
Une brève enquête sur les technologies liées à la protection de la vie privée
Par : Zachary Zanussi, Statistique Canada
À titre d'organisme, Statistique Canada a toujours cherché à adopter rapidement de nouvelles technologies et à faire preuve d'innovation sur le plan des méthodes. Les technologies de données volumineuses, comme l'apprentissage profond, ont augmenté l'utilité des données de manière exponentielle. L'infonuagique a été un instrument qui a permis à cette situation de se produire, tout particulièrement lorsqu'on utilise des données non confidentielles. Cependant, les calculs à partir de données de nature délicate non chiffrées dans un environnement infonuagique pourraient exposer les données à des menaces en matière de confidentialité et à des attaques liées à la cybersécurité. Statistique Canada a adopté des mesures strictes en matière de politique sur la protection des renseignements personnels qui ont été élaborées suite à des décennies de collecte de données et de diffusion de statistiques officielles. Pour tenir compte des nouvelles exigences en ce qui a trait à l'exploitation infonuagique, nous envisageons d'adopter une catégorie de nouvelles techniques cryptographiques, dites technologies liées à la protection de la vie privée (TPVP), qui peuvent aider à accroître l'utilité, en tirant davantage profit des technologies, comme le nuage ou l'apprentissage automatique, tout en continuant d'assurer la position de l'organisme en matière de sécurité. Ce billet présente brièvement un certain nombre de ces TPVP.
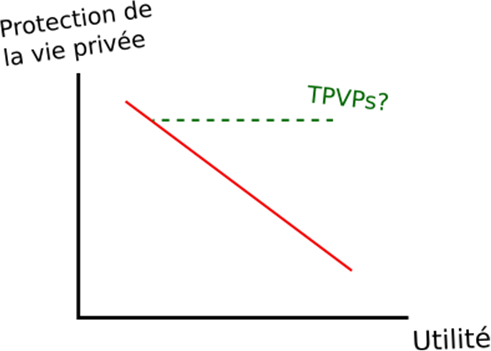
Description - Figure 1
Accroître l'utilité dans l'équation protection de la vie privée contre utilité. La ligne rouge pleine montre l'équilibre entre la protection de la vie privée et l'utilité avec des méthodes classiques, tandis que la ligne verte pointillée montre le résultat qu'on espère obtenir avec les nouvelles technologies de protection de la vie privée.Qu'entend-on par protection de la vie privée? Par protection de la vie privée, on entend le droit des personnes de contrôler ou d'influencer quels renseignements à leur sujet peuvent être recueillis, utilisés et stockés et par qui, ainsi que les entités auxquelles ces renseignements peuvent être divulgués. À titre d'organisme national de la statistique au Canada, la plupart des données qu'utilise Statistique Canada sont fournies par des répondants, comme une personne ou une entreprise. La confidentialité des données est protégée au moyen des cinq principes de protection (en anglais seulement), afin d'assurer le respect de la vie privée des répondants en veillant à ce que les données qu'ils fournissent ne puissent pas permettre de les identifier directement ou à partir de données statistiques. Vous trouverez davantage d'information sur l'approche de Statistique Canada en matière de protection de la vie privée en consultant le Centre de confiance de Statistique Canada.
Une atteinte à la vie privée implique qu’un pirate réussit à identifier une réponse et à l'attribuer à un répondant en particulier. On considère les données des répondants comme les intrants de certains processus statistiques qui produisent des extrants. Si un pirate a accès aux données d'entrée, il s'agit d'une atteinte à la confidentialité à l'entrée, alors que, si le pirate peut recréer par ingénierie inverse les données sur la vie privée à partir des données de sortie, il s'agit d'une atteinte à la confidentialité à la sortie. On peut empêcher ces deux types d'atteintes au moyen de méthodes statistiques classiques, comme la préservation de l'anonymat, dans le cadre de laquelle on supprime les caractéristiques potentielles d'identification des données; ou la perturbation, dans le cadre de laquelle on modifie les valeurs des données d'une certaine manière pour empêcher toute nouvelle identification exacte. Malheureusement, ces méthodes classiques font en sorte de sacrifier forcément l'utilité des données, tout particulièrement les données de nature délicate. En outre, il existe de nombreux exemples d'identifications qui prouvent que ces techniques classiques n'offrent pas nécessairement les garanties voulues en matière de sécurité cryptographiqueNote de bas de page 1, Note de bas de page 2. L'objectif est de tirer avantage des TPVP pour maintenir des attributs de protection de la vie privée stricts tout en préservant autant que possible l'utilité. À la fin, on améliore effectivement l'utilité dans l'équation protection de la vie privée contre utilité.
La confidentialité différentielle pour préserver la confidentialité à la sortie
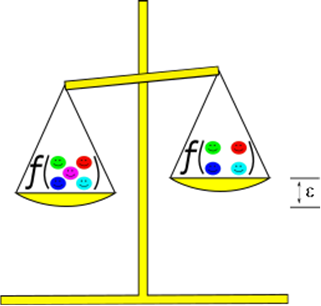
Description - Figure 2
Légende de la figure : Dans le cas de la confidentialité différentielle, les données de sortie d'un algorithme pour des ensembles de données très semblables devraient correspondre à une valeur convenue désignée par le nom epsilon. Dans ce cas-ci, l'ajout du répondant du centre (magenta) modifie la sortie de ƒ d'une quantité limitée à ε.La confidentialité à la sortie des répondants est protégée en tenant attentivement compte des résultats des statistiques agrégées. Par exemple, un adversaire pourrait rétablir les données d'entrée en réalisant une analyse attentive des statistiques publiées. Dans le même ordre d'idées, si le public peut interroger une base de données sécurisée, alors que cet accès lui permet de demander des statistiques simples (moyenne, maximum, minimum et autres) sur des sous-ensembles de la base de données, un adversaire pourrait faire une utilisation abusive de ce système pour extraire des données d'entrée. La confidentialité différentielle réduit ce risque, car on ajoute du « bruit » aux données d'entrée ou de sortie. Du premier coup d'œil, il s'agit tout simplement d'un exemple de perturbation des données qu'on utilise dans le cadre des statistiques officielles depuis des décennies. On a perfectionné la technique en adoptant une formule mathématique rigoureuse de confidentialité différentielle, qui permet d'évaluer avec précision le point exact où un algorithme se trouve sur l'échelle « Protection de la vie privée – Utilité » au moyen d'un paramètre ε, ou epsilon.
Un algorithme porte le nom ε-différentiellement privé si l'exécution de l'algorithme dans deux bases de données dont seulement une entrée est différente produit des résultats qui diffèrent de moins de ε. De manière informelle, cela signifie qu'un adversaire qui emploie la même statistique provenant de différents sous-ensembles d'une base de données peut seulement inférer une certaine quantité de renseignements de la base de données liée par ε. En pratique, avant la diffusion de statistiques, on détermine le niveau de protection de la vie privée requis pour établir ε. On ajoute ensuite du « bruit aléatoire » aux données, jusqu'à ce que les algorithmes ou statistiques à calculer soient ε-différentiellement privés. Au moyen de la confidentialité différentielle, on garantit une meilleure protection des données de sortie tout en maximisant l'utilité.
Les calculs privés comme moyen de protéger la confidentialité à l'entrée
Le terme « calculs privés » est un terme général qui renvoie à un certain nombre de différents cadres pour calculer les données de manière sécurisée. Par exemple, supposons que vous avez des données privées pour lesquelles vous aimeriez réaliser une forme de calcul. Cependant, vous n'avez pas accès à un environnement de calcul sécurisé. Vous pourriez donc souhaiter utiliser le chiffrement homomorphique. Supposons, aussi, que vous et de nombreux pairs souhaitez réaliser un calcul partagé de vos données sans les partager entre vous. Vous pourriez avoir recours, dans ce cas-ci, au calcul sécurisé multi-parties. Ces deux paradigmes de calcul sécurisé seront examinés de manière plus approfondie ci-dessous.
En raison des avancées récentes en infonuagique, les personnes et les organisations ont un accès jamais vu à des environnements infonuagiques puissants et abordables. Cependant, la plupart des fournisseurs de services nuagiques ne garantissent pas la sécurité des données lors de leur traitement. Cela signifie que le nuage est encore hors de portée pour de nombreuses organisations disposant de données privées de nature très délicate. Le chiffrement homomorphique (CH) pourrait changer la donne. Tandis que les données doivent être déchiffrées avant et après utilisation (chiffrement au repos) avec les algorithmes de chiffrement classiques, dans le cadre du CH, les calculs peuvent être effectués directement au moyen de données chiffrées. Les résultats des calculs peuvent être dévoilés uniquement après déchiffrement. Le titulaire des données peut donc chiffrer ses données et les envoyer dans le nuage en sachant qu'elles sont protégées de manière cryptographique. Le nuage peut réaliser les calculs souhaités de manière homomorphique et retourner les résultats chiffrés. Seul le titulaire des données peut déchiffrer et consulter les données. De cette manière, le client peut confier ses calculs dans le nuage sans reposer sur sa relation de confiance pour savoir que ses données sont protégées. Ses données sont sécurisées grâce au chiffrement! Malheureusement, le CH augmente la complexité des calculs, dans une mesure qui peut être beaucoup plus élevée que les calculs non chiffrés correspondants.
Supposons qu'un certain nombre d'hôpitaux ont des données au sujet de patients ayant une maladie rare. S'ils regroupent leurs données, ils pourraient réaliser des calculs qui pourraient les aider à mettre en application des stratégies de prévention et de traitement. Dans de nombreux pays, les lois exigent que les établissements médicaux protègent les données médicales de leurs patients. Dans le passé, il n'y avait qu'une seule solution à ce problème, c'est-à-dire faire en sorte que tous les hôpitaux s'entendent sur une seule autorité de confiance qui recueillerait les données et réaliserait les calculs. Aujourd'hui, les hôpitaux pourraient mettre en place le calcul (sécurisé) multi-parties (CMP). Au moyen du CMP, les hôpitaux peuvent collaborer et réaliser conjointement leurs calculs sans partager leurs données d'entrée avec quiconque. Il n'est donc pas nécessaire de faire appel à une autorité de confiance, car les données personnelles d'entrée sont protégées même si des hôpitaux étaient « malhonnêtes ». On met habituellement en œuvre des protocoles de CMP au moyen de multiples rondes de « partage secret », dans le cadre desquelles chaque partie dispose d'une composante d'un calcul plus petit qu'elle utilise pour effectuer un calcul de plus grande envergure. Malheureusement, le CMP augmente la complexité des calculs, mais pas autant que le CH. En outre, les protocoles exigent habituellement de multiples rondes de communications interactives.
Apprentissage échelonné
Les réseaux neuronaux et l'intelligence artificielle sont peut-être les deux technologies qui ont été les plus prospères à l'époque des données volumineuses. Au lieu de préparer un programme pour réaliser une tâche, des données sont saisies dans une machine, et un modèle entraîné est utilisé pour réaliser la tâche. La collecte de données devient l'aspect le plus important du processus. Comme mentionné ci-dessus, ce processus de collecte peut être prohibitif lorsque les données sont réparties et de nature délicate. L'apprentissage échelonné fait partie des protocoles de CMP qui cherchent à entraîner un modèle utilisant des données appartenant à de multiples parties qui souhaitent garder leurs données privées. Deux protocoles qui mettent en œuvre ce processus de manière légèrement différente, à savoir l'apprentissage fédéré et l'apprentissage divisé, seront abordés. En ce qui a trait au reste de cette section, on suppose que les utilisateurs ont une connaissance de base de la manière d'entraîner un réseau neuronal.
À la base de ces deux protocoles se trouve une même formule; de multiples parties ont accès à des données qu'elles jugent délicates. Un serveur d'autorité centrale non fiable les aidera. Les parties s'entendent sur une architecture de réseau neuronal qu'elles souhaitent entraîner, ainsi que sur d'autres caractéristiques particulières, comme les hyperparamètres. À cette étape-ci, les deux concepts divergent.
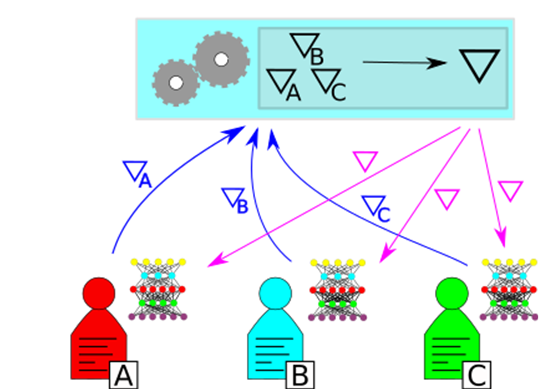
Description - Figure 3
En apprentissage fédéré, chaque titulaire de données calcule des gradients pour ses données, avant de les envoyer à une autorité centrale qui calcule ∇ et les redistribue à chaque partie. De cette manière, chaque partie peut obtenir un réseau neuronal entraîné pour tenir compte de l'union des ensembles de données, sans partager les données.Dans le cas de l'apprentissage fédéré, chaque partie dispose d'une copie locale identique du réseau qu'elle entraîne. Les parties réalisent chacune une époque d'entraînement de leur réseau, avant d'envoyer les gradients à l'autorité. L'autorité coordonne ces gradients et demande à chaque partie de mettre à jour ses modèles locaux en combinant les renseignements tirés des données de chaque partie. Le processus est ensuite répété pour le nombre souhaité d'époques, alors que l'autorité et chaque partie disposent finalement d'une version entraînée du réseau qu'elles peuvent utiliser comme bon leur semble. Les réseaux obtenus sont identiques. Le processus ne révèle aucun autre renseignement sur les données que les gradients accumulés qui ont été calculés par chaque partie. Cette situation pourrait éventuellement faciliter les attaques. Il faut en tenir compte lors de la mise en œuvre d'un cadre d'apprentissage fédéré.
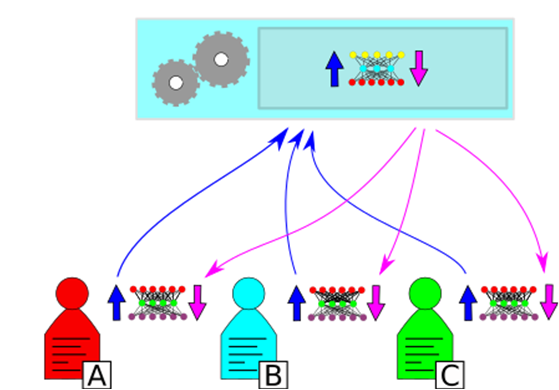
Description - Figure 4
Dans le cadre de l'apprentissage divisé, le réseau souhaité est « divisé » entre les parties et le serveur. La propagation avant va vers le haut en bleu foncé. La rétropropagation va vers le bas en magenta. Chaque partie réalise une propagation avant jusqu'à la division, avant d'envoyer le résultat au serveur, qui réalise une propagation avant et une rétropropagation à nouveau, envoyant les gradients aux parties respectives qui peuvent mettre leurs réseaux à jour.Dans l'apprentissage divisé, le réseau neuronal est divisé par l'autorité à une certaine couche. Les couches découlant de la division sont partagées avec les parties. Chaque partie produit ses données jusqu'à la division, avant d'envoyer les activations à la couche de division au serveur. Le serveur achève la propagation avant pour le reste du réseau, puis réalise une rétropropagation jusqu'à la division, avant d'envoyer les gradients aux parties qui peuvent ensuite achever une rétropropagation et mettre à jour leur copie du réseau. Après le nombre souhaité d'époques, l'autorité répartit la moitié de son réseau à chaque partie. Chaque partie dispose ainsi de sa propre copie de l'ensemble du réseau, dont la section inférieure de chaque réseau est adaptée explicitement à ses données. Les seules données exposées sont celles qui ont été inférées à partir des activations et des gradients échangés à chaque époque. Les couches sous la division servent à modifier les données suffisamment pour veiller à ce qu'elles soient protégées (appelé parfois « écrasement » des données), tout en permettant au serveur de recueillir des renseignements de celles-ci.
Cet article a porté sur un certain nombre de nouvelles technologies de protection de la vie privée, ainsi que sur la manière dont elles peuvent accroître l'utilité des données sans exposer davantage la vie privée des personnes les ayant fournies. Les prochaines publications étudieront de manière plus approfondie certaines de ces technologies. Demeurez à l'affût! Prochainement nous allons étudier de manière plus approfondie le chiffrement homomorphique, de la mathématique des treillis aux applications.
Souhaitez-vous être tenu au courant de ces nouvelles technologies? Voulez-vous faire état de vos travaux dans le domaine de la protection de la vie privée? Consultez la page GCConnex de notre communauté de pratique sur les technologies de protection de la vie privée, afin de discuter de ces publications sur la protection de la vie privée du Réseau de la science des données, d'interagir avec des pairs qui s'intéressent à la protection de la vie privée, et de partager des ressources et des idées avec la communauté. Vous pouvez également commenter ce billet ou fournir des suggestions de publications futures dans le cadre de la série de publications.
- Date de modification :