
Modèles de vision par ordinateur : projet de classification des semences
Par le laboratoire d'intelligence artificielle de l'Agence canadienne d'inspection des aliments
Introduction
L'équipe du laboratoire d'intelligence artificielle (IA) de l'Agence canadienne d'inspection des aliments (ACIA) est composée d'un groupe diversifié d'experts, y compris des scientifiques des données, des développeurs de logiciels et des chercheurs diplômés, qui travaillent ensemble pour offrir des solutions novatrices pour l'avancement de la société canadienne. En collaborant avec des membres des directions générales interministérielles du gouvernement, le laboratoire d'IA tire parti d'algorithmes d'apprentissage automatique à la fine pointe de la technologie pour offrir des solutions axées sur les données à des problèmes réels et favoriser un changement positif.
Au laboratoire d'IA de l'ACIA, nous exploitons le plein potentiel des modèles d'apprentissage profond. Notre équipe spécialisée de scientifiques des données tire parti de la puissance de cette technologie transformatrice et élabore des solutions personnalisées adaptées aux besoins particuliers de nos clients.
Dans le présent article, nous justifions le recours aux modèles de vision par ordinateur pour la classification automatique des espèces de semences. Nous démontrons de quelle façon nos modèles personnalisés ont permis d'obtenir des résultats prometteurs en utilisant des images de semences « réelles » et nous décrivons nos orientations futures pour le déploiement d'une application SeedID conviviale.
Au laboratoire d'intelligence artificielle de l'ACIA, nous nous efforçons non seulement de repousser les frontières de la science en tirant parti de modèles de pointe, mais aussi en rendant ces services accessibles à d'autres et en favorisant le partage des connaissances, afin de promouvoir l'évolution constante de la société canadienne.
Vision par ordinateur
Pour comprendre le fonctionnement des modèles de classification d'images, nous devons d'abord définir les objectifs visés par la vision par ordinateur.
Qu'est-ce que la vision par ordinateur?
Les modèles de vision par ordinateur tentent essentiellement de résoudre ce qu'on appelle mathématiquement des problèmes mal posés. Les modèles cherchent à répondre à la question suivante : qu'est-ce qui a engendré l'image?
En tant qu'humains, nous faisons cela naturellement. Lorsque les photons pénètrent dans nos yeux, notre cerveau est capable de traiter les différents modèles de lumière, ce qui nous permet d'inférer l'existence du monde physique qui se trouve devant nous. Dans le contexte de la vision par ordinateur, nous essayons de reproduire notre capacité humaine innée de perception visuelle au moyen d'algorithmes mathématiques. Des modèles de vision par ordinateur efficaces pourraient alors être utilisés pour répondre à des questions liées aux tâches suivantes :
- Catégorisation d'objets : la capacité de classer des objets dans une image ou de reconnaître le visage d'une personne dans des images.
- Catégorisation de scènes et de contextes : la capacité à comprendre ce qui se passe dans une image à partir de ses composantes (p. ex. intérieur et extérieur, circulation et absence de circulation).
- Information spatiale qualitative : la capacité de décrire qualitativement des objets dans une image, comme un objet rigide en mouvement (p. ex. autobus), un objet non rigide en mouvement (p. ex. drapeau), un objet vertical, horizontal, incliné, etc.
Pourtant, bien que ces tâches semblent simples, les ordinateurs ont encore des difficultés à interpréter et à comprendre avec précision notre monde complexe.
Pourquoi la vision par ordinateur est-elle si difficile?
Pour comprendre pourquoi les ordinateurs semblent avoir de la difficulté à accomplir ces tâches, nous devons d'abord considérer ce qu'est une image.

Êtes-vous en mesure de décrire cette image à partir de ces valeurs?
Description - Figure 1
Cette image montre une image pixélisée en brun et blanc du visage d'une personne. Le visage de la personne est pixélisé, les pixels étant blancs et l'arrière-plan brun. À côté de l'image se trouve une image agrandie qui montre les valeurs des pixels correspondant à une petite section de l'image d'origine.
Une image est un ensemble de chiffres, avec généralement trois canaux de couleur : rouge, vert, bleu (RVB). Afin de tirer une signification de ces valeurs, l'ordinateur doit effectuer ce que l'on appelle une reconstruction d'image. Dans sa forme la plus simplifiée, nous pouvons exprimer mathématiquement cette idée par une fonction inverse :
x = F-1(y)
où :
y représente les mesures des données (c.-à-d. les valeurs des pixels);
x représente une version reconstruite des mesures, y, dans une image.
Cependant, il s'avère que la résolution de ce problème inverse est plus difficile que prévu en raison de la nature « mal posée » du problème.
Qu'est-ce qu'un problème mal posé?
Lorsqu'une image est enregistrée, il se produit une perte inhérente de renseignements puisque le monde en 3D est projeté sur un plan en 2D. Même pour nous, la compression de l'information spatiale que nous recueillons du monde physique peut rendre difficile de distinguer ce que nous voyons sur les photos.

Michel-Ange (1475-1564). L'occlusion causée par les différents points de vue peut rendre difficile la reconnaissance d'une même personne.
Description - Figure 2
L'image montre trois tableaux de personnages différents, chacun avec une expression différente sur le visage. L'un des personnages semble être en pleine réflexion, tandis que les deux autres semblent être dans un état de contemplation. Les tableaux sont réalisés dans un matériau sombre et brut, et les détails des visages sont bien définis. L'effet global de l'image en est un de profondeur et de complexité. Les tableaux sont soumis à une rotation dans chaque cadre pour créer un sentiment de changement.

Fond de canettes de soda. Des orientations différentes peuvent rendre impossible l'identification du contenu de la canette.
Description - Figure 3
L'image montre cinq canettes en métal. Quatre de ces canettes ont une tache de couleur différente sur le dessus. Les couleurs sont le bleu, le vert, le rouge et le jaune. Les canettes sont disposées sur un comptoir. Le comptoir comporte une surface sombre, semblable à du granit ou du béton.

Base de données des visages de Yale. Les variations d'éclairage peuvent rendre difficile la reconnaissance d'une même personne (rappel : tout ce que les ordinateurs « voient », ce sont des valeurs de pixels).
Description - Figure 4
L'image montre deux images du même visage. Les images sont prises sous différents angles, ce qui se traduit par deux expressions du visage perçues différemment. Sur l'image de gauche, l'homme a une expression faciale neutre, tandis que sur l'image de droite, il a une expression grave et courroucée.

Rick Scuteri-USA TODAY Sports. Des échelles différentes peuvent rendre difficile la compréhension du contexte des images.
Description - Figure 5
L'image montre quatre images différentes, à des échelles différentes. La première image ne contient seulement que ce qui ressemble à l'œil d'un oiseau. La deuxième image contient la tête et le cou d'une oie. La troisième image montre l'animal en entier, et la quatrième image montre un homme debout devant l'oiseau, indiquant une direction.

Différentes photos de chaises. La variation entre les catégories peut rendre difficile la catégorisation des objets (nous pouvons discerner une chaise grâce à son aspect fonctionnel).
Description - Figure 6
L'image montre cinq chaises différentes. La première est une chaise rouge avec un cadre en bois. La deuxième est une chaise pivotante en cuir noir. La troisième ressemble à une chaise non conventionnelle de forme artistique. La quatrième ressemble à une chaise de bureau de style minimaliste, et la dernière ressemble à un banc.
Il peut être difficile de reconnaître des objets dans des images 2D en raison d'éventuelles propriétés mal posées, notamment :
- Manque d'unicité : Plusieurs objets peuvent donner lieu à la même mesure.
- Incertitude : Le bruit (p. ex. le flou, la pixillation, les dommages physiques) dans les photos peut rendre difficile, voire impossible, la reconstitution et la reconnaissance d'une image.
- Incohérence : de légers changements dans les images (p. ex. différents points de vue, différents éclairages, différentes échelles) peuvent rendre complexe le fait de trouver la solution « x » à partir des points de données disponibles « y »
Si les tâches de vision par ordinateur peuvent, à première vue, sembler superficielles, le problème sous-jacent qu'elles tentent de résoudre est très complexe!
Nous allons maintenant nous pencher sur certaines solutions axées sur l'apprentissage profond pour résoudre les problèmes de vision par ordinateur.
Réseaux neuronaux convolutifs (RNC)
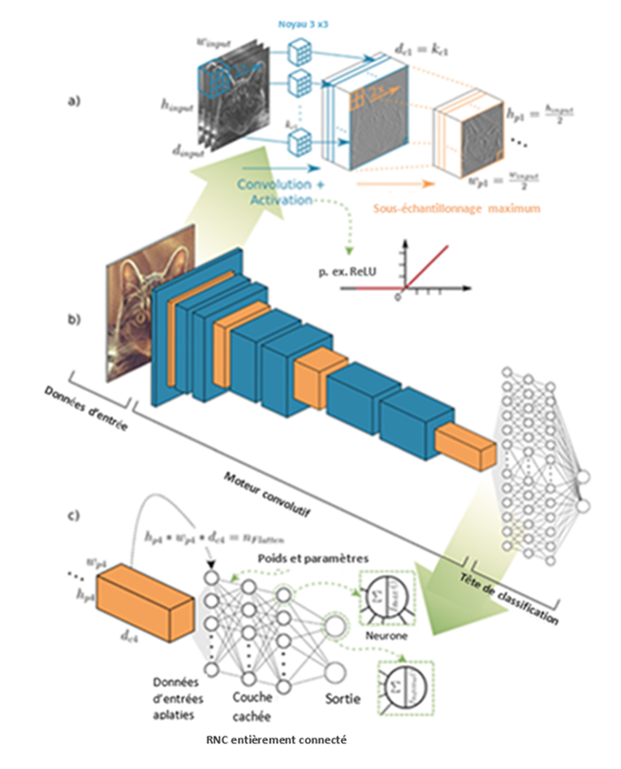
Représentation graphique d'une architecture de réseau neuronal convolutif (RNC) pour la reconnaissance d'images. (Hoeser and Kuenzer, 2020 (en anglais seulement))
Description - Figure 7
Voici un diagramme de l'architecture d'un réseau neuronal convolutif. Le réseau se compose de plusieurs couches, dont une couche d'entrée, une couche convolutive, une couche de sous-échantillonnage et une couche de sortie. La couche d'entrée reçoit une image et la fait passer par la couche convolutive, qui applique un ensemble de filtres à l'image pour en extraire les caractéristiques.
La couche de sous-échantillonnage réduit la taille de l'image en appliquant une opération de sous-échantillonnage à la sortie de la couche convolutive. La couche de sortie traite l'image et produit un résultat final. Le réseau est entraîné à l'aide d'un ensemble de données d'images et de leurs étiquettes correspondantes.
Les réseaux neuronaux convolutifs (RNC) sont un type d'algorithme qui s'est avéré très efficace pour résoudre de nombreux problèmes de vision par ordinateur, comme nous l'avons décrit précédemment. Afin de classer ou d'identifier des objets dans des images, un modèle RNC apprend d'abord à reconnaître des caractéristiques simples dans les images, telles que les contours, les coins et les textures. Pour ce faire, il applique différents filtres à l'image. Ces filtres aident le réseau à se concentrer sur des motifs précis. Au fur et à mesure de son apprentissage, le modèle commence à reconnaître des caractéristiques plus complexes et combine les caractéristiques simples apprises à l'étape précédente pour créer des représentations plus abstraites et plus significatives. Enfin, le RNC utilise les caractéristiques apprises précédemment pour classer les images en fonction des classes avec lesquelles il a été entraîné.
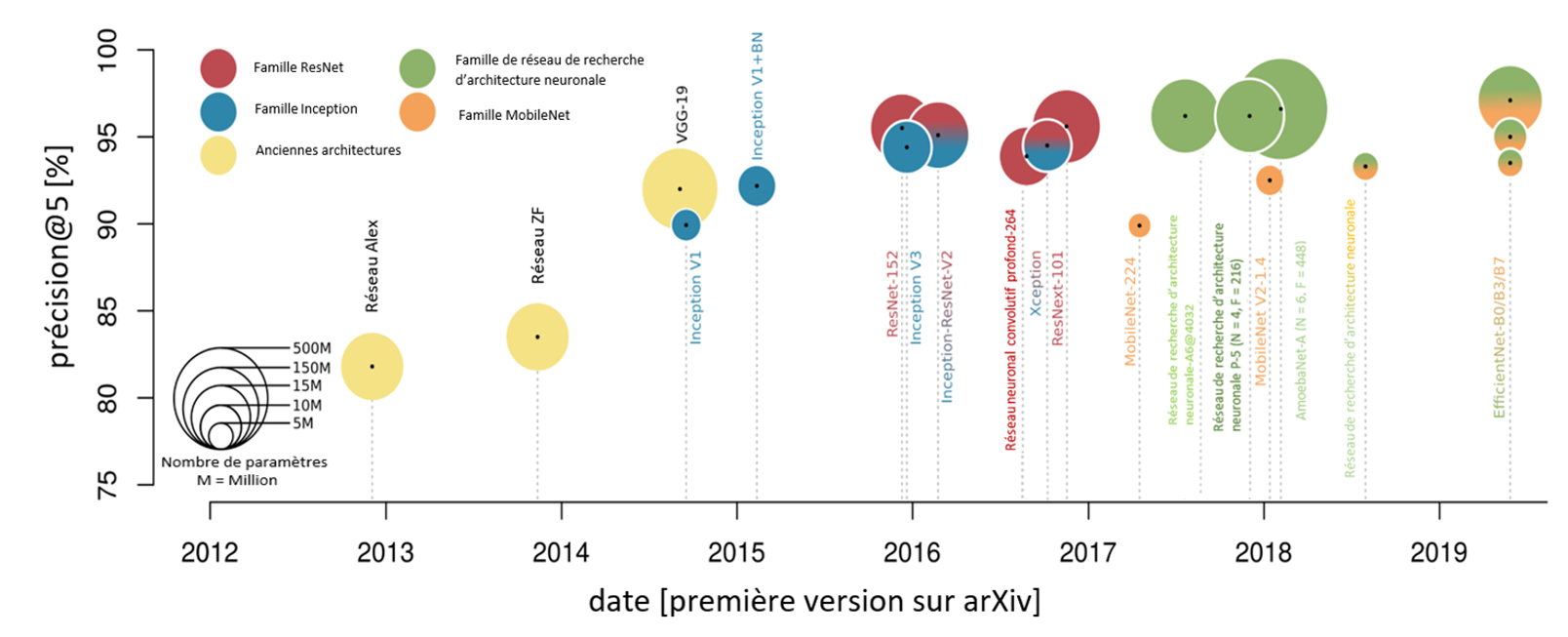
Évolution des architectures RNC et de leur précision pour les tâches de reconnaissance d'images entre 2012 et 2019. (Hoeser and Kuenzer, 2020 (en anglais seulement)).
Description - Figure 8
L'image montre le tracé de la taille des différentes architectures et modèles de RNC entre 2012 et 2019. Chaque réseau neuronal est représenté par un cercle, la taille du cercle correspondant à la taille du réseau neuronal en termes de nombre de paramètres.
Le premier RNC a été proposé par Yann LeCun en 1989 (LeCun, 1989 (en anglais seulement)) pour la reconnaissance des chiffres manuscrits. Depuis lors, les RNC ont évolué de manière importante au fil des ans, grâce aux progrès réalisés à la fois dans l'architecture des modèles et dans la puissance informatique disponible. Aujourd'hui encore, les RNC continuent de faire leurs preuves en tant qu'architectures puissantes pour diverses tâches de reconnaissance et d'analyse de données.
Transformateurs de vision (ViT)
Les transformateurs de vision (ViT) relèvent d'un développement récent dans le domaine de la vision par ordinateur qui applique aux données visuelles le concept des transformateurs, conçu à l'origine pour les tâches de traitement du langage naturel. Au lieu de traiter une image comme un objet en 2D, les transformateurs de vision la considèrent comme une séquence de « cases », de la même manière que les transformateurs traitent une phrase comme une séquence de mots.
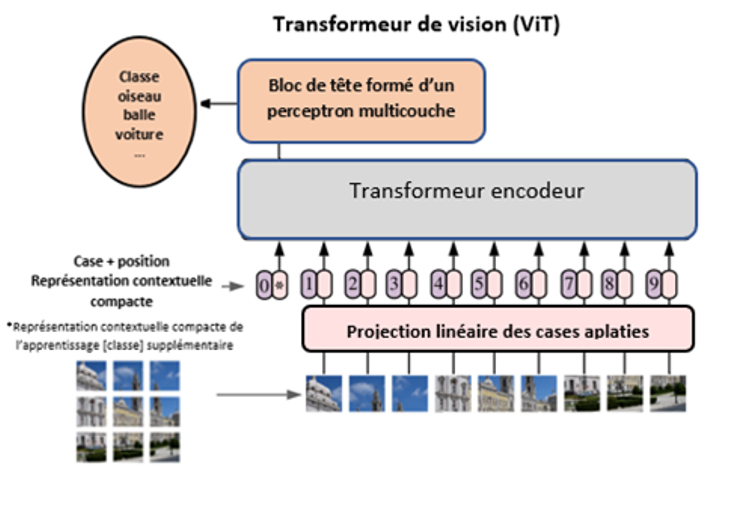
Vue d'ensemble d'un transformateur de vision comme illustré dans Une image vaut 16x16 mots : Transformateurs pour la reconnaissance d'images à l'échelle (en anglais seulement). Depuis la publication du transformateur de vision original, de nombreuses variations et de nombreuses variétés ont été proposées et étudiées.
Description - Figure 9
L'image montre le diagramme de l'architecture ViT. On peut y voir une image de l'image d'entrée, divisée en différentes cases, et chaque case est introduite dans le réseau neuronal. Le réseau se compose d'un bloc de codage du transformateur et d'un bloc de tête formé d'un perceptron multicouche, suivi d'une tête de classification.
Le processus commence par la division d'une image en une grille de cases. Chaque case est ensuite aplatie en une séquence de vecteurs de pixels. Des codages de position sont ajoutés pour conserver les renseignements sur la position, comme le font les transformateurs pour les tâches linguistiques. L'entrée transformée est ensuite traitée au moyen de plusieurs couches d'encodeurs du transformateur pour créer un modèle capable de comprendre des données visuelles complexes.
Tout comme les réseaux neuronaux convolutifs (RNC) apprennent à identifier les modèles et les caractéristiques d'une image par l'entremise des différentes couches convolutives, les transformateurs de vision identifient les modèles en se concentrant sur les relations entre les cases d'une image. Ils apprennent essentiellement à évaluer l'importance des différentes cases par rapport aux autres afin d'établir des classifications précises. Le modèle ViT a été présenté pour la première fois par l'équipe de Google Brain dans un article publié en 2020. Bien que les RNC aient dominé le domaine de la vision par ordinateur pendant des années, l'introduction des transformateurs de vision a démontré que les méthodes mises au point pour le traitement du langage naturel pouvaient également être utilisées pour des tâches de classification d'images, souvent avec des résultats supérieurs.
L'un des principaux avantages des transformateurs de vision est que, contrairement aux RNC, ils ne reposent pas sur une hypothèse intégrée de localité spatiale et d'invariance de décalage. Cela signifie qu'ils sont mieux adaptés aux tâches nécessitant une compréhension globale d'une image, ou lorsque de légers décalages peuvent modifier radicalement la signification d'une image.
Cependant, les ViT nécessitent généralement une plus grande quantité de données et de ressources de calcul que les RNC. Ce facteur a conduit à une tendance de modèles hybrides qui combinent à la fois les RNC et les transformateurs afin d'exploiter les forces des deux architectures.
Classification des semences
Contexte :
L'industrie des semences et des céréales du Canada, qui représente plusieurs milliards de dollars, s'est taillé une réputation mondiale en ce qui concerne la production, la transformation et l'exportation de semences de qualité supérieure pour la plantation ou de céréales destinées à l'alimentation dans une vaste gamme de cultures. Son succès est attribuable à l'engagement du Canada en faveur de l'innovation et du développement de technologies de pointe, ce qui lui permet de fournir des produits de haute qualité conformes aux normes nationales et internationales, avec une certification diagnostique qui répond aux besoins nationaux et internationaux.
Naturellement, une collaboration entre une équipe de recherche du Centre pour la science et la technologie des semences et du laboratoire d'intelligence artificielle de l'ACIA a été mise en place pour maintenir le rôle du Canada en tant que chef de file de renom dans le secteur mondial des semences ou des céréales et dans les industries de mise à l'essai connexes.
Contexte : Contrôle de la qualité
La qualité des semences d'une culture est consignée dans un rapport de classement. La catégorie finale indique dans quelle mesure un lot de semences satisfait aux normes de qualité minimales, conformément au Règlement sur les semences du Canada. Les facteurs utilisés pour déterminer la qualité des cultures comprennent les graines de mauvaises herbes contaminées, conformément à l'Arrêté sur les graines de mauvaises herbes du Canada, l'analyse de la pureté, ainsi que la germination et les maladies. Bien que la germination offre un potentiel de rendement au champ, il est essentiel d'évaluer la pureté physique de la plante pour s'assurer qu'elle contient une grande quantité des semences désirées et qu'elle est exempte de contaminants, comme des espèces interdites et réglementées, des semences de culture différente ou des graines de mauvaises herbes différentes. L'inspection des semences joue un rôle important dans la prévention de la propagation des espèces interdites et réglementées énumérées dans l'Arrêté sur les graines de mauvaises herbes. Le Canada est l'une des plus importantes bases de production pour l'approvisionnement alimentaire mondial, exportant un grand nombre de céréales comme le blé, le canola, les lentilles et le lin. Pour satisfaire à l'exigence de certification phytosanitaire et avoir accès à de vastes marchés étrangers, l'analyse des semences de mauvaises herbes réglementées pour les destinations d'importation est en forte demande, avec un délai d'exécution rapide et des changements fréquents. La capacité de contrôle pour la détection des graines de mauvaises herbes nécessite le soutien de technologies de pointe, car les méthodes traditionnelles font face à un grand défi en raison de la demande.
Justification
À l'heure actuelle, l'évaluation de la qualité d'une culture est effectuée manuellement par des experts humains. Cependant, ce processus est fastidieux et prend beaucoup de temps. Au laboratoire d'IA, nous tirons parti de modèles de vision par ordinateur avancés pour classer automatiquement les espèces de semences à partir d'images, ce qui rend ce processus plus efficace et plus fiable.
Ce projet vise à développer et à déployer un puissant pipeline de vision par ordinateur pour la classification des espèces de semences. En automatisant ce processus de classification, nous pouvons simplifier et accélérer l'évaluation de la qualité des cultures. Nous développons des solutions fondées sur des algorithmes avancés et des techniques d'apprentissage profond, tout en assurant une évaluation impartiale et efficace de la qualité des cultures, ouvrant ainsi la voie à l'amélioration des pratiques agricoles.
Projet no 1 : Imagerie et analyse multispectrales
Dans le cadre de ce projet, nous utilisons un modèle de vision par ordinateur personnalisé pour évaluer la pureté du contenu, en déterminant et en classifiant les espèces de semences désirées pour les distinguer des espèces de semences non désirées.
Nous parvenons à récupérer et à déterminer les cas de contamination par trois espèces de mauvaises herbes différentes dans un mélange trié d'échantillons de blé.
Notre modèle est personnalisé de manière à accepter des entrées d'images multispectrales uniques à haute résolution à 19 canaux et à atteindre une précision de plus de 95 % sur les données d'essai.
Nous avons exploré plus en profondeur le potentiel de notre modèle à classer de nouvelles espèces, en introduisant cinq nouvelles espèces de canola dans l'ensemble de données et en observant des résultats similaires. Ces résultats encourageants mettent en évidence le potentiel d'utilisation continue de notre modèle, même lorsque de nouvelles espèces de semences sont introduites.
Notre modèle a été formé pour classer les espèces suivantes :
- Trois espèces différentes de chardon (mauvaises herbes) :
- Cirsium arvense (espèces réglementées)
- Carduus nutans (semblables aux espèces réglementées)
- Cirsium vulgare (semblables aux espèces réglementées)
- Six semences de culture :
- Triticum aestivum, sous-espèce aestivum
- Brassica napus, sous-espèce napus
- Brassica juncea
- Brassica juncea (de type jaune)
- Brassica rapa, sous-espèce oleifera
- Brassica rapa, sous-espèce oleifera (de type brun)
Notre modèle a permis d'identifier correctement chaque espèce de semence avec une précision de plus de 95 %.
De plus, lorsque les semences des trois espèces différentes de chardon ont été intégrées au criblage du blé, le modèle a atteint une précision moyenne de 99,64 % sur 360 semences. Ces résultats ont permis de démontrer la robustesse du modèle et sa capacité à classer de nouvelles images.
Enfin, nous avons introduit cinq nouveaux types et espèces de canola et évalué le rendement de notre modèle. Les résultats préliminaires de cette expérience ont montré une précision d'environ 93 % sur les données de test.
Projet no 2 : Imagerie et analyse en mode RVB au microscope numérique
Dans le cadre de ce projet, nous utilisons un processus en deux étapes pour déterminer un total de 15 espèces de semences différentes ayant une importance réglementaire et présentant un défi morphologique à divers niveaux de grossissement.
Tout d'abord, un modèle de segmentation des semences est utilisé pour déterminer chaque instance d'une semence dans l'image. Ensuite, un modèle de classification permet de classer chaque espèce de semence.
Nous réalisons plusieurs études par ablation en entraînant le modèle sur un profil de grossissement, puis en le testant sur des images de semences provenant d'un autre ensemble d'images à divers niveaux de grossissement. Nous obtenons des résultats préliminaires prometteurs d'une précision de plus de 90 % pour tous les niveaux de grossissement.
Trois niveaux de grossissement différents ont été fournis pour les 15 espèces suivantes :
- Ambrosia artemisiifolia
- Ambrosia trifida
- Ambrosia psilostachya
- Brassica junsea
- Brassica napus
- Bromus hordeaceus
- Bromus japonicus
- Bromus secalinus
- Carduus nutans
- Cirsium arvense
- Cirsium vulgare
- Lolium temulentum
- Solanum carolinense
- Solanum nigrum
- Solanum rostratum
Un mélange de 15 espèces différentes a été pris en photo à différents niveaux de grossissement. Le niveau de grossissement a été indiqué par le nombre total d'occurrences de semences présentes dans l'image, soit : 1, 2, 6, 8 ou 15 semences par image.
Afin d'établir un protocole d'enregistrement d'image normalisé, nous avons entraîné de manière indépendante des modèles distincts à partir d'un sous-ensemble de données à chaque niveau de grossissement, puis nous avons évalué le rendement du modèle sur un ensemble de données de test réservé à tous les niveaux de grossissement.
Les résultats préliminaires ont démontré la capacité du modèle à déterminer correctement les espèces de semences à différents niveaux de grossissement avec une précision de plus de 90 %.
Ces résultats ont permis de révéler le potentiel du modèle à classer avec précision des données jusque-là inconnues à différents niveaux de grossissement.
Tout au long de nos expériences, nous avons essayé et testé différentes méthodologies et différents modèles.
Les modèles avancés équipés d'une forme canonique comme les transformateurs « Swin » ont mieux résisté et se sont révélés moins perturbés par le niveau de grossissement et de zoom.
Discussion et défis
La classification automatique des semences est une tâche difficile. L'entraînement d'un modèle d'apprentissage automatique pour la classification des semences pose plusieurs défis en raison de l'hétérogénéité inhérente aux différentes espèces et entre celles-ci. Par conséquent, de grands ensembles de données sont nécessaires pour entraîner efficacement un modèle à l'apprentissage de caractéristiques propres à une espèce. De plus, le degré élevé de ressemblance entre différentes espèces au sein des genres pour certaines d'entre elles rend difficile, même pour des experts humains, la distinction entre des espèces intragenres étroitement apparentées. De plus, la qualité de la capture d'images peut également avoir une incidence sur le rendement des modèles de classification des semences, car les images de faible qualité peuvent entraîner la perte de renseignements importants nécessaires à une classification précise.
Pour relever ces défis et améliorer la robustesse des modèles, des techniques d'enrichissement des données ont été appliquées dans le cadre des étapes de prétraitement. Les transformations affines, comme la mise à l'échelle et la traduction d'images, ont été utilisées pour augmenter la taille de l'échantillon, tandis que l'ajout de bruit gaussien peut augmenter la variation et améliorer la généralisation sur les données non encore vues par le modèle, empêchant ainsi le surapprentissage sur les données d'entraînement.
Le choix de l'architecture de modèle appropriée a été crucial pour atteindre le résultat souhaité. Un modèle peut ne pas produire de résultats exacts si les utilisateurs finaux ne respectent pas un protocole normalisé, particulièrement lorsque les données fournies ne correspondent pas à la distribution prévue. Par conséquent, il était impératif de tenir compte de diverses sources de données et d'utiliser un modèle qui fait montre d'une capacité de généralisation efficace entre domaines pour assurer une classification exacte des semences.
Conclusion
Le projet de classification des semences est un exemple de la collaboration fructueuse et continue entre le laboratoire d'IA et le Centre pour la science et la technologie des semences de l'ACIA. En mettant en commun leurs connaissances et leur expertise respectives, les deux équipes contribuent à l'avancement des industries des semences et des céréales du Canada. Le projet de classification des semences montre de quelle façon l'utilisation d'outils avancés d'apprentissage automatique peut améliorer considérablement l'exactitude et l'efficacité de l'évaluation de la qualité des semences ou des céréales en conformité avec le Règlement sur la protection des semences ou le Règlement sur la protection des végétaux, au plus grand bénéfice du secteur agricole, des consommateurs, de la biosécurité et de la salubrité des aliments.
En tant que scientifiques des données, nous reconnaissons l'importance de la collaboration ouverte et nous sommes déterminés à respecter les principes de la science ouverte. Notre objectif est de promouvoir la transparence et la mobilisation grâce à un libre échange avec le public.
En rendant notre application accessible, nous invitons les autres chercheurs, les experts en semences et les développeurs à contribuer à son amélioration et à sa personnalisation. Cette approche collaborative favorise l'innovation, ce qui permet à la communauté d'améliorer collectivement les capacités de l'application SeedID et de répondre aux exigences particulières de différents domaines.
Rencontre avec le scientifique des données

Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Inscrivez-vous à la présentation Rencontre avec le scientifique des données.
À bientôt!
MS Teams – le lien sera fourni aux participants par courriel
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
- Date de modification :