
Modélisation du contexte à l'aide de transformateurs : reconnaissance des aliments
Par : Mohammadreza Dorkhah, Sayema Mashhadi et Shannon Lo, Statistique Canada
Introduction
Notre équipe de chercheurs de la Division de la science des données et du Centre de données sur la santé de la population (CDSP) de Statistique Canada a mené un projet de validation de principe permettant de distinguer des aliments dans des images et de chercher une autre façon de recueillir des données sur la nutrition.
Étant donné que ce projet était le premier du genre à Statistique Canada, les équipes qui ont participé à la création de cette validation de principe devaient utiliser exclusivement des ensembles de données d'images d'aliments accessibles au public. Par conséquent, nous avons constitué un ensemble de données définitif contenant des images et des étiquettes qui correspondaient aux aliments et aux boissons consommés par les Canadiens à partir de trois autres ensembles de données. L'ensemble de données qui en a résulté a servi à concevoir un modèle d'apprentissage profond de reconnaissance des aliments qui peut prédire 187 catégories différentes d'aliments ou de boissons et discerner plusieurs produits dans une seule image.
Le modèle d'apprentissage profond de reconnaissance des aliments s'appuie sur un transformateur de vision à la fine pointe de la technologie comme encodeur, appelé « transformateur de segmentation » (segmentation transformer, ou SETR), et un modèle image-texte multimodal pour la modélisation du contexte, appelé « module d'apprentissage de recettes » (Recipe Learning Module, ou ReLeM). Dans le cadre du projet, les membres de l'équipe du CDSP ont testé et vérifié manuellement le rendement des modèles SETR et ReLeM, que nous expliquerons plus loin dans le présent article.
Ensembles de données
Les trois ensembles de données publiques que nous avons utilisés pour concevoir notre ensemble de données définitif convenaient à notre objectif de segmentation sémantique au niveau des ingrédients pour les images d'aliments. Cependant, étant donné que chaque ensemble de données comporte un ensemble différent de catégories d'aliments, nous avons dû les mettre manuellement en correspondance avec des catégories dérivées d'un guide de nutrition (Valeur nutritive de quelques aliments usuels). Les figures 1, 2 et 3 montrent des exemples d'images et de leurs étiquettes pour chacun des trois ensembles de données. Les étiquettes sont des masques de segmentation d'images utilisés pour annoter chaque pixel et distinguer des éléments tels que l'eau, le pain et d'autres aliments.
FoodSeg103
- 7,118 images (4,983 images d'entraînement, 2,135 images de validation
- 102 catégories d'aliments
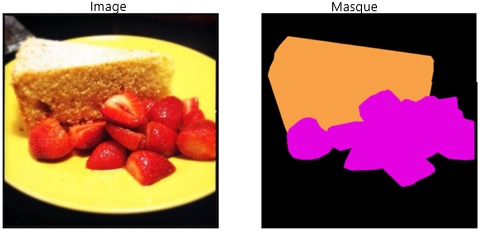
Figure 1 : Exemple d'image et de résultat tirés de l'ensemble de données FoodSeg103
Une image d'un gâteau et de fraises tranchées à gauche. L'image de sortie à droite représente la forme du gâteau et des fraises dans leurs propres couleurs.
| Couleur | Nom de Colour | Catégorie initiale | Guide de nutrition |
|---|---|---|---|
| L'arrière-plan de la cellule du tableau est coloré "Saumon clair" | Saumon clair | Gâteau | Gâteau |
| L'arrière-plan de la cellule du tableau est coloré "Magenta" | Magenta | Fraise | Fraise |
UECFoodPIX
- 10,000 images (9,000 images d'entraînement, 1,000 images de validation)
- 102 catégories d'aliments

Figure 2 : Exemple d'image et de résultat tirés de l'ensemble de données UECFoodPIX.
Une image d'aliments composée de saumon, d'une omelette, de riz, d'une soupe et d'autres aliments à gauche. L'image de sortie à droite représente les formes des images d'aliments dans leurs couleurs correspondantes.
| Couleur | Nom de Colour | Catégorie initiale | Guide de nutrition |
|---|---|---|---|
| L'arrière-plan de la cellule du tableau est coloré "Lime" | Lime | Autres | Autres |
| L'arrière-plan de la cellule du tableau est coloré "Bleu royal" | Bleu royal | Riz mélangé | Céréales, riz |
| L'arrière-plan de la cellule du tableau est coloré "Bleu ardoise" | Bleu ardoise | Soupe de miso | Soupe |
| L'arrière-plan de la cellule du tableau est coloré "Bleu ardoise moyen" | Bleu ardoise moyen | Boisson | Boisson |
| L'arrière-plan de la cellule du tableau est coloré "Brique de feu" | Brique de feu | Saumon grillé | Poisson |
| L'arrière-plan de la cellule du tableau est coloré "Lime" | Lime | Autres | Autres |
MyFoodRepo
- 58,157 images (54,392 images d'entraînement, 946 images de validation et 2,819 images d'essai)
- 323 catégories d'aliments
- Nous avons utilisé des techniques de raffinement pour pallier le problème lié aux masques grossiers.
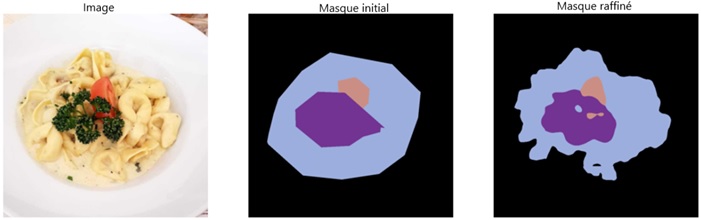
Figure 3 : Exemples d'images tirés de l'ensemble de données MyFoodRepo.
Une image d'aliments composée de pâtes à la crème, garnies de persil et de tomates à gauche. Deux images de sortie à droite représentent les formes des images d'aliments dans leurs couleurs correspondantes, l'une pour le masque initial et l'autre pour le masque raffiné.
| Couleur | Nom de Colour | Catégorie initiale | Guide de nutrition |
|---|---|---|---|
| L'arrière-plan de la cellule du tableau est coloré "Bleu acier clair" | Bleu acier clair | Sauce à la crème | Sauce |
| L'arrière-plan de la cellule du tableau est coloré "Violet" | Violet | Persil | Persil |
| L'arrière-plan de la cellule du tableau est coloré "Saumon foncé" | Saumon foncé | Tomate | Tomate |
Certaines catégories se chevauchent dans chaque ensemble de données étiquetées et ont été combinées en une seule dans notre ensemble de données définitif. Après la suppression de quelques étiquettes en raison du nombre insuffisant d'exemples d'images et après le regroupement d'autres étiquettes afin d'obtenir des groupes cohérents de types d'aliments similaires, 187 types différents d'aliments et de boissons ont été établis au total.
Segmentation d'images
La segmentation d'images constitue la base de nombreuses tâches de vision par ordinateur en aval, comme la détection d'objets et la classification d'images. C'est une méthode qui consiste à diviser une image en sous-groupes. Cette division s'effectue habituellement en fonction du contour ou des limites visibles des objets dans une image afin d'en réduire la complexité. La segmentation peut également signifier l'attribution d'étiquettes à chaque pixel d'une image dans le but de définir les éléments importants. La segmentation d'images a plusieurs utilités dans les domaines des véhicules autonomes, de l'analyse d'images médicales et d'images satellites, de la vidéosurveillance et d'autres tâches de reconnaissance et de détection. La segmentation d'images est également utilisée en imagerie médicale, comme l'indique un récent article du Réseau de la science des données intitulé « Segmentation d'images en imagerie médicale ». Les modèles de segmentation d'images basés sur un réseau neuronal contiennent presque toujours un encodeur et un décodeur. L'encodeur sert à l'apprentissage de la représentation des caractéristiques, et le décodeur sert à la classification en pixels des représentations des caractéristiques.
Trois grands types de techniques de segmentation d'images sont utilisés couramment dans le domaine de la vision par ordinateur :
- Segmentation sémantique : Elle permet d'associer chaque pixel d'une image à une étiquette de catégorie, comme une voiture, un arbre, un fruit ou une personne. Elle traite plusieurs objets de la même catégorie comme une seule entité.
- Segmentation d'instance : Elle ne permet pas d'associer chaque pixel d'une image à une étiquette de catégorie. Elle traite plusieurs objets de la même catégorie en tant qu'instances individuelles distinctes, sans nécessairement reconnaître les instances individuelles. Par exemple, la voiture 1 et la voiture 2 sont représentées par des couleurs différentes dans une image.
- Segmentation panoptique : Elle permet de combiner les concepts de segmentation sémantique et de segmentation d'instance, et d'attribuer deux étiquettes à chaque pixel d'une image, à savoir l'étiquette sémantique et l'identificateur d'instance.
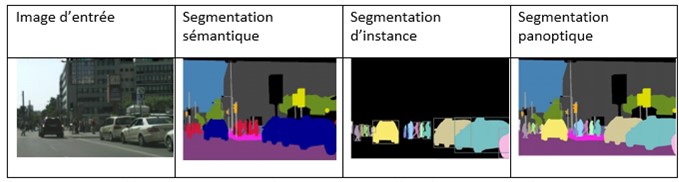
Figure 4 : Exemple de segmentation sémantique, de segmentation d'instance et de segmentation panoptique à partir d'une seule image d'entrée.
Quatre images représentant une image d'entrée et trois types de segmentation utilisés sur l'image, à savoir la segmentation sémantique, la segmentation d'instance et la segmentation panoptique.
Pipeline de segmentation d'images d'aliments
Les modèles de segmentation sémantique ont été jugés appropriés pour notre modèle de reconnaissance des aliments. Cela s'explique principalement par la capacité du modèle à reconnaître le type de nourriture ou de boisson, puisque c'était le principal objectif de l'exercice. Les réseaux entièrement convolutifs (REC) sont des choix populaires pour la segmentation sémantique. Cependant, les modèles d'encodeurs basés sur la résolution spatiale des images d'entrée par sous-échantillonnage du REC entraînent la création de mises en correspondance des caractéristiques à basse résolution. Dans l'article intitulé « Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers », les auteurs ont proposé un nouveau modèle de segmentation basé sur l'architecture de transformateur pur, appelé « transformateur de segmentation » (SEgmentation TRansformer, ou SETR). Un encodeur SETR traite une image d'entrée comme une séquence de morceaux d'image représentés par la vectorisation de morceaux d'image acquis, puis transforme la séquence au moyen de la modélisation par autoattention globale pour l'apprentissage de la représentation discriminante des caractéristiques. Ce modèle a fourni davantage de contexte pour la tâche de reconnaissance des aliments à l'aide du module ReLeM, comme l'ont proposé les auteurs du rapport intitulé « A Large-Scale Benchmark for Food Image Segmentation ». Les modules SETR et ReLeM sont expliqués plus en détail ci-dessous.
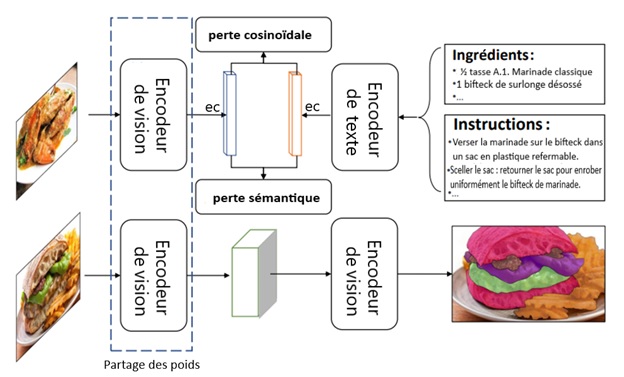
Figure 5 : Diagramme du pipeline de segmentation d'images d'aliments. Source : A Large-Scale Benchmark for Food Image Segmentation.
Le diagramme du pipeline de segmentation d'images d'aliments montre l'interaction entre le module d'apprentissage de recettes et le module de segmentation d'images.
Texte dans l'image : Encodeur de vision, ec perte cosinoïdale/perte sémantique ec, Encodeur de texte, Ingrédients : ½ tasse A.1. Marinade classique, 1 bifteck de surlonge désossé. Instructions : Verser la marinade sur le bifteck dans un sac en plastique refermable. Sceller le sac : retourner le sac pour enrober uniformément le bifteck de marinade. Encodeur de vision (partage des poids), Décodeur de vision
Encodeur de vision (partage des poids) à Décodeur de vision
Module d'apprentissage de recettes
Le module ReLeM fournit des modèles contenant des renseignements contextuels sur les ingrédients tirés de recettes de cuisine. Dans l'article intitulé « A Large-Scale Benchmark for Food Image Segmentation », les auteurs décrivent le module ReLeM comme [traduction] « une approche de préentraînement multimodal […] qui permet de doter de manière explicite un modèle de segmentation de connaissances riches et sémantiques sur les aliments ».
Le module a été entraîné à l'aide d'un ensemble de données Recipe1M (voir Learning Cross-Modal Embeddings for Cooking Recipes and Food Images). Cet ensemble de données contient plus de 1 million de recettes et 800 000 images d'aliments. En étant exposé à des recettes et à des images d'aliments, le module ReLeM forme des associations entre les ingrédients, un peu comme les humains comprennent quels aliments se trouvent généralement ensemble.
Lors de l'entraînement d'un modèle de classification des images d'aliments, il est important d'utiliser des recettes comme données d'entraînement. Cela permet au module de créer des associations entre des ingrédients qui peuvent varier visuellement lorsqu'ils sont préparés différemment. Le module ReLeM apprend également les instructions de préparation des aliments dans des recettes. Par exemple, les aubergines en purée diffèrent visuellement des aubergines frites. En revanche, il peut y avoir différents ingrédients qui se ressemblent, comme le lait et le yogourt. Le module ReLeM a établi des associations entre les ingrédients et les aliments qui apparaissent souvent ensemble, ce qui est utile dans ces scénarios. Par exemple, si un verre contenant une substance blanche et une assiette de biscuits aux pépites de chocolat figurent dans l'image, le module ReLeM pourrait déduire que la substance blanche est plus probablement du lait que du yogourt, puisqu'il y a une association connue entre le lait et les biscuits. Le module ReLeM s'appuie sur la perte sémantique et cosinoïdale pour déterminer la similitude entre les aliments.
Modèle de transformateur de segmentation
Les transformateurs et les modèles d'autoattention ont permis d'améliorer la compréhension et le rendement du traitement du langage naturel. Les modèles GPT-3 (transformateur génératif préentraîné de troisième génération) et BERT (représentations de l'encodeur bidirectionnel à partir de transformateurs), très populaires dans le domaine du traitement du langage naturel, sont basés sur l'architecture du transformateur. La même architecture peut être utilisée pour les images, mais cet apprentissage de séquence à séquence suppose des séquences 1D en entrée. Le modèle d'encodeur SETR de pointe prétraite les images 2D avant de les alimenter dans l'architecture du transformateur. L'image 2D est décomposée en petits morceaux de taille fixe, puis chaque morceau est converti en une séquence 1D. Cette séquence de morceaux d'image est représentée par la vectorisation de morceaux d'images acquis dont il a été question dans le document mentionné précédemment sur la segmentation sémantique. Une fois cette séquence de vectorisation des caractéristiques fournie à l'entrée, le transformateur apprend la représentation discriminante des caractéristiques qui sont retournées à la sortie de l'encodeur SETR. Le modèle de l'encodeur est plus complexe que le modèle du décodeur, puisqu'il doit apprendre et produire une représentation de caractéristiques complexes pour différencier chaque catégorie avec précision.
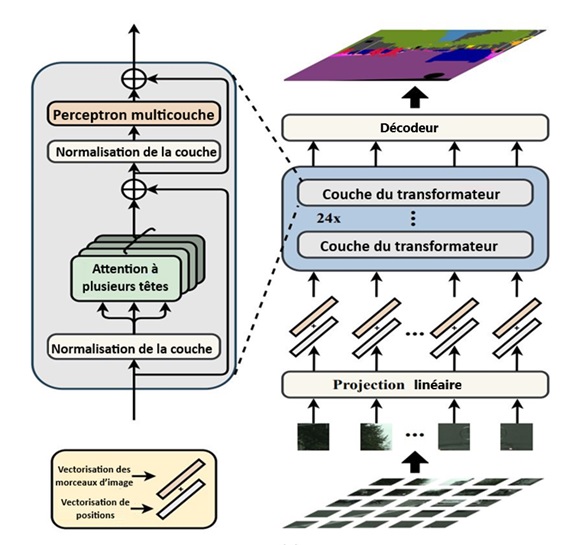
Figure 6 : Encodeur SETR tiré de l'article « Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers »
Le diagramme illustre la conception du transformateur de segmentation (SETR).
Texte dans l'image : Vectorisation des morceaux d'image et Vectorisation de positions, Normalisation de la couche, Attention à plusieurs têtes, Perceptron multicouche. Projection linéaire, 24x, Couche du transformateur, Décodeur
Un décodeur est ensuite utilisé pour récupérer la résolution d'image d'origine au moyen d'une classification à l'échelon des pixels. Dans notre cas, nous avons utilisé le décodeur d'agrégation de caractéristiques à plusieurs niveaux (multi-level feature aggregation, ou MLA). Le décodeur MLA accepte les représentations des caractéristiques de chaque couche du SETR. Toutes ces représentations de caractéristiques ont en commun la même résolution (aucune perte de résolution comme au moyen d'un REC) et passent par une série de remodelage et de suréchantillonnage pour obtenir les étiquettes de pixels.
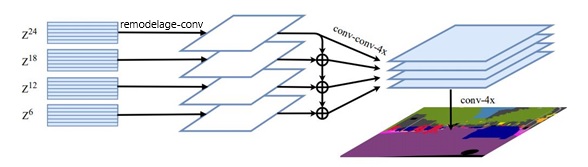
Figure 7 : Décodeur MLA tiré de l'article« Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers »
Le diagramme illustre l'agrégation des caractéristiques à plusieurs niveaux. Plus précisément, une variante de type SETR-MLA.
Texte dans l'image : Z24, Z18, Z12, Z6, remodelage-conv, conv-conv-4x, conv-4x
Résultats
Voici les résultats de validation fondés sur les mesures de la moyenne de l'intersection sur l'union (MIoU), de l'exactitude moyenne (mAcc) et l'exactitude globale (aAcc) :
| Mesure | Valeur |
|---|---|
| MIoU | 40,74 % |
| mAcc | 51,98 % |
| aAcc | 83,21 % |
Résultats de tests basés sur les mesures de la précision, du rappel et du score F1 :
| Mesure | Valeur |
|---|---|
| Précision | 81,43 % |
| Rappel | 80,16 % |
| Score F1 | 80,79 % |
Sans l'initialisation de l'encodeur de vision selon les poids ReLeM entraînés :

Figure 8 : Exemple d'un masque prédit sans l'initialisation de l'encodeur de vision selon les poids ReLeM entraînés.
Une image de muffins à gauche et un exemple d'un masque prédit à droite sans initialisation de l'encodeur de vision selon les poids ReLeM entraînés.
| Couleur | Nom de Colour | Catégorie prédite |
|---|---|---|
| L'arrière-plan de la cellule du tableau est coloré "Jaune Vert" | Jaune Vert | Pain, grains entiers (blé entier) |
| L'arrière-plan de la cellule du tableau est coloré "Turquoise" | Turquoise | Thé |
| L'arrière-plan de la cellule du tableau est coloré "Saumon foncé" | Orchidée | Pomme |
| L'arrière-plan de la cellule du tableau est coloré "Orchidée moyenne" | Orchidée moyenne | Patate douce |
| L'arrière-plan de la cellule du tableau est coloré "Magenta" | Magenta | Boulette de pâte (dumpling) |
Au moyen de l'initialisation de l'encodeur de vision selon les poids ReLeM entraînés :

Figure 9 : Exemple d'un masque prédit au moyen de l'initialisation de l'encodeur de vision selon les poids ReLeM entraînés.
Une image de muffins à gauche et un exemple d'un masque prédit à droite au moyen de l'initialisation de l'encodeur de vision selon les poids ReLeM entraînés.
| Couleur | Nom de Colour | Catégorie prédite |
|---|---|---|
| L'arrière-plan de la cellule du tableau est coloré "Turquoise" | Turquoise | Gâteau |
| L'arrière-plan de la cellule du tableau est coloré "Vert foncé" | Vert foncé | Banane |
Conclusion
Le modèle de reconnaissance des aliments permet de prédire avec exactitude plusieurs aliments et boissons figurant dans une image en moins d'une seconde, et il permet d'obtenir systématiquement de bons résultats avec certaines catégories, comme le pain. Cependant, il a plus de difficultés avec des catégories d'apparence semblable, comme le bœuf et l'agneau. Le rendement peut être amélioré en ajoutant plus de données étiquetées pour des catégories minoritaires, en effectuant une ronde supplémentaire de reclassification des aliments d'apparence semblable et en utilisant des techniques contre le déséquilibre des catégories.
Rencontre avec le scientifique des données

Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Mardi, le 17 janvier
14 h 00 à 15 h 00 HE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données. À bientôt !
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
- Date de modification :