
Modélisation thématique et modélisation thématique dynamique : Une revue technique
Par : Loic Muhirwa, Statistique Canada
Dans le sous-domaine de l'apprentissage automatique du traitement du langage naturel (TLN), un modèle thématique (topic modeling) est un type de modèle non supervisé servant à découvrir des sujets abstraits dans un corpus. La modélisation thématique peut être considérée comme une sorte de regroupement flou (soft clustering) de documents au sein d'un corpus. La modélisation thématique dynamique désigne l'introduction d'une dimension temporelle dans une analyse de modélisation thématique. L'aspect dynamique de la modélisation thématique est un domaine de recherche en pleine croissance et auquel de nombreuses applications ont recours, y compris l'analyse sémantique de séries chronologiques, la classification sans supervision de documents et la détection d'événements. Dans le cas de la détection d'événements, si la structure sémantique d'un corpus représente un phénomène du monde réel, un changement significatif dans cette structure sémantique peut être utilisé pour représenter et détecter des événements du monde réel. À cette fin, l'article présente les aspects techniques d'une nouvelle méthode bayésienne de modélisation thématique dynamique dans le contexte des problèmes de détection d'événements.
Dans le contexte d'une preuve de concept, un système de modélisation thématique dynamique a été conçu, mis en œuvre et déployé à l'aide de la Base canadienne de données des coroners et des médecins légistes (BCDCML), une nouvelle base de données élaborée à Statistique Canada en collaboration avec les 13 coroners en chef provinciaux et territoriaux, les médecins légistes en chef et l'Agence de la santé publique du Canada. La BCDCML contient des renseignements normalisés sur les circonstances des décès déclarés aux coroners et aux médecins légistes au Canada. En particulier, la BCDCML contient des données non structurées sous forme de variables en texte libre, appelées textes narratifs, qui fournissent des renseignements détaillés sur les circonstances entourant les décès déclarés. L'ensemble des textes narratifs forme un corpus (une collection de documents) adapté à l'exploration de texte, ce qui soulève la question suivante : les techniques d'apprentissage automatique peuvent-elles servir à découvrir des structures sémantiques utiles et nouvelles ? Et dans l'affirmative, peut-on analyser ces structures sémantiques dynamiquement (dans le temps) pour détecter les textes narratifs émergeants sur les décès?
Les premiers résultats sont prometteurs. L'étape suivante comporte deux volets, à savoir : premièrement, régler plus précisément le système et la construction de la détection d'événements et, deuxièmement, étant donné que ce système servira à aider les analystes à réaliser des études et des recherches sur la BCDCML, les renseignements qui en découleront devront être interprétables par l'être humain. Le présent article donne un aperçu technique de la méthodologie sur laquelle repose la modélisation thématique, explique la base de l'allocation de Dirichlet latente et introduit une dimension temporelle dans l'analyse de la modélisation thématique. Un futur article présentera l'application de ces techniques à la BCDCML.
Allocation de Dirichlet latente
L'allocation de Dirichlet latente (ou LDA pour Latent Dirichlet Allocation)Note de bas de page 1 est un exemple de modèle thématique couramment utilisé par la communauté de l'apprentissage automatique. En raison des performances des modèles de LDA, on en retrouve plusieurs implantations en production dans des langages populaires de script orientés données comme PythonNote de bas de page 2. L'allocation de Dirichlet latente a d'abord été introduite comme une généralisation de l'analyse sémantique latente probabiliste (PLSA pour Probabilistic Latent Semantic Analysis)Note de bas de page 3 présentant d'importantes améliorations, dont l'une était entièrement générativeNote de bas de page 4.
Le modèle
La LDA est considérée comme un modèle génératif, car la distribution conjointe (produit de la vraisemblance par la loi a priori) est explicitement définie, ce qui permet de générer des documents simplement en échantillonnant à partir de la distribution. Les hypothèses du modèle sont clairement démontrées par l’examen du processus générateur qui décrit la façon dont chaque mot d’un document donné est généré.
En termes formels, supposons que sont respectivement le nombre de sujets et la taille de l’ensemble de notre vocabulaire. Le vocabulaire fait référence à l’ensemble de tous les termes utilisés pour produire les documents. De plus, supposons que et sont des vecteurs représentant des distributions discrètes sur les sujets et le vocabulaire respectivement. Dans une LDA, un document est représenté par une distribution de sujets distincte et un sujet est représenté par une distribution de mots distincte. Soit un vecteur one-hot représentant un mot particulier dans le vocabulaire et un vecteur one-hot représentant un sujet particulier.
Les notations et peuvent servir à décrire le processus génératif qui génère un mot dans un document en échantillonnant à partir d'une distribution de sujets et d’une distribution de mots. La LDA suppose que ces distributions sont tirées de distributions de Dirichlet, à savoir et , où et sont les paramètres de l’absence de densité. Ensuite, au moyen de ces distributions, on tire d’abord un sujet , puis à partir de ce sujet, on tire un mot . En d’autres termes, les mots d’un document sont échantillonnés à partir d’une distribution de mots régie par une distribution de sujets fixe représentant ce document. La Figure 1 démontre ce processus de génération en notation de plaque graphique, pour un corpus de taille avec des documents de taille fixe . Bien qu’on suppose généralement que la taille du document provienne d’un processus de Poisson indépendant, pour le moment, à des fins de simplification de la notation, on suppose sans perte de généralité que les documents sont de taille fixe.
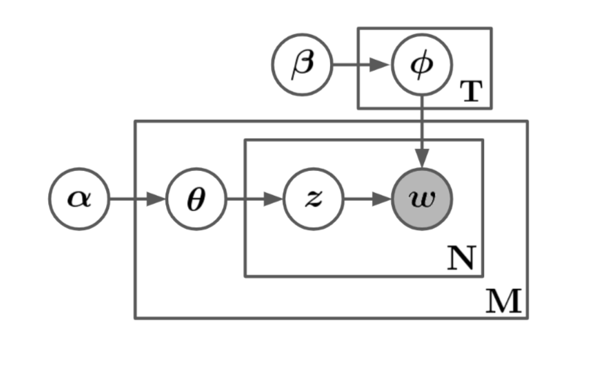
Description de la figure 1 - Notation de plaque du processus génératif. Les cases sont des « plaques » représentant des répliques et les nœuds ombrés sont observés.
Illustration du processus génératif de LDA en notation de plaque. Le diagramme est composé d’un graphique acyclique dirigé, où les nœuds représentent des variables et les arêtes représentent des dépendances variables. Les nœuds externes du graphique dirigé sont les hyperparamètres du modèle et ces nœuds n’ont pas d’arêtes intérieures, ce qui signifie qu’ils ne dépendent d’aucun autre paramètre du modèle. À partir des hyperparamètres, les arêtes conduisent aux autres variables jusqu’à ce qu’elles atteignent un nœud final, représentant un mot. À une extrémité, le nœud d’hyperparamètres de sujet mène à un nœud de distribution de mot, qui mène finalement au nœud de mot. À partir d’une autre extrémité, l’hyperparamètre du document, mène à un nœud de distribution de sujet, qui mène à un nœud d’affectation de mot-sujet, puis au nœud de mot. Ce nœud de mot est ombré et il s'agit du seul nœud ombré. L’ombrage indique que le nœud en question représente une variable observée, ce qui signifie que tous les autres nœuds du graphique ne sont pas observés. Certains nœuds sont contenus dans une case rectangulaire comportant une variable dans son coin inférieur droit. Les cases représentent les répétitions, et la variable en bas à droite représente la taille de la répétition. Le nœud de distribution de mot est contenu dans une case avec un nombre variable de répétitions, . L’affectation mot-sujet et les nœuds de mot sont contenus dans une case avec un nombre variable de répétitions, . Cette dernière est ensuite contenue dans une case plus grande qui comprend le nœud de distribution de sujet avec un nombre variable de répétitions, . Puisque l’affectation mot-sujet et les nœuds de mot sont contenus dans deux cases, ces deux variables ont un nombre de répétitions égal au produit de la variable se trouvant dans le coin inférieur droit des deux cases, en l'occurrence fois .
| Variable | Description |
|---|---|
| Un ensemble représentant tous les documents bruts, c'est-à-dire le corpus | |
| Nombre de sujets | |
| Nombre de mots dans le vocabulaire | |
| Distribution de sujets représentant le document; il s'agit d'un vecteur dense | |
| Nombre de mots dans le document | |
| Distribution de mots représentant le sujet; il s'agit d'un vecteur dense | |
| Affectation de sujet pour le mot dans le document; il s'agit d'un vecteur one-hot | |
| Affectation du vocabulaire pour le mot dans le document; il s'agit d'un vecteur one-hot | |
| Paramètre de l'absence de densité de Dirichlet pour les sujets | |
| Paramètre de l'absence de densité de Dirichlet pour les documents |
Soit un ensemble représentant l’ensemble de toutes les affectations de sujets, il s'agit d’un ensemble de taille et soit un ensemble représentant l’ensemble de toutes les distributions de sujets (documents) et enfin, soit une matrice aléatoire représentant l’ensemble de toutes les distributions de mots (sujets), c.-à-d. . Il s’ensuit que si la entrée d’un sujet donné, par exemple est 1, alors :
Équation 1 :
D'après la notation ci-dessus, la distribution conjointe peut être définie comme suit :
Équation 2 :
Étant donné que l’une des hypothèses du modèle est que les distributions de sujets sont conditionnellement indépendantes par rapprt à β, la forme suivante est équivalente :
Équation 3 :
Maintenant que le modèle est spécifié, le processus de génération peut sembler plus clair en pseudo-code. D’après la distribution conjointe, le processus génératif se déroule comme suit :
Étant donné : V, T,
pour effectuer
fin
pour effectuer
pour effectuer
fin
fin
Notons que T, le nombre de sujets, est fixe et que le fait d’être fixe est en fait une hypothèse et une exigence du modèle; cela implique également, dans le contexte bayésien, que T est un paramètre du modèle et non pas une variable latente. Cette différence est loin d’être négligeable, comme le montre la section sur l’inférence.
Il est important de distinguer l’allocation de Dirichlet latente d’un simple modèle de groupement Dirichlet-multinomial. Un modèle de groupement Dirichlet-multinomial comporterait un modèle à deux niveaux dans lequel on échantillonne un Dirichlet une fois pour un corpus, une variable de groupement multinomiale est sélectionnée une fois pour chaque document dans le corpus, et un ensemble de mots est sélectionné pour le document, conditionnel à la variable de groupement. Comme dans de nombreux modèles de groupement, un tel modèle restreint le document à être associé à un seul sujet. En revanche, la LDA comporte trois niveaux et, notamment, le nœud de sujet est échantillonné de façon répétée dans le document. Selon ce modèle, les documents peuvent être associés à plusieurs sujetsNote de bas de page 1.
Inférence
L’inférence avec la LDA équivaut à une ingénierie inverse du processus génératif décrit dans la section précédente. Quand le processus génératif passe d’un sujet à un mot, l’inférence a posteriori ira donc d’un mot à un sujet. Avec la LDA, nous supposons que et sont des variables latentes plutôt que des paramètres de modèle. Cette différence a des conséquences drastiques sur la façon dont les quantités d’intérêt sont inférées, celles-ci étant les distributions et . En revanche, si et étaient modélisées comme des paramètres, on pourrait utiliser l’algorithme espérance-maximisation (EM) pour trouver l’estimation du maximum de vraisemblance (EMV). Après la convergence de l’algorithme EM, on récupère les paramètres appris pour atteindre l’objectif consistant à trouver les sujets abstraits dans le corpus. L'algorithme EM fournit des estimations ponctuelles du paramètre du modèle en marginalisant les variables latentes. Le problème est que les quantités d’intérêt sont marginalisées et que l’estimation ponctuelle ne serait pas fidèle à la méthode de l’inférence bayésienne. Pour une véritable inférence bayésienne, l’accès à la distribution a posteriori des variables latentes et serait nécessaire. Ensuite, cette distribution a posteriori est examinée et quelques difficultés de calcul qui contribueront à motiver une approche d’inférence seront soulignées.
La distribution a posteriori est de la forme suivante :
Équation 4 :
Penchons-nous de plus près sur le dénominateur :
Équation 5 :
L’équation (5) est connue sous le nom de preuve et agit comme une constante de normalisation. Pour calculer la preuve, il faut calculer une intégrale de grande dimension sur la probabilité conjointe. Comme le montre l’équation (5), le couplage de et les rend inséparables dans la sommation et, par conséquent, cette intégrale est au moins exponentielle dans , ce qui la rend insoluble. L'insolvabilité de l’intégrale de la preuve est un problème courant de l’inférence bayésienne, qu’on appelle problème d’inférenceNote de bas de page 1. L’inférence et la mise en œuvre de la LDA diffèrent dans la façon dont elles résolvent ce problème.
Inférence variationnelle
Dans l'apprentissage automatique moderne, l'inférence (bayésienne) variationnelle (IV) sert le plus souvent à déduire la distribution conditionnelle sur les variables latentes compte tenu des observations et des paramètres. C'est aussi ce qu'on appelle la distribution a posteriori sur les variables latentes (équation (2)). À un niveau élevé, l'IV est simple : l'objectif est d'obtenir une approximation de la distribution a posteriori insoluble avec une distribution qui provient d'une famille de distributions tractables. Cette famille de distributions tractables est ce qu'on appelle les distributions variationnelles (à partir du calcul variationnel). Une fois que la famille de distributions est spécifiée, on obtient une approximation de la distribution a posteriori en trouvant la distribution variationnelle qui optimise une certaine mesure entre elle-même et la distribution a posteriori. Une des mesures servant couramment à mesurer la similarité entre deux distributions est la divergence de Kullback-Leibler qui est définie comme suit :
Équation 6 :
où et sont les distributions de probabilité sur le même support. Dans l’article original sur l’allocation de Dirichlet latenteNote de bas de page 1, les auteurs proposent une famille de distributions ayant la forme suivante :
Équation 7 :
où , et sont des paramètres variationnels libres. Cette famille de distributions est obtenue par découplage de et (ce couplage est ce qui a mené à l’insolvabilité), ce qui rend les variables latentes conditionnellement indépendantes sur les paramètres variationnels. Ainsi, l’inférence approximative est réduite au problème d’optimisation déterministe suivant :
Équation 8 :
où est la distribution a posteriori d’intérêt et dont l’approximation finale est obtenue par :
Équation 9 :
Dans le contexte du problème, le problème d’optimisation de l’équation (8) est mal posé puisqu’il nécessite et que l’approximation de est le problème d’inférence initial. Il est facile de démontrer ce qui suit :
Équation 10 :
Équation 11 :
est appelée ELBO (Evidence Lower Bound, borne inférieure de la preuve) et bien qu’elle dépende de la vraisemblance, elle n'a pas de p(·) et est donc tractable. Par conséquent, le problème d’optimisation de l’équation (8) équivaut au problème d’optimisation suivant :
Équation 12 :
Ainsi, l’inférence dans la LDA maximise l’ELBO sur une famille de distributions tractables pour donner une approximation de la distribution a posteriori. En général, on met en œuvre une méthode d’optimisation stochastique pour surmonter la complexité du calcul, en particulier la méthode de descente par coordonnée stochastique. De plus amples détails sur l’analyse de l’IV sont fournis dansNote de bas de page 1, les sections 5.2, 5.3 et 5.4 deNote de bas de page 1 et la section 4 deNote de bas de page 4.
Modélisation thématique dynamique
La modélisation thématique dynamique désigne l’introduction d’une dimension temporelle dans une analyse de modélisation thématique. En particulier, la modélisation thématique dynamique dans le cadre du présent projet fait référence à l’étude de l’évolution dans le temps de sujets donnés. Le projet vise à analyser des sujets fixes sur un intervalle de temps donné. Étant donné que les documents provenant de la BCDCML ont une estampille temporelle naturelle, à savoir la date du décès (DDD), ils constituent un moyen canonique de diviser l’ensemble de données complet en plusieurs corpus couvrant chacun un intervalle de temps. Une fois les données divisées, on peut appliquer la LDA à chaque corpus. Il est ensuite possible d’analyser l’évolution de chaque sujet dans le temps.
L’un des défis de cette méthode dynamique réside dans la mise en correspondance de sujets à partir de deux fenêtres de temps adjacentes. En raison de la nature stochastique du problème d’optimisation à l’étape de l’inférence, chaque fois qu’une instance de la LDA est exécutée, l’ordre des sujets abstraits qui en résultent est aléatoire. Plus précisément, si l'on a deux fenêtres de temps adjacentes indexées par et et un sujet fixe indexé par , comment peut-on s’assurer que le sujet au temps donné correspond au sujet au temps ? Pour répondre à cette question, il est possible de construire des lois a priori de sujets pour le temps en utilisant les paramètres de sujets appris lors du temps . Pour mieux comprendre le mécanisme, le terme « a priori » renvoie aux paramètres des distributions a priori et non aux distributions elles-mêmes; de même, il désigne les quantités qui sont proportionnelles à l’emplacement (espérance) des distributions antérieures. Dans cette configuration, la loi a priori de sujet peut être représentée par une matrice de sorte que l’entrée soit la loi a priori du terme étant donné le sujet. Notons que sans information a priori ou connaissance de domaine sur , le paramètre de probabilité du terme étant donné le sujet, une loi a priori uniforme serait imposée en faisant de une constante et serait donc représentée minimalement par un scalaire. Chaque fois que est constant, la loi de Dirichlet qui en résulte est symétrique et on dit qu’elle a une loi a priori symétrique, qui est la constante. Supposons qu’au temps nous avons appris la matrice des paramètres de sujet , avant d’apprendre nous imposerons une loi a priori sous la forme suivante :
Équation 13 :
La matrice sert de loi a priori informative pour , ce qui implique essentiellement qu’on suppose que les distributions de sujets provenant de fenêtres de temps adjacentes sont semblables en un sens. sert de loi a priori uniforme non informative, cette matrice lisse essentiellement l’information pointue de . Parce que le vocabulaire évolue également au fil du temps, ce qui signifie que certains mots sont ajoutés et d'autres supprimés du vocabulaire à mesure que le modèle voit de nouveaux corpus, il faut en tenir compte dans la loi a priori. Il est nécessaire de s’assurer que tout sujet non encore appris est susceptible d’inclure un nouveau mot même si, dans les fenêtres temporelles précédentes, ce même sujet avait une probabilité de 0 d’inclure ce mot. L’introduction de avec une valeur non nulle de η garantit que tout nouveau mot a une probabilité non nulle d’être repris par un sujet en évolution.
On dit qu’une distribution de Dirichlet avec une valeur non constante de a une loi a priori non symétrique. En général, la littérature recommande de ne pas utiliser de lois a priori non symétriquesNote de bas de page 5 puisqu’il est habituellement déraisonnable de supposer qu’il y a suffisamment d’information a priori sur les distributions de mots dans des sujets inconnus. Notre cas est différent. Il est raisonnable de supposer que des corpus de temps adjacents ont en commun un certain niveau d’information sur la distribution de mots et, pour mieux justifier cette loi a priori, un chevauchement entre les corpus adjacents sera imposé. Supposons que et sont des corpus respectivement au temps et , essentiellement, la condition suivante sera imposée :
Équation 14 :
La proportion de chevauchement est contrôlée par un hyperparamètre défini au préalable. Soulignons que le chevauchement renforce l’hypothèse selon laquelle est une loi a priori raisonnable pour . Cependant, on pourrait toujours raisonnablement supposer que cette loi a priori est raisonnable, même si les corpus ne se chevauchaient pas, puisque et seraient assez proches dans le temps et auraient alors en commun un certain niveau d’information pour ce qui est de la distribution de mots.
- Date de modification :