
Code de niveau de production dans le domaine de la science des données
Par David Chiumera, Statistique Canada
Au cours des dernières années, le domaine de la science des données a connu une croissance explosive puisque les entreprises de nombreux secteurs investissent massivement dans des solutions fondées sur les données afin d’optimiser les processus de prise de décision. Cependant, le succès de tout projet de science des données dépend fortement de la qualité du code en arrière-plan. L’écriture du code de niveau de production est essentielle pour veiller à ce que les modèles et les applications de la science des données soient mis en œuvre et appliqués efficacement, permettant ainsi aux entreprises de réaliser la pleine valeur de leur investissement dans la science des données.
Le code de niveau de production correspond à un code conçu pour satisfaire les besoins d’un utilisateur final, l’accent étant mis sur l’extensibilité, la robustesse et la maintenabilité. Cela contraste avec le code écrit uniquement à des fins d’expérimentation et d’exploration, qui peut ne pas être optimisé en vue d’être utilisé dans l’environnement de production. L’écriture du code de niveau de production est essentielle pour les projets en science des données, car elle permet le déploiement efficace de solutions dans des environnements de production, où ils peuvent être intégrés à d’autres systèmes et utilisés pour éclairer la prise de décision.
Le code de niveau de production présente plusieurs avantages clés pour les projets en science des données. Tout d’abord, il garantit que les solutions de science des données peuvent être facilement déployés et appliqués. Deuxièmement, il réduit le risque d’erreurs, de vulnérabilités et de temps d’arrêt. Enfin, il facilite la collaboration entre les scientifiques des données et les réalisateurs de logiciels, ce qui leur permet de travailler ensemble plus efficacement pour fournir des solutions de haute qualité. Enfin, il favorise la réutilisation du code et la transparence, ce qui permet aux scientifiques des données d’échanger leurs travaux avec d’autres et de s’appuyer sur le code existant pour améliorer les projets à venir.
Dans l’ensemble, le code de niveau de production est un élément essentiel de tout projet de science des données réussi. En accordant la priorité au développement d’un code qui est de haute qualité, évolutif et maintenable, les entreprises peuvent ainsi assurer l’optimisation de leur investissement dans la science des données, prendre des décisions plus éclairées et acquérir un avantage concurrentiel dans l’économie actuelle axée sur les données.
La portée de la science des données et ses différentes applications
Le champ d’application de la science des données est vaste; il englobe un large éventail de techniques et d’outils utilisés pour tirer des connaissances à partir de données. À la base, la science des données comprend la collecte, l’épuration et l’analyse des données afin de cerner les tendances et de faire des prédictions. Ses applications sont nombreuses, allant de l’intelligence économique et de l’analyse marketing jusqu’aux soins de santé et à la recherche scientifique. La science des données est utilisée pour résoudre un large éventail de problèmes, comme la prédiction du comportement des consommateurs, la détection de la fraude, l’optimisation des activités et l’amélioration des résultats des soins de santé. Comme la quantité de données générées continue de croître, le champ d’application de la science des données devrait aussi continuer de s’étendre, en mettant de plus en plus l’accent sur l’utilisation de techniques avancées comme l’apprentissage automatique et l’intelligence artificielle.
Pratiques de programmation et de génie logiciel appropriées pour les scientifiques des données
Des pratiques de programmation et de génie logiciel appropriées sont essentielles pour créer des applications de science des données robustes qui peuvent être déployées et tenues à jour efficacement. Les applications robustes sont celles qui sont fiables, évolutives et efficaces et qui répondent aux besoins de l’utilisateur final. Plusieurs types de pratiques de programmation et de génie logiciel sont particulièrement importants dans le contexte de la science des données, comme le contrôle de version, les tests automatisés, la documentation, la sécurité, l’optimisation du code et l’usage adéquat des modèles de conception, pour n’en citer que quelques-uns.
En suivant les bonnes pratiques, les scientifiques des données peuvent créer des applications robustes qui sont fiables, évolutives et efficaces, tout en mettant l’accent sur les besoins de l’utilisateur final. Cela est essentiel pour garantir que les solutions de la science des données apportent une valeur optimale aux entreprises et aux autres organismes.
Projet de prétraitement des données administratives et son objectif : un exemple
Le projet de prétraitement des données administratives (PDA) est une application du secteur 7 qui nécessite la participation de la Division de la science des données pour réusiner une composante élaborée par un citoyen en raison de divers problèmes qui nuisaient à son état de préparation pour l’environnement de production. Plus précisément, la base du code utilisée pour intégrer les flux de travail externes au système ne respectait pas les pratiques de programmation établies, ce qui se traduisait par une expérience utilisateur lourde et difficile. De plus, on remarque une absence notable de rétroaction pertinente de la part du programme lorsqu’il y a une défaillance, ce qui fait en sorte qu’il est difficile de diagnostiquer et de régler les problèmes.
On a aussi constaté des lacunes dans la base de code en ce qui a trait à la documentation, à la journalisation des erreurs et aux messages d’erreur significatifs pour les utilisateurs, ce qui a encore aggravé le problème. Le couplage dans la base de code était excessif, ce qui fait en sorte qu’il a été difficile de modifier ou d’étendre des fonctions du programme, au besoin. De plus, il n’y avait aucun essai unitaire en place pour assurer la fiabilité et l’exactitude. En outre, le code était trop adapté à un exemple précis. Il était donc difficile de l’appliquer d’une façon générale à d’autres scénarios d’utilisation. Il y avait aussi plusieurs caractéristiques souhaitées qui n’étaient pas présentes pour satisfaire les besoins du client.
Ces problèmes nuisaient grandement à la capacité du projet de PDA d’effectuer le prétraitement de données semi-structurées. L’absence de rétroaction et de documentation a fait en sorte qu’il était extrêmement difficile, voire impossible, pour le client d’utiliser efficacement les flux de travail intégrés, ce qui a donné lieu à de la frustration et à des inefficacités. Souvent, les résultats du programme n’étaient pas conformes aux attentes, et l’absence d’essais unitaires ne permettait pas de garantir la fiabilité et la précision. En résumé, le projet de PDA nécessitait le réusinage des flux de travail intégrés (c.-à-d. l’épuration ou le remaniement du code). Ce processus à multiples facettes comprenait le règlement d’un éventail de problèmes de programmation et d’ingénierie pour que l’application soit plus robuste et prête pour l’environnement de production. Pour ce faire, nous avons utilisé une approche de réusinage « Rouge-Vert » pour améliorer la qualité du produit.
Réusinage à l’aide d’une approche « Rouge-Vert » au lieu d’une approche « Vert-Rouge »
Le réusinage est le processus de remaniement du code existant en vue d’en améliorer la qualité, la lisibilité, la maintenance et le rendement. Cela peut nécessiter diverses activités, y compris l’épuration du formatage du code, l’élimination des codes en double, l’amélioration des conventions de dénomination et l’introduction de nouvelles abstractions et de nouveaux modèles de conception.
Le réusinage est avantageux pour diverses raisons. Premièrement, cette approche peut améliorer la qualité globale de la base de code, ce qui facilite la compréhension et la maintenance. Cela permet d’économiser du temps et des efforts à long terme, surtout lorsque les bases de code deviennent plus grandes et plus complexes. De plus, le réusinage peut améliorer la performance et réduire les risques de bogues et d’erreurs, ce qui se traduit par une application plus fiable et robuste.
Une approche courante de réusinage est l’approche « Rouge-Vert », qui fait partie du processus de développement basé sur les tests. Dans l’approche Rouge-Vert, un scénario d’essai défaillant est écrit avant que le code ne soit écrit ou réusiné. À la suite de ce test défaillant, on procède à l’écriture du code minimal qui serait requis pour obtenir un test réussi, après quoi on réusine le code pour l’améliorer, au besoin. Pour l’approche Vert-Rouge, on procède dans le sens inverse : le code est écrit avant l’écriture et l’exécution des scénarios d’essai.
L’un des avantages de l’approche Rouge-Vert est la capacité de détecter les erreurs dès le début du processus de développement, ce qui permet de réduire le nombre de bogues et d’améliorer l’efficacité des cycles de développement. L’approche met également l’accent sur le développement basé sur les tests, ce qui peut mener à un code plus fiable et précis. De plus, elle incite les développeurs à prendre en compte l’expérience de l’utilisateur dès le départ, en veillant à ce que la base de code soit conçue en ayant l’utilisateur final en tête.
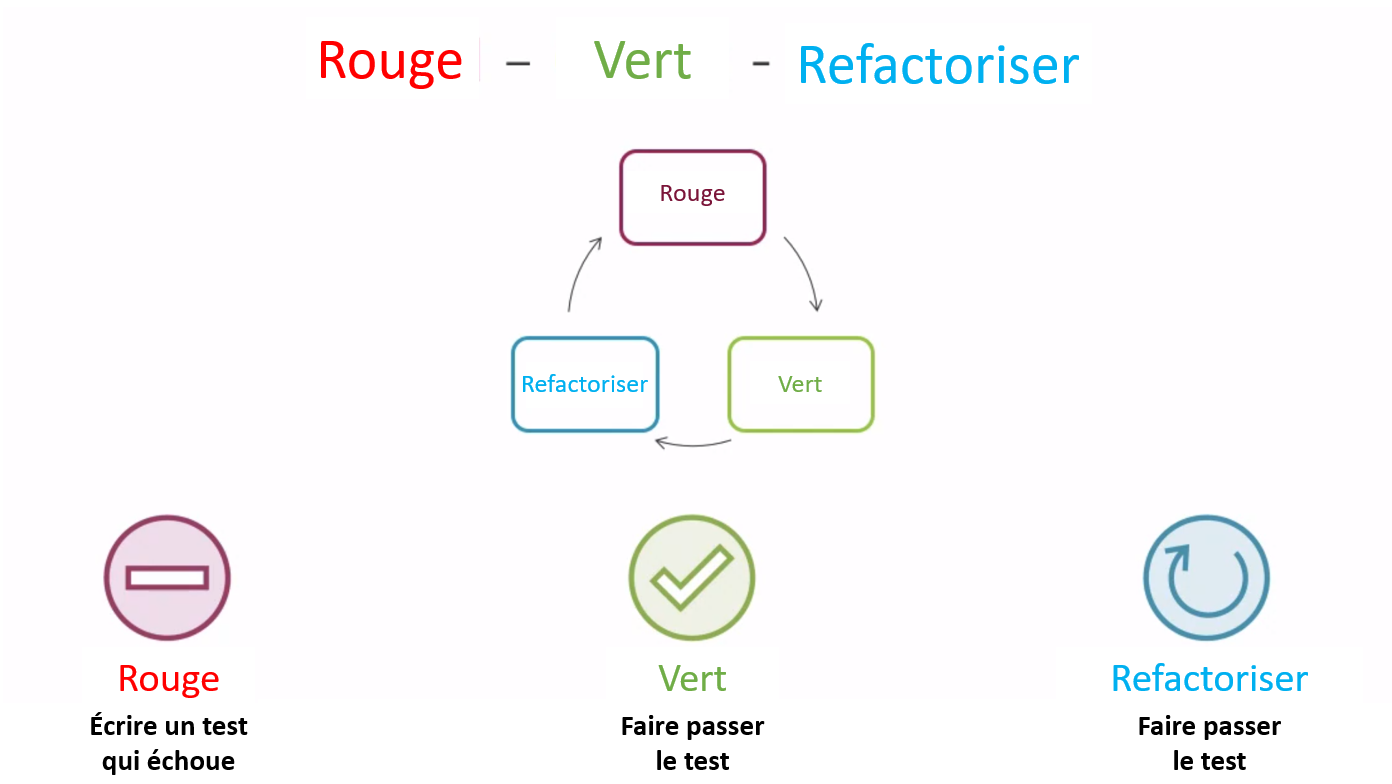
Figure 1 : Rouge-Vert-Réusinage
La première étape, la composante « Rouge », désigne l’écriture d’un test qui échoue. À partir de là, le code est modifié pour obtenir un test réussi, ce qui correspond à la composante « Vert ». Enfin, on procède au réusinage, le cas échéant, pour améliorer davantage la base de code. Un autre test sera ensuite créé et exécuté. Si ce test échoue, le processus retourne à la composante « Rouge ». Le cycle se poursuit indéfiniment jusqu’à ce que l’état souhaité soit atteint, ce qui met fin à la boucle de commande.
Dans le cas du projet de PDA, l’approche Rouge-Vert a été appliquée lors du processus de réusinage. Ceci a mené à un processus de déploiement sans heurt, et l’application était plus fiable, plus robuste et plus facile à utiliser. En appliquant cette approche, nous avons pu relever les différents défis de programmation et d’ingénierie auxquels fait face le projet, ce qui a permis d’obtenir une application plus efficiente, plus efficace, plus stable et prête pour l’environnement de production.
Les pratiques normalisées manquent souvent dans les travaux de science des données
Si la science des données est devenue un domaine essentiel dans de nombreuses industries, elle n’est pas exempte de défis. L’un des principaux problèmes est l’absence de pratiques normalisées qui font souvent défaut dans les travaux de science des données. Bien qu’il existe de nombreuses pratiques normalisées qui peuvent améliorer la qualité, la maintenabilité et la reproductibilité du code de la science des données, de nombreux scientifiques des données les négligent au profit de solutions rapides.
La présente section aborde certaines des pratiques normalisées les plus importantes qui font souvent défaut dans les travaux de science des données. Ces pratiques comprennent :
- le contrôle de la version;
- la vérification du code (unité, intégration, système, acceptation);
- la documentation;
- l’examen du code;
- la garantie de la reproductibilité;
- le respect des règles de style (c’est-à-dire les normes PEP);
- l’utilisation des annotations de type;
- la rédaction de chaînes de documentation claires;
- la journalisation des erreurs;
- la validation de données;
- l’écriture d’un code de faible entretien;
- la mise en œuvre de processus d’intégration continue et de déploiement continu (IC/DC).
En suivant ces pratiques normalisées, les scientifiques des données peuvent améliorer la qualité et la fiabilité de leur code, réduire les erreurs et les bogues et rendre leur travail plus accessible aux autres.
Documenter le code
La documentation du code est essentielle pour rendre le code compréhensible et utilisable par d’autres développeurs. Dans le domaine de la science des données, il peut s’agir de documenter les étapes de nettoyage des données, d’ingénierie des caractéristiques, de formation des modèles et d’évaluation. Sans une documentation appropriée, il peut être difficile pour les autres de comprendre ce que fait le code, les hypothèses formulées et les compromis envisagés. L’absence de documentation appropriée peut également rendre difficile la reproduction des résultats, ce qui est un aspect fondamental de la recherche scientifique et de la création d’applications robustes et fiables.
Rédaction de chaînes de documentation claires
Les chaînes de documentation sont des chaînes qui fournissent de la documentation sur les fonctions, les classes et les modules. Elles sont généralement écrites dans un format spécial qui peut être facilement analysé par des outils comme Sphinx pour générer de la documentation. La rédaction d’une documentation claire peut aider les autres développeurs à comprendre ce que fait une fonction ou un module, les arguments qu’elle prend et ce qu’elle renvoie. Elle peut également fournir des exemples d’utilisation du code, ce qui peut permettre à d’autres développeurs d’intégrer plus facilement le code dans leurs propres projets.
def complex (real=0.0, imag=0.0):
"""Form a complex number.
Keyword arguments:
real -- the real part (default 0.0)
imag -- the imaginary part (default 0.0)
"""
if imag == 0.0 and real == 0.0:
return compelx_zero
...
Exemple de chaîne de documentation multiligne
Respect des règles de style
Les règles de style relatives au code jouent un rôle crucial pour assurer la lisibilité, la maintenabilité et la cohérence d’un projet. En respectant ces règles, les développeurs peuvent améliorer la collaboration et réduire le risque d’erreurs. Une indentation cohérente, des noms de variables clairs, des commentaires concis et le respect des conventions établies sont quelques-uns des éléments clés de règles de style efficaces qui contribuent à la production d’un code de haute qualité et bien organisé. Les normes PEP (proposition d’amélioration de Python), qui fournissent des lignes directrices et de bonnes pratiques pour l’écriture du code Python, en sont un exemple. Elles garantissent que le code peut être compris par d’autres développeurs Python, ce qui est important dans les projets collaboratifs, mais aussi pour la maintenabilité générale. Certaines normes PEP traitent des conventions d’appellation (en anglais seulement), du formatage du code (en anglais seulement), et de la manière de gérer les erreurs et les exceptions (en anglais seulement).
Utilisation des annotations de type
Les annotations de type sont des annotations qui indiquent le type d’une variable ou d’un argument de fonction. Elles ne sont pas strictement nécessaires à l’exécution du code Python, mais elles peuvent améliorer la lisibilité, la maintenabilité et la fiabilité du code. Les annotations de type peuvent aider à détecter les erreurs plus tôt dans le processus de développement et à rendre le code plus facile à comprendre pour les autres développeurs. Elles offrent également une meilleure prise en charge de l’environnement de développement interactif et peuvent améliorer les performances en permettant une allocation plus efficace de la mémoire.
Contrôle de version
Le contrôle de version est le processus de gestion des modifications apportées au code et à d’autres fichiers au fil du temps. Il permet aux développeurs de suivre et d’annuler les modifications, de collaborer sur le code et de s’assurer que tout le monde travaille avec la même version de code. Dans le domaine de la science des données, le contrôle de version est particulièrement important, car les expériences peuvent générer de grandes quantités de données et de codes. En utilisant le contrôle de version, les scientifiques des données peuvent s’assurer qu’ils peuvent reproduire et comparer les résultats entre les différentes versions de leur code et de leurs données. Le contrôle de version permet également de suivre et de documenter les modifications, ce qui peut s’avérer important à des fins de conformité et de vérification.
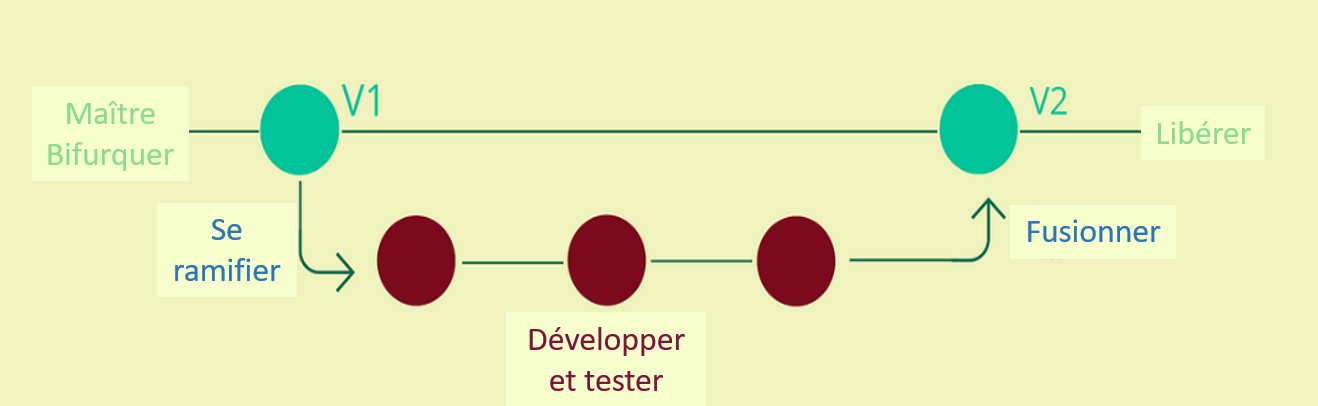
Figure 2 : Illustration du contrôle de version
Une branche principale (V1) est créée en tant que projet principal. Une nouvelle branche dérivée de la V1 est créée afin de développer et de tester jusqu’à ce que les modifications soient prêtes à être fusionnées avec la V1, créant ainsi la V2 de la branche principale. La V2 est ensuite publiée.
Vérification du code
La vérification du code est la vérification formelle (et parfois automatisée) de l’exhaustivité, de la qualité et de l’exactitude du code par rapport aux résultats attendus. Il est essentiel de vérifier le code pour s’assurer que la base de code fonctionne comme prévu et que l’on peut s’y fier. Dans le domaine de la science des données, les tests peuvent inclure des essais unitaires pour les fonctions et les classes, des essais d’intégration pour les modèles et les pipelines, et des essais de validation pour les ensembles de données. En vérifiant le code, les scientifiques des données peuvent détecter les erreurs et les bogues plus tôt dans le processus de développement et s’assurer que les changements apportés au code n’introduisent pas de nouveaux problèmes. Cela permet d’économiser du temps et des ressources à long terme en réduisant la probabilité d’erreurs inattendues et en améliorant la qualité générale du code.
Examens du code
Les examens du code sont un processus au cours duquel d’autres développeurs examinent le nouveau code et les modifications apportées au code pour s’assurer qu’ils respectent les normes de qualité et de style, qu’ils sont maintenables et qu’ils répondent aux exigences du projet. Dans le domaine de la science des données, les examens du code peuvent être particulièrement importants, car les expériences peuvent générer du code et des données complexes, et parce que les scientifiques des données travaillent souvent de manière indépendante ou en petites équipes. Les examens du code permettent de détecter les erreurs, de s’assurer que le code respecte les meilleures pratiques et les exigences du projet et de promouvoir l’échange des connaissances et la collaboration entre les membres de l’équipe.
Garantie de la reproductibilité
La reproductibilité est un aspect essentiel de la recherche scientifique et de la science des données. Des résultats reproductibles sont nécessaires pour vérifier et approfondir les études antérieures et pour garantir que les résultats sont cohérents, valides et fiables. Dans le domaine de la science des données, la reproductibilité peut inclure la documentation du code et des données, l’utilisation du contrôle de version, des essais rigoureux et la fourniture d’instructions détaillées pour l’exécution des expériences. En garantissant la reproductibilité, les scientifiques des données peuvent rendre leurs résultats plus fiables et crédibles et accroître la confiance dans leurs conclusions.
Journalisation
La journalisation consiste à tenir un registre des événements qui se produisent dans un système informatique. Cela est important pour le dépannage, la collecte de renseignements, la sécurité, la fourniture de renseignements sur la vérification, entre autres raisons. Il s’agit généralement de l’écriture de messages dans un fichier journal. La journalisation est un élément essentiel du développement de logiciels robustes et fiables, y compris les applications de science des données. La journalisation des erreurs permet de cerner les problèmes liés à l’application, ce qui permet de la déboguer et de l’améliorer. En journalisant les erreurs, les développeurs peuvent savoir ce qui n’a pas fonctionné dans l’application, ce qui peut les aider à diagnostiquer le problème et à prendre des mesures correctives.
À l’aide de la journalisation, les développeurs peuvent également suivre les performances de l’application au fil du temps, ce qui leur permet de déterminer les goulots d’étranglement potentiels et les domaines à améliorer. Cela peut s’avérer particulièrement important pour les applications de science des données qui pourraient devoir traiter de grands ensembles de données ou d’algorithmes complexes.
Dans l’ensemble, la journalisation est une pratique essentielle pour développer et maintenir des applications de haute qualité de science des données.
Écriture d’un code de faible entretien
Lorsqu’il s’agit d’applications de science des données, la performance est souvent un facteur clé. Pour que l’application soit rapide et réactive, il est important d’écrire un code optimisé pour la vitesse et l’efficacité.
L’un des moyens d’y parvenir est d’écrire un code de faible entretien. Un code de faible entretien est un code qui utilise un minimum de ressources et dont le coût de calcul est faible. Cela peut contribuer à améliorer les performances de l’application, en particulier lorsqu’il s’agit de grands ensembles de données ou d’algorithmes complexes.
L’écriture d’un code de faible entretien nécessite un examen minutieux des algorithmes et des structures de données utilisés dans l’application ainsi qu’une attention particulière à l’utilisation de la mémoire et à l’efficacité du traitement. Il convient de réfléchir aux besoins, à l’architecture globale et à la conception d’un système afin d’éviter des modifications importantes de la conception en cours de route.
En outre, le code de faible entretien est facile à tenir à jour et nécessite des révisions et des mises à jour peu fréquentes. Il s’agit d’un point important, car cela réduit le coût de maintenance des systèmes et permet un développement plus axé sur les améliorations ou les nouvelles solutions.
Dans l’ensemble, l’écriture du code de faible entretien est une pratique importante pour les scientifiques des données qui souhaitent développer des applications rapides et réactives capables de gérer de grands ensembles de données et des analyses complexes tout en maintenant des coûts de maintenance faibles.
Validation des données
La validation des données consiste à vérifier que les données d’entrée répondent à certaines exigences ou normes. La validation des données est une autre pratique importante dans le domaine de la science des données, car elle permet de cerner les erreurs ou les incohérences dans les données avant qu’elles n’aient une incidence sur le processus d’analyse ou de modélisation.
La validation des données peut prendre de nombreuses formes, de la vérification du format correct des données à la vérification qu’elles soient dans les fourchettes ou les valeurs attendues. Il existe différents types de contrôles de validation des données, comme le type, le format, l’exactitude, la cohérence et l’unicité. En validant les données, les scientifiques des données peuvent s’assurer que leurs analyses sont basées sur des données exactes et fiables, ce qui peut améliorer la précision et la crédibilité de leurs résultats.
Intégration continue et déploiement continu
L’intégration continue et le déploiement continu (IC/DC) sont un ensemble de bonnes pratiques visant à automatiser le processus de création, d’essai et de déploiement de logiciels. L’IC/DC peut contribuer à améliorer la qualité et la fiabilité des applications de science des données en garantissant que les changements sont testés de manière approfondie et déployés rapidement et de manière fiable.
L’IC/DC suppose l’automatisation du processus de construction, des essais et de déploiement des logiciels, souvent à l’aide d’outils et de plateformes comme Jenkins, GitLab ou GitHub Actions. En automatisant ces processus, les développeurs peuvent s’assurer que l’application est construite et testée de manière cohérente et que les erreurs ou les problèmes qui empêchent le déploiement du code problématique sont déterminés et traités rapidement.
L’IC/DC peut également contribuer à améliorer la collaboration entre les membres de l’équipe, en garantissant que les changements sont intégrés et testés dès qu’ils sont effectués, plutôt que d’attendre un cycle de publication périodique.
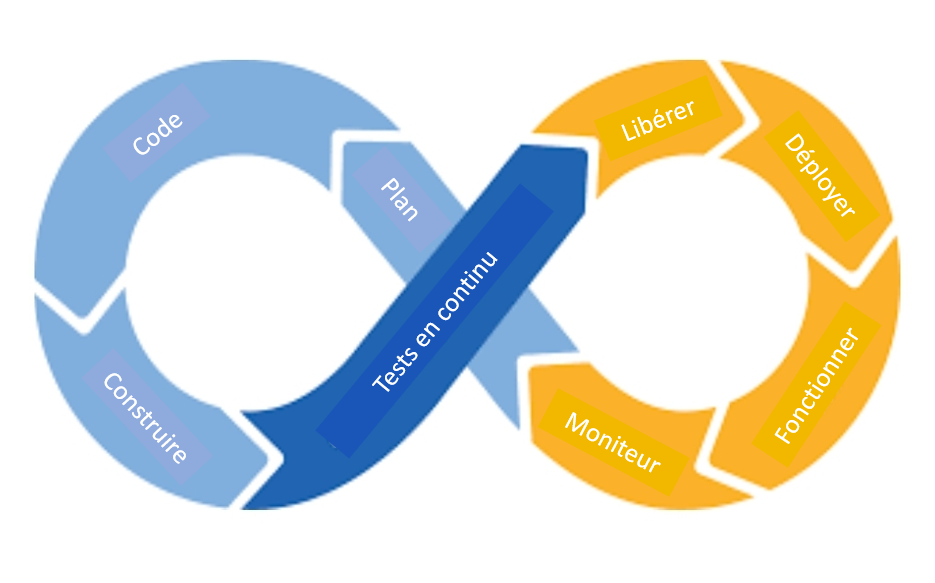
Figure 3 : IC/DC
L’image illustre un processus répétitif représenté par le symbole de l’infini divisé en huit parties inégales. En partant du milieu et en allant dans le sens inverse des aiguilles d’une montre, les premières de ces parties sont : planifier, coder, construire et tester en continu. Ensuite, en partant de la dernière partie, qui était au centre, et en se déplaçant dans le sens des aiguilles d’une montre, les parties sont : publier, déployer, opérer et surveiller, avant de revenir à l’état initial de l’image.
Dans l’ensemble, l’IC/DC est une pratique importante pour les scientifiques des données qui souhaitent développer et déployer des applications de science des données de haute qualité de manière rapide et fiable.
Conclusion
En résumé, le code de niveau de production est essentiel pour les projets et les applications de science des données. Des pratiques de programmation appropriées et des principes de génie logiciel comme l’adhésion aux normes PEP, l’utilisation des annotations de type, la rédaction d’une documentation claire, le contrôle de version, la vérification du code, la journalisation des erreurs, la validation des données, l’écriture d’un code de faible entretien, la mise en œuvre d’une intégration continue et d’un déploiement continu (IC/DC) et la garantie de la reproductibilité sont essentiels pour créer des applications robustes, maintenables et évolutives.
Le non-respect de ces pratiques peut entraîner des difficultés comme le manque de documentation, l’absence de journalisation des erreurs, l’absence de messages d’erreur importants pour les utilisateurs, un code fortement couplé, un code trop adapté à un exemple précis, l’absence de caractéristiques souhaitées par les clients et l’absence de rétroaction en cas d’échec. Ces problèmes peuvent avoir de graves répercussions sur la préparation de la production et frustrer les utilisateurs. Si un utilisateur est frustré, sa productivité s’en ressentira, ce qui entraînera des répercussions négatives en aval sur la capacité des entreprises à remplir efficacement leur mission.
Le conseil le plus pratique pour mettre en œuvre un code de niveau de production est de travailler ensemble, d’attribuer des responsabilités et des délais clairs et de comprendre l’importance de chacun de ces concepts. Ce faisant, il devient facile de mettre en œuvre ces pratiques dans les projets et de créer des applications maintenables et évolutives.
Rencontre avec le scientifique des données

Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Inscrivez-vous à la présentation Rencontre avec le scientifique des données.
À bientôt!
MS Teams – le lien sera fourni aux participants par courriel
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
- Date de modification :