
By David Chiumera, Statistics Canada
In recent years, the field of data science has experienced explosive growth, with businesses across many sectors investing heavily in data-driven solutions to optimize decision-making processes. However, the success of any data science project relies heavily on the quality of the code that underpins it. Writing production-level code is crucial to ensure that data science models and applications can be deployed and maintained effectively, enabling businesses to realize the full value of their investment in data science.
Production-level code refers to code that is designed to meet the needs of the end user, with a focus on scalability, robustness, and maintainability. This contrasts with code that is written purely for experimentation and exploratory purposes, which may not be optimized for production use. Writing production-level code is essential for data science projects as it allows for the efficient deployment of solutions into production environments, where they can be integrated with other systems and used to inform decision-making.
Production-level code has several key benefits for data science projects. Firstly, it ensures that data science solutions can be easily deployed and maintained. Secondly, it reduces the risk of errors, vulnerabilities, and downtime. Lastly, it facilitates collaboration between data scientists and software developers, enabling them to work together more effectively to deliver high-quality solutions. Finally, it promotes code reuse and transparency, allowing data scientists to share their work with others and build on existing code to improve future projects.
Overall, production-level code is an essential component of any successful data science project. By prioritizing the development of high-quality, scalable, and maintainable code, businesses can ensure that their investment in data science delivers maximum value, enabling them to make more informed decisions and gain a competitive edge in today's data-driven economy.
Scope of Data Science and its various applications
The scope of data science is vast, encompassing a broad range of techniques and tools used to extract insights from data. At its core, data science involves the collection, cleaning, and analysis of data to identify patterns and make predictions. Its applications are numerous, ranging from business intelligence and marketing analytics to healthcare and scientific research. Data science is used to solve a wide range of problems, such as predicting consumer behavior, detecting fraud, optimizing operations, and improving healthcare outcomes. As the amount of data generated continues to grow, the scope of data science is expected to expand further, with increasing emphasis on the use of advanced techniques such as machine learning and artificial intelligence.
Proper programming and software engineering practices for Data Scientists
Proper programming and software engineering practices are essential for building robust data science applications that can be deployed and maintained effectively. Robust applications are those that are reliable, scalable, and efficient, with a focus on meeting the needs of the end user. There are several types of programming and software engineering practices that are particularly important in the context of data science, such as version control, automated testing, documentation, security, code optimization, and proper use of design patterns to name a few.
By following proper practices, data scientists can build robust applications that are reliable, scalable, and efficient, with a focus on meeting the needs of the end user. This is critical for ensuring that data science solutions deliver maximum value to businesses and other organizations.
Administrative Data Pre-processing Project (ADP) project and its purpose - an example.
The ADP project is a Field 7 application that required involvement from the Data Science Division to refactor a citizen developed component due to a variety of issues that were negatively impacting its production readiness. Specifically, the codebase used to integrate workflows external to the system was found to be lacking in adherence to established programming practices, leading to a cumbersome and difficult user experience. Moreover, there was a notable absence of meaningful feedback from the program upon failure, making it difficult to diagnose and address issues.
Further exacerbating the problem, the codebase was also found to be lacking in documentation, error logging, and meaningful error messages for users. The codebase was overly coupled, making it difficult to modify or extend the functionality of the program as needed, and there were no unit tests in place to ensure reliability or accuracy. Additionally, the code was overfitted to a single example, which made it challenging to generalize to other use cases, there were also several desired features that were not present to meet the needs of the client.
Given these issues, the ability for the ADP project to pre-process semi-structured data was seriously compromised. The lack of feedback and documentation made it exceedingly difficult for the client to use the integrated workflows effectively, if at all, leading to frustration and inefficiencies. The program outputs were often inconsistent with expectations, and the absence of unit tests meant that reliability and accuracy were not assured. In summary, the ADP project's need for a refactor of the integrated workflows (a.k.a. clean-up or redesign) was multifaceted and involved addressing a range of programming and engineering challenges to ensure a more robust and production-ready application. To accomplish this, we used a Red Green refactoring approach to improve the quality of the product.
Red Green vs Green Red approach to refactoring
Refactoring is the process of restructuring existing code in order to improve its quality, readability, maintainability, and performance. This can involve a variety of activities, including cleaning up code formatting, eliminating code duplication, improving naming conventions, and introducing new abstractions and design patterns.
There are several reasons why refactoring is beneficial. Firstly, it can improve the overall quality of the codebase, making it easier to understand and maintain. This can save time and effort over the long term, especially as codebases become larger and more complex. Additionally, refactoring can improve performance and reduce the risk of bugs or errors, leading to a more reliable and robust application.
One popular approach to refactoring is the "Red Green" approach, as part of the test-driven development process. In the Red Green approach, a failing test case is written before any code is written or refactored. This failing test is then followed by writing the minimum amount of code required to make the test pass, before proceeding to refactor the code to a better state if necessary. In contrast, the Green Red approach is the reverse of this, where the code is written before the test cases are written and run.
The benefits of the Red Green approach include the ability to catch errors early in the development process, leading to fewer bugs and more efficient development cycles. The approach also emphasizes test-driven development, which can lead to more reliable and accurate code. Additionally, it encourages developers to consider the user experience from the outset, ensuring that the codebase is designed with the end user in mind.
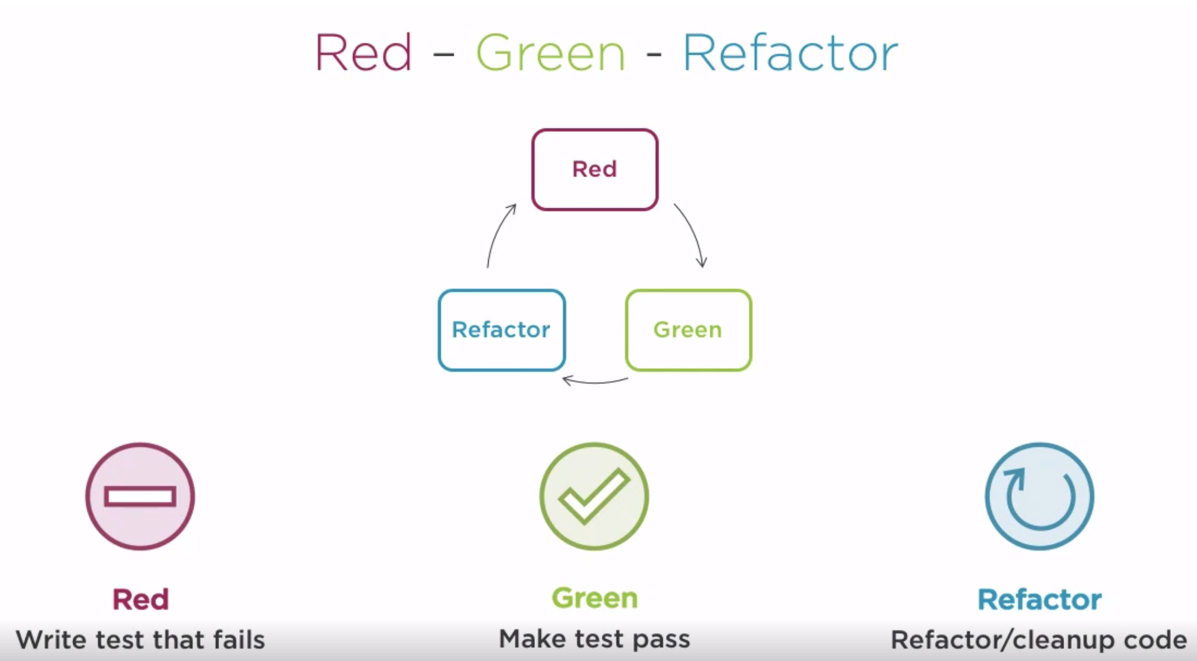
Figure 1: Red Green Refactor
The first step, the Red component, refers to writing a test that fails. From here the code is modified to make the test pass, which refers to the Green component. Lastly, any refactoring that needs to be done to further improve the codebase is done, another test is created and run to test which fails, this is the red component again. The cycle continues indefinitely until the desired state is reached terminating the feedback loop.
In the case of the ADP project, the Red Green approach was applied during the refactoring process. This led to a smooth deployment process, with the application being more reliable, robust, and easier to use. By applying this approach, we were able to address the various programming and engineering challenges facing the project, resulting in a more efficient, effective, stable, and production-ready application.
Standard Practices Often Missing in Data Science Work
While data science has become a critical field in many industries, it is not without its challenges. One of the biggest issues is the lack of standard practices that are often missing in data science work. While there are many standard practices that can improve the quality, maintainability, and reproducibility of data science code, many data scientists overlook them in favor of quick solutions.
This section will cover some of the most important standard practices that are often missing in data science work. These include:
- version control
- testing code (unit, integration, system, acceptance)
- documentation
- code reviews
- ensuring reproducibility
- adhering to style guidelines (i.e. PEP standards)
- using type hints
- writing clear docstrings
- logging errors
- validating data
- writing low-overhead code
- implementing continuous integration and continuous deployment (CI/CD) processes
By following these standard practices, data scientists can improve the quality and reliability of their code, reduce errors and bugs, and make their work more accessible to others.
Documenting Code
Documenting code is crucial for making code understandable and usable by other developers. In data science, this can include documenting data cleaning, feature engineering, model training, and evaluation steps. Without proper documentation, it can be difficult for others to understand what the code does, what assumptions were made, and what trade-offs were considered. It can also make it difficult to reproduce results, which is a fundamental aspect of scientific research as well as building robust and reliable applications.
Writing Clear Docstrings
Docstrings are strings that provide documentation for functions, classes, and modules. They are typically written in a special format that can be easily parsed by tools like Sphinx to generate documentation. Writing clear docstrings can help other developers understand what a function or module does, what arguments it takes, and what it returns. It can also provide examples of how to use the code, which can make it easier for other developers to integrate the code into their own projects.
def complex (real=0.0, imag=0.0):
"""Form a complex number.
Keyword arguments:
real -- the real part (default 0.0)
imag -- the imaginary part (default 0.0)
"""
if imag == 0.0 and real == 0.0:
return compelx_zero
...
Multi-Line Docstring Example
Adhering to Style Guidelines
Style guidelines in code play a crucial role in ensuring readability, maintainability, and consistency across a project. By adhering to these guidelines, developers can enhance collaboration and reduce the risk of errors. Consistent indentation, clear variable naming, concise commenting, and following established conventions are some key elements of effective style guidelines that contribute to producing high-quality, well-organized code. An example of this are PEP (Python Enhancement Proposal) standards, which provide guidelines and best practices for writing Python code. It ensures that code can be understood by other Python developers, which is important in collaborative projects but also for general maintainability. Some PEP standards address naming conventions, code formatting, and how to handle errors and exceptions.
Using Type Hints
Type hints are annotations that indicate the type of a variable or function argument. They are not strictly necessary for Python code to run, but they can improve code readability, maintainability, and reliability. Type hints can help detect errors earlier in the development process and make code easier to understand by other developers. They also provide better interactive development environment (IDE) support and can improve performance by allowing for more efficient memory allocation.
Version Control
Version control is the process of managing changes to code and other files over time. It allows developers to track and revert changes, collaborate on code, and ensure that everyone is working with the same version of the code. In data science, version control is particularly important because experiments can generate large amounts of data and code. By using version control, data scientists can ensure that they can reproduce and compare results across different versions of their code and data. It also provides a way to track and document changes, which can be important for compliance and auditing purposes.
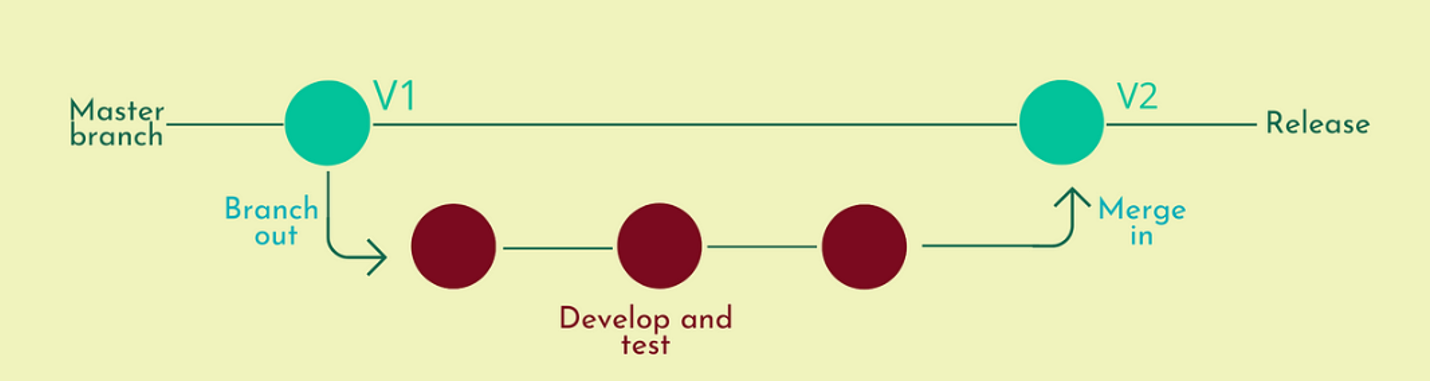
Figure 2: Version Control Illustration
A master branch (V1) is created as the main project. A new branch off shooting V1 is created in order to develop and test until the modifications are ready to be merged with V1, creating V2 of the master branch. V2 is then released.
Testing Code
Testing code is the formal (and sometimes automated) verification of the completeness, quality, and accuracy of code against expected results. Testing code is essential for ensuring that the codebase works as expected and can be relied upon. In data science, testing can include unit tests for functions and classes, integration tests for models and pipelines, and validation tests for datasets. By testing code, data scientists can catch errors and bugs earlier in the development process and ensure that changes to the code do not introduce new problems. This can save time and resources in the long run by reducing the likelihood of unexpected errors and improving the overall quality of the code.
Code Reviews
Code reviews are a process in which other developers review new code and code changes to ensure that they meet quality and style standards, are maintainable, and meet the project requirements. In data science, code reviews can be particularly important because experiments can generate complex code and data, and because data scientists often work independently or in small teams. Code reviews can catch errors, ensure that code adheres to best practices and project requirements, and promote knowledge sharing and collaboration among team members.
Ensuring Reproducibility
Reproducibility is a critical aspect of scientific research and data science. Reproducible results are necessary for verifying and building on previous research, and for ensuring that results are consistent, valid and reliable. In data science, ensuring reproducibility can include documenting code and data, using version control, rigorous testing, and providing detailed instructions for running experiments. By ensuring reproducibility, data scientists can make their results more trustworthy and credible and can increase confidence in their findings.
Logging
Logging refers to the act of keeping a register of events that occur in a computer system. This is important for troubleshooting, information gathering, security, providing audit info, among other reasons. It generally refers to writing messages to a log file. Logging is a crucial part of developing robust and reliable software, including data science applications. Logging errors can help identify issues with the application, which in turn helps to debug and improve it. By logging errors, developers can gain visibility into what went wrong in the application, which can help them diagnose the problem and take corrective action.
Logging also enables developers to track the performance of the application over time, allowing them to identify potential bottlenecks and areas for improvement. This can be particularly important for data science applications that may be dealing with large datasets or complex algorithms.
Overall, logging is an essential practice for developing and maintaining high-quality data science applications.
Writing Low-Overhead Code
When it comes to data science applications, performance is often a key consideration. To ensure that the application is fast and responsive, it's important to write code that is optimized for speed and efficiency.
One way to achieve this is by writing low-overhead code. Low-overhead code is code that uses minimal resources and has a low computational cost. This can help to improve the performance of the application, particularly when dealing with large datasets or complex algorithms.
Writing low-overhead code requires careful consideration of the algorithms and data structures used in the application, as well as attention to detail when it comes to memory usage and processing efficiency. Thought should be given to the system needs and overall architecture and design of a system up front to avoid major design changes down the road.
Additionally, low-overhead code is easily maintained requiring infrequent reviews and updates. This is important as it reduces the cost to maintain systems and allows for more focused development on improvements or new solutions.
Overall, writing low-overhead code is an important practice for data scientists looking to develop fast and responsive applications that can handle large datasets and complex analyses while keeping maintenance costs low.
Data Validation
Data validation is the process of checking that the input data meets certain requirements or standards. Data validation is another important practice in data science as it can help to identify errors or inconsistencies in the data before they impact the analysis or modeling process.
Data validation can take many forms, from checking that the data is in the correct format to verifying that it falls within expected ranges or values. Different types of data validation checks exist, such as type, format, correctness, consistency, and uniqueness. By validating data, data scientists can ensure that their analyses are based on accurate and reliable data, which can improve the accuracy and credibility of their results.
Continuous Integration and Continuous Deployment (CI/CD)
Continuous Integration and Continuous Deployment (CI/CD) is a set of best practices for automating the process of building, testing, and deploying software. CI/CD can help to improve the quality and reliability of data science applications by ensuring that changes are tested thoroughly and deployed quickly and reliably.
CI/CD involves automating the process of building, testing, and deploying software, often using tools and platforms such as Jenkins, GitLab, or GitHub Actions. By automating these processes, developers can ensure that the application is built and tested consistently, and that any errors or issues that block deployment of problematic code are identified and addressed quickly.
CI/CD can also help to improve collaboration among team members, by ensuring that changes are integrated and tested as soon as they are made, rather than waiting for a periodic release cycle.
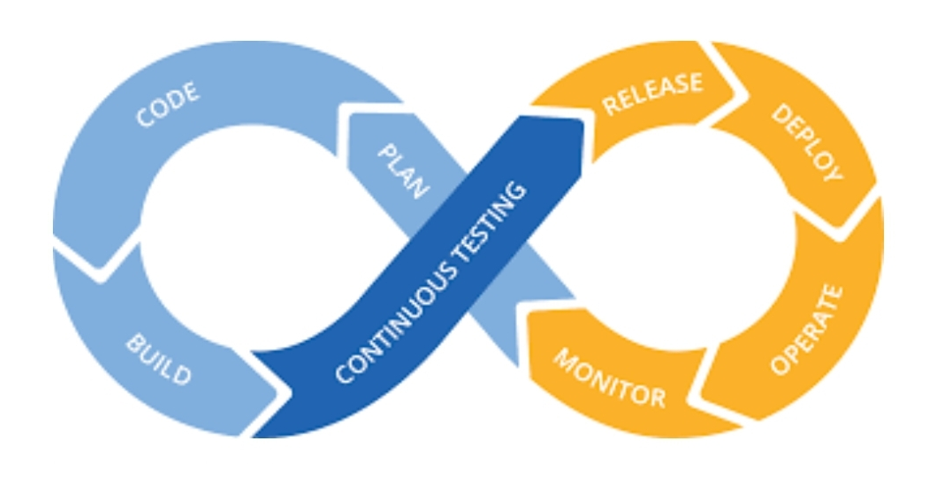
Figure 3: CI/CD
The image illustrates a repeating process represented by the infinity symbol sectioned into 8 unequal parts. Starting from the middle and moving counterclockwise the first of these parts are: plan, code, build, and continuous testing. Then continuing from the last piece, which was in the center, moving clockwise the parts are: release, deploy, operate, and then monitor, before moving back to the original state of plan.
Overall, CI/CD is an important practice for data scientists looking to develop and deploy high-quality data science applications quickly and reliably.
Conclusion
In summary, production-level code is critical for data science projects and applications. Proper programming practices and software engineering principles such as adhering to PEP standards, using type hints, writing clear docstrings, version control, testing code, logging errors, validating data, writing low-overhead code, implementing continuous integration and continuous deployment (CI/CD), and ensuring reproducibility are essential for creating robust, maintainable, and scalable applications.
Not following these practices can result in difficulties such as a lack of documentation, no error logging, no meaningful error messages for users, highly coupled code, overfitted code to a single example, lacking features desired by clients, and failure to provide feedback upon failure. These issues can severely impact production readiness and frustrate users. If a user is frustrated, then productivity will be impacted and result in negative downstream impacts on businesses’ ability to effectively deliver their mandate.
The most practical tip for implementing production-level code is to work together, assign clear responsibilities and deadlines, and understand the importance of each of these concepts. By doing so, it becomes easy to implement these practices in projects and create maintainable and scalable applications.
Meet the Data Scientist

If you have any questions about my article or would like to discuss this further, I invite you to Meet the Data Scientist, an event where authors meet the readers, present their topic and discuss their findings.
Register for the Meet the Data Scientist event. We hope to see you there!
MS Teams – link will be provided to the registrants by email
Subscribe to the Data Science Network for the Federal Public Service newsletter to keep up with the latest data science news.