4 Étude de la courbe de consommation moyenne d'électricité
Hervé Cardot, Alain Dessertaine, Camelia Goga, Étienne Josserand et Pauline Lardin
Précédent | Suivant
Nous disposons d'une population composée de courbes de
consommation électrique mesurées toutes les demi-heures pendant deux semaines
consécutives. Nous avons points de mesure
pour chaque semaine et nous souhaitons estimer la courbe moyenne de
consommation de la deuxième semaine. On note la consommation
d'électricité de l'individu mesurée la deuxième
semaine et sa consommation au
cours de la première semaine. La consommation moyenne de chaque individu durant la première
semaine, qui est une
information simple et peu coûteuse à transmettre, sera utilisée comme
information auxiliaire. Cette variable (réelle) qui est connue pour tous les
éléments de la population
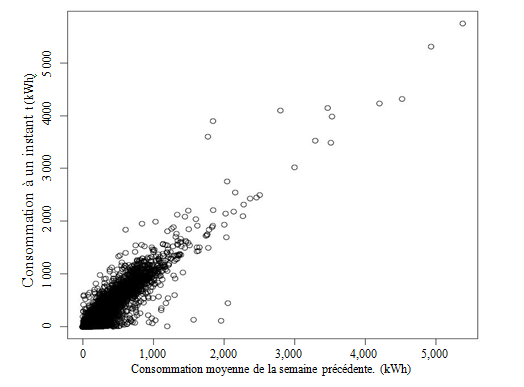
est fortement liée à la courbe de consommation courante. On note sur la figure 4.1
que la consommation courante en chaque est quasiment
proportionnelle à la consommation moyenne de la semaine précédente.
Description de la figure 4.1
Figure 4.1 : Représentation de la consommation à un
instant en fonction de la consommation moyenne de la
semaine précédente.
4.1 Description des stratégies utilisées
Nous considérons des échantillons de taille fixe obtenus selon
différents plans de sondage. Les stratégies présentées sont répétées fois afin d'évaluer
et de comparer leurs performances.
1. ÉASSR et estimateur de Horvitz-Thompson.
La mise en œuvre de ce plan est simple, l'estimateur de
Horvitz-Thompson de la courbe moyenne est donné par (2.6) et l'estimateur de sa
covariance par (2.7).
2. Sondage stratifié STRAT et estimateur de Horvitz-Thompson.
Le plan stratifié est très efficace si les strates sont
homogènes par rapport à la variable d'intérêt. Dans ce travail, nous avons
utilisé l'algorithme des -means afin de constituer les strates et nous avons
considéré strates. Une
première stratification (STRAT 1) a été effectuée à partir de la classification
des trajectoires discrétisées de la première
semaine. Une seconde stratification, qui utilise uniquement l'information agrégée
a également été considérée. Elle
est notée STRAT 2.
Les tailles des strates obtenues en
utilisant les deux stratifications ainsi que les tailles optimales, selon (2.5),
des échantillons à sélectionner dans chaque strate sont données dans les
tableaux 4.1 et 4.2. Dans les deux cas, les strates sont numérotées en ordre
croissant par rapport à la consommation moyenne de chaque strate. Plus
précisement, la strate 1 correspond aux faibles consommateurs et la strate 10
est composée des 10 plus gros consommateurs d'électricité. Notons que la
première stratification, qui nécessite de connaître la consommation
d'électricité à chaque instant de mesure exige plus d'information que la deuxième stratification. La
courbe moyenne est construite en utilisant (2.3) et sa covariance est estimée
par (2.4).
Tableau 4.1
STRAT 1 : stratification à partir des courbes. Les strates sont construites à partir des courbes de la semaine 1. L'allocation optimale est calculée à partir des courbes de la semaine 1.
Sommaire du tableau
Le tableau montre la stratification à partir des courbes. Les données sont présentées selon h (titres de rangée) et 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 (figurant comme en-tête de colonne).
|
h
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
N
h
|
3 866
|
4 769
|
623
|
2 690
|
664
|
1 251
|
806
|
328
|
62
|
10
|
|
n
h
|
212
|
345
|
87
|
242
|
117
|
179
|
172
|
101
|
35
|
10
|
Tableau 4.2
STRAT 2 : stratification à partir de la consommation moyenne L'allocation optimale est calculée à partir de la consommation moyenne de la semaine 1.
Sommaire du tableau
Le tableau montre la stratification à partir de la consommation moyenne . Les données sont présentées selon h (titres de rangée) et 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 (figurant comme en-tête de colonne).
|
h
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
N
h
|
3 257
|
4 236
|
3 139
|
1 937
|
1 189
|
731
|
415
|
125
|
30
|
10
|
|
n
h
|
260
|
293
|
248
|
204
|
159
|
133
|
111
|
56
|
26
|
10
|
3. Sondage et estimateur de Horvitz-Thompson.
Nous avons utilisé l'algorithme du cube proposé par Deville
et Tillé (2004) et Chauvet et Tillé (2006) où les probabilités d'inclusion sont
proportionnelles à . Afin d'avoir un plan de sondage
proche de l'entropie maximale, un tri aléatoire de la population est effectué
avant le tirage de l'échantillon La covariance de
l'estimateur de la moyenne est estimée à l'aide de la formule (2.9).
L'algorithme du cube est disponible sous R dans le package sampling,
fonction samplecube et une macro SAS est disponible sur le site web de
l'INSEE (Institut National de Statistique et des Etudes Economiques).
4. ÉASSR et estimateur MA.
L'estimateur assisté par le
modèle est construit à l'aide
de l'information auxiliaire donnée par où est la consommation
moyenne de la semaine précédente. Dans ces conditions, est la somme sur
toute la population des valeurs
estimées par le modèle (voir
formule (2.13)). La covariance de l'estimateur de la moyenne est estimée à
l'aide de la formule (2.15).
4.2 Erreur d'estimation de la courbe moyenne
L'erreur d'estimation de
la courbe moyenne aux instants est évaluée selon
le critère
Les résultats sont présentés dans le tableau 4.3 pour simulations
(réplications). Ils montrent clairement que, pour cette étude, la prise en
compte de la consommation totale de la semaine précédente permet d'améliorer de
manière importante la précision de l'estimation de la moyenne par rapport à
l'échantillonnage aléatoire simple sans remise en divisant l'erreur quadratique
moyenne par 5. Parmi les
différentes stratégies, les plus performantes semblent être celles qui prennent
en compte l'information auxiliaire via les probabilités d'inclusion (STRAT, et systématique proportionnel à la taille).
Tableau 4.3
Erreur quadratique d'estimation de la moyenne avec réplications.
Sommaire du tableau
Le tableau montre l'erreur quadratique d'estimation de la moyenne avec réplications.. Les données sont présentées selon stratégie (titres de rangée) et moyenne, 1erquartile, médiane, 3eme (figurant comme en-tête de colonne).
|
Stratégie
|
moyenne
|
1
er quartile
|
médiane
|
3
emequartile
|
|
ÉASSR
|
40,53
|
10,82
|
22,16
|
51,09
|
|
STRAT (1)
|
5,78
|
3,68
|
5,08
|
7,07
|
|
STRAT (2)
|
6,49
|
4,03
|
5,48
|
7,88
|
|
|
7,06
|
3,99
|
5,52
|
8,16
|
|
systématique
|
6,73
|
3,85
|
5,20
|
8,07
|
|
MA
|
8,29
|
5,24
|
7,14
|
10,06
|
4.3 Taux de couverture et largeur des bandes de confiance
La construction des bandes de confiance de niveau nécessite le calcul
des quantiles d'ordre du supremum de
processus gaussiens.
Pour ne pas privilégier une méthode de construction de
bande de confiance par rapport à l'autre, nous avons appliqué les deux
algorithmes sur un même échantillon et nous avons considéré le même nombre de processus. Ce
nombre varie d'un
estimateur à l'autre en raison des temps de calculs nécessaires pour les
approches de type bootstrap (voir Section 4.4).
Description de la figure 4.2
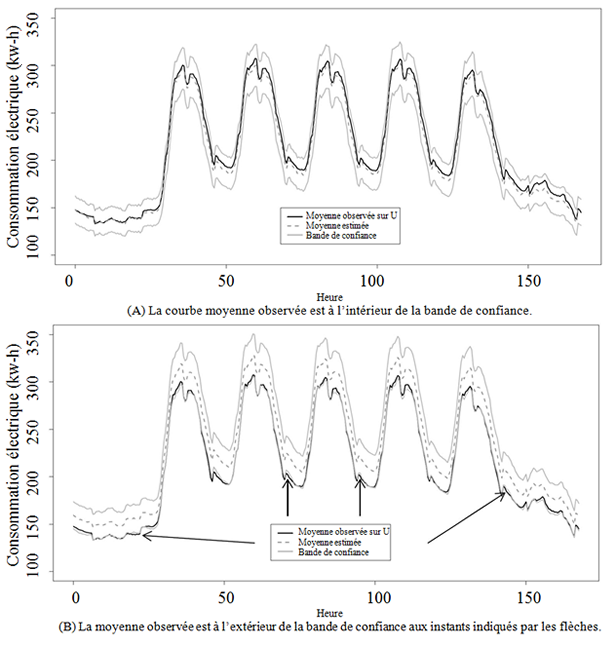
Figure 4.2 : Exemples de
bande de confiance.
Le taux de couverture empirique est la proportion de fois,
parmi les réplications, où la
vraie courbe moyenne se trouve, pour
tous les instants à l'intérieur de la
bande de confiance construite à partir d'une estimation . Nous avons représenté sur la figure
4.2 deux exemples de bandes de confiance (courbes grises continues) construites
à partir des courbes estimées (courbes grises pointillées). Sur la figure 4.2(A),
nous constatons que la vraie courbe moyenne sur la population (courbe noir
continue) est à l'intérieur de la bande de confiance à chaque instant. À
l'opposé, sur la figure 4.2(B), nous constatons que la courbe moyenne de la
population est en général surestimée et qu'il existe quelques instants
(indiqués par les flèches) où la courbe observée sort de la bande de confiance.
Les taux de couverture empiriques sont présentés dans le tableau 4.4.
Les deux méthodes de construction des bandes de confiance
donnent des taux de couverture similaires et assez proches des taux nominaux
souhaités (95 % et 99 %). Les résultats semblent cependant légèrement moins
satisfaisants pour les plans et pour l'approche MA pour lesquels la variance de
l'estimateur est complexe et plus difficile à estimer précisément.
Tableau 4.4
Taux de couverture empirique (en %), pour réplications.
Sommaire du tableau
Le tableau montre le taux de couverture empirique (en %), pour réplications. Les données sont présentées selon méthodes (titres de rangée) et nombre M de processus, bootstrap, processus Gaussien (figurant comme en-tête de colonne).
|
Méthodes
|
Nombre M de processus
|
Bootstrap
|
Processus Gaussien
|
|
|
|
|
|
|
ÉASSR
|
5 000
|
94,95
|
98,85
|
94,80
|
98,70
|
|
STRAT (1)
|
5 000
|
93,92
|
98,34
|
94,09
|
98,43
|
|
STRAT (2)
|
5 000
|
94,3
|
98,45
|
94
|
98,55
|
|
|
1 000
|
94,73
|
98,77
|
93,87
|
98,61
|
|
MA
|
5 000
|
94,3
|
98,5
|
92,85
|
98,15
|
Un autre indicateur
intéressant est la largeur moyenne de la bande de confiance,
dont les valeurs sont présentées dans le tableau 4.5. Les deux
méthodes fournissent des bandes de confiance dont les largeurs sont similaires.
On note également que l'utilisation de la variable auxiliaire permet de
diminuer sensiblement la largeur moyenne des bandes, celle-ci étant divisée par
deux si on considère un des plans stratifiés plutôt qu'un plan d'ÉASSR.
Description de la figure 4.3
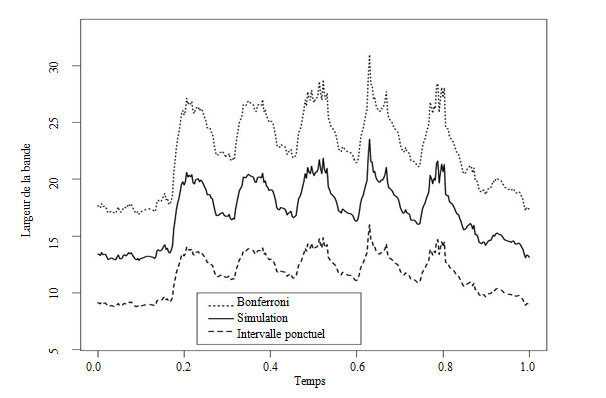
Figure 4.3 : Échantillonnage aléatoire simple sans
remise. Largeur des bandes de confiance ponctuelles, globales par simulations
de processus et avec Bonferroni ().
Description de la figure 4.4
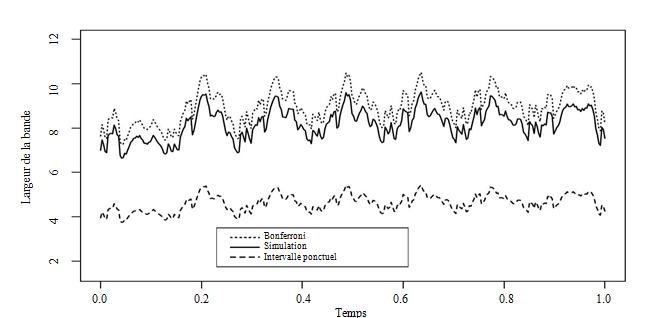
Figure 4.4 : Sondage stratifié (STRAT 1). Largeur des
bandes de confiance ponctuelles, globales par simulations de processus et avec
Bonferroni (avec ).
Les figures 4.3 et 4.4 présentent les largeurs des bandes
de confiance pour un niveau , pour chaque instant, selon qu'elles soient ponctuelles (
), estimées par simulations de processus gaussiens ou bien
obtenues en considérant l'approche basée sur l'inégalité de Bonferroni
appliquée en chaque point de mesure. On a alors, dans ce dernier cas, , le quantile d'ordre d'une loi . Les bandes obtenues par
Bonferroni sont conservatives et considèrent en quelque sorte le pire des cas
en termes d'information, celui de l'indépendance des intervalles ponctuels. On
peut remarquer que l'approche par simulation permet de réduire sensiblement la
largeur moyenne des bandes en comparaison avec Bonferroni lorsque le plan ne
permet pas de prendre en compte toute l'information temporelle des données (figure
4.3). À l'opposé, pour le plan stratifié (figure 4.4) qui permet une estimation
précise de la courbe moyenne, la bande de confiance construite par simulation
est proche de celle de Bonferroni, ce qui s'interprète intuitivement comme le
fait que quasiment toute l'information a été capturée par le plan de sondage.
Tableau 4.5
Largeur moyenne des bandes de confiance, pour réplications.
Sommaire du tableau
Le tableau montre la largeur moyenne des bandes de confiance, pour réplications.. Les données sont présentées selon méthodes (titres de rangée) et nombre M de processus, bootstrap, processus Gaussien (figurant comme en-tête de colonne).
|
Méthodes
|
Nombre M de processus
|
Bootstrap
|
Processus Gaussien
|
|
|
|
|
|
|
ÉASSR
|
5 000
|
35,98
|
43,35
|
35,99
|
43,19
|
|
STRAT (1)
|
5 000
|
16,64 |
18,92
|
16,62
|
18,88
|
|
STRAT (2)
|
5 000
|
17,58
|
19,99
|
17,55
|
19,94
|
|
|
1 000
|
17,85
|
20,31
|
17,62
|
19,93
|
|
MA
|
5 000
|
19,88
|
22,65 |
19,75
|
22,44
|
4.4 Temps de calcul
Les temps de calcul avec la méthode par bootstrap sont
largement supérieurs, de l'ordre d'un facteur de 1 à 1000, à ceux de la méthode
par simulations de processus gaussiens (voir tableau 4.6). Cette différence
importante provient du fait que les méthodes de bootstrap nécessitent de
répéter tout le processus d'estimation pour chaque échantillon bootstrapé :
construction de la population fictive, tirage d'un nouvel échantillon, calcul
de l'estimateur. On remarque également que les plans qui font intervenir de
l'information auxiliaire sont moins rapides que le plan d'ÉASSR même si
utilisés individuellement leur temps de calcul reste tout à fait raisonnable.
Tableau 4.6
Temps d'exécution d'une simulation en secondes pour réplications. Les stratégies ÉASSR, MA et STRAT ont été programmés avec R et avec SAS.
Sommaire du tableau
Le tableau montre Temps d'exécution d'une simulation en secondes pour réplications. Les stratégies ÉASSR, MA et STRAT ont été programmés avec R et avec SAS. Les données sont présentées selon stratégie (titres de rangée) et bootstrap, processus gaussiens (figurant comme en-tête de colonne).
|
Stratégie
|
Bootstrap
|
Processus gaussiens
|
|
ÉASSR
|
1 170,6
|
1,0
|
|
STRAT
|
1 839,5
|
1,4
|
|
|
5 020,0
|
7,3 |
|
MA
|
3 156
|
1,4
|
Précédent | Suivant
