
Approches de microsimulation

- Introduction
- Explication par opposition à prédiction
- Modèles généraux par opposition à spécialisés
- Modèles de cohorte par opposition aux modèles de population
- Modèles de population ouvert par opposition à fermé
- Populations de départ transversales par opposition à populations synthétiques
- Temps continu par opposition à discret
- Modèles orientés cas et modèles orientés temps
Introduction
Le présent document offre une analyse de diverses approches de microsimulation qui entrent en jeu quand nous simulons des sociétés au moyen d'un ordinateur. Ces approches peuvent, à leur tour, être comparées en fonction des objectifs, de la portée et des méthodes de simulation des populations.
En ce qui concerne l'objectif, nous faisons principalement la distinction entre la prédiction et l'explication, qui s'avère être également la distinction entre les objectifs de la microsimulation empirique guidée par les données, d'une part, et la simulation orientée agents, d'autre part. L'approche de prédiction est en outre examinée sous l'angle des projections par opposition aux prévisions.
En ce qui concerne la portée d'une simulation, la comparaison porte sur deux aspects — nous commençons par faire la distinction entre les modèles généraux et les modèles spécialisés, puis entre les modèles de population et les modèles de cohorte.
Enfin, en examinant les méthodes de simulation des populations, nous axons la discussion sur trois dimensions. La première est le genre de population que nous simulons, ce qui nous permet de faire la distinction entre les modèles de population ouverts par opposition à fermés, ainsi qu'entre les populations de départ transversales par opposition à synthétiques. La deuxième est le cadre temporel utilisé, qui peut être discret ou continu. La troisième est l'ordre dans lequel les vies sont simulées, ce qui donne lieu à un modèle axé sur les cas ou un modèle axé sur le temps.
Explication par opposition à prédiction
La modélisation est une abstraction, une réduction de la complexité grâce à l'isolement des forces qui dictent les phénomènes étudiés. La quête d'une formule décrivant le comportement humain, surtout en économie, est si intense que des hypothèses excessivement simplifiées sont souvent le prix accepté pour la beauté ou l'élégance des modèles. La notion selon laquelle la beauté réside dans la simplicité se dégage même de certains modèles orientés agents. Epstein établit une analogie particulièrement intéressante entre la simulation orientée agents et les tableaux des impressionnistes français, l'un de ces tableaux (une scène de rue) figurant sur la couverture de l'ouvrage intitulé « Generative Social Sciences » (Epstein 2006). Les individus dans toute leur diversité ne sont esquissés que par quelques points, mais en regardant le tableau d'une certaine distance, nous pouvons clairement reconnaître la scène.
Les modèles statistiques et comptables peuvent‑ils rivaliser en beauté avec la naissance de phénomènes sociaux à partir d'un ensemble de règles simples? À peine — ils sont complexes et requièrent une multitude de paramètres. Si les statisticiens voient encore de l'élégance dans les fonctions de régression, la beauté est difficile à préserver quand il s'agit de produire des déclarations de revenus ou de demander des prestations de retraite. La plupart d'entre nous trouvent la comptabilité ennuyeuse et les modèles fondés sur une multitude d'équations statistiques et de règles comptables peuvent devenir rapidement difficiles à comprendre. Alors, que peuvent offrir les modèles de simulation pour compenser leur manque de beauté? La réponse est simple : leur utilité. Essentiellement, un modèle de microsimulation est utile s'il possède un pouvoir prédictif ou explicatif.
Dans une simulation orientée agent, expliquer signifie générer les phénomènes sociaux de manière ascendante, la norme de génération de l'explication étant parfaitement illustrée par le slogan : Si vous ne l'avez pas cultivé, vous ne l'avez pas expliqué (qui est considéré comme une condition nécessaire, mais non suffisante pour l'explication). Ce slogan exprime la critique de l'école de modélisation orientée agents à l'égard de l'école économique dominante, qui met l'accent sur les équilibres sans accorder beaucoup d'attention à la façon dont ces équilibres peuvent être atteints ou s'ils peuvent jamais être atteints en réalité. De nouveau, les modèles orientés agents s'appuient sur une approche ascendante pour produire une société virtuelle. Leurs points de départ sont les théories du comportement individuel exprimées dans le code informatique. L'éventail de modélisations du comportement varie donc de l'application de règles simples à une approche fondée sur les concepts de l'intelligence artificielle répartie. Dans ce dernier cas, les acteurs simulés sont des agents « intelligents » qui sont dotés de récepteurs qui leur permettent de recevoir de l'information provenant de l'environnement. Ils possèdent des capacités cognitives, des croyances et des intentions. Ils ont des objectifs, des stratégies de développement et tirent des leçons de leurs propres expériences et de celles d'autres agents. À l'heure actuelle, ce type de simulation est exécuté presque exclusivement à des fins explicatives. Leurs auteurs espèrent que les phénomènes qui se dégagent des actions et des interactions des agents dans la simulation ont leurs pendants dans les sociétés réelles. De cette façon, la simulation appuie l'élaboration de la théorie.
Le contraste de l'explication réside dans la prédiction détaillée, qui représente le principal objectif de la microsimulation guidée par les données. Si la microsimulation est conçue et utilisée de manière opérationnelle pour faire des prévisions et des recommandations stratégiques, les modèles « doivent être ancrés fermement dans une réalité empirique et les relations qu'ils contiennent devraient avoir été estimées au moyen de données réelles et éprouvées minutieusement en utilisant des méthodes statistiques et économétriques bien établies. Dans ce cas, la faisabilité d'une inférence à une population ou un processus économique réel est d'une grande importance » (Klevmarken, 1997).
Afin de prédire l'état futur d'un système, il faut aussi faire la distinction entre les projections et les prévisions. Les projections sont des prédictions de type « et si? ». Elles sont toujours « correctes », en fonction des hypothèses qui sont énoncées (à condition qu'aucune erreur de programmation ne soit commise). Par contre, les prévisions sont des tentatives en vue de prédire l'avenir le plus probable et, puisqu'il ne peut y avoir qu'un seul résultat futur réel, la plupart des prévisions s'avèrent par conséquent fausses. Dans le cas des prévisions, nous n'essayons pas simplement de trouver « ce qui arrive si » (comme dans le cas des projections); nous essayons plutôt de déterminer quelles sont les hypothèses et les scénarios les plus plausibles, donc à obtenir la prévision résultante la plus plausible. (Il convient toutefois de souligner que des hypothèses non plausibles ne sont pas nécessairement sans valeur. Les hypothèses d'état stationnaire sont des exemples d'hypothèses qui sont conceptuellement séduisantes et par conséquent très courantes, mais habituellement non plausibles. Sous ce genre d'hypothèses, les individus sont vieillis dans un monde inchangé en ce qui concerne le contexte socioéconomique, tel que la croissance économique et les politiques, et le comportement individuel est « gelé » en ne permettant pas les effets de cohorte ou de période. Puisqu'une représentation transversale de la population d'aujourd'hui ne résulte pas d'un monde en état stationnaire, le « gel » du comportement individuel et du contexte socioéconomique permet d'isoler et d'étudier de futurs phénomènes et dynamiques résultant des changements antérieurs, tels qu'un mouvement de population.)
À quel point l'explication diffère‑t‑elle de la prédiction? Pourquoi ne pouvons‑nous pas reformuler le slogan mentionné plus haut en : Si vous ne l'avez pas prévu, vous ne l'avez pas expliqué? D'abord, être capable de produire de bonnes prédictions ne signifie pas nécessairement comprendre pleinement les opérations qui sous‑tendent les processus étudiés. Nous n'avons pas besoin d'une compréhension théorique totale pour prédire que le tonnerre suivra l'éclair ou que la fécondité est plus élevée à certaines étapes du cycle de vie qu'à d'autres. Les prédictions peuvent être fondées entièrement sur les régularités et les tendances observées. En fait, la théorie est souvent sacrifiée en faveur d'un modèle très détaillé qui offre un bon ajustement aux données. Mais ce sacrifice n'est évidemment pas sans danger. Si les comportements ne sont pas modélisés explicitement, les hypothèses correspondantes ne le sont pas non plus, ce qui peut rendre les modèles difficiles à comprendre et les transformer en boîte noire. Par ailleurs, s'ils sont capables de « cultiver » certains phénomènes sociaux, les modèles orientés agents le font de manière très stylisée. Jusqu'à présent, ces modèles n'ont pas atteint un pouvoir prédictif suffisant. Parmi les adeptes de la microsimulation guidée par les données, les modèles orientés agents sont donc souvent considérés comme des jouets.
Néanmoins, quelles que soient les raisons de développer un modèle de microsimulation, les modélisateurs tireront généralement un résultat positif de l'exercice : la clarification des concepts. La modélisation du comportement requiert un niveau de précision (éventuellement transféré dans le code informatique) que l'on ne trouve habituellement pas en sciences sociales où abondent les théories purement descriptives. Nous pouvons affirmer sans trop nous avancer que la modélisation proprement dite fournit des éclaircissements sur les processus qui sont modélisés (p. ex.Burch 1999). Si certains de ces avantages se dégagent de toute modélisation statistique, la simulation accroît les possibilités. En exécutant un modèle de simulation, nous obtenons toujours des éclaircissements sur la réalité que nous essayons de simuler ainsi que sur le fonctionnement de nos modèles et les conséquences de nos hypothèses de modélisation. En ce sens, les modèles de microsimulation sont toujours des outils exploratoires, que leur objectif principal soit l'explication ou la prédiction. Autrement dit, les modèles de microsimulation fournissent des plateformes expérimentales aux sociétés au sein desquelles, par nature, la possibilité d'expériences vraiment naturelles est limitée.
Modèles généraux par opposition à spécialisés
Le développement de modèles de microsimulation à grande échelle requiert habituellement un investissement initial considérable, surtout dans le cas de la simulation de politiques. Même si nous ne voulons simuler qu'une politique particulière, nous devons créer une population et modéliser les changements démographiques avant de pouvoir ajouter le comportement économique et les routines comptables nécessaires pour l'étude. Nous pouvons arriver ainsi à une situation où il devient plus logique de concevoir des modèles de microsimulation d'« usage général », et d'attirer ainsi des investisseurs prospectifs provenant de divers domaines. Un modèle capable de produire des projections détaillées des prestations de retraite pourrait facilement être étendu à d'autres domaines d'avantages fiscaux. Un modèle dans lequel sont incluses les structures familiales pourrait être étendu à la simulation de la prestation de soins non officiels. Une lutte pour survivre peut même aboutir à des applications assez exotiques — par exemple, l'un des plus grands modèles, le modèle CORSIM des États‑Unis, a survécu à des difficultés financières grâce à une subvention offerte par une association de dentistes qui s'intéressait à la projection des futures demandes de prothèses dentaires.
Par conséquent, il n'est pas étonnant de constater une tendance générale à planifier et à développer les applications de microsimulation sous forme de modèles polyvalents généraux dès le début. En fait, de grands modèles généraux existent à l'heure actuelle pour de nombreux pays, comme l'illustre le tableau qui suit.
| Pays | Modèle |
|---|---|
| Australie: | APPSIM, DYNAMOD |
| Canada: | DYNACAN, LifePaths |
| France: | DESTINIE |
| Norvège: | MOSART |
| Suède: | SESIM, SVERIGE |
| Royaume-Uni: | SAGEMOD |
| États-Unis: | CORSIM |
Durant la création de modèles généraux, le contrôle des ambitions et la modularité de la conception sont deux facteurs essentiels de réussite. Quelques‑uns seulement des grands modèles d'aujourd'hui ont effectivement atteint et retenu leur taille initiale prévue. Les approches excessivement ambitieuses ont dû être corrigées par des simplifications importantes, comme cela a été le cas de DYNAMOD, qui était prévu au départ comme un modèle micro‑macro intégré.
Les modèles de microsimulation spécialisés sont axés sur quelques comportements et (ou) segments de population particuliers. Le modèle de soins de longue durée du NCCSU en est un exemple (Hancock et coll., 2006). Ce modèle simule les revenus et les avoirs de futures cohortes de personnes âgées et leur capacité à participer aux frais de soins à domicile. Par conséquent, il porte sur la simulation de l'examen des ressources pour les politiques relatives aux soins de longue durée, dont les résultats sont entrés dans un macromodèle des demandes et coûts futurs.
Il est également arrivé que des modèles assez spécialisés au départ finissent par devenir plus généraux. Cela s'est produit dans le cas du SESIM et de LifePaths, qui ont tous deux été développés au départ pour l'étude des prêts aux étudiants. LifePaths est un exemple particulièrement intéressant, parce qu'il est non seulement devenu un grand modèle général, mais aussi parce qu'il a servi de fondement, dans une version simplifiée, à la création d'une famille distincte de modèles spécialisés de la santé (modèles Pohem de Statistique Canada).
Modèles de cohorte par opposition aux modèles de population
Comparativement aux modèles généraux de population, les modèles de cohorte sont spécialisés, puisqu'ils ne simulent qu'un seul segment de population, à savoir une cohorte de naissances. Cette simplification est utile si nous désirons étudier une seule cohorte ou comparer deux cohortes.
Les études économiques de cohorte unique portent habituellement sur le revenu et les effets de redistribution du régime d'avantages fiscaux au long de la trajectoire de vie. Les modèles HARDING et LIFEMOD développés en parallèle, le premier pour l'Australie et le second, pour la Grande‑Bretagne (Falkingham et Harding 1996) en sont des exemples. En général, ce genre de modèle repose sur l'hypothèse d'un univers en équilibre; autrement dit, la cohorte HARDING est née en 1960 et vit dans un univers qui ressemble à l'Australie en 1986.
Les modèles de population ont trait à l'ensemble de la population plutôt qu'à des cohortes particulières. Naturellement, la simulation de l'ensemble de la population élimine plusieurs limites des modèles de cohorte, y compris les problèmes d'évolution démographique et de distribution entre les cohortes (tel que l'équité intergénérationnelle).
Modèles de population ouvert par opposition à fermé
À l'échelle planétaire, la population humaine est fermée. Tout individu est né et mourra sur la planète, possède des parents biologiques nés sur la planète et interagit avec d'autres humains avec lesquels il partage ces mêmes traits. Par contre, il n'en est plus ainsi si l'on se concentre sur la population d'une région ou d'un pays particulier. Les gens migrent entre les régions, forment des partenariats avec des personnes provenant d'autres régions, etc. Dans de telles conditions, nous avons affaire à des populations ouvertes. Par conséquent, dans un modèle de simulation dans lequel nous ne sommes presque jamais intéressés par la modélisation de l'ensemble de la population mondiale, comment pouvons‑nous régler ce problème?
La solution requiert habituellement un certain degré de créativité. Ainsi, si nous permettons l'immigration, nous aurons toujours le problème de devoir trouver le moyen de modéliser un pays particulier sans modéliser le reste du monde. En ce qui concerne l'immigration, de nombreuses approches ont été adoptées, allant du clonage de « nouveaux immigrants » existants à l'échantillonnage à partir d'une population hôte, voire même à partir de divers « bassins » de populations hôtes représentant différentes régions
Un exercice conceptuellement plus exigeant est la simulation de l'appariement de partenaires. En microsimulation, les termes population fermée et population ouverte correspondent habituellement au fait que l'appariement des conjoints est limité aux personnes à l'intérieur de la population (fermée) ou que les conjoints sont « créés sur demande » (ouverte). Lorsque nous modélisons une population fermée, le problème est que nous ne simulons habituellement qu'un échantillon d'une population et non la population entière d'un pays. Si notre échantillon est trop petit, il est peu probable que nous trouverons des appariements raisonnables dans l'échantillon simulé. Il en est particulièrement ainsi si la géographie est également un facteur important dans notre modèle. Par exemple, si l'échantillon ne contient pas beaucoup d'individus représentant la population d'une petite ville, très peu d'entre eux trouveront un partenaire vivant à une distance raisonnable.
Les principaux avantages des modèles fermés tiennent au fait qu'ils permettent de suivre les réseaux de parenté et qu'ils donnent lieu à une plus grande cohérence (en supposant que la population est suffisamment grande pour trouver des appariements appropriés). En revanche, les principaux inconvénients des modèles fermés sont les problèmes d'échantillonnage et l'intensité des calculs associés à l'appariement des partenaires. Dans une population de départ tirée d'un échantillon, le modèle n'est pas nécessairement équilibré en ce qui concerne les liens de parenté autres que ceux entre conjoints, puisque les parents et la fratrie d'une personne ne sont pas inclus dans la population de base s'ils ne vivent pas dans le même ménage (Toder et coll. 2000).
La modélisation de populations ouvertes nécessite une certaine abstraction. Ici, les partenaires sont créés sur demande — avec des caractéristiques produites synthétiquement ou échantillonnées à partir d'une population hôte — et sont traités davantage comme des attributs d'un individu « dominant » que comme des individus « à part entière ». Bien que leurs trajectoires de vie (ou certains aspects présentant un intérêt pour la simulation de l'individu dominant) soient simulées, ils ne sont pas personnellement pris en compte comme des individus dans une sortie de données agrégées.
Populations de départ transversales par opposition à populations synthétiques
Chaque modèle de microsimulation doit commencer à un certain point dans le temps, si bien qu'il est nécessaire d'obtenir une population de départ. Dans les modèles de population, nous pouvons distinguer deux types : transversale et synthétique. Dans le premier cas, nous tirons une population de départ d'un ensemble de données transversales, puis nous vieillissons tous les individus à partir de ce moment‑là jusqu'à leur décès (en ajoutant évidemment de nouveaux individus aux événements de naissance). Dans le second cas, nous suivons une approche habituellement adoptée également dans les modèles de cohorte — tous les individus sont modélisés de leur naissance jusqu'à la fin de leur vie.
Si nous ne nous intéressons qu'à l'avenir, pourquoi partirions‑nous d'une population synthétique qui nous obligerait à simuler le passer également? Certes, partir d'un ensemble de données transversales peut être plus simple. Quand nous partons de « données réelles » représentatives, nous ne devons pas produire rétrospectivement une population, ce qui signifie que nous n'avons pas besoin de données historiques pour modéliser le comportement passé. Nous ne devons pas non plus nous préoccuper de problèmes de cohérence, puisque les simulations à partir de populations synthétiques manquent habituellement de cohérence transversale complète.
Malheureusement, de nombreuses applications de microsimulation nécessitent au moins une certaine information biographique qui n'est pas disponible dans les ensembles de données transversaux. Par exemple, les antécédents d'emploi et de cotisations déterminent les futures pensions. Par conséquent, une certaine modélisation rétrospective ou historique sera généralement nécessaire dans la plupart des applications de microsimulation.
Un moyen d'éviter d'utiliser une population de départ synthétique quand une simulation historique est, en fait, nécessaire pourrait consister à partir d'une ancienne enquête. Cette idée a été suivie dans le modèle CORSIM qui a utilisé une population de départ provenant d'une enquête réalisée en 1960 (ce qui fait également de ce modèle un sujet d'étude intéressant en soi). Bien que la possibilité qui s'ensuit de créer des prévisions rétrospectives peut faciliter l'évaluation de la qualité du modèle comparativement à la réalité, ce genre d'approche pose néanmoins des problèmes. CORSIM fait un usage intensif de méthodes d'alignement pour rajuster ses prévisions rétrospectives d'après les données publiées. Même si de nombreux résultats par groupe et de résultats agrégés peuvent être alignés exactement avec les données récentes, il n'existe aucun moyen de s'assurer que les distributions conjointes fondées sur les données de 1960 sont encore exactes après plusieurs décennies.
Dans le cas de la création d'une population de départ synthétique, toutes les données sont imputées. Nous avons donc besoin de modèles de comportement individuels remontant à un siècle complet. Bien que cette approche soit exigeante, elle a des avantages. Premièrement, la taille de la population n'est pas limitée par une enquête; nous pouvons créer des populations plus grandes, donc réduire la variabilité Monte Carlo. Deuxièmement, le fait que la population est synthétique permet d'éviter les conflits relatifs à la confidentialité. (Statistique Canada suit cette approche dans son modèle LifePaths.) Dans l'ensemble, plus la quantité d'information passée qui doit être imputée est grande et plus l'information passée joue un rôle important dans ce que l'application essaye de prédire ou d'expliquer, plus l'approche d'une population de départ synthétique devient attrayante. Par exemple, Wachter (Wachter 1995) a simulé les réseaux de parenté de la population américaine selon une approche fondée sur une population de départ synthétique remontant jusqu'au début du XIXe siècle. Ce genre d'information détaillée sur les liens de parenté ne se trouve dans aucune enquête et ne peut donc être construite qu'au moyen d'une microsimulation.
Temps continu par opposition à discret
La distinction entre les modèles peut se fonder sur le cadre temporel, qui peut être continu ou discret. Un cadre de temps continu est habituellement associé aux modèles statistiques de durée d'un événement, selon une approche fondée sur les risques concurrents. À partir d'un point de départ fixe, un processus aléatoire produit les durées de tous les événements pris en considération, l'événement dont la survenue est la plus rapprochée du point de départ étant celui qui est exécuté, tandis que les autres sont censurés. Ensuite, la procédure complète est répétée en prenant cet événement comme nouveau point de départ et le cycle se poursuit jusqu'à ce qu'ait lieu l'événement de « décès » de l'individu simulé.
La figure 1 illustre l'évolution d'une trajectoire de vie simulée dans un modèle en temps continu. Au départ, il existe trois événements (E1, E2, E3) possédant chacun une durée générée aléatoirement. Dans l'exemple, E1 survient le premier, de sorte qu'il devient l'événement qui est exécuté; après cela, les durées pour les trois événements sont « redéterminées ». Cependant, comme E3 n'est pas défini comme étant conditionnel à la survenue de E1 dans l'exemple, sa durée ne change pas, tandis que de nouvelles durées sont produites pour E1 et E2. E3 finit par avoir la durée la plus courte suivante, de sorte qu'il est le suivant à être exécuté. Ensuite les durées sont de nouveau générées pour les trois éléments et le cycle continue.
Figure 1 : Évolution d'une trajectoire de vie simulée
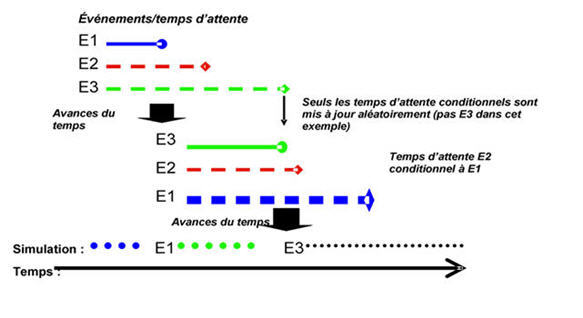
Techniquement, les modèles en temps continu sont très commodes, parce qu'ils permettent d'ajouter de nouveaux processus sans changer les modèles des processus existants à condition que les exigences statistiques pour les modèles à risques concurrents soient satisfaites (voir Galler 1997 pour une description des problèmes connexes).
Néanmoins, la modélisation en temps continu n'implique pas automatiquement qu'il n'existe pas d'événements en temps discret (horloge). Des événements en temps discret peuvent survenir en cas d'introduction de covariables variant en fonction du temps, tels que les indices économiques mis à jour périodiquement (p. ex.chômage) ou les variables de flux (p. ex.revenu personnel). La mise à jour périodique des indices censure alors tous les autres processus à chaque étape temporelle périodique. Si les périodes d'interruption sont si brèves (p. ex.un jour) que le nombre maximal d'autres événements durant une période devient presque égal à un, le modèle a convergé vers un modèle en temps discret.
Les modèles en temps discret déterminent les états et les transitions pour chaque période, sans tenir compte des points temporels exacts dans l'intervalle. L'hypothèse est que les événements ne surviennent qu'une fois durant une période. Comme plusieurs événements peuvent avoir lieu durant une période de temps discret, il faut soit utiliser des périodes courtes pour éviter la survenue de multiples événements ou modéliser toutes les combinaisons possibles d'événements uniques en tant qu'événements proprement dit. Les cadres de temps discret sont utilisés dans la plupart des modèles dynamiques des avantages fiscaux, les plus anciens utilisant habituellement un cadre annuel, principalement à cause de contraintes informatiques. Toutefois, étant donné l'accroissement de la puissance informatique et la réduction de son coût au cours du temps, nous pouvons nous attendre à ce que des étapes de temps plus courtes prédominent dans les futurs modèles. Quand les périodes deviennent si courtes que nous pouvons presque exclure la possibilité d'événements multiples, nous avons atteint une « pseudo‑continuité ». Le cas échéant, nous pouvons même utiliser des modèles de durée statistique. Le modèle australien DYNAMOD est un exemple de combinaison des deux approches.
Modèles orientés cas et modèles orientés temps
La distinction entre les modèles orientés cas et ceux orientés temps tient à l'ordre dans lequel les vies des individus sont simulées. Dans les premiers, un cas est simulé de la naissance au décès avant que la simulation du cas suivant débute. Les cas peuvent être des personnes individuelles ou une personne ainsi que toutes les personnes « non dominantes » qui ont été créées sur demande pour cette personne. Dans les seconds, toutes les vies ayant trait à un cas particulier sont simulées simultanément au cours du temps.
La modélisation orientée cas n'est possible que s'il n'y a pas d'interaction entre les cas. Les interactions sont limitées aux personnes appartenant à un cas, ce qui restreint considérablement ce qui peut être modélisé. L'avantage de ce genre de modèle est de nature technique — puisque chaque cas est simulé indépendamment des autres, il est plus facile de répartir la tâche globale de simulation entre plusieurs ordinateurs. En outre, la mémoire peut être libérée après que chaque cas a été simulé, puisque l'information sous‑jacente ne doit pas être sauvegardée en prévision d'une utilisation future. (Les modèles orientés cas peuvent être utilisés avec des modèles de populations ouvertes, mais non des modèles de populations fermées.)
Dans les modèles orientés temps, tous les individus sont simulés simultanément au cours d'une période prédéfinie. Comme tous les individus vieillissent simultanément (par opposition aux individus d'un cas seulement), la demande de ressources informatiques augmente définitivement. Dans un cadre en temps continu, l'événement suivant qui a lieu est le premier événement planifié au sein de la population entière. Donc, la puissance informatique peut encore être un goulet d'étranglement dans ce genre de simulation — les modèles utilisés à l'heure actuelle ont habituellement des tailles de population inférieures à un million.
- Date de modification :