
Utiliser la science des données et les outils infonuagiques pour évaluer les répercussions économiques de la COVID-19
Par : Razieh Pourhasan, Statistique Canada
Alors que les effets de la COVID-19 sur l’économie continuent de se faire ressentir à un rythme effréné, il est plus important que jamais pour les Canadiens et les entreprises de disposer de renseignements fiables pour comprendre ces changements. Une équipe de scientifiques des données et d’analystes de Statistique Canada travaille fort pour répondre à ce besoin d’information en automatisant l’extraction des données textuelles de sources variées et l’analyse de ces données en temps quasi réel. Ces sources comprennent le système InfoMedia du gouvernement du Canada, des sites Web d’entreprises et éventuellement des comptes Twitter et LinkedIn d’entreprises. Cependant, l’inclusion des médias sociaux dépendra de l’obtention des permissions nécessaires. Le projet est axé sur les répercussions économiques d’événements sociaux ou politiques d’importance, comme la pandémie de COVID-19, sur la vie des Canadiens.

La propagation rapide du virus et l’impact de la pandémie ont créé la nécessité d’obtenir des données rapidement et de haute qualité à un rythme sans précédent pour informer les Canadiens et appuyer la prise de décisions. Les événements reliés à la COVID-19 ont complètement changé la façon dont le travail est mené et ont établi des attentes différentes dans une nouvelle réalité numérique. La rapidité est plus importante que jamais et Statistique Canada utilise des outils reliés à la science des données pour réagir rapidement à l’évolution de la situation et mieux comprendre les répercussions sur notre pays et notre économie.
Pour produire différents types de produits analytiques à l’intention des décideurs et des Canadiens, les analystes s’intéressent à différents types de renseignements. Par exemple, les analystes qui réalisent des analyses sur la COVID-19 cherchent à relever des nouvelles pertinentes pour répondre à des questions comme celles qui suivent :
- Quelles sont les entreprises les plus concernées ou touchées par la pandémie?
- Ces entreprises ont-elles fermé des succursales?
- Ces entreprises participent-elles à la production d’équipement de protection individuelle?
- Combien de pertes d’emploi ont été signalées?
Le projet comporte deux phases selon la source d’extraction et la permission donnée pour le moissonnage du Web. Au cours de la première phase, l’extraction se limite au système InfoMedia du gouvernement du Canada et aux sites de nouvelles de quelques entreprises. Au cours de la deuxième phase, l’extraction inclura éventuellement un plus grand nombre d’entreprises canadiennes ainsi que des données issues de Twitter et de LinkedIn, à la condition d’obtenir l’approbation d’accéder à ces sources de données pour pouvoir les utiliser.
Répondre aux besoins des analystes
Afin de mieux répondre aux divers besoins des analystes dans leur effort pour fournir des renseignements actuels aux Canadiens, l’équipe de la science des données optimise la méthode d’extraction et les analyses en temps réel dans le but d’inclure le plus de renseignements possible de différentes sources. L’équipe établit le déroulement de ses travaux en utilisant une infrastructure robuste qui est accessible sur la plateforme de Statistique Canada depuis le nuage Azure de Microsoft. Ensuite, Kubeflow est utilisé pour créer des carnets Jupyter en scripts python, Elasticsearch (ES) est utilisé pour l’absorption et l’intégration des données, et des tableaux de bord Kibana sont utilisés pour concevoir des tableaux de bord et des représentations visuelles afin de présenter les résultats aux analystes.
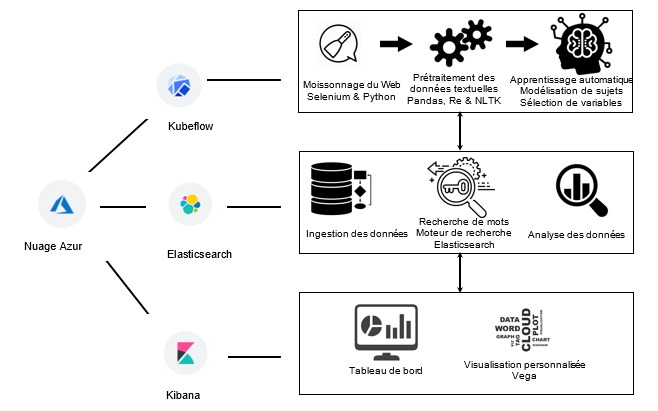
Description - nuage Azure
Diagramme montrant les icônes du nuage Azur, Kubeflow, Elasticsearch et Kibana.
- Les étapes de Kubeflow sont : moissonnage du Web, Selenium et Python; prétraitement des données textuelles, Pandas, Re et NLTK; apprentissage automatique, modélisation de sujets et sélection de variables.
- Les étapes d’Elasticsearch sont : Ingestion des données; Recherche de mots, moteur de recherche Elasticsearch; Analyse des données.
- Les étapes de Kibana sont : Tableau de bord; Visualisation personnalisée, Vega.
L’étape suivante consiste à créer un pipeline Kubeflow pour extraire automatiquement des données textuelles en procédant au moissonnage des sites de nouvelles des entreprises à l’aide de Selenium et de modules Python, pour effectuer le prétraitement et le nettoyage des données au moyen de Pandas, de Regular Expression et de Natural Language Toolkit, et enfin, pour absorber les données extraites dans ES aux fins d’analyse. Les scientifiques des données réalisent ensuite l’analyse exploratoire des données, ce qui peut être aussi simple que le compte de mots ou la recherche de mots clés à l’aide du moteur de recherche ES ou aussi complexe qu’un algorithme d’apprentissage automatique comme dans le cas de la modélisation de sujets pour le regroupement de documents appliquée au moyen du code Python intégré.
Les résultats des analyses sont par la suite visualisés dans le tableau de bord Kibana au moyen de diagrammes à barres ou à secteurs, de nuages de mots, de nuages de points ou de graphiques combinatoires personnalisés à l’aide de l’interface Vega dans Kibana. Ces tableaux de bord représentent les produits finaux qui sont présentés aux analystes, soit en leur fournissant un lien URL auquel ils peuvent accéder par l’intermédiaire de leur compte infonuagique, soit en définissant un avis par courriel afin qu’ils puissent recevoir les produits souhaités dans leur boîte de réception.
Regard vers l’avenir
À l’heure actuelle, le projet est axé sur les données d’entreprise, mais il pourrait être élargi pour englober d’autres sources d’information tirées du Web. Il pourrait aussi être adapté pour inclure différentes unités d’analyse, comme les produits, l’emploi, les données financières, les comportements sociaux et les comportements influant sur la santé, les sentiments, etc.
Un analyste consacre généralement de 5 à 30 heures par mois pour effectuer des recherches sur le Web, trouver des renseignements utiles, les extraire et les compiler. Ce projet pourrait réduire cette durée de trois fois ou même plus, ce qui en fait une option très efficace pour les analystes.
À l’aide de l’extraction de données automatisée, de l’application d’algorithmes d’apprentissage automatique et du modèle de prestation infonuagique, il est en général plus facile de réaliser des analyses en temps réel et de fournir rapidement les résultats aux décideurs. Les entreprises canadiennes et les Canadiens profitent de tous de ces renseignements actuels, tandis que notre société cherche à mieux comprendre les répercussions de la COVID-19 sur notre économie et notre société.
Membres de l’équipe
Scientifiques des données : Chatana Mandava, Razieh Pourhasan, Christian Ritter.
Analystes : Tracey Capuano, Lisa Fleury, David Glanville, François Lavoie, Joanne Moreau, Anthony Peluso.
- Date de modification :