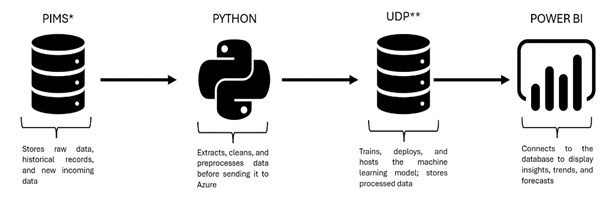
Why are we conducting this survey?
This survey collects information on scientific activities of Canadian businesses and industrial non-profit organizations. The research and development expenditures and personnel information is used by federal, provincial and territorial governments and agencies, academics, trade associations and international organizations for statistical analyses and policy purposes. These data also contribute to national totals of research and development activities. The payments and receipts information is used by these agencies to monitor knowledge flows across international borders and between Canadian businesses.
Your information may also be used by Statistics Canada for other statistical and research purposes.
Your participation in this survey is required under the authority of the Statistics Act.
Other important information
Authorization to collect this information
Data are collected under the authority of the Statistics Act, Revised Statutes of Canada, 1985, Chapter S-19.
Confidentiality
By law, Statistics Canada is prohibited from releasing any information it collects that could identify any person, business, or organization, unless consent has been given by the respondent, or as permitted by the Statistics Act. Statistics Canada will use the information from this survey for statistical purposes only.
Record linkages
To enhance the data from this survey and to reduce the reporting burden, Statistics Canada may combine the acquired data with information from other surveys or from administrative sources.
Data-sharing agreements
To reduce respondent burden, Statistics Canada has entered into data-sharing agreements with provincial and territorial statistical agencies and other government organizations, which have agreed to keep the data confidential and use them only for statistical purposes. Statistics Canada will only share data from this survey with those organizations that have demonstrated a requirement to use the data.
Provincial and territorial statistical agencies
Section 11 of the Statistics Act provides for the sharing of information with provincial and territorial statistical agencies that meet certain conditions. These agencies must have the legislative authority to collect the same information, on a mandatory basis, and the legislation must provide substantially the same provisions for confidentiality and penalties for disclosure of confidential information as the Statistics Act. Because these agencies have the legal authority to compel businesses to provide the same information, consent is not requested and businesses may not object to the sharing of the data.
For this survey, there are Section 11 agreements with the provincial and territorial statistical agencies of Newfoundland and Labrador, Nova Scotia, New Brunswick, Quebec, Ontario, Manitoba, Saskatchewan, Alberta, British Columbia and the Yukon. The shared data will be limited to information on in-house research and development expenditures (Question 14) and in-house research and development personnel (Question 72) pertaining to business establishments located within the jurisdiction of the respective province or territory.
Section 12 of the Statistics Act provides for the sharing of information with federal, provincial or territorial government organizations. Under Section 12, you may refuse to share your information with any of these organizations by writing a letter of objection to the Chief Statistician, specifying the organizations with which you do not want Statistics Canada to share your data and mailing it to the following address:
Chief Statistician of Canada
Statistics Canada
Attention of Director, Enterprise Statistics Division
150 Tunney's Pasture Driveway
Ottawa, Ontario
K1A 0T6
You may also contact us by email at statcan.esdhelpdesk-dsebureaudedepannage.statcan@statcan.gc.ca or by fax at 613-951-6583.
Other data-sharing agreement
For this survey, there are Section 12 agreements with the statistical agencies of Prince Edward Island, the Northwest Territories and Nunavut. The shared data will be limited to information on in-house research and development expenditures (Question 14) and in-house research and development personnel (Question 72) pertaining to business establishments located within the jurisdiction of the respective province or territory.
Innovation, Science and Economic Development Canada
For this survey, Statistics Canada will share survey data with Innovation, Science and Economic Development Canada. The shared data will be limited to information on research and development expenditures (Questions 4 to 21) and in-house research and development personnel (Questions 70 to 72).
Natural Resources Canada
For respondents with expenditures on energy-related research and development in technology (fossil fuels, renewable energy resources, nuclear fission and fusion, electric power, hydrogen and fuel cells, energy efficiency, other energy-related technologies), Statistics Canada will also share survey data with the Office of Energy Research and Development (OERD) of Natural Resources Canada. The shared data will be limited to information on Energy Research and Development Expenditures by Area of Technology (Questions 22 to 69).
Business or organization and contact information
1. Verify or provide the business or organization's legal and operating name and correct where needed.
Note: Legal name modifications should only be done to correct a spelling error or typo.
Legal Name
The legal name is one recognized by law, thus it is the name liable for pursuit or for debts incurred by the business or organization. In the case of a corporation, it is the legal name as fixed by its charter or the statute by which the corporation was created.
Modifications to the legal name should only be done to correct a spelling error or typo
To indicate a legal name of another legal entity you should instead indicate it in question 3 by selecting 'Not currently operational' and then choosing the applicable reason and providing the legal name of this other entity along with any other requested information.
Operating Name
The operating name is a name the business or organization is commonly known as if different from its legal name. The operating name is synonymous with trade name.
- Legal name
- Operating name (if applicable)
2. Verify or provide the contact information of the designated business or organization contact person for this questionnaire and correct where needed.
Note: The designated contact person is the person who should receive this questionnaire. The designated contact person may not always be the one who actually completes the questionnaire.
- First name
- Last name
- Title
- Preferred language of communication
- Mailing address (number and street)
- City
- Province, territory or state
- Postal code or ZIP code
- Country
- Email address
- Telephone number (including area code)
- Extension number (if applicable)
The maximum number of characters is 10.
- Fax number (including area code)
3. Verify or provide the current operational status of the business or organization identified by the legal and operating name above.
- Operational
- Not currently operational
Why is this business or organization not currently operational?
- Seasonal operations
- When did this business or organization close for the season?
- When does this business or organization expect to resume operations?
- Ceased operations
- When did this business or organization cease operations?
- Why did this business or organization cease operations?
- Bankruptcy
- Liquidation
- Dissolution
- Other - Specify the other reasons for ceased operations
- Sold operations
- When was this business or organization sold?
- What is the legal name of the buyer?
- Amalgamated with other businesses or organizations
- When did this business or organization amalgamate?
- What is the legal name of the resulting or continuing business or organization?
- What are the legal names of the other amalgamated businesses or organizations?
- Temporarily inactive but will re-open
- When did this business or organization become temporarily inactive?
- When does this business or organization expect to resume operations?
- Why is this business or organization temporarily inactive?
- No longer operating due to other reasons
- When did this business or organization cease operations?
- Why did this business or organization cease operations?
4. Verify or provide the current main activity of the business or organization identified by the legal and operating name above.
Note: The described activity was assigned using the North American Industry Classification System (NAICS).
This question verifies the business or organization's current main activity as classified by the North American Industry Classification System (NAICS). The North American Industry Classification System (NAICS) is an industry classification system developed by the statistical agencies of Canada, Mexico and the United States. Created against the background of the North American Free Trade Agreement, it is designed to provide common definitions of the industrial structure of the three countries and a common statistical framework to facilitate the analysis of the three economies. NAICS is based on supply-side or production-oriented principles, to ensure that industrial data, classified to NAICS, are suitable for the analysis of production-related issues such as industrial performance.
The target entity for which NAICS is designed are businesses and other organizations engaged in the production of goods and services. They include farms, incorporated and unincorporated businesses and government business enterprises. They also include government institutions and agencies engaged in the production of marketed and non-marketed services, as well as organizations such as professional associations and unions and charitable or non-profit organizations and the employees of households.
The associated NAICS should reflect those activities conducted by the business or organizational units targeted by this questionnaire only, as identified in the 'Answering this questionnaire' section and which can be identified by the specified legal and operating name. The main activity is the activity which most defines the targeted business or organization's main purpose or reason for existence. For a business or organization that is for-profit, it is normally the activity that generates the majority of the revenue for the entity.
The NAICS classification contains a limited number of activity classifications; the associated classification might be applicable for this business or organization even if it is not exactly how you would describe this business or organization's main activity.
Please note that any modifications to the main activity through your response to this question might not necessarily be reflected prior to the transmitting of subsequent questionnaires and as a result they may not contain this updated information.
The following is the detailed description including any applicable examples or exclusions for the classification currently associated with this business or organization.
Description and examples
- This is the current main activity
- Provide a brief but precise description of this business or organization's main activity
- e.g., breakfast cereal manufacturing, shoe store, software development
- This is not the current main activity
Main activity
5. You indicated that is not the current main activity.
Was this business or organization's main activity ever classified as:?
- Yes
- When did the main activity change?
Date
- No
6. Search and select the industry classification code that best corresponds to this business or organization's main activity.
How to search:
- if desired, you can filter the search results by first selecting this business or organization's activity sector
- enter keywords or a brief description that best describes this business or organization main activity
- press the Search button to search the database for an activity that best matches the keywords or description you provided
- then select an activity from the list.
Select this business or organization's activity sector (optional)
- Farming or logging operation
- Construction company or general contractor
- Manufacturer
- Wholesaler
- Retailer
- Provider of passenger or freight transportation
- Provider of investment, savings or insurance products
- Real estate agency, real estate brokerage or leasing company
- Provider of professional, scientific or technical services
- Provider of health care or social services
- Restaurant, bar, hotel, motel or other lodging establishment
- Other sector
Enter keywords or a brief description, then press the Search button
Additional reporting instructions
1. Throughout this questionnaire, please report financial information in thousands of Canadian dollars.
For example, an amount of $763,880.25 should be reported as: 764, CAN$ '000
I will report in the format above
Reporting period
1. What is the end date of this organization's fiscal year?
Note: For this survey, this organization's fiscal year end date should fall on or before March 31, 2025.
Here are some examples of fiscal periods that fall within the targeted dates:
- May 1, 2023 to April 30, 2024
- July 1, 2023 to June 30, 2024
- October 1, 2023 to September 30, 2024
- January 1, 2024 to December 31, 2024
- February 1, 2024 to January 31, 2025
- April 1, 2024 to March 31, 2025
Fiscal Year-End date
This fiscal year will be referred to as 2024 throughout the questionnaire
Organization status
2. What is this organization's GST number (9-digit business number)?
GST number (9-digit business number)
In-house research and development ( R&D ) expenditures
Before you begin please be aware of the definitions for this survey
'In-house R&D ' refers to
Expenditures within Canada for R&D performed within this organization by:
- employees (permanent, temporary or casual)
- self-employed individuals or contractors who are working on-site on this organization's R&D projects.
'Outsourced R&D ' refers to
Payments made within or outside Canada to other organizations, businesses or individuals to fund R&D performance:
- grants
- fellowships
- contracts.
In-house research and development ( R&D ) expenditures
3. In 2024, did this organization have expenditures for R&D performed in-house within Canada?
Exclude payments for outsourced (contracted out or granted) R&D, which should be reported in question 9.
In-house refers to R&D which is performed on-site or within the organization's establishment. Exclude R&D expenses performed by other companies or organizations. A later question will collect these data.
Research and experimental development ( R&D ) comprise creative and systematic work undertaken in order to increase the stock of knowledge - including knowledge of humankind, culture and society - and to devise new applications of available knowledge.
R&D is performed in the natural sciences, engineering, social sciences and humanities. There are three types of R&D activities: basic research, applied research and experimental development.
Research work in the social sciences
Include if projects are employing new or significantly different modelling techniques or developing new formulae, analyzing data not previously available or applying new research techniques, development of community strategies for disease prevention, or health education.
Exclude:
- routine analytical projects using standard techniques and existing data
- routine market research
- routine statistical analysis intended for on-going monitoring of an activity.
4. In 2024, what were this organization's expenditures for R&D performed in-house within Canada?
Exclude payments for outsourced (contracted out or granted) R&D, which should be reported in question 9.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
In-house R&D expenditures are composed of current in-house R&D expenditures and capital in-house R&D expenditures.
Current in-house R&D expenditures
Include:
- wages, salaries, benefits and fringe benefits, materials and supplies
- services to support R&D, including on-site R&D consultants and contractors
- necessary background literature
- minor scientific equipment
- associated administrative overhead costs.
a. Wages, salaries of permanent, temporary and casual R&D employees
Include benefits and fringe benefits of employees engaged in R&D activities. Benefits and fringe benefits include bonus payments, holiday or vacation pay, pension fund contributions, other social security payments, payroll taxes, etc.
b. Services to support R&D
Include:
- payments to on-site R&D consultants and contractors working under the direct control of your business
- other services including indirect services purchased to support in-house R&D such as security, storage, repair, maintenance and use of buildings and equipment
- computer services, software licensing fees and dissemination of R&D findings.
c. R&D materials
Include:
- water, fuel, gas and electricity
- materials for creation of prototypes
- reference materials (books, journals, etc.)
- subscriptions to libraries and data bases, memberships to scientific societies, etc.
- cost of outsourced (contracted out or granted) small R&D prototypes or R&D models
- materials for laboratories (chemicals, animal, etc.)
- all other R&D -related materials.
d. All other current R&D costs including overhead
Include administrative and overhead costs (e.g., office, lease/rent, post and telecommunications, internet, legal expenditures, insurance), prorated if necessary to allow for non- R&D activities within the business.
Exclude:
- interest charges
- value-added taxes (goods and services tax (GST) or harmonized sales tax (HST)).
Capital in-house expenditures are the annual gross amount paid for the acquisition of fixed assets that are used repeatedly, or continuously in the performance of R&D for more than one year. Report capital in-house expenditures in full for the period when they occurred.
Include costs for software, land, buildings and structures, equipment, machinery and other capital costs.
Exclude capital depreciation.
e. Software
Include applications and systems software (original, customized and off-the-shelf software), supporting documentation and other software-related acquisitions.
f. Land acquired for R&D including testing grounds, sites for laboratories and pilot plants.
g. Buildings and structures that are constructed or purchased for R&D activities or that have undergone major improvements, modifications, renovations and repairs for R&D activities.
h. Equipment, machinery and all other capital
Include major equipment, machinery and instruments, including embedded software, acquired for R&D activities.
In 2024, what were this organization's expenditures for R&D performed in-house within Canada?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| 2024 - Current in-house R&D expenditures within Canada |
|---|
a. Wages, salaries of permanent, temporary and casual R&D employees
Include fringe benefits. |
|
|---|
b. Services to support R&D
Include services of self-employed individuals or contractors who are working on-site on this business's R&D projects.
Exclude contracted out or granted expenditures to other organizations to perform R&D (report in question 9). |
|
|---|
| c. R&D materials |
|
|---|
d. All other current R&D costs
Include overhead costs. |
|
|---|
| 2024 - Total current in-house R&D expenditures within Canada |
|
|---|
| 2024 - Capital in-house R&D expenditures within Canada |
|---|
e. Software
Exclude capital depreciation. |
|
|---|
f. Land
Exclude capital depreciation. |
|
|---|
g. Buildings and structures
Exclude capital depreciation. |
|
|---|
h. Equipment, machinery and all other capital
Exclude capital depreciation. |
|
|---|
| 2024 - Total capital in-house R&D expenditures within Canada |
|
|---|
| 2024 - Total in-house R&D expenditures within Canada |
|
|---|
5. In 2025 and 2026, does this organization plan to have expenditures for R&D performed in-house within Canada?
Exclude payments for outsourced (contracted out or granted) R&D, which should be reported in question 11.
Select all that apply.
In-house R&D expenditures are composed of current in-house R&D expenditures and capital in-house R&D expenditures.
Research and experimental development ( R&D ) comprise creative and systematic work undertaken in order to increase the stock of knowledge - including knowledge of humankind, culture and society - and to devise new applications of available knowledge
Inclusions
Prototypes
Include design, construction and operation of prototypes, provided that the primary objective is to make further improvements or to undertake technical testing.
Exclude if the prototype is for commercial purposes.
Clinical Trials
Include clinical trial phases 1, 2, and 3. Include clinical trial phase 4 only if it brings about a further scientific or technological advance.
Pilot plants
Include construction and operation of pilot plants, provided that the primary objective is to make further improvements or to undertake technical testing.
Exclude if the pilot plant is intended to be operated for commercial purposes.
New computer software or significant improvements/modifications to existing computer software
Includes technological or scientific advances in theoretical computer sciences; operating systems e.g., improvement in interface management, developing new operating system of converting an existing operating system to a significantly different hardware environment; programming languages; and applications if a significant technological change occurs.
Contracts
Include all contracts which require R&D. For contracts which include other work, report only the R&D costs.
Research work in the social sciences
Include if projects are employing new or significantly different modelling techniques or developing new formulae, analyzing data not previously available or applying new research techniques, development of community strategies for disease prevention, analysis of the effectiveness of health interventions, or health education.
Exclusions
Routine analysis in the social sciences including policy-related studies, management studies and efficiency studies
Exclude analytical projects of a routine nature, with established methodologies, principles and models of the related social sciences to bear on a particular problem (e.g., commentary on the probable economic effects of a change in the tax structure, using existing economic data; use of standard techniques in applied psychology to select and classify industrial and military personnel, students, etc., and to test children with reading or other disabilities).
Consumer surveys, advertising, market research
Exclude projects of a routine nature, with established methodologies intended for commercialization of the results of R&D.
Routine quality control and testing
Exclude projects of a routine nature, with established methodologies not intended to create new knowledge, even if carried out by personnel normally engaged in R&D.
Pre-production activities such as demonstration of commercial viability, tooling up, trial production, trouble shooting
Although R&D may be required as a result of these steps, these activities are excluded.
Prospecting, exploratory drilling, development of mines, oil or gas wells
Include only if for R&D projects concerned with new equipment or techniques in these activities, such as in-situ and tertiary recovery research.
Engineering
Exclude engineering unless it is in direct support of R&D.
Design and drawing
Exclude design and drawing unless it is in direct support of R&D.
Patent and licence work
Exclude all administrative and legal work connected with patents and licences.
Cosmetic modifications or style changes to existing products
Exclude if no significant technical improvement or modification to the existing products has occurred.
General purpose or routine data collection
Exclude projects of a routine nature, with established methodologies intended for on-going monitoring of an activity.
Routine computer programming, systems maintenance or software application
Exclude projects of a routine nature, with established methodologies intended to support on-going operations.
Routine mathematical or statistical analysis or operations analysis
Exclude projects of a routine nature, with established methodologies intended for on-going monitoring of an activity.
Activities associated with standards compliance
Exclude projects of a routine nature, with established methodologies intended to support standards compliance.
Specialized routine medical care such as routine pathology services
Exclude projects of a routine nature, with established methodologies intended for on-going monitoring of an activity where results do not further scientific, technological advance, or understanding of the effectiveness of a technology.
- In 2025
- In 2026
- No planned in-house R&D expenditures
6. In 2025, what are this organization's planned expenditures for R&D performed in-house within Canada?
Exclude payments for outsourced (contracted out or granted) R&D, which should be reported in question 11.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
In 2025, what are this organization's planned expenditures for R&D performed in-house within Canada?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. 2025 - Total current in-house R&D expenditures within Canada |
|
|---|
| b. 2025 - Total capital in-house R&D expenditures within Canada |
|
|---|
7. In 2026, what are this organization's planned expenditures for R&D performed in-house within Canada?
Exclude payments for outsourced (contracted out or granted) R&D, which should be reported in question 11.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
In 2026, what are this organization's planned expenditures for R&D performed in-house within Canada?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. 2026 - Total current in-house R&D expenditures within Canada |
|
|---|
| b. 2026 - Total capital in-house R&D expenditures within Canada |
|
|---|
Outsourced (contracted out or granted) R&D expenditures
8. In 2024, did this organization have outsourced (contracted out or granted) R&D expenditures within Canada or outside Canada?
Include:
- funding or grants provided to other organizations to perform R&D
- contracted out expenditures for R&D.
Exclude services of self-employed individuals or contractors who are working on-site on this organization's R&D projects, which should be reported in question 4.
Select all that apply.
Outsourced (contracted out or granted) R&D expenditures are payments made through contracts, grants and fellowships to another company, organization or individual to purchase R&D activities.
- Within Canada
- Outside Canada
- No payment made to others to perform R&D
9. In 2024, what were this organization's outsourced (contracted out or granted) R&D expenditures within Canada or outside Canada?
Include:
- funding or grants provided to other organizations to perform R&D
- contracted out expenditures for R&D.
Exclude services of self-employed individuals or contractors who are working on-site on this organization's R&D projects, which should be reported in question 4.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Include payments made through contracts, grants, donations and fellowships to another company, organization or individual to purchase or fund R&D activities.
Exclude expenditures for on-site R&D contractors.
Parent and subsidiary companies are companies connected to each other through majority ownership of the subsidiary company by the parent company. Affiliated companies are companies connected to a parent through minority ownership of the affiliated companies by the parent.
Companies include all incorporated for-profit businesses and government business enterprises providing products in the market at market rates.
Private non-profit organizations include voluntary health organizations, private philanthropic foundations, associations, consortia, accelerators, and societies and research institutes. They are not-for-profit organizations that serve the public interest by supporting activities related to public welfare (such as health, education, the environment).
Industrial research institutes or associations include all non-profit organizations that serve the business sector, with industrial associations frequently consisting of their membership.
Universities include hospitals and clinics when they are affiliated with a university and provide education services or when R&D activity is under the direct control of a university.
Federal government includes all federal government departments and agencies. It excludes federal government business enterprises providing products in the market.
Provincial or territorial governments include all provincial or territorial government ministries, departments and agencies. It excludes provincial or territorial government business enterprises providing products in the market.
Provincial or territorial research organizations are organizations created under provincial or territorial law which conduct or facilitate research on behalf of the province or territory.
Other organizations - individuals, non-university educational institutions, for profit accelerators and incubators, foreign governments including ministries, departments and agencies of foreign governments.
In 2024, what were this organization's outsourced (contracted out or granted) R&D expenditures within Canada or outside Canada?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Within Canada
CAN$ '000 |
Outside Canada
CAN$ '000 |
|---|
| a. Companies |
|
|
|---|
| b. Private non-profit organizations |
|
|
|---|
| c. Industrial research institutes or associations |
|
|
|---|
| d. Hospitals |
|
|
|---|
| e. Universities |
|
|
|---|
| f. Federal government departments and agencies |
|
|
|---|
| g. Provincial or territorial government departments, ministries and agencies |
|
|
|---|
| h. Provincial or territorial research organizations |
|
|
|---|
i. Other organizations
e.g., individuals, non-university educational institutions, foreign governments |
|
|
|---|
| 2024 - Total outsourced (contracted out or granted) R&D expenditures |
|
|
|---|
10. In 2025 and 2026, does this organization plan to outsource (contract out or grant) R&D expenditures within Canada or outside Canada?
Include:
- funding or grants provided to other organizations to perform R&D
- contracted out expenditures for R&D.
Exclude services of self-employed individuals or contractors who are working on-site on this organization's R&D projects, which should be reported in questions 6 and 7.
Select all that apply.
Outsourced (contracted out or granted) R&D expenditures are payments made through contracts, grants and fellowships to another company, organization or individual to purchase R&D activities.
- In 2025
- In 2026
- No planned payments to others to perform R&D
11. In 2025 and 2026, what are this organization's planned outsourced (contracted out or granted) R&D expenditures within Canada or outside Canada?
Include:
- funding or grants provided to other organizations to perform R&D
- contracted out expenditures for R&D.
Exclude services of self-employed individuals or contractors who are working on-site on this organization's R&D projects, which should be reported in questions 6 and 7.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Include payments made through contracts, licenses, grants, donations, endowments and fellowships to another company, university, hospital, consortia, organization or individual to purchase or fund R&D activities.
Exclude expenditures for on-site R&D contractors.
In 2025 and 2026, what are this organization's planned outsourced (contracted out or granted) R&D expenditures within Canada or outside Canada?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Within Canada
CAN$ '000 |
Outside Canada
CAN$ '000 |
|---|
| a. 2025 |
|
|
|---|
| b. 2026 |
|
|
|---|
In-house and Outsourced (contracted out or granted) R&D expenditures from 2024 to 2026
12. In-house and Outsourced (contracted out or granted) R&D expenditures from 2024 to 2026
12. Summary of total R&D expenditures from 2024 to 2026
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
2024
CAN$ '000 |
2025
CAN$ '000 |
2026
CAN$ '000 |
|---|
| Total current in-house R&D expenditures within Canada |
|
|
|
|---|
| Total capital in-house R&D expenditures within Canada |
|
|
|
|---|
| Total in-house R&D expenditures within Canada |
|
|
|
|---|
| Total outsourced (contracted out or granted) R&D expenditures |
|
|
|
|---|
| Total R&D expenditures |
|
|
|
|---|
Geographic distribution of in-house R&D expenditures within Canada in 2024
13. In 2024, in which provinces or territories did this organization have expenditures for R&D performed in-house?
Exclude:
- payments for outsourced (contracted out or granted) R&D, which should be reported in question 9
- capital depreciation.
Select all that apply.
- Newfoundland and Labrador
- Prince Edward Island
- Nova Scotia
- New Brunswick
- Quebec
- Ontario
- Manitoba
- Saskatchewan
- Alberta
- British Columbia
- Yukon
- Northwest Territories
- Nunavut
14. In 2024, how were this organization's total expenditures for R&D performed in-house distributed by province or territory?
Exclude:
- payments for outsourced (contracted out or granted) R&D, which should be reported in question 9
- capital depreciation.
Please report all amounts in thousands of Canadian dollars.
For in-house R&D activities on federal lands, please include in the closest province or territory.
In 2024, how were this organization's total expenditures for R&D performed in-house distributed by province or territory?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Current in-house R&D expenditures
CAN$ '000 |
Capital in-house R&D expenditures
CAN$ '000 |
|---|
| a. Newfoundland and Labrador |
|
|
|---|
| b. Prince Edward Island |
|
|
|---|
| c. Nova Scotia |
|
|
|---|
| d. New Brunswick |
|
|
|---|
| e. Quebec |
|
|
|---|
| f. Ontario |
|
|
|---|
| g. Manitoba |
|
|
|---|
| h. Saskatchewan |
|
|
|---|
| i. Alberta |
|
|
|---|
| j. British Columbia |
|
|
|---|
| k. Yukon |
|
|
|---|
| l. Northwest Territories |
|
|
|---|
| m. Nunavut |
|
|
|---|
| 2024 - Total current and capital in-house R&D expenditures |
|
|
|---|
| 2024 - Total current and capital in-house R&D expenditures previously reported from question 4 |
|
|
|---|
Sources of funds for in-house R&D expenditures in 2024
15. In 2024, what were the sources of funds for this organization's total expenditures for R&D performed in-house?
Include Canadian and foreign sources.
Exclude:
- payments for outsourced (contracted out or granted) R&D, which should be reported in question 9.
- capital depreciation.
Select all that apply.
Funds from this organization
Amount contributed by this organization to R&D performed within Canada (include amounts eligible for income tax purposes, e.g., Scientific Research and Experimental Development ( SR-ED ) program, other amounts spent for projects not claimed through SR-ED, and funds for land, buildings, machinery and equipment (capital expenditures) purchased for R&D ).
Funds from parent, affiliated and subsidiary companies
Amount received from parent, affiliated and subsidiary companies used to perform R&D within Canada (include amounts eligible for income tax purposes, e.g., Scientific Research and Experimental Development ( SR-ED ) program, other amounts spent for projects not claimed through SR-ED, and funds for land, buildings, machinery and equipment (capital expenditures) purchased for R&D ).
R&D contract work for companies
Funds received from companies to perform R&D on their behalf.
Federal government grants or funding
Grants or funds received from the federal government in support of R&D activities not connected to a specific contractual deliverable.
Federal government contracts
Funds received from the federal government in support of R&D activities connected to a specific contractual deliverable.
Provincial or territorial government grants or funding
Grants or funds received from the provincial or territorial government in support of R&D activities not connected to a specific contractual deliverable.
Provincial or territorial government contracts
Funds received from the provincial or territorial government in support of R&D activities connected to a specific contractual deliverable.
R&D contract work for private non-profit organizations
Funds received from non-profit organizations to perform R&D on their behalf.
Other sources
Funds received from all other sources not previously classified.
- Funds from this organization
Include interest payments, other income and funding or tax credits from tax incentives.
- Funds from member companies or affiliates (Include annual fees and sustaining grants)
- Federal government grants or funding
Include R&D grants or funding or R&D portion only of other grants or funding. Do not include funds or tax credits from SR&ED tax incentives.
- Federal government contracts
Include R&D contracts or R&D portion only of other contracts.
- R&D contract work for companies
- Provincial or territorial government grants or funding
Include R&D grants or funding or R&D portion only of other grants or funding.
- From which province or territory did this organization receive provincial or territorial government R&D grants or funding?
Select all that apply.
- Newfoundland and Labrador
- Prince Edward Island
- Nova Scotia
- New Brunswick
- Quebec
- Ontario
- Manitoba
- Saskatchewan
- Alberta
- British Columbia
- Yukon
- Northwest Territories
- Nunavut
- Provincial or territorial government contracts
Include R&D contracts or R&D portion only of other contracts.
- From which province or territory did this organization receive provincial or territorial government R&D contracts?
Select all that apply.
- Newfoundland and Labrador
- Prince Edward Island
- Nova Scotia
- New Brunswick
- Quebec
- Ontario
- Manitoba
- Saskatchewan
- Alberta
- British Columbia
- Yukon
- Northwest Territories
- Nunavut
- R&D contract work for companies
- Other sources
e.g., universities, foreign governments, individuals
16. In 2024, what were the sources of funds for this organization's total expenditures of $ [Amount] for R&D performed in-house?
Exclude:
- payments for outsourced (contracted out or granted) R&D, which should be reported in question 9
- capital depreciation.
Please report all amounts in thousands of Canadian dollars
Report '0' for no R&D expenditures.
Funds from this organization
Amount contributed by this organization to R&D performed within Canada (include amounts eligible for income tax purposes, e.g., Scientific Research and Experimental Development ( SR-ED ) program, other amounts spent for projects not claimed through SR-ED, and funds for land, buildings, machinery and equipment (capital expenditures) purchased for R&D ).
Funds from member companies or affiliates
Amount received from parent, affiliated and subsidiary companies used to perform R&D within Canada (include amounts eligible for income tax purposes, e.g., Scientific Research and Experimental Development ( SR-ED ) program, other amounts spent for projects not claimed through SR-ED, and funds for land, buildings, machinery and equipment (capital expenditures) purchased for R&D ).
R&D contract work for companies
Funds received from companies to perform R&D on their behalf.
Federal government grants or funding
Grants or funds received from the federal government in support of R&D activities not connected to a specific contractual deliverable.
Federal government contracts
Funds received from the federal government in support of R&D activities connected to a specific contractual deliverable.
Provincial or territorial government grants or funding
Grants or funds received from the provincial or territorial government in support of R&D activities not connected to a specific contractual deliverable.
Provincial or territorial government contracts
Funds received from the provincial or territorial government in support of R&D activities connected to a specific contractual deliverable.
R&D contract work for private non-profit organizations
Funds received from non-profit organizations to perform R&D on their behalf.
Other sources
Funds received from all other sources not previously classified.
In 2024, what were the sources of funds for this organization's total expenditures of $ [Amount] for R&D performed in-house?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
From within Canada
CAN$ '000 |
From outside Canada
CAN$ '000 |
|---|
a. Funds from this organization
Include interest payments, other income and funding or tax credits from tax incentives. |
|
|
|---|
| b. Funds from member companies or affiliates |
|
|
|---|
c. Federal government grants or funding
Include R&D grants or funding or R&D portion only of other grants or funding. |
|
|
|---|
| d. Federal government contracts |
|
|
|---|
| R&D contract work for companies |
|---|
e. Business 1
GST number (9-digit business number (BN) or charitable registration number)
Legal name |
|
|
|---|
f. Business 2
GST number (9-digit business number (BN) or charitable registration number)
Legal name |
|
|
|---|
g. Business 3
GST number (9-digit business number (BN) or charitable registration number)
Legal name |
|
|
|---|
h. Business 4
GST number (9-digit business number (BN) or charitable registration number)
Legal name |
|
|
|---|
| i. Other contracts not listed above |
|
|
|---|
Provincial or territorial government grants or funding
Include R&D grants or funding or R&D portion only of other grants or funding. |
|---|
| j. Newfoundland and Labrador |
|
|
|---|
| k. Prince Edward Island |
|
|
|---|
| l. Nova Scotia |
|
|
|---|
| m. New Brunswick |
|
|
|---|
| n. Quebec |
|
|
|---|
| o. Ontario |
|
|
|---|
| p. Manitoba |
|
|
|---|
| q. Saskatchewan |
|
|
|---|
| r. Alberta |
|
|
|---|
| s. British Columbia |
|
|
|---|
| t. Yukon |
|
|
|---|
| u. Northwest Territories |
|
|
|---|
| v. Nunavut |
|
|
|---|
Provincial or territorial government contracts
Include R&D contracts or R&D portion only of other contracts. |
|---|
| w. Newfoundland and Labrador |
|
|
|---|
| x. Prince Edward Island |
|
|
|---|
| y. Nova Scotia |
|
|
|---|
| z. New Brunswick |
|
|
|---|
| aa. Quebec |
|
|
|---|
| ab. Ontario |
|
|
|---|
| ac. Manitoba |
|
|
|---|
| ad. Saskatchewan |
|
|
|---|
| ae. Alberta |
|
|
|---|
| af. British Columbia |
|
|
|---|
| ag. Yukon |
|
|
|---|
| ah. Northwest Territories |
|
|
|---|
| ai. Nunavut |
|
|
|---|
| R&D contract work for private non-profit organizations |
|---|
aj. Organization 1
GST number (9-digit business number (BN) or charitable registration number)
Legal name |
|
|
|---|
ak. Organization 2
GST number (9-digit business number (BN) or charitable registration number)
Legal name |
|
|
|---|
al. Organization 3
GST number (9-digit business number (BN) or charitable registration number)
Legal name |
|
|
|---|
am. Other sources
e.g., universities, foreign governments, individuals |
|
|
|---|
| 2024 - Total in-house R&D expenditures by sources of funds by origin |
|
|
|---|
| 2024 - Total in-house R&D expenditures (Canadian and foreign sources) |
|
|
|---|
| Total in-house R&D expenditures previously reported from question 4 |
|
|
|---|
Fields of R&D for in-house R&D expenditures within Canada in 2024
17. In 2024, in which field(s) of research and development did this organization have R&D performed in-house within Canada?
Exclude:
- payments for outsourced (contracted out or granted) R&D, which should be reported in question 9
- capital depreciation.
Select all that apply.
Natural and formal sciences: physical sciences, chemical sciences, earth and related environmental sciences, biological sciences, other natural sciences.
Engineering and technology: civil engineering, electrical engineering, electronic engineering and communications technology, mechanical engineering, chemical engineering, materials engineering, medical engineering, environmental engineering, environmental biotechnology, industrial biotechnology, nanotechnology, other engineering and technologies.
Software-related sciences and technology: software engineering and technology, computer sciences, information technology and bioinformatics.
Medical and health sciences: basic medicine, clinical medicine, health sciences, medical biotechnology, other medical sciences.
Agricultural sciences: agriculture, forestry and fisheries sciences, animal and dairy sciences, veterinary sciences, agricultural biotechnology, other agricultural sciences.
Social sciences and humanities:
psychology, educational sciences, economics and business, other social sciences, humanities.
- Natural and formal sciences
Exclude computer sciences, information sciences and bioinformatics.
- Engineering and technology
Exclude software engineering and technology.
- Software-related sciences and technology
- Medical and health sciences
- Agricultural sciences
- Social sciences and humanities
18. In 2024, how were this organization's total expenditures of $ [Amount] for R&D performed in-house within Canada distributed by field(s) of research and development?
Exclude:
- payments for outsourced (contracted out or granted) R&D, which should be reported in question 9
- capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Natural and formal sciences
Mathematics: pure mathematics, applied mathematics, statistics and probability.
Physical sciences: atomic, molecular and chemical physics, interaction with radiation, magnetic resonances, condensed matter physics, solid state physics and superconductivity, particles and fields physics, nuclear physics, fluids and plasma physics (including surface physics), optics (including laser optics and quantum optics), acoustics, astronomy (including astrophysics, space science).
Chemical sciences: organic chemistry, inorganic and nuclear chemistry, physical chemistry, polymer science and plastics, electrochemistry (dry cells, batteries, fuel cells, metal corrosion, electrolysis), colloid chemistry, analytical chemistry.
Earth and related environmental sciences: geosciences, geophysics, mineralogy and palaeontology, geochemistry and geophysics, physical geography, geology and volcanology, environmental sciences, meteorology, atmospheric sciences and climatic research, oceanography, hydrology and water resources.
Biological sciences: cell biology, microbiology and virology, biochemistry, molecular biology and biochemical research, mycology, biophysics, genetics and heredity (medical genetics under medical biotechnology), reproductive biology (medical aspects under medical biotechnology), developmental biology, plant sciences and botany, zoology, ornithology, entomology and behavioural sciences biology, marine biology, freshwater biology and limnology, ecology and biodiversity conservation, biology (theoretical, thermal, cryobiology, biological rhythm), evolutionary biology.
Other natural sciences: other natural sciences.
Engineering and technology
Civil engineering: civil engineering, architecture engineering, municipal and structural engineering, transport engineering.
Electrical engineering, electronic engineering and communications technology: electrical and electronic engineering, robotics and automatic control, micro-electronics, semiconductors, automation and control systems, communication engineering and systems, telecommunications, computer hardware and architecture.
Mechanical engineering: mechanical engineering, applied mechanics, thermodynamics, aerospace engineering, nuclear-related engineering (nuclear physics under Physical sciences), acoustical engineering, reliability analysis and non-destructive testing, automotive and transportation engineering and manufacturing, tooling, machinery and equipment engineering and manufacturing, heating, ventilation and air conditioning engineering and manufacturing.
Chemical engineering: chemical engineering (plants, products), chemical process engineering.
Materials engineering: materials engineering and metallurgy, ceramics, coating and films (including packaging and printing), plastics, rubber and composites (including laminates and reinforced plastics), paper and wood and textiles, construction materials (organic and inorganic).
Medical engineering: medical and biomedical engineering, medical laboratory technology (excluding biomaterials which should be reported under Industrial biotechnology).
Environmental engineering: environmental and geological engineering, petroleum engineering (fuel, oils), energy and fuels, remote sensing, mining and mineral processing, marine engineering, sea vessels and ocean engineering.
Environmental biotechnology: environmental biotechnology, bioremediation, diagnostic biotechnologies in environmental management (DNA chips and bio-sensing devices).
Industrial biotechnology: industrial biotechnology, bioprocessing technologies, biocatalysis and fermentation bioproducts (products that are manufactured using biological material as feedstock), biomaterials (bioplastics, biofuels, bio-derived bulk and fine chemicals, bio-derived materials).
Nanotechnology: nano-materials (production and properties), nano-processes (applications on nano-scale).
Other engineering and technologies: food and beverages, oenology, other engineering and technologies.
Software-related sciences and technologies
Software engineering and technology: computer software engineering, computer software technology, and other related computer software engineering and technologies.
Computer sciences: computer science, artificial intelligence, cryptography, and other related computer sciences.
Information technology and bioinformatics: information technology, informatics, bioinformatics, biomathematics, and other related information technologies.
Medical and health sciences
Basic medicine: anatomy and morphology (plant science under Biological science), human genetics, immunology, neurosciences, pharmacology and pharmacy and medicinal chemistry, toxicology, physiology and cytology, pathology.
Clinical medicine: andrology, obstetrics and gynaecology, paediatrics, cardiac and cardiovascular systems, haematology, anaesthesiology, orthopaedics, radiology and nuclear medicine, dentistry, oral surgery and medicine, dermatology, venereal diseases and allergy, rheumatology, endocrinology and metabolism and gastroenterology, urology and nephrology, and oncology.
Health sciences: health care sciences and nursing, nutrition and dietetics, parasitology, infectious diseases and epidemiology, occupational health.
Medical biotechnology: health-related biotechnology, technologies involving the manipulation of cells, tissues, organs or the whole organism, technologies involving identifying the functioning of DNA, proteins and enzymes, pharmacogenomics, gene-based therapeutics, biomaterials (related to medical implants, devices, sensors).
Other medical sciences: forensic science, other medical sciences.
Other medical sciences: forensic science, other medical sciences.
Agricultural sciences
Agriculture, forestry and fisheries sciences: agriculture, forestry, fisheries and aquaculture, soil science, horticulture, viticulture, agronomy, plant breeding and plant protection.
Animal and dairy sciences: animal and dairy science, animal husbandry.
Veterinary sciences: veterinary science (all).
Agricultural biotechnology: agricultural biotechnology and food biotechnology, genetically modified (GM) organism technology and livestock cloning, diagnostics (DNA chips and biosensing devices), biomass feedstock production technologies and biopharming.
Other agricultural sciences: other agricultural sciences.
Social sciences and humanities
Psychology: cognitive psychology and psycholinguistics, experimental psychology, psychometrics and quantitative psychology, and other fields of psychology.
Educational sciences: education, training and other related educational sciences.
Economics and business: micro-economics, macro-economics, econometrics, labour economics, financial economics, business economics, entrepreneurial and business administration, management and operations, management sciences, finance, pharmacoeconomics, and all other related fields of economics and business.
Other social sciences: anthropology (social and cultural) and ethnology, demography, geography (human, economic and social), planning (town, city and country), management, organisation and methods (excluding market research unless new methods/techniques are developed), law, linguistics, political sciences, sociology, miscellaneous social sciences and interdisciplinary, and methodological and historical science and technology activities relating to subjects in this group.
Humanities: history (history, prehistory and history, together with auxiliary historical disciplines such as archaeology, numismatics, palaeography, genealogy, etc.), languages and literature (ancient and modern), other humanities (philosophy (including the history of science and technology)), arts (history of art, art criticism, painting, sculpture, musicology, dramatic art excluding artistic "research" of any kind), religion, theology, other fields and subjects pertaining to the humanities, and methodological, historical and other science and technology activities relating to the subjects in this group.
In 2024, how were this organization's total expenditures of $ [Amount] for R&D performed in-house within Canada distributed by field(s) of research and development?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
Natural and formal sciences
Exclude: computer sciences, information technology and bioinformatics (to be reported at lines s. and t.) |
|---|
| a. Mathematics |
|
|---|
| b. Physical sciences |
|
|---|
| c. Chemical sciences |
|
|---|
| d. Earth and related environmental sciences |
|
|---|
| e. Biological sciences |
|
|---|
| f. Other natural sciences |
|
|---|
| Total natural and formal sciences |
|
|---|
Engineering and technology
Exclude: software engineering and technology (to be reported at line r.) |
|---|
| g. Civil engineering |
|
|---|
| h. Electrical engineering, electronic engineering and communications technology |
|
|---|
| i. Mechanical engineering |
|
|---|
| j. Chemical engineering |
|
|---|
| k. Materials engineering |
|
|---|
| l. Medical engineering |
|
|---|
| m. Environmental engineering |
|
|---|
| n. Environmental biotechnology |
|
|---|
| o. Industrial biotechnology |
|
|---|
| p. Nanotechnology |
|
|---|
| q. Other engineering and technologies |
|
|---|
| Total engineering and technology |
|
|---|
| Software-related sciences and technology |
|
|---|
| r. Software engineering and technology |
|
|---|
| s. Computer sciences |
|
|---|
| t. Information technology and bioinformatics |
|
|---|
| Total software-related sciences and technology |
|
|---|
| Medical and health sciences |
|---|
| u. Basic medicine |
|
|---|
| v. Clinical medicine |
|
|---|
| w. Health sciences |
|
|---|
| x. Medical biotechnology |
|
|---|
| y. Other medical sciences |
|
|---|
| Total medical and health sciences |
|
|---|
| Agricultural sciences |
|---|
| z. Agriculture, forestry and fisheries sciences |
|
|---|
| aa. Animal and dairy sciences |
|
|---|
| ab. Veterinary sciences |
|
|---|
| ac. Agricultural biotechnology |
|
|---|
| ad. Other agricultural sciences |
|
|---|
| Total agricultural sciences |
|
|---|
| Social sciences and humanities |
|---|
| ae. Psychology |
|---|
| af. Educational sciences |
|
|---|
| ag. Economics and business |
|
|---|
| ah. Other social sciences |
|
|---|
| ai. Humanities |
|
|---|
| Total social sciences and humanities |
|
|---|
| 2024 - Total in-house R&D expenditures within Canada by field of research and development |
|
|---|
| Total in-house R&D expenditures previously reported from question 4 |
|---|
19. Summary of 2024 total in-house R&D expenditures within Canada distributed by field(s) of research and development.
Summary of 2024 total in-house R&D expenditures within Canada distributed by field(s) of research and development.
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| Total natural and formal sciences |
|
|---|
| Total engineering and technology |
|
|---|
| Total software-related sciences and technology |
|
|---|
| Total medical and health sciences |
|
|---|
| Total agricultural sciences |
|
|---|
| Total social sciences and humanities |
|
|---|
| Total in-house R&D expenditures within Canada by fields of research and development |
|
|---|
Nature of R&D for in-house R&D expenditures within Canada in 2024
20. In 2024, how were this organization's total expenditures for R&D performed in-house within Canada of $ [Amount] distributed by nature of R&D?
Basic research is experimental or theoretical work undertaken primarily to acquire new knowledge of the underlying foundation of phenomena and observable facts, without any particular application or use in view.
Applied research is original investigation undertaken in order to acquire new knowledge. It is, however, directed primarily towards a specific, practical aim or objective.
Experimental development is systematic work, drawing on knowledge gained from research and practical experience and producing additional knowledge, which is directed to producing new products or processes or to improving existing products or processes.
(OECD. Frascati Manual: Proposed Standard for Surveys on Research and Experimental Development, 2015)
In 2024, how were this organization's total expenditures for R&D performed in-house within Canada of $ [Amount] distributed by nature of R&D?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Percentage of total in-house R&D expenditures |
|---|
| a. Basic research |
|
|---|
| b. Applied research |
|
|---|
| c. Experimental development |
|
|---|
| Total percentage |
|
|---|
Results of R&D expenditures from 2022 to 2024
21. During the three (3) years 2022, 2023 and 2024, did this organization's total expenditures for R&D performed in-house and outsourced (contracted out or granted) within Canada or outside Canada lead to new or significant improvements to the following?
Goods
Goods developed through new knowledge from research discoveries include determination of effectiveness of existing treatment protocols, establishment of new treatment protocols (including diagnostic procedures, tests and protocols), and creation of new service delivery models and reference tools (including electronic applications).
During the three (3) years 2022, 2023 and 2024, did this organization's total expenditures for R&D performed in-house and outsourced (contracted out or granted) within Canada or outside Canada lead to new or significant improvements to the following?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Yes |
No |
|---|
a. Goods
Include goods developed through new knowledge from research discoveries |
|
|
|---|
b. Services
Include on-going knowledge transfer to physicians, first responders, patients and the general public. |
|
|
|---|
| c. Methods of manufacturing or producing goods and services |
|
|
|---|
| d. Logistics, delivery or distribution methods for this organization's inputs, goods or services |
|
|
|---|
| e. Supporting activities for this organization's processes, such as maintenance systems or operations for purchasing, accounting or computing |
|
|
|---|
Energy-related R&D by area of technology
22. In 2024, did this organization's total in-house and outsourced (contracted out or granted) R&D expenditures include energy-related R&D in the following categories?
- Fossil fuels: crude oils and natural gas exploration, crude oils and natural gas production, oil sands and heavy crude oils surface and sub-surface production and separation of the bitumen, tailings management, refining, processing and upgrading, coal production, separation and processing, transportation of fossil fuels.
- Renewable energy resources: solar photovoltaics (PV), solar thermal-power and high-temperature applications, solar heating and cooling, wind energy, bio-energy - biomass production, bio-energy - biomass conversion to fuels, bio-energy - biomass conversion to heat and electricity, and other bio-energy, small hydro (less than 10 MW), large hydro (greater than or equal to 10 MW), other renewable energy.
- Nuclear: materials exploration, mining and preparation, tailings management, nuclear reactors, other fission, fusion.
- Electric power: generation in utility sector, combined heat and power in industry and in buildings, electricity transmission, distribution and storage of electricity.
- Hydrogen and fuel cells: hydrogen production for process applications, hydrogen production for transportation applications, hydrogen transport and storage, other hydrogen, fuel cells, both stationary and mobile.
- Energy efficiency: industry, residential and commercial, transportation, other energy efficiency.
- Other energy-related technologies: carbon capture, transportation and storage for fossil fuel production and processing, electric power generation, industry in end-use sector, energy systems analysis, all other energy-related technologies.
In 2024, did this organization's total in-house and outsourced (contracted out or granted) R&D expenditures include energy-related R&D in the following categories?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Yes |
No |
|---|
| a. Fossil fuels |
|
|
|---|
| b. Renewable energy resources |
|
|
|---|
| c. Nuclear fission and fusion |
|
|
|---|
| d. Electric power |
|
|
|---|
| e. Hydrogen and fuel cells |
|
|
|---|
| f. Energy efficiency |
|
|
|---|
| g. Other energy-related technologies |
|
|
|---|
Energy-related R&D by area of technology — Fossil fuels
23. In 2024, did this organization's total in-house and outsourced (contracted out or granted) R&D expenditures include fossil fuels-related R&D in the following categories?
Select all that apply.
Crude oils and natural gas exploration:
Includes development of advanced exploration methods (geophysical, geochemical, seismic, magnetic) for on-shore and off-shore prospecting.
Crude oil and natural gas production (including enhanced recovery) and storage:
Includes on-shore and off-shore deep drilling equipment and techniques for conventional oil and gas, secondary and tertiary recovery of oil and gas, hydro fracturing techniques, processing and cleaning of raw product, storage on remote platforms (e.g., Arctic, off-shore), safety aspects of off-shore platforms.
Oil sands and heavy crude oils surface and sub-surface production and separation of the bitumen, tailings management:
Includes surface and in-situ production (e.g., SAGD), tailings management.
Refining, processing and upgrading:
Includes processing of natural gas to pipeline specifications, and refining of conventional crude oils to refined petroleum products (RPPs), and the upgrading of bitumen and heavy oils either to synthetic crude oil or to RPPs. Upgrading may be done at an oil sands plant, regional merchant upgraders or integrated into a refinery producing RPPs.
Coal production, separation and processing:
Includes coal, lignite and peat exploration, deposit evaluation techniques, mining techniques, separation techniques, coking and blending, other processing such as coal to liquids, underground (in-situ) gasification.
Transportation of fossil fuels:
Includes transport of gaseous, liquid and solid hydrocarbons via pipelines (land and submarine) and their network evaluation, safety aspects of LNG transport and storage.
- Crude oils and natural gas exploration
- Crude oils and natural gas production and storage
Include enhanced recovery natural gas production.
- Oil sands and heavy crude oil surface and sub-surface production and separation of bitumen, tailings management
- Refining, processing and upgrading of fossil fuels
- Coal production, separation and processing
- Transportation of fossil fuels
- None of the above
Energy-related R&D by area of technology
Report all 2024 R&D expenditures for fossil fuels within this reporting unit.
24. In 2024, what were this organization's energy R&D expenditures on crude oils and natural gas exploration?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Crude oils and natural gas exploration:
Include development of advanced exploration methods (geophysical, geochemical, seismic, magnetic) for on-shore and off-shore prospecting.
In 2024, what were this organization's energy R&D expenditures on crude oils and natural gas exploration?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for fossil fuels within this reporting unit.
25. In 2024, what were this organization's energy R&D expenditures on crude oils and natural gas production and storage?
Include enhanced recovery.
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Crude oil and natural gas production (including enhanced recovery) and storage:
Include on-shore and off-shore deep drilling equipment and techniques for conventional oil and gas, secondary and tertiary recovery of oil and gas, hydro fracturing techniques, processing and cleaning of raw product, storage on remote platforms (e.g., Arctic, off-shore), safety aspects of off-shore platforms.
In 2024, what were this organization's energy R&D expenditures on crude oils and natural gas production and storage?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for fossil fuels within this reporting unit.
26. In 2024, what were this organization's energy R&D expenditures on oil sands and heavy crude oil surface and sub-surface production and separation of bitumen, tailings management?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Oil sands and heavy crude oils surface and sub-surface production and separation of the bitumen, tailings management:
Include surface and in-situ production (e.g., SAGD), tailings management.
In 2024, what were this organization's energy R&D expenditures on oil sands and heavy crude oil surface and sub-surface production and separation of bitumen, tailings management?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for fossil fuels within this reporting unit.
27. In 2024, what were this organization's energy R&D expenditures on refining, processing and upgrading of fossil fuels?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Refining, processing and upgrading:
Include processing of natural gas to pipeline specifications, and refining of conventional crude oils to refined petroleum products (RPPs), and the upgrading of bitumen and heavy oils either to synthetic crude oil or to RPPs. Upgrading may be done at an oil sands plant, regional merchant upgraders or integrated into a refinery producing RPPs.
In 2024, what were this organization's energy R&D expenditures on refining, processing and upgrading of fossil fuels?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for fossil fuels within this reporting unit.
28. In 2024, what were this organization's energy R&D expenditures on coal production, separation and processing?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Coal production, separation and processing:
Include coal, lignite and peat exploration, deposit evaluation techniques, mining techniques, separation techniques, coking and blending, other processing such as coal to liquids, underground (in-situ) gasification.
In 2024, what were this organization's energy R&D expenditures on coal production, separation and processing?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for fossil fuels within this reporting unit.
29. In 2024, what were this organization's energy R&D expenditures on transportation of fossil fuels?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Transportation of fossil fuels:
Include transport of gaseous, liquid and solid hydrocarbons via pipelines (land and submarine) and their network evaluation, safety aspects of LNG transport and storage.
In 2024, what were this organization's energy R&D expenditures on transportation of fossil fuels?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Energy-related R&D by area of technology — Renewable energy resources
30. In 2024, did this organization's total in-house and outsourced (contracted out or granted) R&D expenditures include renewable energy resources-related R&D in the following categories?
Select all that apply.
Solar photovoltaics (PV):
Include solar cell development, PV-module development, PV-inverter development, building-integrated PV-modules, PV-system development, other.
Solar thermal-power and high-temperature applications:
Include solar chemistry, concentrating collector development, solar thermal power plants, high-temperature applications for heat and power.
Solar heating and cooling:
Include daylighting, passive and active solar heating and cooling, collector development, hot water preparation, combined-space heating, solar architecture, solar drying, solar-assisted ventilation, swimming pool heating, low-temperature process heating, other.
Wind energy:
Include technology development, such as blades, turbines, converters structures, system integration, other.
Bio-energy - Biomass production/supply and transport:
Include improvement of energy crops, research on bio-energy production potential and associated land-use effects, supply and transport of bio-solids, bio-liquids, biogas and bio-derived energy products (e.g., ethanol, biodiesel), compacting and baling, other.
Bio-energy - Biomass conversion to fuels:
Include conventional bio-fuels, cellulosic-derived alcohols, biomass gas-to-liquids, other energy-related products and by-products.
Bio-energy - Biomass conversion to heat and electricity:
Include bio-based heat, electricity and combined heat and power (CHP).
Exclude multi-firing with fossil fuels.
Other bio-energy:
Include recycling and the use of municipal, industrial and agricultural waste as energy not covered elsewhere.
Small hydro - (less than 10 MW):
Include plants with capacity below 10 MW.
Large hydro - (greater than or equal to 10 MW):
Include plants with capacity of 10 MW and above.
Other renewable energy:
Include hot dry rock, hydro-thermal, geothermal heat applications (including agriculture), tidal power, wave energy, ocean current power, ocean thermal power, other.
- Solar photovoltaics (PV)
- Solar thermal-power and high-temperature applications
- Solar heating and cooling
- Wind energy
- Bio-energy - biomass production and transportation
- Bio-energy - biomass conversion to transportation fuel
- Bio-energy - biomass conversion to heat and electricity
- Other bio-energy
- Small hydro (less than 10 MW)
- Large hydro (greater than or equal to 10 MW)
- Other renewable energy
Include ocean and geothermal.
- None of the above
Energy-related R&D by area of technology
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
31. In 2024, what were this organization's energy R&D expenditures on solar photovoltaics (PV)?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Solar photovoltaics (PV):
Include solar cell development, PV-module development, PV-inverter development, building-integrated PV-modules, PV-system development, other.
In 2024, what were this organization's energy R&D expenditures on solar photovoltaics (PV)?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
32. In 2024, what were this organization's energy R&D expenditures on solar thermal-power and high-temperature applications?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Solar thermal-power and high-temperature applications:
Include solar chemistry, concentrating collector development, solar thermal power plants, high-temperature applications for heat and power.
In 2024, what were this organization's energy R&D expenditures on solar thermal-power and high-temperature applications?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
33. In 2024, what were this organization's energy R&D expenditures on solar heating and cooling?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Solar heating and cooling:
Include daylighting, passive and active solar heating and cooling, collector development, hot water preparation, combined-space heating, solar architecture, solar drying, solar-assisted ventilation, swimming pool heating, low-temperature process heating, other.
In 2024, what were this organization's energy R&D expenditures on solar heating and cooling?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
34. In 2024, what were this organization's energy R&D expenditures on wind energy?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Wind energy:
Include technology development, such as blades, turbines, converters structures, system integration, other.
In 2024, what were this organization's energy R&D expenditures on wind energy?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
35. In 2024, what were this organization's energy R&D expenditures on bio-energy - biomass production and transport?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Bio-energy - Biomass production/supply and transport:
Include improvement of energy crops, research on bio-energy production potential and associated land-use effects, supply and transport of bio-solids, bio-liquids, biogas and bio-derived energy products (e.g., ethanol, biodiesel), compacting and baling, other.
In 2024, what were this organization's energy R&D expenditures on bio-energy - biomass production and transport?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
36. In 2024, what were this organization's energy R&D expenditures on bio-energy - biomass conversion to transportation fuel?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Bio-energy - Biomass conversion to transportation fuel:
Include conventional bio-fuels, cellulosic-derived alcohols, biomass gas-to-liquids, other energy-related products and by-products.
In 2024, what were this organization's energy R&D expenditures on bio-energy - biomass conversion to transportation fuel?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
37. In 2024, what were this organization's energy R&D expenditures on bio-energy - biomass conversion to heat and electricity?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Bio-energy - Biomass conversion to heat and electricity:
Include bio-based heat, electricity and combined heat and power (CHP).
Exclude multi-firing with fossil fuels.
In 2024, what were this organization's energy R&D expenditures on bio-energy - biomass conversion to heat and electricity?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
38. In 2024, what were this organization's energy R&D expenditures on other bio-energy?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Other bio-energy:
Include recycling and the use of municipal, industrial and agricultural waste as energy not covered elsewhere.
In 2024, what were this organization's energy R&D expenditures on other bio-energy?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
39. In 2024, what were this organization's energy R&D expenditures on small hydro (less than 10 MW)?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars
Report '0' for no R&D expenditures.
Small hydro - (less than 10 MW):
Include plants with capacity below 10 MW.
In 2024, what were this organization's energy R&D expenditures on small hydro (less than 10 MW)?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
40. In 2024, what were this organization's energy R&D expenditures on large hydro (greater than or equal to 10 MW)?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Large hydro - (greater than or equal to 10 MW):
Include plants with capacity of 10 MW or greater.
In 2024, what were this organization's energy R&D expenditures on large hydro (greater than or equal to 10 MW)?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for renewable energy resources within this reporting unit.
41. In 2024, what were this organization's energy R&D expenditures on other renewable energy?
Include ocean and geothermal.
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Other renewable energy:
Include hot dry rock, hydro-thermal, geothermal heat applications (including agriculture), tidal power, wave energy, ocean current power, ocean thermal power, other.
In 2024, what were this organization's energy R&D expenditures on other renewable energy?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Energy-related R&D by area of technology - Nuclear fission and fusion
42. In 2024, did this organization's total in-house and outsourced (contracted out or granted) R&D expenditures include nuclear fission and fusion-related R&D in the following categories?
Select all that apply.
Exploration, mining and preparation, tailings management:
Include development of advanced exploration methods (geophysical, geochemical) for prospecting, ore surface and in-situ production, uranium and thorium extraction and conversion, enrichment, handling of tailings and remediation.
Nuclear reactors:
Include nuclear reactors of all types and related system components.
Other fission:
Include nuclear safety, environmental protection (emission reduction or avoidance), radiation protection and decommissioning of power plants and related nuclear fuel cycle installations, nuclear waste treatment, disposal and storage, fissile material recycling, fissile materials control, transport of radioactive materials.
Fusion:
Include all types (e.g., magnetic confinement, laser applications).
- Nuclear materials exploration, mining and preparation, tailings management
- Nuclear reactors
- Other fission
- Fusion
- None of the above
Energy-related R&D by area of technology
Report all 2024 R&D expenditures for nuclear fission and fusion within this reporting unit.
43. In 2024, what were this organization's energy R&D expenditures on nuclear materials exploration, mining and preparation, tailings management?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Exploration, mining and preparation, tailings management:
Include development of advanced exploration methods (geophysical, geochemical) for prospecting, ore surface and in-situ production, uranium and thorium extraction and conversion, enrichment, handling of tailings and remediation.
In 2024, what were this organization's energy R&D expenditures on nuclear materials exploration, mining and preparation, tailings management?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for nuclear fission and fusion within this reporting unit.
44. In 2024, what were this organization's energy R&D expenditures on nuclear reactors?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Nuclear reactors:
Include nuclear reactors of all types and related system components.
In 2024, what were this organization's energy R&D expenditures on nuclear reactors?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for nuclear fission and fusion within this reporting unit.
45. In 2024, what were this organization's energy R&D expenditures on other fission?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Other fission:
Include nuclear safety, environmental protection (emission reduction or avoidance), radiation protection and decommissioning of power plants and related nuclear fuel cycle installations, nuclear waste treatment, disposal and storage, fissile material recycling, fissile materials control, transport of radioactive materials.
In 2024, what were this organization's energy R&D expenditures on other fission?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for nuclear fission and fusion within this reporting unit.
46. In 2024, what were this organization's energy R&D expenditures on fusion?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Fusion:
Include all types (e.g., magnetic confinement, laser applications).
In 2024, what were this organization's energy R&D expenditures on fusion?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Energy-related R&D by area of technology - Electric power
47. In 2024, did this organization's total in-house and outsourced (contracted out or granted) R&D expenditures include electric power-related R&D in the following categories?
Select all that apply.
Electric power generation in utility sector:
Include conventional and non-conventional technology (e.g., pulverised coal, fluidised bed, gasification-combined cycle, supercritical), re-powering, retrofitting, life extensions and upgrading of power plants, generators and components, super-conductivity, magneto hydrodynamic, dry cooling towers, co-firing (e.g., with biomass), air and thermal pollution reduction or avoidance, flue gas cleanup (excluding CO2 removal), CHP (combined heat and power) not covered elsewhere.
Electric power - combined heat and power in industry, buildings:
Include industrial applications, small scale applications for buildings.
Electricity transmission, distribution and storage:
Include solid state power electronics, load management and control systems, network problems, super-conducting cables, AC and DC high voltage cables, HVDC transmission, other transmission and distribution related to integrating distributed and intermittent generating sources into networks, all storage (e.g., batteries, hydro reservoirs, fly wheels), other.
- Electric power generation in utility sector
- Electric power - combined heat and power in industry, buildings
- Electricity transmission, distribution and storage
- None of the above
Energy-related R&D by area of technology
Report all 2024 R&D expenditures for electric power within this reporting unit.
48. In 2024, what were this organization's energy R&D expenditures on electric power generation in utility sector?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Electric power generation in utility sector:
Include conventional and non-conventional technology (e.g., pulverised coal, fluidised bed, gasification-combined cycle, supercritical), re-powering, retrofitting, life extensions and upgrading of power plants, generators and components, super-conductivity, magneto hydrodynamic, dry cooling towers, co-firing (e.g., with biomass), air and thermal pollution reduction or avoidance, flue gas cleanup (excluding CO2 removal), CHP (combined heat and power) not covered elsewhere.
In 2024, what were this organization's energy R&D expenditures on electric power generation in utility sector?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for electric power within this reporting unit.
49. In 2024, what were this organization's energy R&D expenditures on electric power - combined heat and power in industry, buildings?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Electric power - combined heat and power in industry, buildings:
Include industrial applications, small scale applications for buildings.
In 2024, what were this organization's energy R&D expenditures on electric power - combined heat and power in industry, buildings?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for electric power within this reporting unit.
50. In 2024, what were this organization's energy R&D expenditures on electricity transmission, distribution and storage?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Electricity transmission, distribution and storage:
Include solid state power electronics, load management and control systems, network problems, super-conducting cables, AC and DC high voltage cables, HVDC transmission, other transmission and distribution related to integrating distributed and intermittent generating sources into networks, all storage (e.g., batteries, hydro reservoirs, fly wheels), other.
In 2024, what were this organization's energy R&D expenditures on electricity transmission, distribution and storage?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Energy-related R&D by area of technology - Hydrogen and fuel cells
51. In 2024, did this organization's total in-house and outsourced (contracted out or granted) R&D expenditures include hydrogen and fuel cells-related R&D in the following categories?
Select all that apply.
Other hydrogen:
Include end uses (e.g., combustion), other infrastructure and systems R&D (refuelling stations).
Stationary fuel cells:
Include electricity generation, other stationary end-use.
Mobile fuel cells:
Include portable applications.
- Hydrogen production for process applications
- Hydrogen production for transportation applications
- Hydrogen transport and storage
- Other hydrogen
- Stationary fuel cells
- Mobile fuel cells
- None of the above
Energy-related R&D by area of technology
Report all 2024 R&D expenditures for hydrogen and fuel cells within this reporting unit.
52. In 2024, what were this organization's energy R&D expenditures on hydrogen production for process applications?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
In 2024, what were this organization's energy R&D expenditures on hydrogen production for process applications?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for hydrogen and fuel cells within this reporting unit.
53. In 2024, what were this organization's energy R&D expenditures on hydrogen production for transportation applications?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
In 2024, what were this organization's energy R&D expenditures on hydrogen production for transportation applications?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for hydrogen and fuel cells within this reporting unit.
54. In 2024, what were this organization's energy R&D expenditures on hydrogen transport and storage?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
In 2024, what were this organization's energy R&D expenditures on hydrogen transport and storage?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for hydrogen and fuel cells within this reporting unit.
55. In 2024, what were this organization's energy R&D expenditures on other hydrogen?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Other hydrogen:
Include end uses (e.g., combustion), other infrastructure and systems R&D (refuelling stations).
In 2024, what were this organization's energy R&D expenditures on other hydrogen?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for hydrogen and fuel cells within this reporting unit.
56. In 2024, what were this organization's energy R&D expenditures on stationary fuel cells?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Stationary fuel cells:
Include electricity generation, other stationary end-use.
In 2024, what were this organization's energy R&D expenditures on stationary fuel cells?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for hydrogen and fuel cells within this reporting unit.
57. In 2024, what were this organization's energy R&D expenditures on mobile fuel cells?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Mobile fuel cells:
Include portable applications.
In 2024, what were this organization's energy R&D expenditures on mobile fuel cells?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Energy-related R&D by area of technology - Energy efficiency
58. In 2024, did this organization's total in-house and outsourced (contracted out or granted) R&D expenditures include energy efficiency-related R&D in the following categories?
Select all that apply.
Energy efficiency for industry:
Include reduction of energy consumption through improved use of energy and/or reduction or avoidance of air and other emissions related to the use of energy in industrial systems and processes (excluding bio-energy-related) through the development of new techniques, new processes and new equipment, other.
Energy efficiency for residential, institutional and commercial:
Include space heating and cooling, ventilation and lighting control systems other than solar technologies, low energy housing design and performance other than solar technologies, new insulation and building materials, thermal performance of buildings, domestic appliances, other.
Energy efficiency for transportation:
Include analysis and optimisation of energy consumption in the transport sector, efficiency improvements in light-duty vehicles, heavy-duty vehicles, non-road vehicles, public transport systems, engine-fuel optimisation, use of alternative fuels (liquid and gaseous, other than hydrogen), fuel additives, diesel engines, Stirling motors, electric cars, hybrid cars, air emission reduction, other.
Other energy efficiency:
Include waste heat utilisation (heat maps, process integration, total energy systems, low temperature thermodynamic cycles), district heating, heat pump development, reduction of energy consumption in the agricultural sector.
- Energy efficiency applications for industry
- Energy efficiency for residential, institutional and commercial sectors
- Energy efficiency for transportation
- Other energy efficiency
- None of the above
Energy-related R&D by area of technology
Report all 2024 R&D expenditures for energy efficiency within this reporting unit.
59. In 2024, what were this organization's energy R&D expenditures on energy efficiency applications for industry?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Energy efficiency for industry:
Include reduction of energy consumption through improved use of energy and/or reduction or avoidance of air and other emissions related to the use of energy in industrial systems and processes (excluding bio-energy-related) through the development of new techniques, new processes and new equipment, other.
In 2024, what were this organization's energy R&D expenditures on energy efficiency applications for industry?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|
|---|
| a. Funds from this organization |
|
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|
|---|
| c. All other Canadian sources of funds |
|
|
|---|
| d. All foreign sources of funds |
|
|
|---|
| Total in-house R&D |
|
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|
|---|
| Total outsourced R&D |
|
|
|---|
Report all 2024 R&D expenditures for energy efficiency within this reporting unit.
60. In 2024, what were this organization's energy R&D expenditures on energy efficiency for residential, institutional and commercial sectors?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Energy efficiency for residential, institutional and commercial:
Include space heating and cooling, ventilation and lighting control systems other than solar technologies, low energy housing design and performance other than solar technologies, new insulation and building materials, thermal performance of buildings, domestic appliances, other.
In 2024, what were this organization's energy R&D expenditures on energy efficiency for residential, institutional and commercial sectors?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for energy efficiency within this reporting unit.
61. In 2024, what were this organization's energy R&D expenditures on energy efficiency for transportation?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Energy efficiency for transportation:
Include analysis and optimisation of energy consumption in the transport sector, efficiency improvements in light-duty vehicles, heavy-duty vehicles, non-road vehicles, public transport systems, engine-fuel optimisation, use of alternative fuels (liquid and gaseous, other than hydrogen), fuel additives, diesel engines, Stirling motors, electric cars, hybrid cars, air emission reduction, other.
In 2024, what were this organization's energy R&D expenditures on energy efficiency for transportation?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for energy efficiency within this reporting unit.
62. In 2024, what were this organization's energy R&D expenditures on other energy efficiency?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Other energy efficiency:
Include waste heat utilisation (heat maps, process integration, total energy systems, low temperature thermodynamic cycles), district heating, heat pump development, reduction of energy consumption in the agricultural sector.
In 2024, what were this organization's energy R&D expenditures on other energy efficiency?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Energy-related R&D by area of technology - Other energy-related technologies
63. In 2024, did this organization's total in-house and outsourced (contracted out or granted) R&D expenditures include other energy-related R&D in the following categories?
Select all that apply.
Carbon capture end-use:
Include industry in the end-use sector, such as steel production, manufacturing, etc. (exclude fossil fuel production and processing and electric power production).
Energy system analysis:
Include system analysis related to energy R&D not covered elsewhere, sociological, economical and environmental impact of energy which are not specifically related to one technology area listed in the sections above.
All other energy technologies:
Include energy technology information dissemination, studies not related to a specific technology area listed above.
- Carbon capture, transport and storage related to fossil fuel production and processing
- Carbon capture, transport and storage related to electric power production
- Carbon capture, transport and storage related to industry in end-use sector
- Energy system analysis
- All other energy-related technologies
- None of the above
Energy-related R&D by area of technology
Report all 2024 R&D expenditures for other energy-related technologies within this reporting unit.
64. In 2024, what were this organization's energy R&D expenditures on carbon capture, transport and storage related to fossil fuel production and processing?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
In 2024, what were this organization's energy R&D expenditures on carbon capture, transport and storage related to fossil fuel production and processing?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for other energy-related technologies within this reporting unit.
65. In 2024, what were this organization's energy R&D expenditures on carbon capture, transport and storage related to electric power production?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
In 2024, what were this organization's energy R&D expenditures on carbon capture, transport and storage related to electric power production?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for other energy-related technologies within this reporting unit.
66. In 2024, what were this organization's energy R&D expenditures on carbon capture, transport and storage related to industry in end-use sector?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Carbon capture end-use:
Include industry in the end-use sector, such as steel production, manufacturing, etc. (exclude fossil fuel production and processing and electric power production).
In 2024, what were this organization's energy R&D expenditures on carbon capture, transport and storage related to industry in end-use sector?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|
|---|
| a. Funds from this organization |
|
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|
|---|
| c. All other Canadian sources of funds |
|
|
|---|
| d. All foreign sources of funds |
|
|
|---|
| Total in-house R&D |
|
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|
|---|
| Total outsourced R&D |
|
|
|---|
Report all 2024 R&D expenditures for other energy-related technologies within this reporting unit.
67. In 2024, what were this organization's energy R&D expenditures on energy system analysis?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Energy system analysis:
Include system analysis related to energy R&D not covered elsewhere, sociological, economical and environmental impact of energy which are not specifically related to one technology area listed in the sections above.
In 2024, what were this organization's energy R&D expenditures on energy system analysis?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Report all 2024 R&D expenditures for other energy-related technologies within this reporting unit.
68. In 2024, what were this organization's energy R&D expenditures on other energy-related technologies?
Exclude capital depreciation.
Please report all amounts in thousands of Canadian dollars.
Report '0' for no R&D expenditures.
Other energy-related technologies:
Include energy technology information dissemination, studies not related to a specific technology area listed above.
In 2024, what were this organization's energy R&D expenditures on other energy-related technologies?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
CAN$ '000 |
|---|
| a. Funds from this organization |
|
|---|
| b. Funds from federal, provincial or territorial government(s) |
|
|---|
| c. All other Canadian sources of funds |
|
|---|
| d. All foreign sources of funds |
|
|---|
| Total in-house R&D |
|
|---|
| e. Outsourced (contracted out or granted) within Canada |
|
|---|
| f. Outsourced (contracted out or granted) outside Canada |
|
|---|
| Total outsourced R&D |
|
|---|
Summary of energy-related and total R&D expenditures
69. Summary of total 2024 energy-related R&D and total R&D expenditures
Summary of total 2024 energy-related R&D and total R&D expenditures
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Total energy-related R&D |
Total R&D |
|---|
| Total funds from this organization |
|
|
|---|
| Total funds from federal, provincial or territorial government(s) |
|
|
|---|
| Total all other Canadian sources of funds |
|
|
|---|
| Total all foreign sources of funds |
|
|
|---|
| Total in-house R&D expenditures |
|
|
|---|
| Total outsourced (contracted out or granted) within Canada |
|
|
|---|
| Total outsourced (contracted out or granted) outside Canada |
|
|
|---|
| Total outsourced (contracted out or granted) R&D expenditures |
|
|
|---|
| Total R&D expenditures |
|
|
|---|
In-house R&D personnel in 2024
70. In 2024, how many in-house R&D personnel within Canada did this organization have in the following R&D occupations?
Full-time equivalent (FTE)
R&D may be carried out by persons who work solely on R&D projects or by persons who devote only part of their time to R&D and the balance to other activities such as testing, quality control and production engineering. To arrive at the total effort devoted to R&D in terms of personnel, it is necessary to estimate the full-time equivalent of these persons working only part-time in R&D.
Full-time equivalent (FTE) = Number of persons who work solely on R&D projects + the time of persons working only part of their time on R&D.
Example calculation: If out of four scientists engaged in R&D work, one works solely on R&D projects and the remaining three devote only one quarter of their working time to R&D, then: FTE = 1 + 1/4 + 1/4 + 1/4 = 1.75 scientists.
R&D personnel
Include:
- permanent, temporary and casual R&D employees
- independent on-site R&D consultants and contractors working in your business's offices, laboratories, or other facilities
- employees engaged in R&D -related support activities.
Researchers and research managers are composed of:
- Scientists, social scientists, engineers and researchers are professionals engaged in the conception or creation of new knowledge. They conduct research and improve or develop concepts, theories, models, techniques instrumentation, software or operational methods. They may be certified by provincial or territorial educational authorities, provincial, territorial or national scientific or engineering associations.
- Senior research managers plan or manage R&D projects and programs. They may be certified by provincial or territorial educational authorities, provincial, territorial or national scientific or engineering associations.
R&D technical, administrative and support staff are composed of:
- Technicians and technologists and research assistants are persons whose main tasks require technical knowledge and experience in one or more fields of engineering, the physical and life sciences, or the social sciences, humanities and the arts. They participate in R&D by performing scientific and technical tasks involving the application of concepts, operational methods and the use of research equipment, normally under the supervision of researchers. They may be certified by provincial or territorial educational authorities, provincial, territorial or national scientific or engineering associations.
- Other R&D technical, administrative support staff include skilled and unskilled craftsmen, and administrative, secretarial and clerical staff participating in R&D projects or directly associated with such projects.
On-site R&D consultants and contractors are individuals hired 1) to perform project-based work or to provide goods at a fixed or ascertained price or within a certain time or 2) to provide advice or services in a specialized field for a fee and, in both cases, work at the location specified and controlled by the contracting company or organization.
In 2024, how many in-house R&D personnel within Canada did this organization have in the following R&D occupations?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Men (FTEs) |
Women (FTEs) |
Non-binary persons (FTEs) |
Total (FTEs) |
|---|
| Researchers and research managers |
|---|
a. Scientists, social scientists, engineers and researchers
Include software developers and programmers. |
|
|
|
|
|---|
| b. Senior research managers |
|
|
|
|
|---|
| Total researchers and research managers |
|
|
|
|
|---|
| R&D technical, administrative and support staff |
|---|
c. Technicians, technologists and research assistants
Include software technicians. |
|
|
|
|
|---|
| d. Other R&D technical, administrative and support staff |
|
|
|
|
|---|
| Total R&D technical, administrative and support staff |
|
|
|
|
|---|
| Other R&D occupations |
|---|
| e. On-site R&D consultants and contractors |
|
|
|
|
|---|
| Total in-house R&D personnel within Canada |
|
|
|
|
|---|
71. Of this organization's total in-house R&D personnel reported above, what percentage performed software-related activities?
Software-related sciences and technologies
- Software engineering and technology: computer software engineering, computer software technology and other related computer software engineering and technologies.
- Computer sciences: computer science, artificial intelligence, cryptography and other related computer sciences.
- Information technology and bioinformatics: information technology, informatics, bioinformatics, biomathematics and other related information technologies.
Percentage of software-related activities
72. In 2024, how were the [Amount] total in-house R&D personnel distributed by province or territory?
Please report in full time equivalents (FTE).
R&D personnel
Include:
- permanent, temporary and casual R&D employees
- independent on-site R&D consultants and contractors working in your business's offices, laboratories, or other facilities
- employees engaged in R&D -related support activities.
Researchers and research managers are composed of:
- Scientists, social scientists, engineers and researchers are professionals engaged in the conception or creation of new knowledge. They conduct research and improve or develop concepts, theories, models, techniques instrumentation, software or operational methods. They may be certified by provincial or territorial educational authorities, provincial, territorial or national scientific or engineering associations.
- Senior research managers plan or manage R&D projects and programs. They may be certified by provincial or territorial educational authorities, provincial, territorial or national scientific or engineering associations.
R&D technical, administrative and support staff are composed of:
- Technicians and technologists and research assistants are persons whose main tasks require technical knowledge and experience in one or more fields of engineering, the physical and life sciences, or the social sciences, humanities and the arts. They participate in R&D by performing scientific and technical tasks involving the application of concepts, operational methods and the use of research equipment, normally under the supervision of researchers. They may be certified by provincial or territorial educational authorities, provincial, territorial or national scientific or engineering associations.
- Other R&D technical, administrative support staff include skilled and unskilled craftsmen, and administrative, secretarial and clerical staff participating in R&D projects or directly associated with such projects.
On-site R&D consultants and contractors are individuals hired 1) to perform project-based work or to provide goods at a fixed or ascertained price or within a certain time or 2) to provide advice or services in a specialized field for a fee and, in both cases, work at the location specified and controlled by the contracting company or organization.
Full-time equivalent (FTE)
R&D may be carried out by persons who work solely on R&D projects or by persons who devote only part of their time to R&D, and the balance to other activities such as testing, quality control and production engineering. To arrive at the total effort devoted to R&D in terms of personnel, it is necessary to estimate the full-time equivalent of these persons working only part-time in R&D.
Full-time equivalent (FTE): Number of persons who work solely on R&D projects + the time of persons working only part of their time on R&D.
Example calculation: If out of four scientists engaged in R&D work, one works solely on R&D projects and the remaining three devote only one quarter of their working time to R&D, then: FTE = 1 + 1/4 + 1/4 + 1/4 = 1.75 scientists.
In 2024, how were the [Amount] total in-house R&D personnel distributed by province or territory?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Number of researchers and research managers |
Number of R&D technical, administrative and support staff |
Number of on-site R&D consultants and contractors |
|---|
| a. Newfoundland and Labrador |
|
|
|
|---|
| b. Prince Edward Island |
|
|
|
|---|
| c. Nova Scotia |
|
|
|
|---|
| d. New Brunswick |
|
|
|
|---|
| e. Quebec |
|
|
|
|---|
| f. Ontario |
|
|
|
|---|
| g. Manitoba |
|
|
|
|---|
| h. Saskatchewan |
|
|
|
|---|
| i. Alberta |
|
|
|
|---|
| j. British Columbia |
|
|
|
|---|
| k. Yukon |
|
|
|
|---|
| l. Northwest Territories |
|
|
|
|---|
| m. Nunavut |
|
|
|
|---|
| Total in-house R&D personnel within Canada |
|
|
|
|---|
| Total R&D personnel previously reported from question 70 |
|
|
|
|---|
Technology and technical assistance payments in 2024
73. In 2024, did this organization make or receive payments inside or outside Canada for the following technology and technical assistance?
Technology and technical assistance payments
Definitions (equivalent to the Canadian Intellectual Property Office)
- Patent
Government grant giving the right to exclude others from making, using or selling an invention.
- Copyright
Legal protection for literary, artistic, dramatic or musical works, computer programs, performer's performances, sound recordings, and communication signals.
- Trademark
A word, symbol or design, or combination of these, used to distinguish goods or services of one person or organization from those of others in the marketplace.
- Industrial design
Legal protection against imitation of the shape, pattern, or ornamentation of an object.
- Integrated circuit topography
Three-dimensional configurations of the elements and interconnections embodied in an integrated circuit product.
- Original software
Computer programs and descriptive materials for both systems and applications. Original software can be created in-house or outsourced and includes packaged software with customization.
- Packaged or off-the-shelf software
Packaged software purchased for organizational use and excludes software with customization.
- Databases
Data files organized to permit effective access and use of the data including access clinical trial registries and administrative health data for research purposes. Includes partnerships supporting the development of databases, such as patient or clinical trial registries or biobanks, to be used for research purposes (e.g., developing a national bladder cancer patient registry with Bladder Cancer Canada for future research).
- Other technology and technical assistance
Technical assistance, industrial processes and know-how including technology transfer and know how such as batch pilot production, method develop, and validation related to technology or manufacturing transfer.
In 2024, did this organization make or receive payments inside or outside Canada for the following technology and technical assistance?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Made Payments |
Received Payments |
Both made and received payments |
Not applicable |
|---|
| a. Patents |
|
|
|
|
|---|
| b. Copyrights |
|
|
|
|
|---|
| c. Trademarks |
|
|
|
|
|---|
| d. Industrial designs |
|
|
|
|
|---|
| e. Integrated circuit topography |
|
|
|
|
|---|
| f. Original software |
|
|
|
|
|---|
| g. Packaged or off-the-shelf software |
|
|
|
|
|---|
h. Databases
Useful life exceeding one year. |
|
|
|
|
|---|
i. Other technology and technical assistance
Include technical assistance, industrial processes and know-how. |
|
|
|
|
|---|
74. In 2024, how much did this organization pay to other organizations for technology and technical assistance?
Please report all amounts in thousands of Canadian dollars.
Report '1' for payments made between $1 and $999.
Technology and technical assistance payments
Definitions (equivalent to the Canadian Intellectual Property Office)
- Patent
Government grant giving the right to exclude others from making, using or selling an invention.
- Copyright
Legal protection for literary, artistic, dramatic or musical works, computer programs, performer's performances, sound recordings, and communication signals.
- Trademark
A word, symbol or design, or combination of these, used to distinguish goods or services of one person or organization from those of others in the marketplace.
- Industrial design
Legal protection against imitation of the shape, pattern, or ornamentation of an object.
- Integrated circuit topography
Three-dimensional configurations of the elements and interconnections embodied in an integrated circuit product.
- Original software
Computer programs and descriptive materials for both systems and applications. Original software can be created in-house or outsourced and includes packaged software with customization.
- Packaged or off-the-shelf software
Packaged software purchased for organizational use and excludes software with customization.
- Databases
Data files organized to permit effective access and use of the data including access clinical trial registries and administrative health data for research purposes. Includes partnerships supporting the development of databases, such as patient or clinical trial registries or biobanks, to be used for research purposes (e.g., developing a national bladder cancer patient registry with Bladder Cancer Canada for future research).
- Other
Technical assistance, industrial processes and know-how including technology transfer and know how such as batch pilot production, method develop, and validation related to technology or manufacturing transfer.
In 2024, how much did this organization pay to other organizations for technology and technical assistance?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Payments made within Canada
CAN$ '000 |
Payments made outside Canada
CAN$ '000 |
|---|
| Payments made to members, affiliated companies or organizations |
|---|
| a. Patents |
|
|
|---|
| b. Copyrights |
|
|
|---|
| c. Trademarks |
|
|
|---|
| d. Industrial designs |
|
|
|---|
| e. Integrated circuit topography |
|
|
|---|
| f. Original software |
|
|
|---|
| g. Packaged or off-the-shelf software |
|
|
|---|
h. Databases
Useful life exceeding one year. |
|
|
|---|
i. Other technology and technical assistance
Include technical assistance, industrial processes and know-how. |
|
|
|---|
| Total payments made to members, affiliated companies or organizations |
|
|
|---|
| Payments made to other organizations, companies or individuals |
|---|
| j. Patents |
|
|
|---|
| k. Copyrights |
|
|
|---|
| l. Trademarks |
|
|
|---|
| m. Industrial designs |
|
|
|---|
| n. Integrated circuit topography |
|
|
|---|
| o. Original software |
|
|
|---|
| p. Packaged or off-the-shelf software |
|
|
|---|
q. Databases
Useful life exceeding one year. |
|
|
|---|
r. Other technology and technical assistance
Include technical assistance, industrial processes and know-how. |
|
|
|---|
| Total payments made to other organizations, companies or individuals |
|
|
|---|
| Total payments made to other organizations for technology and technical assistance |
|
|
|---|
75. In 2024, how much did this organization receive from other organizations for technology and technical assistance?
Please report all amounts in thousands of Canadian dollars.
Report '1' for payments received between $1 and $999.
Technology and technical assistance payments
Definitions (equivalent to the Canadian Intellectual Property Office)
- Patent
Government grant giving the right to exclude others from making, using or selling an invention.
- Copyright
Legal protection for literary, artistic, dramatic or musical works, computer programs, performer's performances, sound recordings, and communication signals.
- Trademark
A word, symbol or design, or combination of these, used to distinguish goods or services of one person or organization from those of others in the marketplace.
- Industrial design
Legal protection against imitation of the shape, pattern, or ornamentation of an object.
- Integrated circuit topography
Three-dimensional configurations of the elements and interconnections embodied in an integrated circuit product.
- Original software
Computer programs and descriptive materials for both systems and applications. Original software can be created in-house or outsourced and includes packaged software with customization.
- Packaged or off-the-shelf software
Packaged software purchased for organizational use and excludes software with customization.
- Databases
Data files organized to permit effective access and use of the data including access clinical trial registries and administrative health data for research purposes. Includes partnerships supporting the development of databases, such as patient or clinical trial registries or biobanks, to be used for research purposes (e.g., developing a national bladder cancer patient registry with Bladder Cancer Canada for future research).
- Other
Technical assistance, industrial processes and know-how including technology transfer and know how such as batch pilot production, method develop, and validation related to technology or manufacturing transfer.
In 2024, how much did this organization receive from other organizations for technology and technical assistance?
Table summary
This table contains no data. It is an example of an empty data table used by respondents to provide data to Statistics Canada.
| |
Payments received from within Canada
CAN$ '000 |
Payments received from outside Canada
CAN$ '000 |
|---|
| Payments received from members, affiliated companies or organizations |
|---|
| a. Patents |
|
|
|---|
| b. Copyrights |
|
|
|---|
| c. Trademarks |
|
|
|---|
| d. Industrial designs |
|
|
|---|
| e. Integrated circuit topography |
|
|
|---|
| f. Original software |
|
|
|---|
| g. Packaged or off-the-shelf software |
|
|
|---|
h. Databases
Useful life exceeding one year. |
|
|
|---|
i. Other technology and technical assistance
Include technical assistance, industrial processes and know-how. |
|
|
|---|
| Total payments received from members, affiliated companies or organizations |
|
|
|---|
| Payments received from other organizations, companies or individuals |
|---|
| j. Patents |
|
|
|---|
| k. Copyrights |
|
|
|---|
| l. Trademarks |
|
|
|---|
| m. Industrial designs |
|
|
|---|
| n. Integrated circuit topography |
|
|
|---|
| o. Original software |
|
|
|---|
| p. Packaged or off-the-shelf software |
|
|
|---|
q. Databases
Useful life exceeding one year. |
|
|
|---|
r. Other technology and technical assistance
Include technical assistance, industrial processes and know-how. |
|
|
|---|
| Total payments received from other organizations, companies or individuals |
|
|
|---|
| Total payments received from other organizations for technology and technical assistance |
|
|
|---|
Environmental and clean technology R&D expenditures in 2024
76. In 2024, what percentage of this organization's total expenditures of $ [Amount] for R&D performed in-house within Canada was related to research and development of environmental and clean technologies?
Environmental and clean technology is defined as any process, product, or service that reduces environmental impacts: through environmental protection activities that prevent, reduce or eliminate pollution or any other degradation of the environment, resource management activities that result in the more efficient use of natural resources, thus safeguarding against their depletion; or the use of goods that have been adapted to be significantly less energy- or resource-intensive than the industry standard
Report '0' for no environmental and clean technology R&D expenditures.
If precise figures are not available, please provide your best estimate.
Percentage of environmental and clean technology R&D
77. In 2024, in which of the following categories of environmental and clean technology did this organization perform R&D activities?
Select all that apply.
Air pollution management: Activities aimed at reducing the emissions of pollutants (including greenhouse gases) to the atmosphere. Include pollution abatement and control (e.g., end-of-pipe processes) and pollution prevention (e.g., integrated processes), as well as related measurement, control, laboratories and the like.
Solid waste management: Activities related to the collection, treatment, storage, disposal, and recycling of all domestic, industrial, non-hazardous and hazardous waste (including low-level radioactive waste). Include monitoring activities. Exclude radioactive waste and mine tailings handling and treatment (to be reported under Protection against radiation and Wastewater management, respectively).
Wastewater management: Activities aimed at pollution reduction or prevention through the abatement of pollutants or the reduction of the release of wastewater. Include measures aimed at reducing pollutants before discharge, reducing the release of wastewater, septic tanks, treatment of cooling water, handling and treatment of mine tailings, etc.
Protection and remediation of soil, groundwater and surface water: Activities aimed at the prevention of pollution infiltration: remediation or cleaning up of soils and water bodies; protection of soil from erosion, salinization and physical degradation; monitoring, control, laboratories and the like. Exclude management of wastewater released to surface waters, municipal sewer systems or soil, or injected underground (to be reported under Wastewater management) and protection of biodiversity and habitat (to be reported under Protection of biodiversity and habitat).
Protection of biodiversity and habitat: Activities related to protecting wildlife and habitat from the effects of economic activity, and to restoring wildlife or habitat that has been adversely affected by such activity. Include related environmental measurements, monitoring, control, laboratories and the like.
Noise and vibration abatement: Activities aimed at controlling or reducing industrial and transport noise and vibration for the sole purpose of protecting the environment. Include preventive in-process modifications at the source, construction of anti-noise/vibration facilities, measurement, control, laboratories and the like.
Protection against radiation: Activities aimed at preventing, reducing, or eliminating the negative consequences of radiation on the environment. This includes all handling, transportation, and treatment of radioactive waste (i.e. waste that requires shielding during normal handling and transportation due to high radionuclide content), the protection of ambient media, measurement, control, laboratories and the like, as well as any other activities related to the containment of radioactive waste. Exclude activities and measures related to low-level radioactive waste (to be reported under Solid waste management), the prevention of technological hazards (e.g., external safety of nuclear power plants), and measures taken to protect workers.
Heat or energy savings and management: Activities aimed at reducing the intake of energy through in-process modifications (such as adjustment of production processes or heat and electricity co-generation), as well as reducing heat and energy losses. This includes insulation activities, energy recovery, measurement, control, laboratories and the like.
Renewable energy: Energy obtained from resources that naturally replenish or renew within a human lifespan (i.e. the resource is a sustainable source of energy). This includes wind, solar, aero-thermal, geothermal, hydrothermal and ocean energy, hydropower, biomass, landfill gas, sewage treatment plant gas and biogases.
- Air pollution management
e.g., greenhouse gas control technologies or management services, physical or chemical treatment technologies, air pollution modeling and mapping services
- Solid waste management
e.g., collection of waste, recycling and organics, compaction-related technologies, landfill leachate collection and containment technologies
- Wastewater management
e.g., physical or chemical treatments of industrial wastewater, mine tailing handling and treatment, biological treatments of sewage
- Protection and remediation of soil, groundwater and surface water
e.g., in situ and ex situ biological, physical, chemical, thermal treatments, containment
- Protection of biodiversity and habitat
- Noise and vibration abatement
Exclude R&D related to workers' health and safety.
- Protection against radiation
Exclude R&D related to workers' health and safety.
- Heat and energy savings and management
e.g., efficient equipment (advance insulation, high efficiency pumps or burners (Energy Star certified), etc.), energy storage technologies (flywheels, fuel cells, etc.), lighting upgrades, smart grid services and associated technologies
- Fuel efficient vehicles and transportation goods or technologies
e.g., electric and hybrid vehicles, vehicles using alternative fuels, alternative fuel retrofits on existing vehicles, low-rolling resistance tires
- Production of energy from renewable sources
e.g., equipment, services, and technologies used to produce electricity or heat from renewable sources
- Production of nuclear energy
e.g., equipment, services, and technologies used to produce electricity or heat from nuclear energy
Exclude the R&D on feedstock used to produce energy (such as uranium).
- Other environmental protection or resource management activities
Specify the other environmental protection or resource management activities
Organization status
78. In 2024, what were this organization's total expenditures within Canada?
Please report all amounts in thousands of Canadian dollars.
If precise figures are not available, please provide your best estimate.
Total expenditures represent the total budget for all operations of this organization in the fiscal period. If 'total expenditures' cannot be calculated, total funds (from members, government programs and all other sources of funds) or total revenues may be provided.
CAN$ '000
Notification of intent to extract web data
79. Does this organization have a website?
- Yes
- Specify the organization website address 1
- e.g., www.example.gc.ca
- Specify the organization website address 2
- e.g., www.example.gc.ca
- Specify the organization website address 3
- e.g., www.example.gc.ca
- No
Notification of intent to extract web data
Statistics Canada engages in web-data extraction, also known as web scraping, which is a process by which information is gathered and copied from the Web using automated scripts or robots, for retrieval and analysis. As a result, we may visit the website for this organization to search for and compile additional information. The use of web scraping is part of a broader effort to reduce the response burden on organizations, as well as produce additional statistical indicators to ensure that our data remain accurate and relevant.
We will strive to ensure that the data collection does not interfere with the functionality of the website. Any data collected will be used by Statistics Canada for statistical and research purposes only, in accordance with the agency's privacy and confidentiality mandate. All information collected by Statistics Canada is strictly protected.
More information regarding Statistics Canada's web scraping initiative.
Learn more about Statistics Canada's transparency and accountability.
If you have any questions or concerns, please contact Statistics Canada Client Services, toll-free at 1-877-949-9492 (TTY: 1-800-363-7629) or by email at infostats@statcan.gc.ca- this link will open in a new window. Additional information about this survey can be found by selecting the following link: Information for survey participants (ISP).
Changes or events
80. Indicate any changes or events that affected the reported values for this organization, compared with the last reporting period.
Select all that apply.
- Outsourcing of R&D project(s)
- Initiation of new R&D project(s)
- Completion of existing R&D project(s)
- Major change in funding of R&D project(s) (loss of funding)
- Major change in funding of R&D project(s) (increase in funding)
- Organizational change that affected R&D activities (expansion, reduction, restructuring)
- Economic change that affected R&D activities
- Lack of availability of qualified R&D personnel
- Other
Specify the other changes or events:
- No changes or events
Contact person
81. Statistics Canada may need to contact the person who completed this questionnaire for further information.
Is the provided given names and the provided family name the best person to contact?
Who is the best person to contact about this questionnaire?
- First name:
- Last name:
- Title:
- Email address:
- Telephone number (including area code):
- Extension number (if applicable):
The maximum number of characters is 5.
- Fax number (including area code):
Feedback
82. How long did it take to complete this questionnaire?
Include the time spent gathering the necessary information.
83. Do you have any comments about this questionnaire?