
Par Saptarshi Dutta Gupta, Statistique Canada
Introduction
À l'ère numérique, les organisations recueillent et stockent de grandes quantités de données sur leurs clients, leurs employés et leurs partenaires. Ces données contiennent souvent des renseignements identificatoires personnels (RIP). Avec la multiplication des violations de données et des cyberattaques, la protection des RIP est devenue une préoccupation majeure pour les entreprises et les organismes gouvernementaux. Par exemple, Statistique Canada mène chaque année des centaines d'enquêtes sur un large éventail de sujets et est tenu de protéger les renseignements fournis par les répondants.
Le Canada dispose de deux lois fédérales sur la protection des renseignements personnels qui sont appliquées par le Commissariat à la protection de la vie privée du Canada :
- Loi sur la protection des renseignements personnels : elle régit la manière dont le gouvernement fédéral traite les renseignements personnels. Cette loi protège les renseignements personnels, définit comme des renseignements enregistrés qui concernent une « personne identifiable ».
- Loi sur la protection des renseignements personnels et les documents électroniques : elle est la loi fédérale sur la protection des renseignements personnels qui s'applique aux organisations recueillant, utilisant ou divulguant des données personnelles dans le cadre d'activités commerciales. Cette loi exige des organisations qu'elles obtiennent le consentement des personnes concernées par la collecte, l'utilisation ou la divulgation de données personnelles et qu'elles protègent les données personnelles contre l'accès, l'utilisation ou la divulgation non autorisés.
Outre les lois susmentionnées, l'ensemble des organisations doivent également respecter le Règlement général sur la protection des données (RGPD). Ce règlement est le plus strict au monde en matière de protection de la vie privée et de sécurité. Bien qu'il ait été rédigé et adopté par l'Union européenne (UE), il impose des obligations aux organisations, peu importe leur emplacement, lorsqu'elles ciblent ou recueillent des données relatives à des personnes dans l'UE. Le RGPR prévoit de lourdes amendes pour les organisations qui ne respectent pas ses normes en matière de protection des renseignements personnels et de sécurité, les sanctions pouvant atteindre des dizaines de millions d'euros.
Dans le présent article, nous présentons en détail Microsoft Presidio et la façon dont cet outil aide les organisations au Canada à se conformer aux lois en matière de protection de la vie privée. Nous abordons d'abord les principales fonctionnalités et capacités de Microsoft Presidio, puis la façon dont il peut aider les organisations à respecter leurs obligations en vertu de ces lois.
Définitions
Avant d’aborder le reste de l’article, il est important de comprendre la différence entre les termes « anonymisation », « dépersonnalisation » et « pseudoanonymisation » qui ont été utilisés.
- Anonymisation : L’anonymisation s’entend du processus consistant à retirer ou à masquer de façon irréversible les renseignements identificatoires contenus dans les données de manière à ce que les données initiales ne puissent être réidentifiées. L’objectif est de rendre impossible ou extrêmement difficile le lien entre les données et la personne qu’elles représentent. Les données anonymisées ne devraient pas contenir d’identificateurs directs ou indirects qui pourraient être utilisés pour identifier des personnes.
- Dépersonnalisation : La dépersonnalisation consiste à retirer ou à modifier les RIP d’un ensemble de données afin d’empêcher l’identification des personnes. Contrairement à l’anonymisation, la dépersonnalisation n’exige pas nécessairement que les données deviennent complètement non identifiables. Elle vise plutôt à supprimer ou à modifier des identificateurs précis, comme les noms, les adresses, les numéros de sécurité sociale ou toute autre information qui pourraient être utilisés seuls ou en combinaison avec d’autres données pour identifier des personnes.
- Pseudoanonymisation : La pseudoanonymisation est une technique qui consiste à remplacer les identificateurs directs par des pseudonymes ou des identificateurs uniques, dissociant ainsi les données des personnes qu’elles représentent. Contrairement à l’anonymisation, où les données originales sont modifiées pour empêcher la réidentification, la pseudoanonymisation conserve la capacité de réidentifier des personnes à l’aide de renseignements supplémentaires stockés séparément, comme une clé ou un tableau de recherche. La pseudoanonymisation est couramment utilisée dans les situations où les données doivent être couplées entre différents systèmes ou bases de données tout en protégeant la vie privée des personnes.
Qu'est-ce que les RIPs?
Les renseignements identificatoires personnels (RIP) désignent les données qui peuvent être utilisées pour identifier une personne. Il s'agit notamment de noms, d'adresses, de numéros de téléphone, de numéros d'assurance sociale, de renseignements financiers, de dossiers médicaux, entre autres. Les RIP sont des renseignements de nature très délicate qui doivent être protégés contre tout accès non autorisé, car ils pourraient être utilisés dans le cas de vol d'identité ou d'autres activités frauduleuses.
Selon l'utilisation directe ou indirecte d'un renseignement pour réidentifier une personne, voici deux catégories dans lesquelles les renseignements susmentionnés peuvent être classés4 :
- Identificateurs directs : ensemble de variables propres à une personne (nom, adresse, numéro de téléphone, compte bancaire) qui pourraient être utilisées pour identifier directement cette personne.
- Quasi-identificateurs : renseignements tels que le genre, la nationalité ou la ville de résidence qui, pris isolément, ne permettent pas la réidentification d'une personne, sauf s'ils sont combinés à d'autres quasi-identificateurs et à des connaissances sur ses antécédents.
Pourquoi la protection des RIP est-elle importante?
La protection des RIP est importante parce que toute personne a droit au respect de sa vie privée et doit avoir un contrôle sur la façon dont ses renseignements personnels sont recueillis, utilisés et divulgués. Les violations de données et le vol d'identité peuvent avoir des répercussions importantes pour les particuliers, y compris des pertes financières, une atteinte à leur réputation et une détresse émotionnelle. Par conséquent, il est primordial pour les organisations de prendre des mesures rigoureuses pour protéger les RIP.
Contexte
a) Anonymisation des données structurées
Il existe des modèles mathématiques établis de protection de la vie privée permettant d'anonymiser les données structurées. Il s'agit notamment des modèles suivants :
- K-anonymat : un ensemble de données masquées est considéré comme k-anonyme si, dans l'ensemble de données, chaque renseignement contenu pour une personne se confond totalement à au moins k-1 autres personnes. Deux méthodes peuvent être utilisées pour parvenir au k-anonymat : la première est la suppression, qui consiste à supprimer complètement la valeur d'un attribut d'un ensemble de données. La seconde est la généralisation, qui consiste à remplacer une valeur précise d'un attribut par une valeur plus générale.
- I-diversité : il s'agit d'une extension du k-anonymat. Si nous assemblons des séries de rangées dans un ensemble de données qui ont des quasi-identificateurs identiques, il y a au moins « l » valeurs distinctes pour chaque attribut de nature délicate. Nous pouvons alors dire que cet ensemble de données présente une l-diversité.
- Confidentialité différentielle : ce modèle vise à garantir que le résultat d'un processus ou d'un algorithme reste à peu près le même, que les données d'une personne soient incluses ou non. Cela signifie qu'il est impossible de déterminer avec certitude si une personne en particulier est présente dans l'ensemble de données simplement en examinant le résultat d'une analyse différentielle de la confidentialité.
Il existe plusieurs autres techniques d'anonymisation qui peuvent être appliquées aux données structurées et non structurées. En voici quelques-unes :
- Mélange des données : consiste à réorganiser de manière aléatoire les rangées ou les colonnes d'un ensemble de données afin de perturber les éventuelles corrélations entre les variables.
- Perturbation des données : consiste à ajouter du bruit ou des erreurs aléatoires aux données afin de réduire le risque de réidentification. Parmi les techniques pouvant être utilisées, mentionnons l'ajout de bruit gaussien ou l'arrondissement des valeurs au multiple le plus proche d'un certain nombre.
- Agrégation des données : consiste à agréger les données à un niveau plus élevé, par exemple au niveau de la ville ou de l'État, afin de protéger les données individuelles.
- Suppression des données : consiste à supprimer complètement les renseignements de nature délicate de l'ensemble de données, par exemple en supprimant des colonnes ou des rangées précises, ou en remplaçant les valeurs de nature délicate par une valeur de paramètre fictif (p. ex. « ****** »).
- Généralisation des données : consiste à remplacer des valeurs précises par des valeurs plus générales, comme remplacer une adresse municipale précise par la ville ou l'État seulement.
- Brouillage des données : consiste à remplacer des renseignements de nature délicate par des données fausses ou trompeuses, par exemple en générant des noms aléatoires ou de fausses adresses.
Il est essentiel de comprendre qu'aucune technique d'anonymisation n'est totalement infaillible. Par conséquent, il est généralement nécessaire d'utiliser une combinaison de techniques pour protéger efficacement les données de nature délicate. Il est également fondamental d'évaluer et de mettre à jour de façon continue les techniques d'anonymisation dès l'apparition de nouveaux risques et de nouvelles techniques de réidentification.
b) Anonymisation des données non structurées
Le processus d'anonymisation des données non structurées, comme le texte ou les images, est une tâche plus difficile. Il consiste à détecter l'endroit où se trouvent les renseignements de nature délicate dans les données non structurées, puis de leur appliquer des techniques d'anonymisation. En raison de la nature des données non structurées, l'utilisation directe de modèles simples fondés sur des règles pourrait ne pas donner de très bons résultats.
C'est pourquoi le traitement du langage naturel (TLN) a été appliqué à l'anonymisation du texte. Plus précisément, la reconnaissance d'entités nommées (REN), qui est un type de tâche d'étiquetage de séquences, est utilisée pour indiquer si un jeton (comme un mot) correspond à une entité nommée, comme PERSONNE (PER), EMPLACEMENT, DATE/HEURE ou une ORGANISATION (ORG), comme l'indique l'image ci-dessous. O indique qu'aucune entité n'a été reconnue.
Image 1 : Tâche d'étiquetage de séquences – Reconnaissance d'entités nommées
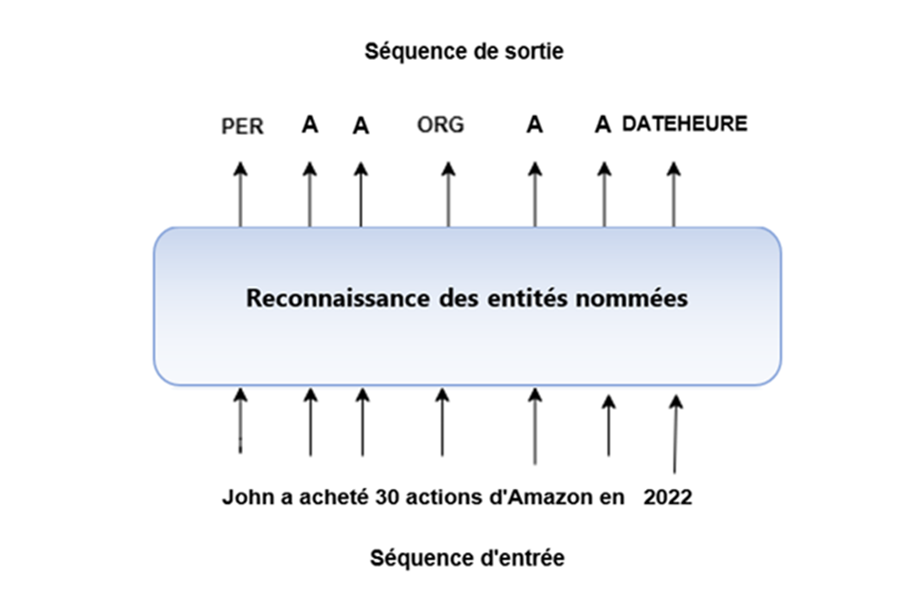
Description - Image 1 : Tâche d’étiquetage de séquences – Reconnaissance d’entités nommées
Cette image décrit le résultat obtenu après le passage d’une séquence de chaînes de caractères dans un outil de reconnaissance d’entités nommées (REN). La chaîne de caractères « John a acheté 30 actions d’Amazon en 2022 » représente les données d’entrée. Après avoir passé la séquence dans un modèle de REN, chaque mot est classé selon son entité correspondante. John est désigné comme la personne (PER), Amazon comme l’organisation (ORG), 2022 comme la date (DATE/HEURE) et le reste des données comme les autres renseignements.
Plusieurs modèles neuronaux ont permis d'atteindre des résultats ultra-performants dans les tâches de REN sur des ensembles de données contenant des entités nommées générales. Des résultats aussi performants sont également obtenus lorsque ces modèles sont entraînés sur des données du domaine médical contenant divers types de renseignements personnels. Ces architectures de modèles comprennent des réseaux neuronaux récurrents (RNR) avec intégration de caractères (en anglais seulement) ou des transformateurs bidirectionnels (BERT) (en anglais seulement).
SpaCy (en anglais seulement) utilise également un modèle de langage qui repose sur RoBERTa, mis au point sur l'ensemble de données Ontonotes comprenant 18 catégories d'entités nommées, comme PERSONNE, EGP (entité géopolitique), CARDINAL, EMPLACEMENT, etc.
Microsoft Presidio utilise une combinaison de méthodes de TLN fondées sur des règles pour rendre anonyme le contenu de nature délicate dont nous parlerons plus loin.
Microsoft Presidio
Pourquoi avons-nous besoin de Microsoft Presidio?
Lorsque nous appliquons l'anonymisation des RIP à des applications réelles, il peut y avoir différentes exigences opérationnelles qui rendent difficile l'utilisation directe de modèles préentraînés. Par exemple, le gouvernement du Canada reçoit plusieurs demandes au cours d'un processus annoncé, des demandes qui sont ensuite examinées. Avant le processus d'examen, les RIP doivent être épurés afin d'éviter toute fuite de renseignements personnels et toute partialité. Outre les entités de RIP courants, le gouvernement utilise également un code d'identification de dossier personnel (CIDP) pour chaque employé, modulus-11 check digit (en anglais seulement) [Source : SCT - Dictionnaire d'éléments d'information des titulaires]
Un modèle de REN préentraîné ne peut pas détecter ces entités spéciales. Pour obtenir de bons résultats, il est nécessaire de mettre au point le modèle à l'aide de données auxquelles des étiquettes sont ajoutées. C'est pourquoi il est nécessaire de disposer d'un outil qui puisse utiliser un modèle de REN préentraîné et qui soit facilement personnalisable et extensible.
Presidio (du latin praesidium qui signifie « ce qui protège, défend ») permet de s'assurer que les données de nature délicate sont correctement gérées et administrées. Il fournit des modules d'identification et d'anonymisation rapides pour les entités privées dans le texte et les images telles que les numéros de cartes de crédit, les noms, les emplacements, les numéros de sécurité sociale, les portefeuilles de bitcoins, les numéros de téléphone américains, les données financières et bien plus encore.
L'un des principaux avantages du cadre Presidio est sa capacité à évoluer. Il peut traiter de grands ensembles de données, ce qui le rend apte à être utilisé par des organisations disposant de grandes quantités de données. Il est également conçu pour être flexible et adaptable, ce qui permet aux organisations de personnaliser son utilisation pour répondre à leurs besoins précis.
Image 2 : Flux de travail pour la détection des RIP dans Microsoft Presidio [Source : Presidio: Data Protection and De-identification SDK (en anglais seulement)]

Description - Image 2 : Flux de travail pour la détection des RIP dans Microsoft Presidio
L’animation montre le flux de détection de Presidio qui est utilisé pour détecter les RIP. Une entrée passe par Regex qui effectue une reconnaissance des formes, suivie d’un algorithme de REN pour détecter les entités, d’une somme de contrôle pour valider les formes, de mots contextuels pour augmenter la confiance dans la détection et de plusieurs techniques d’anonymisation. L’image montre la séquence d’entrée : « Salut, je m’appelle David et mon numéro est 212 555 1234 ». Après avoir traversé le flux de détection Presidio, le prénom David et le numéro 212 555 1234 sont perçus comme des RIP.
Objectifs
- Présenter les technologies de dépersonnalisation aux organisations d'une manière conviviale afin de promouvoir le respect de la vie privée et la transparence dans la prise de décisions.
- Rendre la technologie flexible et personnalisable pour répondre à des besoins opérationnels précis.
- Soutenir la dépersonnalisation entièrement automatisée et semi-automatisée des RIP sur plusieurs plateformes.
Principales caractéristiques
- Permet de reconnaître les RIP à l'aide de diverses méthodes comme la reconnaissance d'entités nommées, les expressions normales, la logique fondée sur des règles et la somme de contrôle ainsi que le contexte pertinent, dans plusieurs langues.
- Permet de se connecter à des modèles externes de détection des RIP.
- Offre différentes options d'utilisation, notamment les charges de travail Python ou PySpark, Docker et Kubernetes.
- Permet la personnalisation de l'identification et de l'anonymisation des RIP.
- Comprend un module pour épurer les RIP sous forme de texte dans les images.
Modules principaux de Presidio
a) Presidio Analyzer :
(i) Vue d'ensemble
Presidio Analyzer est un service qui repose sur Python pour détecter les entités des RIP dans le texte. Au cours de l'analyse, il exécute un ensemble de différents reconnaisseurs des RIP, chacun étant chargé de détecter une ou plusieurs entités de RIP à l'aide de mécanismes différents. Presidio Analyzer est livré avec un ensemble de reconnaisseurs prédéfinis, mais il peut facilement étendre sa portée à d'autres types de reconnaisseurs personnalisés. Les reconnaisseurs prédéfinis et personnalisés tirent avantage de la reconnaissance d'entités nommées, des expressions normales, de la logique fondée sur des règles et de la somme de contrôle ainsi que du contexte pertinent dans plusieurs langues pour détecter les RIP dans un texte non structuré, comme présenté dans le flux de travail pour la détection ci-dessous.
Image 3 : Presidio Analyzer pour la détection des RIP [Source : Presidio Analyzer (en anglais seulement)]

Description - Image 3 : Presidio Analyzer pour la détection des RIP
L’image montre comment Presidio Analyzer est utilisé pour détecter les RIP. Le texte d’entrée passe par plusieurs reconnaisseurs de RIP, dont le reconnaisseur intégré, le reconnaisseur personnalisé et les modèles personnalisés. Le reconnaisseur intégré comprend les expressions normales (Regex), la somme de contrôle, la REN et les mots contextuels. Une fois que l’entrée de texte est passée par tous les reconnaisseurs, les RIP sont détectés.
Par défaut, Microsoft Presidio peut reconnaître les entités suivantes : Entités prises en charge – Microsoft Presidio (en anglais seulement)
(ii) Installation
Presidio Analyzer peut être installé (en anglais seulement) au moyen de pip, d'une image de menu fixe ou peut être construit à partir de la source.
(iii) Exécution d'un analyseur de base
Une fois l'installation terminée, un analyseur de base peut être exécuté avec quelques lignes de code, comme présenté ci-dessous :
from presidio_analyzer import AnalyzerEngine
# Set up the engine, loads the NLP module (spaCy model by default) and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text="Mr. John lives in Vancouver. His email id is john@sfu.ca", language='en')
print(results)
[type: EMAIL_ADDRESS, start: 45, end: 56, score: 1.0, type: PERSON, start: 4, end: 8, score: 0.85, type: LOCATION, start: 18, end: 27, score: 0.85, type: URL, start: 50, end: 56, score: 0.5]
Par défaut, Presidio utilise le modèle en_core_web_lg de spaCy et peut détecter les entités suivantes : Entités prises en charge – Microsoft Presidio (en anglais seulement). Comme le montre le code ci-dessus, les entités PERSONNE, COURRIEL, EMPLACEMENT et URL ont été détectées. La portée de l'analyseur peut être étendue pour permettre la détection de nouvelles entités, comme nous le verrons plus loin.
(iv) Capacités de Presidio Analyzer
- Permet la détection de nouvelles entités de RIP
Pour élargir les fonctions de détection de Presidio à de nouveaux types d'entités de RIP, des objets EntityRecognizer devraient être ajoutés à la liste actuelle des reconnaisseurs. Ces objets reposent sur Python et peuvent détecter une ou plusieurs entités dans un langage précis.
Le diagramme à catégories suivant montre les différents types de familles de reconnaisseurs compris dans Presidio :
Image 4 : Diagramme à catégories pour les différents types de reconnaisseurs dans Presidio [Source : Supporting detection of new types of PII entities (en anglais seulement)]
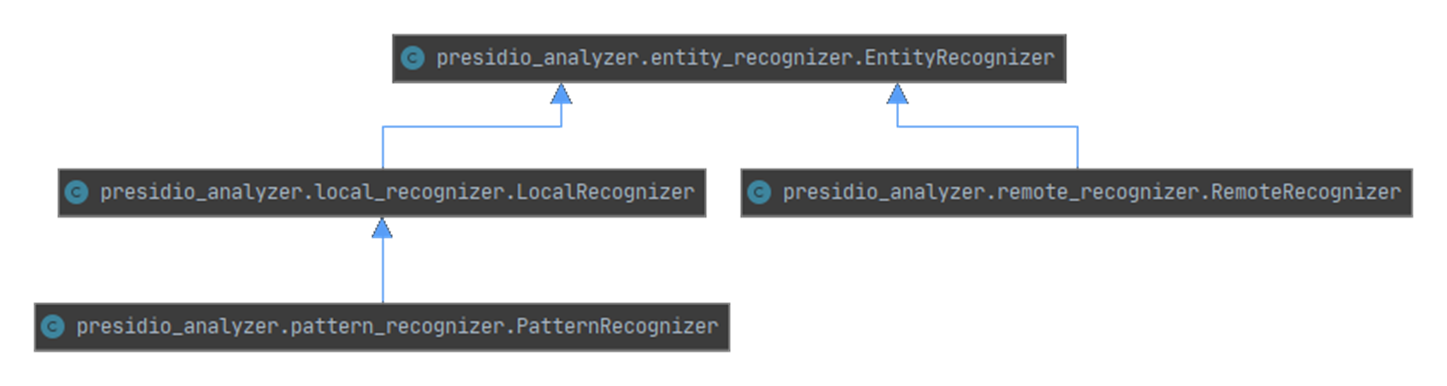
Description - Image 4 : Diagramme à catégories pour les différents types de reconnaisseurs dans Presidio
L’image montre le diagramme à catégories pour les différents types de reconnaisseurs dans Presidio. EntityRecognizer est une catégorie abstraite pour tous les reconnaisseurs. RemoteRecognizer est une catégorie abstraite permettant de mobiliser des détecteurs de RIP externes. La catégorie abstraite LocalRecognizer est mise en œuvre par tous les reconnaisseurs fonctionnant au sein du processus de Presidio Analyzer. PatternRecognizer est une catégorie permettant de prendre en charge la logique de reconnaissance fondée sur les expressions normales (Regex) et les listes de rejet, y compris la validation (p. ex. avec la somme de contrôle) et la prise en charge contextuelle.
Dans le diagramme présenté ci-dessus :
- EntityRecognizer est une catégorie abstraite pour tous les reconnaisseurs.
- RemoteRecognizer est une catégorie abstraite permettant de mobiliser des détecteurs de RIP externes.
- La catégorie abstraite LocalRecognizer est mise en œuvre par tous les reconnaisseurs fonctionnant au sein du processus de Presidio Analyzer.
- La catégorie PatternRecognizer permet de prendre en charge la logique de reconnaissance fondée sur les expressions normales (Regex) et les listes de rejet, y compris la validation (p. ex. avec la somme de contrôle) et la prise en charge contextuelle.
Une façon simple d'étendre la portée de l'analyseur afin de détecter des entités de RIP supplémentaires peut se faire en deux étapes :
- Créer une nouvelle catégorie selon EntityRecognizer.
- Ajouter le nouveau reconnaisseur au registre correspondant pour qu'AnalyzerEngine puisse l'utiliser pendant l'analyse.
Exemple :
Pour les reconnaisseurs simples fondés sur des expressions normales ou des listes de rejet, nous pouvons tirer avantage de la catégorie PatternRecognizer fournie et mobiliser l'outil de reconnaissance comme le montre l'écran suivant :
from presidio_analyzer import PatternRecognizer
titles_recognizer = PatternRecognizer(supported_entity="TITLE", deny_list=["Mr.","Mrs.","Miss"])
titles_recognizer.analyze(text="Mr. John lives in Vancouver. His email id is john@sfu.ca", entities="TITLE")
[type: TITLE, start: 0, end: 3, score: 1.0]
Ensuite, nous pouvons l'ajouter à la liste des reconnaisseurs pour la détection d'autres entités de RIP :
from presidio_analyzer import AnalyzerEngine, RecognizerRegistry
registry = RecognizerRegistry()
registry.load_predefined_recognizers()
# Add the recognizer to the existing list of recognizers
registry.add_recognizer(titles_recognizer)
# Set up analyzer with our updated recognizer registry
analyzer = AnalyzerEngine(registry=registry)
# Run with input text
text="Mr. John lives in Vancouver. His email id is john@sfu.ca"
results = analyzer.analyze(text=text, language="en")
results
[type: TITLE, start: 0, end: 3, score: 1.0,
type: EMAIL_ADDRESS, start: 45, end: 56, score: 1.0,
type: PERSON, start: 4, end: 8, score: 0.85,
type: LOCATION, start: 18, end: 27, score: 0.85,
type: URL, start: 50, end: 56, score: 0.5]
Pour des catégories EntityRecognizer plus complexes, comme la détection de CIDP pour le gouvernement du Canada, le reconnaisseur peut être créé dans le code en suivant les étapes suivantes :
- Créer une nouvelle catégorie Python qui met en œuvre la catégorie LocalRecognizer (en anglais seulement) (LocalRecognizer met en œuvre la catégorie de base EntityRecognizer (en anglais seulement)). Cette catégorie comprend les fonctions suivantes :
- charger : charger un modèle ou une ressource à utiliser lors de la reconnaissance
- analyser : fonction principale à lancer pour extraire des entités du nouveau reconnaisseur.
- L'ajouter au registre de reconnaisseur en utilisant registry.add_recognizer(my_recognizer). Pour obtenir plus d'exemples, consultez la section concernant la personnalisation de Presidio Analyzer (en anglais seulement) dans le bloc-notes Jupyter.
Il existe plusieurs autres façons de créer un reconnaisseur personnalisé dans Presidio, notamment :
- Création d'un reconnaisseur à distance : Utilisation d'un reconnaisseur à distance, qui interagit avec un service externe pour la détection des RIP. Il peut s'agir d'un service tiers ou d'un service personnalisé fonctionnant parallèlement à Presidio.
- Création de reconnaisseurs ponctuels : Création de reconnaisseurs ponctuels à l'aide de l'interface de programmation d'applications (API) de Presidio Analyzer. Ces reconnaisseurs, au format JSON, peuvent être ajoutés à la requête /analyse et ne sont utilisés que pour cette requête précise.
- Lecture de reconnaisseurs de formes à partir de fichiers YAML : Lecture de reconnaisseurs de formes à partir de fichiers YAML, ce qui permet aux utilisateurs d'ajouter une logique de reconnaissance sans écrire de code. Vous trouverez un exemple de fichier YAML ici: Example Recognizers (en anglais seulement). Une fois le fichier YAML créé, il peut être chargé dans RecognizerRegistry.
2. Prise en charge multilingue
Presidio peut détecter les RIP dans plusieurs langues à l'aide de ses reconnaisseurs et modèles intégrés. Par défaut, il comprend des reconnaisseurs et des modèles en anglais. Toutefois, ces reconnaisseurs dépendent de la langue, soit par leur logique, soit par les mots contextuels utilisés pour rechercher des entités.
Pour améliorer les résultats pour des langues précises, il est possible de mettre à jour les mots contextuels des reconnaisseurs existants ou d'ajouter de nouveaux reconnaisseurs qui prennent en charge des langues supplémentaires. Chaque reconnaisseur ne peut prendre en charge qu'une seule langue. Il est donc nécessaire d'ajouter de nouveaux reconnaisseurs pour des langues supplémentaires.
3. Personnalisation des modèles de TLN
Comme indiqué précédemment, Presidio Analyzer utilise par défaut le modèle fr_core_web_lg de spaCy (en anglais seulement), mais il peut facilement être personnalisé en tirant avantage d'autres modèles de TLN, qu'ils soient publics ou exclusifs. Presidio utilise des moteurs de TLN pour deux tâches principales : la détection des RIP fondée sur la REN et l'extraction de fonctionnalités pour une logique selon des règles personnalisées (comme tirer parti des mots contextuels pour améliorer la détection). Ces modèles peuvent être entraînés ou téléchargés à partir de structures de TLN existantes comme spaCy (en anglais seulement), Stanza (en anglais seulement) et Transformers (en anglais seulement).
La configuration du nouveau modèle peut se faire de deux manières :
- par code : en créant un NlpEngine à l'aide de la catégorie NlpEnginerProvider et en le transmettant à AnalyzerEngine en tant qu'entrée.
- par configuration : en établissant les modèles à utiliser dans le fichier conf par défaut (en anglais seulement). Ce dernier est lu lors de l'initialisation par défaut d'AnalyzerEngine. Le chemin d'accès à un fichier de configuration personnalisé peut également être transmis à NlpEngineProvider.
Outre les capacités intégrées de spaCy, Stanza ou Transformers, il est possible de créer de nouveaux reconnaisseurs qui servent d'interfaces avec d'autres modèles (p. ex. flair).
b) Presidio Anonymizer :
Presidio Anonymizer est également un service en Python. Il anonymise les entités de RIP détectées avec les valeurs souhaitées en appliquant certains opérateurs comme « remplacer », « masquer » et « épurer ». Par défaut, il remplace les RIP détectés par leur type d'entité, comme <COURRIEL> ou <NUMÉRO_TÉLÉPHONE>, directement dans le texte. Mais il est possible de le personnaliser, en prévoyant une logique d'anonymisation différente pour les différents types d'entités.
L'ensemble Presidio Anonymizer contient à la fois des anonymiseurs et des désanonymiseurs.
- Les anonymiseurs sont utilisés pour remplacer le texte d'une entité de RIP par une autre valeur en appliquant un opérateur donné. Les différents opérateurs intégrés sont les suivants :
- remplacer : remplace les RIP par la valeur souhaitée
- épurer : supprime complètement les RIP du texte
- sectionner : sectionne le texte des RIP (peut être sha256, sha512 ou md5).
- masquer : remplace les RIP par un caractère donné
- crypter : chiffre les RIP à l'aide d'une clé cryptographique donnée
- personnaliser :remplace les RIP par le résultat de la fonction exécutée sur les RIP
Image 5 : Flux de travail de l'anonymiseur des RIP [Source : Presidio Anonymizer (en anglais seulement)]
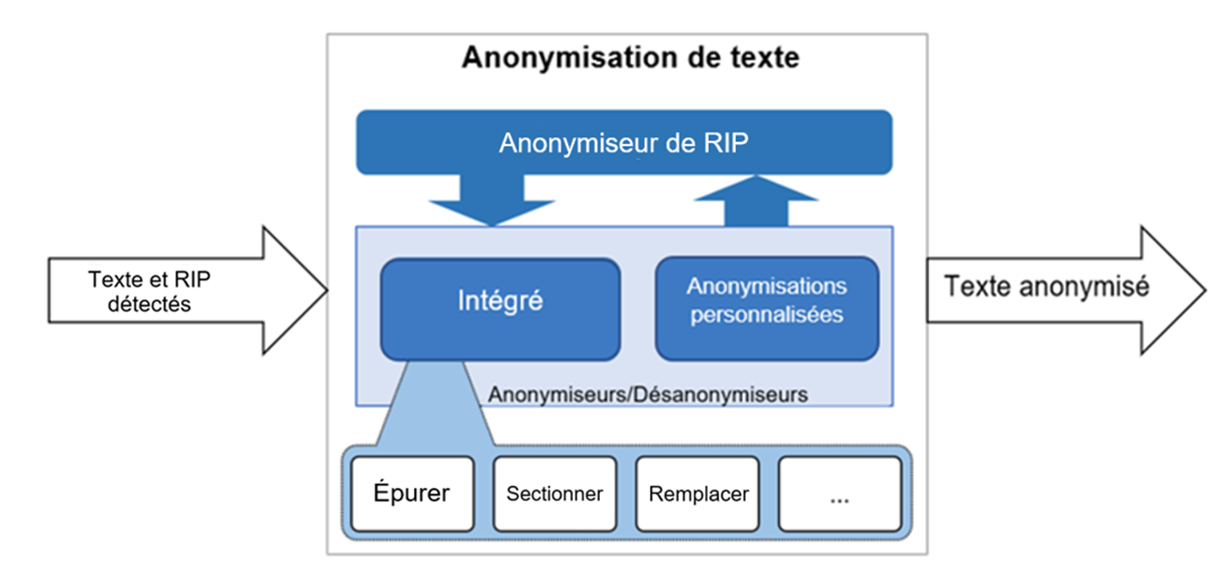
Description - Image 5 : Flux de travail de l’anonymiseur des RIP
L'image présente la fonction de Presidio Anonymizer. La partie gauche montre le texte et les RIP détectés qui sont transmis à l'anonymiseur intégré et à l'anonymiseur personnalisé. L'anonymiseur intégré se compose d'opérateurs comme « épurer », « sectionner » et « remplacer ». Après avoir fait passer le texte et les RIP détectés dans l'anonymiseur de RIP, le texte anonymisé est rendu.
Exemple :
frompresidio_anonymizer import AnonymizerEngine from presidio_anonymizer.entities import RecognizerResult, OperatorConfig # Initialize the engine: engine = AnonymizerEngine() # Invoke the anonymize function with the text, # analyzer results (potentially coming from presidio-analyzer) and # Operators to get the anonymization output: result = engine.anonymize( text="Mr. John lives in Vancouver. His email id is john@sfu.ca", analyzer_results= results )results
Données de sortie :
text: <TITLE> <PERSON> lives in <LOCATION>. His email id is <EMAIL_ADDRESS>
items:
[
{'start': 54, 'end': 69, 'entity_type': 'EMAIL_ADDRESS', 'text': '<EMAIL_ADDRESS>', 'operator': 'replace'},
{'start': 26, 'end': 36, 'entity_type': 'LOCATION', 'text': '<LOCATION>', 'operator': 'replace'},
{'start': 8, 'end': 16, 'entity_type': 'PERSON', 'text': '<PERSON>', 'operator': 'replace'},
{'start': 0, 'end': 7, 'entity_type': 'TITLE', 'text': '<TITLE>', 'operator': 'replace'}
]
Presidio permet également à l'extension de Presidio Anonymizer de prendre en charge des opérateurs supplémentaires.
- Les désanonymiseurs sont utilisés pour annuler l'opération d'anonymisation (p. ex. pour déchiffrer un texte chiffré).
Comme le texte d'entrée peut potentiellement contenir des entités de RIP qui se chevauchent, différents scénarios d'anonymisation sont possibles :
- Pas de chevauchement (RIP uniques) : Lorsqu'il n'y a pas de chevauchement dans l'étendue des entités, Presidio Anonymizer utilise un opérateur d'anonymisation donné ou par défaut pour anonymiser et remplacer l'entité textuelle des RIP.
- Chevauchement total de l'étendue des entités des RIP: Lorsque les sous-chaînes des entités se chevauchent, ce sont les RIP dont la note est la plus élevée qui sont retenues. Entre les RIP qui ont des notes semblables, la sélection est arbitraire.
- Un RIP est contenu dans un autre : Presidio Anonymizer utilisera le RIP dont le texte est le plus grand, même si sa note est inférieure.
- Intersection partielle : Presidio Anonymizer rendra anonyme chaque texte individuellement et remettra une concaténation du texte anonymisé. Pour commencer, installez Presidio comme l'indiquent les instructions présentées ici : Installing Presidio (en anglais seulement)
Conclusion
En conclusion, Microsoft Presidio est un outil précieux pour détecter les renseignements identificatoires personnels (RIP) dans les données textuelles. Sa conception flexible permet aux utilisateurs de créer des reconnaisseurs et des modèles personnalisés pour répondre à des cas d'utilisation précis, et sa prise en charge multilingue assure une détection efficace des RIP dans un large éventail de scénarios. En outre, la possibilité d'utiliser des services externes, des reconnaisseurs ponctuels et des reconnaisseurs de formes à partir de fichiers YAML permet aux utilisateurs d'intégrer facilement de nouvelles capacités de détection. Dans l'ensemble, les capacités de détection complètes des RIP de Presidio, ainsi que ses options de personnalisation, en font un atout pour les organisations qui cherchent à protéger des données de nature délicate.
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
Références
What is GDPR, the EU's new data protection law? - GDPR.eu (en anglais seulement)
La protection des renseignements personnels et la confidentialité
Pierre Lison, Ildikó Pilán, David Sánchez, Montserrat Batet et Lilja Øvrelid. 2021. « Anonymisation Models for Text Data : State of the Art, Challenges and Future Directions (en anglais seulement) », Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing.
Documents officiels : Microsoft Presidio (en anglais seulement)
GitHub - microsoft/presidio: Context aware, pluggable, and customizable data protection and de-identification SDK for text and images (en anglais seulement)
PII anonymization made easy by Presidio | by Lingzhen Chen | Towards Data Science (en anglais seulement)
Presidio Research · spaCy Universe (en anglais seulement)
Evaluation of an automated Presidio anonymisation model for unstructured radiation oncology electronic medical records in an Australian setting - ScienceDirect (en anglais seulement)
Le Centre de confiance de Statistique Canada
La protection des renseignements personnels et la confidentialité