
Apprentissage auto-supervisé en vision par ordinateur : classification d’images
Par : Johan Fernandes, Statistique Canada
Introduction
La vision par ordinateur comprend des tâches telles que la classification d'images, la détection d'objets et la segmentation d'images Note de bas de page 1. La classification d'images consiste à affecter une image entière à l'une de plusieurs classes finies. Par exemple, si une image contient un « chien » qui occupe 90 % de l'espace, elle est étiquetée comme étant un « chien ». De multiples modèles d'apprentissage profond (AP) utilisant des réseaux de neurones artificiels (RNA) ont été élaborés pour classer les images avec une grande précision. Les modèles de pointe pour cette tâche utilisent des RNA de différentes profondeurs et largeurs.
Ces modèles d'AP sont entraînés sur plusieurs images de différentes classes afin de développer leurs capacités de classification. À l'instar de l'entraînement d'un enfant humain pour faire la distinction entre les images d'une « voiture » et d'un « vélo », ces modèles doivent se voir présenter de multiples images de classes telles que « voiture » et « vélo » pour générer cette connaissance. Cependant, les humains ont l'avantage supplémentaire d'élaborer un contexte en observant leur environnement. Notre esprit peut capter des signaux sensoriels (sonores et visuels) qui nous aident à développer cette connaissance pour tous les types d'objets Note de bas de page 2. Par exemple, lorsque nous observons une voiture sur la route, notre esprit peut générer des connaissances contextuelles sur l'objet (la voiture) grâce à des caractéristiques visuelles telles que l'emplacement, la couleur, la forme, l'éclairage entourant l'objet et l'ombre qu'il crée.
Par ailleurs, un modèle d'AP créé expressément pour la vision par ordinateur doit être formé pour développer ces connaissances qui sont stockées sous la forme de poids et de biais qu'il utilise dans son architecture. Ces poids et ces biais sont mis à jour en fonction de ces connaissances lors de l'apprentissage du modèle. Le processus d'entraînement le plus courant, appelé apprentissage supervisé, consiste à entraîner le modèle avec l'image et l'étiquette correspondante afin d'améliorer sa capacité de classification. Cependant, la génération d'étiquettes pour toutes les images est chronophage et coûteuse, car cela implique que des annotateurs humains génèrent manuellement des étiquettes pour chacune des images. Par contre, l'apprentissage auto-supervisé est un nouveau paradigme d'entraînement qui peut être utilisé pour entraîner des modèles d'AP afin de classer des images sans le goulot d'étranglement d'étiquettes bien définies pour chaque image pendant l'entraînement. Dans le cadre de ces travaux, je décrirai l'état actuel de l'apprentissage auto-supervisé et son incidence sur la classification d'images.
Importance de l'apprentissage auto-supervisé
L'apprentissage auto-supervisé vise à mettre en place un environnement permettant d'entraîner le modèle d'AP à extraire le maximum de caractéristiques ou de signaux de l'image. Des études récentes ont montré que la capacité d'extraction de caractéristiques des modèles d'AP est limitée lorsqu'ils sont entraînés avec des étiquettes, car ils doivent sélectionner des signaux qui les aideront à élaborer un modèle pour associer des images semblables à cette étiquette Note de bas de page 2, Note de bas de page 3. Avec l'apprentissage auto-supervisé, le modèle est entraîné à comprendre les signaux sensoriels (p. ex. la forme et le contour d'objets) des images d'entrée sans qu'on lui montre les étiquettes associées.
En outre, puisque l'apprentissage auto-supervisé ne limite pas le modèle à l'élaboration d'une représentation discrète (étiquette) d'une image, il peut apprendre à extraire des caractéristiques beaucoup plus riches d'une image que son équivalent supervisé. Il dispose d'une plus grande liberté pour améliorer la façon dont il représente une image, car il n'a plus besoin d'être entraîné à associer une étiquette à une image Note de bas de page 3. Au lieu de cela, le modèle peut se concentrer sur l'élaboration d'une représentation des images grâce aux caractéristiques améliorées qu'il extrait et sur l'identification d'un modèle permettant de regrouper les images d'une même classe.
L'apprentissage auto-supervisé utilise davantage de signaux de réaction pour améliorer sa connaissance d'une image que l'apprentissage supervisé Note de bas de page 2. Par conséquent, le terme « auto‑supervisé » est de plus en plus souvent utilisé à la place de « non supervisé », car on peut faire valoir que les modèles d'AP reçoivent des signaux d'entrée provenant des données plutôt que des étiquettes. Cependant, ils bénéficient d'une certaine forme de supervision et ne sont pas complètement laissés à eux-mêmes dans le processus d'entraînement. Dans la section suivante, je décrirai les composantes nécessaires à l'apprentissage auto-supervisé.
Ces signaux sont améliorés par une technique appelée « augmentation des données », dans laquelle l'image est recadrée, certaines sections de l'image sont cachées ou le schéma de couleurs de l'image est modifié. À chaque augmentation, le modèle d'AP reçoit une image différente de la même classe ou catégorie que l'image originale. En exposant le modèle à de telles images augmentées, il peut être entraîné à extraire des caractéristiques riches fondées sur les sections visibles de l'imageNote de bas de page 4. En outre, cette méthode d'entraînement élimine le temps système lié à la génération d'étiquettes pour toutes les images, permettant ainsi d'adapter la classification d'images à des domaines où les étiquettes ne sont pas facilement disponibles.
Composantes des méthodes d'apprentissage auto-supervisé :
Encodeur ou extracteur de caractéristiques :
En tant qu'être humain, lorsque nous regardons une image, nous pouvons automatiquement recenser des caractéristiques telles que le contour et la couleur des objets afin de déterminer le type d'objet dans l'image. Pour qu'une machine puisse effectuer une telle tâche, nous utilisons un modèle d'AP, que nous appelons encodeur ou extracteur de caractéristiques puisqu'il peut automatiquement coder et extraire les caractéristiques d'une image. L'encodeur se compose de couches de RNA ordonnées de façon séquentielle, comme le montre la figure 1.
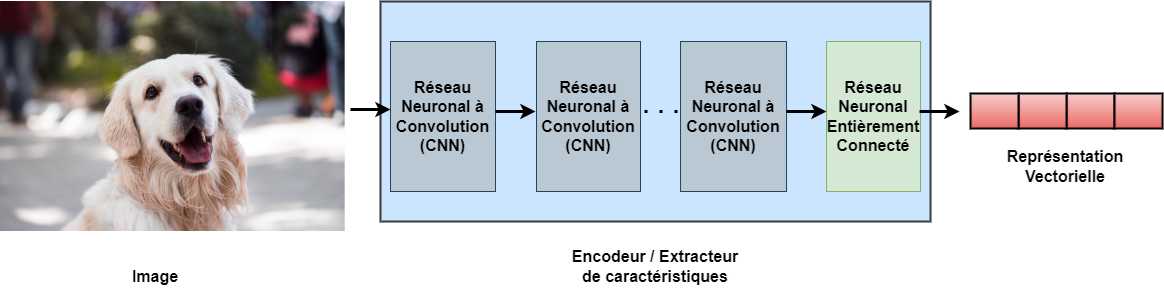
Figure 1: Composantes d’un encodeur ou extracteur de caractéristiques d’apprentissage profond
L’image décrit la structure d’un encodeur ou d’un extracteur de caractéristiques ainsi qu’un exemple de l’entrée qu’il reçoit et de la sortie qu’il fournit. L’entrée dans l’encodeur est une image qui, dans ce cas, montre un chien et la sortie est un vecteur qui peut représenter cette image dans un espace dimensionnel supérieur. L’encodeur est constitué de plusieurs couches neuronales à couche unique qui sont empilées l’une sur l’autre ou à côté l’une de l’autre, comme le montre cette image. Chaque couche se compose de plusieurs neurones convolutifs. Ces couches choisiront des caractéristiques essentielles qui aideront l’encodeur à représenter l’image comme un vecteur qui constitue la sortie finale de l’encodeur. Le vecteur qu’il produit à la fin aura n dimensions, et chaque dimension sera réservée à une caractéristique. Ce vecteur peut être projeté dans un espace n-dimensionel et peut être utilisé pour regrouper des vecteurs de la même classe comme un chien ou un chat.
Une image contient plusieurs caractéristiques. La tâche de l'encodeur consiste à extraire uniquement les caractéristiques essentielles, à faire abstraction du bruit et à convertir ces caractéristiques en une représentation vectorielle. Cette représentation codée de l'image peut être projetée dans un espace n-dimensionnel ou latent, selon la taille du vecteur. Par conséquent, pour chaque image, l'encodeur génère un vecteur représentant l'image dans cet espace latent. Le principe sous-jacent est de s'assurer que les vecteurs d'images de la même classe peuvent être regroupés dans cet espace latent. Par conséquent, les vecteurs de « chats » seront regroupés, tandis que les vecteurs de « chiens » formeront un groupe distinct, les deux groupes de vecteurs étant clairement séparés l'un de l'autre.
Les encodeurs sont entraînés pour améliorer leur représentation d'images afin de pouvoir coder des caractéristiques plus riches des images dans des vecteurs qui aideront à distinguer ces vecteurs dans l'espace latent. Les vecteurs générés par les encodeurs peuvent être utilisés pour traiter de multiples tâches de vision par ordinateur, telles que la classification d'images et la détection d'objets. Les couches de RNA dans l'encodeur sont traditionnellement des couches d'un réseau neuronal convolutif (RNC), comme le montre la figure 1. Toutefois, les derniers modèles d'AP utilisent des couches de réseau attentionnel dans leur architecture. Ces encodeurs sont appelés transformateurs, et des travaux récents ont commencé à les utiliser pour traiter la classification d'images en raison de leur incidence dans le domaine du traitement du langage naturel. Les vecteurs peuvent être transmis à des modèles de classification, qui peuvent être une série de couches de RNA ou des modèles basés sur le regroupement, tels que le classificateur k plus proches voisins (KPPV). La littérature actuelle sur l'apprentissage auto-supervisé utilise les classificateurs KPPV pour regrouper les images, car ils ne requièrent que le nombre de groupes comme argument et n'ont pas besoin d'étiquettes.
Augmentation des données :
Les étiquettes d'images ne sont pas fournies aux encodeurs entraînés de manière auto-supervisée. Par conséquent, la capacité de représentation des encodeurs doit être améliorée uniquement à partir des images qu'ils reçoivent. En tant qu'être humain, nous pouvons regarder des objets sous différents angles et perspectives afin d'en comprendre la forme et le contour. De même, les images augmentées aident les encodeurs en offrant des perspectives différentes des images d'apprentissage originales. Ces perspectives d'image peuvent être développées en appliquant à l'image des stratégies telles que le redimensionnement, le rognage et le décalage de couleurs, comme le montre la figure 2. Les images augmentées améliorent la capacité de l'encodeur à extraire des caractéristiques riches d'une image en apprenant à partir d'une section ou d'une parcelle de l'image et en appliquant ces connaissances pour prédire d'autres sections de l'image Note de bas de page 4.

Figure 2 : Stratégies d’augmentation pouvant être utilisées pour entraîner des encodeurs dans un format auto-supervisé. Ces stratégies d’augmentation sont appliquées de manière aléatoire à l’image lors de l’entraînement des encodeurs.
L’image comporte quatre façons de représenter une image pour l’entraînement de type apprentissage auto supervisé. Une image d’un chien corgi est utilisée comme échantillon dans ce cas. La première façon est l’image originale en elle-même sans filtres supplémentaires sur l’image. La deuxième façon est de retourner l’image horizontalement. Ainsi, l’image du chien corgi qui regardait à l’origine vers sa gauche regarde maintenant vers sa droite. La troisième façon est de redimensionner l’image et de recadrer une section de l’image qui comporte l’objet d’intérêt. Dans ce cas, le chien corgi est au centre de l’image, donc une version recadrée de la tête du chien et d’une partie de son corps est utilisée comme image augmentée. La dernière façon est de changer l’échelle de couleur de l’image, soit l’augmentation par décalage de couleur. La couleur du chien qui était de couleur dorée dans l’image d’origine prendra une couleur bleue dans le cadre de cette stratégie d’augmentation.
Architecture de réseau siamois :
De nombreuses méthodes d'apprentissage auto-supervisé utilisent l'architecture de réseau siamois pour entraîner les encodeurs. Comme le montre la figure 3, un réseau siamois est constitué de deux encodeurs qui peuvent partager la même architecture (p. ex. ResNet-50 pour les deux encodeurs) Note de bas de page 3. Les deux encodeurs reçoivent des lots d'images pendant l'entraînement (lots d'entraînement). Les deux encodeurs recevront une image de chaque lot, mais avec des stratégies d'augmentation différentes appliquées aux images qu'ils reçoivent. Comme le montre la figure 3, nous considérons les deux encodeurs E1 et E2. Dans ce réseau, l'image (x) est augmentée par deux stratégies différentes pour générer x1 et x2, qui sont respectivement transmises à E1 et E2. Chaque encodeur fournit alors une représentation vectorielle de l'image, qui peut être utilisée pour mesurer la similarité et calculer la perte.
Pendant la phase d'apprentissage, les poids entre les deux encodeurs sont mis à jour à l'aide d'un processus appelé distillation des connaissances. Il s'agit d'un format d'entraînement étudiant-enseignant. L'encodeur étudiant est entraîné en ligne et subit une propagation vers l'avant et vers l'arrière, tandis que les poids de l'encodeur enseignant sont mis à jour à intervalles réguliers à l'aide de poids stables de l'étudiant avec des techniques telles que la moyenne mobile exponentielle Note de bas de page 3.
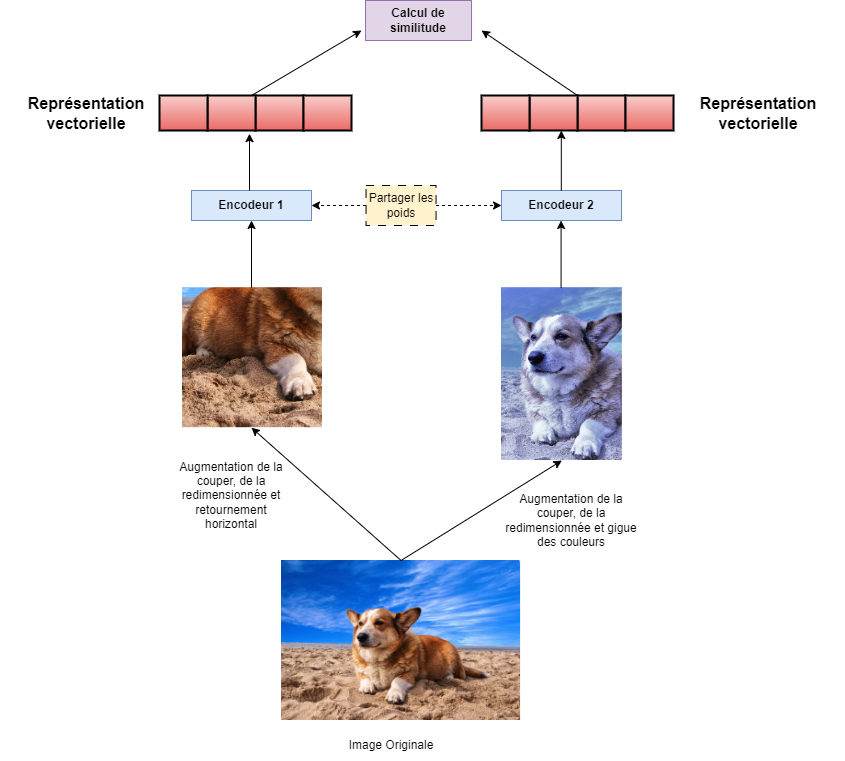
Figure 3. Un réseau siamois composé de deux encodeurs entraînés en parallèle pour générer des représentations d’images, garantissant que les représentations d’images de la même classe sont semblables les unes aux autres.
L’image décrit la configuration d’un réseau siamois, une technique populaire pour l’entraînement des encodeurs auto-supervisés. Le réseau siamois est composé de deux encodeurs qui auront la même architecture de réseau neuronal. Les deux encodeurs sont entraînés en parallèle. L’image montre qu’une image d’un chien corgi est envoyée aux deux encodeurs. Un encodeur se comporte comme un élève qui s’appelle E1 tandis que l’autre encodeur se comporte comme un enseignant qui s’appelle E2. E1 reçoit l’image d’un chien corgi augmentée par recadrage et retournement horizontal. E2 reçoit une image du même chien corgi que E1 augmentée par recadrage et décalage de couleurs. L’image montre également que les deux encodeurs partagent leurs connaissances au moyen de poids à intervalles réguliers pendant la phase d’entraînement. Les deux encodeurs fournissent des représentations vectorielles comme sortie finale. Une cote de similitude est calculée pour mesurer si le E1 a pu apprendre au moyen des poids stables du E2 et améliorer ses connaissances de représentation.
Méthodes d'apprentissage auto-supervisé contrasté et non contrasté :
Toutes les méthodes d'apprentissage auto-supervisé disponibles utilisent ces composantes, avec quelques modifications supplémentaires pour améliorer leur performance respective. Ces méthodes d'apprentissage peuvent être regroupées en deux catégories :

Figure 4. Paire positive et négative de morceaux d’image.
L’image montre comment on peut créer des paires positives et négatives d’images. L’image est divisée en deux parties. Dans la première partie, il y a deux images différentes de chiens corgi. L’augmentation par recadrage est utilisée pour extraire les sections importantes comme le visage et le corps des chiens et pour créer deux nouvelles images. Les nouvelles images augmentées par recadrage des deux images de chiens corgi peuvent maintenant être considérées comme une paire positive comme le montre l’image. Dans la deuxième partie de cette image, un exemple d’une paire négative d’images est montré. Contrairement à la première partie, il y a une image originale d’un chien corgi et une autre d’un chat. Une fois que l’augmentation par recadrage est effectuée sur ces images, nous voyons deux nouvelles images des originaux. L’un a le visage du chat tandis que l’autre a le visage du chien corgi. Ces nouvelles images seront considérées comme une paire négative d’images.
Méthodes d'apprentissage contrasté
Ces méthodes nécessitent des paires positives et négatives de chaque image pour entraîner et améliorer la capacité de représentation des encodeurs. Elles utilisent la perte contrastive pour entraîner les encodeurs dans un réseau siamois avec distillation des connaissances. Comme le montre la figure 4, une paire positive est une image augmentée ou un morceau de la même classe que l'image originale. Une paire négative serait une image ou un morceau d'une autre image appartenant à une classe différente. La fonction sous-jacente de toutes les méthodes d'apprentissage contrasté est d'aider les encodeurs à générer des vecteurs de sorte que les vecteurs des paires positives soient plus proches les uns des autres et que ceux des paires négatives soient plus éloignés les uns des autres dans l'espace latent.
De nombreuses méthodes populaires, telles que SimCLR Note de bas de page 4 et MoCo Note de bas de page 5, sont fondées sur ce principe et fonctionnent efficacement sur de grands ensembles de données d'objets naturels comme ImageNet. Des paires d'images positives et négatives sont fournies dans chaque lot d'entraînement afin d'éviter que les encodeurs ne s'effondrent dans un état où ils produisent des vecteurs que d'une seule classe. Cependant, pour entraîner les encodeurs avec des paires d'images négatives, ces méthodes reposent sur des lots de grande taille (jusqu'à 4 096 images dans un lot d'entraînement). En outre, de nombreux ensembles de données, contrairement à ImageNet, ne comportent pas de multiples images par classe, ce qui rend la génération de paires négatives dans chaque lot difficile, voire impossible. Par conséquent, la recherche récente s'oriente vers des méthodes d'apprentissage non contrasté.
Méthodes d'apprentissage non contrasté
Des méthodes telles que DINO Note de bas de page 3, BYOL Note de bas de page 6 et BarlowTwins Note de bas de page 7 entraînent les encodeurs dans un format auto-supervisé sans qu'il soit nécessaire de distinguer les images en paires positives et négatives dans leurs lots d'entraînement. Les méthodes telles que DINO continuent d'utiliser le réseau siamois dans un format étudiant-enseignant et s'appuient sur une forte augmentation des données. Cependant, elles améliorent les méthodes d'apprentissage contrasté en y apportant quelques améliorations :
- Les morceaux d'images fournissent une vue locale de l'image à l'étudiant et une vue globale de l'image à l'encodeur enseignant Note de bas de page 3.
- Une couche de prédiction est ajoutée à l'encodeur étudiant pour générer une sortie fondée sur la probabilité Note de bas de page 3. Cette couche est utilisée uniquement pendant l'entraînement.
- Au lieu de calculer la perte de contraste entre les paires d'images, la sortie des encodeurs est utilisée pour calculer un type de classification de perte, tel que l'entropie croisée ou la perte L2, pour déterminer si les vecteurs de sortie des encodeurs étudiants et enseignants sont semblables ou non Note de bas de page 3, Note de bas de page 6, Note de bas de page 7, Note de bas de page 8.
- Recours à la méthode de moyenne mobile exponentielle ou à toute autre méthode de moyenne mobile pour mettre à jour les poids du réseau enseignant à partir des poids en ligne du réseau étudiant, tout en évitant la rétropropagation sur le réseau enseignant Note de bas de page 3, Note de bas de page 6, Note de bas de page 7, Note de bas de page 8.
Contrairement aux méthodes d'apprentissage contrasté, ces méthodes ne nécessitent pas de lots de grande taille pour l'entraînement et n'ont pas besoin de temps système supplémentaire pour garantir la présence de paires négatives dans chaque lot d'entraînement. En outre, les modèles d'apprentissage profond (AP) tels que le transformeur de vision, qui ont la capacité d'apprendre à partir de la vue locale d'une image et de prédire d'autres vues locales semblables tout en tenant compte de la vue globale, ont remplacé les encodeurs de RNC classiques. Ces modèles ont permis d'améliorer les méthodes d'apprentissage non contrasté pour dépasser les précisions de classification d'images des techniques d'apprentissage supervisé.
Conclusion
L'apprentissage auto-supervisé est un processus d'entraînement qui peut aider les modèles d'AP à s'entraîner plus efficacement que les méthodes populaires d'apprentissage supervisé sans le recours à des étiquettes. Cette efficacité est évidente dans la précision supérieure que les modèles d'AP ont atteinte sur des ensembles de données populaires tels que ImageNet lorsqu'ils sont entraînés dans une configuration auto-supervisée comparativement à une configuration supervisée. En outre, l'apprentissage auto-supervisé élimine la nécessité d'étiqueter les images avant l'entraînement, ce qui constitue un avantage supplémentaire. L'avenir est prometteur pour les solutions qui adoptent ce type d'apprentissage pour les tâches de classification d'images, car un nombre croissant de recherches sont menées sur ses applications dans des domaines qui n'impliquent pas d'objets naturels, tels que les images médicales et documentaires.
Rencontre avec le scientifique des données

Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Jeudi, le 15 juin
De 13 00 h à 16 00 h, HE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données.
À bientôt!
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
- Date de modification :