
Utilisation de l'apprentissage automatique pour prédire le rendement des cultures
Par : Kenneth Chu, Statistique Canada
La Division de la science des données (DScD) de Statistique Canada a récemment terminé un projet de recherche pour la Série de rapports sur les grandes cultures (SRGC, ou Enquête sur les grandes cultures, EGC) Note de bas de page 1 portant sur l'utilisation des techniques d'apprentissage automatique (plus précisément, les techniques de régression supervisée) afin de prédire le rendement des cultures en début de saison.

L'objectif du projet était d'étudier si les techniques d'apprentissage automatique pouvaient être utilisées pour améliorer la précision de la méthode actuelle de prédiction du rendement des cultures (appelée la méthode de référence).
Deux grands défis se posaient : (1) comment intégrer toute technique de prédiction (apprentissage automatique ou autre) à l'environnement de production des EGC selon une méthodologie solide, et (2) comment évaluer toute méthode de prédiction de façon utile dans le contexte de production des EGC.
Pour le point (1), le protocole de validation de la fenêtre mobile progressive Note de bas de page 2 (initialement conçu pour un apprentissage supervisé à partir de données de série chronologique) a été adapté pour éviter la fuite de renseignements temporels. Pour le point (2), l'équipe a choisi de procéder à une vérification en examinant la série réelle d'erreurs de prédiction obtenue dans le cas d'un déploiement sur des cycles de production passés.
Motivation
Traditionnellement, la SRGC publie des estimations annuelles du rendement des cultures à la fin de chaque année de référence (peu après les récoltes). De plus, les prédictions du rendement des cultures pour l'année complète sont diffusées plusieurs fois au cours de l'année de référence. On communique avec les exploitants agricoles en mars, juin, juillet, septembre et novembre aux fins de collecte des données, leur imposant un lourd fardeau de réponse.
En 2019, pour la province du Manitoba, une méthode fondée sur un modèle (essentiellement une sélection de variables par la méthode LASSO [en anglais Least Absolute Shrinkage and Selection Operator] suivie d'une régression linéaire robuste) a été proposée pour générer les prédictions de juillet à partir d'observations satellites longitudinales des niveaux de végétation locaux ainsi que des mesures météorologiques régionales. La question sur la prédiction du rendement des récoltes a pu être retirée du questionnaire de l'EGC de juillet pour le Manitoba, ce qui a réduit le fardeau de réponse.
Technique de régression de base : XGBoost et apprenants de base linéaires
Plusieurs techniques de prédiction ont été examinées, notamment les forêts d'arbres décisionnels, les machines à vecteur de support, les modèles linéaires généralisés elastic-net standardisés et les perceptrons multicouches. Des considérations relatives à l'exactitude et au temps de calcul nous ont menés à concentrer notre attention sur XGBoost Note de bas de page 3, combiné aux apprenants de base linéaires.
Validation de la fenêtre mobile progressive pour éviter les fuites de renseignements temporels
La principale contribution de ce projet de recherche est l'adaptation de la validation de la fenêtre mobile progressive (RWFV) Note de bas de page 2 comme protocole d'ajustement d'hyperparamètres. La validation RWFV est un cas particulier de validation progressive Note de bas de page 2; il s'agit d'une famille de protocoles de validation conçus pour éviter la fuite de renseignements temporels pour un apprentissage supervisé fondé sur des données de série chronologique.
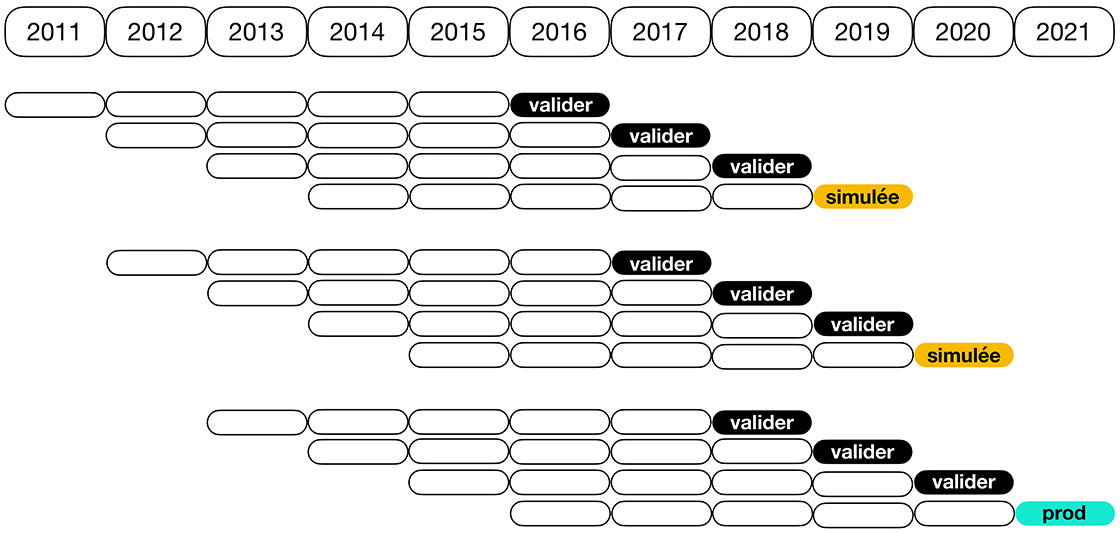
Supposons que vous formiez un modèle de prédiction en vue d'un déploiement pour le cycle de production de 2021. L'illustration suivante présente un schéma de validation de la fenêtre mobile progressive, selon une fenêtre d'entraînement de cinq ans et une fenêtre de validation de trois ans.

Description - Figure 1
Exemple d'un système de validation par fenêtre mobile progressive. Cette figure représente, à titre d'exemple, un système de validation à fenêtre mobile progressive avec une fenêtre de formation de cinq ans et une fenêtre de validation de trois ans. Un modèle de validation de ce type est utilisé pour déterminer la configuration optimale des hyperparamètres à utiliser lors de la formation du modèle de prédiction réel qui sera déployé en production.La case bleue au bout du schéma représente le cycle de production de 2021 et les cinq cases blanches à sa gauche correspondent à la fenêtre d'entraînement de cinq ans qui est utilisée. Cela signifie que les données d'entraînement pour le cycle de production de 2021 seront celles portant sur les cinq années la précédant strictement et immédiatement (2016 à 2020). Pour la validation, ou l'ajustement d'hyperparamètres, pour le cycle de production de 2021, les trois cases noires au-dessus de la case bleue correspondent à notre choix d'une fenêtre de validation de trois ans.
Le protocole RWFV est utilisé pour choisir la configuration optimale à partir de l'espace de recherche d'hyperparamètres, comme suit :
- fixer temporairement une configuration candidate arbitraire d'hyperparamètres provenant de l'espace de recherche;
- utiliser cette configuration pour former un modèle pour l'année de validation de 2020 à l'aide de données provenant des cinq années de 2015 à 2019;
- utiliser ce modèle formé obtenu pour fournir des prédictions pour l'année de validation de 2020; calculer en conséquence les erreurs de prédiction au niveau de la parcelle pour 2020;
- agréger les erreurs de prédiction au niveau de la parcelle jusqu'à obtenir une mesure de rendement numérique unique appropriée;
- répéter la procédure pour les deux autres années de validation (2018 et 2019).
En calculant la moyenne des mesures de rendement pour les années de validation 2018, 2019 et 2020, le résultat obtenu est une mesure de rendement numérique unique ou une erreur de validation pour la configuration temporairement fixée d'hyperparamètres.
Cela doit ensuite être répété pour toutes les configurations candidates d'hyperparamètres de l'espace de recherche d'hyperparamètres. La configuration optimisée à réellement déployer en production est celle qui fournit la meilleure mesure de rendement agrégée. Il s'agit de la validation de la fenêtre mobile progressive ou plus précisément notre adaptation de cette méthode au contexte de la prédiction de rendement des cultures.
Il convient de noter que le protocole susmentionné respecte la contrainte opérationnelle selon laquelle, pour le cycle de production de 2021, le modèle de prédiction formé doit avoir été formé et validé en fonction de données provenant d'années strictement précédentes; en d'autres termes, le protocole évite la fuite de renseignements temporels.
Mise à l'essai adaptée à la production par série d'erreurs de prédiction de cycles de production virtuels
Pour évaluer (de la façon la plus pertinente dans le contexte de production des EGC) le rendement de la stratégie de prédiction susmentionnée fondée sur XGBoost (linéaire) et RWFV, les scientifiques des données ont calculé la série d'erreurs de prédiction obtenue si la stratégie avait réellement été déployée pour des cycles de production passés. En d'autres termes, ces erreurs de prédiction de cycles de production passés virtuels ont été considérées comme des estimations de l'erreur de généralisation dans le contexte de la production statistique des EGC.
L'illustration suivante représente la série d'erreurs de prédiction des cycles de production virtuels.
Description - Figure 2
Série d'erreurs de prédiction des cycles de production virtuels. Les cycles de production virtuels sont exécutés pour les années de référence passées, comme décrit dans la figure 1. Comme les données de rendement réel des cultures sont déjà connues pour les cycles de production passés, il est possible de calculer les erreurs de prévision réelles si la stratégie de prévision proposée avait été effectivement déployée pour les cycles de production passés (représentés par des cases oranges). La série d'erreurs de prévision qui en résulte pour les cycles de production passés est utilisée pour évaluer la précision et la stabilité de la stratégie de prévision du rendement des cultures proposée.Il s'agit alors de répéter, pour chaque cycle de production virtuel (représenté par une case orange), ce qui vient d'être décrit pour la case bleue. La différence est maintenant la suivante : pour la case bleue (c.-à-d. le cycle de production actuel), il N'EST PAS encore possible de calculer les erreurs de production ou de prédiction au moment de la prédiction du rendement des cultures (en juillet), puisque la saison de croissance n'est pas terminée. Cependant, il est possible de le faire pour les cycles de production virtuels passés (les cases orange).
Ces erreurs de prédiction pour des cycles de production virtuels passés peuvent être illustrées dans le graphique suivant :
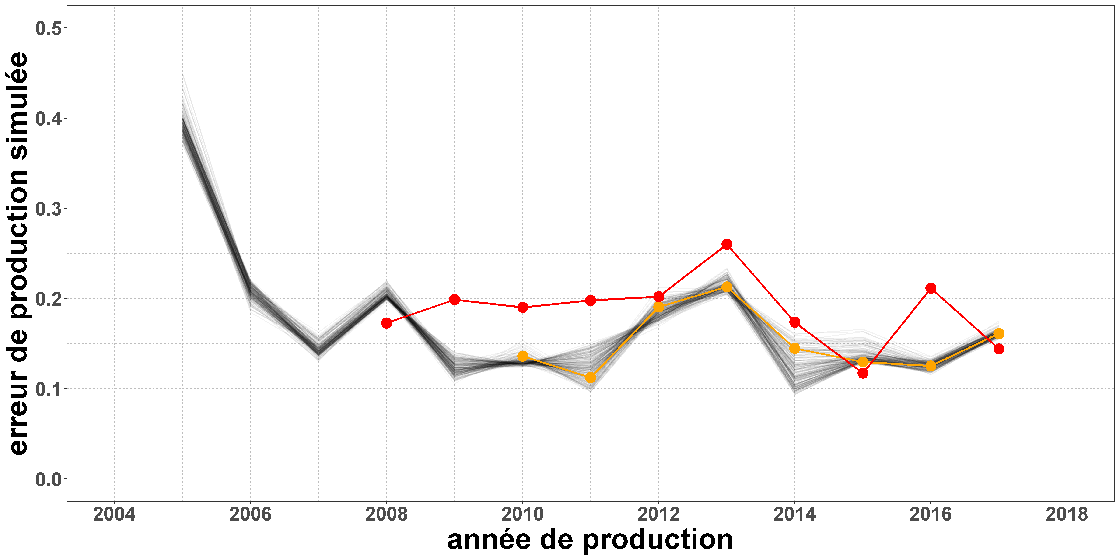
Description - Figure 3
Comparaison graphique de la stratégie de prédiction XGBoost(Linear)/RWFV avec le modèle de référence. La ligne rouge représente la série d'erreurs de production simulées de la stratégie de base, tandis que la ligne orange représente la stratégie XGBoost(Linear)/RWFV. Cette dernière stratégie présente des erreurs de prédiction toujours plus faibles sur des cycles de production passés virtuels consécutifs.La ligne rouge représente les erreurs de prédiction du modèle de référence, alors que la ligne orange, celles de la stratégie XGBoost/RWFV. Les lignes grises représentent les erreurs de prédiction pour chaque configuration candidate d'hyperparamètres de notre grille de recherche choisie (qui comprend 196 configurations).
La stratégie de prédiction XGBoost/RWFV a enregistré des erreurs de prédiction moindres que la méthode de référence, de façon constante sur des essais de production historiques consécutifs.
La stratégie proposée est actuellement en phase finale d'essai de préproduction, pour être appliquée conjointement par des spécialistes de domaine et les méthodologistes du programme agricole.
Importance de l'évaluation des protocoles
L'équipe a choisi de ne pas utiliser de méthode de validation habituelle, comme la validation test ou la validation croisée, ni une estimation générique d'erreur de généralisation, comme une erreur de prédiction sur un ensemble de données d'essai mis de côté au préalable.
Ces décisions sont fondées sur notre détermination à proposer un protocole de validation et un choix d'estimations d'erreurs de généralisation (respectivement, RWFV et séries d'erreurs de prédiction de cycles de production virtuels) qui soient bien plus pertinents et adéquats pour le contexte de production des EGC.
Les méthodologistes et praticiens en apprentissage automatique sont encouragés à évaluer attentivement si les protocoles de validation ou mesures d'évaluation génériques sont effectivement adaptés à leur cas d'utilisation et, dans le cas contraire, à rechercher d'autres options plus pertinentes et utiles pour le contexte donné. Pour de plus amples renseignements au sujet de ce projet, veuillez envoyer un courriel à statcan.dsnfps-rsdfpf.statcan@statcan.gc.ca.
- Date de modification :