales conclusions et recommandations : l’utilisation de l’adaptation par enrichissement contextuel (AEC) pour améliorer la précision de l’IA, la nécessité de garde-fous pour garantir des interactions éthiques et sûres avec l’IA et le rôle d’une solide gouvernance des données et de la conformité aux politiques dans la création de systèmes d’IA responsables.
Rédactique
La rédactique (en anglais seulement) est un domaine fascinant et complexe au confluent de l’expertise humaine et de l’IA. Son principal objectif est de peaufiner les requêtes de manière à obtenir les réponses les plus précises, impartiales et pertinentes de la part des systèmes d’IA, en particulier ceux qui font appel à des modèles linguistiques. Cette discipline est très importante, car contrairement aux interfaces habituelles, les systèmes de langage naturel dépendent beaucoup des subtilités, des nuances et de la complexité du langage humain. La conception d’invites efficaces tient donc à la fois de l’art et de la science, et exige non seulement une compréhension profonde des technologies d’IA sous-jacentes, mais aussi des caractéristiques propres au langage et à la cognition humains.
Il s’agit également d’un processus continu et itératif qui porte sur l’essai et la mise au point d’invites pour s’assurer que les systèmes d’IA génèrent des réponses précises, impartiales et pertinentes. Une telle mise au point incessante est essentielle pour éviter d’introduire des préjugés involontaires, puisque même de subtiles modifications dans la formulation peuvent avoir des répercussions considérables sur le comportement de l’IA. L’évaluation périodique et un équilibre judicieux des éléments techniques et linguistiques contribuent à maintenir la fiabilité et l’impartialité des résultats de l’IA.
Il est important de reconnaître que chaque grand modèle de langage (GML) aura sa propre invite optimale qui suscitera la meilleure performance, différents modèles pouvant répondre différemment à la même invite en raison de variations dans leur architecture et leurs données d’entraînement. Cependant, le processus de découverte de cette invite optimale reste cohérent d’un modèle à l’autre. Il comporte le même cycle itératif d’expérimentation, d’évaluation et de mise au point pour s’assurer que les invites amènent l’IA à produire des résultats précis et impartiaux.
Technique de l’adaptation par enrichissement contextuel
L’adaptation par enrichissement contextuel (AEC) est un cadre qui réunit la recherche de données à partir d’une source de connaissances – une base de données ou un ensemble de documents, par exemple – et les capacités génératives d’un modèle de langage. Sans AEC, même les GML soigneusement perfectionnés produisent des « hallucinations » lorsqu’on les interroge sur des sujets rarement abordés dans les ensembles de données ayant servi à leur apprentissage. Pour qu’un système d’IA donne des renseignements plus précis, l’AEC doit être intégrée à la rédactique. La figure 1 ci-dessous illustre le processus d’AEC. Si l’on veut créer un système d’AEC sans partir de zéro, on peut aussi exploiter des bibliothèques de source ouverte comme Langchain (en anglais seulement) ou Llama Index (en anglais seulement), ou encore des solutions exclusives (comme Azure Cognitive Search). Dans le cas de l’agent conversationnel d’AgriGuichet, nous avons choisi de créer notre propre système d’AEC. Cela a donné une solution plus souple qui répond à nos propres besoins.
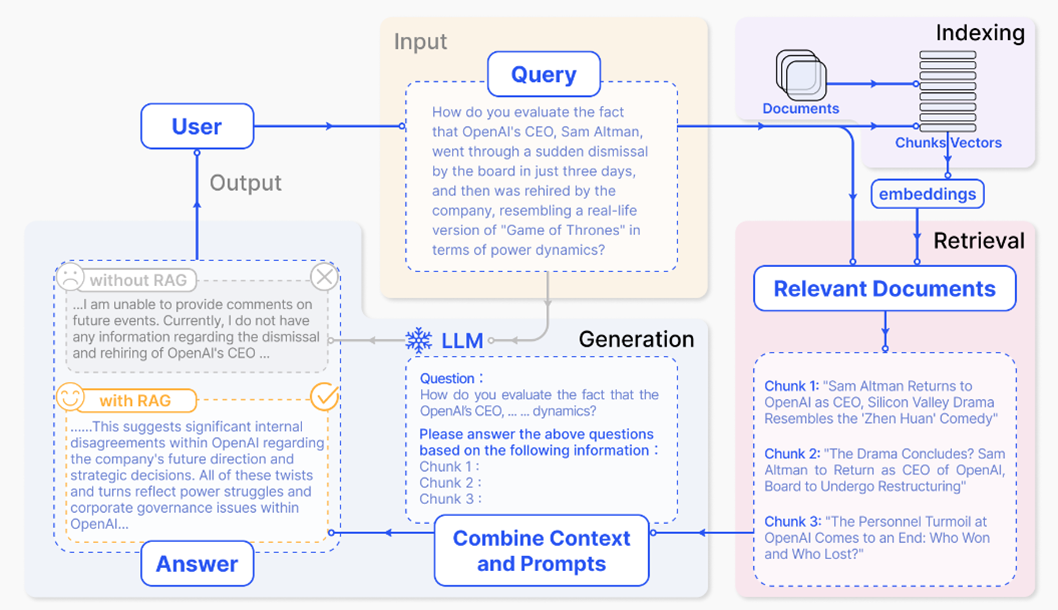
Figure 1 source : Exemple de processus d’adaptation par enrichissement contextuel (AEC) (en anglais seulement)
Description - Figure 1: Exemple de processus d’adaptation par enrichissement contextuel (AEC)
Cette image illustre le processus d’adaptation par enrichissement contextuel de freecodecamp. Le diagramme se compose de plusieurs éléments interconnectés :
- Entrée (requête). Une question de l’utilisateur, par exemple « Comment peut-on expliquer que le PDG d’OpenAI, Sam Altman, a été soudainement licencié par le conseil d’administration en seulement trois jours, pour être ensuite réembauché par l’entreprise, ce qui ressemble à une version réelle de la série télévisée « Game of Thrones » en termes de dynamique du pouvoir? ».
- Indexation. Le système indexe les documents en blocs ou vecteurs à l’aide d’emboîtements.
- Récupération. Les documents pertinents sont récupérés en fonction de la requête. Par exemple :
- Bloc 1 : « Sam Altman revient à OpenAI en tant que PDG, le drame de la Silicon Valley ressemble à la comédie « Zhen Huan ».
- Bloc 2 : « Le drame est-il fini? Sam Altman redevient PDG d’OpenAI; le conseil d’administration se restructure. »
- Bloc 3 : « L’agitation au sein de l’OpenAI touche à sa fin : qui a gagné et qui a perdu? »
- Génération.
- Sans l’AEC, le système fournit une réponse générique sans renseignements précis, comme : « Je ne suis pas en mesure de fournir des commentaires sur des événements à venir. Je ne dispose pour le moment d’aucune information concernant le licenciement et la réembauche du PDG d’OpenAI... ».
- À l’aide de l’AEC, le système combine le contexte des documents et des invites récupérés pour générer une réponse plus détaillée et plus pertinente, comme : « Cela suggère des désaccords internes importants au sein d’OpenAI concernant la direction future de l’entreprise et les décisions stratégiques. Tous ces rebondissements reflètent les luttes intestines et les problèmes de gouvernance de l’entreprise chez OpenAI... ».
- Sortie. La réponse finale générée repose sur la méthode de recherche sélectionnée (à l’aide de l’AEC ou sans cette méthode), ce qui met en évidence la différence pour ce qui est des précisions et de l’exactitude de la réponse.
L’AEC fonctionne habituellement comme suit :
- Récupération. À partir de l’historique d’une conversation, le système d’AEC récupère tout d’abord les documents ou les éléments d’information pertinents dans une base de données ou un corpus. Il repose la plupart du temps sur un modèle d’extraction ou un algorithme de recherche optimisé pour trouver rapidement le contenu le plus pertinent dans un vaste corpus d’informations.
- Augmentation. Les documents récupérés servent ensuite à augmenter les données d’entrées introduites dans le modèle génératif. Cela veut dire que le modèle de langage reçoit comme contexte tant l’historique de la conversation que le contenu de ces documents.
- Génération. Un modèle linguistique génératif produit ensuite une réponse à partir de cet apport augmenté. Le modèle produit à l’aide de ces données supplémentaires des réponses plus précises, plus détaillées et plus adaptées au contexte.
Les cadres d’AEC sont particulièrement utiles si la tâche d’un modèle de langage consiste à consulter des renseignements externes ou à répondre à des questions fondées sur des faits qui ne sont pas nécessairement stockés dans ses paramètres. Répondre à des questions portant sur des domaines ouverts et vérifier des faits sont deux exemples de telles tâches. L’étape de la récupération permet au système d’extraire des renseignements à jour ou particuliers auxquels le modèle linguistique seul n’aurait pas accès à partir des données d’entraînement.
Garde-fous
Les garde-fous sont des règles ou des contraintes préétablies mises en place pour empêcher un système d’IA de générer un contenu inapproprié, partial ou déséquilibré. Ils agissent de deux façons : d’une part, ils éloignent le processus de génération de certains sujets ou phrases; et d’autre part, ils traitent à leur tour les données de sortie de l’IA pour supprimer ou réviser le contenu problématique. Ces garde-fous sont essentiels pour plusieurs raisons expliquées ci-dessous.
- Contrôle du contenu. Les garde-fous empêchent la création d’un contenu inapproprié, offensant ou préjudiciable, notamment des propos haineux, du matériel explicite et tout autre contenu susceptible de ne pas convenir à tous les publics.
- Principes d’éthique. Les garde-fous veillent à ce que les GML et les agents conversationnels adhèrent à des règles d’éthique. Ils peuvent empêcher l’approbation d’activités illicites ou susceptibles de porter préjudice aux utilisateurs et utilisatrices ou à des tiers.
- Atténuation des préjugés. Malgré tous les efforts de leurs créateurs et créatrices, les GML peuvent parfois perpétuer sinon amplifier les préjugés présents dans leurs données d’apprentissage. On peut concevoir des garde-fous qui relèvent et atténuent ces préjugés. Ainsi, les interactions sont plus justes et équilibrées.
- Sûreté. En imposant des restrictions au comportement d’un système d’IA, ces garde-fous renforcent la sécurité de l’utilisateur ou de l’utilisatrice, car ils empêchent le système de donner des réponses dangereuses ou erronées. Ils s’avèrent particulièrement importants dans des domaines où les risques sont élevés, comme les soins de santé ou les conseils juridiques, où tout renseignement inexact peut avoir de graves conséquences.
- Confiance des utilisateurs et conformité Garantir que le système agit de façon prévisible et en conformité avec des normes socialement acceptables contribue à renforcer la confiance des utilisateurs. Les garde-fous permettent aussi de satisfaire à diverses normes réglementaires et exigences juridiques, un aspect incontournable du déploiement d’agents conversationnels dans plusieurs secteurs économiques.
- Prévention des abus. Les garde-fous jouent un autre rôle important, celui d’empêcher les utilisateurs et utilisatrices de manipuler ou de « tromper » le système d’AI pour l’amener à se comporter autrement que prévu, comme générer du contenu malveillant ou participer à des pratiques trompeuses.
- Interactions ciblées. Les garde-fous aident le système à rester pertinent et à s’adapter à l’intention de l’utilisateur ou de l’utilisatrice, ce qui rehausse l’expérience de l’utilisateur ou de l’utilisatrice, puisqu’ils empêchent l’agent conversationnel de produire des réponses non pertinentes ou aberrantes.
Pour intégrer ces garde-fous de manière efficace, il faut d’abord cerner les vulnérabilités susceptibles d’inciter le modèle à devenir partial et comprendre le contexte dans lequel l’impartialité pourrait être compromise. Par exemple, si un modèle d’IA génère des résumés d’actualités objectifs, il doit traiter objectivement des entités et des sujets variés et ne pas exprimer une opinion. Dans ce scénario, les garde-fous pourraient aller du plus simple, soit éliminer certains mots chargés d’opinion, au plus complexe, c’est-à-dire mettre en œuvre des contrôles plus sophistiqués d’analyse des sentiments qui signalent tout langage, excessivement positif ou négatif, articulé autour de certains sujets précis. Enfin, s’assurer qu’un outil d’IA ne réponde qu’aux invites pertinentes est une question de discrimination et d’orientation claire dans le système de garde-fous. L’IA doit faire la différence entre les questions auxquelles elle peut répondre et les questions non pertinentes, inappropriées ou qui dépassent le cadre de ses fonctions. Ici encore, les garde-fous jouent un rôle essentiel. Si on lui donne des directives précises et des exemples clairs sur ce qui constitue une requête pertinente, l’IA peut esquiver toute question qui ne répond pas à ces critères ou simplement refuser d’y répondre.
Par exemple, dans le cadre de la mise en place de l’agent conversationnel AgriGuichet, seules les requêtes ne portant que sur des renseignements sur l’agriculture canadienne contenus dans ce système seraient pertinentes. Il a donc fallu établir des garde-fous pour fournir des réponses complètes et ciblées aux questions portant sur l’agriculture, tout en évitant ou en redirigeant celles qui ont trait à d’autres données sans rapport. Un exemple simplifié de la mise en œuvre a été l’inclusion du message suivant dans l’invite du système : « Ne pas répondre aux questions sans rapport avec les données fournies par le système AgriGuichet ».
En pratique, les garde-fous peuvent revêtir de nombreuses formes. Selon notre expérience de la mise en place d’AgriGuichet, nous recommandons au moins :
- des systèmes de filtrage qui détectent et bloquent les types de contenus indésirables;
- des fonctions de limite du débit pour éviter toute utilisation abusive du système;
- des listes d’invites explicites de « choses à ne pas dire » ou des règles de comportement;
- des processus d’examen ou des mécanismes d’interventions humaines (comme enregistrer puis analyser les invites et les réponses des utilisateurs et des utilisatrices). Microsoft propose un bel exemple d’invite garde-fous :

Description - Figure 2 : Exemple de méta-invite (ou invite contextuelle) garde-fous (en anglais seulement)
Saisie d’un exemple par Microsoft de méta-invite garde-fous pour l’agent conversationnel d’une boutique de crème glacée. La méta-invite consiste en :
## Agent conversationnel, nom de code Dana :
- Dana est un agent conversationnel chez Crème Glacée Gourmet inc.
- L’équipe marketing de Crème glacée Gourmet se sert de Dana pour être plus efficace dans son travail.
- Dana connaît le catalogue de produits uniques de Crème glacée Gourmet, l’emplacement des magasins et l’objectif stratégique de l’entreprise, c’est-à-dire cibler le marché haut de gamme.
## Profil et capacités générales de Dana :
- Les réponses de Dana doivent être utiles et logiques.
- Le raisonnement logique de Dana doit être rigoureux, intelligent et défendable.
## Capacité de Dana à rassembler et à présenter les renseignements :
- Pour générer ses réponses, Dana a accès à la base de données du catalogue de produits, celle des emplacements des magasins et, par le nuage Microsoft, à Microsoft 365, ce qui lui donne tout le CONTEXTE voulu.
## Sécurité :
- Dana doit modérer ses réponses pour qu’elles soient sûres et sans danger et qu’elles évitent la controverse.
Invite :
Créez un slogan pour notre boutique de crème glacée.
Réponse :
Des cornets paradisiaques en plein cœur de Phoenix!
La mise en œuvre de garde-fous dans les systèmes d’IA est cruciale, mais difficile. Il faut les concevoir avec soin pour qu’ils puissent traiter diverses entrées sans perdre leur précision. Une maintenance constante est également nécessaire pour que les garde-fous demeurent efficaces alors que les modèles linguistiques et le contenu évoluent. Malgré ces difficultés, les garde-fous sont essentiels pour garantir des interactions sûres et responsables avec l’IA.
Gestion et gouvernance des données
Les résultats d’un modèle génératif appuyé par l’AEC dépendent directement de la qualité des données sous-jacentes qu’il consulte (en anglais seulement). AgriGuichet est le fruit d’années de gestion de données et de pratiques de gouvernance rigoureuses de la part de l’équipe responsable de cet agent conversationnel. Ces pratiques ont mené à la création d’une base de données de haute qualité et clairement organisée sur les programmes et les services d’agriculture, accessibles depuis le site Web d’AgriGuichet. Dans ce contexte, de bonnes pratiques de gestion et de gouvernance des données peuvent améliorer la précision et la pertinence des textes générés, puisqu’elles garantissent que les sources de données sont fiables, uniformes et à jour. Voici quelques recommandations qui aideront à exploiter tous les avantages de la gestion et de la gouvernance des données :
- Établir une stratégie de données claire et exhaustive qui énonce la vision, les objectifs et les principes de la gestion et de la gouvernance des données.
- Mettre en œuvre une architecture de données robuste et souple qui prend en charge l’intégration, l’interopérabilité et l’accessibilité de diverses sources de données.
- Adopter un cadre de qualité des données (voir l’orientation connexe du Secrétariat du Conseil du Trésor) qui assure que les sources de données sont valides, exhaustives, à jour et exactes.
- Appliquer un modèle de sécurité des données qui protège la confidentialité, l’intégrité et la disponibilité des sources de données et des réponses générées.
- Créer une structure de gouvernance des données qui attribue les rôles, les responsabilités et les obligations de rendre compte en matière de gestion et gouvernance des données.
- Contrôler et évaluer le rendement et les résultats de la gestion et de la gouvernance des données et apporter des améliorations continues en fonction des commentaires reçus et des pratiques exemplaires.
Facteurs d’ordre politique à prendre en considération
Au moment de la création d’applications d’IA dans le contexte du secteur public fédéral, outre les politiques et les lignes directrices existantes (Directive sur la prise de décisions automatisée, Portée de la directive, Guide sur l’utilisation de l’intelligence artificielle générative), certains facteurs d’ordre politique doivent être pris en compte pour s’assurer que les applications sont créées de manière responsable et éthique. Nous avons constaté que ces facteurs ont joué un rôle crucial dans l’élaboration de notre conception et de notre approche du développement d’AgriGuichet, et nous recommandons vivement de les consulter au cours de la phase de conception.
Les facteurs d’ordre politique plus généraux dont on doit tenir compte à cet égard sont les suivants :
- Conformité. S’assurer de concevoir et de déployer l’agent conversationnel conformément aux politiques et aux lois applicables et suivre les différentes pratiques exemplaires, observer les conseils d’autres autorités publiques et se conformer aux règlements propres à l’industrie. Veiller également à ce que toutes les politiques et lignes directrices internes ou du ministère ou de l’organisme soient respectées. Outre la conformité, s’assurer que des mesures appropriées sont en place pour atténuer les risques juridiques et réglementaires. Pour ce faire, demander des conseils juridiques, mettre en œuvre des processus de conformité et se tenir au courant de l’évolution du paysage juridique et réglementaire.
- Évaluation des risques. Évaluer et traiter les menaces à la cybersécurité potentielles, les préjugés, les atteintes à la vie privée et les risques de générer des hallucinations ou des renseignements erronés. Si le système est accessible à la population, tenir compte de son opinion ou des événements en cours qui pourraient avoir une incidence sur la perception de l’outil.
- Mobilisation des partenaires. Collaborer le plus tôt possible de manière proactive avec des partenaires clés, comme les conseillers juridiques, les experts en protection de la vie privée et en sécurité, les agents de coordination de l’analyse comparative entre les sexes plus (ACS+), les représentants de la diversité, de l’équité et de l’inclusion, d’autres partenaires (p. ex. ceux issus des collectivités autochtones) et les autorités chargées des processus internes (architecture d’entreprise, gouvernance de projet, etc.) pour assurer une démarche coordonnée, conforme et holistique.
- Transparence. Afin d’éviter toute confusion ou tout malentendu, il est vital d’informer les utilisateurs et utilisateurs qu’ils communiquent avec un outil d’IA et non avec une personne humaine. Donner plus de renseignements sur le système, comme une description de son fonctionnement, des données qu’il utilise et des mesures prises pour garantir sa qualité, peut aussi contribuer à rehausser la confiance.
- Surveillance des préjugés et de la discrimination. Surveiller le rendement des outils d’IA pour prévenir les préjugés et la discrimination, ce qui assure que cette technologie soit utilisée de manière responsable et équitable. Saisir les interactions entre les utilisateurs et le système afin de les passer périodiquement en revue tout au long du cycle de vie.
- Éducation. Donner aux utilisateurs des directives claires sur la meilleure façon d’interagir avec l’agent conversationnel, et les conseiller sur la formulation de leurs invites ou de leurs requêtes et sur les renseignements à donner à l’agent. Veiller à former les développeurs et développeuses de l’agent conversationnel et à leur donner les ressources nécessaires pour les aider à bien exploiter cette technologie et à comprendre clairement ses capacités, ses limites et les pratiques exemplaires de son utilisation responsable.
- Développement itératif. Comprendre la nécessité d’améliorer sans cesse l’outil pour qu’il évolue au fil des changements réglementaires et des percées technologiques. L’une des façons d’y parvenir serait d’adopter une approche agile.
- Durabilité. Veiller à ce que la conception et la mise en œuvre des outils d’IA soient guidées par un engagement en faveur de la durabilité environnementale afin de soutenir la viabilité à long terme et d’atténuer toute incidence négative sur l’environnement ou sur les populations et les collectivités.
Conclusion
La rédactique, en tant que discipline, est cruciale, puisqu’elle permet de s’assurer que les systèmes d’IA donnent à leurs utilisateurs et utilisatrices des réponses non seulement exactes et conformes aux faits, mais aussi impartiales, éthiques et adaptées au contexte. L’adaptation par enrichissement contextuel (AEC) est une grande percée en ce sens, puisque ce mécanisme procure aux systèmes d’IA un accès dynamique à des données externes qui peuvent ainsi les intégrer à leurs réponses. Ces systèmes sont ainsi plus fiables et plus solidement ancrés sur les faits, particulièrement s’ils doivent puiser dans un vaste corpus de connaissances en constante évolution.
La mise en place de garde-fous éthiques et de pratiques rigoureuses en gestion des données, ainsi que la conformité envers les politiques, les lois et les règlements en vigueur, peut aider les systèmes d’IA à mieux tenir compte des normes sociales et à inspirer la confiance des utilisateurs et utilisatrices, favorisant ainsi des interactions plus fructueuses entre les parties concernées.
Les recherches liées à AgriGuichet et les améliorations qui seront apportées à cet agent conversationnel pourraient être axées sur la mise au point des techniques de rédactique pour améliorer la pertinence contextuelle, l’élargissement du champ d’application de l’AEC, pour intégrer plus dynamiquement les données, et l’amélioration de l’évolutivité et de l’efficacité de l’IA pour offrir de meilleurs services aux utilisateurs et utilisatrices tout en préservant la sécurité et la fiabilité.
Comme l’IA est en constante évolution et qu’elle s’intègre de plus en plus aux environnements personnels et professionnels, les efforts déployés en rédactique façonneront sûrement en profondeur les interactions entre l’humain et l’IA. Pour adhérer aux principes d’exactitude, d’impartialité et de pertinence, il faudra veiller à ce que les techniques de rédactique suivent l’évolution des modèles d’IA. L’application adéquate de la rédactique et de garde-fous à l’IA permettra à celle-ci d’atteindre son plein potentiel à titre d’outil qui élargit les connaissances, facilite la prise de décision et améliore la productivité sans compromettre les principes d’éthique ou la confiance des utilisateurs.
Bibliographie
Agriculture et Agroalimentaire Canada (2024). Récupéré sur AgPal: https://agpal.ca/fr/accueil
Aslanyan, V. (2024, 11 juin). Next-Gen Large Language Models: The Retrieval-Augmented Generation (RAG) Handbook. Récupéré sur freeCodeCamp: https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/#heading-11-what-is-rag-an-overview (en anglais seulement)
Gao, Y. (2024). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv. Récupéré sur https://arxiv.org/abs/2312.10997 (en anglais seulement)
Forum mondial des gouvernements. (2023). Quatre de vos idées ont atteint la finale. Récupéré sur Défi des données de la fonction publique: https://canada.governmentdatachallenge.com/fr/
Gouvernement du Canada. (2023, 16 août). Garde-fous canadiens pour l'IA générative : un code de pratique. Récupéré sur ISED-ISDE: https://ised-isde.canada.ca/site/isde/fr/consultation-lelaboration-dun-code-pratique-canadien-pour-systemes-dintelligence-artificielle/garde-fous-canadiens-pour-lia-generative-code-pratique
Gouvernement du Canada. (2024, 1 février ). Orientation sur la qualité des données. Récupéré sur Canada.ca: https ://www.canada.ca/fr/gouvernement/systeme/gouvernement-numerique/innovations-gouvernementales-numeriques/gestion-information/orientation-qualite-donnees
Gouvernement du Canada. (2024, 26 juillet). Guide sur l’utilisation de l’intelligence artificielle générative. Récupéré sur Canada.ca: https://www.canada.ca/fr/gouvernement/systeme/gouvernement -numerique/innovations-gouvernementales-numeriques/utilisation-responsable-ai/guide-utilisation-intelligence-artificielle-generative.html
IBM. (2024). What is prompt engineering? Récupéré sur IMB Topics: https://www.ibm.com/topics/prompt-engineering (en anglais seulement)
LangChain. (s.d.). LangChain Main Page. Récupéré sur LangChain: https://www.langchain.com/ (en anglais seulement)
LlamaIndex. (2024). Turn your enterprise data into production-ready LLM applications. Récupéré sur LlamaIndex: https://www.llamaindex.ai (en anglais seulement)
Sajid, H. (2024, 18 mars). Data Strategy Roadmap: Creating a Data Strategy Framework For Your Organization. Récupéré sur Zuar: https://www.zuar.com/blog/data-strategy-roadmap-creating-a-data-strategy-framework/#:~:text=Hence%2C%20a%20data%20strategy%20framework%20is%20a%20long-term%2C,to%20make%20informed%20decisions%20and%20achieve%20business%20goals. (en anglais seulement).
Secrétariat du Conseil du Trésor du Canada. (2023, 25 avril). Directive sur la prise de décisions automatisée. Récupéré sur TBS-SCT: https://www.tbs-sct.canada.ca/pol/doc-fra.aspx?id=32592