
Par : Divita Narang, Agence de la consommation en matière financière du Canada
Introduction
À l’ère moderne, l’intégration continue et le déploiement continu (CI/CD) sont des pratiques essentielles de génie logiciel et d’ingénierie des données qui permettent de simplifier le développement et la livraison grâce à l’automatisation. Ces méthodologies jouent un rôle clé dans l’atteinte de la maturité technique et dans la mise à l’échelle des projets (passage d’un environnement de validation de principe à un environnement de production).
Lorsque ces pratiques sont mises en application dans l’écosystème d’Azure (Azure Data Factory [ADF] et Azure DevOps) ou d’un autre fournisseur de boîte à outils ou d’infonuagique de votre choix, elles permettent aux équipes d’automatiser le déploiement de pipelines de données, de jeux de données, de variables, et de ressources connexes, ce qui permet de faire des mises à jour plus rapides, de gérer les versions et d’assurer l’uniformité des environnements tout au long du cycle de vie du développement.
Azure Data Factory (ADF) est un service d’infonuagique géré qui est conçu pour les processus complexes (extraction-transformation-chargement [ETL], extraction-chargement-transformation [ELT], et intégration de données). Ce service aide les utilisateurs à orchestrer les mouvements de données à vaste échelle au moyen d’un large éventail de fonctionnalités et de connecteurs intégrés tout en garantissant la sécurité grâce à des groupes Microsoft Entra (en anglais seulement) intégrés. ADF est conçu pour répondre efficacement aux besoins des organisations, par exemple déplacer des données d’un point A vers un point B tout en apportant des changements comme appliquer des formats et des types de données et bien plus encore. Par exemple, ADF peut ingérer les données d’une application frontale destinée aux clients et les intégrer dans une base de données. Ce point de terminaison peut ensuite être utilisé pour divers cas d’utilisation en aval, par exemple pour les rapports, les analyses, l’apprentissage automatique, l’intelligence artificielle, etc.
Azure DevOps est la suite complète d’outils de Microsoft pour la gestion des versions, l’automatisation, et la gestion de projet. Ce logiciel peut stocker les référentiels Git dans Azure Repos et activer l’intégration continue et le déploiement continu (CI/CD) au moyen d’Azure Pipelines, qui est utilisé pour le déploiement de projets de code. Azure Pipelines combine l’intégration continue, la mise à l’essai continue et la livraison continue pour concevoir, tester et livrer le code à de multiples environnements de destination.
À l’Agence de la consommation en matière financière du Canada (ACFC), nous utilisons largement ADF et Azure Pipelines pour gérer l’intégration et le déploiement des ressources de données à destination et à partir de points de terminaison comme Microsoft Dataverse, API Microsoft Graph et les bases de données SQL Server. Notre équipe de données en pleine croissance explore constamment des approches innovantes pour l’exécution des processus d’ingénierie des données.
Récemment, nous avons relevé le défi d’automatiser les pipelines de déploiement pour ADF. Antérieurement, les processus manuels associés aux déploiements prenaient généralement beaucoup de temps, soit entre deux et quatre heures pour un référentiel de code de taille moyenne. Le code ne pouvait être téléversé dans le nouvel environnement que manuellement ou à l’aide de scripts PowerShell, le téléchargement pouvant durer jusqu’à quelques minutes pour chaque fichier. De plus, le code devait être nettoyé et préparé manuellement pour les nouveaux environnements. Nous nous attendions à ce que le temps nécessaire pour exécuter ces tâches augmente en raison de la croissance, au fil du temps, de la taille des bases de code au sein des projets. Veuillez noter que le temps de déploiement peut varier considérablement, ce qui dépend de la taille de la base de code et de divers autres facteurs (en anglais seulement).
Même si ces efforts d’automatisation nous facilitent la tâche, il convient de noter que les processus manuels peuvent toujours être utilisés comme solution de remplacement en cas d’indisponibilité de membres de l’équipe, ou d’échec de processus automatisés ne pouvant pas être rapidement rétablis.
Même si l’éventail des pratiques CI/CD est vaste, pour le reste du présent article, nous allons mettre l’accent sur l’intégration continue et le déploiement continu dans le contexte du déplacement de ressources d’Azure Data Factory d’un environnement de niveau inférieur, comme un environnement de développement, vers un environnement de niveau supérieur, comme un environnement de simulation ou de production. Les pipelines peuvent être exécutés manuellement, en fonction d’un calendrier, ou être déclenchés par une modification du référentiel, comme une validation et fusion (commit/merge) à une branche particulière.
Aperçu de la solution
Dans cet article, nous allons mettre l’accent sur la solution illustrée dans l’architecture suivante :
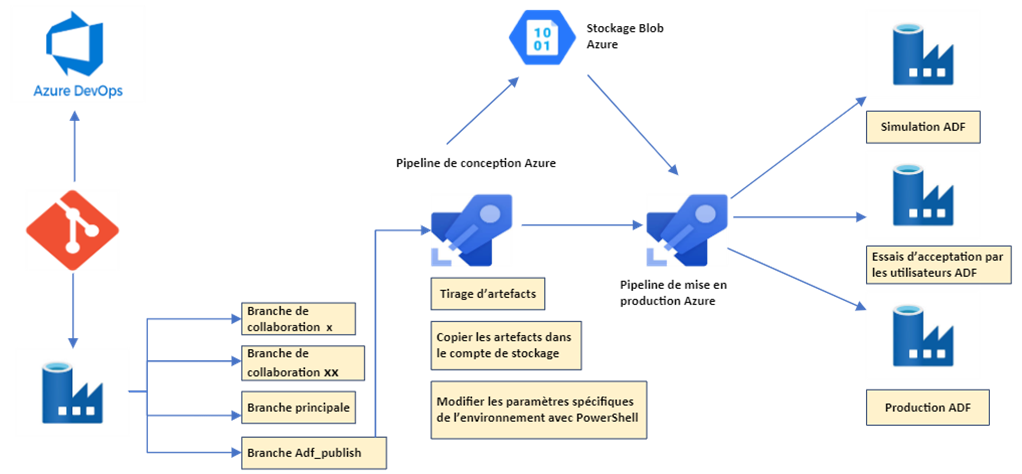
Figure 1 : Diagramme de l’architecture de la solution.
Description - Figure 1 : Diagramme de l’architecture de la solution.
Cette image montre l’architecture des composants Azure utilisés dans la solution, y compris Azure DevOps, Azure Data Factory, Azure Pipelines, et différents environnements (par exemple, un environnement de simulation, un environnement d’essais d’acceptation par les utilisateurs ou un environnement de production).
Remarque : Dans Azure Data Factory, le code est fondé sur les modèles Azure Resource Manager (ARM). Il s’agit essentiellement de l’infrastructure en tant que code dans le format JavaScript Object Notation (JSON) (en anglais seulement). Ces fichiers définissent l’infrastructure et la configuration pour les ressources d’Azure. Tout comme le code d’application, le code d’infrastructure peut être stocké et versionné dans un référentiel source.
Prérequis de la solution
- Contrôle de code source avec Git, fondé sur Azure DevOps
- Parallélisme d’agent de pipeline activé pour le projet Azure DevOps (formulaire de demande de parallélisme)
- Connexions de service sur Azure DevOps avec accès à des groupes de ressources pertinents où l’usine de données se trouve
- Services liés dans Azure Data Factory et autres données d’authentification pertinentes stockées sous forme de secrets dans Azure Key Vault
- Compte de stockage blob avec un accès en mode lecture et écriture pour stocker les modèles ARM
Intégration continue :
Les modifications aux codes sont publiées en utilisant le bouton de publication dans l’interface utilisateur d’ADF une fois le développement terminé sur la branche de collaboration et la demande de tirage exécutée sur la branche principale.
Lors de la publication, ADF prend en charge le processus de génération et de validation des modèles ARM. Les modèles générés contiennent toutes les ressources d’usine à données comme les pipelines, les jeux de données, les services liés, les environnements d’exécution d’intégration, les déclencheurs et plus encore. Toutes ces ressources sont susceptibles d’avoir des paramètres qui varient d’un environnement à l’autre. Ces paramètres doivent être attentivement validés, faute de quoi ils peuvent causer des erreurs de déploiement ou pire : un déploiement réussi avec des références incorrectes à des paramètres comme des données d’authentification inexactes pour un service lié (serveur SQL). Une bonne partie du temps consacré au développement a été utilisée pour trouver des solutions à ces difficultés, comme nous le verrons plus en détail dans les sections suivantes.
Configuration pour un pipeline de conception :
Pour la configuration d’un pipeline de conception, plusieurs tâches accessibles dans Azure Pipelines sont utilisées. Voici les étapes découplées :
- Obtenez des ressources dans le pipeline de votre référentiel (repo) d’Azure DevOps et (ce qui est très important) sélectionnez « adf_publish » comme branche par défaut.
- Utilisez la tâche « Publish Artifact » (publier l’artefact) pour déposer les artefacts à utiliser par le pipeline.
- Utilisez la tâche « PowerShell Script » pour exécuter un script afin de remplacer tous les paramètres, ce qui vise à assurer leur compatibilité avec l’environnement cible. Par exemple, si le nom de la base de données de développement est « Dev-DB » dans le code source et que l’environnement cible est un environnement de simulation avec un nom de base de données comme « Stg-DB », le script PowerShell peut exécuter un remplacement de chaîne dans tous les fichiers pour toutes les références à des variables afin de veiller à ce que la bonne base de données cible y soit reflétée. Veuillez consulter cet exemple de code (en anglais seulement) pour en savoir plus.
Conseil de pro : Les premiers modèles ARM comprennent beaucoup de paramètres, mais il est préférable d’exécuter le script sur chaque fichier de modèle ARM. Il existe également une méthode permettant de modifier les paramètres en utilisant la fonction « Override Parameters » (outrepasser les paramètres) dans la section de mise en production du pipeline, un sujet que nous aborderons plus loin dans cet article. - Utilisez la tâche « Azure File Copy » (copie de fichier Azure) pour copier tous les modèles du dossier « linkedTemplates » de votre référentiel dans un compte de stockage. Le stockage de modèles ARM dans le stockage blob crée une redondance pour le stockage d’un code modifié à l’étape 3, ce qui est souhaitable. Il s’agit également d’une pratique requise pour les bases de code de grande taille.
Conseil de pro : Nettoyez le conteneur de stockage avant de copier les modèles. De plus, créez des conteneurs distincts pour différents types d’environnements (simulation, essais d’acceptation par les utilisateurs, production, etc.), ce qui vous aidera à rester organisé et à réduire les risques de déploiement erroné.
Après la configuration, le pipeline aura à peu près l’air de ce qui suit :
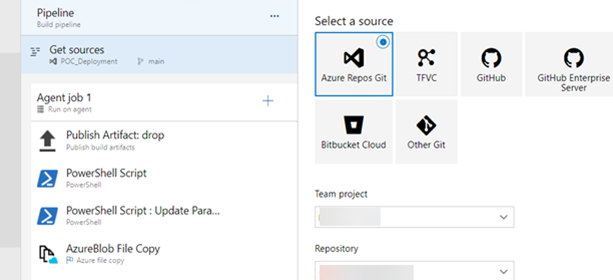
Figure 2 : Capture d’écran des composants du pipeline dans Azure DevOps (en anglais seulement)
Description - Figure 2 : Capture d’écran des composants du pipeline dans Azure DevOps
Cette image présente une section d’une interface de pipeline dans Azure DevOps. Elle comprend plusieurs étapes du pipeline de conception pour la solution décrite dans cet article. Ces étapes comprennent les suivantes : une tâche de dépôt — publication d’artefact (Publish Artifact: drop), deux tâches de script PowerShell et une tâche de copie de fichier Blob Azure.
Configuration pour un pipeline de mise en production :
- Créez une tâche vide en sélectionnant l’option « Empty job » dans la section « Releases » d’Azure DevOps.
- Ajoutez les artefacts du référentiel traités par le pipeline de conception créé précédemment.
- Cherchez et créez une tâche « PowerShell ». Indiquez le chemin d’accès au script de prédéploiement et de postdéploiement. Ce script est utilisé pour arrêter les déclencheurs avant le déploiement et les redémarrer après. Il est fourni par Microsoft : Scripts de prédéploiement et de postdéploiement CI/CD — Azure Data Factory | Microsoft Learn. Vous pouvez télécharger le script dans le référentiel du projet pour l’utiliser plus facilement.
- Cherchez et créez une tâche « ARM Template Deployment » (déploiement de modèle ARM) et remplissez les champs en fonction du pipeline précédent et de la configuration du projet.
- Dans la section « Override template parameters » (outrepasser les paramètres du modèle), des paramètres sont déjà téléchargés en fonction du fichier « ArmTemplateParameters_master.json » qui fait partie des artefacts du projet. Ces paramètres peuvent être personnalisés davantage en fonction du fichier de configuration « arm-template-parameters-definition.json » dans Azure Data Factory : Utiliser des paramètres personnalisés avec le modèle Resource Manager — Azure Data Factory | Microsoft Learn.
Si vous choisissez cette option, vous n’avez pas besoin d’exécuter l’étape 3 dans la configuration du pipeline de conception. Voici un exemple d’utilisation de paramètres personnalisés pour Stockage Blob Azure, Azure SQL Database et Dataverse (services de données communs pour les applications).

Figure 3 : Capture d’écran d’un exemple de code dans l’interface utilisateur d’Azure Data Factory
Description - Figure 3 : Capture d’écran d’un exemple de code dans l’interface utilisateur d’Azure Data Factory
Cette image présente un exemple de code dans le fichier « arm-template-parameters-definition.json » de l’instance Azure Data Factory. Il contient la configuration pour des ressources comme Stockage Blob Azure, Azure SQL Database et les services de données communs pour les applications, chacune ayant des propriétés et paramètres imbriqués, ce qui comprend un champ de valeur par défaut (« defaultValue »).
Cette approche pourrait ne pas être adaptée s’il y a plus de 256 paramètres, car il s’agit du nombre maximal permis. Si la refactorisation du code est une possibilité pour votre projet, prenez en considération les solutions de rechange suivantes :
- Réduisez le nombre de paramètres en utilisant des paramètres globaux dans la mesure du possible.
- Prenez note des paramètres qui sont implicitement hérités et retirez-les lorsqu’ils sont redondants. Par exemple, les paramètres de jeux de données sont hérités des services liés et il pourrait ne pas être nécessaire de les ajouter aux jeux de données s’ils sont déjà présents dans les services liés.
- Si vous ne jugez pas que cela va compliquer la maintenance et la création de nouvelles ressources, divisez la solution en de multiples usines de données pour les solutions de grande taille.
- Utilisez des scripts PowerShell pour nettoyer et préparer le code pour les différents environnements utilisés dans cette solution.
Après la configuration, le pipeline de mise en production aura l’air à peu près de ce qui suit :
Notez bien que la tâche de prédéploiement utilise le même script que la tâche de postdéploiement, mais que les arguments de script sont différents.
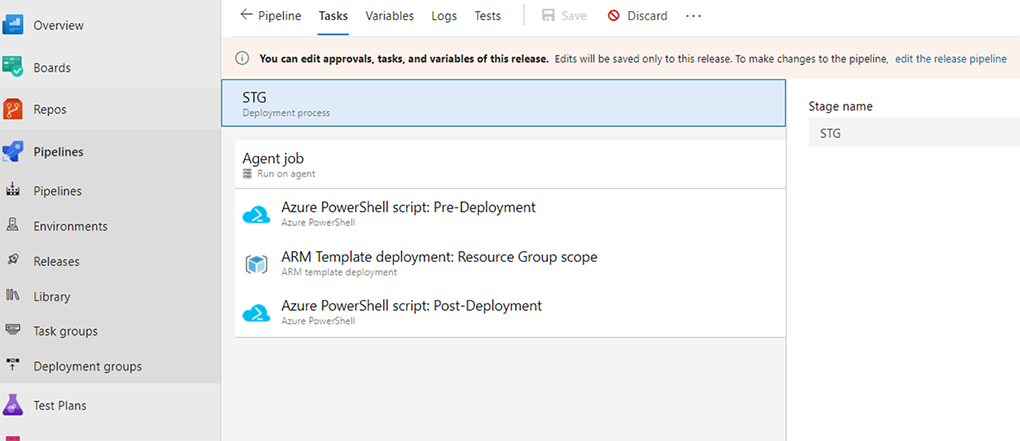
Figure 4 : Capture d’écran des composants du pipeline dans Azure DevOps (en anglais seulement)
Description - Figure 4 : Capture d’écran des composants du pipeline dans Azure DevOps
Cette image présente les différentes étapes du pipeline de mise en production dans Azure DevOps, lesquelles comprennent les tâches de script de prédéploiement et de postdéploiement de PowerShell ainsi qu’une tâche de déploiement de modèle ARM.
Dépannage, mise à l’essai et quelques autres conseils de pro :
- Pour commencer à mettre à l’essai la nouvelle solution, il peut être utile de créer une usine de données test et de la déployer dans Azure Data Factory pour s’assurer que tous les paramètres sont copiés correctement et que les connexions de services liés et de jeux de données fonctionnent bien.
- Pendant et après les déploiements : surveillez la journalisation au niveau du groupe de ressources dans l’onglet « Deployments » (déploiements) du portail Azure d’Azure Data Factory afin de vérifier la progression et obtenir des journaux d’erreurs plus descriptifs.
- Si les champs temporels dans les déclencheurs de la fenêtre bascule (tumbling window) ne sont pas compatibles avec l’environnement cible, le déploiement va échouer. Une solution simple consiste à assurer la concordance des champs temporels avec les déclencheurs dans les environnements de déploiement cibles.
- Les environnements d’exécution d’intégration peuvent également être incompatibles dans différents environnements. Une solution rapide consiste à supprimer ou à mettre à jour les références aux environnements d’exécution d’intégration en utilisant le script PowerShell à l’étape 2 du pipeline de conception.
- Utilisez un correctif (hotfix) si l’usine de données déployée comporte un bogue qui doit être corrigé dès que possible.
- Si les paramètres globaux sont spécifiques à chaque environnement, la case « Include global parameters » (inclure les paramètres globaux) peut être décochée dans la section de configuration du modèle ARM dans ADF. De cette manière, il y aura moins de paramètres à personnaliser lors du déploiement.
- Les déclencheurs d’intégration continue peuvent être activés à la fois dans le pipeline et dans le niveau de mise en production en fonction des calendriers, des demandes de tirage ou des artefacts.
- Pour les déploiements critiques, les approbations préalables aux déploiements peuvent également être configurées au niveau de mise en production, par exemple pour les déploiements dans un environnement de production.
- Déterminez à l’avance si vous allez choisir le mode de déploiement incrémentiel ou complet, surtout s’il y a différences dans la façon dont les environnements utilisés stockent les ressources.
- Durant la phase de mise à l’essai, les modèles ARM peuvent être manuellement exportés vers un espace de stockage local et les scripts PowerShell créés pour la gestion des paramètres peuvent être exécutés localement afin d’accélérer les essais et le dépannage.
Évaluation
C’est une façon parmi d’autres de procéder aux déploiements automatisés dans Azure Data Factory pour différents environnements. Nous avons choisi de concevoir cette solution en utilisant les services Azure, car c’est le fournisseur de services d’infonuagique choisi par l’Agence. Ce processus nous a aidés à explorer les solutions de données pour l’automatisation de l’intégration continue et du déploiement continu. De plus, il démontre qu’il est possible d’économiser beaucoup de temps dans le cadre des déploiements. Par ailleurs, en raison de la courbe d’apprentissage, comme c’est le cas pour tout nouveau processus, nous avons constaté des erreurs et avons passé beaucoup de temps à résoudre les problèmes, ce qui nous a amenés à découvrir des singularités dans le processus, qui font l’objet de conseils de pro ci-dessus. Ces conseils peuvent s’avérer très utiles et vous faire gagner du temps et des efforts en vous aidant à éviter les pièges les plus courants et à simplifier vos processus de déploiement fondés sur Azure.
Conclusion
Nous sommes déterminés à améliorer notre environnement opérationnel pour les déploiements itératifs en perfectionnant continuellement nos processus d’intégration continue et de déploiement continu. De plus, nous recueillons activement les commentaires des membres de notre équipe afin de déterminer les points à améliorer dans le cadre de nos mises à jour.
Compte tenu du rythme rapide de l’innovation et de la disponibilité croissante de fonctionnalités intégrées dans les produits de données de Microsoft, nous recommandons également aux lecteurs de consulter les ressources suivantes : Publication automatisée pour CI/CD, Déployer des modèles ARM liés à VSTS et Déploiements dans Microsoft Fabric.
Restez à l’affût pour obtenir de plus amples renseignements et des mises à jour sur ces sujets dans nos prochains articles!