
Renseignements à l'appui du Répertoire des programmes
Les renseignements sur les ressources financières, les ressources humaines et le rendement liés au Répertoire des programmes de Statistique Canada figurent dans l'InfoBase du GC.
Les renseignements sur les ressources financières, les ressources humaines et le rendement liés au Répertoire des programmes de Statistique Canada figurent dans l'InfoBase du GC.
Ministre de tutelle : L'honorable François-Philippe Champagne, C.P., député
Administrateur général : Anil Arora
Portefeuille ministériel : Innovation, Sciences et Développement économique
Instruments habilitants :
Année de constitution ou de création : Le Bureau fédéral de la statistique a été fondé en 1918. L'organisme a adopté la dénomination Statistique Canada en 1971, dans le cadre de la révision de la Loi sur la statistique.
Autres : En vertu de la Loi sur la statistique, Statistique Canada doit recueillir, compiler, analyser, dépouiller et publier des renseignements statistiques portant sur les activités commerciales, industrielles, financières, sociales, économiques et générales de la population du Canada et sur l'état de celle-ci.
Statistique Canada suit deux principaux objectifs :
Le bureau central de Statistique Canada est situé à Ottawa. L'organisme dispose de bureaux régionaux partout au pays, plus précisément à Halifax, à Sherbrooke, à Montréal, à Toronto, à Sturgeon Falls, à Winnipeg, à Edmonton et à Vancouver. En outre, l'organisme compte 35 centres de données de recherche au pays, lesquels sont situés dans des établissements universitaires. De plus, le personnel des ministères et organismes fédéraux et de certains ministères et organismes provinciaux a accès à cinq salles sécurisées. Dans les centres, les chercheurs ont accès, depuis un milieu universitaire sécurisé, à des microdonnées provenant de programmes d'enquête auprès de la population et des ménages. Les Canadiennes et les Canadiens peuvent suivre l'organisme sur Twitter, Facebook, Instagram, Reddit, YouTube ainsi que sur les fils d'actualité.
La section « Raison d'être, mandat et rôle : qui nous sommes et ce que nous faisons » est accessible sur le site Web de Statistique Canada.
Pour obtenir plus de renseignements sur les engagements organisationnels énoncés dans la lettre de mandat de l'organisme, veuillez consulter la lettre de mandat du ministre.
Des renseignements sur le contexte opérationnel sont accessibles sur le site Web de Statistique Canada.
Le Cadre ministériel des résultats et le Répertoire des programmes officiels de Statistique Canada de 2021-2022 sont présentés ci-dessous.
Statistique Canada produit des renseignements statistiques objectifs de grande qualité pour l'ensemble du Canada. Les renseignements statistiques produits portent sur les activités commerciales, industrielles, financières, sociales, économiques, environnementales et générales de la population canadienne et sur l'état de celle-ci.
Des renseignements statistiques de grande qualité sont à la disposition des Canadiens.
Les Canadiens accèdent à des renseignements statistiques de grande qualité.
Les renseignements statistiques de grande qualité sont pertinents pour les Canadiens.
Le graphique suivant présente les dépenses prévues (votées et législatives) au fil du temps.

| 2019–20 | 2020–21 | 2021–22 | 2022–23 | 2023–24 | 2024-25 | |
|---|---|---|---|---|---|---|
| Activités à frais recouvrables (revenus nets) | 120 038 | 123 989 | 127 584 | 120 000 | 120 000 | 120 000 |
| Postes législatifs | 73 190 | 83 531 | 90 714 | 79 967 | 72 931 | 72 223 |
| Crédits votés | 473 759 | 537 787 | 792 670 | 496 727 | 443 463 | 436 340 |
| Total | 666 988 | 745 308 | 1 010 967 | 696 694 | 636 394 | 628 564 |
Le tableau « Sommaire du rendement budgétaire pour les responsabilités essentielles et les services internes » présente les ressources financières budgétaires affectées aux responsabilités essentielles et aux services internes de Statistique Canada.
| Responsabilités essentielles et services internes | Budget principal des dépenses 2021-2022 | Dépenses prévues 2021-2022 | Dépenses prévues 2022-2023 | Dépenses prévues 2023-2024 | Autorisations totales pouvant être utilisées 2021-2022 | Dépenses réelles (autorisations utilisées) 2019-2020 | Dépenses réelles (autorisations utilisées) 2020-2021 | Dépenses réelles (autorisations utilisées) 2021-2022 |
|---|---|---|---|---|---|---|---|---|
| Renseignements statistiques | 855 425 655 | 855 425 655 | 616 663 357 | 560 200 355 | 972 123 133 | 584 770 894 | 666 463 788 | 920 977 524 |
| Services internes | 66 905 037 | 66 905 037 | 80 030 892 | 76 193 902 | 100 209 616 | 82 217 225 | 78 844 148 | 89 989 424 |
| Total | 922 330 692 | 922 330 692 | 696 694 249 | 636 394 257 | 1 072 332 749 | 666 988 119 | 745 307 936 | 1 010 966 948 |
| Revenus disponibles | -120 000 000 | -120 000 000 | -120 000 000 | -120 000 000 | -127 583 773 | -120 038 495 | -123 989 068 | -127 583 773 |
| Total | 802 330 692 | 802 330 692 | 576 694 249 | 516 394 257 | 944 748 976 | 546 949 624 | 621 318 868 | 883 383 175 |
Le financement de Statistique Canada provient de deux sources, à savoir les crédits parlementaires directs et les activités à frais recouvrables. L'organisme est autorisé à générer 120 millions de dollars par année en revenus disponibles dans deux secteurs : les enquêtes statistiques et les services connexes, ainsi que les demandes personnalisées et les ateliers. Si l'organisme dépasse cette somme en revenus disponibles, il peut présenter une demande d'augmentation de l'autorisation, comme il l'a fait ces dernières années.
Depuis quelques années, les revenus disponibles provenant des activités à frais recouvrables ont représenté de 120 millions de dollars à 127 millions de dollars par année du total des ressources budgétaires de l'organisme. Une part importante de ces revenus disponibles provient de ministères et d'organismes fédéraux et sert à financer des projets statistiques précis.
Les fluctuations des dépenses observées entre les années figurant dans le graphique et celles figurant dans le tableau ci-dessus sont principalement attribuables au Programme du recensement. L'activité de ce programme a culminé en 2021-2022, lorsque le Recensement de la population de 2021 et le Recensement de l'agriculture de 2021 ont été menés, et elle diminuera en 2022-2023 et 2023-2024, lorsque ces activités prendront fin. Cette tendance est typique pour l'organisme en raison de la nature cyclique du Programme du recensement. Le financement pour le Recensement de la population et le Recensement de l'agriculture de 2026 n'a pas encore été approuvé, ce qui amplifie la baisse du financement global du Programme du recensement.
De plus, le financement reçu pour plusieurs nouvelles initiatives du budget de 2021 diminue de 2022-2023 à 2023-2024 et demeure relativement stable en 2024-2025.
La différence entre les dépenses réelles de 2021-2022 et les autorisations totales pouvant être utilisées de 2021-2022 est surtout attribuable à la manière dont l'organisme assure la gestion stratégique de ses investissements. L'organisme se sert du mécanisme de report du budget d'exploitation pour gérer la nature cyclique des opérations de ses programmes et de ses investissements en matière de priorités stratégiques. Tout au long de l'année, les excédents prévus des programmes ou des projets reportés sont gérés de façon centralisée, par priorité, dans le cadre des responsabilités essentielles liées aux renseignements statistiques.
En outre, les efforts considérables déployés pour passer des opérations sur papier en personne aux activités virtuelles en ligne pour le Recensement de la population de 2021 ont généré des économies. Ces fonds sont retournés au cadre financier.
Les dépenses au titre des services internes de 2019-2020 à 2021-2022 tiennent compte de ressources prévues provenant du financement temporaire lié à une initiative approuvée en 2018-2019, soit la migration de l'infrastructure de l'organisme vers l'infonuagique. La diminution du financement pour les prochaines années est en grande partie attribuable au financement continu lié aux dépenses en infonuagique qui n'a pas encore été garanti et à la façon dont l'organisme gère stratégiquement ses investissements. Les investissements sont gérés de façon centralisée, dans le cadre des responsabilités essentielles liées aux renseignements statistiques, en fonction des priorités établies. Le financement des investissements des années précédentes prendra fin au cours des années à venir, tandis que les nouvelles décisions d'investissement seront prises plus tard durant l'année.
Le tableau suivant présente une comparaison entre les dépenses brutes prévues et les dépenses nettes pour 2021-2022.
| Responsabilités essentielles et services internes | Dépenses brutes réelles 2021-2022 | Recettes réelles affectées aux dépenses 2021-2022 | Dépenses nettes réelles (autorisations utilisées 2021-2022 |
|---|---|---|---|
| Renseignements statistiques | 920 977 524 | 127 583 773 | 793 393 751 |
| Services internes | 89 989 424 | 0 | 89 989 424 |
| Total | 1 010 966 948 | 127 583 773 | 883 383 175 |
Statistique Canada a généré des revenus disponibles de 127 millions de dollars grâce à la vente de produits et services statistiques.
Le tableau « Sommaire des ressources humaines pour les responsabilités essentielles et les services internes » présente les équivalents temps plein (ETP) affectés à chacune des responsabilités essentielles et aux services internes de Statistique Canada.
| Responsabilités essentielles et services internes | Nombre d'équivalents temps plein réels 2019-2020 | Nombre d'équivalents temps plein réels 2020-2021 | Nombre d'équivalents temps plein prévus 2021-2022 | Nombre d'équivalents temps plein réels 2021-2022 | Nombre d'équivalents temps plein prévus 2022-2023 | Nombre d'équivalents temps plein prévus 2023-2024 |
|---|---|---|---|---|---|---|
| Renseignements statistiques | 5 595 | 6 099 | 6 026 | 7 186 | 5 889 | 5 387 |
| Services internes | 626 | 684 | 563 | 713 | 659 | 642 |
| Total | 6 221 | 6 783 | 6 589 | 7 899 | 6 548 | 6 029 |
| Revenus disponibles | -1 366 | -1 340 | -1 231 | -1 542 | -1 181 | -1 181 |
| Total | 4 855 | 5 443 | 5 358 | 6 357 | 5 367 | 4 848 |
Tout comme les tendances des dépenses prévues, les variations des équivalents temps plein (ETP) d'une année à l'autre sont en grande partie attribuables à la nature cyclique du Programme du recensement. L'activité a atteint un sommet en 2021-2022, au moment de la tenue du Recensement de la population de 2021 et du Recensement de l'agriculture de 2021, et diminuera par la suite, lorsque ces activités prendront fin.
Pour obtenir des renseignements sur les dépenses votées et les dépenses législatives de Statistique Canada, consultez les Comptes publics du Canada 2021.
Des renseignements sur l'harmonisation des dépenses de Statistique Canada avec les dépenses et les activités du gouvernement du Canada figurent dans l'InfoBase du GC.
Les états financiers (non audités) de Statistique Canada pour l'exercice se terminant le 31 mars 2022 sont affichés sur le site Web de l'organisme.
L'organisme utilise la méthode de comptabilité d'exercice intégrale pour la préparation et la présentation de ses états financiers annuels, lesquels font partie du processus de production de rapports sur les résultats ministériels. Toutefois, les autorisations de dépenses présentées dans les sections précédentes du présent rapport continuent de reposer sur la comptabilité des dépenses. Un rapprochement entre les bases de rapport figure à la note 3 des états financiers.
| Renseignements financiers | Résultats prévus 2021-2022 | Résultats réels 2021-2022 | Résultats réels 2020-2021 | Écart (résultats réels de 2021-2022 moins résultats prévus de 2021-2022) | Écart (résultats réels de 2021-2022 moins résultats réels de 2020-2021) |
|---|---|---|---|---|---|
| Total des charges | 1 048 174 102 | 1 098 855 896 | 852 413 139 | 50 681 794 | 246 442 757 |
| Total des revenus | 120 000 000 | 127 990 099 | 120 247 616 | 7 990 099 | 7 742 483 |
| Coût de fonctionnement net avant le financement du gouvernement et les transferts | 928 174 102 | 970 865 797 | 732 165 523 | 42 691 695 | 238 700 274 |
L'état des résultats prospectif (non audité) de Statistique Canada pour l'exercice se terminant le 31 mars 2022 figure sur le site Web de l'organisme. Les hypothèses qui sous-tendent les prévisions ont été formulées avant la fin de l'exercice 2020-2021.
Le coût de fonctionnement net avant le financement du gouvernement et les transferts s'est établi à 970,9 millions de dollars, ce qui représente une augmentation de 238,7 millions de dollars (32,6 %) par rapport au coût de 732,2 millions de dollars enregistré en 2020-2021. La hausse des charges et des revenus est principalement attribuable à une augmentation globale des activités de l'organisme, en particulier pour le Programme du Recensement de la population de 2021. De plus, les coûts salariaux ont augmenté en raison de la ratification de certaines conventions collectives en 2021-2022.
L'écart entre les coûts nets prévus et réels pour 2021-2022 est de 42,7 millions de dollars (4,6 %). Les dépenses ont été supérieures de 50,7 millions de dollars à ce qui avait été prévu. La ratification de conventions collectives et de nouvelles initiatives, comme de meilleures données pour de meilleurs résultats, le renforcement des soins de longue durée et des soins de soutien, l'amélioration des données sur l'état des entreprises et une meilleure compréhension de notre environnement, ont contribué à une augmentation importante des dépenses. Le financement qui a été reporté de 2020-2021 contribue également à cette augmentation. Cela a permis à l'organisme de répondre aux besoins de ses programmes cycliques et d'investir dans ses plans stratégiques intégrés. Les augmentations sont en partie compensées par le report du budget à 2022-2023. Les revenus ont été supérieurs de 8 millions de dollars à ce qui avait été prévu.
Pour obtenir de plus amples renseignements sur la répartition des dépenses selon le programme et le type de dépense, veuillez consulter les deux graphiques ci-dessous.
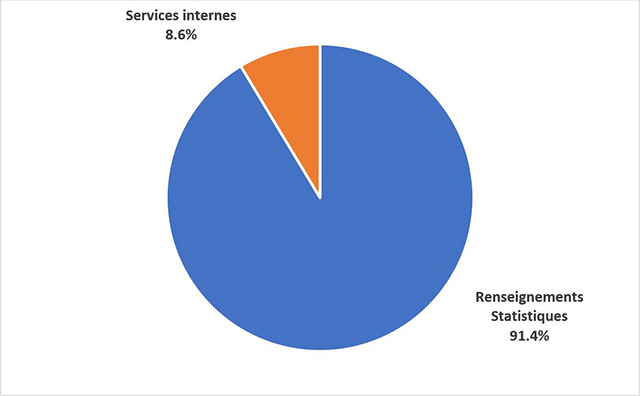
Les charges totales, y compris les revenus disponibles et les services fournis sans frais par les ministères et organismes fédéraux, se sont chiffrées à 1,1 milliard de dollars en 2021-2022. Elles comprennent 1,0 milliard de dollars (91,4 %) pour les renseignements statistiques et 94,9 millions de dollars (8,6 %) pour les services internes.
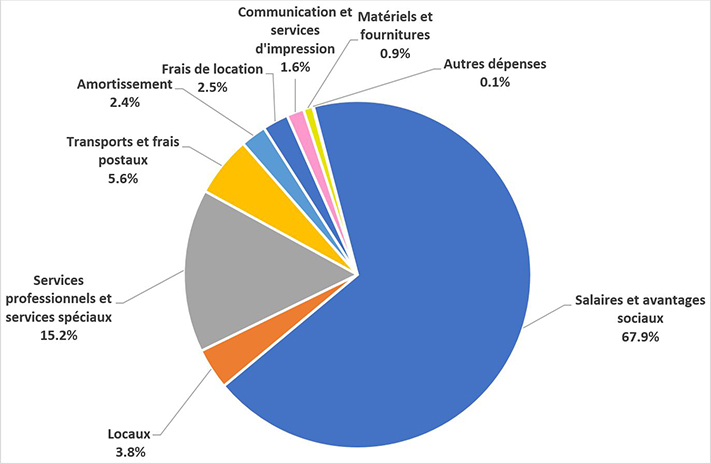
Statistique Canada a dépensé 1,1 milliard de dollars en 2021-2022. Ces dépenses comprennent 746,8 millions de dollars engagés pour les salaires et avantages sociaux du personnel (67,9 %), 42,1 millions de dollars pour les locaux (3,8 %), 166,8 millions de dollars pour les services professionnels et les services spéciaux (15,2 %), 61,5 millions de dollars pour le transport et les frais postaux (5,6 %), 26,9 millions de dollars en frais de location (2,5 %), 26,2 millions de dollars pour l'amortissement (2,4 %), 17,6 millions de dollars pour la communication et l'impression (1,6 %), 9,5 millions de dollars en matériels et fournitures (0,9 %) et 1,5 million de dollars pour les autres dépenses (0,1 %).
| Renseignements financiers | 2021-2022 | 2020-2021 | Écart (2021-2022 moins 2020-2021) |
|---|---|---|---|
| Total des passifs nets | 142 525 338 | 160 919 348 | -18 394 010 |
| Total des actifs financiers nets | 67 079 045 | 77 141 756 | -10 062 711 |
| Dette nette du ministère | 75 446 293 | 83 777 592 | -8 331 299 |
| Total des actifs non financiers | 170 908 816 | 170 230 625 | 678 191 |
| Situation financière nette du ministère | 95 462 523 | 86 453 033 | 9 009 490 |
La situation financière nette de Statistique Canada s'établissait à 95,5 millions de dollars à la fin de 2021-2022, ce qui représente une augmentation de 9 millions de dollars par rapport à la situation financière nette de 2020-2021 qui se situait à 86,5 millions de dollars.
La diminution du total des passifs nets s'explique principalement par une baisse des charges à payer pour les indemnités de vacances et de congés compensatoires découlant du remboursement obligatoire des congés annuels et compensatoires et une diminution des comptes créditeurs.
La diminution du total des actifs financiers nets s'explique principalement par une baisse des montants à recevoir du Trésor au 31 mars 2022 pour les comptes créditeurs et les salaires et traitements à payer. Cela est contrebalancé par une augmentation des comptes débiteurs d'autres ministères et organismes gouvernementaux et de parties externes.
Pour obtenir de plus amples renseignements sur la répartition des bilans dans l'état de la situation financière, veuillez consulter les deux graphiques ci-dessous.
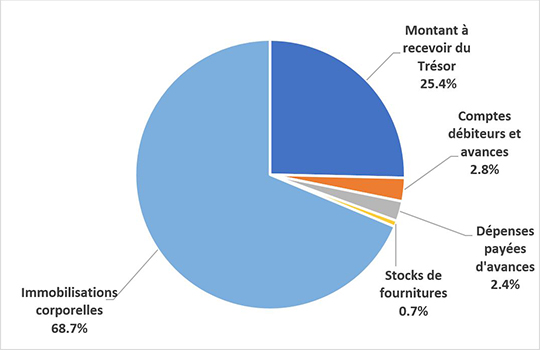
Le total des actifs, y compris les actifs financiers et non financiers, s'établissait à 238 millions de dollars à la fin de 2021-2022. Les immobilisations corporelles représentent la partie la plus importante des actifs, soit 163,5 millions de dollars (68,7 %). Ces actifs comprennent les logiciels (85,3 millions de dollars), les logiciels en voie de développement (62,6 millions de dollars), les améliorations locatives (13,9 millions de dollars) et d'autres actifs (1,7 million de dollars). La partie qui reste comprend les montants à recevoir du Trésor (60,4 millions de dollars) [25,4 %], les dépenses payées d'avance (5,7 millions de dollars) [2,4 %], les comptes débiteurs et avances (6,7 millions de dollars) [2.8 %] et les stocks de fournitures (1,7 million de dollars) [0,7 %].
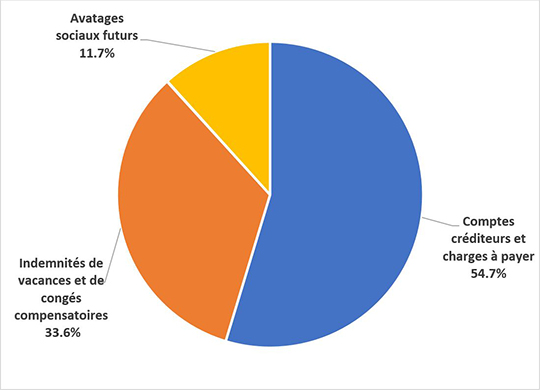
Le total des passifs s'établissait à 142,5 millions de dollars à la fin de 2021-2022. Les comptes créditeurs et charges à payer constituent la partie la plus importante, soit 77,9 millions de dollars (54,7 %) du passif total. Les comptes créditeurs et charges à payer comprennent les comptes créditeurs de parties externes (30,2 millions de dollars), les comptes créditeurs d'autres ministères et organismes fédéraux (13,3 millions de dollars) et les salaires et traitements à payer (34,4 millions de dollars). La proportion suivante en importance est celle correspondant aux indemnités de vacances et de congés compensatoires, soit 47,9 millions de dollars (33,6 %), suivie de celle attribuable aux avantages sociaux futurs, soit 16,7 millions de dollars (11,7 %).
Statistique Canada produit des renseignements statistiques objectifs de grande qualité pour l'ensemble du Canada. Les renseignements statistiques produits portent sur les activités commerciales, industrielles, financières, sociales, économiques, environnementales et générales de la population canadienne et sur l'état de celle-ci.
Les Canadiennes et les Canadiens ont clairement indiqué que des données pertinentes, actuelles et de grande qualité sont essentielles à la réponse du pays à la pandémie et à la reprise. Statistique Canada a répondu à la demande urgente de données pertinentes et fiables, en adaptant ses programmes pour fournir des renseignements opportuns fondés sur des données, pour suivre les répercussions sociales, économiques et sanitaires de la COVID-19 sur tous les groupes de population, en particulier les groupes vulnérables. Ces renseignements fondés sur les données guident les dirigeants dans l'évaluation des options de politiques et de programmes pour aider le Canada à tracer la voie vers la reprise.
Le travail de modernisation que l'organisme a accompli au cours des dernières années lui a permis de se transformer avec détermination. Alors que Statistique Canada poursuivait son parcours de modernisation, il a redoublé d'efforts pour se conformer aux cinq principes de modernisation suivants :
 Offrir des produits et des services axés sur l'utilisateur
Offrir des produits et des services axés sur l'utilisateurPour joindre les Canadiennes et les Canadiens de différentes manières, et veiller à ce qu'un plus grand nombre d'entre eux aient accès aux renseignements dont ils ont besoin, au moment où ils en ont besoin et dans les formats dont ils ont besoin, Statistique Canada a élaboré des façons novatrices pour rendre les données plus faciles à trouver, à partager et à utiliser. Notamment, l'organisme a :
Pour s'assurer que les renseignements statistiques rejoignent un plus grand nombre de Canadiennes et de Canadiens et que ces derniers comprennent mieux les données, Statistique Canada diffuse ses produits dans divers formats.


Afin de moderniser son site Web, Statistique Canada a créé plusieurs portails pour donner accès à des données thématiques.

La Stratégie de mobilisation axée sur la raison d'être de Statistique Canada a donné lieu à une approche plus centrée sur l'utilisateur, et plus moderne, pertinente et novatrice, pour mobiliser la population canadienne. Les chiffres pour 2021-2022, lesquels ont dépassé toutes les attentes, témoignent du succès de la stratégie.
Statistique Canada continue de mettre à jour son Portail de statistiques sur le logement, en réponse à la demande croissante de données agrégées sur le logement. Grâce à un accès amélioré à une variété de données sur le logement, ce portail facilite la collaboration entre les utilisateurs et les fournisseurs de données et contient des liens vers plus de 700 produits de données. Les tableaux de données du Programme de la statistique du logement canadien contiennent actuellement 68 millions d'estimations, qui sont élargies et mises à jour chaque année.
Statistique Canada a lancé d'autres produits et composantes pour l'initiative Analyse des données en tant que service (ADS), une plateforme infonuagique qui fournit aux Canadiennes et aux Canadiens des outils utiles pour accéder aux données de Statistique Canada et les analyser, comme ils n'ont jamais pu le faire auparavant. La plateforme est utilisée par des chercheurs, des universitaires, des décideurs et toute personne qui a besoin d'une plateforme puissante pour travailler avec des données.
L'ADS a continué d'évoluer en 2021-2022 et compte maintenant plus de deux douzaines de partenaires de collaboration de tous les ordres de gouvernement, dans le secteur privé et dans le milieu de la recherche.
Reconnaissance de l'Analyse des données en tant que service
L'équipe de l'Analyse des données en tant que service est reconnue dans l'ensemble du gouvernement du Canada et a été retenue parmi les finalistes de prix nationaux, dans le cadre des Prix de la collectivité du numérique du gouvernement du Canada. Cela comprend le Prix d'excellence en matière de gouvernement ouvert et le Prix d'excellence dans la conception de services aux utilisateurs.
Les chercheurs et les universitaires doivent accéder aux microdonnées pour mener leurs travaux. Toutes les microdonnées sont désagrégées, soigneusement modifiées et examinées pour s'assurer qu'aucune personne ou entreprise n'est identifiée directement ou indirectement.
 Utiliser des méthodes de pointe : les répercussions de la pandémie de COVID-19
Utiliser des méthodes de pointe : les répercussions de la pandémie de COVID-19Les Canadiennes et Canadiens ont besoin de renseignements actuels et exacts fondés sur des données pour appuyer la prise de décisions fondées sur des données probantes, particulièrement en période critique comme la pandémie de COVID-19. L'organisme a répondu aux demandes croissantes engendrées par la pandémie en fournissant des données plus opportunes et une analyse en temps réel des tendances. La collecte des données dans les domaines suivants donne lieu à la production de meilleurs renseignements sur les répercussions de la pandémie sur la population canadienne :

Le questionnaire du recensement de 2021 comprenait une question sur le genre qui permettait à la population transgenre et non-binaire de s'autodéclarer.
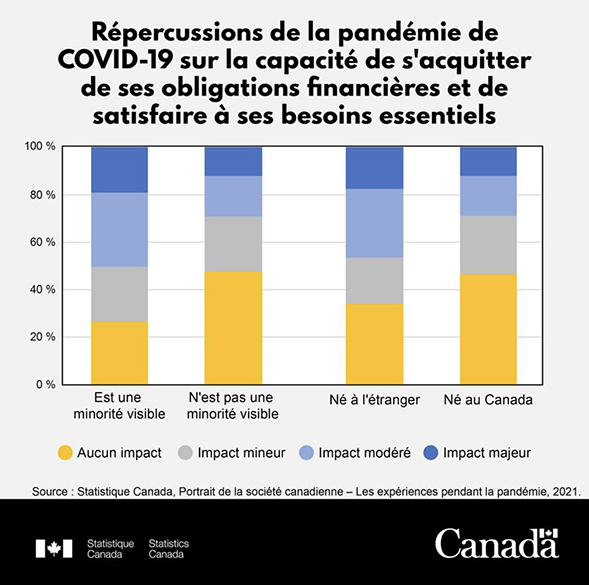
| Aucune répercussion | Aucune répercussion | Aucune répercussion | Répercussions majeures | |
|---|---|---|---|---|
| Répercussions majeures | 27 % | 23 % | 31 % | 19 % |
| Ne fait pas partie de groupes désignés comme minorités visibles | 48 % | 23 % | 17 % | 12 % |
| Nés à l'étranger | 34 % | 19 % | 29 % | 18 % |
| Nés à l'étranger | 46 % | 25 % | 17 % | 12 % |
| Source(s) : Portrait de la société canadienne — Les expériences pendant la pandémie (PCS2), 2021. | ||||
La pandémie de COVID-19 a eu des répercussions sur de nombreux aspects de la société et de l'économie canadiennes, y compris l'emploi. Des données importantes sur le marché du travail ont continué d'être transmises au moyen de l'EPA afin de faire la lumière sur les conséquences de la pandémie, mais d'autres enquêtes et outils ont été créés pour transmettre des données à jour à la population canadienne.

La pandémie de COVID-19 a mis en évidence des lacunes statistiques liées à l'équipement de protection individuelle, à la couverture vaccinale, à la santé mentale et aux soins en établissement.
En 2021-2022 :

La proportion de personnes occupées ayant une incapacité liée à la santé mentale a augmenté de 2,3 points de pourcentage de 2019 (6,4 %) à 2021 (8,7 %)
Recensement de la population de 2021
Statistique Canada a pris toutes les précautions nécessaires et a adapté son approche pour le Recensement de 2021 afin de protéger la santé et la sécurité de son personnel et de la population, tout en veillant à ce que des données soient recueillies au sujet de l'ensemble des Canadiennes et des Canadiens.

Au moyen d'une approche qui privilégie le numérique, nous avons veillé à la santé et à la sécurité de la population canadienne et du personnel du recensement pendant la pandémie de COVID-19 et la saison des feux de forêt.
Taux de réponse en ligne
Notre taux de réponse en ligne n'a jamais été aussi élevé !
Pour assurer la sécurité de son personnel et de la population, Statistique Canada a mis en œuvre une approche sans contact, a encouragé l'autodéclaration et a réduit le plus possible les déplacements. Ces nouvelles mesures ont permis à l'organisme de poursuivre la collecte de données malgré les feux de forêt, les inondations, les restrictions de voyage et les éclosions de COVID-19, particulièrement dans les 700 communautés autochtones, nordiques et éloignées, et les données recueillies ont été traitées dans un délai plus court. Malgré ces nombreux défis, les opérations sur le terrain pour le Recensement de la population de 2021 ont connu un grand succès, grâce aux 35 000 employés du recensement (qui comprenaient un nombre sans précédent de personnes de diverses origines ethniques, dépassant les cibles d'équité en matière d'emploi). Les objectifs de collecte ont donc été atteints, et le taux de participation global s'est élevé à 98 %. Le taux de réponse en ligne de 84 % représente un niveau record pour la réponse en ligne, et il s'agit du taux le plus élevé à avoir été enregistré à ce jour parmi nos partenaires du monde entier.
Les données du recensement sont utilisées quotidiennement par tous les ordres de gouvernement, les entreprises et les particuliers pour prendre des décisions importantes, notamment en ce qui a trait à l'évaluation des répercussions de la pandémie de COVID-19, à la planification des services communautaires (p. ex. les écoles et les services d'urgence), à la détermination de la demande des consommateurs et du marché, et aux investissements. Les premiers résultats du Recensement de 2021 ont été diffusés en février 2022, et des résultats continueront d'être publiés tout au long de l'année. Ces diffusions donneront un aperçu de la diversité croissante du Canada, aideront à mesurer la reprise du pays après la pandémie, et permettront de placer les répercussions sociales et économiques sur les groupes marginalisés au cœur de la prise de décisions.
Recensement de l'agriculture de 2021
De même, il y a eu de bons taux de réponse pour le Recensement de l'agriculture de 2021 en ce qui concerne la représentation de l'industrie et des régions; dans l'ensemble, le taux de participation s'est établi à 86 % et le taux de réponse en ligne, à 86 %. Ces résultats sont principalement attribuables à une vaste stratégie de mobilisation et à une collaboration étroite avec les partenaires de l'industrie pour encourager leurs membres à remplir le questionnaire. Le soutien des partenaires provinciaux et d'Agriculture et Agroalimentaire Canada s'est également révélé très précieux tout au long du cycle du Recensement de 2021. Bien que le fardeau de réponse ait toujours été un problème pour les agriculteurs, cela n'a pas été exprimé dans la même mesure en 2021, et ce, malgré la pandémie et les phénomènes météorologiques extrêmes. Cela rend compte des relations étroites que l'organisme a établies avec les partenaires de l'industrie au cours des dernières années, ainsi que des messages clairs et du ferme appui des partenaires démontrant une compréhension de la valeur de ces données. Les prochaines étapes consistent à terminer la diffusion de produits de données et d'études supplémentaires présentant des perspectives économiques, sociales et environnementales afin de maximiser la valeur pour les utilisateurs de données.
Campagne de communications du Recensement de 2021 : méthodes nouvelles et novatrices
Afin de soutenir la campagne de communications du Recensement de 2021, l'organisme s'est appuyé sur des partenariats établis au cours de l'étape de la collecte des données du recensement pour créer des outils qui répondent aux besoins des intervenants, comme les organismes à but non lucratif, les écoles, les universités, les organisations autochtones, les divers ordres de gouvernement, les influenceurs sur les médias sociaux et les entreprises.
Cette campagne novatrice primée a contribué au succès de la première collecte des données du recensement à être menée pendant une pandémie. La campagne publicitaire réalisée pour le Recensement de 2021 a permis de dépasser les données repères : 503 millions d'impressions ont été faites, et la vidéo a été visionnée 70 millions de fois. Au total, 12 000 organismes ont été joints avant et pendant la période de collecte pour appuyer les activités de recrutement et de collecte du Recensement de la population. Le contenu lié au recensement publié sur les médias sociaux a été consulté plus de 326 millions de fois et a fait l'objet de 12,5 millions d'interactions, comme des mentions « J'aime », des partages et des commentaires. La stratégie de l'organisme visant les influenceurs a reçu l'appui de plus de 200 Canadiennes et Canadiens de renom, dont des astronautes, des athlètes olympiques et des récipiendaires du prix Juno.
La première diffusion des données du Recensement de 2021, qui a eu lieu en 2021-2022, a généré 3 091 citations dans les médias. Plus de 1 000 intervenants ont enrichi le contenu des médias sociaux de Statistique Canada, et 28 296 visites ont été enregistrées relativement à l'article sur le Recensement de la population et les chiffres de logements publié dans Le Quotidien.
Utiliser des méthodes de pointe : au-delà de la pandémie de COVID-19Statistique Canada a continué de mettre en place de nouveaux outils et de nouvelles méthodes de pointe pour accroître l'utilisation de la science des données dans tous ses programmes et produire des statistiques fiables. Les initiatives suivantes sont des exemples d'utilisation de méthodes de pointe par Statistique Canada en 2021-2022.
L'organisme a lancé l'Enquête sociale canadienne (ESC), une première enquête omnibus, en avril 2021, et la première diffusion a eu lieu en septembre 2021. L'ESC permet de recueillir des renseignements sur divers sujets sociaux, comme la santé, le bien-être, les répercussions de la COVID-19, les activités, l'emploi du temps et la préparation aux situations d'urgence. Ces renseignements aideront à orienter la prestation de services et de mesures de soutien destinés à la population canadienne pendant et après la pandémie, et guideront l'élaboration de politiques sur un éventail d'enjeux sociaux et économiques.
L'Enquête sur les dépenses des ménages (EDM) permet de recueillir des données sur les habitudes de consommation des Canadiennes et des Canadiens et sur le montant que les ménages paient pour la nourriture, les vêtements, le logement, le transport, les soins de santé et d'autres articles. En 2021, l'EDM a été transférée sur la plateforme intégrée de collecte de données de Statistique Canada, et un questionnaire électronique a été ajouté à ses modes de collecte de données. La modernisation des outils de collecte de l'EDM a permis plus de souplesse dans la collecte des données.
L'Environnement global pour l'écosystème de la statistique économique est un projet pluriannuel qui vise à améliorer le cadre international de reconnaissance de la comptabilité environnementale. Il a également pour but d'améliorer le partage des données grâce à l'harmonisation et à l'interopérabilité des systèmes de données avec les organismes statistiques internationaux. Il permettra d'harmoniser le déroulement des processus, les concepts et les classifications qui servent à la production des données du Système canadien des comptes macroéconomiques (SCCM), tout en renforçant et en modernisant l'infrastructure de technologie de l'information requise pour l'exécution des travaux en cours et à venir.
Le but de ce projet est que toutes les données du SCCM soient produites dans un environnement flexible, fiable, traçable et réutilisable, afin que les consommateurs de données profitent d'estimations plus facilement comparables et d'une infrastructure de métadonnées uniforme, et qu'ils continuent d'avoir confiance en la qualité des données.
En 2021-2022, cette initiative a permis d'instaurer la normalisation grâce à l'adoption de l'échange de données et de métadonnées statistiques, une initiative internationale qui vise à améliorer l'échange de données entre les pays.

En décembre 2021, Statistique Canada a publié son Plan d'action pour la science ouverte en réponse à la publication de la Feuille de route pour la science ouverte en février 2020. Dans la feuille de route, les ministères et organismes à vocation scientifique ont été invités à entreprendre les prochaines étapes pour rendre la science fédérale accessible à tous, tout en respectant la vie privée, et en prenant en compte la sécurité, les considérations éthiques et la protection de la propriété intellectuelle.
Le nouveau Recensement de l'environnement a été annoncé dans le budget de 2021, et Statistique Canada a diffusé une étude initiale sur l'activité humaine et l'environnement, qui rend compte de l'étendue et de l'état des écosystèmes au Canada, ainsi que des biens et des services qui en découlent. En intégrant ces données environnementales aux renseignements sociaux et économiques, Statistique Canada peut brosser pour les Canadiennes et les Canadiens un tableau qui orientera la mise en place de solutions durables. Le Recensement de l'environnement permettra de suivre le rendement du Canada vers un rôle de chef de file mondial de la croissance économique durable.
Dans le cadre des efforts continus visant à remédier à la surreprésentation des Autochtones et des membres des groupes racisés dans le système de justice, Statistique Canada collabore avec Justice Canada pour faire progresser l'Initiative de modernisation des données relatives à la justice du budget de 2021. Cette initiative a pour but de moderniser le système de justice du Canada, d'appuyer les politiques fondées sur des données probantes et d'assurer la responsabilisation au sein du système de justice pénale, en améliorant la collecte et l'utilisation des données désagrégées. En 2021-2022, de nouvelles données sur les admissions dans les établissements correctionnels parmi les Autochtones et les membres de groupes racisés ont été recueillies et diffusées, démontrant une fois de plus leur surreprésentation dans le système de justice.
L'Initiative de modernisation de l'analyse des données est fondée sur une approche à l'échelle de Statistique Canada pour la transition à une nouvelle méthode de travail plus ouverte. Elle repose sur une approche d'expérimentation scientifique approfondie pour veiller à assurer l'utilité des normes, des pratiques et des procédures pour les analystes.
En 2021-2022, des mesures de sécurité claires ont été mises en place pour combler les lacunes et veiller à ce que des pratiques appropriées de gérance et de sécurité des données régissent les solutions internes élaborées par les analystes à l'échelle de l'organisme. Une Foire de développement citoyen s'est tenue à l'automne 2021 afin de présenter les projets de sources ouvertes dans l'ensemble de l'organisme, de promouvoir la collaboration et la réutilisation de solutions dans l'ensemble des programmes statistiques, et de renforcer les pratiques exemplaires de gestion des solutions internes élaborées par des analystes. En outre, un marathon de programmation sur la ludification de la documentation a eu lieu au début de 2022 afin de permettre aux membres du personnel de socialiser et d'adopter les nouvelles normes pour l'analyse moderne des données dans leur travail au quotidien.
Dans le cadre de son engagement à offrir à la population canadienne des données géospatiales jusqu'au plus petit niveau de détail possible, Statistique Canada a collaboré avec le Commissariat aux incendies de la Colombie-Britannique pour créer le Tableau de bord communautaire pour la réduction des risques d'incendie. Ce projet pilote géospatial montre visuellement les niveaux de risque d'incendie à l'échelle des quartiers pour l'ensemble de la province de la Colombie-Britannique. L'objectif est de peaufiner le produit pilote et de faire progresser la Base de données nationale sur les incendies afin que les autres provinces et territoires puissent également visualiser leurs données.

Les personnes appartenant à des groupes désignés comme minorités visibles considèrent que leur quartiers sont moins sécuritaires pour les personnes ayant une couleur de peau, une origine ethnique ou une religion différente.
Source : Statistique Canada, Portrait de la société canadienne – Les expériences pendant la pandémie, 2021.
Les enquêtes par panel en ligne nécessitent la création d'un bassin de personnes qui sont d'accord pour répondre à une série d'enquêtes en ligne sur une période déterminée au préalable. Statistique Canada a continué de mettre à l'essai cette méthode de collecte en lançant avec succès sa deuxième série d'enquêtes par panel en ligne, Portrait de la société canadienne; deux diffusions ont eu lieu en septembre 2021. La première enquête de la série porte sur les perceptions de la vie pendant la pandémie, et la deuxième, sur les expériences vécues pendant la pandémie.
Statistique Canada utilise des liens vers des sources de données fiscales et administratives pour améliorer l'ensemble actuel de données sur l'incapacité, y compris des renseignements provenant de programmes de soutien gouvernementaux, comme le crédit d'impôt pour personnes handicapées et le régime enregistré d'épargne-invalidité. Des données administratives sur les immigrants reçus (données sur l'établissement) ont été ajoutées à la Base de données longitudinales sur l'immigration.
L'organisme a également travaillé avec des partenaires fédéraux pour voir comment on pourrait mieux comprendre l'ampleur de la traite des personnes, qui fait un nombre disproportionné de victimes chez les femmes. Plus particulièrement, Statistique Canada a codirigé un groupe de travail sur les données sur la traite des personnes avec Sécurité publique Canada afin d'explorer la meilleure façon d'utiliser les ensembles de données administratives détenues par d'autres organismes gouvernementaux.
Le Secrétariat du Conseil du Trésor a reconnu Statistique Canada comme l'organisme ayant obtenu les meilleurs résultats pour l'expérimentation en 2021, mentionnant tout particulièrement son Conseil de recherche et développement comme pratique exemplaire à l'échelle de l'organisme pour la gouvernance de l'innovation, dans le cadre du processus d'évaluation du Cadre de responsabilisation de gestion. Les exemples qui suivent sont dignes de mention pour 2021-2022 :
 Collaborer avec les partenaires et les mobiliser
Collaborer avec les partenaires et les mobiliserEn 2021-2022, Statistique Canada a élargi son engagement auprès de partenaires clés afin de veiller à ce que les données recueillies auprès de ses partenaires et avec ceux-ci ajoutent de la valeur à l'écosystème de données et l'enrichissent, sur la base d'une utilisation responsable, de la confiance, de la protection de la vie privée et de la confidentialité. Cette collaboration comprenait :
« Statistique Canada est fier de s'appuyer sur une solide base de collaboration avec la Fédération canadienne des municipalités et ses membres afin de mieux comprendre les besoins des collectivités d'un océan à l'autre. Alors que nous travaillons tous pour faire face aux répercussions sociales et économiques de la COVID-19, il est plus important que jamais de chercher collectivement des solutions fondées sur des données qui fonctionnent pour les familles, les entreprises et les différentes communautés. »
Anil Arora,
Statisticien en chef du Canada
Statistique Canada a renforcé son partenariat avec la Fédération canadienne des municipalités, afin de mieux faire connaître les renseignements fondés sur des données dans la prise de décisions fondées sur des données probantes et d'aider l'organisme à mieux comprendre les besoins en données des collectivités de toutes les tailles. Par exemple, le projet de données de la Ville de Vancouver est une initiative pilote dont les principaux jalons comprenaient :
Dans le cadre de sa collaboration continue avec les ministères et organismes fédéraux, Statistique Canada demeure un chef de file de la gérance des données en veillant à ce que la fonction publique fédérale puisse régir et gérer efficacement ses actifs en données afin de mieux servir la population canadienne.
Statistique Canada a entrepris de nombreux projets en 2021-2022 pour appuyer les ministères et organismes fédéraux dans leurs efforts en vue d'utiliser les données comme actif stratégique.


| Langues cries | Langue parlée à la maison | |
|---|---|---|
| Langues cries | 78 025 | 83 960 |
| Inuktitut | 36 185 | 39 030 |
| Ojibwé | 20 470 | 21 805 |
| Oji-cri | 13 635 | 13 855 |
| Oji-cri | 11 320 | 11 785 |
| Source: Statistique Canada, Recensement de la population de 2016. | ||
Statistique Canada appuie les organisations et les communautés autochtones qui mettent en place l'infrastructure et acquièrent les compétences nécessaires à l'élaboration et au maintien de programmes statistiques fondés sur leurs besoins. En 2021-2022, l'organisme a rencontré des organisations autochtones pour discuter des données et de la recherche sur les Autochtones et a facilité l'examen de 18 articles de recherche.
Statistique Canada a également amélioré l'accès à ses actifs en données pour les organisations et les communautés autochtones. L'organisme a notamment créé un portail de données autochtones sur son site Web pour permettre aux utilisateurs de trouver, d'utiliser et de partager facilement des statistiques sur des sujets clés et des projections démographiques pour les Autochtones au cours des prochaines décennies. L'organisme a aussi fourni des avis de diffusion de contenu autochtone dans des recherches et des tableaux publiés dans un bulletin mensuel destiné aux organisations autochtones.
Statistique Canada a continué de fournir du soutien aux provinces et aux territoires dans leur lutte contre la COVID-19 en assurant une capacité de mobilisation pour la recherche de contacts et les activités de suivi. L'organisme a aussi effectué des appels au nom de l'Agence de la santé publique du Canada pour l'aider à surveiller les déplacements et à assurer le suivi des séjours d'hébergement approuvés par le gouvernement. À la fin de 2021-2022, l'équivalent de 2,7 millions d'appels de 15 minutes avaient été faits auprès des Canadiennes et des Canadiens.
 Coopération internationale, renforcement des capacités statistiques et promotion de la littératie des données
Coopération internationale, renforcement des capacités statistiques et promotion de la littératie des donnéesGrâce à de nouveaux partenariats, Statistique Canada a appuyé des initiatives visant à s'assurer que les diverses communautés peuvent créer et maintenir des programmes statistiques fondés sur leurs besoins particuliers. Les exemples d'initiatives de mobilisation externe visant à renforcer la capacité statistique et la littératie des données allaient de la coopération internationale à des cours de formation pour aider les utilisateurs à comprendre l'utilisation des données.

À titre d'organisme national de statistique de renommée mondiale, Statistique Canada agit comme chef de file des pratiques exemplaires sur la scène internationale et veille à leur application. Entre autres initiatives internationales de leadership, des membres de l'organisme président :
Statistique Canada a respecté les normes internationales en matière de données afin de créer et de partager des données, et de les intégrer aux données des partenaires et à d'autres formes de données accessibles au public. En adoptant de nouvelles normes, l'organisme s'est assuré de promouvoir l'interopérabilité des données, un principe important des principes FAIR selon lesquels l'information doit être facile à trouver, accessible, interopérable et réutilisable, et de servir de catalyseur pour les analyses favorisant l'intégration. L'organisme a toujours adopté de nouvelles versions de normes ouvertes, comme l'Échange de données et de métadonnées statistiques, améliorant ainsi la façon dont il décrit et échange les données (y compris les données géospatiales) et les renseignements avec ses partenaires et la communauté d'utilisateurs.
Statistique Canada a continué de jouer un rôle de chef de file au sein du Réseau de recherche fondamentale de la CEE-ONU. Il a poursuivi la mise sur pied du groupe de travail sur les données synthétiques du Réseau, groupe qui compte plus de 25 participants provenant de 9 organismes nationaux de statistique.
En outre, Statistique Canada est devenu membre du Comité directeur du Congrès mondial de la statistique de 2023 et copréside le conseil consultatif national de l'événement. À cet égard, les principales activités de Statistique Canada consisteront à fournir un soutien aux organisateurs en ce qui concerne les commanditaires, le marketing local et national, et les bénévoles. L'organisme ajoutera également une saveur canadienne à l'événement.

Depuis 2015, Statistique Canada joue un rôle de chef de file au sein du Groupe d'experts des Nations Unies et de l'extérieur chargé des indicateurs relatifs aux objectifs de développement durable (ODD). L'organisme a continué de collaborer étroitement avec des partenaires fédéraux essentiels pour faire progresser les Carrefour de données liées aux objectifs de développement durable (ODD), en partageant un code ouvert pour la mesure des progrès relatifs aux ODD, dans le cadre de l'initiative ouverte des ODD. Statistique Canada a joué un rôle de premier plan dans l'établissement du Cadre d'indicateurs canadien afin de mesurer les progrès au pays. Il a aussi créé un carrefour de visualisation des données novateur pour rendre les données sur les ODD plus attrayantes et accessibles pour les Canadiennes et les Canadiens.
Les pays dont les systèmes statistiques sont moins rigoureux ne disposent pas des données nécessaires à la prise de décisions judicieuses en matière de politiques, ce qui fait en sorte qu'il leur est plus difficile de surmonter une crise. C'est la raison pour laquelle Statistique Canada a offert de la formation et du soutien aux pays en développement pour leur permettre de bâtir, de maintenir et d'améliorer leurs systèmes statistiques nationaux. Par exemple, en 2021-2022, Statistique Canada a aidé les organismes nationaux de statistique des Caraïbes à créer et à améliorer leurs sites Web et leurs mécanismes de diffusion.
Statistique Canada a établi un cadre de calibre mondial pour protéger et traiter les données en toute sécurité, sans compromettre la confidentialité des renseignements et la confiance des Canadiennes et des Canadiens. Le système de l'organisme comporte un équilibre entre la gouvernance interne et les conseils externes d'organismes de gouvernance, comme le Comité ministériel de vérification et le Conseil consultatif canadien de la statistique (CCCS), afin d'assurer à la population canadienne que la protection des renseignements personnels et la confidentialité sont enchâssées dans tout ce que l'organisme produit.
En 2021-2022, le CCCS a diffusé son deuxième rapport, intitulé Consolider les fondations de notre système national de statistique. Le rapport présente trois grandes recommandations :
L'organisme a commencé à intégrer les conseils du CCCS dans ses actions et continuera de mettre en œuvre ses recommandations. Il continuera en outre de collaborer étroitement avec ses partenaires, à l'intérieur et à l'extérieur du gouvernement fédéral, pour réaliser des progrès tangibles concernant les recommandations.
Le Cadre de nécessité et de proportionnalité a été élaboré pour faire en sorte que Statistique Canada recueille uniquement l'information nécessaire pour produire des données à jour de grande qualité, tout en protégeant complètement la vie privée des Canadiennes et des Canadiens et en assurant la sécurité des données recueillies.
En 2021-2022, ce cadre a été amélioré afin de tenir compte plus explicitement des principes d'éthique, des protocoles et de la mobilisation du public qui régissent la collecte de données de nature délicate. Le Cadre de nécessité et de proportionnalité 2.0 comporte davantage de contexte historique que le cadre original et en est actuellement à l'étape de l'évaluation par les pairs et de la révision institutionnelle. Il fournit des directives plus détaillées aux gestionnaires de programme de Statistique Canada sur les activités de collecte des données et il est révisé pour continuer de se conformer aux lois canadiennes sur la protection de la vie privée, au fur et à mesure de leur mise à jour.
La nouvelle Infrastructure sécurisée pour l'intégration des données de Statistique Canada est un ensemble de méthodes, de technologies et de protocoles élaborés pour améliorer la façon dont l'organisme combine ses données existantes avec celles provenant d'autres organisations, tout en assurant la protection des renseignements personnels et la confidentialité. En créant un environnement sécuritaire pour combiner les données, l'organisme maximise l'information à sa disposition. Cela peut contribuer à bâtir un Canada plus équitable en assurant la justice et l'inclusion dans le processus décisionnel.
Statistique Canada met continuellement à jour ses politiques pour tenir compte de l'environnement statistique actuel. Par exemple, l'organisme a adopté un nouveau plan de gestion des ressources informationnelles, entérinant la façon dont il protège l'authenticité, la fiabilité, l'intégrité et la convivialité de ses renseignements et de ses données, au fil du temps. Les modifications apportées aux politiques améliorent la position de risque de l'organisme et garantissent davantage la sécurité des renseignements que lui confient les Canadiennes et les Canadiens.
Le Projet de gestion intégrée de l'information et des données vise à établir un cadre moderne qui améliorera de façon importante les processus et la gouvernance des actifs en données et des fonds de renseignements passés, présents et futurs de l'organisme. Le projet continue de mobiliser les intervenants, afin d'atteindre ses objectifs visionnaires.
Statistique Canada dirige l'élaboration des indicateurs du Cadre de qualité de vie. Ce cadre, qui a été annoncé dans le budget de 2021, vise à contribuer à la modernisation du système de statistiques nationales sur la qualité de vie et son cadre conceptuel connexe, et il aidera le gouvernement du Canada à tenir compte de tous les aspects de la qualité de vie des Canadiennes et des Canadiens dans ses décisions. La version bêta du Carrefour de la qualité de vie a été diffusée en mars 2022 et comporte des métadonnées, des données et des visualisations des 20 indicateurs principaux du Cadre de qualité de vie.

Appuyé par une base d'intendance, métadonnées, normes et qualité
Statistique Canada continue d'appuyer la littératie des données auprès de ses nombreux intervenants dans le cadre de l'Initiative de formation en littératie des données, qui continue de croître et comprend 16 nouvelles vidéos de formation publiées au cours du présent exercice, qui couvrent huit nouveaux sujets. Toutes ces vidéos, ainsi que la nouvelle version de l'outil de formation intitulé « Les statistiques : le pouvoir des données! », conçu pour aider les élèves et les enseignants du secondaire à tirer le meilleur parti des statistiques, sont disponibles gratuitement dans le catalogue d'apprentissage de l'organisme. À ce jour, l'Initiative de formation en littératie des données a enregistré plus de 67 000 visiteurs et 150 000 pages vues.
L'organisme a établi un partenariat avec Apolitical pour lancer une formation intensive sur la littératie des données. Le déploiement complet a eu lieu en octobre 2021. Ce cours est le premier en son genre. Jusqu'à présent, il a été suivi par plus de 5 000 fonctionnaires de centaines d'organismes gouvernementaux, et 95 % des apprenants ont convenu que leurs compétences en matière de données se sont améliorées. Statistique Canada a reçu le Prix de l'équipe mondiale de la fonction publique de l'année 2021 dans la catégorie « Champions des données et du numérique » d'Apolitical pour ses travaux sur la littératie des données.
À l'appui de la littératie des données, le module « Les statistiques : le pouvoir des données! » du site Web de l'organisme a été mis à jour pour rendre compte des changements dans l'écosystème de données. En 2021-2022, plusieurs séminaires liés à la qualité et à l'éthique des données ont été offerts à l'intention d'intervenants de l'extérieur de l'organisme.
 Instaurer une culture de souplesse et bâtir un effectif flexible
Instaurer une culture de souplesse et bâtir un effectif flexibleAu cours de la dernière année, Statistique Canada a tiré parti du succès de son initiative intitulée « Effectif moderne et milieu de travail flexible ». L'organisme a poursuivi un modèle hybride qui améliorera les services et la valeur pour la population canadienne, en :

Dans le cadre de ses efforts continus pour veiller à ce que les modalités de travail hybride soient équitables pour tous les membres du personnel, l'organisme a réalisé des progrès sur différents fronts au cours de la dernière année.

Statistique Canada assure un suivi continu de son environnement interne et externe afin d'élaborer des stratégies d'atténuation des risques. L'organisme a déterminé les risques liés à ses responsabilités de base et a établi des stratégies pour les années qui viennent. C'est la raison pour laquelle Statistique Canada continuera d'adapter et de faire évoluer ses instruments directeurs et ses cadres de supervision, ainsi que de collaborer de façon proactive avec les Canadiennes et les Canadiens, grâce à des communications claires, transparentes et proactives. Il doit aussi continuer d'investir dans une infrastructure rigoureuse, tant sur le plan de la technologie que de la méthodologie, afin d'assurer la fiabilité, l'actualité, la variabilité dimensionnelle et la sécurité de ses statistiques. L'organisme a déterminé six risques ministériels et des stratégies d'atténuation correspondantes.
Le maintien de l'exactitude et de l'intégrité des données et des fonds de renseignements, y compris la prévention des erreurs majeures, entre souvent en conflit avec les pressions exercées, telles que la nécessité de produire des renseignements plus rapidement et dans des environnements de production de plus en plus complexes, l'utilisation croissante de sources de données multiples et de nouvelles techniques, et l'augmentation des demandes de renseignements.
Parmi les activités d'atténuation des risques, Statistique Canada a effectué des analyses approfondies et une validation systématique, a amélioré les renseignements spécialisés, a mis en œuvre des améliorations liées au processus, a mobilisé les intervenants clés aux fins de la validation, a mis à l'essai de façon rigoureuse les nouveaux processus et a amélioré ses pratiques de gestion de l'information.
Des mesures de contrôle et de protection rigoureuses sont essentielles pour gérer de façon sécuritaire la quantité considérable de renseignements confidentiels et de nature délicate dont est responsable l'organisme et pour protéger ces renseignements contre les atteintes à la vie privée, la divulgation illicite et les menaces à la cybersécurité.
Outre sa culture et ses valeurs bien ancrées, l'organisme dispose de mécanismes et de processus de surveillance et de gouvernance qui permettent d'atténuer ce risque. L'organisme continue de faire preuve de vigilance en passant en revue de façon proactive les processus et les procédures liés à la confidentialité, en mettant en place la stratégie et la feuille de route de Statistique Canada en ce qui concerne la cybersécurité, et en appliquant des mesures de protection rigoureuses (p. ex. la Politique sur la diffusion officielle). Les mesures clés comprennent le fait d'évaluer régulièrement la situation en matière de sécurité des technologies de l'information et d'offrir de la formation sur la protection de la vie privée et la confidentialité à son personnel et ses partenaires.
Dans le contexte du marché du travail très concurrentiel, l'organisme fait face à des risques inhérents liés à l'insuffisance des ressources humaines, de la capacité et de l'expertise qui lui sont nécessaire pour mener à bien son vaste mandat et répondre à son large éventail de priorités.
Des stratégies d'atténuation concernant les ressources humaines ont été mises en place et comprennent l'augmentation de l'utilisation de programmes d'affectation souples, la poursuite d'une stratégie d'embauche à l'échelle nationale et l'élaboration d'une nouvelle stratégie intégrée en matière de ressources humaines axée sur la création d'un effectif diversifié, inclusif et bilingue. L'organisme a également mis en œuvre des fonds de démarrage et des cadres pour de nouvelles idées afin de réduire les risques et d'optimiser l'affectation des ressources, a encouragé le développement conjoint avec les citoyens et a poursuivi la migration de l'organisme vers l'infonuagique, ce qui permet d'accéder à des capacités et des solutions autonomes, sur demande et modulables concernant l'infrastructure.
Les demandes externes croissantes découlant d'un environnement en constante évolution peuvent nécessiter des modifications pour assurer la pertinence des programmes.
Pour atténuer ce risque, Statistique Canada a lancé son initiative de modernisation fondée sur la prestation de services axés sur l'utilisateur. En écoutant les Canadiennes et les Canadiens au moyen de nombreux mécanismes, y compris la mobilisation des intervenants, les comités consultatifs, les sondages et la surveillance des médias, l'organisme leur a fourni les renseignements dont ils avaient besoin, au moment où ils en avaient besoin et de la façon dont ils le souhaitaient. Les résultats comprennent un accès plus facile et élargi à des statistiques plus à jour et plus précises.
Comme l'initiative de modernisation de l'organisme est complexe et de grande envergure, il y a un risque que ses objectifs ne soient pas atteints en temps opportun et que les attentes accrues des utilisateurs ne soient pas satisfaites.
Pour atténuer ce risque, Statistique Canada a établi une gouvernance plus ferme et a mis en œuvre des processus opérationnels intégrés afin d'assurer une planification et une surveillance des activités plus harmonisées et efficaces. En outre, l'organisme a exploré d'autres sources de données ouvertes, a élaboré des indicateurs de la qualité et a déterminé et comblé les lacunes en matière de compétences. Il a également établi des relations stratégiques avec des partenaires clés et intensifié la mobilisation des utilisateurs en vue de mieux comprendre leurs besoins et de peaufiner la transformation.
Les violations des règles de protection des renseignements et la divulgation illicite de renseignements, les campagnes de désinformation et d'autres facteurs peuvent avoir une incidence sur la confiance du public à l'égard de l'organisme, ce qui pourrait amener la population canadienne à se tourner vers d'autres sources d'information.
L'atténuation des risques au sein de l'organisme comprenait de vastes activités de mobilisation auprès de la population canadienne et des communications ouvertes et transparentes pour démontrer aux Canadiennes et Canadiens de quelle façon les données de l'organisme ont une incidence sur leur vie et pour les sensibiliser aux dispositions très strictes de l'organisme en matière de protection de la confidentialité et de la vie privée. L'organisme a travaillé avec des experts du monde entier pour établir un équilibre entre le besoin en renseignements et la protection de la vie privée, et a mis en œuvre son nouveau Cadre de nécessité et de proportionnalité. Il a également continué à promouvoir le Centre de confiance de l'organisme sur son site Web.
La diffusion des données du principal produit de l'organisme — le recensement — a entraîné des répercussions sur les résultats de 2021-2022. La première année de résultats consiste en une série d'événements très attendus sous la forme de diffusions de données, qui sont extrêmement pertinentes pour la population canadienne. Statistique Canada a continué de donner suite à la demande d'information fondée sur des données probantes en produisant de nombreux produits statistiques nouveaux et d'actualité, qui ont été bien reçus par les Canadiennes et les Canadiens. Cette année, l'accent a été mis sur la collecte des données du recensement. L'organisme a atteint 7 des 10 cibles d'indicateurs de rendement pour 2021-2022, dont 4 ont été largement dépassées.
À l'approche de l'exercice 2022-2023, Statistique Canada continue d'intégrer l'information sur le rendement à ses processus décisionnels afin de s'assurer de continuer à fournir des données et des renseignements précieux pour la population canadienne, avec des ressources qui correspondent aux priorités du gouvernement.
Le tableau suivant montre, pour les renseignements statistiques, les résultats obtenus, les indicateurs de rendement, les cibles et les dates cibles pour 2021-2022, ainsi que les résultats réels pour les trois derniers exercices pour lesquels vous avez accès aux résultats réels.
| Résultats ministériels | Indicateurs de rendement | Cible | Date d'atteinte de la cible | Résultats réels 2019-2020 | Résultats réels 2020-2021 | Résultats réels 2021-2022 |
|---|---|---|---|---|---|---|
| Des renseignements statistiques de grande qualité sont à la disposition des Canadiennes et des Canadiens | Nombre de corrections apportées après la diffusion en raison de l'exactitude | 0 | 31 mars 2022 | 1 | 6 | 7Note de bas de tableau 1 |
| Pourcentage de normes internationales auxquelles Statistique Canada se conforme | 90 %Note de bas de tableau 2 | 31 mars 2022 | 88 % | 88 % | 88 % | |
| Nombre de produits statistiques accessibles sur le site Web | 41 800 | 31 mars 2022 | 37 254 | 40 738 | 43 184 | |
| Nombre de tableaux de données de Statistique Canada accessibles sur le Portail de données ouvertes | 7 750 | 31 mars 2022 | 7 386 | 7 755 | 8 088 | |
| Renseignements statistiques de grande qualité consultés par les Canadiennes et les Canadiens | Nombre de visites au site Web de Statistique Canada | 37 500 000 | 31 mars 2022 | 20 285 269 | 28 193 955Note de bas de tableau 3 | 45 972 326Note de bas de tableau 4Note de bas de tableau 5 |
| Pourcentage de visiteurs du site Web qui ont trouvé les renseignements qu'ils cherchaient | 78 % | 31 mars 2022 | 78 % | 77 % | 74 %Note de bas de tableau 6 | |
| Nombre d'interactions dans les médias sociaux | 2 900 000 | 31 mars 2022 | 521 441Note de bas de tableau 7 | 1 211 316Note de bas de tableau 3 | 13 174 481Note de bas de tableau 4Note de bas de tableau 5 | |
| Renseignements statistiques de grande qualité pertinents pour les Canadiennes et les Canadiens | Nombre de citations dans les médias sur les données de Statistique Canada | 74 000 | 31 mars 2022 | 56 921 | 253 171Note de bas de tableau 3 | 139 078Note de bas de tableau 5 |
| Nombre de citations dans des revues | 23 000 | 31 mars 2022 | 26 505 | 33 596Note de bas de tableau 3 | 40 248Note de bas de tableau 8 | |
| Pourcentage d'utilisateurs satisfaits des renseignements statistiques | 80 % | 31 mars 2022 | 80 % | 80 % | 80 % | |
|
||||||
Les renseignements sur les ressources financières, les ressources humaines et le rendement liés au Répertoire des programmes de Statistique Canada figurent dans l'InfoBase du GC.
Le tableau suivant montre, pour les renseignements statistiques, les dépenses budgétaires de 2021-2022, ainsi que les dépenses réelles pour cet exercice.
| Budget principal des dépenses 2021-2022 | Dépenses prévues 2021-2022 | Autorisations totales pouvant être utilisées 2021-2022 | Dépenses réelles (autorisations utilisées) 2021-2022 | Écart (dépenses réelles moins dépenses prévues) 2021-2022 | |
|---|---|---|---|---|---|
| Dépenses brutes | 855 425 655 | 855 425 655 | 972 123 133 | 920 977 524 | 65 551 869 |
| Revenus disponibles | -120 000 000 | -120 000 000 | -127 583 773 | -127 583 773 | -7 583 773 |
| Dépenses nettes | 735 425 655 | 735 425 655 | 844 539 360 | 793 393 751 | 57 968 096 |
Les renseignements sur les ressources financières, les ressources humaines et le rendement liés au Répertoire des programmes de Statistique Canada figurent dans l'InfoBase du GC.
Le tableau suivant indique, en équivalents temps plein, les ressources humaines dont le ministère a besoin pour s'acquitter de cette responsabilité essentielle en 2021-2022.
| Nombre d'équivalents temps plein prévus 2021-2022 | Nombre d'équivalents temps plein réels 2021-2022 | Écart (nombre d'équivalents temps plein réels moins nombre d'équivalents temps plein prévus) 2021-2022 | |
|---|---|---|---|
| Dépenses brutes | 6 026 | 7 186 | 1 160 |
| Revenus disponibles | -1 231 | -1 542 | -311 |
| Dépenses nettes | 4 795 | 5 644 | 849 |
L'écart entre les dépenses prévues et les dépenses réelles est attribuable à l'augmentation des ressources attribuées aux nombreuses nouvelles initiatives prévues dans le budget 2021. Ces initiatives comprennent de meilleures données pour de meilleurs résultats, le renforcement des soins de longue durée et des soins de soutien, l'amélioration des données sur l'état des entreprises et une meilleure compréhension de notre environnement.
Du financement a été reporté de 2020-2021, ce qui a permis à l'organisme de répondre aux besoins de ses programmes cycliques et d'investir dans ses plans stratégiques intégrés. Les augmentations salariales supplémentaires, la rémunération rétroactive et les autres paiements découlant de la ratification des conventions collectives sont inclus.
Les augmentations sont en partie compensées par un report de budget à 2022-2023.
De plus, le nombre d'équivalents temps plein varie légèrement en raison de l'écart entre les taux de salaires réels versés et les taux de salaires moyens estimés utilisés pour prévoir les dépenses.
Les renseignements sur les ressources financières, les ressources humaines et le rendement liés au Répertoire des programmes de Statistique Canada figurent dans l'InfoBase du GC.
On entend par services internes les groupes d'activités et de ressources connexes que le gouvernement fédéral considère comme des services de soutien aux programmes ou qui sont requis pour respecter les obligations d'une organisation. Les services internes désignent les activités et les ressources des 10 catégories de services distinctes qui soutiennent l'exécution des programmes au sein de l'organisation, sans égard au modèle de prestation des services internes de l'organisation. Les 10 catégories de services sont les suivantes :
Les services internes de Statistique Canada ont participé à la réponse de l'organisme à la COVID-19. Cela comprenait la prestation de programmes essentiels à la mission et l'adaptation des pratiques pour appuyer le Recensement de 2021, tout en maintenant la sécurité et la santé des membres du personnel, ainsi que des plans et des activités, comme des plans de retour au bureau et de la formation sur la santé mentale et le bien-être.
L'organisme entend offrir un milieu de travail diversifié, inclusif, respectueux et sain, qui fait preuve de souplesse et d'adaptabilité. Pour appuyer cette vision, l'accent a été mis sur la mise en œuvre de stratégies et de nouvelles initiatives en réponse aux résultats des sondages menés auprès du personnel et des groupes de discussion. Les stratégies relatives aux services internes touchent les domaines suivants :
Statistique Canada a mis à jour son Plan intégré des activités et des ressources humaines pour 2021 à 2024 afin de rendre compte de ses engagements de renforcer la diversité et l'inclusion, de cerner les domaines où les programmes et les services des ressources humaines devraient continuer d'évoluer, en fonction des besoins émergents qui se manifestent en raison des perturbations et du rythme de changement découlant de la pandémie de COVID-19, ainsi que de se tenir au fait des objectifs, possibilités et défis opérationnels contemporains. Statistique Canada a fixé des objectifs stratégiques pour continuer à développer une main-d'œuvre souple et outillée :
Les autres domaines d'intérêt comprennent la création d'un effectif diversifié, la mise en place d'un milieu de travail inclusif et la promotion et le soutien d'un milieu de travail sain et sécuritaire sur les plans physique et psychologique. C'est la raison pour laquelle Statistique Canada a aussi lancé son nouveau Plan d'action en matière d'équité, de diversité et d'inclusion de 2021 à 2025 : Aller de l'avant ensemble.
Grâce au plan, la représentation des talents en matière d'équité dans chacun des groupes désignés s'est améliorée à l'échelle de l'organisme, y compris au niveau de la direction. L'organisme a déployé des efforts pour éliminer les obstacles à l'avancement professionnel auxquels font face les talents méritants sur le plan de l'équité, en prenant des mesures, comme accorder la priorité à la diversité dans la formation linguistique, lancer des processus de sélection ciblés et établir des partenariats avec des organisations externes, afin d'améliorer le recrutement de talents en matière d'équité. Les taux de promotion des groupes racisés ont augmenté, et le maintien en poste des talents s'est amélioré. En 2020-2021, parmi les membres du personnel qui ont été promus, 16 % se sont identifiés comme membres d'un groupe racisé; ce chiffre est passé à 23 % en 2021-2022. Cet accent accru sur le maintien en poste s'est traduit par une augmentation de 24 % des employées et employés racisés qui sont demeurés en poste.
L'élaboration d'un Cadre de mesure de l'accessibilité a entraîné des réalisations importantes à ce chapitre. Ce cadre, qui met l'accent sur les environnements bâtis, les services, la technologie, la culture, l'emploi et les mesures d'adaptation en milieu de travail, détermine les obstacles et mesure les progrès vers l'atteinte d'un milieu de travail entièrement accessible et d'un effectif inclusif qui appuie la participation de l'ensemble du personnel. Statistique Canada a aussi lancé son étude intitulée « Mobiliser l'innovation culturelle des personnes en situation de handicap », un projet de recherche novateur utilisant diverses méthodes et conçu pour déterminer et faire ressortir les obstacles dans les systèmes d'emploi et les processus d'adaptation.
Le Groupe consultatif sur le développement des talents de Statistique Canada a été créé en juin 2021 et son cadre est actuellement en voie d'élaboration. Un examen des principaux programmes de recrutement et de perfectionnement de Statistique Canada a été lancé afin de maintenir la compétitivité de l'organisme et de mieux refléter ses besoins changeants, ainsi que ceux de ses recrues, et ses secteurs d'activité.
L'organisme a également approuvé une stratégie de leadership renouvelée, qui s'harmonise avec les initiatives actuelles et futures (culture, valeurs, intégration, gestion des talents, reconnaissance, diversité, langues officielles et avenir du travail) et qui met l'accent sur l'appropriation et l'autonomisation, où tous les membres du personnel, des recrues aux cadres supérieurs, ont la possibilité de se perfectionner et de devenir des leaders.
En 2021-2022, divers outils d'analyse des données ont été utilisés aux fins des ressources humaines. Les données du Sondage sur le mieux-être des employés ont été recueillies et couplées aux bases de données administratives sur les ressources humaines afin d'examiner le lien qui existe entre les facteurs et les comportements. De plus, afin de planifier la configuration optimale des modalités de travail suivant la pandémie, le Sondage éclair sur la COVID-19 et ses répercussions sur les employés de Statistique Canada a été mené en avril 2021 pour comprendre les souhaits du personnel quant au retour au bureau et au télétravail.
Statistique Canada a approuvé une nouvelle approche axée sur les données pour le rendement des cadres supérieurs en janvier 2022, selon laquelle des indicateurs et des sources de données éclairés constituent le fondement des évaluations du rendement des cadres supérieurs, afin d'éliminer les préjugés dans le processus d'évaluation et de promouvoir l'uniformité à l'échelle de l'organisme. Une grille de performance a été établie à l'appui de cette nouvelle approche pour obtenir et présenter les cotes.
Au cours de 2021-2022, Statistique Canada s'est appuyé sur son cadre de planification des activités pour soutenir l'établissement de stratégies et la planification des investissements. En reconnaissance des progrès importants réalisés dans le cadre de son programme de modernisation, Statistique Canada a établi des stratégies visant à renforcer les partenariats, à améliorer la confiance de la population canadienne et à mettre l'accent sur la production de données intégrées et de renseignements exploitables.
Statistique Canada a profité de l'information fiable, neutre et objective fournie par la Direction de l'audit et de l'évaluation pour éclairer la prise de décisions. En 2021-2022, l'organisme a reçu des commentaires dans le cadre de projets d'audit et d'évaluation qui utilisaient une approche de plus en plus souple et ciblée. Ces renseignements et conseils opportuns, qui ont été fournis à des moments critiques aux premières étapes de la planification et de la mise en œuvre de nouvelles stratégies et initiatives de programme, comme la modernisation d'un milieu de travail hybride, ont appuyé les principales priorités de l'organisme.
La structure de gouvernance permet la production de données opérationnelles à jour, pertinentes, exploitables et intégrées pour appuyer la prise de décisions fondées sur les risques. Les réalisations en 2021-2022 comprennent la création du Cadre de gestion intégrée du risque et de la Politique de gestion intégrée des risques, qui servent de fondement à la gestion du risque et à la promotion d'une culture du risque dynamique et agile au sein de Statistique Canada.
Dans notre environnement en évolution axé sur le numérique, les solutions numériques ont joué un rôle clé dans la réussite de nombreuses initiatives dont il est question dans le présent rapport, grâce à la mise en place de technologies et d'une infrastructure fondamentales pour ces initiatives. Par exemple, le Secteur des solutions numériques de l'organisme a appuyé la réalisation du Recensement de la population et du Recensement de l'agriculture, et soutenu le lancement du Recensement de l'environnement. Il a fourni l'équipement et le soutien nécessaires à tous les membres du personnel qui travaillent à domicile dans le cadre du modèle hybride et a veillé à ce que les nouveaux produits de données liés à la COVID-19 soient disponibles pour appuyer la production de renseignements fondés sur des données et la prise de décisions fondées sur des données probantes.
En tant que chef de file de l'un des projets exploratoires sur l'infonuagique du gouvernement du Canada, Statistique Canada est particulièrement bien placé pour explorer, développer et adopter de nouvelles technologies. L'adoption de services et de technologies infonuagiques est un élément essentiel des efforts de modernisation de l'organisme, car elle lui permet d'obtenir des résultats mesurables dans le cadre de son travail quotidien.
Le projet de mise en œuvre des services infonuagiques et le projet de migration de la charge de travail sont des piliers essentiels qui permettent à l'organisme de faire évoluer ses applications et ses services, à l'appui de son mandat visant un modèle d'infrastructure plus évolutif et moderne. Ces projets se poursuivront en 2022-2023. Dans cet environnement, la plateforme et les services d'analyse des données ont fourni aux partenaires clés et à la population de nombreux nouveaux produits et services, ce qui a grandement contribué à la prise de décisions éclairées par les données pendant la pandémie et a continué d'appuyer le programme de modernisation de l'organisme pour l'avenir. Grâce à la plateforme et aux services que l'organisme a mis en place, les membres du personnel disposent des outils nécessaires pour aller de l'avant avec succès dans le cadre d'initiatives clés de numérisation, comme l'Initiative de modernisation de l'analyse des données.

L'organisme s'est associé au Centre canadien d'innovation pour la santé mentale en milieu de travail afin d'offrir des ateliers en ligne à l'ensemble du personnel. En 2021-2022, 2 263 personnes ont participé à environ 75 ateliers et séances portant sur des sujets comme la santé mentale, l'avenir du travail, la diversité et l'inclusion. L'accent mis sur le mieux-être cette année a fourni l'occasion d'offrir des ressources en santé mentale et de la formation aux gestionnaires, y compris de la formation de premiers soins en santé mentale, la formation intitulée « L'esprit au travail pour les gestionnaires », des séances d'information à l'interne sur des sujets précis adaptés aux besoins de chaque division, ainsi que d'accueillir des conférenciers invités de divers horizons, y compris le Bureau des conférenciers fédéraux pour des milieux de travail sains.
Afin d'appuyer la santé psychologique du personnel, l'Équipe de la santé organisationnelle de Statistique Canada a lancé la première version du Sondage sur le mieux-être des employés, en novembre 2021. Le sondage a permis de brosser un tableau complet de la santé psychologique du personnel et des facteurs clés qui peuvent éclairer les mesures fondées sur des données probantes à l'échelle de l'organisme.
Le tableau suivant présente, pour les services internes, les dépenses budgétaires en 2021-2022, ainsi que les dépenses pour cet exercice.
| Budget principal des dépenses 2021-2022 | Dépenses prévues 2021-2022 | Autorisations totales pouvant être utilisées 2021-2022 | Dépenses réelles (autorisations utilisées) 2021-2022 | Écart (dépenses réelles moins dépenses prévues) 2021-2022 |
|---|---|---|---|---|
| 66 905 037 | 66 905 037 | 100 209 616 | 89 989 424 | 23 084 387 |
Le tableau suivant présente, en équivalents temps plein, les ressources humaines dont le ministère a besoin pour fournir ses services internes en 2021-2022.
| Nombre d'équivalents temps plein prévus 2021-2022 | Nombre d'équivalents temps plein réels 2021-2022 | Écart (nombre d'équivalents temps plein réels moins nombre d'équivalents temps plein prévus) 2021-2022 |
|---|---|---|
| 563 | 713 | 150 |
L'écart entre les dépenses prévues et les dépenses réelles est principalement attribuable à l'augmentation des ressources destinées à une initiative sur la migration de l'infrastructure infonuagique de l'organisme, approuvée en 2018-2019, ainsi qu'aux dépenses supplémentaires liées au soutien interne en technologie de l'information.
Les investissements internes approuvés dans le cadre du Processus intégré de planification stratégique de l'organisme contribuent également à cette augmentation. Au cours des dernières années, les investissements étaient déclarés de façon centralisée dans le cadre des responsabilités essentielles des renseignements statistiques, et plus précisément du programme des centres d'expertise.
| Total des dépenses réelles pour 2021-2022 | Nombre réel d'équivalents temps plein pour 2021-2022 | |
|---|---|---|
| Total des dépenses brutes | 1 010 966 948 | 7 899 |
| Revenus disponibles | -127 583 773 | -1 542 |
| Total des dépenses nettes | 883 383 175 | 6 357 |
En 2021-2022, Statistique Canada a accru la vitesse à laquelle ses renseignements fondés sur des données sont fournis à la population canadienne pour répondre aux besoins changeants et appuyer une reprise inclusive et durable.
L'organisme a joué un rôle de premier plan dans les efforts du gouvernement visant à fournir des données désagrégées de grande qualité afin d'éclairer la prise de décisions fondées sur des données probantes et de fournir des données actuelles et des analyses en temps réel sur les répercussions de la pandémie de COVID-19. Parallèlement, l'organisme a aussi mené l'un des recensements les plus réussis de l'histoire, dans le but de brosser un portrait à jour et détaillé du Canada. Grâce au soutien, à la collaboration et à la sensibilisation des Canadiennes et des Canadiens à l'importance du recensement, le taux de participation au Recensement de la population de 2021 s'est élevé à 98 %. Par ailleurs, 84 % des répondants ont rempli leur questionnaire en ligne, ce qui représente un niveau record. Le taux de participation au Recensement de l'agriculture de 2021 s'est élevé à 86 % et le taux de réponse en ligne, à 86 % dans l'ensemble.
Les initiatives et les projets présentés dans ce rapport démontrent l'incidence que l'organisme a eue sur la vie de la population canadienne.
« Les membres de notre organisme ont su relever les défis posés par la pandémie et ont offert des produits et des services plus utiles que jamais. Nous demeurons des chefs de file à toutes les étapes de la chaîne de valeur des données et nous utilisons des méthodes modernes pour fournir, à partir de ces données, des renseignements utiles qui permettent d'améliorer véritablement la vie des Canadiennes et des Canadiens. »
Anil Arora
Statisticien en chef du Canada
Fidèle à sa philosophie de services axés sur les clients, Statistique Canada a mis au point des solutions numériques pour accroître l'accès sur demande à des données de grande qualité dans des formats conviviaux. L'organisme a également continué d'accroître la clarté et l'accessibilité de ses communications à l'ensemble de la population, et a trouvé des façons novatrices de présenter et de partager les données, ce qui en a facilité l'accès et l'utilisation. Voici des exemples de ces innovations :
Au cours de la dernière année, Statistique Canada a mis en œuvre des méthodes et des outils de calibre mondial pour intégrer les données provenant de multiples sources, dont les données administratives et d'autres données non traditionnelles. L'organisme a mis à profit son expertise pour répondre aux besoins croissants de la population et des entreprises en matière de renseignements statistiques détaillés, de grande qualité et plus actuels.
En 2021-2022, Statistique Canada a déterminé d'autres façons de collaborer avec des partenaires nouveaux et existants afin de s'assurer que des données supplémentaires provenant de diverses sources sont intégrées, et qu'un plus grand nombre d'utilisateurs disposent des renseignements dont ils ont besoin pour prendre des décisions fondées sur des données probantes.
Dans le cadre de l'engagement à renforcer la capacité statistique de concert avec ses partenaires et à promouvoir la littératie des données au sein de la population canadienne, Statistique Canada a maintenu une approche proactive pour encadrer l'utilisation des données comme actif stratégique, en mettant l'accent sur l'amélioration de la capacité des utilisateurs à prendre des décisions fondées sur les données, tout en indiquant la voie à suivre à l'échelle nationale et internationale.
Avant la pandémie, Statistique Canada avait amorcé une transformation importante pour moderniser l'organisme et améliorer la prestation de services de données à l'intention de la population canadienne. Cet exercice comprend l'utilisation d'outils comme l'infonuagique, les produits de visualisation des données et les outils analytiques pour améliorer la qualité et l'utilité des données et du matériel, afin d'appuyer un effectif flexible et mobile. Cela a permis à l'organisme de mobiliser son effectif en mars 2020 et de continuer à fournir aux Canadiennes et aux Canadiens des données essentielles pour éclairer leurs décisions pendant une crise nationale. Maintenant que le pays passe à la prochaine phase de la réponse à la pandémie et de la reprise, Statistique Canada demeure déterminé à poursuivre son parcours de modernisation, en investissant dans des outils de données modernes et un environnement de travail hybride, afin d'améliorer l'expérience du personnel, les opérations, les processus opérationnels et la productivité.
De plus, l'organisme a réalisé des progrès importants dans la mise en œuvre de son Plan d'action en matière d'équité, de diversité et d'inclusion, ce qui aidera à faire en sorte que Statistique Canada reflète véritablement les populations diversifiées qu'il sert.
Pour en savoir plus sur les plans, les priorités et les résultats atteints de Statistique Canada, consulter la section « Résultats : ce que nous avons accompli » du présent rapport.

Je suis heureux de présenter les réalisations de Statistique Canada pour l'exercice 2021-2022 dans le présent Rapport sur les résultats ministériels.
Alors que le pays composait encore avec la pandémie de COVID-19 et d'autres défis, Statistique Canada a accéléré sa communication, aux Canadiennes et aux Canadiens, de renseignements fondés sur des données afin d'appuyer une reprise inclusive et durable.
Plus particulièrement, l'organisme a produit des résultats pour la population canadienne quant aux priorités suivantes pour 2021-2022 :
En plus de ses communications à grande vitesse et de sa diffusion de renseignements statistiques de grande qualité, l'engagement de Statistique Canada à l'égard de la protection des renseignements personnels et de la transparence continue d'être renforcé au moyen de cadres éthiques et de son Centre de confiance. J'invite les Canadiennes et les Canadiens à nous fournir leur rétroaction par l'intermédiaire du Centre de confiance et à en apprendre davantage sur la façon dont Statistique Canada recueille et utilise leurs données de façon responsable afin de leur fournir les données probantes dont ils ont besoin pour prendre des décisions éclairées.
Le niveau de réussite de Statistique Canada cette année n'aurait pu être atteint sans l'étroite collaboration des membres de nombreux groupes qui ont fourni des conseils et du soutien pour réaliser les travaux de l'organisme. J'aimerais remercier le Conseil consultatif canadien de la statistique, les comités consultatifs, les partenaires de tous les ordres de gouvernement ainsi que les secteurs privé, universitaire et sans but lucratif. Ils ont tous joué un rôle important dans les réalisations accomplies au cours de l'année écoulée.
L'accès à des données actuelles et exactes est plus essentiel que jamais pour déterminer si le Canada est sur la bonne voie, maintenant que le pays, ainsi que son économie et sa société, se remettent graduellement de la pandémie.
Anil Arora
Statisticien en chef du Canada

Nous sommes heureux de vous présenter le Rapport sur les résultats ministériels 2021-2022 de Statistique Canada.
Au cours de la dernière année, les diverses organisations du portefeuille d'Innovation, Sciences et Développement économique (ISDE) ont travaillé ensemble sans relâche pour positionner le Canada comme chef de file mondial en matière d'innovation et façonner une économie qui profite à tout le monde.
Dans le cadre du portefeuille d'ISDE, Statistique Canada a conservé son rôle de premier plan en ce qui concerne l'intendance des données au sein de la fonction publique fédérale et a veillé à ce que les ministères et organismes soient en mesure de régir et de gérer efficacement leurs actifs en données afin de mieux servir la population canadienne. Nous sommes ravis de voir comment l'organisme a innové et exploité ses plans de modernisation pour renforcer les capacités et les cadres statistiques.
En 2021-2022, Statistique Canada a accéléré la communication de renseignements fondés sur des données afin de répondre aux besoins changeants des Canadiennes et Canadiens en matière de données et de prise de décisions pour ainsi favoriser une reprise plus verte et inclusive. L'organisme a également terminé avec succès le Recensement de 2021, dont les résultats répondront aux besoins de la population canadienne et éclaireront les décisions stratégiques dans les années à venir. Les efforts déployés par l'organisme en vue d'améliorer la qualité et la disponibilité des données désagrégées permettront à toutes les communautés de tirer parti des décisions stratégiques.
Nous vous invitons à lire ce rapport pour découvrir comment Statistique Canada, à l'instar d'ISDE et d'autres partenaires du portefeuille, travaille avec les Canadiennes et Canadiens — et pour eux — afin de faire du Canada un leader mondial sur le plan économique.
L'honorable François-Philippe Champagne,
Ministre de l'Innovation, des Sciences et de l'Industrie
Lettre de mandat du ministre de l'Innovation, des Sciences et de l'Industrie


