
Use of Machine Learning for Crop Yield Prediction
By: Kenneth Chu, Statistics Canada
The Data Science Division (DScD) at Statistics Canada recently completed a research project for the Field Crop Reporting Series (FCRS) Footnote 1 on the use of machine learning techniques (more precisely, supervised regression techniques) for early-season crop yield prediction.

The project objective was to investigate whether machine learning techniques could be used to improve the precision of the existing crop yield prediction method (referred to as the Baseline method).
The project faced two key challenges: (1) how to incorporate any prediction technique (machine learning or otherwise) into the FCRS production environment in a methodologically sound way, and (2) how to evaluate any prediction method meaningfully within the FCRS production context.
For (1), the rolling window forward validation Footnote 2 protocol (originally designed for supervised learning on time series data) was adapted to safeguard against temporal information leakage. For (2), the team opted to perform testing by examining the actual series of prediction errors that would have resulted had it been deployed in past production cycles.
Motivation
Traditionally, the FCRS publishes annual crop yield estimates at the end of each reference year (shortly after harvest). In addition, full-year crop yield predictions are published several times during the reference year. Farms are contacted in March, June, July, September and November for data collection, resulting in a heavy response burden for farm operators.
In 2019, for the province of Manitoba, a model-based method—essentially, variable selection via LASSO (Least Absolute Shrinkage and Selection Operator), followed by robust linear regression—was introduced to generate the July predictions based on longitudinal satellite observations of local vegetation levels as well as region-level weather measurements. This allowed the removal of the question about crop yield prediction from the Manitoba FCRS July questionnaire, reducing the response burden.
Core regression technique: XGBoost with linear base learner
A number of prediction techniques were examined, including: random forests, support vector machines, elastic-net regularized generalized linear models, and multilayer perceptrons. Accuracy and computation time considerations led us to focus attention on XGBoost Footnote 3 with linear base learner.
Rolling Window Forward Validation to prevent temporal information leakage
The main contribution of the research project is the adaptation of rolling window forward validation (RWFV) Footnote 2 as hyperparameter tuning protocol. RWFV is a special case of forward validation Footnote 2, a family of validation protocols designed to prevent temporal information leakage for supervised learning based on time series data.
Suppose you are training a prediction model for deployment in production cycle 2021. This following schematic illustrates a rolling window forward validation scheme with a training window of five years, and a validation window of three years.

Description - Figure 1
Example of a rolling window forward validation scheme. This figure depicts, as an example, a rolling window forward validation scheme with a training window of five years and a validation window of three years. A validation scheme of this type is used to determine the optimal hyperparameter configuration to use when training the actual prediction model to be deployed in production.The blue box at the bottom represents the production cycle 2021 and the five white boxes to its left correspond to the fact that a training window of five years is being used. This means that the training data for production cycle 2021 will be those from the five years strictly and immediately prior (2016 to 2020). For validation, or hyperparameter tuning for production cycle 2021, the three black boxes above the blue box correspond to our choice that the validation window is three years.
The RWFV protocol is used to choose the optimal configuration from the hyperparameter search space, as follows:
- Fix temporarily an arbitrary candidate hyperparameter configuration from the search space.
- Use that configuration to train a model for validation year 2020 using data from the following five years: 2015 to 2019.
- Use that resulting trained model to make predictions for the validation year 2020. Compute accordingly the parcel-level prediction errors for 2020.
- Aggregate the parcel-level prediction errors down to an appropriate single numeric performance metric.
- Repeat for the two other validation years (2018 and 2019).
Averaging the performance metrics across the validation years 2018, 2019 and 2020, the result is a single numeric performance metric/validation error for the temporarily fixed hyperparameter configuration.
Next, this was repeated for all candidate hyperparameter configurations in the hyperparameter search space. The optimized configuration to actually be deployed in production is the one that yields the best aggregated performance metric. This is rolling window forward validation, or more precisely, our adaptation of it to the crop yield prediction context.
Note that the above protocol respects the operational constraint that, for production cycle 2021, the trained prediction model must have been trained and validated on data from strictly preceding years; in other words, the protocol prevents temporal information leakage.
Production-pertinent testing via prediction error series from virtual production cycles
To evaluate—in a way most pertinent to the production context of the FCRS—the performance of the aforementioned prediction strategy based on XGBoost(Linear) and RWFV, the data scientists computed the series of prediction errors that would have resulted had the strategy actually been deployed for past production cycles. In other words, these prediction errors of virtual past production cycles were regarded as estimates of the generalization error within the statistical production context of the FCRS.
The following schematic illustrates the prediction error series of the virtual production cycles:

Description - Figure 2
Prediction error series of virtual production cycles. Virtual production cycles are run for past reference years, as described in Figure 1. Since the actual crop yield data are already known for past production cycles, the actual prediction errors had the proposed prediction strategy been actually deployed for past production cycles (represented by orange boxes) can be computed. The resulting series of prediction errors for past production cycles is used to assess the accuracy and stability of the proposed crop yield prediction strategy.Now repeat, for each past virtual production cycle (represented by an orange box), what was just described for the blue box. The difference now is the following: for the blue box, namely the current production cycle, it is NOT yet possible to compute the production/prediction errors at time of crop yield prediction (in July) since the current growing season has not ended. However, for the past virtual production cycles (the orange boxes), it is possible.
These prediction errors in virtual past production cycles can be illustrated in the following plot:
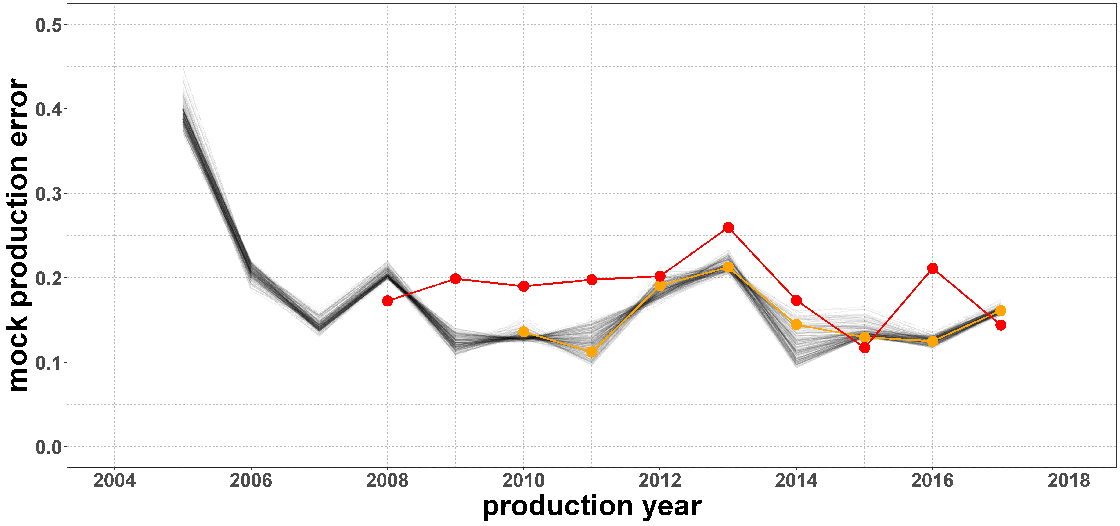
Description - Figure 3
Graphical comparison of the XGBoost(Linear)/RWFV prediction strategy against the Baseline strategy. The red line is the mock production error series of the Baseline strategy, while the orange is that of the XGBoost(Linear)/RWFV strategy. The latter strategy exhibits consistently smaller prediction errors across consecutive virtual past production cycles.The red line illustrates the Baseline model prediction errors, while the orange line illustrates the XGBoost/RWFV strategy prediction errors. The gray lines illustrate the prediction errors for each of the candidate hyperparameter configurations in our chosen search grid (which contains 196 configurations).
The XGBoost/RWFV prediction strategy exhibited smaller prediction errors than the Baseline method, consistently over consecutive historical production runs.
Currently, the proposed strategy is in the final pre-production testing phase, to be jointly conducted by subject matter experts and the agricultural program’s methodologists.
The importance of evaluating protocols
The team chose not to use a more familiar validation method such as hold-out or cross validation, nor a generic generalization error estimate such as prediction error on a testing data set kept aside at the beginning.
These decisions were taken based on our determination that our proposed validation protocol and choice of generalization error estimates (RWFV and virtual production cycle prediction error series, respectively) would be much more relevant and appropriate given the production context of the FCRS.
Methodologists and machine learning practitioners are encouraged to evaluate carefully whether generic validation protocols or evaluation metrics are indeed appropriate for their use cases at hand, and if not, seek alternatives that are more relevant and meaningful within the given context. For more information about this project, please email statcan.dsnfps-rsdfpf.statcan@statcan.gc.ca.
References
- Date modified: