
Publication
Rural and Small Town Canada Analysis Bulletin
Domestic Water Use: The Relevance of Rurality in Quantity Used and Perceived Quality
Other information
Conclusions

Archived Content
Information identified as archived is provided for reference, research or recordkeeping purposes. It is not subject to the Government of Canada Web Standards and has not been altered or updated since it was archived. Please "contact us" to request a format other than those available.
This bulletin focuses on the effect of "rurality" in determining the quantity of water used, at the municipal level, and on water quality perception of households, as measured by a household's water treatment choices. The baseline data presented in this bulletin indicates that, on average, water used for domestic purposes is higher in rural municipalities than in urban ones, but that rural households who drink tap water are less likely to treat their water than urban households. Urban households are also more reliant on municipal water systems than rural households. Though municipal water systems are the main source of water for the majority of rural households, private wells remain an important source of water as well.
The results of this analysis suggest that economic incentives are more relevant than location characteristics in determining average water use. Areas with higher shares of water metering use less water than areas with lower shares of water metering. The effect of population density and regional type are less clear, although they are to some extent consistent with the expectation that areas that are more rural would have higher water use compared to urban residents because of the tendency to have larger gardens that need summer watering.
In contrast, locational characteristics are significant determinants of the choice of treating tap water for domestic consumption while the source of water (municipal or private) is not. The location effect on treatment choices remains strong even after controlling for socio-economic characteristics of the household. However, some socio-economic characteristics also have a significant impact on the likelihood of a household treating its water.
Rural households appear more confident in the quality of their water supply, compared to their urban counterparts. Almost 60% of rural households do not treat their water, whereas fewer than 50% of CMA households do not treat their water. Finally, the type of water consumed (primarily tap or a combination of tap and bottle water) does not appear to be a factor in the treatment decision.
There are several implications for municipal water strategies. First, the results suggest that economic incentives might play a significant role for municipal water management. Even though the introduction of water metering systems cannot be viewed as a substitute for infrastructure policies, this could remain an important measure in containing the quantity of water used.
Second, assuming that the choice of water treatment reflects quality perception, municipal water sources are not perceived to have higher quality as compared to private sources. Household characteristics, such as higher education and income level, explain in part the choice of treating the water, but there appears to be a location specific factor that should be further investigated. With the notable exception of Montreal, urban households are more sensitive to water quality issues, as reflected by the decision to treat tap water for domestic consumption.
Appendix Table A.1
Population and communities included in the Municipal Water and Wastewater Survey
Appendix Table A.2
Primary type of drinking water consumed by households, Canada, 2006
Appendix Table A.3
Descriptive statistics: Factors associated with domestic water use from municipal water systems, Canada, 2004
Appendix Table A.4
Regression results: Variables in regression of factors associated with domestic water use across municipal water systems
Appendix Table A.5
Descriptive statistics: Variables in logistic regression of factors associated with households which treat drinking water
Appendix Table A.6
Logistic regression results: Variables in logistic regression of factors associated with households which treat drinking water
Appendix Table A.7
Predicted percent of households which treat their drinking water, showing results for selected case households
Box 3 Methodology
A standard linear regression model was used to investigate the effect of water metering on total water use (see Appendix A.3 and Appendix A.4). The model is based on Municipal Water and Wastewater Survey (MWWS) 2004 data. The dependent variable is the average daily domestic flow. The explanatory variables include metering and location variables. Metering is measured by three dummy variables: high metering; some metering; and low metering. The "low metering" category was used as the reference group and therefore dropped from the model. The results were shown as relative to this reference group. Location variables include population density, Census Metropolitan Area (CMA), Census Agglomeration (CA), strong Metropolitan Influenced Zone (MIZ), moderate MIZ, and weak/no MIZ. As the reference group, "CMA" was dropped from the model and the results were presented as relative to this group. All variables were dummy variables except for population density (for definitions, please see Box 2).
Two alternative specifications were used. In the first specification, the average daily domestic flow is determined by metering variables and population density only. In the second specification, we add also the regional dummies. Each specification was estimated with two samples. The first was the full sample of 963 observations, for which data was available, and the second was an "omitted outliers" sample that excluded the top and bottom 5% of observations. A severe cut-off (removing the bottom 5% and top 5% of observations) was employed in order to assess the sensitivity of the results to unusually high and low water use per capita in the MWWS 2004 dataset.
It should be noted that the analysis conducted with the MWWS 2004 was also replicated with Municipal Water Use (MUD) survey data for 1998 and 2001, for the municipalities for which the same data was available. The results for these previous years are similar to those obtained for 2004, with the main difference being that locational factors (and particularly population density) were even less important in explaining water use levels when 1998 or 2001 data are used. In part, these differences can be explained by the inclusion of some rural communities in the 2004 database and a 2004 usable sample with lower average population density. Results for the MUD 1998 and MUD 2001 estimations are available from the authors upon request.
A logistic regression model was used to explain the household decision to treat drinking water. The dependent variable of this model is the dichotomous choice "treat/do not treat" drinking water, coded as 1 and 0 respectively. The explanatory variables included in the model are family size, age cohorts of household members, highest level of education achieved by any household member, total household income, household's type of water system (municipal or private; private includes surface sources), type of water primarily drunk in the household, municipality type (Box 2), and large urban indicators for Vancouver, Toronto, and Montreal. Each variable is classified as a dummy variable (1 for true, 0 for false) except for family size, where we recorded the number of family members in each of 5 age groups.
The dichotomous nature of treatment choices makes the analysis suitable for qualitative dependent variable modeling (Long and Freese, 2001). Generally, this specification postulates the existence of a latent model, which is continuous in its dependent variable (for instance, willingness to treat the water) but which is not observable in reality. The model for the observable dichotomous outcome is derived from this latent process (see Long and Freese, 2001). Hence, for the logistic regression, which is one form of qualitative dependent variable modeling, the resulting specification is as follows,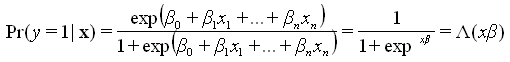
This implies that the probability of observing a positive outcome (y=1), that is, the presence of water treatment, is a function of a set of explanatory variables (x) defined by the logistic cumulative distribution function and Λ(.). In this equation, the β's represent the parameters to be estimated. Thus, using a more explicit notation for the set of explanatory variables included in the model (demographic, socio-economic, source, and location) we can write the model as,
![]()
This equation represents the logistic regression model used in this study, which is estimated by maximum likelihood methods and using the bootstrapping procedure in SPSS.
Bootstrapping. The sampling designs for Statistics Canada's surveys are generally complex. As a result, the variance of an indicator cannot be estimated with simple formulas. Therefore, re-sampling methods are often used to estimate the variance. For the HES 2006 data, we use bootstrapping methods to estimate the variance of a variable and to derive coefficients of variation as quality indicators of the estimates. Similarly we use bootstrapping methods to make inferences in the logistic model. The bootstrap method consists of sub-sampling the initial sample and then estimating the variance using the sub-sample results. For this computation we used bootstrap weights, generated in the survey process. All these estimates were conducted using the BOOTVARE_V30.SPS program (see Estimation of the Variance Using Bootstrap Weights User's Guide for the BOOTVARE_V30.SPS Program (Version 3.0), Statistics Canada, unpublished document).
Interpreting odds ratios. The odds ratio measures the effect of a unit change in the explanatory variable on the odds of observing a positive outcome (water treatment, in our case). The Odds Ratio is calculated as: OR = e ßk, where e is the base of the natural log and βk is the estimated coefficient for the kth variable. The exponential of the coefficient is interpreted as: for a unit change in xk, the odds of observing a positive outcome (treatment) is expected to change by a factor of "exp(ßk)", holding all other variables constant. An odds ratio of 1 indicates the explanatory variable has no effect on the treatment choice. For dummy variables, the odds ratio indicates the change in odds as compared to the omitted category. For example, a household income of $80,000 to 90,000 increases the odds of treating water by a factor of 1.28, as compared to households with income less than $20,000 (Appendix Table A.6).
Predicted probabilities. Generally, the information provided by the logit coefficient on the relationship between explanatory variables and outcomes is limited to the sign and statistical significance. A more meaningful interpretation of this relationship comes from the computation of predicted probabilities (Long and Freese, 2001). The predicted probability is the probability computed using the coefficient estimated by the model for any specific value of the explanatory variables. They are computed as:
![]()
where the β-hat coefficients are those estimated with the logit model and the value of the explanatory variables (Demo, SocioEco, Source and Loc) defines a specific household profile.
Notes
- Note that each CMA and CA typically has many municipalities included within their boundaries (Box 2) and many of these municipalities would have their own water service. In 2001, there were 50 census subdivisions (i.e. incorporated towns and municipalities) within the Montreal CMA, 17 within the Toronto CMA and 18 within the Vancouver CMA.
- Reynaud et al. (2005) performed an analysis of 899 municipalities which pooled data from the 1993, 1995 and 1998 versions of the MUD database. They determined that the estimated change in the quantity of water consumed in response to a different price is somewhat over-estimated if one does not first take into account that the decision to introduce a water pricing structure is influenced by the characteristics of the municipality. Thus, our results may overstate (somewhat) the estimated lower level of water consumption due to the presence of water metering.
- Date modified: