
Considérations sur les biais dans le traitement bilingue des langues naturelles
par : Marie-Pier Schinck, Eunbee (Andrea) Jang et Julien-Charles Lévesque, Emploi et Développement social Canada
Introduction et objectif de l'étude
Ces dernières années, le ministère de l'Emploi et Développement social Canada (EDSC) a utilisé le traitement du langage naturel (TLN) dans de nombreux projets et a repéré des défis associés au travail lorsque la proportion de données de chaque langue officielle est débalancée. Les récents progrès réalisés dans le domaine du TLN sont principalement axés sur la langue anglaise, et les ressources consacrées aux langues autres que l'anglais sont limitées. Ainsi, lorsqu'ils travaillent sur des solutions de TLN appliquées pour EDSC, les scientifiques des données doivent prendre des décisions concernant le traitement de la langue française, tout en faisant face à des ressources limitées et à des priorités concurrentes.
Les auteurs de cette étude ont initialement soulevé des préoccupations concernant le traitement de la langue française en se fondant principalement sur leur expérience en tant que scientifiques des données travaillant avec des ensembles de données bilingues à EDSC (voir : Langues officielles et traitement du langage naturel). En réponse, les auteurs ont consulté divers scientifiques des données fédéraux et des chercheurs en TLN. Ils ont alors constaté que ces défis ne se limitaient pas à EDSC et étaient, en fait, communs à divers ministères et organismes.
L'objectif principal du projet est d'explorer cette question et d'acquérir des connaissances transférables que les scientifiques des données peuvent utiliser pour améliorer l'équité des solutions fournies par EDSC.
Comme point de départ, nous mesurons l'ampleur du biais linguistique dans quatre projets d'EDSC où des systèmes de classification multilingue ont été mis en œuvre. Nous mettons également à l'essai des stratégies de rééquilibrage afin de mieux comprendre la représentation idéale de la langue minoritaire. Nous comparons les rendements des modèles dans plusieurs scénarios, à savoir des modèles multilingues, des modèles unilingues séparés, ou une approche interlinguistique fondée sur une traduction du français vers l'anglais permettant un entraînement unilingue à partir d'un modèle unilingue anglais. Nous pouvons ainsi observer la mesure dans laquelle les rendements des modèles s'améliorent ou se détériorent en fonction de chaque langue.
2 – Mise en place de l'étude
Les quatre ensembles de données utilisés dans le cadre de cette étude portent sur des problèmes de classification supervisée de projets antérieurs et en cours à EDSC. Le champ d'application a été limité à des problèmes de classification supervisée afin de représenter le temps et les ressources disponibles pour ce projet, en raison de la facilité d'accès aux données et parce qu'il s'agit de la tâche de TLN la plus communément traitée par notre équipe.
| Ensemble de données | Description | Nombre de documents | Proportion de données françaises |
|---|---|---|---|
| T4 | Notes de résumé des appels rédigées par les agents du centre d'appels de Service Canada (SC). Ces notes sont généralement constituées de phrases courtes et incomplètes utilisant du jargon administratif. Le projet vise à réduire le travail humain coûteux en repérant automatiquement les cas où SC a renvoyé un formulaire T4 aux particuliers. | 6 000 | 35 % |
| RH | Réponses des candidats et candidates à une question de présélection dans un processus d'embauche. Ce projet de recherche a été entrepris pour évaluer la faisabilité de l'utilisation du TLN pour filtrer un bassin de candidats et candidates dans le cadre de processus de recrutement à grande échelle. | 5 000 | 6 % |
| RE | Commentaires rédigés par les employeurs sur les formulaires de relevé d'emploi (RE) reçus par SC. Les commentaires figurant sur les RE sont généralement des phrases courtes et incomplètes qui utilisent fréquemment du jargon utilisé dans le domaine de l'assurance-emploi. Le projet est conçu pour réduire le travail manuel des employés de SC en classant les commentaires figurant sur les RE en divers objectifs. | 280 000 | 28 % |
| DGAPRI | Articles d'actualité provenant de sources médiatiques canadiennes, obtenus par l'intermédiaire de la plateforme InfoMedia. La tâche consiste à indiquer si un article doit être signalé comme une source pertinente à inclure dans un dossier destiné aux sous-ministres. | 69 000 | 25 % |
2.1 – Vectorisation et architecture du modèle
Pour notre expérience, nous avons entraîné des modèles pour chaque ensemble de données et pour plusieurs méthodes de vectorisation, architectures de modèles et configurations d'hyperparamètres (voir tableau 2). Les méthodes de vectorisation et les modèles choisis couvrent certains des outils les plus courants utilisés pour les problèmes de classification de TLN. Les méthodes de vectorisation comprennent une méthode de sélection des caractéristiques appliquée aux sacs de mots reposant sur la distribution khi carré (Chi2BOW), des vectorisations FastText (FT) et des vectorisations contextuelles provenant d'un algorithme multilingue BERT (Devlin et al., 2018b).
Pour la configuration du modèle, nous disposons de deux grands ensembles d'architectures de classification, que nous appelons les méthodes d'apprentissage contextuelles et non contextuelles. On entend par « non contextuel » les systèmes d'apprentissage qui traitent des représentations agrégées de phrases et rejettent les renseignements relatifs à l'ordre des mots. Il s'agit notamment de la régression logistique (LR), du perceptron multicouche (MLP) et de XGBoost (XGB; Chen et Guestrin, 2016). En revanche, les approches contextuelles prennent en compte les renseignements relatifs à l'ordre des mots dans l'apprentissage et la prédiction. Nous avons mis en œuvre deux architectures de modèles contextuelles, un réseau de neurones récurrents à mémoire court et long terme (LSTM, Hochreiter et Schmidhuber, 1997) et un modèle populaire basé sur l'attention appelé BERT (Devlin et al., 2018a). Les détails de la recherche des hyperparamètres sont inadmissibles pour le présent article, mais les principaux résultats sont fournis à la lumière d'une méthodologie de recherche exhaustive. Nous avons également évalué les méthodes de LR, de MLP et de XGB avec une simple vectorisation de sac de mots (sans sélection de caractéristiques du khi carré), bien qu'elle soit omise dans cet article pour simplifier la présentation. N'hésitez pas à communiquer avec les auteurs pour obtenir le rapport dans son intégralité.
| Vectorisation | Modèles |
|---|---|
| Khi carré avec sac de mots (Chi2BOW) | Régression logistique (RL) |
| Chi2BOW | Perceptron multicouche (MLP) |
| Chi2BOW | XGBoost (XGB) |
| FastText (FT) | LSTM |
| BERT (WordPiece) | BERT |
3 – Présence de biais
Dans la présente étude, nous nous intéresserons au biais linguistique en examinant la disparité dans la précision des tests entre les deux langues officielles. La présence de biais sera évaluée dans plusieurs contextes différents, et ceux-ci seront abordés plus en détail ci-dessous.
Disparité des rendements des modèles multilingues
Notre première expérience consistait à entraîner des modèles multilingues (c.-à-d. un entraînement simultané des deux langues avec un seul modèle), avec les méthodes abordées dans la section précédente, en utilisant la représentation linguistique trouvée dans les ensembles de données originaux (sans rééquilibrage). Pour évaluer la présence d'un biais linguistique, nous avons ensuite comparé le rendement obtenu pour la partie française des données avec celui obtenu pour la partie anglaiseNote de bas de page 1. La figure 1 montre la précision des tests par langue pour la meilleure configuration des hyperparamètres de chaque méthode testée.
Figure 1 : Précision du test par rapport à la langue du texte.
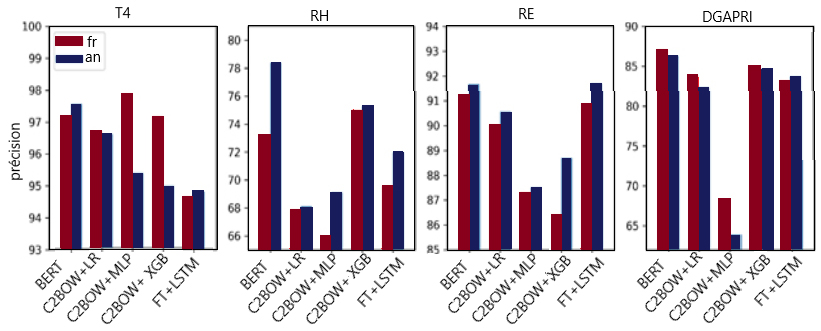
Figure 1 : Précision du test par rapport à la langue du texte.
Rendements de toutes les méthodes énumérées au tableau 2, réparties par ensemble de données et par langue. Les données détaillées sont présentées ci-dessous.
| Ensemble de données | T4 | RH | RE | DGAPRI | ||||
|---|---|---|---|---|---|---|---|---|
| Méthode/Langue | Ang. | Fr. | Ang. | Fr. | Ang. | Fr. | Ang. | Fr. |
| BERT | 97,6 | 97,2 | 78,4 | 73,2 | 91,7 | 91,2 | 86,3 | 87,0 |
| C2BOW + LR | 96,6 | 96,7 | 68,1 | 67,9 | 90,6 | 90,0 | 82,3 | 83,8 |
| C2BOW + MLP | 95,4 | 97,9 | 69,1 | 66,1 | 87,5 | 87,3 | 63,9 | 68,3 |
| C2BOW + XGBoost | 95,0 | 97,2 | 75,3 | 75,0 | 88,7 | 86,4 | 84,6 | 85,0 |
| FT + LSTM | 94,8 | 94,7 | 72,0 | 69,6 | 91,7 | 90,9 | 83,7 | 83,2 |
Un examen de la figure 1 nous permet d'abord de conclure qu'aucune tendance dominante ne se perpétue dans les quatre ensembles de données. Par exemple, l'ensemble de données du projet des RE montre que les résultats obtenus pour la partie anglaise des données surpassent systématiquement ceux de la partie française des données. En revanche, pour l'ensemble de données du projet T4, la tendance inverse se dégage; en effet, la plupart des méthodes produisent pour la partie française un rendement supérieur à celui de la partie anglaise. Cela peut s'expliquer par le fait que l'ensemble de données du projet T4 contient la plus grande proportion de données françaises ainsi que par le contenu des données en soi, où le contexte commercial appuie l'hypothèse d'une distribution sous-jacente différente pour chaque langue, de sorte que le problème de classification est plus facile à résoudre en français qu'en anglais. Les ensembles de données des projets de la DGAPRI et des RH affichent des tendances moins claires : le rendement du français surpasse légèrement celui de l'anglais pour la DGAPRI, tandis qu'on observe l'inverse pour les RH.
Pour obtenir une image plus détaillée, nous avons compilé les différences de rendement de ces expériences et les avons normalisées en calculant leurs écarts réduits (des scores plus élevés indiquant un meilleur rendement relatif en anglais). Cet exercice a révélé qu'en moyenne, les modèles multilingues entraînés pour cette étude ont obtenu des résultats légèrement supérieurs en anglais qu'en français, par un facteur de 0,13 écart-type sur la mesure de rendement. Les tendances sur les ensembles de données individuels sont légèrement plus fortes, avec une différence moyenne de 0,56 et 0,41 écart-type respectivement pour les ensembles de données des projets des RE et des RH, et de -0,33 pour le projet T4. Malgré ce léger biais général en faveur de l'anglais, la principale conclusion de ces résultats est l'importance d'une analyse de rendement minutieuse propre à la langue dans l'utilisation de modèles multilingues, car la présence de biais variera en fonction des propriétés de l'ensemble de données et du contexte commercial qui sous-tend la collecte des données.
Influence de la distribution des langues dans les systèmes multilingues
Dans la présente section, nous explorons l'incidence de la proportion linguistique (c.-à.d. le rapport entre les données françaises et anglaises) dans les systèmes multilingues. Nous évaluons deux méthodes qui sont couramment utilisées pour les tâches de classification du TLN et qui ont donné des résultats satisfaisants sur nos repères : BOW+XGBoost et BERT. Pour notre évaluation, nous utiliserons l'ensemble de données du projet des RE en raison de sa taille plus importante.
Dans l'expérience, le sous-échantillonnage est appliqué à l'une des langues afin d'obtenir un rapport cible entre les données françaises et les données anglaises de l'ordre de 10:90 à 90:10. Les données d'essai restent intactes avec un rapport entre le français et l'anglais de 28:72, afin d'effectuer chaque fois une évaluation en fonction des mêmes échantillons.
Figure 2 : Expérience de rapport linguistique sur des données du projet des RE. À gauche : Sacs de mots avec un classificateur XGBoost. À droite : Moyenne du modèle BERT sur trois répétitions par rapport.
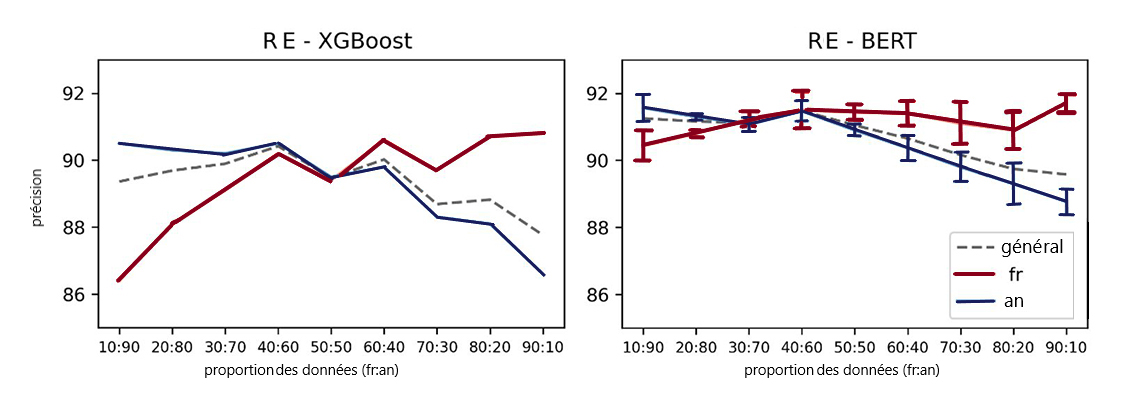
Figure 2 : Expérience de rapport linguistique sur des données du projet des RE. À gauche : Sacs de mots avec un classificateur XGBoost. À droite : Moyenne du modèle BERT sur trois répétitions par rapport.
Les deux graphiques ci-dessus montrent le résultat des expériences de rapport linguistique sur l'ensemble de données du projet des RE. À gauche se trouvent les rendements du modèle XGBoost et à droite, les rendements du modèle BERT, avec une moyenne établie sur trois répétitions par rapport. L'axe des x des deux graphiques montre la proportion des données, une série de rapports entre le français et l'anglais. Il part d'un rapport de 10:90 entre le français et l'anglais pour arriver à un rapport de 90:10. L'axe des y est le score de précision exprimé en pourcentage. La ligne pointillée grise représente le score de précision général de chaque modèle, et les lignes colorées pleines montrent séparément le rendement de chaque langue : le rouge représente la partie française des données, et le bleu la partie anglaise des données. D'après ces chiffres, l'augmentation de la proportion d'une langue pour l'entraînement d'un modèle entraînera une amélioration des rendements dans cette langue, et la tendance inverse est également observée. De plus, les graphiques montrent que le rapport où le français et l'anglais ont la plus faible disparité en matière de rendements est différent du rapport original (28:72) de l'ensemble de données. Il s'agit d'un rapport de 50:50 pour le modèle XGBoost (à gauche) et d'un rapport de 40:60 pour le modèle BERT.
La figure 2 illustre les rendements de ces deux modèles avec les répartitions des rapports de données décrites ci-dessus. Comme prévu, l'expérience montre qu'une diminution de la proportion de données dans une langue donnée tend à réduire le rendement dans cette langue dans tous les cas; la tendance inverse est observée lorsque la proportion d'une langue augmente, bien que le rendement reste parfois stable pour divers rapports. La courbe de précision générale est systématiquement plus proche de la courbe de précision de l'anglais, car elle est calculée sur un ensemble de tests utilisant le rapport linguistique fixe (fr:ang) que l'on trouve dans l'ensemble de données original (28:72).
Les expériences montrent également que les rapports linguistiques optimaux varient en fonction des diverses méthodes d'apprentissage. Plus précisément, pour BOW + XGBoost, les scores de précision du français et de l'anglais présentent l'écart le plus faible avec un rapport de 50:50 (fr:ang). Avec la méthode BERT, les deux langues présentent le plus faible écart de précision aux rapports 30:70 et 40:60. Ceci est particulièrement intéressant étant donné que le rapport optimal est différent du rapport original dans l'ensemble de données, dans ce cas 28:72.
Cette expérience indique que la manipulation artificielle de la proportion linguistique peut intensifier ou améliorer les biais. Il est conseillé d'avoir une proportion de langues quelque peu équilibrée à l'entraînement afin de réduire la disparité entre le rendement des deux langues. Cependant, il faut faire un compromis entre la précision générale (précision pour l'ensemble des échantillons) et la précision pour les textes français et anglais : le point de rendement optimal peut ne pas être le même pour les deux critères.
Compromis entre la modélisation multilingue et unilingue
Dans la présente section, nous présentons une analyse de la disparité des rendements pour chaque langue dans l'entraînement d'un modèle dans les deux langues, ce qu'on appelle le contexte multilingue (multi), et dans l'entraînement de deux modèles (un par langue), soit le contexte unilingue (uni). Les résultats sont présentés séparément pour chaque langue; la section en langue française comprend également le rendement d'un système unilingue anglais entraîné avec des données françaises traduites vers anglais (trad_uni). Il convient de souligner que le modèle n'a été entraîné qu'avec des données françaises traduites, plutôt qu'avec l'ensemble des données comprenant les données originales anglaises et les données françaises traduites, principalement en raison de contraintes en termes de ressources informatiques. Cette expérience vise à comprendre la mesure dans laquelle le signal nécessaire à la classification demeure intact après la traduction de documents. Pour la traduction, nous utilisons le modèle de traduction automatique neuronal Marian.Note de bas de page 2
Anglais
Le diagramme à barres de la figure 3 montre le meilleur rendement de chaque méthode pour la partie anglaise des données. Deux barres sont associées à chaque méthode : la barre de gauche montre le contexte multilingue et la barre de droite, le contexte unilingue.
En termes d'architecture de modèle, on constate que le modèle BERT est le plus performant sur tous les ensembles de données. En revanche, la méthode de perceptron multicouche avec vectorisation du sac de mots au khi carré (C2BOW + MLP) est l'une des configurations les moins performantes parmis tous les ensembles de données.
Figure 3 : Comparaison du rendement en anglais (précision du test) dans deux contextes – multilingue et unilingue
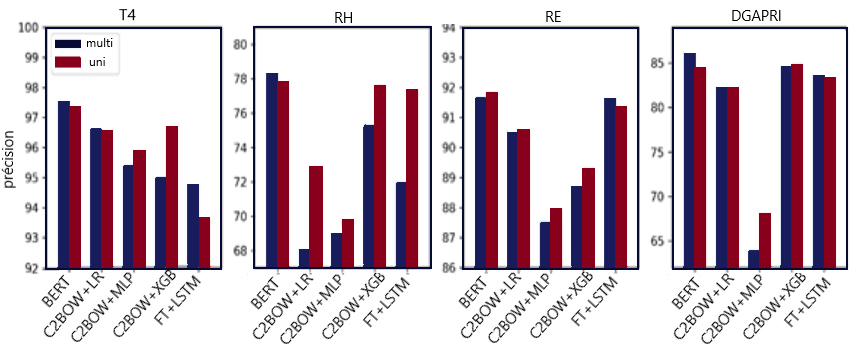
Figure 3 : Comparaison du rendement en anglais (précision du test) dans deux contextes – multilingue et unilingue
Rendement sur des textes anglais pour toutes les méthodes énumérées au tableau 2 entraînées dans un cadre unilingue et multilingue, réparties par ensemble de données. Les données détaillées sont présentées ci-dessous.
| Ensemble de données | T4 | RH | RE | DGAPRI | ||||
|---|---|---|---|---|---|---|---|---|
| Méthode/Mode | Multi | Uni | Multi | Uni | Multi | Uni | Multi | Uni |
| BERT | 97,57 | 97,35 | 78,40 | 77,84 | 91,66 | 91,83 | 86,29 | 84,47 |
| C2BOW + LR | 96,63 | 96,56 | 68,14 | 72,87 | 90,56 | 90,58 | 82,34 | 82,12 |
| C2BOW + MLP | 95,41 | 95,90 | 69,09 | 69,79 | 87,52 | 87,95 | 63,92 | 68,07 |
| C2BOW + XGB | 95,01 | 96,69 | 75,30 | 77,61 | 88,70 | 89,30 | 84,65 | 84,83 |
| FT + LSTM | 94,82 | 93,65 | 71,97 | 77,37 | 91,69 | 91,37 | 83,70 | 83,30 |
Pour les ensembles de données des projets T4, des RH et de la DGAPRI, le rendement du modèle BERT est plus élevé dans le contexte multilingue, tandis que le contexte unilingue surpasse légèrement le contexte multilingue pour l'ensemble de données du projet des RE, qui, fait intéressant, est le plus grand ensemble de données. Bien que l'entraînement multilingue semble donner de meilleurs résultats pour les modèles reposant sur BERT, les méthodes multilingues affichent, dans leur ensemble, un rendement légèrement inférieur à celui des modèles unilingues, en moyenne de 0,56 %. Nous considérons cela comme une preuve que la méthode d'entraînement (multilingue ou unilingue) n'a pas d'incidence considérable sur la catégorie de langue dominante, l'anglais.
Français
La figure 4 présente la comparaison générale des trois approches avec la modélisation française. Plus précisément, nous comparons le rendement de la partie française des données dans le contexte multilingue (multi) avec des approches unilingues, l'une avec des modèles entraînés avec des données françaises originales (uni) et l'autre avec les données françaises traduites en anglais à introduire dans un système unilingue anglais (trad_uni). Pour trad_uni, nous utilisons uniquement la partie française des données pour l'entraînement, et laissons de côté les données originales en anglais, afin d'observer directement l'incidence de l'approche axée sur la traduction sur la langue minoritaire.
Figure 4 : Comparaison du rendement du français pour trois approches – multilingue, unilingue, traduit unilingue.
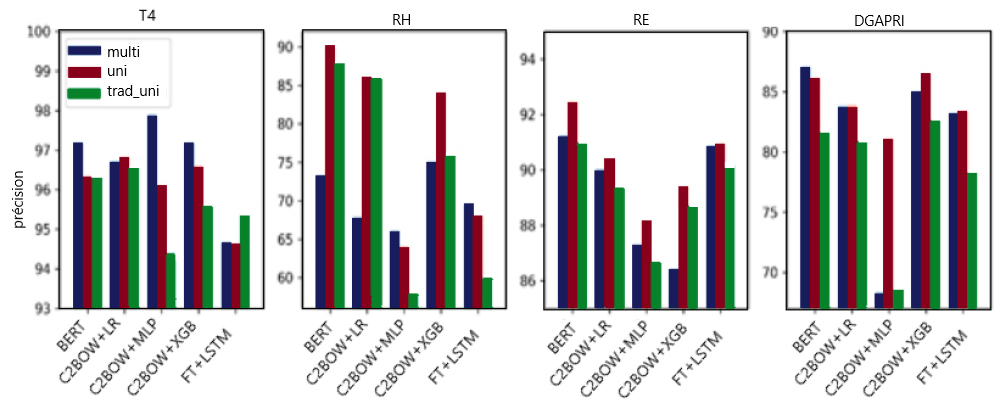
Figure 4 : Comparaison du rendement du français pour trois approches – multilingue, unilingue, traduit unilingue.
Rendement sur des textes français pour toutes les méthodes énumérées au tableau 2 entraînées dans un contexte unilingue ou multilingue, réparties par ensemble de données. Les données détaillées sont présentées ci-dessous.
| Ensemble de données | T4 | RH | RE | DGAPRI | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Méthode/Mode | multi | trad_uni | uni | multi | trad_uni | uni | multi | trad_uni | uni | multi | trad_uni | uni |
| BERT | 97,18 | 96,34 | 96,34 | 73,21 | 88,00 | 90,00 | 91,23 | 90,99 | 92,45 | 87,05 | 81,63 | 86,10 |
| C2BOW + LR | 96,71 | 96,59 | 96,83 | 67,86 | 86,00 | 86,00 | 90,02 | 89,39 | 90,36 | 83,79 | 80,89 | 83,85 |
| C2BOW + MLP | 97,89 | 94,39 | 96,10 | 66,07 | 58,00 | 64,00 | 87,30 | 86,69 | 88,20 | 68,32 | 68,62 | 81,08 |
| C2BOW + XGB | 97,18 | 95,61 | 96,59 | 75,00 | 76,00 | 84,00 | 86,42 | 88,71 | 89,38 | 84,97 | 82,63 | 86,47 |
| FT + LSTM | 94,68 | 95,37 | 94,63 | 69,57 | 60,00 | 68,00 | 90,88 | 90,16 | 90,92 | 83,21 | 78,30 | 83,36 |
En ce qui concerne l'architecture des modèles, à l'instar de ce qui a été observé pour l'anglais, les meilleures méthodes ont tendance à varier en fonction de l'ensemble de données, BERT étant la méthode la plus performante dans l'ensemble. La méthode BERT est la meilleure pour les données du projet des RH, des RE et de la DGAPRI; le contexte unilingue surpasse les deux autres contextes dans les deux premiers cas (RH et RE) et le contexte multilingue obtient les meilleurs résultats pour la DGAPRI. Il est intéressant de noter que la méthode Chi2BOW + MLP offre un résultat supérieur à toutes les autres méthodes pour l'ensemble de données du projet T4, alors qu'elle obtient les plus mauvais résultats pour les trois autres ensembles de données.
En ce qui concerne les systèmes d'entraînement, nous remarquons tout d'abord que trad_uni semble être le contexte le moins performant en général pour les ensembles de données des projets T4, des RE et de la DGAPRI. En ce qui concerne le projet des RH, trad_uni n'est pas toujours la pire approche, mais ce n'est pas non plus le meilleur modèle. Il semble que les erreurs de deux modèles en cascade, le modèle neuronal de traduction automatique utilisé et le classificateur principal, sont potentiellement propagées lorsqu'ils sont utilisés l'un après l'autre. Cela prouve que la traduction n'est peut-être pas une option idéale pour atténuer le problème du déséquilibre des données. Toutefois, il convient de noter que la portée de notre expérience sur l'approche fondée sur la traduction est limitée à la partie française des données et que le résultat peut varier si l'intégralité des données (soit les données anglaises et les données françaises traduites en anglais) est utilisée dans un système unilingue anglais.
Les modèles unilingues français semblent offrir des résultats supérieurs à ceux des modèles multilingues équivalents pour trois des quatre ensembles de données, soit les RH, les RE et la DGAPRI. Pour l'ensemble de données du projet T4, nous observons que les modèles multilingues surpassent la version unilingue pour la majorité des méthodes. Enfin, une évaluation des différences de scores de précision pour la partie française des données entre les modèles unilingues et multilingues nous permet de constater que les modèles unilingues surpassent en moyenne les modèles multilingues de 2,22 points de pourcentage de précision. Cette différence est beaucoup plus prononcée que ce qui a été observé pour la langue anglaise. Cela indique que le choix d'utiliser un modèle multilingue, par opposition à deux modèles unilingues, entraînera en moyenne une baisse plus importante du rendement dans la partie française des données, par rapport à la partie anglaise.
4 – Conclusion
La prise de décisions concernant le traitement de données textuelles bilingues est monnaie courante pour de nombreux spécialistes des données travaillant en tant que fonctionnaires fédéraux. Bien que le statut des langues officielles prescrit qu'il ne devrait pas y avoir de différence dans le traitement de chaque langue, cela peut être particulièrement difficile lorsque les outils de TLN sont plus nombreux et de qualité supérieure en anglais qu'en français. Cette initiative visait à acquérir des connaissances appliquées et transférables afin d'aider les spécialistes des données du gouvernement du Canada à prendre des décisions plus éclairées dans l'élaboration de solutions de TLN pour des ensembles de données bilingues.
Nos résultats ont d'abord indiqué qu'aucune tendance ne s'applique à tous les ensembles de données lorsqu'on examine le biais dans les modèles multilingues. Par exemple, l'ensemble de données du projet des RE a montré un léger biais où le rendement des commentaires en anglais est systématiquement plus élevé que celui des commentaires en français, tandis que l'analyse des données du projet T4 a révélé une tendance inverse avec un biais favorisant le français. En résumé, bien qu'il n'y ait pas de règle définitive concernant l'apparition de biais dans les modèles multilingues dans tous les ensembles de données, certains modèles ont tendance à être moins performants dans l'une des langues officielles, ce qui fait ressortir la nécessité d'une évaluation adaptée à la langue pour éviter les risques de traitement biaisé ou de répercussion disparate. Les expériences sur les proportions de langues dans le contexte multilingue ont montré que l'objectif d'une représentation de 30 % à 50 % du français par sous-échantillonnage de la langue majoritaire donne les meilleurs résultats. Plus précisément, elle permet de réduire la disparité du rendement entre les deux langues officielles, sans nuire au rendement général.
L'exploration du contexte multilingue par rapport au contexte unilingue a révélé que l'incidence sur le rendement de la partie anglaise des données était négligeable, car les deux contextes donnent des résultats semblables, bien que le rendement soit légèrement supérieur dans le contexte unilingue. D'autre part, on constate avec la partie française des données une diminution plus importante du rendement dans le contexte multilingue, par rapport au contexte unilingue. Cela signifie que, lorsqu'une identification linguistique de bonne qualité est disponible, les praticiens de la science des données dans l'ensemble du gouvernement du Canada devraient sérieusement envisager l'utilisation de deux modèles unilingues, car cela tend à donner de meilleures performances en moyenne, par opposition à l'utilisation d'un seul modèle multilingue. Enfin, la traduction du français pour l'utilisation d'un modèle unilingue anglais s'est avérée le moins prometteur des trois contextes pour tous les ensembles de données. Puisque, selon notre expérience, il comporte un plus grand risque de biais sur la langue minoritaire, nous recommandons d'effectuer une analyse complète de son incidence lorsque l'on tente de déployer un modèle unilingue unique reposant sur la traduction de la langue minoritaire.

Si vous avez des questions à propos de cet article ou si vous souhaitez en discuter, nous vous invitons à notre nouvelle série de présentations Rencontre avec le scientifique des données où le(s) auteur(s) présenteront ce sujet aux lecteurs et aux membres du RSD.
Mardi, le 21 juin
14h00 à 15h00 p.m. HAE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données. À bientôt !
References
Chen, T., et C. Guestrin. 2016. « Xgboost: A scalable tree boosting system », Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, p. 785 à 794.
Devlin, J., M.W. Chang, K. Lee et K. Toutanova. 2018a. « BERT: Pre-training of deep bidirectional transformers for language understanding », arXiv, prépublication arXiv:1810.04805.
Devlin, J., M.W. Chang, K. Lee et K. Toutanova. 2018b. Multilingual BERT, GitHub: google-research / bert (le contenu de cette page est en anglais)
Hochreiter, S., et J. Schmidhuber. 1997. « Long short-term memory », Neural Computation, vol. 9, no 8, p. 1735 à 1780.
- Date de modification :