
Guide de l’utilisateur
Fichiers de microdonnées 2010 et 2009–2010
Juin 2011
Quoi de neuf dans l’enquete sue la sante dans les collectivites canadiennes 2010?
1.0 Introduction
2.0 Historique
3.0 Remaniement de l’ESCC en 2007
4.0 Contenu de l’ESCC
5.0 Plan d’échantillonnage
6.0 Collecte des données
7.0 Traitement des données
8.0 Pondération
9.0 Qualité des données
10.0 Lignes directrices pour la totalisation, l’analyse et la diffusion
11.0 Tableaux de la variabilité d’échantillonnage approximative
12.0 Fichiers de microdonnées : description, accès et utilisation
Annexe A – Contenu de l’enquete sur la sante dans les collectivites canadiennes (2009–2010)
Annexe B – Selection du contenu optionnel par province et territoire (2010 et 2009–2010)
Annexe C – Geographie disponible sur le fichier maitre et de partage et codes correspondants : Canada, provinces/territoires, regions/territoires, regions sociosanitaires et groupes homologues
Annexe D – (2010) – Repartition de l’echantillon par resion sociosanitaire et par base de sondage de l’ESCC et repartition par reseau local d’reseau local d’integration des services de sante (RLISS) et par base de sonage de l’ESCC en ontario
Annexe E – (2010) – Taux de reponse par region sociosanitaire et par base de dondage de l’ESCC et taux de reponse par reseau local d’integration des services de sante (RLISS) et par base de sondage de l’ESCC en ontario
Annexe F – (2009–2010) – Repartition de l’echantillon par resion sociosanitaire et par base de sondage de l’ESCC
Annexe G – (2009–2010) – Taux de reponse par region sociosanitaire et par base de sondage de l’ESCC et taux de reponse par reseau local d’integration des services de sante (RLISS) et par base de sondage de l’ESCC en ontario
Quoi de neuf dans l’enquete sur la santé dans les collectivites canadiennes 2010?
Contenu
Quelques changements de contenu ont été fait à au contenu de l’Enquête sur la santé dans les collectivités canadiennes (ESCC) de 2010. De plus, des nouveaux modules ont été ajoutés au contenu commun annuel de 2010.
Changements
- Contact avec certains professionnels de la santé (CHP). Ce module a été retiré du contenu commun annuel pour faire partie du contenu commun 1 an de 2010 seulement.
- Besoins de santé non comblés (UCN) Ce module a été réintroduit dans l’enquête de 2010 dans le contenu commun 1 an après avoir été suspendu depuis 2007. Bien que le nom du module soit nouveau, les questions faisaient partie du module d’Utilisation des soins de santé (HCU).
- Deux sous-modules incluant les trois conditions chroniques suivantes ont été inclus dans le module des Conditions Chroniques (CCC) : Syndrome de fatigue chronique et agresseurs chimiques et fibromyalgie. Les questions au sujet de ces 3 conditions chroniques avaient été demandées pour la dernière fois dans l’ESCC de 2005.
Nouveaux modules
- Perte de productivité (LOP): Ce module a été développé pour remplacer celui sur les Incapacités des deux dernières semaines (TWD).
- Conditions neurologiques (NEU): Ce module a été introduit en 2010 comme contenu commun 1 an et sera répété comme tel en 2011. Les répondants ou des personnes de leur ménage identifies comme ayant une condition neurologique seront recontactés pour une enquête de suivi sur les conditions neurologiques au Canada.
- Vaccin contre la grippe H1N1 (H1N): Ce nouveau module a recueilli l’information à savoir si le répondant a reçu ou non le vaccin contre la grippe H1N1 au cours des 12 derniers mois.
Méthodologie
- L’échantillon de ménages de l’ESCC 2010 a été sélectionné à partir de trois bases de sondage : 49,5% de l’échantillon de ménages provenait d’une base de sondage aréolaire, 49,5 % provenait d’une base liste de numéros de téléphone et 1 % provenait d’une base de sondage à composition aléatoire (CA). Cependant, pour les deux dernières périodes de collecte de 2010, 40,5% provenait de la base aréolaire, 58,5% de la base liste et 1% de la base CA.
- À partir des fichiers de 2010 et 2009-2010, les comptes de projection de la population sont basés sur les comptes de la population du recensement de 2006. Ces comptes sont utilisés pour s’assurer que les poids de l’ESCC et les estimations produites sont en ligne avec des comptes totaux connus de la population. Avant 2010, les comptes du recensement de la population de 2001 étaient utilisés. Des évaluations ont confirmé que l’impact de ce changement sur les estimations de l’ESCC devrait être minime.
Collecte
- En 2009, les intervieweurs ont dû obtenir l’autorisation verbale des parents ou tuteurs pour interviewer des répondants sélectionnés âgés de 12 à 15 ans. En 2010, le bloc du consentement parental (PGC) a été ajouté aux applications. L’ajout de ce bloc officialise le processus consistant à demander au parent ou tuteur (s’il existe un parent ou tuteur dans le ménage) d’un jeune de 12 à 15 ans la permission pour que celui ci participe à l’enquête. Les intervieweurs ont fait appel à plusieurs procédures pour atténuer les éventuelles inquiétudes des parents et mener à terme les interviews.
- Avant 2010, les interviewers recevaient les instructions de demander les questions concernant tout le ménage à la personne la mieux renseignée sur le ménage. En 2010, un module formel a été introduit dans l’application de l’enquête pour faire la transition entre le répondant âgé de 12 à 15 ans à la personne la mieux renseignée à propos du ménage. Les renseignements au niveau du ménage qui sont demandés à la fin de l’enquête (Mesures de sécurité à la maison, Couverture d’assurance, sécurité alimentaire, Problèmes neurologiques, Éducation, Revenu et renseignements administratifs) sont maintenant répondus par la personne qui connaît le mieux le ménage.
Géographie
- En 2010, la définition des régions sociosanitaires (RS) en Alberta a été modifiée entre l’étape d’échantillonnage et la création des fichiers de données. Il y a maintenant 5 RS en Alberta, qui sont des regroupements des 9 RS qui étaient définies lors de l’échantillonnage. Le nombre total de RS est donc passé de 121 à 117 en 2010.
1.0 Introduction
L’Enquête sur la santé dans les collectivités canadiennes (ESCC) est une enquête transversale qui vise à recueillir des renseignements sur l’état de santé, l’utilisation des services de santé et les déterminants de la santé de la population canadienne. Elle est réalisée auprès d’un grand échantillon de répondants et conçue pour fournir des estimations fiables à l’échelle de la région sociosanitaire. En 2007, des changements importants ont été apportés à la conception de l’ESCC. Les données sont dorénavant recueillies sur une base continue et leur diffusion est prévue chaque année, plutôt que chaque deux ans comme c’était le cas avant 2007. Les objectifs de l’enquête ont été révisés. Ces objectifs sont :
- soutenir les programmes de surveillance en santé en produisant des données sur la santé à l’échelle nationale, provinciale et infraprovinciale;
- offrir une source unique de renseignements pour la recherche sur la santé de petites populations et sur des caractéristiques rares;
- diffuser de l’information facilement accessible à une communauté diversifiée d’utilisateurs dans un temps opportun; et
- proposer un instrument d’enquête flexible qui inclut une option de réponse rapide pour répondre à des questions émergentes liées à la santé de la population.
Les autres changements qui ont découlé du remaniement sont détaillés à la section 3.
Les données de l’ESCC sont toujours recueillies auprès de personnes âgées de 12 ans et plus vivant dans des logements privés dans 117 régions sociosanitaires couvrant toutes les provinces et les territoires. Sont exclues de la base de sondage les personnes vivant sur les réserves indiennes et les terres de la Couronne, les résidents des établissements, les membres à temps plein des Forces canadiennes et les personnes vivant dans certaines régions éloignées. L’ESCC couvre environ 98 % de la population canadienne âgée de 12 ans et plus
Le présent document a pour but de faciliter la manipulation des fichiers de microdonnées de l’ESCC et de décrire la méthodologie utilisée. L’enquête produit 3 types de fichiers de microdonnées : des fichiers maîtres, des fichiers de partage et des fichiers de microdonnées à grande diffusion (FMGD). Les caractéristiques de chacun de ces fichiers sont présentées dans ce guide. Les données du FMGD, dont la diffusion est bisannuelle, couvrent deux années. Le prochain FMGD, qui contiendra les données recueillies pour les années 2009 et 2010, sera diffusé en septembre 2011.
Pour toute question concernant les ensembles de données ou leur utilisation, s’adresser à:
Service d’aide aux utilisateurs des produits électroniques : 1 (800) 949–9491
Totalisations spéciales ou renseignements généraux sur les données :
Services personnalisés à la clientèle
Division de la statistique de la santé : (613) 951–1746
Courriel : hd–ds@statcan.gc.ca
Renseignements sur le télé-accès :
Division de la statistique de la santé : (613) 951–1746
Courriel : cchs–escc@statcan.gc.ca
Télécopieur : (613) 951–0792
2.0 Historique
En 1991, le Groupe de travail national sur l’information en matière de santé a relevé plusieurs questions et problèmes posés par le système d’information sur la santé. Selon ses membres, les données étaient fragmentées, elles étaient incomplètes, elles ne pouvaient être partagées facilement et elles n’étaient pas analysées aussi pleinement que possible; en outre, les résultats des études réalisées n’atteignaient pas de façon régulière la population canadienne1.
Pour résoudre ces problèmes, l’Institut canadien d’information sur la santé (ICIS), Statistique Canada et Santé Canada ont conjugué leurs efforts en vue de créer un Carnet de route de l’information sur la santé. L’Enquête sur la santé dans les collectivités canadiennes (ESCC) a été conçue à partir de ce mandat. Le format, le contenu et les objectifs de l’enquête ont été définis après avoir mené des consultations approfondies auprès de spécialistes et d’intervenants fédéraux, provinciaux et de régions sociosanitaires communautaires en vue de déterminer leurs exigences en matière de données2.
Afin de remplir les nombreux besoins en données, le cycle de collecte des données de l’ESCC s’étendait sur deux années. Jusqu’au remaniement de 2007, la première année du cycle, indiquée par la notation «.1», correspondait à une enquête générale sur la santé de la population conçue pour fournir des estimations fiables à l’échelle de la région sociosanitaire. La deuxième année du cycle, représentée par la notation «.2», avait un plus petit échantillon et était conçue pour fournir des données à l’échelle provinciale sur des sujets particuliers ayant trait à la santé.
Nouvelles désignations des Cycles .1 et .2
À partir de 2007, la composante régionale du programme de l’ESCC est dorénavant collectée sur une base continue. Pour éviter toute confusion avec les enquêtes de santé thématiques, les deux composantes ont cessé d’utiliser les notations «.1» et «.2» pour se distinguer entre elles. Dorénavant, on désigne les cycles x.1 de l’ESCC comme «la composante annuelle» de l’ESCC. Le titre au long est « Enquête sur la santé dans les collectivités canadiennes – Composante annuelle, 2009 » et le titre abrégé est simplement « ESCC – 2009 ». La composante thématique de l’enquête demeure, quant à elle, inchangée. Elle continuera d’explorer plus en profondeur des sujets ou des populations plus précises. On la désignera par le nom de l’enquête suivi du sujet des thèmes couverts par chacune des enquêtes (par exemple, «Enquête sur la santé dans les collectivités canadiennes portant sur le vieillissement en santé » ou « ESCC – Vieillissement en santé ».
3.0 Remaniement de l’ESCC en 2007
Jusqu’en 2005, les données de l’ ESCC étaient recueillies à chaque deux ans sur une période annuelle et diffusées aux deux ans, environ 6 mois après la fin de la collecte. Le remaniement de l’ESCC de 2007 visait deux principaux points: mieux répondre aux besoins des partenaires qui désiraient augmenter le contenu de l’enquête et la fréquence des diffusions de données et assurer une meilleure utilisation des ressources opérationnelles. C’est ainsi que des changements à la conception de l’ESCC ont été proposés de manière à augmenter l’efficacité et la flexibilité de l’enquête par une collecte des données sur une base continue.
Des consultations approfondies ont été menées d’un bout à l’autre du Canada auprès de spécialistes et intervenants fédéraux, provinciaux et de régions sociosanitaires. Elles visaient à recueillir les commentaires sur les changements proposés ainsi qu’à recueillir des renseignements détaillés sur les besoins en données et produits de données des divers partenaires.
Les principaux changements qui ont découlé du remaniement de l’ESCC sont les suivants:
- Dans le passé, les données de l’ESCC étaient collectées auprès de 130 000 répondants sur une période de 12 mois. Dorénavant, la collecte de données se déroule sur une base continue. L’échantillon, qui préserve la même taille, est réparti en 12 période de collecte de 2 mois chacune. Chacune des périodes de collecte est représentative de la population vivant dans les 10 provinces canadiennes au cours des deux mois. Pour des raisons opérationnelles, l’échantillon dans les territoires est représentatif de leur population après 12 mois.
- La composante de contenu commun a été scindée en trois : le contenu commun annuel (auparavant le « contenu de base »), le contenu commun un an qui couvre un an de collecte et le contenu commun deux ans qui couvre deux ans de collecte (auparavant le « contenu thématique »). Demandé pour une année, le contenu commun un an est réintroduit tous les deux ou quatre ans. Demandé pour deux années, le contenu commun deux ans, couvrant deux années, est réintroduit tous les quatre ans. L’un et l’autre ont été créés pour tirer profit de l’approche de collecte continue. La durée de collecte des données de cette composante peut être adaptée selon la prévalence des estimations et le niveau géographique désirés. Le contenu commun annuel demeure relativement stable dans le temps. À la discrétion des provinces et des régions, le contenu optionnel peut aussi être modifié sur une base annuelle, plutôt que tous les deux ans.
- Les changements à la collecte et au contenu ont inévitablement un impact sur la stratégie de diffusion. Dans le passé, les données étaient diffusées à tous les deux ans. Depuis 2008, les données de l’ESCC sont diffusées sur une base annuelle. À tous les deux ans, un fichier regroupant l’échantillon des deux années (taille de 130 000) est également produit. En plus des ces fichiers réguliers, d’autres fichiers spéciaux seront rendus disponibles lorsque du contenu supplémentaire aura été recueilli pendant des périodes de collecte qui ne correspondent pas aux périodes annuelles standard, c’est-à-dire de janvier à décembre.
- La collecte annuelle de données est divisée en 6 périodes de 2 mois. Contrairement à ce qui se faisait avant, ces périodes ne se chevauchent plus, ce qui permet d’assurer une surveillance plus efficace de la collecte et d’effectuer au besoin des modifications à l’interface de collecte à tous les deux mois.
4.0 Contenu de l’ESCC
En plus de données sociodémographiques et administratives, le contenu de l’ESCC comporte trois composantes qui répondent chacune à des besoins différents: la composante de contenu commun inclut le contenu commun annuel, le contenu d’un an et le contenu deux ans, la composante de contenu optionnel et la composante de réponse rapide. L’annexe A présente la liste des modules qui ont été inclus dans le questionnaire de 2009 et 2010 selon leur composante.
La durée moyenne d’une entrevue de l’ESCC est estimée entre 40 et 45 minutes.
| Composante de l’ ESCC | Durée moyenne |
|---|---|
Contenu commun
|
30 minutes (20 minutes) (10 minutes) |
| Contenu optionnel | 10 minutes |
| Contenu de réponse rapide (facultatif) | 2 minutes |
4.1 Contenu commun
La composante de contenu commun de l’ESCC comprend des questions qui sont demandées aux répondants de toutes les provinces et territoires (à moins d’exception). Cette composante est scindée en trois : le contenu commun annuel, le contenu commun un an et le contenu commun deux ans.
Le contenu commun annuel inclut des questions qui sont demandées à tous les répondants. Ces questions demeureront relativement stables dans le questionnaire pour une période d’environ six ans, à moins qu’un enjeu majeur soit soulevé concernant la qualité des données.
Le contenu commun un an et deux ans (auparavant appelé « contenu thématique ») comprennent des questions se rapportant à un sujet particulier. Combinés, ils comptent pour 10 minutes de l’entrevue. Les modules comportant ce type de contenu pourraient être réintroduits dans l’enquête tous les deux, quatre ou six ans, au besoin. Ceci permet une meilleure planification du contenu de l’ESCC à moyen terme.
Certains modules inclus dans le contenu commun un an peuvent être demandés à un sous-échantillon de répondants si l’objectif de ces questions est de fournir des estimations fiables à l’échelle nationale ou provinciale, plutôt qu’à l’échelle de la région sociosanitaire. Cette approche est utilisée dans le but de minimiser le fardeau de réponse et les coûts qui s’y rattachent.
4.2 Contenu optionnel
La composante de contenu optionnel offre aux régions sociosanitaires de choisir du contenu qui répond aux priorités provinciales et régionales en matière de santé publique. Le contenu optionnel est sélectionné à partir d’une longue liste de modules disponibles pour inclusion dans l’ESCC. Les modules de contenu choisis par une région ne sont demandés qu’aux résidants des régions qui ont sélectionné ces modules. En réalité, depuis 2005 (cycle 3.1), les régions et les provinces ont choisi de coordonner la sélection du contenu optionnel de manière à uniformiser la sélection des modules optionnels à l’échelle provinciale. Le contenu optionnel peut varier d’une année à l’autre selon les besoins et doit être revu chaque deux ans.
Il convient de mentionner que contrairement au contenu commun, les données provenant des modules de contenu optionnel ne peuvent être généralisées à l’échelle du Canada3.
L’annexe B présente les résultats de la sélection du contenu optionnel pour l’année en cours selon la province de résidence.
4.3 Contenu de réponse rapide
La composante de réponse rapide est offerte contre recouvrement des coûts aux organisations désirant obtenir des estimations nationales sur un sujet émergent ou particulier lié à la santé de la population. La réponse rapide est formée d’un maximum de deux minutes de contenu. Les questions apparaissent au questionnaire pendant une seule période de collecte (deux mois) et sont demandées à tous les répondants de l’ESCC au cours de cette période.
4.4 Contenu des fichiers de microdonnées
Différents fichiers de données sont produits à partir des données de l’enquête :
- période de référence d’un an;
- période de référence de deux ans;
- sous-échantillon d’un an.
Le tableau 4.2 fournit des précisions concernant la disponibilité du contenu dans les fichiers de, 2009.
Fichiers à période de référence d’un an
L’enquête produit des fichiers tous les ans. En juin 2011, un fichier dont la période de référence est 2010 a été diffusé. Il contient les répondants de la collecte de 2010 ainsi que les variables du contenu commun annuel, celles du contenu commun un an, celles du contenu commun de deux ans et du contenu optionnel.
Fichier à période de référence de deux ans
Chaque deux ans, un fichier combinant les deux années les plus récentes de données est également diffusé. En juin 2011, un fichier combiné estaussidiffusé en juin 2011 contient les données de 2009 et de 2010. C’est en 2013 qu’est prévue la diffusion du fichier des deux années suivantes, à savoir les années de référence 2011 et 2012.
Le fichier de deux ans inclut tous les répondants ainsi que l’ensemble des questions qui sont demeurées dans l’enquête au cours de cette période. À moins d’exception, il s’agit de la composante des questions du contenu commun annuel, deux ans et le contenu optionnel choisi pour deux ans. Le contenu commun un an et le contenu optionnel choisi pour une année seulement ne sont pas disponibles dans le fichier de données de deux ans.
Fichiers de sous-échantillons d’un an
Les modules collectés auprès d’un sous-échantillon de la population continueront d’être diffusés dans des fichiers séparés. Ces derniers incluent le contenu commun annuel et un an collectés auprès d’un sous-échantillon de répondants.
| Année | Modules |
|---|---|
| 2000 | Temps d’attente et Accès aux services de soins de santé |
| 2003 | Visites chez le dentiste, Conduite et sécurité, Indice de l’état de santé, Médicaments, Santé buccale 2 |
| 2005 | Temps d’attente et Accès aux services de soins de santé, Satisfaction des patients à l’égard des services de soins de santé, Indice de l’état de santé, Taille et poids mesurés, Consommation de fruits et légumes, Population active – formulaire long |
| 2007 | Temps d’attente et Accès aux services de soins de santé, Satisfaction des patients à l’égard des services de soins de santé |
| 2008 | Taille et poids mesurés |
| 2009 | Temps d’attente et Accès aux services de soins de santé |
| Fichiers | Contenu commun annuel |
Contenu commun un an de 20091 | Contenu commun un an de 20102 | Contenu commun deux ans de 2009–2010 | Contenu optionnel3 | |
|---|---|---|---|---|---|---|
| 2009 | Principal Sous-échantillon (2 modules) |
Oui Oui |
Non Oui |
S/O S/O |
Oui Non |
Oui Non |
| 2010 | Principal | Oui | S/O | Oui | Oui | Oui |
| 2009–2010 | Principal | Oui | Non | Non | Oui | Oui |
|
||||||
5.0 Plan d’échantillonnage
5.1 Population cible
L’ESCC vise la population de 12 ans et plus vivant à domicile et résidant dans les dix provinces et trois territoires. Sont exclues du champ de l’enquête les personnes vivant sur les réserves indiennes et les terres de la Couronne, les résidents des établissements, les membres à temps plein des Forces canadiennes et les personnes vivant dans certaines régions éloignées. L’ESCC couvre environ 98% de la population canadienne de 12 ans et plus.
5.2 Régions sociosanitaires
À des fins administratives, chaque province est divisée en plusieurs régions sociosanitaires (RS) et chaque territoire est considéré comme formant une RS unique. En collaboration avec les provinces, Statistique Canada est parfois appelé à modifier les limites de certaines RS afin qu’elles correspondent aux données géographiques du recensement ou encore afin de mieux tenir compte des besoins en données sur la santé selon de nouvelles bornes géographiques. Pour l’ESCC 2010, des données ont été recueillies pour 114 RS dans les dix provinces, ainsi que pour une RS par territoire, pour un total de 117 RS (Annexe C).
En 2010, la définition des RS en Alberta a été modifiée entre l’étape d’échantillonnage et la création des fichiers de données. Il y a maintenant 5 RS en Alberta, qui sont des regroupements des 9 RS qui étaient définies lors de l’échantillonnage4. Le présent chapitre sur le plan d’échantillonnage, de même que les données portant sur les tailles d’échantillon présentées à l’annexe D et à l’annexe F, réfèrent aux 9 RS telles qu’elles étaient définies lors de l’échantillonnage.
5.3 Taille et répartition de l’échantillon
Afin de produire des estimations fiables pour chaque RS et compte tenu du budget accordé pour l’ESCC, il a été établi que l’enquête devait être réalisée auprès d’un échantillon d’environ 130 000 personnes sur une période de 2 ans. La production d’estimations fiables pour chaque RS était l’objectif principal, mais la qualité des estimations pour certaines caractéristiques importantes pour les provinces a été jugée importante également. Par conséquent, la stratégie de répartition de l’échantillon, qui comporte trois étapes, accorde une importance plus ou moins égale aux RS et aux provinces. A la première étape, on impose une taille minimum de 500 répondants par RS, considérée comme étant le minimum requis afin d’obtenir un niveau de qualité de données raisonnable. Par contre, pour des raisons de fardeau de réponse, on impose une fraction de sondage maximum de 1 sur 20 logements afin d’éviter d’échantillonner trop de logements dans des petites régions qui sont aussi interpellées par d’autres enquêtes. Notons que très peu de RS ont une taille de moins de 500 due à la limite de la fraction de sondage. Cette première étape a réparti au total 60350 unités. La deuxième étape consiste à répartir le reste de l’échantillon disponible par province en suivant une répartition proportionnelle à la taille de la population par province. La taille totale de l’échantillon par province est donc la somme des tailles établies aux deux premières étapes. Il est à noter que la stratégie de répartition de l’échantillon a été utilisée pour l’ESCC au cycle 3.1 et que les tailles alors établies ont restées sensiblement les mêmes depuis. L’échantillon est ensuite divisé également pour chacune des 2 années de collecte. Le tableau 5.1 donne la taille d’échantillon pour 2010 et pour 2009-2010.
| Province | Nombre de RS | Taille d’échantillon visée 2009 | Taille d’échantillon visée 2009–2010 |
|---|---|---|---|
| Terre-Neuve-et-Labrador | 4 | 2 005 | 4 010 |
| Île-du-Prince-Édouard | 3 | 1 001 | 2 002 |
| Nouvelle-Écosse | 6 | 2 521 | 5 041 |
| Nouveau-Brunswick | 7 | 2 575 | 5 150 |
| Québec | 16 | 12 145 | 24 289 |
| Ontario1 | 36 | 22 172 | 44 379 |
| Manitoba | 10 | 3 750 | 7 500 |
| Saskatchewan | 11 | 3 860 | 7 720 |
| Alberta | 9 | 6 100 | 12 200 |
| Colombie-Britannique | 16 | 8 045 | 16 095 |
| Yukon | 1 | 600 | 1 200 |
| Territoires du Nord-Ouest | 1 | 600 | 1 200 |
| Nunavut | 1 | 350 | 700 |
| Canada | 121 | 65 724 | 131 486 |
|
|||
À la troisième étape, l’échantillon provincial a été réparti entre les RS proportionnellement à la racine carrée de la population estimée de la RS. Cette stratégie en trois étapes permet d’obtenir un échantillon suffisant pour chaque RS, sans perturber considérablement la répartition proportionnelle à la taille par province.
Il convient de souligner que les trois territoires, qui ont été traités séparément, n’étaient pas visés par la stratégie susmentionnée de répartition de l’échantillon. Au total, pour 2008, 600 unités d’échantillonnage ont été attribuées au Yukon, 600 aux Territoires du Nord–Ouest et 350 au Nunavut. Ces tailles sont déterminées selon le budget disponible. La répartition de l’échantillon dans les territoires est faite proportionnellement à la taille de la population dans les strates. Les strates utilisées sont les mêmes que celles définies par l’enquête sur la population active (EPA) qui regroupent un ensemble de collectivités. Pour plus de détails, se reporter à la section 5.4.1.
L’échantillon est ensuite divisé entre la base aréolaire et la base liste pour chaque RS5, tel que décrit dans la section suivante. Mentionnons finalement que la taille des échantillons tirés de chaque base a été augmentée avant la collecte des données afin de tenir compte des unités hors du champ de l’enquête et du taux de non–réponse anticipés à partir des taux obtenus lors des cycles précédents de l’ESCC. Les tailles d’échantillons par RS et par base de sondage sont données à l’annexe D pour 2010 et à l’annexe F pour 2009-2010.
5.4 Bases de sondage et stratégies d’échantillonnage des ménages
L’échantillon de ménages de l’ESCC a été sélectionné à partir de trois bases de sondage : 49,5% de l’échantillon de ménages provenait d’une base de sondage aréolaire, 49,5 % provenait d’une base liste de numéros de téléphone et 1 % provenait d’une base de sondage à composition aléatoire (CA). Ceci décrit la stratégie usuelle pour l’ESCC. Pour les deux dernières périodes de collecte de 2010, 40,5% provenait de la base aréolaire, 58,5% de la base liste et 1% de la base CA. Le transfert d’échantillon de la base aréolaire vers la base liste a été effectué dans le but de réduire les coûts de collecte.
5.4.1 Échantillonnage des ménages à partir de la base aréolaire
La base aréolaire conçue pour l’Enquête sur la population active (EPA) du Canada a servi de base de sondage principale pour l’ESCC. Le plan d’échantillonnage de l’EPA est un plan d’échantillonnage en grappes stratifié à plusieurs degrés où le logement représente l’unité finale d’échantillonnage6. À la première étape, des strates homogènes sont formées et des échantillons indépendants de grappes sont sélectionnés dans chaque strate. À la deuxième étape, une liste de logements pour chaque grappe est créée, puis des logements sont sélectionnés dans chaque liste.
Pour les besoins du plan d’échantillonnage de l’EPA, chaque province est répartie en trois catégories de région, soit les grands centres urbains, les villes et les régions rurales. Des strates géographiques ou socioéconomiques sont formées à l’intérieur de chaque grand centre urbain. Dans les strates, des grappes sont formées par regroupement de 150 à 250 logements. Dans certains centres urbains, des strates distinctes sont créées pour les appartements ou pour les aires de diffusion (AD) du recensement pour cibler les ménages à haut revenu, les immigrants et les autochtones. Dans chaque strate, six grappes ou des bâtiments d’habitation (parfois 12 ou 18 appartements) sont sélectionnées par une méthode d’échantillonnage aléatoire avec probabilité proportionnelle à la taille (PPT), cette dernière correspondant au nombre de ménages. Le nombre6 est utilisé pour l’ensemble du plan d’échantillonnage afin de permettre le renouvellement mensuel d’un sixième de l’échantillon de l’EPA.
Les autres villes et régions rurales de chaque province sont stratifiées, en premier lieu, en fonction de données géographiques, puis selon les caractéristiques socioéconomiques. Dans la plupart des strates, six grappes (habituellement des AD du recensement) sont sélectionnées par la méthode PPT. Certains centres urbains isolés géographiquement sont couverts par un plan de sondage à trois degrés. Ce type de plan de sondage est utilisé au Québec, en Ontario, en Alberta et en Colombie-Britannique.
Une fois la liste des nouvelles grappes établie, l’échantillon est tiré par échantillonnage systématique des logements. La taille de chaque échantillon systématique est appelée le rendement. Le tableau 5.2 donne un aperçu des catégories d’unités primaires d’échantillonnage (UPE) utilisées dans l’échantillon de l’EPA et le rendement prévu par échantillon systématique. Comme les taux d’échantillonnage sont prédéterminés, il existe souvent un écart entre la taille prévue d’échantillon et les chiffres obtenus. Par exemple, le rendement de l’échantillon est parfois excessif. Cette situation peut se présenter dans des secteurs où le nombre de logements a augmenté à la suite de nouveaux projets de construction. Pour réduire le coût de la collecte des données, la production excessive est corrigée en éliminant, dès le départ, une partie des unités sélectionnées. Cette modification est considérée lors de la pondération.
| Région | Unité primaire d’échantillonnage (UPE) |
Taille (ménages par UPE) |
Rendement (ménages échantillonnés) |
|---|---|---|---|
| Toronto, Montréal, Vancouver | Grappe | 150 à 250 | 6 |
| Autres villes | Grappe | 150 à 250 | 8 |
| La plupart des régions rurales/petits centres urbains | Grappe | 100 à 250 | 10 |
Afin de répondre aux exigences particulières de l’ESCC, certaines modifications ont dû être apportées à cette stratégie d’échantillonnage. Pour obtenir un échantillon d’environ 32 000 répondants pour une année donnée, il a fallu sélectionner près de 48 000 logements de la base aréolaire afin de tenir compte des logements vacants et des ménages non-répondants. Chaque mois, le plan d’échantillonnage de l’EPA fournit environ 60 000 logements répartis entre les diverses régions économiques des dix provinces alors que, pour l’ESCC, il fallait obtenir un échantillon d’environ 48 000 logements réparti par RS dont les limites géographiques différaient de celles des régions économiques de l’EPA. Globalement, l’ESCC nécessitait la sélection d’un nombre inférieur de logements que produit le mécanisme de sélection de l’EPA, ce qui correspond à un facteur de redressement de 0,80 (48 000/60 000). Toutefois, comme ce facteur de redressement variait de 0,3 à 3,0 au niveau des RS, certains ajustements ont été nécessaires.
Les modifications apportées au processus de sélection dans les régions variaient selon le facteur de redressement. Pour les RS où le facteur était égal ou inférieur à 1, le nombre d’UPE choisies a été réduit si nécessaire. Par exemple, si le facteur était de 0,5, alors seulement 3 UPE ont été choisies dans chaque strate de l’EPA au lieu du nombre habituel de 6 UPE. Pour les RS avec un facteur supérieur à 1 mais égal ou inférieur à 2, le processus d’échantillonnage des logements à l’intérieur d’une UPE a été répété pour un sous-ensemble des UPE sélectionnées appartenant à la RS en question. Par exemple, si le facteur était de 1,6, alors la sélection des logements a été répétée dans 4 des 6 UPE pour chaque strate dans la RS. Lorsque la répétition de la sélection de logements à l’intérieur d’une UPE était nécessaire mais qu’aucun autre logement n’était disponible dans cette UPE, alors une autre UPE a été choisie. Lorsque le facteur était supérieur à 2, le processus d’échantillonnage des logements a été répété à l’intérieur d’autres UPE appartenant à la RS en question7.
Finalement, lorsque le nombre de logements disponibles dans les UPE sélectionnées était supérieur au nombre de logements requis, un sous-échantillon a été tiré. Ce processus est appelé la stabilisation.
Échantillonnage des ménages à partir de la base aréolaire dans les trois territoires
Pour des raisons opérationnelles, le plan d’échantillonnage à partir de la base aréolaire de l’EPA pour les trois territoires est différent. Pour chaque territoire, les collectivités les plus populeuses ont chacune leur propre strate, alors que les collectivités les moins populeuses sont groupées en strates en fonction de diverses caractéristiques (population, données géographiques, proportion d’Inuit et/ou d’Autochtones et revenu médian du ménage). L’EPA a défini cinq strates pour le Yukon, dix pour les Territoires du NordOuest et sept pour le Nunavut. Pour les strates regroupant plus d’une collectivité, le premier degré d’échantillonnage consiste à sélectionner aléatoirement une collectivité avec probabilité proportionnelle à la taille de la population dans chaque strate. Puis, à l’intérieur de chaque collectivité, le deuxième degré d’échantillonnage consiste à sélectionner des ménages de façon identique à la stratégie d’échantillonnage décrite plus haut. L’ESCC a sélectionné son échantillon à partir des mêmes collectivités sélectionnées par l’EPA tout en s’assurant de sélectionner des logements différents. Si trop ou pas assez de logements étaient disponibles pour une collectivité à l’intérieur d’une strate, une autre collectivité était choisie pour l’ESCC. Pour les collectivités les plus populeuses ayant leur propre strate, seulement un plan à un degré était nécessaire pour sélectionner directement les ménages de façon identique à la stratégie d’échantillonnage décrite plus haut.
Il convient de mentionner que la base de sondage de l’ESCC couvrait 90 % des ménages privés du Yukon, 97 % de ceux des Territoires du Nord–Ouest et 71 % de ceux du Nunavut8.
5.4.2 Échantillonnage des ménages à partir de la base liste de numéros de téléphone
À l’exception de 5 RS ( les 2 RS provenant de la base CA et les trois territoires), la base liste de numéros de téléphone a été utilisée dans toutes les régions pour compléter la base aréolaire. La base liste est l’annuaire téléphonique du Canada, une base administrative externe de numéros de téléphones contenant les noms, les adresses et les numéros de téléphone répertoriés dans les annuaires de téléphone du Canada et qui est mise à jour à tous les 6 mois. Elle a été stratifiée par RS en utilisant un fichier de conversion de codes postaux de sorte à pouvoir associer un RS à chaque numéro de téléphone. Dans chaque RS, un échantillon de numéros de téléphone a été tiré par échantillonnage aléatoire simple. Comme pour la base de sondage à CA, des numéros de téléphone supplémentaires ont été sélectionnés pour tenir compte des numéros hors service ou hors du champ d’observation.
Il importe de souligner que la sous-couverture de la base liste de numéros de téléphone est plus importante que celle de la base de sondage à CA, car les numéros non publiés n’ont aucune chance d’être sélectionnés. Néanmoins, comme la base liste est toujours utilisée en complément de la base aréolaire, l’effet de la sous–couverture dû à l’utilisation de la base liste de numéros de téléphone est minimal et est corrigé lors de la pondération.
5.4.3 Échantillonnage des ménages à partir de la base de sondage à CA de numéros de téléphone
Dans 4 RS, un échantillon de numéros de téléphone provenant de la base de sondage à composition aléatoire (CA) a été utilisé pour sélectionner un échantillon de ménages. L’échantillonnage de ménages à partir de la base à CA a été réalisé selon la méthode d’élimination des banques non valides (EBNV) adoptée par l’Enquête sociale générale9. Une banque de cent numéros (c’est–à–dire les huit premiers chiffres d’un numéro de téléphone à 10 chiffres) est considérée comme non valide si elle ne contient aucun numéro de téléphone résidentiel. Au départ, la base de sondage comprend la liste de toutes les banques valides de cent numéros et celles qui ne sont pas valides sont éliminées de la base de sondage à mesure qu’on les repère. Il convient de souligner que ces banques de cent numéros ne sont éliminées de la base de sondage que lorsque l’on possède des preuves qu’elles ne sont pas valides provenant de sources diverses multiples. En l’absence de renseignements, la banque est retenue dans la base de sondage. Pour éliminer les banques non valides, on s’est servi de l’annuaire du téléphone, ainsi que de divers fichiers administratifs internes.
D’après les renseignements géographiques disponibles (codes postaux), les banques de cent numéros retenues dans la base de sondage ont été regroupées pour créer des strates CA englobant, de façon aussi exacte que possible, les régions sociosanitaires. À l’intérieur de chaque strate CA, une banque de cent numéros a été choisie au hasard et un numéro compris entre 00 et 99 a été généré aléatoirement afin de créer un numéro de téléphone complet à 10 chiffres. Cette méthode a été répétée jusqu’à ce que l’on ait atteint le nombre requis de numéros de téléphone pour la strate CA. Comme fréquemment, le numéro obtenu n’est pas en service ou est hors du champ d’observation, il faut générer un grand nombre de numéros supplémentaires pour atteindre la taille visée d’échantillon. Ce taux de réussite diffère selon la région. Dans le cas de l’ ESCC, il variait de 25% à 50% parmi les 4 RS qui y ont eu recours.
5.5 Répartition de l’échantillon par période de collecte des données
Afin d’équilibrer la charge de travail des intervieweurs et de réduire au minimum les effets saisonniers éventuels sur les estimations de caractéristiques importantes telle que l’activité physique, dans chaque RS, l’échantillon initial de logements/numéros de téléphone a été réparti au hasard, de façon égale pour chaque période de collecte de 2 mois.
Pour l’échantillon de la base aréolaire, chaque UPE sélectionnée dans chaque RS a été répartie au hasard à une période de collecte en tenant compte de plusieurs contraintes reliées aux opérations sur le terrain ou encore à la pondération tout en conservant une taille égale par période. Par exemple, on s’est assuré d’avoir un échantillon représentatif de la population canadienne aux 6 mois en s’assurant d’avoir un échantillon de logements couvrant toutes les strates de l’EPA sur cette période.
Pour les listes des numéros de téléphone, des échantillons indépendants ont été sélectionnés à chaque période de collecte. Cette stratégie permet d’assurer que chaque échantillon soit représentatif de la population canadienne faisant partie du champ d’observation de l’enquête à chaque deux mois.
5.6 Échantillonnage des personnes interviewées
Comme pour les cycles précédents, la sélection des répondants a été conçue de façon à ce que les jeunes (de 12 à 19 ans) soient surreprésentés dans l’échantillon. La stratégie d’échantillonnage adoptée a tenu compte des besoins des utilisateurs de données, du coût, de l’efficacité du plan d’échantillonnage, du fardeau de réponse et des contraintes opérationnelles. Une personne est sélectionnée par ménage en utilisant diverses probabilités de sélection variant selon l’âge et selon la composition du ménage. Les probabilités choisies font suite à des résultats de simulations reposant sur divers paramètres dans le but de déterminer l’approche optimale sans générer de poids d’échantillonnage extrêmes en bout de ligne.
Les facteurs multiplicatifs du poids de sélection ont été modifiés entre 2009 et 2010 pour augmenter la probabilité de sélectionner des répondants âgés entre 12 et 19 ans, ou entre 20 et 29 ans. Le tableau 5.3 donne les facteurs multiplicatifs de poids de sélection utilisés pour déterminer les probabilités de sélection des personnes dans les ménages échantillonnés, par groupe d’âge, pour 2009 et 2010. Par exemple, pour un ménage de trois personnes formé de deux adultes âgés entre 45 et 64 et d’un jeune de 15 ans, le jeune aura 7 chances sur 9 d’être sélectionné (c.-à-d. 70/(70+10+10)) tandis que chacun des adultes aura 1 chance sur 9 d’être sélectionné. Afin d’éviter l’obtention de poids extrêmes, il y a une exception à la règle: si la taille du ménage est plus grande ou égale à 5 ou si le nombre de personnes âgées de 12 à 19 ans est plus grand ou égal à 3, alors le facteur multiplicatif du poids de sélection est égal à 1 pour toutes les personnes du ménage. Dans ce cas, toutes les personnes du ménage ont la même probabilité d’être sélectionnées.
| Facteurs multiplicatifs du poids de sélection | |||||
|---|---|---|---|---|---|
| Age | 12 à 19 | 20 à 29 | 30 à 44 | 45 à 64 | 65+ |
| Facteurs (2009) | 65 | 25 | 20 | 10 | 10 |
| Facteurs (2010) | 70 | 50 | 20 | 10 | 10 |
5.7 Achat d’échantillon pour l’Ontario
La province de l’Ontario a demandé une augmentation de l’échantillon afin de produire des estimations au niveau de la géographie des réseaux locaux d’intégration des services de santé (RLISS). L’Ontario compte 14 RLISS. L’échantillon de l’ESCC a été augmenté de sorte à obtenir une taille minimum de 2000 par RLISS sur une période de 2 ans. Comme les limites des RS et RLISS s’entrecoupent, le niveau de stratification utilisé a été le croisement RS-RLISS. Les tailles d’échantillon préalablement allouées par RS ont donc été conservées. Dans les cas où la répartition par RS n’a pas permis d’atteindre des tailles de 2000 par RLISS, l’échantillon a été augmenté en conséquence et réparti proportionnellement à la taille de la population dans le croisement RS-RLISS. Le tableau 5.4 donne la taille d’échantillon de répondants visés par RLISS pour 2010 et 2009-2010.
| RLISS | Nombre visé de répondants 2010 | Nombre visé de répondants 2009–2010 |
|---|---|---|
| 01-Erie St. Clair | 1 550 | 3 100 |
| 02-South West | 2 561 | 5 122 |
| 03-Waterloo Wellington | 1 242 | 2 484 |
| 04-Hamilton Niagara Haldimand Brant | 2 597 | 5 194 |
| 05-Central West | 1 056 | 2 125 |
| 06-Mississauga Halton | 1 115 | 2 230 |
| 07-Toronto Central | 1 084 | 2 165 |
| 08-Central | 1 411 | 2 822 |
| 09-Central East | 2 108 | 4 216 |
| 10-South East | 1 313 | 2 626 |
| 11-Champlain | 2 057 | 4 114 |
| 12-North Simcoe Muskoka | 1 047 | 2 097 |
| 13-North East | 1 990 | 3 980 |
| 14-North West | 1 041 | 2 104 |
| Ontario | 22 172 | 44 379 |
La taille totale de l’échantillon des croisements RS-RLISS a ensuite été répartie également entre la base liste et la base aréolaire. Les procédures normales de sélection de l’échantillon dans chaque base ont été appliquées sur l’échantillon total. L’échantillon supplémentaire fait partie intégrante de l’échantillon de l’ESCC. Les tailles d’échantillon par réseau local d’intégration des services de santé et par base de sondage sont données à l’annexe D pour 2010 et à l’annexe F pour 2009-2010.
6.0 Collecte des données
6.1 Interviews assistées par ordinateur
Entre janvier et décembre 2010, un total de plus de 60 000 interviews valables assistées par ordinateur (IAO) ont été effectuées. Environ la moitié ont eu lieu au moyen de la méthode de l’interview sur place assistée par ordinateur (IPAO), l’autre moitié ayant consisté en des interviews téléphoniques assistées par ordinateur (ITAO). Le double d’interviews valables ont été effectuées entre janvier 2009 et décembre 2010.
L’IAO offre deux principaux avantages par rapport aux autres méthodes de collecte. D’abord, la technique est étayée d’un système de gestion des cas et d’une fonctionnalité de transmission de données. Le système de gestion des cas enregistre automatiquement de l’information de gestion importante sur chaque tentative effectuée dans un cas particulier et produit des rapports aux fins de la gestion du processus de collecte. L’IAO comprend également un ordonnanceur automatique d’appels, c’est–à–dire un système central qui optimise l’horaire des rappels et le calendrier des rendez–vous à l’appui de la collecte par ITAO.
Le système de gestion des cas achemine les applications de questionnaire et les fichiers d’échantillons du Bureau central de Statistique Canada aux bureaux régionaux de collecte dans le cas de l’ITAO et des bureaux régionaux aux ordinateurs portables des intervieweurs dans celui de l’IPAO. Les données destinées au Bureau central sont acheminées en sens inverse. Par souci de confidentialité, les données sont chiffrées avant la transmission. Elles sont ensuite déchiffrées une fois sauvegardées sur un ordinateur sécurisé distinct, sans accès à distance.
Deuxièmement, grâce à l’IAO une interview personnalisée peut être conçue à l’intention de chaque répondant en fonction de ses caractéristiques particulières et des réponses d’enquête. Notamment :
- l’application saute automatiquement les questions qui ne s’appliquent pas au répondant;
- des règles de vérification sont appliquées automatiquement pour repérer les réponses incohérentes ou non incluses dans la fourchette de valeurs permises, et des messages-guides apparaissent à l’écran en réaction à une inscription non valable. De cette façon, l’intervieweur reçoit une rétroaction immédiate et peut corriger toute incohérence;
- le texte des questions, y compris les périodes de référence et les pronoms, est personnalisé automatiquement d’après des facteurs comme l’âge et le sexe du répondant, la date de l’interview et les réponses aux questions précédentes.
6.2 Développement des applications de l’ ESCC
L’ESCC utilise deux applications d’IAO distinctes pour la collecte de données, l’une pour les interviews téléphoniques (ITAO), l’autre pour les interviews sur place (IPAO). Cette façon de faire permet d’adapter la fonctionnalité de chaque application au type d’interview menée. Chaque application comporte les composantes Entrée, C2 (contenu sur la santé) et Sortie.
Les composantes Entrée et Sortie comprennent des séries standard de questions auxquelles l’intervieweur a pu se référer pour prendre contact avec un répondant, recueillir de l’information importante sur l’échantillon, choisir les répondants et évaluer l’état des cas. La composante C2 consiste en les modules sur la santé et représente la plus grande partie des applications. Il s’agit, notamment, des modules communs posés à tous les répondants et du contenu optionnel, qui variaient d’une région sociosanitaire à l’autre. Chacune des applications a été l’objet de trois étapes de mise à l’essai: les tests modulaires, intégrés et de bout en bout.
Les tests modulaires consistent à mettre à l’essai indépendamment chaque module de contenu afin de vérifier la spécification exacte des instructions «passez à», la logique d’enchaînement et le texte, dans les deux langues officielles. À cette étape, les instructions «passez à» et la logique d’enchaînement entre modules ne sont pas testées, car chaque module est considéré comme un questionnaire autonome. Lorsque les responsables des essais ont terminé la vérification de tous les modules, ces derniers sont regroupés en applications intégrées avec les composantes Entrée et Sortie. À ce moment, les applications intégrées passent à l’étape suivante des essais.
Les tests intégrés portent sur l’ensemble des modules expérimentés, regroupés en applications intégrées avec les composantes Entrée et Sortie. La deuxième étape des essais vise à assurer que des renseignements clés, par exemple l’âge et le sexe, sont transmis de la composante Entrée aux sous-programmes du Contenu sur la santé et Sortie. Elle confirme également que les variables qui influent sur les instructions « passez à » et la logique d’enchaînement sont transmises correctement de module en module à l’intérieur de la composantedu Contenu sur la santé. Étant donné que, à ce moment, le fonctionnement des applications est essentiellement identique à ce qu’il sera sur le terrain, tous les scénarios possibles auxquels feront face les intervieweurs sont simulés afin d’en assurer la fonctionnalité rigoureuse. Les scénarios servent à tester divers aspects des composantes Entrée et Sortie, y compris la prise de contact, la collecte d’information sur le contact, la question de savoir si un cas répond à la fourchette des valeurs acceptables, le listage de ménages, la prise de rendez–vous et la sélection de répondants. Les tests servent également à confirmer que, au cours d’une interview, les modules de contenu optionnel choisis pour une région sociosanitaire donnée sont activés.
Les essais de bout en bout situent les applications entièrement intégrées dans un environnement de collecte simulé. Les applications sont chargées dans des ordinateurs connectés à un serveur d’essai. Ensuite, des données sont recueillies, transmises et extraites en temps réel, comme ce serait le cas sur le terrain. Cette dernière étape des essais permet d’expérimenter tous les aspects techniques de la saisie, de la transmission et de l’extraction des données pour chacune des applications de l’ESCC. Il s’agit, par ailleurs, de la dernière occasion de déceler des erreurs dans les composantes Entrée, Contenu sur la santé et Sortie.
6.3 Formation des intervieweurs
Les gestionnaires de projet, les intervieweurs principaux et les intervieweurs des bureaux régionaux responsables de la collecte des données de l’ESCC ont reçu une trousse de formation pour de l’auto-apprentissage avant le début de la collecte. Ces trousses ont été préparées par l’équipe projet de l’ESCC en vue d’être utilisées par les intervieweurs expérimentés de l’ESCC afin de leur procurer une mise à niveau de leurs connaissances. Les gestionnaires de projet et les intervieweurs principaux ont également mené, au besoin, des séances de formation pour les nouveaux intervieweurs . Enfin, des séances de formation mettant l’emphase sur des sujets spécifiques reliés à la collecte des données de l’ESCC se sont déroulées sur une base mensuelle.
L’objet des séances de formation était de familiariser les intervieweurs avec les applications de l’enquête, de les familiariser avec le contenu et de les introduire aux procédures d’entrevue spécifiques à l’ESCC 2010. La formation était centrée sur :
- les buts et objectifs de l’enquête, incluant une partie centrée sur le remaniement de l’enquête;
- les techniques d’enquête;
- les fonctionnalités des applications;
- le contenu des questionnaires, qui a été l’objet d’exercices avec emphase sur les changements significatifs apportés au contenu;
- les techniques à appliquer par l’intervieweur pour mener à bien l’interview, soit des exercices complets dont l’objet était de réduire au minimum la non–réponse;
- la simulation d’interviews difficiles et de situations de non–réponse;
- la gestion de l’enquête;
- les procédures de transmission.
La formation visait en priorité à réduire au minimum les cas de non–réponse. À cette fin, les intervieweurs ont participé à des exercices qui consistaient à persuader des répondants réticents de participer à l’enquête. En outre, les intervieweurs principaux responsables de la conversion des cas de refus à chaque bureau régional de collecte ont participé à une série d’ateliers sur la façon d’éviter les refus.
6.4 L’interview
Des unités d’échantillonnage sélectionnées à partir de la liste de numéros de téléphone et de la base CA ont répondu aux questions posées, à partir de centres d’appel centralisés, par des intervieweurs selon la méthode de l’ITAO. Un intervieweur principal affecté au même centre d’appels assurait la surveillance des intervieweurs. Des intervieweurs sur place décentralisés ont interviewé, au moyen de la méthode de l’IPAO, des unités d’échantillonnage sélectionnées dans la base aréolaire. Bien que, dans certaines situations, les intervieweurs sur place aient été autorisés à mener tout ou partie d’une interview par téléphone, environ les trois ont été effectuées exclusivement sur place. Les intervieweurs sur place ont effectué leur travail en autonomie à la maison, au moyen d’ordinateurs portables, et ils étaient surveillés à distance par des intervieweurs principaux. La variable SAM_TYP apparaissant dans les fichiers de microdonnées signifie qu’un cas a été choisi soit dans la base aréolaire (IPAO), soit dans la liste des numéros de téléphone ou la base CA (ITAO).
Dans tous les logements choisis, l’intervieweur demandait à un membre du ménage bien informé de fournir l’information démographique de base sur tous les occupants. Puis, il sélectionnait un membre du ménage pour une interview plus approfondie, appelée interview du Contenu sur la santé.
Les intervieweurs qui se servaient de la méthode de l’IPAO ont reçu la formation nécessaire pour procéder à une première prise de contact sur place avec chaque ménage échantillonné. Si la première visite se soldait par une non–réponse, un suivi par téléphone était permis. La variable ADM_N09 apparaissant dans les fichiers de microdonnées indique si l’interview a été effectuée sur place, par téléphone ou au moyen d’un ensemble des deux techniques.
Par souci d’assurer la qualité des données recueillies, les intervieweurs avaient reçu instruction de prendre tous les moyens à leur disposition pour mener en privé l’interview avec le répondant choisi. Là où la situation était inévitable, le répondant a été interviewé en présence d’une autre personne. Dans les fichiers de microdonnées, des indicateurs signalent si une personne autre que le répondant était présente à l’interview (ADM_N10) et si, de l’avis de l’intervieweur, la présence de l’autre personne a influencé les réponses du répondant (ADM_N11).
De nombreuses techniques, y compris les suivantes, ont été mises en œuvre afin de parvenir à un taux de réponse optimal.
a) Lettres d’introduction
Avant le début de chaque période de collecte, les ménages échantillonnés ont reçu des lettres d’introduction qui expliquaient l’objet de l’enquête. Elles énonçaient, notamment, l’importance de l’enquête et offraient des exemples de l’utilisation prévue des données tirées de l’ESCC.
b) Prise de contact
Les intervieweurs ont reçu instruction de mettre en œuvre tous les moyens raisonnables pour obtenir des interviews. Lorsque l’appel (ou la visite) de l’intervieweur était prévu à un moment peu commode, il fixait le moment d’un rappel qui convenait au répondant. Si l’intervieweur ne parvenait pas à prendre rendez–vous par téléphone, il devait effectuer une visite de suivi sur place. S’il n’y avait personne à la maison lors de la première visite, l’intervieweur laissait à la porte une brochure qui expliquait l’enquête et annonçait l’intention de l’intervieweur de prendre contact ultérieurement. De nombreux rappels ont été effectués, à divers moments et différents jours.
c) Conversion des cas de refus
Si une personne refusait d’abord de participer à l’enquête, le bureau régional de Statistique Canada lui faisait parvenir une lettre qui soulignait l’importance de l’enquête et de la collaboration du ménage. Ensuite, un intervieweur principal, un surveillant de projet ou un autre intervieweur rappelait le répondant (ou lui rendait visite) pour faire valoir l’importance de sa participation.
d) Obstacles linguistiques
Pour parer aux problèmes de langue susceptible de nuire aux interviews, tous les bureaux régionaux de Statistique Canada ont embauché des intervieweurs qui parlaient un grand nombre de langues. Au besoin, les cas étaient transférés à un intervieweur capable de remplir le questionnaire dans la langue voulue.
e) Interviews de jeunes
En 2009, les intervieweurs ont dû obtenir l’autorisation verbale des parents ou tuteurs pour interviewer des répondants sélectionnés âgés de 12 à 15 ans. En 2010, le bloc du consentement parental (BCP) a été ajouté aux applications. L’ajout de ce bloc officialise le processus consistant à demander au parent ou tuteur (s’il existe un parent ou tuteur dans le ménage) d’un jeune de 12 à 15 ans la permission pour que celui–ci participe à l’enquête. Les intervieweurs ont fait appel à plusieurs procédures pour atténuer les éventuelles inquiétudes des parents et mener à terme les interviews. Notamment, ils portaient sur eux une fiche intitulée « Nota aux parents/tuteurs concernant les interviews de jeunes à l’intention de l’Enquête sur la santé dans les collectivités canadiennes ». La fiche expliquait les raisons pour lesquelles des renseignements étaient recueillis auprès de jeunes, énumérait les thèmes dont traitait l’enquête, demandait l’autorisation de communiquer et de coupler l’information obtenue et expliquait la nécessité de respecter la vie privée et la confidentialité des jeunes.
Si un parent ou tuteur demandait à voir les questions, les intervieweurs avaient pour consigne soit de les leur montrer, soit, si l’interview avait lieu au téléphone, de faire en sorte que le bureau régional leur envoie sur– le–champ un exemplaire du questionnaire.
S’il se révélait impossible d’interviewer en privé le jeune sélectionné, soit sur place, soit par téléphone (sans qu’une autre personne soit à l’écoute), le code de refus était attribué à l’interview. Cependant, dans le cas des interviews selon la méthode de l’IPAO, s’il était impossible d’interviewer en confidence le jeune sélectionné, l’intervieweur pouvait proposer au parent ou tuteur de lui permettre de lire à haute voix les questions, après quoi le jeune pouvait y répondre directement à l’ordinateur.
On a ajouté le bloc de la personne la mieux renseignée (PMK) à l’application de 2010 afin de recueillir auprès de la personne la mieux renseignée du ménage les renseignements au niveau du ménage qui sont demandés à la fin de l’enquête (Mesures de sécurité à la maison, Couverture d’assurance, sécurité alimentaire, Problèmes neurologiques, Éducation, Revenu et renseignements administratifs). Ce bloc est activé quand le répondant sélectionné est âgé entre 12 et 15 ans. Une fois de plus, ce bloc officialise le processus qui consiste à identifier une personne du ménage qui est susceptible de mieux pouvoir répondre à ces questions au niveau du ménage que ne l’est le jeune répondant sélectionné. Si une PMK est trouvée, l’interview passe du jeune répondant sélectionné de 12 à 15 ans à un parent ou tuteur qui termine le reste de l’interview après le bloc de la PMK.
Puisque le bloc PMK ne faisait pas partie de l’ESCC de 2009, les variables de ce bloc ne sont pas disponibles dans le fichier de 2009–2010.
f) Interviews par procuration
Dans les cas où le répondant sélectionné était, pour des raisons de santé physique ou mentale, incapable de se prêter à l’interview, les renseignements à son sujet ont été fournis par un autre membre bien informé du ménage. C’est ce qu’on appelle une interview par procuration. Quoique les interviewés aient été en mesure de donner des réponses exactes à la plupart des questions de l’enquête, les questions plus délicates ou personnelles allaient au–delà des connaissances d’un répondant substitut. Par conséquent, certaines questions posées dans le cadre des interviews par procuration sont demeurées sans réponse. Il fallait donc tout tenter pour réduire au minimum le nombre d’interviews par procuration.
En 2010, on a modifié le bloc de l’interview par procuration (GR) pour faire en sorte que l’intervieweur indique expressément si l’interview est menée par procuration en raison d’un problème de santé physique ou d’un problème de santé mentale. Dans l’un ou l’autre de ces cas, l’intervieweur doit ensuite inscrire le problème particulier. La variable ADM_PRX indique si l’interview a été réalisée par procuration ou non.
6.5 Opérations sur le terrain
La plus grande part de l’échantillon de 2009 et 2010 a été répartie sur une base annuelle en six périodes de collecte de deux mois chacune qui ne se chevauchent pas. Les bureaux régionaux de collecte ont reçu instruction de passer les quatre premières semaines de chaque période de collecte à interviewer la majorité de l’échantillon, puis de consacrer les quatre semaines suivantes aux interviews restantes et au suivi des cas de non–réponse. À la deuxième semaine de chaque période, des tentatives devaient avoir été effectuées relativement à tous les cas.
Les bureaux de collecte centralisés ont reçu les fichiers d’échantillons environ deux semaines avant le début de chaque période de collecte. Chaque échantillon IPAO comprenait une série de cas fictifs dont devaient s’occuper les intervieweurs principaux afin de confirmer que les procédures de transmission de données fonctionnaient bien tout au long du cycle de collecte. Après réception des échantillons, il incombait aux surveillants de projet de planifier les tâches des intervieweurs chargés des interviews selon la méthode de l’IPAO. Quand la situation s’y prêtait, les tâches étaient limitées à 15 cas par intervieweur.
Le surveillant de projet, l’intervieweur principal et l’équipe de soutien technique du bureau régional étaient chargés de transmettre les cas de chaque bureau responsable des interviews effectuées selon la méthode de l’ITAO au Bureau central. Les transmissions ont eu lieu la nuit, et tous les cas menés à bien ont été acheminés au Bureau central de Statistique Canada. Les interviews menées selon la méthode de l’IPAO ont été transmises chaque jour du domicile de l’intervieweur directement au Bureau central de Statistique Canada par voie d’une ligne de téléphone sécurisée.
Pour les taux de réponse finaux, référez à l’annexe E pour 2010 et G pour 2009-2010.
6.6 Contrôle de la qualité et gestion de la collecte
Plusieurs méthodes ont servi à assurer la qualité des données et l’optimisation de la collecte des données. Il s’est agi, entre autres, de mesures internes de vérification du rendement de l’intervieweur et d’une série de rapports de contrôle des diverses cibles de collecte et de la qualité des données.
Le bureau régional validait régulièrement le travail des intervieweurs sur place. Des cas choisis ont été repérés aléatoirement dans les échantillons à chaque période de collecte. Les gestionnaires et les surveillants des bureaux régionaux ont dressé des listes de cas à valider, lesquels ont été confiés à l’équipe de validation, qui communiquait avec les ménages concernés afin de confirmer la tenue d’une interview en règle. Par souci de repérer promptement les problèmes, la validation avait normalement lieu au cours des premières semaines d’une période de collecte. Ensuite, les surveillants adressaient régulièrement une rétroaction aux intervieweurs.
Les intervieweurs travaillant par téléphone ont également été l’objet d’une validation aléatoire. En l’espèce, les intervieweurs principaux des bureaux de collecte responsables des interviews selon la méthode de l’ITAO contrôlaient les interviews afin de vérifier que l’intervieweur appliquait les techniques et les procédures prévues (c’est–à–dire qu’il lisait le libellé des questions tel qu’il figurait dans les applications, qu’il ne posait pas de questions incitatives, et ainsi de suite).
Les responsables ont produit une série de rapports dont l’objet était de contrôler et de gérer efficacement les cibles de collecte et de mettre au jour les problèmes posés par la collecte.
À la fin de chaque période, des rapports cumulatifs ont été produits qui précisaient les taux de réponse, de couplage, de partage et d’interview par procuration, ventilés par échantillon ITAO et IPAO, de même que par région sociosanitaire. Les rapports ont servi à cerner les régions où les niveaux de collecte étaient inférieurs aux cibles, de sorte que les bureaux régionaux puissent y concentrer leurs efforts.
Le Bureau central a effectué des analyses complémentaires au moyen de l’information tirée des applications d’IAO afin de recenser les interviews de durée excessivement courte. Ces dernières ont été signalées au moyen d’indicateurs, supprimées des microdonnées et classées parmi les cas de non–réponse.
7.0 Traitement des données
7.1 Vérification
La vérification des données a été exécutée en grande partie par l’application d’interview assistée par ordinateur (IAO) durant la collecte des données. Les intervieweurs ne pouvaient pas entrer de valeurs hors-normes et les erreurs d’enchaînement faisaient l’objet de l’instruction de contrôle programmée « passez à ». Par exemple, l’IAO s’assurait de ne pas poser au répondant les questions non pertinentes.
En réponse à certaines données incompatibles ou inhabituelles, on a signalé des messages d’avertissement, mais sans prendre de mesures correctrices au moment de l’interview. On a plutôt mis au point, le cas échéant, des versions révisées à appliquer après la collecte des données au bureau central. Les incohérences ont été le plus souvent corrigées en attribuant à l’une ou aux deux variables en question la valeur « non déclaré ».
7.2 Codage
On a fourni des catégories de réponses précodées pour toutes les variables appropriées. Les intervieweurs ont reçu une formation durant laquelle ils ont appris à classer les réponses recueillies dans la catégorie appropriée.
Dans les cas où la réponse donnée par le répondant ne pouvait être assignée facilement à une catégorie existante, l’intervieweur pouvait poser plusieurs questions lui permettant d’entrer une réponse en toutes lettres dans la catégorie « Autre – précisez ». Les réponses à toutes ces questions ont été examinées attentivement lors du traitement des données au bureau central. Dans certains cas, on a donné aux réponses en toutes lettres le code d’une catégorie figurant sur la liste si la réponse faisait double emploi. On tiendra compte des réponses « Autre – précisez » fournies pour toutes les questions lors du perfectionnement des catégories de réponses en vue de futurs cycles de l’enquête.
7.3 Création de variables dérivées
Pour faciliter l’analyse des données, on a dérivé un certain nombre de variables à partir des éléments disponibles sur le questionnaire de l’ESCC. Le quatrième caractère du nom des variables dérivées est en général un « D », « G » ou un « F ». Dans certains cas, les variables dérivées sont simples, donnant lieu à un regroupement des catégories de réponses. Dans d’autres cas, on a combiné plusieurs variables pour en créer une nouvelle. La Documentation sur les variables dérivées (VD) fournit des détails sur la façon de dériver ces variables plus complexes. Pour de plus amples renseignements concernant la nomenclature, veuillez vous référer à la section 12.6.
7.4 Pondération
Le principe de base de l’estimation dans un échantillon aléatoire comme celui de l’ESCC repose sur le fait que chaque personne représente, en plus d’elle-même, plusieurs autres personnes qui ne font pas partie de l’échantillon. Par exemple, dans un échantillon aléatoire simple de 2 % de la population, chaque personne en représente 50. Dans la terminologie en usage ici, nous dirons que nous avons attribué à chaque personne un facteur de pondération de 50.
L’étape de détermination des facteurs de pondération donne lieu au calcul du poids d’échantillonnage de chaque personne échantillonnée. Ce poids apparaît dans le fichier de microdonnées à grande diffusion et doit servir à extraire des estimations de l’enquête. Par exemple, si l’on doit évaluer le nombre de personnes qui fument tous les jours, on le fait en choisissant dans l’échantillon les enregistrements des personnes qui présentent cette caractéristique et en faisant la somme des facteurs de pondération que représentent ces enregistrements.
Vous trouverez les détails sur la façon dont on calcule les poids d’échantillonnage à la section 8.
8.0 Pondération
Pour que les estimations produites à partir de données d’enquête soient représentatives de la population couverte, et non pas seulement représentatives de l’échantillon comme tel, l’utilisateur doit incorporer les facteurs de pondération, appelés ici les poids d’enquête, dans ses calculs. Un poids d’enquête est attribué à chaque personne incluse dans l’échantillon final, c’est-à-dire dans l’échantillon de personnes ayant répondu à l’enquête. Ce poids correspond au nombre de personnes représentées par le répondant dans l’ensemble de la population de l’enquête.
Tel que décrit dans la section 5, l’ESCC a recours à trois bases de sondage pour la sélection de son échantillon: une base aréolaire de logements agissant comme base principale, puis deux bases formées de numéros de téléphone utilisées pour complémenter la base aréolaire. Puisque seulement quelques différences mineures distinguent les deux bases de numéros de téléphone pour la pondération, elles ont été traitées ensemble. On réfère à celles-ci comme faisant partie de la base téléphonique.
Selon les besoins, une seule ou deux bases peuvent être utilisées pour la sélection de l’échantillon dans une région sociosanitaire (RS). Quand on utilise deux bases, la stratégie de pondération traite indépendamment la base aréolaire et la base téléphonique pour dériver les poids au niveau de ménage séparé pour chaque base utilisée. Ces poids des ménages sont ensuite combinés en un seul ensemble de poids des ménages lors d’une étape appelée « intégration ». Suite à la transformation des poids des ménages en poids de personne et à quelques autres ajustements, ce poids intégré devient le poids de personne final.
8.1 Introduction
Tel que mentionné plus haut, les unités des bases aréolaire et téléphonique sont traitées séparément jusqu’à l’étape d’intégration. Les sections suivantes décrivent la stratégie de pondération pour les provinces. La sous- section 8.2 fournit les détails de la stratégie de pondération pour la base aréolaire, puis la sous-section 8.3, ceux pour la base téléphonique. L’intégration des deux bases est traitée en 8.4. Puis, suivent les deux étapes finales de la pondération, c’est-à-dire l’ajustement pour contrôler la saisonnalité des données puis le calage aux marges, qui sont expliquées dans la sous-section 8.5.
Malgré que les deux bases aient été utilisées pour couvrir les trois territoires, les méthodes d’échantillonnage utilisées ont été légèrement modifiées pour les territoires. Ces modifications affectent substantiellement la pondération pour ces trois régions, et celles-ci sont rapportées dans la sous-section 8.6.
Le diagramme A présente un sommaire des différents ajustements faisant partie de la stratégie de pondération. Un système de numérotation est utilisé pour identifier chaque ajustement apporté au poids et sera utilisé tout au long de la section. Les lettres A et T sont utilisées comme préfixes pour référer aux ajustements appliqués aux unités des bases Aréolaire et Téléphonique respectivement. Le préfixe I est quant à lui utilisé pour identifier l’ajustement d’Intégration et ceux qui suivent.
Diagramme A Sommaire de la stratégie de pondération

8.2 Pondération de l’échantillon provenant de la base aréolaire
A0 – Poids initial
La pondération pour la base aréolaire débute avec un poids fourni par l’Enquête sur la population active (EPA). Ce poids est basé sur le plan de sondage de l’EPA puisque le plan de sondage de base aréolaire de l’ESCC découle de celui de l’EPA. Le plan de sondage de l’EPA consiste en un échantillonnage de logements dans les grappes sélectionnées parmi les strates de l’EPA. Lors de l’ajustement initial, le poids de l’EPA est ajusté afin de tenir compte du fait que l’ESCC sélectionne un échantillon représentatif au niveau des régions sociosanitaires (RS). De plus, l’ESCC sélectionne un nombre de grappes différent de l’EPA et peut répéter l’échantillonnage de logements dans les grappes sélectionnées. Le poids résultant est appellé A0. Pour plus de détails sur le mécanisme de sélection, de même qu’une définition plus complète des strates de l’EPA et des grappes, se référer à Statistique Canada (1998)10.
A1 – Ajustement de sous–poids de grappe
Dans les grappes où un accroissement significatif de la population est observé, une méthode de sous-échantillonnage est utilisée afin de ne pas augmenter indûment la tâche de l’interviewer. La méthode alors appliquée par l’EPA pourra être de sous-échantillonner les logements dans cette grappe, de diviser cette grappe en sous-grappes ou de redéfinir cette grappe comme étant une strate et de créer de nouvelles grappes dans cette strate. Dans tous ces cas, un ajustement de sous-poids de grappe est calculé et appliqué aux poids de l’ESCC. Cet ajustement est multiplié par le poids A0 pour produire le poids A1. Encore une fois, plus de détails sont disponibles dans la documentation de l’EPA (Statistique Canada (1998)).
A2 – Stabilisation
Dans certaines RS, l’accroissement de l’échantillon, tel que décrit à la section 5, résulte en un échantillon beaucoup plus grand que nécessaire. Une stabilisation a donc été instaurée afin de ramener la taille de l’échantillon au niveau désiré. Le processus de stabilisation consiste à sous-échantillonner des logements aléatoirement à l’intérieur de la RS parmi les logements originalement sélectionnés dans chaque grappe. Un facteur d’ajustement représentant l’effet de la stabilisation est donc calculé afin de corriger la probabilité de sélection. Ce facteur, multiplié par le poids A1, produit le poids A2.
A3 – Retrait des unités hors champ
Parmi tous les logements échantillonnés, une certaine proportion de ceux-ci est, lors de la collecte, identifiée comme étant hors du champ de l’enquête. Des logements détruits ou en construction, des logements vacants, saisonniers ou secondaires, de même que des établissements, sont tous des exemples de cas hors champ pour l’ESCC. Ces logements sont tout simplement retirés de l’échantillon, ne laissant plus que les logements faisant partie du champ de l’enquête. Les logements ou ménages qui restent dans l’échantillon conservent le même poids qu’à l’étape précédente que l’on appelle maintenant poids A3.
A4 – Non-réponse ménage
Lors de la collecte, une certaine proportion des ménages échantillonnés a inévitablement résulté en non-réponse. Ceci survient habituellement lorsque le ménage refuse de participer à l’enquête, fournit des données inutilisables, ou encore, ne peut être rejoint pour réaliser l’interview. Le poids des ménages non-répondants est redistribué aux répondants à l’aide de groupes de réponses homogènes (GRH). Dans le but de créer ces GRH, la méthode du score basée sur une régression logistique est utilisée afin de déterminer la probabilité de réponse, puis ces probabilités sont utilisées afin de diviser l’échantillon en groupes ayant des propriétés de réponse similaire. L’information disponible pour les non-répondants étant limitée, le modèle de régression comprend donc des variables comme la période de collecte et des informations géographiques, en plus de paradonnées telles que le nombre d’essais pour contacter le ménage, l’heure/jour des essais et si les essais ont été faits au cours de la semaine ou de la fin de semaine. Depuis 2008, les GRH sont créés à l’intérieur des provinces, pour mieux estimer les totaux provinciaux. Un facteur d’ajustement a donc été calculé à l’intérieur de chaque GRH de la façon suivante :

Le poids A3 des ménages répondants est donc multiplié par ce facteur d’ajustement pour produire le poids A4. Les ménages non-répondants sont éliminés du processus de pondération à partir de ce point.
8.3 Pondération de l’échantillon provenant de la base téléphonique
Tel que mentionné précédemment, la base téléphonique est en fait composée de deux bases : la base de sondage à composition aléatoire (CA), puis une base liste de numéros de téléphone. Une seule de ces deux bases peut être utilisée à l’intérieur d’une RS. La base liste est toujours utilisée comme complément à la base aréolaire tandis que la base CA est toujours utilisée seule pour une RS donnée. Les unités provenant de ces deux bases téléphoniques sont toutefois traitées ensemble et sont donc toutes soumises aux mêmes ajustements.
La géographie utilisée pour sélectionner l’échantillon à partir de la base téléphonique ne répliquait pas parfaitement la géographie des RS, ce qui a forcé certaines unités à être sélectionnées dans une certaine région alors que l’information fournie lors de l’interview les localisait plutôt dans une région avoisinante. Cette particularité a été traitée lors de la pondération en appliquant les trois premiers ajustements (T0, T1 et T2) relativement à la RS assignée lors de la sélection de l’échantillon. Les 2 ajustements restants (T3 et T4) sont appliqués à des RS basé sur l’information recueillie auprès du répondant, pour s’assurer que chaque unité soit associée à la bonne RS.
T0 – Poids initial
Le poids initial est défini comme l’inverse de la probabilité de selection et il est calculé quelque peu différemment selon que l’échantillon provienne de la base CA ou de la base liste. Dans les deux cas, le poids initial est défini comme étant l’inverse de la probabilité de sélection, mais puisque les méthodes de sélection diffèrent, les probabilités diffèrent aussi. Pour la base CA, la sélection des numéros est faite à l’intérieur de chaque strate CA. Une strate CA représente un agrégat d’indicatifs régionaux et préfixes (IRP: les six premiers chiffres du numéro à 10 chiffres), contenant chacune des banques valides de cent numéros (voir Norris et Paton11 pour plus de détails). Conséquemment, la probabilité de sélection est le ratio entre le nombre d’unités échantillonnées et cent fois le nombre de banques présentes dans la strate CA.
Pour la base liste, les numéros de téléphone sont sélectionnés parmi tous les numéros disponibles dans la liste, et ce indépendamment pour chaque RS. Ainsi, la probabilité de sélection correspond au ratio entre le nombre d’unités échantillonnées et le nombre de numéros de téléphone dans la liste pour la RS. Le ratio est basé sur la version de la base disponible et du nombre d’unités sélectionnées pour une période de collecte donnée. Pour cette raison, la probabilité de sélection peut changer selon la répartition de l’échantillon et les mises à jour de la base. L’inverse de ces probabilités de sélection représente le poids initial T0.
T1 – Nombre de périodes de collecte
Contrairement à la base aréolaire, pour laquelle l’échantillon est sélectionné entièrement au début du processus d’échantillonnage, des échantillons sont tirés à chaque deux mois pour les bases téléphoniques. À chacun de ces échantillons mensuels correspond un poids initial faisant en sorte que chaque échantillon soit représentatif de la RS. Toutefois, pour que l’échantillon total ne représente qu’une seule fois la population, un facteur d’ajustement doit être appliqué pour réduire les poids de chaque échantillon mensuel. Le facteur d’ajustement appliqué à chaque échantillon mensuel est égal à l’inverse du nombre d’échantillons combinés ou encore, du nombre de périodes de collecte. À partir de ce moment, l’échantillon de la base liste correspond à la moyenne des échantillons des périodes de collecte combinées. Les poids initiaux sont multipliés par cet facteur d’ajustement de produire le poids T1.
T2 - Retrait des unités hors champ
Les numéros de téléphone associés à des entreprises, des établissements ou à d’autres logements hors du champ de l’enquête, de même que les numéros hors service sont tous des exemples de cas hors champ pour la base téléphonique. Comme pour la base aréolaire, ces cas sont simplement retirés de l’échantillon, ne laissant ainsi dans l’échantillon que les logements dans le champ de l’enquête. Ces derniers conservent le même poids qu’à l’étape précédente que l’on appelle maintenant poids T2.
T3 – Non-réponse ménage
L’ajustement fait ici pour compenser l’effet de la non-réponse ménage est identique à celui appliqué pour la base aréolaire (ajustement A4). Par contre, les para-données utilisées diffèrent puisque des applications de collecte différentes sont utilisées pour les interviews en personne et par téléphone. C’est donc cette variable qui a été utilisée pour définir les classes d’ajustement. Le facteur d’ajustement calculé à l’intérieur de chaque classe a été obtenu de la façon suivante:

Le poids T2 des ménages répondants a donc été multiplié par ce facteur d’ajustement pour produire le poids T3. Les ménages non-répondants sont éliminés à partir de ce point.
T4 - Lignes multiples
Le fait que certains ménages possèdent plus d’une ligne téléphonique résidentielle a un impact sur la pondération: plus le ménage a de lignes, meilleure est sa probabilité d’être sélectionné. Conséquemment, les poids doivent être ajustés pour tenir compte du nombre de lignes résidentielles que le ménage possède. Le facteur d’ajustement représente l’inverse du nombre de lignes dans le ménage et le poids T4 est obtenu en multipliant ce facteur par le poids T3.
8.4 Intégration des bases aréolaire et téléphonique
Cette étape consiste à intégrer les poids finaux des échantillons aréolaire et téléphonique créés jusqu’à maintenant, en un seul poids en appliquant une méthode d’intégration12. Le poids des unités qui se trouvent sur la base aréolaire mais pas sur la base téléphonique n’est pas ajusté. Pour toutes les autres unités, un facteur d’ajustement α, compris entre 0 et 1, est appliqué au poids. Le poids des unités de la base aréolaire est multiplié par ce facteur α, alors que le poids des unités de la base téléphonique est multiplié par 1- α. Il est à noter que dans les cas où une RS n’est couverte que par une seule base, le facteur d’ajustement est égal à 1. Depuis 2008, un α fixé à 0,4 est utilisé pour les unités qui se trouvent sur les deux bases, dans le but de créer des estimations cohérentes au travers le temps. Le produit du facteur d’ajustement dérivé ici, par le poids de ménage final calculé auparavant (A4 ou T4 dépendant de quelle base provient l’unité), procure le poids intégré I1.
8.5 Les étapes de pondération post-intégration
I2 – Création du poids-personne
Puisque l’unité d’échantillonnage finale pour l’ESCC est la personne, le poids-ménage calculé jusqu’ici doit être converti en un poids-personne. Celui-ci est obtenu en multipliant le poids I1 par l’inverse de la probabilité de sélection de la personne choisie dans le ménage. Nous obtenons ainsi le poids I2. Rappelons que la probabilité de sélection de la personne change en fonction du nombre de personnes dans le ménage et de l’âge des individus (voir section 5.6 pour plus de détails).
I3 – Non-réponse personne
Dans le cadre de l’ESCC, une interview peut être vue comme un processus en deux étapes. Dans un premier temps, l’intervieweur obtient la liste complète des personnes vivant dans le ménage, puis par la suite interviewe la personne sélectionnée dans le ménage. Dans certains cas, les intervieweurs ne réussissent qu’à compléter la première étape, soit parce qu’ils ne peuvent entrer en contact avec la personne sélectionnée, ou encore parce que la personne sélectionnée refuse d’être interviewée. De tels cas sont définis comme étant des non-réponses à l’échelle de la personne, et un facteur d’ajustement doit être appliqué aux poids des personnes répondantes pour compenser cette non-réponse. Tout comme pour la non-réponse à l’échelle du ménage, l’ajustement est appliqué à l’intérieur de groupes de réponses homogènes (GRH). Dans ce processus, la méthode par score est utilisée pour définir une probabilité de réponse définie à partir des caractéristiques disponibles pour les répondants et les non-répondants. Toutes les caractéristiques recueillies lors du listage des membres du ménage, en plus de l’information géographique et des paradonnées, sont en fait disponibles pour estimer les probabilités de réponse. Ces probabilités sont utilisées afin de définir les GRH et un facteur d’ajustement est calculé à l’intérieur de chaque GRH de la façon suivante :

Le poids I2 des personnes répondantes est donc multiplié par ce facteur d’ajustement pour produire le poids I3. Les personnes non-répondantes sont éliminées de la pondération à partir de ce point.
I4 – Winsorization
Suite à la série d’ajustements appliqués sur les poids, il est possible que certaines unités se retrouvent avec des poids se démarquant des autres poids de leur RS au point même de devenir aberrants. Ces unités peuvent effectivement représenter une proportion anormalement élevée de leur RS et ainsi influencer fortement les estimations et la variance de ces RS. Afin d’éviter cette situation, le poids des répondants qui contribuent de façon aberrante est ajusté à la baisse selon une méthode appelée « winsorization ».
I5 - Calage aux marges
La dernière étape nécessaire afin d’obtenir le poids final de l’ESCC est le calage aux marges (I5). Le calage aux marges est appliqué en utilisant CALMAR13 afin d’assurer que la somme des poids finaux corresponde aux estimations de populations définies à l’échelle des RS, pour chacun des 10 groupes d’âge-sexe d’intérêt, c’est-à-dire les cinq groupes d’âge 12-19, 20-29, 30-44, 45-64, 65+, pour chacun des deux sexes. À partir de 2009, des contrôles additionnels au niveau des sous-régions ont été introduits pour certaines RS. Ces contrôles incluaient les CLSC dans les RS 2403 (Région de la Capitale-Nationale, Québec) et 2415 (Région des Laurentides) et aussi les District Health Authorities (DHA) en Nouvelle-Écosse. Dans un même temps, les poids sont ajustés afin de s’assurer que chaque période de collecte (de deux mois) soit également représentée par l’échantillon. Il est à noter que le calage aux marges a été fait en utilisant une géographie la plus à jour possible, qui diffère peut-être de la géographie utilisée lors de l’échantillonnage.
Les estimations de population sont basées sur les comptes du recensement de 2006, de même que sur les comptes de naissance, de décès, d’immigration et d’émigration depuis ce temps. La moyenne des estimations mensuelles pour chacun des croisements RS-âge-sexe par période de collecte a été retenue pour réaliser le calage. Après le calage, l’ajustement de poids I5 est obtenu. Le poids I5 correspond au poids-personne final de l’ESCC que l’on retrouve dans le fichier de données portant le nom de variable WTS_M pour les utilisateurs du fichier maître ou du FMGD. Avant la période de référence de 2010, les comptes du recensement de la population de 2001 étaient utilisés. Des évaluations ont confirmé que l’impact de ce changement sur les estimations de l’ESCC est minime.
8.6 Particularités de la pondération pour les trois territoires
Tel que décrit à la section 5, le plan d’échantillonnage utilisé pour les trois territoires est quelque peu différent de celui utilisé dans les provinces. La stratégie de pondération est donc adaptée pour répondre à ces différences. Cette section résume les changements apportés à la stratégie expliquée aux sous-sections 8.1 à 8.5.
D’abord pour la base aréolaire, tel que mentionné à la sous-section 5.4.1, une étape additionnelle de sélection est ajoutée pour les territoires. Chaque territoire est initialement stratifié selon des regroupements de communautés à l’intérieur desquels on a sélectionné aléatoirement une communauté. Notar que les capitales de chaque territoire formaient une strate à elles seules, et sont donc toutes trois sélectionnées automatiquement à cette première sélection. Cette particularité n’a eu d’effet que dans le calcul de la probabilité de sélection, et donc dans la valeur du poids initial (A0). Une fois ce poids initial calculé, la même série d’ajustements (A1 à A4) est appliquée aux unités de la base aréolaire. Les classes d’ajustement sont construites, pour les non-réponses ménage et personne, à l’aide du même ensemble de variables disponibles pour les provinces.
Pour ce qui est de la pondération des unités de la base téléphonique, mentionnons tout d’abord que seule la base CA est utilisée, et ce, uniquement à l’intérieur des capitales du Yukon et des Territoires du Nord-Ouest. Tous les ajustements de la base téléphonique sont appliqués afin de calculer un poids pour les unités de la base téléphonique.
Les deux ensembles de poids (aréolaire et téléphonique) sont ensuite intégrés, puis poststratifiés de façon semblable à ce qui est fait pour les provinces, à l’exception de trois détails. D’abord, l’intégration a été appliquée uniquement pour les unités situées dans les capitales du Yukon et des Territoires du Nord-Ouest; les autres communautés étant couvertes uniquement par la base aréolaire. Un autre détail à noter pour le Nunavut est que les comptes de la population utilisés pour le calage aux marges représentent les 10 plus grandes communautés (70% de la population) seulement étant donné le sous-dénombrement de la base aréolaire, telle que décrit à la section 5.4.1. Finalement, en commençant avec les produits de diffusion des périodes de référence de 2008 et 2007-2008, des contrôles ont été mis en place pour s’assurer que la proportion des autochtones et la proportion d’individus vivant dans les régions capitales soient contrôlées dans les Territoires du Nord-Ouest et du Yukon. Un contrôle similaire basé sur le statut Inuit a été introduit pour le Nunavut, et à partir de 2009, un contrôle pour la proportion d’individus vivant dans la région capitale de Nunavut est inclus aussi. Ces contrôles assurent que la proportion des estimations représentées par ces groupes est cohérente avec les proportions indiquées par le Recensement de 2006.
8.7 La création d’un poids pour le fichier partagé
En plus du fichier maître et du FMGD qui contiennent tous les répondants de l’ESCC, un fichier partagé est créé qui contient seulement une portion (> 90%) des répondants originaux de l’ESCC. Les individus sur le fichier partagé ont consenti à partager leurs données avec certains partenaires. Pour compenser la perte des répondants sur le fichier, les poids des « partageurs » doivent être ajustés par le facteur :
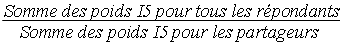
Pareillement à ce qui est fait lors des ajustements pour la non-réponse, ce facteur est créé à l’intérieur de groupes homogènes, en regroupant ici les individus ayant des propensions à partager semblables. Le poids final après cet ajustement est WTS_S.
8.8 Pondération du fichier de deux ans
Quand deux années de données sont combinées pour créer un fichier de deux ans, de nouveaux poids sont calculés en divisant directement les poids annuels en deux. Ceci assure que la somme totale des poids équivaut à la taille moyenne de la population pour la période de référence de deux ans. Pour plus d’information sur comment combiner plusieurs périodes de références, consultez l’article « Combiner les cycles de l’Enquête sur la santé dans les collectivités canadiennes » paru dans les Rapports sur la santé (82-003) de Statistique Canada au lien suivant: 82-003
9.0 Qualité des données
9.1 Taux de réponse
Au total, 88 410 des unités sélectionnées à l’ESCC 2010 faisaient partie du champ de l’enquête14. Parmi ces unités, 71 315 ont accepté de participer à l’enquête, ce qui résulte en un taux de réponse à l’échelle du ménage de 80,7%. Parmi ces ménages répondants, 71 315 personnes ont été sélectionnées (une personne par ménage) pour participer à l’enquête parmi lesquelles 63 191 ont accepté de le faire ce qui résulte en un taux de réponse à l’échelle de la personne de 88,6 %. À l’échelle canadienne, un taux de réponse combiné de 71,5 % a donc été observé pour l’ESCC 2010. Le tableau 9.1 donne les taux de réponse combinés ainsi que l’information pertinente au calcul de ceux-ci pour chaque région sociosanitaire ou regroupement de régions sociosanitaires. Le tableau 9.2 donne la même information mais au niveau des réseaux locaux d’intégration des services de santé (RLISS).
Tableau 9.1 : Taux de réponse par région socio-sanitaire et par base de sondage de l’ESCC 2010
Tableau 9.2 : Taux de réponse par réseau local d’intégration des services de santé (RLISS) et par base de sondage de l’ESCC 2010 en Ontario
9.2 Taux de réponse pour 2009–2010
Au total, 172 671 des unités sélectionnées à l’ESCC 2009–2010 faisaient partie du champ de l’enquête. Parmi ces unités, 139 841 ont accepté de participer à l’enquête, ce qui résulte en un taux de réponse à l’échelle du ménage de 81,0%. Parmi ces ménages répondants, 139 841 personnes ont été sélectionnées (une personne par ménage) pour participer à l’enquête, parmi lesquelles 124 870 ont accepté de le faire, ce qui résulte en un taux de réponse à l’échelle de la personne de 89,3 %. À l’échelle canadienne, un taux de réponse combiné de 72,3 % a donc été observé pour l’ESCC 2009–2010. Le tableau 9.3 donne les taux de réponse combinés ainsi que l’information pertinente au calcul de ceux-ci pour chaque région sociosanitaire ou regroupement de régions sociosanitaires. Le tableau 9.4 donne la même information mais au niveau des réseaux locaux d’intégration des services de santé (RLISS).
Tableau 9.3 : Taux de réponse par région sociosanitaire et par base de sondage de l’ESCC 2009-2010
Tableau 9.4 : Taux de réponse par réseau local d’intégration des services de santé (RLISS) et par base de sondage de l’ESCC 2009-2010 en Ontario
On décrit dans ce qui suit de quelle façon les différentes composantes de l’équation doivent être manipulées afin de calculer correctement les taux de réponse combinés.
Taux de réponse à l’échelle du ménage
HHRR = Nombre de ménages répondants provenant des deux bases / Toutes les ménages faisant partie du champ de l’enquête provenant des 2 bases
Taux de réponse à l’échelle de la personne
PPRR = Nombre de personnes répondantes provenant des deux bases / Toutes les personnes sélectionnées provenant des deux bases
Taux de réponse combiné = HHRR x PPRR
Voici maintenant un exemple de calcul du taux de réponse combiné pour le Canada en utilisant l’information fournie dans le tableau 9.1. La même méthode est utilisée pour calculer les taux pour de plus petites régions telles que les provinces ou les régions sociosanitaires, ou pour calculer les taux pour l’ESCC 2009–2010 à partir des données fournies dans le tableau 9.3.
HHRR =
33 387 + 37 928 = 71 315
40 070 + 48 340 = 88 410
PPRR =
30 449 + 32 742 = 63 191
33 387 + 37 928 = 71 315
Taux de réponse combiné = 0,807 x 0,886
= 0,715
= 71,5%
9.3 Erreurs dans les enquêtes
L’enquête permet de produire des estimations fondées sur l’information recueillie à partir d’un échantillon de personnes. On aurait pu obtenir des estimations quelque peu différentes si on avait effectué un recensement complet en utilisant le même questionnaire, les mêmes intervieweurs, les mêmes superviseurs, les mêmes méthodes de traitement, etc. que ceux utilisés pour l’enquête. La différence entre les estimations tirées de l’échantillon et celles qui découlent d’un dénombrement complet effectué dans des conditions semblables s’appelle l’erreur due à l’échantillonnage des estimations.
Les erreurs qui ne sont pas liées à l’échantillonnage peuvent être commises à presque toutes les étapes d’une enquête. Il est possible que les intervieweurs comprennent mal les instructions, que les répondants fassent des erreurs en complétant le questionnaire, que les réponses soient mal saisies et que des erreurs se produisent au moment du traitement et de la totalisation des données. Tous ces exemples représentent des erreurs non dues à l’échantillonnage.
9.3.1 Erreurs non dues à l’échantillonnage
Sur un grand nombre d’observations, les erreurs aléatoires auront peu d’effet sur les estimations tirées de l’enquête. Toutefois, les erreurs qui se produisent systématiquement contribueront à des biais dans les estimations de l’enquête. On a consacré beaucoup de temps et d’efforts à réduire les erreurs non dues à l’échantillonnage dans l’enquête. Des mesures d’assurance de la qualité ont été appliquées à chaque étape du cycle de collecte et de traitement des données afin de contrôler la qualité des données. On a notamment fait appel à des intervieweurs hautement qualifiés, une formation poussée sur les méthodes d’enquête et le questionnaire et l’observation des intervieweurs afin de déceler les problèmes. La mise à l’essai de l’application IAO et les essais sur le terrain ont également été au nombre des procédures essentielles pour réduire au maximum les erreurs de collecte de données.
L’effet de la non-réponse sur les résultats de l’enquête constitue une source importante d’erreurs non dues à l’échantillonnage dans les enquêtes. L’ampleur de la non-réponse varie de la non-réponse partielle (le fait de ne pas répondre à une ou plusieurs questions) à la non-réponse totale. Dans l’ESCC, il y a peu de non-réponse partielle car une fois le questionnaire débuté les répondants avaient tendance à le terminer. Il y a eu non-réponse totale lorsque la personne sélectionnée pour participer à l’enquête a refusé de le faire ou que l’intervieweur a été incapable d’entrer en contact avec elle. Finalement, les cas de non-réponse totale ont été considérés lors de la pondération en corrigeant les poids des personnes qui ont répondu à l’enquête afin de compenser pour ceux qui n’ont pas répondu. Voir la section 8 pour avoir de plus amples détails sur la correction de la pondération pour la non-réponse.
9.3.2 Erreurs dues à l’échantillonnage
Étant donné que les estimations d’une enquête par sondage comportent inévitablement des erreurs dues à l’échantillonnage, de bonnes méthodes statistiques exigent que les chercheurs fournissent aux utilisateurs une certaine indication de l’ampleur de cette erreur. La mesure de l’importance éventuelle des erreurs dues à l’échantillonnage est fondée sur l’écart type des estimations tirées des résultats de l’enquête. Cependant, en raison de la grande diversité des estimations que l’on peut tirer d’une enquête, l’écart type d’une estimation est habituellement exprimé en fonction de l’estimation à laquelle il se rapporte. Cette mesure, appelée coefficient de variation (CV), s’obtient en divisant l’écart type de l’estimation par l’estimation elle-même et on l’exprime en pourcentage de l’estimation.
Par exemple, supposons qu’une personne estime que 25 % des Canadiens âgés de 12 ans et plus sont des fumeurs réguliers et que cette estimation comporte un écart type de 0,003. On calcule alors le CV de cette estimation de la façon suivante :
(0,003/0,25) x 100% = 1,20%
Statistique Canada utilise fréquemment les résultats du CV pour l’analyse des données et conseille vivement aux utilisateurs produisant des estimations à partir des fichiers de données de l’ESCC de faire de même. Pour plus d’information sur le calcul des CV, voir la section 11. Pour consulter les lignes directrices sur la façon d’interpréter les résultats du CV, se référer au tableau à la fin de la sous-section 10.4.
10.0 Lignes directrices pour la totalisation, l’analyse et la diffusion
Cette section du guide décrit les lignes directrices que doivent suivre les utilisateurs qui totalisent, analysent, publient ou diffusent de quelqu’autre façon des données provenant des fichiers de microdonnées de l’enquête. Ces lignes directrices devraient leur permettre de reproduire les chiffres déjà publiés par Statistique Canada et de produire aussi des chiffres non encore publiés conformes aux lignes directrices établies.
10.1 Lignes directrices pour l’arrondissement
Afin que les estimations calculées d’après ces fichiers de microdonnées (Maitre, Partager, ou FMGD) correspondent à celles produites par Statistique Canada, il est vivement conseillé à l’utilisateur de les arrondir en se conformant aux lignes directrices suivantes.
- Les estimations qui figurent dans le corps d’un tableau statistique doivent être arrondies à la centaine près par la méthode d’arrondissement classique. Selon cette méthode, si le premier ou le seul chiffre à supprimer se situe entre 0 et 4, le dernier chiffre retenu ne change pas. Si le premier ou le seul chiffre à supprimer se situe entre 5 et 9, on augmente d’une unité (1) la valeur du dernier chiffre retenu. Par exemple, si l’on veut arrondir à la centaine près de la façon classique une estimation dont les deux derniers chiffres sont compris entre 00 et 49, il faut les remplacer par 00 et ne pas modifier le chiffre précédent (le chiffre des centaines). Si les deux derniers chiffres sont compris entre 50 et 99, il faut les remplacer par 00 et augmenter d’une unité (1) le chiffre précédent.
- Les totaux partiels de marge et les totaux de marge des tableaux statistiques doivent être calculés à partir de leurs éléments correspondants non arrondis, puis arrondis à leur tour à la centaine près selon la méthode d’arrondissement classique.
- Les moyennes, les proportions, les taux et les pourcentages doivent être calculés à partir d’éléments non arrondis (c’est-à-dire les numérateurs et (ou) dénominateurs), puis arrondis à une décimale par la méthode d’arrondissement classique. Si l’on veut arrondir une estimation à un seul chiffre décimal par cette méthode et que le dernier ou le seul chiffre à supprimer se situe entre 0 et 4, le dernier chiffre à retenir ne change pas. Si le premier ou le seul chiffre à supprimer se situe entre 5 et 9, on augmente d’une unité (1) le dernier chiffre à retenir.
- Les sommes et les différences d’agrégats (ou de rapports) doivent être calculées à partir de leurs éléments correspondants non arrondis, puis arrondies à leur tour à la centaine près (ou à la décimale près) selon la méthode d’arrondissement classique.
- Si, en raison de contraintes d’ordre technique ou autre, on applique une autre méthode que l’arrondissement classique, si bien que les estimations qui seront publiées ou diffusées de toute autre façon diffèrent des estimations correspondantes publiées par Statistique Canada, il est vivement conseillé à l’utilisateur d’indiquer la raison de ces divergences dans le ou les documents à publier ou à diffuser.
- Des estimations non arrondies ne doivent être publiées ou diffusées de toute autre façon en aucune circonstance. Des estimations non arrondies donnent l’impression d’être beaucoup plus précises qu’elles ne le sont en réalité.
10.2 Lignes directrices pour la pondération de l’échantillon en vue de la totalisation
Le plan d’échantillonnage utilisé pour cette enquête n’est pas autopondéré. Autrement dit, le poids d’échantillonnage n’est pas le même pour toutes les personnes qui font partie de l’échantillon. Même pour produire des estimations simples, y compris des tableaux statistiques ordinaires, l’utilisateur doit employer le poids d’échantillonnage approprié. Sinon, les estimations calculées à partir du ficher de microdonnées ne pourront être considérées comme représentatives de la population observée et ne correspondront pas à celles de Statistique Canada.
L’utilisateur ne doit pas non plus perdre de vue qu’en raison du traitement réservé au champ du poids, certains progiciels ne permettent pas d’obtenir des estimations qui coïncident exactement avec celles de Statistique Canada.
10.2.1 Définitions des catégories d’estimations : de type nominal par opposition à quantitatives
Avant d’exposer la façon de totaliser et d’analyser les données de l’enquête, il est bon de décrire les deux grandes catégories d’estimations ponctuelles des caractéristiques de la population qui peuvent être produites à partir du fichier de microdonnées.
Estimations de type nominal:
Les estimations de type nominal sont des estimations du nombre ou du pourcentage de personnes qui, dans la population visée par l’enquête, possèdent certaines caractéristiques ou rentrent dans une catégorie particulière. Le nombre de personnes qui fument tous les jours est un exemple d’estimation de ce genre. L’estimation du nombre de personnes qui possèdent une caractéristique particulière peut aussi être appelée «estimation d’un agrégat».
Exemple de question de type nominal:
Actuellement, est-ce que… fume(z) des cigarettes tous les jours, à l’occasion ou jamais? (SMK_202)
Tous les jours
À l’occasion
Jamais
Estimations quantitatives:
Les estimations quantitatives sont des estimations de totaux ou de moyennes, de médianes ou d’autres mesures de tendance centrale de quantités qui ont trait à tous les membres de la population observée ou à certains d’entre eux.
Un exemple d’estimation quantitative est le nombre moyen de cigarettes que fument par jour les personnes qui fument tous les jours. Le numérateur correspond à l’estimation du nombre total de cigarettes que fument par jour les personnes qui fument tous les jours et le dénominateur, à l’estimation du nombre de personnes qui fument tous les jours.
Exemple de question quantitative :
Actuellement, combien de cigarettes est-ce que… fume(z) chaque jour? (SMK_204)
Nombre de cigarettes
10.2.2 Totalisation d’estimations de type nominal
On peut obtenir, à partir du fichier de microdonnées, des estimations du nombre de personnes qui possèdent une caractéristique donnée en additionnant les poids finaux de tous les enregistrements contenant des données sur la caractéristique étudiée.
Pour obtenir les proportions et les rapports de la forme  , on doit:
, on doit:
- additionner les poids finaux des enregistrements contenant la caractéristique voulue pour le numérateur (
 );
); - additionner les poids finaux des enregistrements contenant la caractéristique voulue pour le dénominateur (
 );
); - diviser l’estimation du numérateur par celle du dénominateur.
10.2.3 Totalisation d’estimations quantitatives
Pour obtenir l’estimation d’une somme ou d’une moyenne pour une variable quantitative, on procède aux étapes suivantes (seule l’étape a) est nécessaire pour obtenir l’estimation pour une somme) :
- multiplier la valeur de la variable étudiée par le poids finaux, puis faire la somme de cette quantité pour tous les enregistrements visés pour obtenir le numérateur(
);
- faire la somme des poids finaux des enregistrements contenant la variable étudiée pour obtenir le dénominateur (
);
- diviser l’estimation du numérateur par l’estimation du dénominateur.
Par exemple, pour estimer le nombre moyen de cigarettes que fument chaque jour les personnes qui fument tous les jours, on calcule d’abord le numérateur (
) en sommant le produit entre la valeur de la variable SMK_204 et le poids WTS_M. Ensuite additionnez cette valeur pour les enregistrements pour lesquels la valeur de la variable SMK_202 est «tous les jours». On obtient ensuite le dénominateur (
) en additionnant le poids final de tous les enregistrements pour lesquels la valeur de la variable SMK_202 est «tous les jours». Le nombre moyen de cigarettes fumées chaque jour par les personnes qui fument tous les jours est finalement obtenu en divisant (
) par (
).
10.3 Lignes directrices pour l’analyse statistique
L’ESCC se fonde sur un plan de sondage complexe qui prévoit une stratification et un échantillonnage à plusieurs degrés, ainsi que la sélection des répondants avec probabilités inégales. L’utilisation des données provenant d’une enquête aussi complexe pose des difficultés aux analystes, car le choix des méthodes d’estimation et de calcul de la variance dépend du plan de sondage et des probabilités de sélection.
Nombre de méthodes d’analyse intégrées aux progiciels statistiques permettent d’utiliser des poids, mais la signification et la définition de ces poids peuvent différer de celles applicables dans le contexte d’une enquête par sondage. Par conséquent, si les estimations calculées au moyen de ces progiciels sont souvent exactes, les variances n’ont, quant à elles, pratiquement aucune signification.
Dans le cas de nombreuses méthodes d’analyse (par exemple la régression linéaire, la régression logistique, l’analyse de la variance), une méthode permet de corriger les résultats obtenus des progiciels courants de façon à ce qu’il soit plus adéquat. Cette méthode consiste à rééchelonner les poids qui figurent dans les enregistrements de façon à ce que le poids moyen soit égal à un (1). Les résultats produits par les progiciels classiques sont ainsi plus raisonnables puisque, même s’ils ne reflètent toujours pas la stratification et la mise en grappes du plan d’échantillonnage, ils tiennent compte de la sélection avec probabilités inégales. On peut effectuer cette transformation en utilisant dans l’analyse un poids égal au poids original divisé par la moyenne des poids originaux pour les unités échantillonnées (personnes) qui contribuent à l’estimation en question.
10.4 Lignes directrices pour la diffusion
Avant de diffuser et/ou de publier des estimations tirées des fichiers de microdonnées, l’utilisateur doit d’abord déterminer le nombre de répondants dans l’échantillon ayant la caractéristique à l’étude (par exemple, le nombre de répondants qui fument lorsqu’on s’intéresse à la proportion de fumeurs pour une population donnée) pour s’assurer qu’il y a assez d’unités pour calculer un estimation de qualité. Pour les utilisateurs de FMGD, si ce nombre est inférieur à 30, l’estimation pondérée ne doit pas être diffusée, quelle que soit la valeur de son coefficient de variation. Pour les utilisateurs des fichers maître ou de partage, il est recommandé d’ avoir au moins 10 observations au numérateur et 20 observations au dénominateur. Pour les estimations pondérées basées sur des échantillons de 10 ou plus (30 ou plus pour le FMGD), l’utilisateur doit calculer le coefficient de variation de l’estimation arrondie et suivre les lignes directrices qui suivent.
Table 10.1 Lignes directrices relatives à la variabilité d’échantillonnage
| Type d’estimation | CV (en %) | Lignes directrices |
|---|---|---|
| Acceptable | 0,0 ≤ CV≤ 16,5 | On peut envisager une diffusion générale non restreinte des estimations. Aucune annotation particulière n’est nécessaire. |
| Marginale | 16,6 < CV ≤ 33,3 | On peut envisager une diffusion générale non restreinte des estimations, en y joignant une mise en garde aux utilisateurs quant à la variabilité d’échantillonnage élevée liée aux estimations. Les estimations de ce genre doivent être identifiées par la lettre E (ou d’une autre manière similaire). |
| Inacceptable | CV > 33,3 | Statistique Canada recommande de ne pas publier des estimations dont la qualité est inacceptable. Toutefois, si l’utilisateur choisit de le faire, il doit alors adjoindre la lettre F (ou un autre identificateur semblable) et les diffuser avec l’avertissement suivant : « Nous avisons l’utilisateur que… (précisez les données)… ne répondent pas aux normes de qualité de Statistique Canada pour ce programme statistique. Les conclusions tirées de ces données ne sauraient être fiables et seront fort probablement erronées. Ces données et toute conclusion qu’on pourrait en tirer ne doivent pas être publiées. Si l’utilisateur choisit de les publier, il est alors tenu de publier également le présent avertissement.» |
11.0 Tableaux de la variabilité d’échantillonnage approximative
Afin de permettre aux utilisateurs d’avoir facilement accès à des coefficients de variation qui s’appliqueraient à une multitude d’estimations de type nominal obtenues à partir de ce fichier de microdonnées à grande diffusion, Statistique Canada a produit un ensemble de tableaux de la variabilité d’échantillonnage approximative. Ces tableaux permettent aux utilisateurs d’obtenir un coefficient de variation approximatif selon la taille de l’estimation calculée à partir des données de l’enquête.
Les coefficients de variation (CV) sont calculés en employant la formule de la variance utilisée pour l’échantillonnage aléatoire simple et en y incorporant un facteur qui reflète la structure en grappes à plusieurs degrés du plan d’échantillonnage. Pour obtenir ce facteur, appelé effet du plan, on a d’abord calculé les effets du plan pour une vaste gamme de caractéristiques, puis pour chaque tableau, choisi une valeur conservatrice parmi tous les effets du plan relatifs à ce tableau. Cette valeur choisie a ensuite été utilisée pour générer le tableau qui peut alors s’appliquer à l’ensemble complet des caractéristiques.
Les effets du plan, les tailles d’échantillon et les comptes de population qui ont servi à produire les tableaux de la variabilité d’échantillonnage approximative de même que les tableaux, sont disponibles à l’Annexe E. Tous les coefficients de variation sont approximatifs dans les tableaux de la variabilité d’échantillonnage approximative et ils ne doivent donc pas être considérés comme des valeurs exactes. Les possibilités concernant le calcul d’un coefficient de variation exact sont discutées dans la sous-section 11.7.
Rappel : Tel qu’indiqué dans «Les lignes directrices relatives à la variabilité d’échantillonnage» à la section 10.4, si le nombre d’observations sur lesquelles une estimation est basée est inférieur à 30, l’estimation pondérée ne doit pas être diffusée, quelle que soit la valeur de son coefficient de variation. Les coefficients de variation basés sur des échantillons de petite taille sont trop imprévisibles pour être adéquatement représentés dans les tableaux.
11.1 Comment utiliser les tableaux de CV pour les estimations de type nominal
Les règles suivantes devraient permettre à l’utilisateur de calculer, à partir des tableaux de la variabilité d’échantillonnage, les coefficients de variation approximatifs d’estimations relatives au nombre, à la proportion ou au pourcentage de personnes dans la population observée qui possèdent une caractéristique donnée ainsi que des rapports et des écarts entre ces estimations.
Règle 1 : Estimations du nombre de personnes possédant une caractéristique donnée (agrégats)
Le coefficient de variation dépend uniquement de la taille de l’estimation elle-même. Dans le tableau de coefficients de variation approximatifs correspondant à la région appropriée, il faut repérer l’estimation calculée dans la colonne d’extrême gauche (intitulée « Numérateur du pourcentage ») et suivre les astérisques (s’il y en a) de gauche à droite jusqu’au premier nombre. Puisque toutes les valeurs possibles de l’estimation ne sont pas disponibles, il faut prendre la valeur la plus petite qui s’en rapproche le plus (par exemple, si l’estimation vaut 1700 et que les deux valeurs disponibles sont 1 000 et 2 000, il faut choisir 1 000). Ce nombre constitue le coefficient de variation approximatif pour l’estimation en question.
Règle 2 : Estimations de proportions ou de pourcentages de personnes possédant une caractéristique donnée
Le coefficient de variation d’une proportion (ou d’un pourcentage) estimée dépend à la fois de l’ordre de grandeur de cette proportion et de l’ordre de grandeur du numérateur utilisé dans le calcul de la proportion. Les proportions estimées sont relativement plus fiables que les estimations correspondantes du numérateur de la proportion lorsque celle-ci est fondée sur un sous-ensemble de la population. Cela est dû au fait que les coefficients de variation des estimations du dernier type sont basés sur le chiffre le plus élevé dans une rangée d’un tableau particulier, tandis que les coefficients de variation des estimations du premier type sont basés sur un chiffre quelconque de cette même rangée (pas nécessairement le plus élevé). (Il convient de noter que dans les tableaux, la valeur des coefficients de variation décroît de gauche à droite sur une même ligne.) Par exemple, la proportion estimative de personnes qui fument tous les jours parmi les fumeurs est plus fiable que le nombre estimatif de personnes qui fument tous les jours.
Lorsque la proportion (ou le pourcentage) est fondée sur la population totale de la région géographique à laquelle le tableau s’applique, le coefficient de variation de la proportion est égal à celui du numérateur de la proportion. Dans ce cas-ci, cela équivaut à appliquer la règle 1.
Lorsque la proportion (ou le pourcentage) est fondée sur un sous-ensemble de la population totale (p. ex., les personnes qui fument), il faut se reporter à la proportion (haut du tableau) et au numérateur de la proportion ou du pourcentage (côté gauche du tableau). Puisque toutes les valeurs possibles de la proportion et du numérateur ne sont pas disponibles, il faut, dans les deux cas, prendre la valeur la plus petite qui s’en rapproche le plus (par exemple, si la proportion est de 23 % et que les deux valeurs disponibles dans la colonne s’en rapprochant le plus sont 20 % et 25 %, il faut choisir 20 %). Le coefficient de variation se trouve à l’intersection de la ligne et de la colonne appropriée.
Règle 3 : Estimations des différences entre des agrégats ou des pourcentages
L’erreur-type d’une différence entre deux estimations est à peu près égale à la racine carrée de la somme des carrés de chaque erreur-type considérée séparément. L’erreur-type d’une différence ( ) est donc :
) est donc :

où représente l’estimation 1, l’estimation 2, et  et
et  sont les coefficients de variation de et respectivement. Le coefficient de variation de
sont les coefficients de variation de et respectivement. Le coefficient de variation de  est donné par
est donné par  . Cette formule donne un résultat exact pour ce qui est de la différence entre des sous-populations indépendantes mais n’est autrement qu’approximative. Cette formule mènera à une surestimation de l’erreur si et sont corrélés positivement et à une sous-estimation de l’erreur si et sont corrélés négativement.
. Cette formule donne un résultat exact pour ce qui est de la différence entre des sous-populations indépendantes mais n’est autrement qu’approximative. Cette formule mènera à une surestimation de l’erreur si et sont corrélés positivement et à une sous-estimation de l’erreur si et sont corrélés négativement.
Règle 4 : Estimations de rapports
Si le numérateur est un sous-ensemble du dénominateur, il faut convertir le rapport en pourcentage et appliquer la règle 2. Ce serait le cas, par exemple, si le dénominateur est le nombre de personnes qui fument et le numérateur est le nombre de personnes qui fument tous les jours parmi celles qui fument.
Si le numérateur n’est pas un sous-ensemble du dénominateur (par exemple, le rapport du nombre de personnes qui fument tous les jours ou à l’occasion au nombre de personnes qui ne fument pas du tout), l’écart-type du rapport entre les estimations est à peu près égal à la racine carrée de la somme des carrés de chaque coefficient de variation pris séparément multipliée par  , où
est le rapport des estimations (
, où
est le rapport des estimations ( ). L’erreur-type d’un rapport est donc :
). L’erreur-type d’un rapport est donc :

où
et
sont les coefficients de variation de et respectivement.
Le coefficient de variation de
est donné par
. La formule tend à surestimer l’erreur si et sont corrélés positivement et à sous–estimer l’erreur si et sont corrélés négativement.
Règle 5 : Estimations des différences entre des rapports
Dans ce cas-ci, les règles 3 et 4 sont combinées. On commence par calculer les coefficients de variation des deux rapports au moyen de la règle 4, puis le coefficient de variation de leur différence au moyen de la règle 3.
11.2 Exemples d’utilisation des tableaux de CV pour des estimations de type nominal
Les exemples réels suivants ont pour but d’aider les utilisateurs à appliquer les règles décrites ci-dessus.
Exemple 1 : Estimations du nombre de personnes possédant une caractéristique donnée (agrégats)
Supposons qu’un utilisateur estime à 4 722 617 le nombre de personnes qui fument tous les jours au Canada. Comment l’utilisateur fait-il pour déterminer le coefficient de variation de cette estimation?
1) Se reporter au tableau de CV pour le CANADA.
2) L’agrégat estimé (4 722 617) ne figure pas dans la colonne de gauche (la colonne «Numérateur du pourcentage »); il faut donc utiliser le nombre le plus petit qui s’en rapproche le plus, soit 4 000 000.
3) Le coefficient de variation d’un agrégat estimé (exprimé en pourcentage) est la première entrée sur cette ligne (à part les astérisques), soit 1,70 %.
4) Le coefficient de variation approximatif de l’estimation est donc 1,70 %. Par conséquent, selon les « Lignes directrices relatives à la variabilité d’échantillonnage » présentées à la section 10.4, l’estimation selon laquelle 4 722 617 personnes fument tous les jours peut être diffusée sans réserve.
Exemple 2 : Estimations de proportions ou de pourcentages de personnes possédant une caractéristique donnée
Supposons qu’un utilisateur estime à 4 722 617 / 6 081 453 = 77,7 % le pourcentage de personnes, parmi les fumeurs, qui fument tous les jours au Canada. Comment l’utilisateur fait-il pour déterminer le coefficient de variation de cette estimation?
- Se reporter au tableau de CV pour le CANADA.
- Parce que l’estimation est un pourcentage basé sur un sous-ensemble de la population totale (c’est–à–dire. les personnes qui fument tous les jours ou à l’occasion), il faut utiliser à la fois le pourcentage (77,7 %) et la partie numérateur du pourcentage (4 722 617) pour déterminer le coefficient de variation.
- Le numérateur (4 722 617) ne figure pas dans la colonne de gauche (la colonne « Numérateur du pourcentage »); il faut donc utiliser le nombre le plus petit qui s’en rapproche le plus, soit 4000000. De même, l’estimation du pourcentage ne figure pas parmi les en-têtes de colonnes; il faut donc utiliser le nombre le plus petit qui s’en rapproche le plus, soit 70,0 %.
- Le nombre qui se trouve à l’intersection de la ligne et de la colonne utilisées, soit 1,0 %, est le coefficient de variation (exprimé en pourcentage) à employer.
- Le coefficient de variation de l’estimation est donc 1,0 %. Par conséquent, selon les «Lignes directrices relatives à la variabilité d’échantillonnage» présentées à la section 10.4, l’estimation selon laquelle 77,7 % des gens qui fument le font tous les jours peut être diffusée sans réserve.
Exemple 3 : Estimations des différences entre des agrégats ou des pourcentages
Supposons qu’un utilisateur estime que, parmi les hommes, 2 535 367 / 13 078 499 = 19,4% fument tous les jours (estimation 1), alors que chez les femmes, ce pourcentage est estimé à 2 187 250 / 13 476 931 = 16,2 % (estimation 2). Comment l’utilisateur fait-il pour déterminer le coefficient de variation de la différence entre ces deux estimations?
1) À l’aide du tableau de CV pour le CANADA, utilisé de la même façon que dans l’exemple 2, vous établissez à 2,4 % le CV de l’estimation1 (exprimé en pourcentage) et à 2,4 % le CV de l’estimation 2 (exprimé en pourcentage).
2) Selon la règle 3, l’erreur-type pour une différence (
= - ) est :

où est l’estimation 1, est l’estimation 2, et α1 et α2 sont les coefficients de variation de et respectivement. L’erreur-type de la différence
= (0,194 - 0,162) = 0,032 est donc :

3) Le coefficient de variation de
est donné par  = 0,0061/0,032 = 0,190.
= 0,0061/0,032 = 0,190.
4) Le coefficient de variation approximatif de la différence entre les estimations est donc 19,0 % (exprimé en pourcentage). Par conséquent, toujours selon les «Lignes directrices relatives à la variabilité d’échantillonnage» présentées à la section 10.4, cette estimation peut être publiée en y joignant une mise en garde.
Exemple 4 : Estimations de rapports
Supposons qu’un utilisateur estime à 4 722 617 le nombre de personnes qui fument tous les jours et à 1 358 836 le nombre de celles qui fument à l’occasion. L’utilisateur veut comparer ces deux estimations sous la forme d’un rapport. Comment fait-il pour déterminer le coefficient de variation de cette estimation?
1) Tout d’abord, cette estimation est une estimation de rapport, où le numérateur de l’estimation (= ) est le nombre de personnes qui fument à l’occasion. Le dénominateur de l’estimation (= ) est le nombre de personnes qui fument tous les jours.
2) Se reporter au tableau de CV pour le CANADA.
3) Le numérateur de cette estimation de rapport est 1 358 836. Le nombre le plus petit qui se rapproche le plus de ce nombre est 1 000 000. Le coefficient de variation de cette estimation (exprimé en pourcentage) est la première entrée sur cette ligne (à part les astérisques), soit 3,7 %.
4) Le dénominateur de cette estimation de rapport 4 722 617. Le nombre le plus petit qui se rapproche le plus de ce nombre est 4 000 000. Le coefficient de variation de cette estimation (exprimé en pourcentage) est la première entrée sur cette ligne (à part les astérisques), soit 1,7 %.
5) Le coefficient de variation approximatif de l’estimation du rapport est donc donné par la règle 4,

,
c’est-à-dire,

où α1 et α2 sont les coefficients de variation de et respectivement. Le rapport des personnes qui fument occasionnellement à celles qui fument tous les jours est 1 358 836/4 722 617, soit 0,29:1. Le coefficient de variation de cette estimation est 4,1 % (exprimé en pourcentage); selon les «Lignes directrices relatives à la variabilité d’échantillonnage» présentées à la section 10.4, l’estimation peut donc être diffusée sans réserve.
11.3 Comment utiliser les tableaux de CV pour calculer les limites de confiance
Bien que les coefficients de variation soient largement utilisés, l’intervalle de confiance d’une estimation représente une mesure plus intuitive de l’erreur d’échantillonnage. Un intervalle de confiance est une façon d’énoncer la probabilité que la valeur vraie de la population se situe dans une plage de valeurs données. Par exemple, un intervalle de confiance de 95 % peut être décrit comme suit : si l’échantillonnage de la population se répète à l’infini, chacun des échantillons donnant un nouvel intervalle de confiance pour une estimation, l’intervalle contiendra la valeur vraie de la population dans 95 % des cas.
Une fois déterminée l’erreur-type d’une estimation, on peut calculer des intervalles de confiance pour les estimations en partant de l’hypothèse qu’en procédant à un échantillonnage répété de la population, les diverses estimations obtenues pour une caractéristique de la population sont réparties selon une distribution normale autour de la valeur vraie de la population. Selon cette hypothèse, il y a environ 68 chances sur 100 que l’écart entre une estimation de l’échantillon et la valeur vraie de la population soit inférieur à une erreur-type, environ 95 chances sur 100 que l’écart soit inférieur à deux erreurs-types et environ 99 chances sur 100 que l’écart soit inférieur à trois erreurs-types. On appelle ces différents degrés de confiance des niveaux de confiance.
L’intervalle de confiance d’une estimation
est généralement exprimé sous la forme de deux nombres, l’un étant inférieur à l’estimation et l’autre supérieur à celle-ci, sous la forme  , où
, où  varie selon le niveau de confiance désiré et l’erreur d’échantillonnage de l’estimation.
varie selon le niveau de confiance désiré et l’erreur d’échantillonnage de l’estimation.
On peut calculer directement les intervalles de confiance d’une estimation à partir des tableaux de la variabilité d’échantillonnage approximative, en trouvant d’abord dans le tableau approprié le coefficient de variation de l’estimation , puis en utilisant la formule suivante pour obtenir l’intervalle de confiance CI correspondant :

où

est le coefficient de variation trouvé pour , et
z = 1 si l’on désire un intervalle de confiance de 68 %
z = 1,6 si l’on désire un intervalle de confiance de 90 %
z = 2 si l’on désire un intervalle de confiance de 95 %
z = 3 si l’on désire un intervalle de confiance de 99 %
Nota : Les lignes directrices concernant la diffusion des estimations de la section 10.4 s’appliquent aussi aux intervalles de confiance. Par conséquent, si l’estimation ne peut être diffusée, alors l’intervalle de confiance ne peut l’être lui non plus.
11.4 Exemple d’utilisation de tableaux de CV pour obtenir des limites de confiance
Voici la marche à suivre pour calculer un intervalle de confiance de 95 % pour la proportion estimée de personnes qui fument tous les jours parmi celles qui fument (d’après l’exemple 2 de la sous-section 11.2).
= 0,777
z = 2
= 0,01 est le coefficient de variation de cette estimation selon les tableaux.

= {0,777 - (2) (0,777) (0,01), 0,777 + (2) (0,777) (0,01)}
= {0,761 , 0,793}
11.5 Comment utiliser les tableaux de CV pour effectuer un test Z
On peut aussi utiliser les erreurs-types pour effectuer des tests d’hypothèses, une technique qui permet de faire la distinction entre les paramètres d’une population à l’aide d’estimations basées sur un échantillon. Ces estimations peuvent être des nombres, des moyennes, des pourcentages, des rapports, etc. Les tests peuvent être effectués à divers niveaux de signification; un niveau de signification est la probabilité de conclure que les caractéristiques sont différentes quand, en fait, elles sont identiques.
Supposons que et sont des estimations basées sur un échantillon pour deux caractéristiques voulues. Supposons aussi que l’erreur-type de la différence  est
. Si z = (
) /
est compris entre -2 et 2, alors on ne peut tirer aucune conclusion à propos de la différence entre les caractéristiques au niveau de signification de 5 %. Toutefois, si ce rapport est inférieur à -2 ou supérieur à +2, la différence observée est significative au niveau de 0,05.
est
. Si z = (
) /
est compris entre -2 et 2, alors on ne peut tirer aucune conclusion à propos de la différence entre les caractéristiques au niveau de signification de 5 %. Toutefois, si ce rapport est inférieur à -2 ou supérieur à +2, la différence observée est significative au niveau de 0,05.
11.6 Exemple d’utilisation des tableaux de CV pour effectuer un test Z
Supposons que nous voulons tester, au niveau de signification de 5 %, l’hypothèse selon laquelle il n’y a pas de différence entre la proportion d’hommes qui fument tous les jours et cette même proportion chez les femmes. Dans l’exemple 3 de la sous-section 11.2, nous avons déterminé que l’erreur-type de la différence entre ces deux estimations est égale à 0,0061. Par conséquent,

Puisque z = 5,25 est supérieur à 2, on doit conclure qu’il existe une différence significative entre les deux estimations au niveau de signification de 0,05. À noter que les deux sous-groupes comparés sont considérés comme étant indépendants, ce qui fait en sorte que le résultat du test est valide.
11.7 Variances ou coefficients de variation exacts
Tous les coefficients de variation qui figurent dans les tableaux de la variabilité d’échantillonnage approximative (tableaux de CV) sont effectivement approximatifs, donc, non officiels.
Le calcul de variance ou coefficient de variation exact n’est pas chose évidente puisqu’il n’existe pas de formule mathématique simple pouvant prendre en compte de tous les aspects du plan d’échantillonnage et de la pondération de l’ESCC. On doit donc avoir recours à d’autres méthodes pour estimer ces mesures de précisions, telles que des méthodes par rééchantillonnage. Parmi celles-ci, la méthode du bootstrap est celle recommandée pour l’analyse des données de l’ESCC.
Le calcul de coefficients de variation (ou tout autre mesure de précision) fait à l’aide de la méthode du bootstrap nécessite toutefois l’accès à de l’information considérée confidentielle qui n’est évidemment pas disponible dans le fichier de microdonnées à grande diffusion. Le calcul doit donc se faire à l’aide du fichier maître. L’accès au fichier maître est discuté à la section 12.3.
Pour le calcul de coefficients de variation, il est conseillé d’utiliser la méthode du bootstrap. Un programme macro, appelé le « Bootvar », a été développé pour faciliter le calcul à l’aide de la méthode bootstrap. Le programme Bootvar est offert en formats SAS et SPSS, et est constitué de macros qui calculent les variances de totaux, ratios, différences entre ratios, et pour des régressions linéaires et logistiques.
Les raisons pour lesquelles un utilisateur pourrait souhaiter connaître la précision exacte de ses estimations sont diverses. En voici quelques-unes.
Premièrement, si un utilisateur désire obtenir des estimations à un niveau géographique autre que ceux présentés dans les tableaux (par exemple, au niveau urbain ou rural), l’utilisation des tableaux de CV publiés ne convient pas parfaitement. Néanmoins, on peut obtenir les coefficients de variation de ce type d’estimations en appliquant la méthode d’estimation par domaine, au moyen du programme de calcul de la variance exacte (le « Bootvar »).
Deuxièmement, si un utilisateur demande des analyses plus complexes, telles que des estimations de paramètres de modèles de régression linéaire ou logistique, les tableaux de CV ne pourront pas fournir les coefficients de variation pour ceux-ci. Certains progiciels statistiques courants permettent d’incorporer les poids d’échantillonnage aux analyses, mais, souvent, les variances produites ne tiennent pas bien compte de la stratification et de la mise en grappe de l’échantillon, contrairement à celles obtenues grâce au programme de calcul de la variance exacte.
Troisièmement, dans le cas de l’estimation de variables quantitatives, il est nécessaire d’utiliser des tableaux distincts pour déterminer l’erreur d’échantillonnage. Or, la plupart des variables de l’ESCC étant de type nominal, de tels tableaux n’ont pas été produits. Les utilisateurs qui souhaitent connaître les coefficients de variation de variables quantitatives peuvent néanmoins obtenir ces derniers grâce au programme de calcul de la variance réelle. À noter, toutefois, que le coefficient de variation d’un total quantitatif est généralement plus grand que celui de l’estimation de type nominal correspondante (c’est–à–dire, l’estimation du nombre de personnes qui contribuent à l’estimation quantitative). Si l’estimation de type nominal correspondante ne peut être diffusée, il en sera de même pour l’estimation quantitative. Par exemple, le coefficient de variation de l’estimation du nombre total de cigarettes que fument chaque jour les personnes qui fument tous les jours serait supérieur à celui de l’estimation correspondante du nombre de personnes qui fument tous les jours. Par conséquent, si on ne peut diffuser le coefficient de variation de cette dernière estimation, on ne pourra non plus diffuser celui de l’estimation quantitative correspondante.
Enfin, un utilisateur qui peut se servir des tableaux de CV, mais obtient ainsi un coefficient de variation compris dans la fourchette marginale (de 16,6 % à 33,3 %), devrait diffuser les estimations associées en y joignant une mise en garde aux utilisateurs quant à la variabilité d’échantillonnage élevée liée aux estimations. Dans ce cas, il serait bon de recalculer le coefficient de corrélation à l’aide du programme de variance exacte pour vérifier si ces estimations peuvent être diffusées sans mise en garde. Cette situation tient au fait que l’estimation des coefficients de variation grâce aux tableaux de la variabilité d’échantillonnage approximative est basée sur une vaste gamme de variables et, donc, jugée grossière, alors que le programme de calcul de la variance réelle produit le coefficient de variation précis associé à la variable en question.
11.8 Seuils pour la diffusion des estimations relatives à l’ ESCC
Le document Tableaux de la variabilité d’échantillonnage approximative, qui est disponible pour les utilisateurs du fichier de partage et du FMGD, présente les tableaux indiquant les seuils de diffusion des totaux selon les estimations pour le Canada, les provinces, les régions sociosanitaires et les CLSC, ainsi que pour les différents groupes d’âge (pour le Canada seulement). Les estimations inférieures à la valeur indiquée dans la colonne « Marginal » ne peuvent en aucun cas être diffusées.
12.0 Fichiers de microdonnées : description, accès et utilisation
L’ESCC produit trois types de fichiers de microdonnéees: les fichiers maîtres, les fichiers de partage et les fichiers de microdonnées à grande diffusion (FMGD). Le tableau 12.1 contient la liste des fichiers disponibles pour les données de 2010.
12.1 Fichiers maîtres
Les fichiers maîtres contiennent toutes les variables et tous les enregistrements de l’enquête collectés au cours d’une période de collecte. Ces fichiers sont accessibles à Statistique Canada pour usage interne, dans les Centres de données de recherche (CDR) de Statistique Canada et peuvent aussi faire l’objet de demandes de totalisations personnalisées.
12.1.1 Centre de données de recherche
Le Programme des CDR permet aux chercheurs d’utiliser les données d’enquête contenues dans les fichiers maîtres dans un environnement sécuritaire situé dans plusieurs universités à travers le Canada. Les chercheurs doivent soumettre des propositions de recherche qui une fois acceptées leur donneront accès aux CDR. Pour plus de renseignements, consultez la page web suivante: CDR
12.1.2 Totalisations personnalisées
Une autre méthode d’accès aux fichiers maîtres consiste à offrir à tous les utilisateurs de faire appel au personnel du Service à la clientèle de la Division de la statistique de la santé pour produire des totalisations personnalisées. Ce service est offert moyennant le recouvrement des coûts. Il permet aux utilisateurs qui ne savent pas se servir de logiciels de totalisation d’obtenir des résultats personnalisés. Les résultats sont filtrés pour s’assurer qu’ils sont conformes aux normes de confidentialité et de fiabilité avant d’être diffusés. Pour plus de renseignements, communiquez avec le Service à la clientèle (613) 951-1746 ou par courriel à hd-ds@statcan.gc.ca.
12.1.3. Télé-accès
En dernier lieu, le service de télé-accès aux fichiers maîtres de l’enquête est un moyen d’accéder à ces données s’il est impossible de passer par un Centre de recherche en données. On peut fournir à l’acheteur d’un produit de microdonnées un fichier maître de données synthétique ou fichier «fictif» et le cliché d’enregistrement correspondant. Grâce à ces outils, le chercheur peut mettre au point son propre ensemble de programmes analytiques. Il ne lui reste plus qu’à envoyer le code pour les totalisations personnalisées par courrier électronique à cchs-escc@statcan.gc.ca. Le code est transmis au réseau interne protégé de Statistique Canada et traité en regard du fichier maître approprié de données de l’ESCC. Les estimations générées seront communiquées à l’utilisateur, sujet aux directives sur l’analyse et la communication des données tel qu’exposé dans les grandes lignes à la section 10 de ce document. Les résultats sont filtrés pour vérifier qu’ils sont conformes aux normes de confidentialité et de fiabilité, puis, les données de sortie sont renvoyées au client. Ce service est gratuit.
12.2 Fichiers de partage
Les fichiers de partage contiennent toutes les variables et tous les enregistrements des répondants de l’ESCC qui ont accepté de partager leurs données avec les partenaires de partage de Statistique Canada, soitles ministères de la santé des provinces et territoires, Santé Canada et l’Agence de santé de la fonction publique. Statistique Canada demande également aux répondants résidant au Québec leur permission de partager leurs données avec l’Institut de la statistique du Québec. Statistique Canada ne fournit le fichier de partage qu’à ces organisations. Les identificateurs personnels sont retirés des fichiers de partage pour préserver la confidentialité des répondants. Les utilisateurs de ces fichiers doivent au préalable avoir porté serment qu’ils ne divulgueront en aucun temps toute information susceptible d’identifier un répondant à l’enquête.
12.3 Fichiers de microdonnées à grande diffusion
Les fichiers de microdonnées à grande diffusion (FMGD) sont élaborés à partir des fichiers maîtres suivant une technique qui vise à concilier l’impératif d’assurer la confidentialité des répondants et la nécessité de produire des données d’utilité maximale à l’échelle de la région sociosanitaire. Les FMGD doivent répondre à des normes sévères de sécurité et de confidentialité, conformément à la Loi sur la statistique avant qu’ils ne soient diffusés pour l’accès public. Pour s’assurer du respect de ces normes, chaque FMGD est soumis à un processus officiel d’examen et d’approbation par un comité formé de haut gestionnaire de Statistique Canada.
Les variables les plus susceptibles de permettre l’identification d’une personne sont supprimées du fichier ou agrégées en catégories moins détaillées.
Le FMGD contient les données des questions posées sur une période de deux ans. À moins d’exception, ces questions sont habituellement celles comprises dans le contenu commun annuel et dans le contenu commun deux ans, ainsi que dans le contenu optionnel, choisi pour deux ans par les provinces et les territoires.
Les FMGD sont accessibles gratuitement dans les établissement d’enseignement post-secondaires font partie de l’Initiative de démocratisation des données. Ils sont aussi disponibles gratuitement sur demande auprès du Service à la clientèle au 613-951-1746 ou à hd-ds@statcan.gc.ca
| Période de référence | Fichiers | Nom des fichiers | Poids d’échatillonnage | Fichiers de poids bootstrap | Variables incluses | Enregistrement inclus |
|---|---|---|---|---|---|---|
| 2010 | Fichier maître principal | HS.txt | WTS_M | b5.txt | Tous les modules communs annuels et un an. | Enregistrements de tous les répondants |
| Fichier de partage | HS.txt | WTS_S | b5.txt | Tous les modules communs et optionnels. | Enregistrement de tous les répondants qui ont accepté de partager leurs données | |
| 2009–2010 | Fichier maître principal | HS.txt | WTS_M | b5.txt | Tous les modules communs annuels et 2 ans et les modules optionnel choisis pour 2 ans. | Enregistrements de tous les répondants |
| Fichier de partage | HS.txt | WTS_S | b5.txt | Tous les modules communs annuels et 2 ans et les modules optionnel choisis pour 2 ans. | Enregistrement de tous les répondants qui ont accepté de partager leurs données |
12.4 Utilisation des fichiers de l’ ESCC: fichier annuel ou fichier deux ans?
Depuis les diffusions des données de 2008 et de 2007-2008, les utilisateurs qui ont accès aux fichiers de partage ou aux fichiers maîtres ont le choix d’utiliser les fichiers d’un an ou de deux ans. Les décisions concernant la période à utiliser pour une analyse donnée devraient être guidées par le niveau de détail et de qualité requis. Avec un fichier d’un an, il n’y aura pas toujours d’estimations en raison de la qualité associée à des échantillons de taille limitée.
Dans le cadre de l’ESCC, avant d’interpréter et d’utiliser une estimation, il est recommandé de s’assurer que cette estimation rencontre les règles suivantes :
- coefficient de variation 33.3 % ou moins ;
- minimum de 10 répondants ayant la caractéristique dans ce domaine (numérateur);
- total minimum de 20 répondants pour le domaine d’intérêt (dénominateur).
Cela ne sera pas possible dans le cas des caractéristiques rares et des domaines détaillés pour les fichiers d’un an. Les utilisateurs devront plutôt se fier aux fichiers de deux ans ou aux fichiers pluriannuels.
Lorsque l’utilisation d’un fichier d’un an ou de deux ans est possible, l’utilisateur devrait envisager un compromis entre l’exactitude et l’actualité. S’il est important de rendre compte des caractéristiques courantes d’une population le plus précisément possible, les fichiers d’un an sont préférables. Toutefois, du fait de l’augmentation de la taille de l’échantillon, des estimations et des analyses plus détaillées peuvent être effectuées avec les fichiers deux ans.
12.5 Utilisation de la variable de pondération
La variable de pondération WTS_M représente le poids d’échantillonnage pour les fichiers principaux de l’enquête. Pour un répondant donné, ce poids d’échantillonnage peut être interprété comme étant le nombre de personnes que le répondant représente dans la population canadienne.Ce poids doit être utilisé en tout temps dans les calculs d’estimations statistiques, afin de permettre l’inférence à l’échelle de la population.La production de résultats non pondérés n’est pas recommandée. La répartition de l’échantillon, de même que les détails du plan de sondage, peuvent entraîner des résultats biaisés qui ne représentent pas correctement la population. Pour une description plus détaillée du calcul de ce poids, consulter la section 8 sur la pondération. La variable de pondération WTS_M doit être utilisée pour des analyses régionales.
Le module Sécurité alimentaire inclut dans les fichiers de certaines périodes référence mesure des concepts qui s’appliquent non seulement à la situation du répondant, mais à celle de l’ensemble de son ménage. L’analyse des variables peut selon le niveau d’analyse nécessiter le recours à un poids calculé de manière à représenter le nombre de ménages au Canada, plutôt que le nombre de personnes. Cette variable de pondération WTS_HH se trouve dans un fichier distinct (HS_HHWT.txt). Elle peut être utilisée en remplacement de la variable WTS_M pour des analyses au niveau des ménages à l’échelle nationale et provinciale. La variable de pondération WTS_M doit être utilisée pour des analyses régionales.
12.6 Convention appliquée pour nommer les variables à partir de 2007
Les conventions appliquées pour nommer des variables permettent aux utilisateurs des données de repérer et d’utiliser facilement celles–ci en fonction du module et du type de variable. La convention appliquée pour nommer les variables de l’ESCC respectent deux exigences: limiter les noms des variables à huit caractères au plus pour qu’il soit facile de les utiliser avec les logiciels d’analyse et permettre de repérer facilement les variables conceptuellement identiques d’une période de collecte à l’autre de l’enquête. Les questions auxquelles on a apporté des changements entre deux périodes de collecte, qui modifient le concept mesuré par la question, sont entièrement renommées pour éviter toute confusion dans l’analyse.
La convention appliquée pour nommer les variables de l’ESCC a été modifiée à partir de 2007. Ainsi, la lettre correspondant à l’édition de l’enquête (par exemple, A = 2000 (cycle 1.1), C = 2003 (cycle 2.1), et E 2005 = (3.1) n’est plus utilisée dans les noms de variables. Une nouvelle variable (REFPER, format = AAAAMM-AAAAMM ) a été ajoutée aux fichiers de microdonnées afin d’identifier le début et la fin de la période de référence au cours de laquelle les données ont été recueillies. Celle-ci s’avérera utile en particulier pour les utilisateurs désireux d’utiliser les données de plusieurs périodes de collecte à la fois. Ainsi, les noms des variables correspondant à des modules ou à des questions identiques entre une année de collecte et une autre (par exemple, 2007 et 2008) seront les mêmes.
La convention appliquée pour nommer les variables à compter de l’ESCC 2007 utilise jusqu’à huit caractères. Les noms de variables sont structurés de la manière suivante:
Positions 1 à 3: Nom du module/de la section du questionnaire
Position 4: Type de variable (sous-tiret, C, D, F ou G)
Positions 5 à 8: Numéro de la question et option de réponse (s’il s’agit d’une question à réponse multiple)
L’exemple 1 présente la structure du nom de la variable correspondant à la question 202 du module Usage du tabac, c’est–à–dire SMK_202:
Positions 1 à 3: SMK Module sur l’usage du tabac
Position 4: _ (sous-tiret = données recueillies)
Position 5 à 8: 202 numéro de la question
L’exemple 2 présente la structure du nom de la variable correspondant à la question 2 du module Utilisation des soins de santé (HCU_02A) qui constitue une question à réponse multiple:
Positions 1 à 3: HCU Module sur l’utilisation des soins de santé
Position 4: _ (sous-tiret = données recueillies)
Position 5 à 8: 02AA numéro de la question correspondant et option de réponse
Dans les positions 1 à 3, on retrouve l’acronyme de chacun des modules. Ces acronymes apparaissent à côté des noms de modules qui sont tous présentés dans la figure de l’annexe A.
La position 4 désigne le type de variable selon qu’il s’agit d’une variable collectée directement à partir d’une question du questionnaire ( «_»), d’une variable codée («C»), dérivée («D»), groupée («G») ou d’une variable indicatrice («F»)15.
En général, les quatre dernières positions (5 à 8) correspondent à la numérotation de la variable qui figure sur le questionnaire. On supprime la lettre «Q» utilisée pour représenter le mot «question» et on présente tous les numéros de question au moyen d’un groupe de deux ou trois chiffres. Par exemple, la question Q01A du questionnaire devient simplement 01A et la question Q15, simplement 15.
| _ | Variable collectée | Variable qui figure directement sur le questionnaire |
|---|---|---|
| C | Variable codée | Variable codée à partir d’une ou de plusieurs variables collectées (par exemple, code de la Classification type des industries (CTI)) |
| D | Variable dérivée | Variable calculée d’après une ou plusieurs variables collectées ou codées, ordinairement pendant le traitement au bureau central (par exemple, indice de l’état de santé) |
| F | Variable indicatrice | Variable calculée à partir d’une ou de plusieurs variables collectées (comme variable dérivée), mais ordinairement par l’application informatique de collecte des données, aux fins de son utilisation ultérieure durant l’interview (par exemple, indicateur de travail) |
| G | Variable groupée | Variables collectées, codées, supprimées ou dérivées, agrégées en un groupe (par exemple, groupes d’âge) |
Parfois, certaines questions comportent plusieurs réponses alors la position finale dans la séquence du nom de la variable est représentée par une lettre. Pour ce genre de questions, de nouvelles variables sont créées dans le but de différencier un « oui » d’un « non » pour chaque possibilité de réponse. Par exemple, si la question Q2 a 4 réponses possibles, les nouvelles questions seraient Q2A pour la première possibilité, Q2B pour la deuxième, Q2C pour la troisième et ainsi de suite. Si seulement les options 2 et 3 sont choisies, alors Q2A = Non, Q2B = Oui, Q2C = Oui et Q2D = Non.
12.7 Convention appliquée pour nommer les variables avant 2007
Tel que mentionné précédemment, la convention appliquée pour nommer les variables a été modifiée en 2007. On a enlevé l’indicateur du cycle au cours duquel les variables avaient été collectées. Cet indicateur se trouvait à la 4e position de 200 à 2005 (cycles 1.1 à 3.1).
Voici la liste des lettres utilisées dans les fichiers de microdonnées de l’ESCC entre 2000 et 2005 (cycles 1.1 à 3.1) et leur cycle correspondant.
Lettre Cycle et nom du cycle
A 2000 Cycle 1.1 : Enquête sur la santé dans les collectivités canadiennes
B 2002 Cycle 1.2 : Enquête sur la santé dans les collectivités canadiennes, santé mentale et bien–être
C 2003 Cycle 2.1 : Enquête sur la santé dans les collectivités canadiennes
D 2004 Cycle 2.2 : Enquête sur la santé dans les collectivités canadiennes, nutrition
E 2005 Cycle3.1 : Enquête sur la santé dans les collectivités canadiennes
12.8 Lignes directrices pour l’utilisation des variables d’un sous‑échantillon – Ne s’applique pas aux fichiers de 2010 et 2009-2010
12.9 Dictionnaires de données
Des dictionnaires de données distincts comprenant des descriptions d’univers et des fréquences sont fournis pour le fichier maître principal et le fichier de sous–échantillon.
Le traitement des modules de contenu optionnel au dictionnaire de données du fichier maître principal est identique à ce qu’il était lors des cycles antérieurs de l’ESCC. Pour chaque module, un indicateur signale si un répondant donné vit dans une région sociosanitaire où le module a été sélectionné comme contenu optionnel. Lorsque l’indicateur est 2 (non), toutes les variables du module ont des valeurs «sans objet». Par exemple, la variable WSTFOPT indique si le module Stress au travail s’applique à un répondant donné.
12.10 Différences dans le calcul des variables de contenu commun fondé sur différents fichiers
Les variables tirées des modules de contenu commun peuvent être estimées à partir de l’un ou l’autre des deux fichiers de données lors qu’un fichier un an et un fichier deux ans sont disponibles. Selon le fichier utilisé, des différences très faibles seront observées.
Toutes les estimations officielles faites par Statistique Canada des variables des modules de contenu commun sont fondées sur le poids d’échantillonnage du fichier maître principal.
Annexe A – Contenu de l’Enquête sur la santé dans les collectivités canadiennes (2009–2010)
| Contenu commun annuel (toutes les regions sociosanitaires) | |||||
|---|---|---|---|---|---|
|
|
Administration et renseignements sociodémographiques
|
|||
| Contenu commun deux ans (toutes les regions sociosanitaires) | |||||
| 2009-2010 : Blessure et santé fonctionnelle | 2009 seulement : Accès aux services de sions de santé i | 2010 seulement : Utilisation des soins de santé et fardeau économique | |||
|
|
|
Utilisation des soins de santé
|
Fardeau économique
|
|
| Contenu optionnel (certaines régions sociosanitaires) | |||||
|
|
|
|
||
| Réponse rapide | |||||
2009
|
2010
|
||||
| i Demandé à un sous-échantillon de répondants. Ces modules de contenu commun un an n’ont pas été demandés aux répondants des territoires. | |||||
Annexe B – Sélection du contenu optionnel par province et territoire (2010 et 2009–2010)
Signes conventionnels dans les tableaux
| Description | Terre- Neuve-et- Labrador |
Île-du- Prince- Édouard |
Nouvelle- Écosse |
Nouveau- Brunswick |
Québec | Ontario | Manitoba | Saskatchewan | Alberta | Colombie- Britannique |
Yukon | Territoires du Nord- Ouest |
Nunavut |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accès aix services de soins de santé (ACC) | … | … | … | … | … | • | … | … | … | … | … | … | … |
| Activités physiques – Installations au travail (PAF) | … | … | • | … | … | … | … | … | … | … | … | … | … |
| Activités sédentaires (SAC) | • | … | … | … | … | … | • | … | … | • | … | … | … |
| Auto-examen des seins (BSX) | … | … | … | … | … | … | … | … | … | … | • | … | … |
| Bien-être psychologique (PWB) | … | … | … | • | … | … | … | … | … | … | … | … | … |
| Changements faits pour améliorer la santé (CIH) | … | • | • | … | … | … | … | … | … | • | • | … | … |
| Choix alimentaires (FDC) | … | … | • | … | • | … | … | … | … | … | • | • | … |
| Conduite et sécurité (DRV) | • | … | … | … | … | • | … | … | • | … | • | … | … |
| Consommation d’alcool – Dépendance (ALD) | … | … | … | … | … | … | … | … | … | … | … | … | … |
| Consommation d’alcool au cours de la dernière semaine (ALW) | • | … | … | … | … | • | … | • | … | … | … | … | … |
| Consultations au sujet de la santé mentale (CMH) | … | • | … | • | • | • | • | • | • | … | • | • | … |
| Contrôle de soi (MAS) | … | … | … | … | … | … | • | … | … | … | … | • | … |
| Couverture d’assurance (INS) | … | … | … | … | … | … | … | … | … | … | … | … | • |
| Dépistage du cancer de la prostate (PSA) | • | • | • | … | … | … | … | … | … | … | • | • | … |
| Dépistage du cancer du côlon et du rectum (CCS) | • | • | • | • | … | • | … | • | … | … | • | • | • |
| Dépression (DEP) | … | • | … | … | • | … | … | • | • | • | … | • | • |
| Détresse (DIS) | … | … | … | … | • | … | … | • | • | … | … | • | … |
| Estime de soi (SFE) | … | … | … | … | • | … | … | … | … | • | … | • | … |
| État de santé (SF-36) (SFR) | … | … | … | … | … | … | • | … | … | … | … | … | … |
| Examen des seins (BRX) | … | • | … | … | … | … | … | • | … | … | • | • | • |
| Examens de la vue (EYX) | … | … | • | … | … | • | … | … | … | … | • | … | … |
| Expériences maternelles – Consommation d’alcool au cours de la grossesse (MXA) | … | … | … | … | … | … | … | … | • | … | • | … | … |
| Expériences maternelles – Usage du tabac au cours de la grossesse (MXS) | … | … | … | … | … | • | … | … | • | … | • | … | … |
| Jeu excessif (CPG) | … | … | … | • | … | … | … | … | • | … | … | … | • |
| Mammographie (MAM) | • | … | • | • | … | … | … | … | • | … | … | • | … |
| Mesures de sécurité à la maison (HMS) | … | … | … | … | … | … | … | … | … | … | … | … | … |
| Organismes à but non lucratif – Participation (ORG) | … | … | … | … | … | … | … | … | … | • | … | • | … |
| Pensées suicidaires et tentatives de suicide (SUI) | • | … | … | … | … | … | … | … | • | • | … | … | • |
| Protection contre le soleil (SSB) | … | • | • | … | • | … | … | … | … | … | … | … | … |
| Santé bucco-dentaire 2 (OH2) | … | • | … | … | … | • | … | … | … | … | … | … | … |
| Satisfaction à l’égard de la vie (SWL) | … | … | … | … | … | … | … | … | … | • | … | … | … |
| Satisfaction à l’égard du système de soins de santé (HCS) | • | … | … | … | … | • | … | • | … | … | … | • | … |
| Satisfaction des patients à l’égard des services de soins de santé (PAS) | … | … | … | … | … | • | … | … | … | … | … | … | … |
| Satisfaction des patients à l’égard des soins de santé communautaires (PSC) | … | … | • | … | … | … | … | … | • | … | … | … | … |
| Sécurité alimentaire (FSC) | • | … | • | … | • | • | • | • | • | • | • | • | • |
| Services de soins de santé à domicile (HMC) | … | … | … | … | … | • | … | … | … | … | … | … | … |
| Soins pour le diabète (DIA) | • | • | … | … | … | … | … | … | … | … | … | … | … |
| Soutien social – Disponibilité (SSA) | … | … | … | • | • | … | … | • | … | • | … | • | … |
| Soutien social – Utilisation (SSU) | … | … | … | • | … | … | … | … | … | • | … | … | … |
| Stress – Faire face au stress (STC) | … | … | … | … | … | … | … | … | … | … | • | … | … |
| Stress – Sources (STS) | … | … | • | … | … | … | … | … | … | … | • | … | … |
| Temps d’attente (WTM) | … | … | … | … | … | • | … | … | … | … | … | … | … |
| Tension artérielle – Vérification (BPC) | … | • | … | • | … | … | … | … | … | … | • | • | … |
| Test pap (PAP) | … | • | • | … | … | … | … | … | … | … | • | … | • |
| Usage de drogues illicites (IDG) | … | … | • | … | • | … | • | … | … | … | … | … | • |
| Usage de suppléments alimentaires - Vitamines et minéraux (DSU) | … | … | … | … | … | … | … | … | … | … | … | • | … |
| Usage du tabac - Autres produits du tabac (TAL) | … | … | … | … | … | • | … | … | … | … | … | … | … |
| Usage du tabac – Consultation d’un médecin (SPC) | … | … | … | … | … | … | • | … | … | … | • | … | … |
| Usage du tabac – Les étapes du changement (SCH) | … | … | … | … | … | … | • | … | … | … | … | … | … |
| Usage du tabac - Méthodes pour cesser de fumer (SCA) | … | … | … | … | … | … | … | … | … | … | • | … | • |
| Visites chez le dentiste (DEN) | … | • | • | … | … | • | … | … | … | … | • | … | … |
Note : • représente les sélectionnés
Signes conventionnels dans les tableaux
| Description | Terre- Neuve-et- Labrador |
Île-du- Prince- Édouard |
Nouvelle- Écosse |
Nouveau- Brunswick |
Québec | Ontario | Manitoba | Saskatchewan | Alberta | Colombie- Britannique |
Yukon | Territoires du Nord- Ouest |
Nunavut |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accès aix services de soins de santé (ACC) | … | … | … | … | … | • | … | … | … | … | … | … | … |
| Activités physiques – Installations au travail (PAF) | … | … | • | … | … | … | … | … | … | … | … | … | … |
| Activités sédentaires (SAC) | • | … | … | … | … | … | • | … | … | • | … | … | … |
| Auto-examen des seins (BSX) | … | … | … | … | … | … | … | … | … | … | • | … | … |
| Bien-être psychologique (PWB) | … | … | … | • | … | … | … | … | … | … | … | … | … |
| Changements faits pour améliorer la santé (CIH) | … | • | • | … | … | … | … | … | … | • | • | … | … |
| Choix alimentaires (FDC) | … | … | • | … | • | … | … | … | … | … | • | • | … |
| Conduite et sécurité (DRV) | • | … | … | … | … | • | … | … | • | … | • | … | … |
| Consommation d’alcool – Dépendance (ALD) | … | … | … | … | … | … | … | … | … | … | … | … | … |
| Consommation d’alcool au cours de la dernière semaine (ALW) | • | … | … | … | … | • | … | • | … | … | … | … | … |
| Consultations au sujet de la santé mentale (CMH) | … | • | … | • | • | • | • | • | • | … | • | • | … |
| Contrôle de soi (MAS) | … | … | … | … | … | … | • | … | … | … | … | • | … |
| Couverture d’assurance (INS) | … | … | … | … | … | … | … | … | … | … | … | … | • |
| Dépistage du cancer de la prostate (PSA) | • | • | • | … | … | … | … | … | … | … | • | • | … |
| Dépistage du cancer du côlon et du rectum (CCS) | • | • | • | • | … | • | … | • | … | … | • | • | • |
| Dépression (DEP) | … | • | … | … | • | … | … | • | • | • | … | • | • |
| Détresse (DIS) | … | … | … | … | • | … | … | • | • | … | … | • | … |
| Estime de soi (SFE) | … | … | … | … | • | … | … | … | … | • | … | • | … |
| État de santé (SF-36) (SFR) | … | … | … | … | … | … | • | … | … | … | … | … | … |
| Examen des seins (BRX) | … | • | … | … | … | … | … | • | … | … | • | • | • |
| Examens de la vue (EYX) | … | … | • | … | … | • | … | … | … | … | • | … | … |
| Expériences maternelles – Consommation d’alcool au cours de la grossesse (MXA) | … | … | … | … | … | … | … | … | • | … | • | … | … |
| Expériences maternelles – Usage du tabac au cours de la grossesse (MXS) | … | … | … | … | … | • | … | … | • | … | • | … | … |
| Jeu excessif (CPG) | … | … | … | • | … | … | … | … | • | … | … | … | • |
| Mammographie (MAM) | • | … | • | • | … | … | … | … | • | … | … | • | … |
| Mesures de sécurité à la maison (HMS) | … | … | … | … | … | … | … | … | … | … | … | … | … |
| Organismes à but non lucratif – Participation (ORG) | … | … | … | … | … | … | … | … | … | • | … | • | … |
| Pensées suicidaires et tentatives de suicide (SUI) | • | … | … | … | … | … | … | … | • | • | … | … | • |
| Protection contre le soleil (SSB) | … | • | • | … | • | … | … | … | … | … | … | … | … |
| Santé bucco-dentaire 2 (OH2) | … | • | … | … | … | • | … | … | … | … | … | … | … |
| Satisfaction à l’égard de la vie (SWL) | … | … | … | … | … | … | … | … | … | • | … | … | … |
| Satisfaction à l’égard du système de soins de santé (HCS) | • | … | … | … | … | • | … | • | … | … | … | • | … |
| Satisfaction des patients à l’égard des services de soins de santé (PAS) | … | … | … | … | … | • | … | … | … | … | … | … | … |
| Satisfaction des patients à l’égard des soins de santé communautaires (PSC) | … | … | • | … | … | … | … | … | • | … | … | … | … |
| Sécurité alimentaire (FSC) | • | … | • | … | • | • | • | • | • | • | • | • | • |
| Services de soins de santé à domicile (HMC) | … | … | … | … | … | • | … | … | … | … | … | … | … |
| Soins pour le diabète (DIA) | • | • | … | … | … | … | … | … | … | … | … | … | … |
| Soutien social – Disponibilité (SSA) | … | … | … | • | • | … | … | • | … | • | … | • | … |
| Soutien social – Utilisation (SSU) | … | … | … | • | … | … | … | … | … | • | … | … | … |
| Stress – Faire face au stress (STC) | … | … | … | … | … | … | … | … | … | … | • | … | … |
| Stress – Sources (STS) | … | … | • | … | … | … | … | … | … | … | • | … | … |
| Temps d’attente (WTM) | … | … | … | … | … | • | … | … | … | … | … | … | … |
| Tension artérielle – Vérification (BPC) | … | • | … | • | … | … | … | … | … | … | • | • | … |
| Test pap (PAP) | … | • | • | … | … | … | … | … | … | … | • | … | • |
| Usage de drogues illicites (IDG) | … | … | • | … | • | … | • | … | … | … | … | … | • |
| Usage de suppléments alimentaires - Vitamines et minéraux (DSU) | … | … | … | … | … | … | … | … | … | … | … | • | … |
| Usage du tabac - Autres produits du tabac (TAL) | … | … | … | … | … | • | … | … | … | … | … | … | … |
| Usage du tabac – Consultation d’un médecin (SPC) | … | … | … | … | … | … | • | … | … | … | • | … | … |
| Usage du tabac – Les étapes du changement (SCH) | … | … | … | … | … | … | • | … | … | … | … | … | … |
| Usage du tabac - Méthodes pour cesser de fumer (SCA) | … | … | … | … | … | … | … | … | … | … | • | … | • |
| Visites chez le dentiste (DEN) | … | • | • | … | … | • | … | … | … | … | • | … | … |
Note : • représente les sélectionnés
Annexe C
| 0 | Canada | |
|---|---|---|
| 10 | Terre-Neuve-et-Labrador | |
| 1011-C | Eastern Regional Integrated Health Authority | |
| 1012-I | Central Regional Integrated Health Authority | |
| 1013-I | Western Regional Integrated Health Authority | |
| 1014-H | Labrador-Grenfell Regional Integrated Health Authority | |
| 11 | Île-du-Prince-Édouard | |
| 1101-D | Kings County | |
| 1102-A | Queens County | |
| 1103-C | Prince County | |
| 12 | Nouvelle-Écosse | |
| 1201-C | Zone 1 | |
| 1202-C | Zone 2 | |
| 1203-C | Zone 3 | |
| 1204-C | Zone 4 | |
| 1205-I | Zone 5 | |
| 1206-A | Zone 6 | |
| 13 | Nouveau-Brunswick | |
| 1301-C | Zone 1 | |
| 1302-C | Zone 2 | |
| 1303-C | Zone 3 | |
| 1304-C | Zone 4 | |
| 1305-I | Zone 5 | |
| 1306-I | Zone 6 | |
| 1307-I | Zone 7 | |
| 24 | Québec | |
| 2401-C | Région du Bas-Saint-Laurent | |
| 2402-C | Région du Saguenay - Lac-Saint-Jean | |
| 2403-A | Région de la Capitale-Nationale | |
| 2404-C | Région de la Mauricie et du Centre-du-Québec | |
| 2405-C | Région de l’Estrie | |
| 2406-G | Région de Montréal | |
| 2407-A | Région de l’Outaouais | |
| 2408-C | Région de l’Abitibi-Témiscamingue | |
| 2409-H | Région de la Côte-Nord | |
| 2410-H | Région du Nord-du-Québec | |
| 2411-I | Région de la Gaspésie - Îles-de-la-Madeleine | |
| 2412-E | Région de la Chaudière-Appalaches | |
| 2413-A | Région de Laval | |
| 2414-E | Région de Lanaudière | |
| 2415-E | Région des Laurentides | |
| 2416-A | Région de la Montérégie | |
| 35 | Ontario par Réseau local d’intégration des services de santé | |
| 3501 | Réseau d’intégration des services de santé de Érié St. Clair | |
| 3502 | Réseau d’intégration des services de santé du Sud-Ouest | |
| 3503 | Réseau d’intégration des services de santé de Waterloo Wellington | |
| 3504 | Réseau d’intégration des services de santé de Hamilton Niagara Haldimand Brant | |
| 3505 | Réseau d’intégration des services de santé du Centre-Ouest | |
| 3506 | Réseau d’intégration des services de santé de Mississauga Halton | |
| 3507 | Réseau d’intégration des services de santé de Toronto-Centre | |
| 3508 | Réseau d’intégration des services de santé du Centre | |
| 3509 | Réseau d’intégration des services de santé du Centre-Est | |
| 3510 | Réseau d’intégration des services de santé du Sud-Est | |
| 3511 | Réseau d’intégration des services de santé de Champlain | |
| 3512 | Réseau d’intégration des services de santé de Simcoe-Nord Muskoka | |
| 3513 | Réseau d’intégration des services de santé du Nord-Est | |
| 3514 | Réseau d’intégration des services de santé du Nord-Ouest | |
| 35 | Ontario par circonscription sanitaire | |
| 3526-C | Circonscription sanitaire du district d’Algoma | |
| 3527-A | Circonscription sanitaire du comté de Brant | |
| 3530-B | Circonscription sanitaire régionale de Durham | |
| 3531-E | Circonscription sanitaire d’Elgin-St. Thomas | |
| 3533-E | Circonscription sanitaire de Grey Bruce | |
| 3534-E | Circonscription sanitaire de Haldimand-Norfolk | |
| 3535-E | Circonscription sanitaire du district de Haliburton, Kawartha et Pine Ridge | |
| 3536-B | Circonscription sanitaire régionale de Halton | |
| 3537-A | Circonscription sanitaire de la cité de Hamilton | |
| 3538-A | Circonscription sanitaire des comtés de Hastings et Prince Edward | |
| 3539-E | Circonscription sanitaire du comté de Huron | |
| 3540-A | Circonscription sanitaire de Chatham-Kent | |
| 3541-A | Circonscription sanitaire de Kingston, Frontenac et Lennox et Addington | |
| 3542-A | Circonscription sanitaire de Lambton | |
| 3543-E | Circonscription sanitaire de Leeds, Grenville et Lanark | |
| 3544-A | Circonscription sanitaire de Middlesex-London | |
| 3546-A | Circonscription sanitaire régionale de Niagara | |
| 3547-C | Circonscription sanitaire du district de North Bay Parry Sound | |
| 3549-H | Circonscription sanitaire du Nord-Ouest | |
| 3551-B | Circonscription sanitaire de la cité d’Ottawa | |
| 3552-E | Circonscription sanitaire du comté d’Oxford | |
| 3553-B | Circonscription sanitaire régionale de Peel | |
| 3554-E | Circonscription sanitaire du district de Perth | |
| 3555-A | Circonscription sanitaire du comté et de la cité de Peterborough | |
| 3556-H | Circonscription sanitaire de Porcupine | |
| 3557-E | Circonscription sanitaire du comté et du district de Renfrew | |
| 3558-E | Circonscription sanitaire de l’Est de l’Ontario | |
| 3560-E | Circonscription sanitaire du district de Simcoe Muskoka | |
| 3561-C | Circonscription sanitaire de Sudbury et son district | |
| 3562-C | Circonscription sanitaire du district de Thunder Bay | |
| 3563-C | Circonscription sanitaire de Timiskaming | |
| 3565-B | Circonscription sanitaire de Waterloo | |
| 3566-B | Circonscription sanitaire de Wellington-Dufferin-Guelph | |
| 3568-B | Circonscription sanitaire de Windsor-Comté d’Essex | |
| 3570-B | Circonscription sanitaire de York | |
| 3595-G | Circonscription sanitaire de la cité de Toronto | |
| 46 | Manitoba | |
| 4610-A | Winnipeg Regional Health Authority | |
| 4615-A | Brandon Regional Health Authority | |
| 4620-E | North Eastman Regional Health Authority | |
| 4625-E | South Eastman Regional Health Authority | |
| 4630-E | Interlake Regional Health Authority | |
| 4640-D | Central Regional Health Authority | |
| 4645-D | Assiniboine Regional Health Authority | |
| 4660-D | Parkland Regional Health Authority | |
| 4670-H | NOR–MAN Regional Health Authority | |
| 4685-F | Burntwood/Churchill | |
| 47 | Saskatchewan | |
| 4701-D | Sun Country Regional Health Authority | |
| 4702-D | Five Hills Regional Health Authority | |
| 4703-D | Cypress Regional Health Authority | |
| 4704-A | Regina Qu’Appelle Regional Health Authority | |
| 4705-D | Sunrise Regional Health Authority | |
| 4706-A | Saskatoon Regional Health Authority | |
| 4707-D | Heartland Regional Health Authority | |
| 4708-D | Kelsey Trail Regional Health Authority | |
| 4709-C | Prince Albert Parkland Regional Health Authority | |
| 4710-H | Prairie North Regional Health Authority | |
| 4714-F | Mamawetan/Keewatin/Athabasca | |
| 48 | Alberta | |
| 4831-A | South Zone | |
| 4832-B | Calgary Zone | |
| 4833-E | Central Zone | |
| 4834-B | Edmonton Zone | |
| 4835-E | North Zone | |
| 59 | Colombie-Britannique | |
| 5911-E | East Kootenay Health Service Delivery Area | |
| 5912-C | Kootenay-Boundary Health Service Delivery Area | |
| 5913-A | Okanagan Health Service Delivery Area | |
| 5914-C | Thompson/Cariboo Health Service Delivery Area | |
| 5921-A | Fraser East Health Service Delivery Area | |
| 5922-B | Fraser North Health Service Delivery Area | |
| 5923-B | Fraser South Health Service Delivery Area | |
| 5931-B | Richmond Health Service Delivery Area | |
| 5932-G | Vancouver Health Service Delivery Area | |
| 5933-B | North Shore/Coast Garibaldi Health Service Delivery Area | |
| 5941-A | South Vancouver Island Health Service Delivery Area | |
| 5942-A | Central Vancouver Island Health Service Delivery Area | |
| 5943-C | North Vancouver Island Health Service Delivery Area | |
| 5951-H | Northwest Health Service Delivery Area | |
| 5952-H | Northern Interior Health Service Delivery Area | |
| 5953-H | Northeast Health Service Delivery Area | |
| 60 | Yukon | |
| 6001-H | Yukon | |
| 61 | Territoires du Nord-Ouest | |
| 6101-H | Territoires du Nord-Ouest | |
| 62 | Nunavut – 10 communautés les plus grandes | |
| 6201-F | Nunavut – 10 communautés les plus grandes | |
| A | Groupe de régions homologues A | |
| B | Groupe de régions homologues B | |
| C | Groupe de régions homologues C | |
| D | Groupe de régions homologues D | |
| E | Groupe de régions homologues E | |
| F | Groupe de régions homologues F | |
| G | Groupe de régions homologues G | |
| H | Groupe de régions homologues H | |
| I | Groupe de régions homologues I | |
Annexe D – Répartition de l’échantillon par région sociosanitaire et par base de sondage de l’ESCC et Répartition par réseau local d’intégration des services de santé (RLISS) et par base de sondage de l’ESCC en Ontario
| Géographie | Base aréolaire | Bases téléphoniques | Combiné | |||
|---|---|---|---|---|---|---|
| Province/ Territoires–Région socio–sanitaire |
Nombre attendu de répondants | taille d’échantillon brute | Nombre attendu de répondants | taille d’échantillon brute | Nombre attendu de répondants | taille d’échantillon brute |
| Canada | ||||||
| Total | 31 092 | 47 287 | 34 632 | 60 424 | 65 724 | 107 711 |
| Terre-Neuve-et-Labrador | ||||||
| Total | 943 | 1 384 | 1 062 | 1 578 | 2 005 | 2 962 |
| 1011 | 381 | 554 | 429 | 642 | 810 | 1 196 |
| 1012 | 221 | 340 | 249 | 374 | 470 | 714 |
| 1013 | 200 | 277 | 225 | 326 | 425 | 603 |
| 1014 | 141 | 214 | 159 | 236 | 300 | 450 |
| Île-du-Prince-Édouard | ||||||
| Total | 471 | 828 | 530 | 986 | 1 001 | 1 814 |
| 1101 | 84 | 151 | 94 | 184 | 178 | 335 |
| 1102 | 216 | 380 | 244 | 446 | 460 | 826 |
| 1103 | 171 | 297 | 192 | 356 | 363 | 653 |
| Nouvelle-Écosse | ||||||
| Total | 1 184 | 1 839 | 1 337 | 2 004 | 2 521 | 3 843 |
| 1201 | 186 | 280 | 210 | 320 | 396 | 600 |
| 1202 | 150 | 229 | 170 | 254 | 320 | 483 |
| 1203 | 169 | 263 | 191 | 306 | 360 | 569 |
| 1204 | 165 | 297 | 185 | 268 | 350 | 565 |
| 1205 | 197 | 257 | 223 | 336 | 420 | 593 |
| 1206 | 317 | 513 | 358 | 520 | 675 | 1 033 |
| Nouveau-Brunswick | ||||||
| Total | 1 211 | 1 890 | 1 364 | 2 070 | 2 575 | 3 960 |
| 1301 | 235 | 357 | 265 | 402 | 500 | 759 |
| 1302 | 228 | 388 | 257 | 402 | 485 | 790 |
| 1303 | 221 | 369 | 249 | 382 | 470 | 751 |
| 1304 | 127 | 187 | 143 | 216 | 270 | 403 |
| 1305 | 118 | 186 | 132 | 202 | 250 | 388 |
| 1306 | 162 | 212 | 183 | 274 | 345 | 486 |
| 1307 | 120 | 191 | 135 | 192 | 255 | 383 |
| Québec | ||||||
| Total | 5 520 | 7 935 | 6 625 | 11 778 | 12 145 | 19 713 |
| 2401 | 282 | 372 | 318 | 496 | 600 | 868 |
| 2402 | 295 | 426 | 333 | 528 | 628 | 954 |
| 2403 | 436 | 659 | 490 | 848 | 926 | 1 507 |
| 2404 | 377 | 517 | 426 | 630 | 803 | 1 147 |
| 2405 | 290 | 467 | 328 | 536 | 618 | 1 003 |
| 2406 | 730 | 1 092 | 823 | 1 526 | 1 553 | 2 618 |
| 2407 | 303 | 475 | 342 | 612 | 645 | 1 087 |
| 2408 | 282 | 364 | 318 | 470 | 600 | 834 |
| 2409 | 282 | 390 | 318 | 622 | 600 | 1 012 |
| 2410 | 0 | 0 | 400 | 1 176 | 400 | 1 176 |
| 2411 | 282 | 404 | 318 | 554 | 600 | 958 |
| 2412 | 340 | 454 | 383 | 694 | 723 | 1 148 |
| 2413 | 315 | 462 | 355 | 636 | 670 | 1 098 |
| 2414 | 337 | 481 | 381 | 636 | 718 | 1 117 |
| 2415 | 358 | 532 | 403 | 708 | 761 | 1 240 |
| 2416 | 611 | 840 | 689 | 1 106 | 1 300 | 1 946 |
| Ontario | ||||||
| Total | 10 317 | 15 867 | 11 855 | 20 898 | 22 172 | 36 765 |
| 3526 | 200 | 280 | 225 | 406 | 425 | 686 |
| 3527 | 190 | 295 | 215 | 364 | 405 | 659 |
| 3530 | 383 | 610 | 432 | 706 | 815 | 1 316 |
| 3531 | 160 | 240 | 180 | 310 | 340 | 550 |
| 3533 | 236 | 361 | 266 | 490 | 502 | 851 |
| 3534 | 182 | 287 | 204 | 370 | 386 | 657 |
| 3535 | 223 | 384 | 252 | 470 | 475 | 854 |
| 3536 | 331 | 483 | 374 | 634 | 705 | 1 117 |
| 3537 | 388 | 626 | 437 | 794 | 825 | 1 420 |
| 3538 | 221 | 363 | 249 | 406 | 470 | 769 |
| 3539 | 139 | 191 | 156 | 286 | 295 | 477 |
| 3540 | 188 | 241 | 212 | 368 | 400 | 609 |
| 3541 | 237 | 440 | 268 | 472 | 505 | 912 |
| 3542 | 204 | 289 | 231 | 440 | 435 | 729 |
| 3543 | 223 | 333 | 252 | 420 | 475 | 753 |
| 3544 | 353 | 581 | 397 | 644 | 750 | 1 225 |
| 3546 | 360 | 538 | 405 | 674 | 765 | 1 212 |
| 3547 | 188 | 301 | 212 | 406 | 400 | 707 |
| 3549 | 169 | 302 | 223 | 437 | 392 | 739 |
| 3551 | 482 | 797 | 543 | 896 | 1 025 | 1 693 |
| 3552 | 176 | 243 | 199 | 312 | 375 | 555 |
| 3553 | 626 | 903 | 706 | 1 286 | 1 332 | 2 189 |
| 3554 | 153 | 203 | 172 | 268 | 325 | 471 |
| 3555 | 200 | 311 | 225 | 408 | 425 | 719 |
| 3556 | 176 | 265 | 199 | 338 | 375 | 603 |
| 3557 | 176 | 272 | 199 | 362 | 375 | 634 |
| 3558 | 244 | 335 | 276 | 466 | 520 | 801 |
| 3560 | 476 | 729 | 631 | 1 157 | 1 107 | 1 886 |
| 3561 | 254 | 419 | 286 | 476 | 540 | 895 |
| 3562 | 260 | 431 | 389 | 700 | 649 | 1 131 |
| 3563 | 118 | 214 | 132 | 242 | 250 | 456 |
| 3565 | 360 | 551 | 405 | 674 | 765 | 1 225 |
| 3566 | 273 | 365 | 310 | 488 | 583 | 853 |
| 3568 | 336 | 498 | 379 | 668 | 715 | 1 166 |
| 3570 | 444 | 659 | 500 | 916 | 944 | 1 575 |
| 3595 | 988 | 1 527 | 1 114 | 2 144 | 2 102 | 3 671 |
| Manitoba | ||||||
| Total | 1 765 | 2 502 | 1 985 | 3 258 | 3 750 | 5 760 |
| 4610 | 496 | 698 | 559 | 858 | 1 055 | 1 556 |
| 4615 | 132 | 188 | 148 | 216 | 280 | 404 |
| 4620 | 118 | 161 | 132 | 242 | 250 | 403 |
| 4625 | 141 | 177 | 159 | 256 | 300 | 433 |
| 4630 | 162 | 268 | 183 | 330 | 345 | 598 |
| 4640 | 188 | 248 | 212 | 318 | 400 | 566 |
| 4645 | 167 | 231 | 188 | 286 | 355 | 517 |
| 4660 | 125 | 180 | 140 | 228 | 265 | 408 |
| 4670 | 118 | 170 | 132 | 230 | 250 | 400 |
| 4685 | 118 | 181 | 132 | 294 | 250 | 475 |
| Saskatchewan | ||||||
| Total | 1 697 | 2 465 | 2 163 | 4 192 | 3 860 | 6 657 |
| 4701 | 141 | 189 | 159 | 262 | 300 | 451 |
| 4702 | 141 | 222 | 159 | 248 | 300 | 470 |
| 4703 | 125 | 184 | 140 | 222 | 265 | 406 |
| 4704 | 291 | 414 | 329 | 528 | 620 | 942 |
| 4705 | 146 | 215 | 164 | 260 | 310 | 475 |
| 4706 | 310 | 453 | 350 | 534 | 660 | 987 |
| 4707 | 127 | 210 | 143 | 210 | 270 | 420 |
| 4708 | 122 | 168 | 138 | 210 | 260 | 378 |
| 4709 | 153 | 222 | 172 | 298 | 325 | 520 |
| 4710 | 141 | 189 | 159 | 274 | 300 | 463 |
| 4714 | 0 | 0 | 250 | 1 146 | 250 | 1 146 |
| Alberta1 | ||||||
| Total | 2 868 | 4 538 | 3 232 | 5 484 | 6 100 | 10 022 |
| 4821 | 240 | 313 | 270 | 434 | 510 | 747 |
| 4822 | 195 | 269 | 220 | 356 | 415 | 625 |
| 4823 | 656 | 1 043 | 739 | 1 228 | 1 395 | 2 271 |
| 4824 | 329 | 541 | 371 | 616 | 700 | 1 157 |
| 4825 | 209 | 297 | 236 | 400 | 445 | 697 |
| 4826 | 616 | 1 032 | 694 | 1 152 | 1 310 | 2 184 |
| 4827 | 254 | 417 | 286 | 528 | 540 | 945 |
| 4828 | 219 | 334 | 246 | 420 | 465 | 754 |
| 4829 | 150 | 293 | 170 | 350 | 320 | 643 |
| Colombie-Britannique | ||||||
| Total | 3 781 | 5 921 | 4 264 | 7 372 | 8 045 | 13 293 |
| 5911 | 143 | 219 | 162 | 286 | 305 | 505 |
| 5912 | 146 | 194 | 164 | 268 | 310 | 462 |
| 5913 | 277 | 353 | 313 | 528 | 590 | 881 |
| 5914 | 235 | 357 | 265 | 418 | 500 | 775 |
| 5921 | 244 | 399 | 276 | 456 | 520 | 855 |
| 5922 | 357 | 564 | 403 | 706 | 760 | 1 270 |
| 5923 | 376 | 540 | 424 | 718 | 800 | 1 258 |
| 5931 | 200 | 293 | 225 | 394 | 425 | 687 |
| 5932 | 376 | 644 | 424 | 846 | 800 | 1 490 |
| 5933 | 256 | 441 | 289 | 558 | 545 | 999 |
| 5941 | 317 | 463 | 358 | 610 | 675 | 1 073 |
| 5942 | 247 | 353 | 278 | 440 | 525 | 793 |
| 5943 | 125 | 249 | 140 | 198 | 265 | 447 |
| 5951 | 153 | 273 | 172 | 318 | 325 | 591 |
| 5952 | 200 | 367 | 225 | 374 | 425 | 741 |
| 5903 | 129 | 212 | 146 | 254 | 275 | 466 |
| Yukon | ||||||
| 6001 | 475 | 779 | 125 | 432 | 600 | 1 211 |
| Territoires du Nord-Ouest | ||||||
| 6101 | 510 | 826 | 90 | 372 | 600 | 1 198 |
| Nunavut | ||||||
| 6201 | 350 | 512 | 0 | 0 | 350 | 512 |
|
||||||
| Géographie | Base aréolaire | Bases téléphoniques | Combiné | |||
|---|---|---|---|---|---|---|
| Province/ Territoires RLISS |
Nombre attendu de répondants | taille d’échantillon brute | Nombre attendu de répondants | taille d’échantillon brute | Nombre attendu de répondants | taille d’échantillon brute |
| Ontario | ||||||
| Total | 11 111 | 15 896 | 11 096 | 19 158 | 22 207 | 35 054 |
| 3501 | 776 | 1 033 | 774 | 1 296 | 1 550 | 2 329 |
| 3502 | 1 282 | 1 853 | 1 279 | 2 130 | 2 561 | 3 983 |
| 3503 | 622 | 867 | 620 | 978 | 1 242 | 1 845 |
| 3504 | 1 300 | 1 850 | 1 297 | 2 136 | 2 597 | 3 986 |
| 3505 | 536 | 772 | 533 | 954 | 1 069 | 1 726 |
| 3506 | 558 | 772 | 557 | 942 | 1 115 | 1 714 |
| 3507 | 541 | 855 | 540 | 1 044 | 1 081 | 1 899 |
| 3508 | 706 | 940 | 705 | 1 320 | 1 411 | 2 260 |
| 3509 | 1 056 | 1 469 | 1 052 | 1 830 | 2 108 | 3 299 |
| 3510 | 657 | 941 | 656 | 1 164 | 1 313 | 2 105 |
| 3511 | 1 030 | 1 474 | 1 027 | 1 632 | 2 057 | 3 106 |
| 3512 | 519 | 759 | 531 | 1 026 | 1 050 | 1 785 |
| 3513 | 996 | 1 491 | 994 | 1 680 | 1 990 | 3 171 |
| 3514 | 532 | 819 | 531 | 1 026 | 1 063 | 1 845 |
Annexe E – (2010) – Taux de réponse par région sociosanitaire et par base de sondage de l’ESCC et Taux de réponse par réseau local d’intégration des services de santé (RLISS) et par base de sondage de l’ESCC en Ontario
Signes conventionnels dans les tableaux
| Géographie | Base aréolaire | Bases téléphoniques | Combiné | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Province/Territoires – Région socio-sanitaire |
Nombre ménages cibles | Nombre ménages répondus | Taux de réponses ménages | Nombre–personnes sélectionnées | Nombre–réponses | Taux de réponses personnes | Taux de réponses | Nombre ménages cibles | Nombre ménages réponses | Taux de réponses ménages | Nombre personnes sélectionnées | Nombre réponses | Taux de réponses personnes | Taux de réponses | Taux de réponses combiné |
| Canada | |||||||||||||||
| Total | 40 070 | 33 387 | 83,3 | 33 387 | 30 449 | 91,2 | 76,0 | 48 340 | 37 928 | 78,5 | 37 928 | 32 742 | 86,3 | 67,7 | 71,5 |
| Terre-Neuve-et-Labrador | |||||||||||||||
| Total | 1 128 | 999 | 88,6 | 999 | 934 | 93,5 | 82,8 | 1 327 | 1 108 | 83,5 | 1 108 | 936 | 84,5 | 70,5 | 76,2 |
| 1011 | 473 | 414 | 87,5 | 414 | 384 | 92,8 | 81,2 | 556 | 466 | 83,8 | 466 | 397 | 85,2 | 71,4 | 75,9 |
| 1012 | 255 | 228 | 89,4 | 228 | 210 | 92,1 | 82,4 | 295 | 241 | 81,7 | 241 | 204 | 84,6 | 69,2 | 75,3 |
| 1013 | 225 | 200 | 88,9 | 200 | 192 | 96,0 | 85,3 | 285 | 247 | 86,7 | 247 | 216 | 87,4 | 75,8 | 80,0 |
| 1014 | 175 | 157 | 89,7 | 157 | 148 | 94,3 | 84,6 | 191 | 154 | 80,6 | 154 | 119 | 77,3 | 62,3 | 73,0 |
| Île-du-Prince-Édouard | |||||||||||||||
| Total | 641 | 541 | 84,4 | 541 | 491 | 90,8 | 76,6 | 693 | 558 | 80,5 | 558 | 482 | 86,4 | 69,6 | 72,9 |
| 1101 | 104 | 92 | 88,5 | 92 | 82 | 89,1 | 78,8 | 60 | 39 | 65,0 | 39 | 32 | 82,1 | 53,3 | 69,5 |
| 1102 | 293 | 233 | 79,5 | 233 | 207 | 88,8 | 70,6 | 383 | 309 | 80,7 | 309 | 269 | 87,1 | 70,2 | 70,4 |
| 1103 | 244 | 216 | 88,5 | 216 | 202 | 93,5 | 82,8 | 250 | 210 | 84,0 | 210 | 181 | 86,2 | 72,4 | 77,5 |
| Nouvelle-Écosse | |||||||||||||||
| Total | 1 496 | 1 264 | 84,5 | 1 264 | 1 144 | 90,5 | 76,5 | 1 644 | 1 368 | 83,2 | 1 368 | 1 198 | 87,6 | 72,9 | 74,6 |
| 1201 | 215 | 198 | 92,1 | 198 | 184 | 92,9 | 85,6 | 261 | 213 | 81,6 | 213 | 188 | 88,3 | 72,0 | 78,2 |
| 1202 | 199 | 169 | 84,9 | 169 | 158 | 93,5 | 79,4 | 204 | 174 | 85,3 | 174 | 156 | 89,7 | 76,5 | 77,9 |
| 1203 | 194 | 162 | 83,5 | 162 | 154 | 95,1 | 79,4 | 248 | 208 | 83,9 | 208 | 189 | 90,9 | 76,2 | 77,6 |
| 1204 | 221 | 188 | 85,1 | 188 | 173 | 92,0 | 78,3 | 215 | 177 | 82,3 | 177 | 153 | 86,4 | 71,2 | 74,8 |
| 1205 | 216 | 188 | 87,0 | 188 | 168 | 89,4 | 77,8 | 271 | 221 | 81,5 | 221 | 191 | 86,4 | 70,5 | 73,7 |
| 1206 | 451 | 359 | 79,6 | 359 | 307 | 85,5 | 68,1 | 445 | 375 | 84,3 | 375 | 321 | 85,6 | 72,1 | 70,1 |
| Nouveau-Brunswick | |||||||||||||||
| Total | 1 564 | 1 322 | 84,5 | 1 322 | 1 197 | 90,5 | 76,5 | 1 680 | 1 416 | 84,3 | 1 416 | 1 232 | 87,0 | 73,3 | 74,9 |
| 1301 | 301 | 233 | 77,4 | 233 | 209 | 89,7 | 69,4 | 317 | 263 | 83,0 | 263 | 234 | 89,0 | 73,8 | 71,7 |
| 1302 | 295 | 246 | 83,4 | 246 | 228 | 92,7 | 77,3 | 332 | 285 | 85,8 | 285 | 257 | 90,2 | 77,4 | 77,4 |
| 1303 | 304 | 259 | 85,2 | 259 | 241 | 93,1 | 79,3 | 305 | 275 | 90,2 | 275 | 238 | 86,5 | 78,0 | 78,7 |
| 1304 | 159 | 133 | 83,6 | 133 | 117 | 88,0 | 73,6 | 172 | 137 | 79,7 | 137 | 122 | 89,1 | 70,9 | 72,2 |
| 1305 | 158 | 146 | 92,4 | 146 | 133 | 91,1 | 84,2 | 160 | 138 | 86,3 | 138 | 115 | 83,3 | 71,9 | 78,0 |
| 1306 | 185 | 173 | 93,5 | 173 | 156 | 90,2 | 84,3 | 232 | 189 | 81,5 | 189 | 157 | 83,1 | 67,7 | 75,1 |
| 1307 | 162 | 132 | 81,5 | 132 | 113 | 85,6 | 69,8 | 162 | 129 | 79,6 | 129 | 109 | 84,5 | 67,3 | 68,5 |
| Québec | |||||||||||||||
| Total | 6 915 | 5 740 | 83,0 | 5 740 | 5 340 | 93,0 | 77,2 | 9 324 | 7 201 | 77,2 | 7 201 | 6 213 | 86,3 | 66,6 | 71,1 |
| 2401 | 285 | 265 | 93,0 | 265 | 252 | 95,1 | 88,4 | 392 | 314 | 80,1 | 314 | 274 | 87,3 | 69,9 | 77,7 |
| 2402 | 351 | 308 | 87,7 | 308 | 299 | 97,1 | 85,2 | 423 | 336 | 79,4 | 336 | 296 | 88,1 | 70,0 | 76,9 |
| 2403 | 629 | 513 | 81,6 | 513 | 480 | 93,6 | 76,3 | 748 | 591 | 79,0 | 591 | 510 | 86,3 | 68,2 | 71,9 |
| 2404 | 429 | 373 | 86,9 | 373 | 350 | 93,8 | 81,6 | 548 | 438 | 79,9 | 438 | 391 | 89,3 | 71,4 | 75,8 |
| 2405 | 381 | 301 | 79,0 | 301 | 270 | 89,7 | 70,9 | 437 | 361 | 82,6 | 361 | 332 | 92,0 | 76,0 | 73,6 |
| 2406 | 950 | 714 | 75,2 | 714 | 655 | 91,7 | 68,9 | 1 346 | 921 | 68,4 | 921 | 763 | 82,8 | 56,7 | 61,8 |
| 2407 | 412 | 337 | 81,8 | 337 | 310 | 92,0 | 75,2 | 503 | 401 | 79,7 | 401 | 357 | 89,0 | 71,0 | 72,9 |
| 2408 | 299 | 266 | 89,0 | 266 | 247 | 92,9 | 82,6 | 402 | 326 | 81,1 | 326 | 280 | 85,9 | 69,7 | 75,2 |
| 2409 | 329 | 291 | 88,4 | 291 | 276 | 94,8 | 83,9 | 426 | 324 | 76,1 | 324 | 273 | 84,3 | 64,1 | 72,7 |
| 2410 | . | . | . | . | . | . | . | 402 | 325 | 80,8 | 325 | 282 | 86,8 | 70,1 | 70,1 |
| 2411 | 344 | 316 | 91,9 | 316 | 291 | 92,1 | 84,6 | 432 | 329 | 76,2 | 329 | 271 | 82,4 | 62,7 | 72,4 |
| 2412 | 394 | 345 | 87,6 | 345 | 320 | 92,8 | 81,2 | 561 | 451 | 80,4 | 451 | 394 | 87,4 | 70,2 | 74,8 |
| 2413 | 432 | 341 | 78,9 | 341 | 317 | 93,0 | 73,4 | 557 | 415 | 74,5 | 415 | 344 | 82,9 | 61,8 | 66,8 |
| 2414 | 417 | 331 | 79,4 | 331 | 310 | 93,7 | 74,3 | 543 | 417 | 76,8 | 417 | 363 | 87,1 | 66,9 | 70,1 |
| 2415 | 483 | 384 | 79,5 | 384 | 357 | 93,0 | 73,9 | 594 | 457 | 76,9 | 457 | 392 | 85,8 | 66,0 | 69,5 |
| 2416 | 780 | 655 | 84,0 | 655 | 606 | 92,5 | 77,7 | 1 010 | 795 | 78,7 | 795 | 691 | 86,9 | 68,4 | 72,5 |
| Ontario | |||||||||||||||
| Total | 13 545 | 11 061 | 81,7 | 11 061 | 9 952 | 90,0 | 73,5 | 17 800 | 13 590 | 76,3 | 13 590 | 11 574 | 85,2 | 65,0 | 68,7 |
| 3526 | 250 | 216 | 86,4 | 216 | 199 | 92,1 | 79,6 | 326 | 264 | 81,0 | 264 | 223 | 84,5 | 68,4 | 73,3 |
| 3527 | 264 | 219 | 83,0 | 219 | 194 | 88,6 | 73,5 | 297 | 238 | 80,1 | 238 | 201 | 84,5 | 67,7 | 70,4 |
| 3530 | 557 | 445 | 79,9 | 445 | 403 | 90,6 | 72,4 | 613 | 473 | 77,2 | 473 | 399 | 84,4 | 65,1 | 68,5 |
| 3531 | 224 | 201 | 89,7 | 201 | 192 | 95,5 | 85,7 | 254 | 199 | 78,3 | 199 | 172 | 86,4 | 67,7 | 76,2 |
| 3533 | 302 | 263 | 87,1 | 263 | 242 | 92,0 | 80,1 | 377 | 290 | 76,9 | 290 | 258 | 89,0 | 68,4 | 73,6 |
| 3534 | 241 | 202 | 83,8 | 202 | 175 | 86,6 | 72,6 | 311 | 254 | 81,7 | 254 | 218 | 85,8 | 70,1 | 71,2 |
| 3535 | 256 | 208 | 81,3 | 208 | 187 | 89,9 | 73,0 | 332 | 267 | 80,4 | 267 | 234 | 87,6 | 70,5 | 71,6 |
| 3536 | 441 | 357 | 81,0 | 357 | 312 | 87,4 | 70,7 | 553 | 433 | 78,3 | 433 | 362 | 83,6 | 65,5 | 67,8 |
| 3537 | 547 | 415 | 75,9 | 415 | 369 | 88,9 | 67,5 | 668 | 485 | 72,6 | 485 | 404 | 83,3 | 60,5 | 63,6 |
| 3538 | 318 | 277 | 87,1 | 277 | 233 | 84,1 | 73,3 | 335 | 261 | 77,9 | 261 | 223 | 85,4 | 66,6 | 69,8 |
| 3539 | 162 | 143 | 88,3 | 143 | 132 | 92,3 | 81,5 | 212 | 171 | 80,7 | 171 | 149 | 87,1 | 70,3 | 75,1 |
| 3540 | 205 | 191 | 93,2 | 191 | 183 | 95,8 | 89,3 | 291 | 222 | 76,3 | 222 | 197 | 88,7 | 67,7 | 76,6 |
| 3541 | 366 | 267 | 73,0 | 267 | 231 | 86,5 | 63,1 | 355 | 284 | 80,0 | 284 | 254 | 89,4 | 71,5 | 67,3 |
| 3542 | 235 | 199 | 84,7 | 199 | 187 | 94,0 | 79,6 | 352 | 270 | 76,7 | 270 | 230 | 85,2 | 65,3 | 71,0 |
| 3543 | 292 | 247 | 84,6 | 247 | 230 | 93,1 | 78,8 | 378 | 298 | 78,8 | 298 | 268 | 89,9 | 70,9 | 74,3 |
| 3544 | 493 | 407 | 82,6 | 407 | 375 | 92,1 | 76,1 | 580 | 449 | 77,4 | 449 | 373 | 83,1 | 64,3 | 69,7 |
| 3546 | 472 | 396 | 83,9 | 396 | 372 | 93,9 | 78,8 | 576 | 458 | 79,5 | 458 | 390 | 85,2 | 67,7 | 72,7 |
| 3547 | 227 | 196 | 86,3 | 196 | 171 | 87,2 | 75,3 | 281 | 215 | 76,5 | 215 | 184 | 85,6 | 65,5 | 69,9 |
| 3549 | 279 | 204 | 73,1 | 204 | 176 | 86,3 | 63,1 | 414 | 325 | 78,5 | 325 | 277 | 85,2 | 66,9 | 65,4 |
| 3551 | 738 | 561 | 76,0 | 561 | 487 | 86,8 | 66,0 | 788 | 606 | 76,9 | 606 | 524 | 86,5 | 66,5 | 66,3 |
| 3552 | 221 | 180 | 81,4 | 180 | 173 | 96,1 | 78,3 | 278 | 220 | 79,1 | 220 | 197 | 89,5 | 70,9 | 74,1 |
| 3553 | 775 | 651 | 84,0 | 651 | 559 | 85,9 | 72,1 | 1 097 | 811 | 73,9 | 811 | 643 | 79,3 | 58,6 | 64,2 |
| 3554 | 178 | 155 | 87,1 | 155 | 150 | 96,8 | 84,3 | 225 | 185 | 82,2 | 185 | 164 | 88,6 | 72,9 | 77,9 |
| 3555 | 256 | 218 | 85,2 | 218 | 201 | 92,2 | 78,5 | 303 | 230 | 75,9 | 230 | 196 | 85,2 | 64,7 | 71,0 |
| 3556 | 235 | 195 | 83,0 | 195 | 176 | 90,3 | 74,9 | 290 | 227 | 78,3 | 227 | 196 | 86,3 | 67,6 | 70,9 |
| 3557 | 209 | 192 | 91,9 | 192 | 172 | 89,6 | 82,3 | 287 | 231 | 80,5 | 231 | 206 | 89,2 | 71,8 | 76,2 |
| 3558 | 305 | 255 | 83,6 | 255 | 229 | 89,8 | 75,1 | 401 | 317 | 79,1 | 317 | 279 | 88,0 | 69,6 | 72,0 |
| 3560 | 538 | 430 | 79,9 | 430 | 381 | 88,6 | 70,8 | 1 086 | 846 | 77,9 | 846 | 721 | 85,2 | 66,4 | 67,9 |
| 3561 | 341 | 296 | 86,8 | 296 | 262 | 88,5 | 76,8 | 368 | 292 | 79,3 | 292 | 261 | 89,4 | 70,9 | 73,8 |
| 3562 | 388 | 283 | 72,9 | 283 | 246 | 86,9 | 63,4 | 699 | 541 | 77,4 | 541 | 461 | 85,2 | 66,0 | 65,0 |
| 3563 | 134 | 114 | 85,1 | 114 | 107 | 93,9 | 79,9 | 211 | 163 | 77,3 | 163 | 141 | 86,5 | 66,8 | 71,9 |
| 3565 | 486 | 400 | 82,3 | 400 | 370 | 92,5 | 76,1 | 605 | 471 | 77,9 | 471 | 417 | 88,5 | 68,9 | 72,1 |
| 3566 | 316 | 275 | 87,0 | 275 | 246 | 89,5 | 77,8 | 410 | 329 | 80,2 | 329 | 297 | 90,3 | 72,4 | 74,8 |
| 3568 | 422 | 335 | 79,4 | 335 | 307 | 91,6 | 72,7 | 595 | 447 | 75,1 | 447 | 366 | 81,9 | 61,5 | 66,2 |
| 3570 | 603 | 485 | 80,4 | 485 | 428 | 88,2 | 71,0 | 815 | 571 | 70,1 | 571 | 467 | 81,8 | 57,3 | 63,1 |
| 3595 | 1 269 | 983 | 77,5 | 983 | 895 | 91,0 | 70,5 | 1 837 | 1 247 | 67,9 | 1 247 | 1 022 | 82,0 | 55,6 | 61,7 |
| Manitoba | |||||||||||||||
| Total | 2 168 | 1 840 | 84,9 | 1 840 | 1 682 | 91,4 | 77,6 | 2 412 | 2 024 | 83,9 | 2 024 | 1 774 | 87,6 | 73,5 | 75,5 |
| 4610 | 640 | 496 | 77,5 | 496 | 438 | 88,3 | 68,4 | 734 | 627 | 85,4 | 627 | 553 | 88,2 | 75,3 | 72,1 |
| 4615 | 169 | 143 | 84,6 | 143 | 139 | 97,2 | 82,2 | 172 | 152 | 88,4 | 152 | 134 | 88,2 | 77,9 | 80,1 |
| 4620 | 131 | 115 | 87,8 | 115 | 106 | 92,2 | 80,9 | 153 | 130 | 85,0 | 130 | 111 | 85,4 | 72,5 | 76,4 |
| 4625 | 177 | 158 | 89,3 | 158 | 147 | 93,0 | 83,1 | 202 | 173 | 85,6 | 173 | 155 | 89,6 | 76,7 | 79,7 |
| 4630 | 187 | 161 | 86,1 | 161 | 148 | 91,9 | 79,1 | 217 | 176 | 81,1 | 176 | 158 | 89,8 | 72,8 | 75,7 |
| 4640 | 226 | 198 | 87,6 | 198 | 183 | 92,4 | 81,0 | 261 | 224 | 85,8 | 224 | 190 | 84,8 | 72,8 | 76,6 |
| 4645 | 197 | 182 | 92,4 | 182 | 167 | 91,8 | 84,8 | 217 | 179 | 82,5 | 179 | 163 | 91,1 | 75,1 | 79,7 |
| 4660 | 140 | 125 | 89,3 | 125 | 115 | 92,0 | 82,1 | 172 | 146 | 84,9 | 146 | 127 | 87,0 | 73,8 | 77,6 |
| 4670 | 138 | 118 | 85,5 | 118 | 107 | 90,7 | 77,5 | 147 | 112 | 76,2 | 112 | 93 | 83,0 | 63,3 | 70,2 |
| 4685 | 163 | 144 | 88,3 | 144 | 132 | 91,7 | 81,0 | 137 | 105 | 76,6 | 105 | 90 | 85,7 | 65,7 | 74,0 |
| Saskatchewan | |||||||||||||||
| Total | 2 034 | 1 771 | 87,1 | 1 771 | 1 664 | 94,0 | 81,8 | 2 742 | 2 244 | 81,8 | 2 244 | 1 985 | 88,5 | 72,4 | 76,4 |
| 4701 | 160 | 153 | 95,6 | 153 | 151 | 98,7 | 94,4 | 203 | 171 | 84,2 | 171 | 157 | 91,8 | 77,3 | 84,8 |
| 4702 | 197 | 178 | 90,4 | 178 | 171 | 96,1 | 86,8 | 207 | 167 | 80,7 | 167 | 142 | 85,0 | 68,6 | 77,5 |
| 4703 | 140 | 134 | 95,7 | 134 | 130 | 97,0 | 92,9 | 176 | 134 | 76,1 | 134 | 120 | 89,6 | 68,2 | 79,1 |
| 4704 | 351 | 310 | 88,3 | 310 | 284 | 91,6 | 80,9 | 426 | 347 | 81,5 | 347 | 307 | 88,5 | 72,1 | 76,1 |
| 4705 | 155 | 142 | 91,6 | 142 | 139 | 97,9 | 89,7 | 209 | 177 | 84,7 | 177 | 161 | 91,0 | 77,0 | 82,4 |
| 4706 | 390 | 306 | 78,5 | 306 | 273 | 89,2 | 70,0 | 479 | 385 | 80,4 | 385 | 334 | 86,8 | 69,7 | 69,9 |
| 4707 | 154 | 135 | 87,7 | 135 | 131 | 97,0 | 85,1 | 167 | 143 | 85,6 | 143 | 126 | 88,1 | 75,4 | 80,1 |
| 4708 | 134 | 120 | 89,6 | 120 | 113 | 94,2 | 84,3 | 148 | 126 | 85,1 | 126 | 114 | 90,5 | 77,0 | 80,5 |
| 4709 | 192 | 152 | 79,2 | 152 | 141 | 92,8 | 73,4 | 224 | 175 | 78,1 | 175 | 158 | 90,3 | 70,5 | 71,9 |
| 4710 | 161 | 141 | 87,6 | 141 | 131 | 92,9 | 81,4 | 186 | 160 | 86,0 | 160 | 135 | 84,4 | 72,6 | 76,7 |
| 4714 | . | . | . | . | . | . | . | 317 | 259 | 81,7 | 259 | 231 | 89,2 | 72,9 | 72,9 |
| Alberta | |||||||||||||||
| Total | 3 898 | 3 244 | 83,2 | 3 244 | 2 925 | 90,2 | 75,0 | 4 500 | 3 571 | 79,4 | 3 571 | 3 084 | 86,4 | 68,5 | 71,6 |
| 4831 | 497 | 426 | 85,7 | 426 | 400 | 93,9 | 80,5 | 656 | 533 | 81,3 | 533 | 478 | 89,7 | 72,9 | 76,1 |
| 4832 | 917 | 796 | 86,8 | 796 | 728 | 91,5 | 79,4 | 1 026 | 802 | 78,2 | 802 | 682 | 85,0 | 66,5 | 72,6 |
| 4833 | 699 | 569 | 81,4 | 569 | 517 | 90,9 | 74,0 | 812 | 644 | 79,3 | 644 | 552 | 85,7 | 68,0 | 70,7 |
| 4834 | 917 | 727 | 79,3 | 727 | 639 | 87,9 | 69,7 | 988 | 783 | 79,3 | 783 | 685 | 87,5 | 69,3 | 69,5 |
| 4835 | 868 | 726 | 83,6 | 726 | 641 | 88,3 | 73,8 | 1 018 | 809 | 79,5 | 809 | 687 | 84,9 | 67,5 | 70,4 |
| Colombie-Britannique | |||||||||||||||
| Total | 4 977 | 4 143 | 83,2 | 4 143 | 3 760 | 90,8 | 75,5 | 5 869 | 4 552 | 77,6 | 4 552 | 3 991 | 87,7 | 68,0 | 71,5 |
| 5911 | 188 | 167 | 88,8 | 167 | 156 | 93,4 | 83,0 | 226 | 172 | 76,1 | 172 | 156 | 90,7 | 69,0 | 75,4 |
| 5912 | 162 | 145 | 89,5 | 145 | 134 | 92,4 | 82,7 | 185 | 152 | 82,2 | 152 | 132 | 86,8 | 71,4 | 76,7 |
| 5913 | 314 | 290 | 92,4 | 290 | 275 | 94,8 | 87,6 | 462 | 374 | 81,0 | 374 | 330 | 88,2 | 71,4 | 78,0 |
| 5914 | 279 | 245 | 87,8 | 245 | 221 | 90,2 | 79,2 | 320 | 251 | 78,4 | 251 | 222 | 88,4 | 69,4 | 74,0 |
| 5921 | 347 | 284 | 81,8 | 284 | 252 | 88,7 | 72,6 | 352 | 277 | 78,7 | 277 | 247 | 89,2 | 70,2 | 71,4 |
| 5922 | 517 | 436 | 84,3 | 436 | 402 | 92,2 | 77,8 | 591 | 451 | 76,3 | 451 | 382 | 84,7 | 64,6 | 70,8 |
| 5923 | 480 | 396 | 82,5 | 396 | 372 | 93,9 | 77,5 | 587 | 446 | 76,0 | 446 | 380 | 85,2 | 64,7 | 70,5 |
| 5931 | 247 | 197 | 79,8 | 197 | 190 | 96,4 | 76,9 | 307 | 225 | 73,3 | 225 | 183 | 81,3 | 59,6 | 67,3 |
| 5932 | 533 | 400 | 75,0 | 400 | 376 | 94,0 | 70,5 | 639 | 457 | 71,5 | 457 | 405 | 88,6 | 63,4 | 66,6 |
| 5933 | 285 | 222 | 77,9 | 222 | 168 | 75,7 | 58,9 | 442 | 334 | 75,6 | 334 | 289 | 86,5 | 65,4 | 62,9 |
| 5941 | 417 | 355 | 85,1 | 355 | 321 | 90,4 | 77,0 | 509 | 403 | 79,2 | 403 | 360 | 89,3 | 70,7 | 73,5 |
| 5942 | 300 | 264 | 88,0 | 264 | 242 | 91,7 | 80,7 | 359 | 293 | 81,6 | 293 | 263 | 89,8 | 73,3 | 76,6 |
| 5943 | 211 | 174 | 82,5 | 174 | 161 | 92,5 | 76,3 | 165 | 130 | 78,8 | 130 | 120 | 92,3 | 72,7 | 74,7 |
| 5951 | 205 | 165 | 80,5 | 165 | 140 | 84,8 | 68,3 | 227 | 186 | 81,9 | 186 | 167 | 89,8 | 73,6 | 71,1 |
| 5952 | 315 | 253 | 80,3 | 253 | 216 | 85,4 | 68,6 | 300 | 242 | 80,7 | 242 | 214 | 88,4 | 71,3 | 69,9 |
| 5953 | 177 | 150 | 84,7 | 150 | 134 | 89,3 | 75,7 | 198 | 159 | 80,3 | 159 | 141 | 88,7 | 71,2 | 73,3 |
| Yukon | |||||||||||||||
| 6001 | 659 | 573 | 86,9 | 573 | 541 | 94,4 | 82,1 | 201 | 167 | 83,1 | 167 | 158 | 94,6 | 78,6 | 81,3 |
| Territoires du Nord-Ouest | |||||||||||||||
| 6101 | 641 | 556 | 86,7 | 556 | 518 | 93,2 | 80,8 | 148 | 129 | 87,2 | 129 | 115 | 89,1 | 77,7 | 80,2 |
| Nunavut | |||||||||||||||
| 6201 | 404 | 333 | 82,4 | 333 | 301 | 90,4 | 74,5 | . | . | . | . | . | . | . | 74,5 |
| Géographie | Base aréolaire | Bases téléphoniques | Combiné | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Province/ Territoires – RLISS |
Nombre ménages cibles | Nombre ménages réponses | Taux de réponses ménages | Nombre personnes sélectionnées | Nombre réponses | Taux de réponses personnes | Taux de réponses | Nombre ménages cibles | Nombre ménages réponses | Taux de réponses ménages | Nombre personnes sélectionnées | Nombre réponses | Taux de réponses personnes | Taux de réponses | Taux de réponses combiné |
| Ontario | |||||||||||||||
| Total | 13 545 | 11 061 | 81,7 | 11 061 | 9 952 | 90,0 | 73,5 | 17 800 | 13 590 | 76,3 | 13 590 | 11 574 | 85,2 | 65,0 | 68,7 |
| 3501 | 862 | 725 | 84,1 | 725 | 677 | 93,4 | 78,5 | 1 238 | 939 | 75,8 | 939 | 793 | 84,5 | 64,1 | 70,0 |
| 3502 | 1 561 | 1 332 | 85,3 | 1 332 | 1 244 | 93,4 | 79,7 | 1 918 | 1 510 | 78,7 | 1 510 | 1 308 | 86,6 | 68,2 | 73,4 |
| 3503 | 757 | 641 | 84,7 | 641 | 587 | 91,6 | 77,5 | 929 | 731 | 78,7 | 731 | 653 | 89,3 | 70,3 | 73,5 |
| 3504 | 1 666 | 1 342 | 80,6 | 1 342 | 1 210 | 90,2 | 72,6 | 2 008 | 1 554 | 77,4 | 1 554 | 1 319 | 84,9 | 65,7 | 68,8 |
| 3505 | 574 | 474 | 82,6 | 474 | 395 | 83,3 | 68,8 | 870 | 634 | 72,9 | 634 | 509 | 80,3 | 58,5 | 62,6 |
| 3506 | 727 | 605 | 83,2 | 605 | 538 | 88,9 | 74,0 | 918 | 695 | 75,7 | 695 | 558 | 80,3 | 60,8 | 66,6 |
| 3507 | 600 | 468 | 78,0 | 468 | 432 | 92,3 | 72,0 | 926 | 634 | 68,5 | 634 | 529 | 83,4 | 57,1 | 63,0 |
| 3508 | 930 | 735 | 79,0 | 735 | 664 | 90,3 | 71,4 | 1 243 | 872 | 70,2 | 872 | 715 | 82,0 | 57,5 | 63,5 |
| 3509 | 1 320 | 1 069 | 81,0 | 1 069 | 961 | 89,9 | 72,8 | 1 601 | 1 212 | 75,7 | 1 212 | 1 022 | 84,3 | 63,8 | 67,9 |
| 3510 | 893 | 723 | 81,0 | 723 | 631 | 87,3 | 70,7 | 995 | 784 | 78,8 | 784 | 693 | 88,4 | 69,6 | 70,1 |
| 3511 | 1 335 | 1 076 | 80,6 | 1 076 | 951 | 88,4 | 71,2 | 1 546 | 1 210 | 78,3 | 1 210 | 1 058 | 87,4 | 68,4 | 69,7 |
| 3512 | 466 | 367 | 78,8 | 367 | 325 | 88,6 | 69,7 | 1 016 | 785 | 77,3 | 785 | 671 | 85,5 | 66,0 | 67,2 |
| 3513 | 1 187 | 1 017 | 85,7 | 1 017 | 915 | 90,0 | 77,1 | 1 479 | 1 164 | 78,7 | 1 164 | 1 008 | 86,6 | 68,2 | 72,1 |
| 3514 | 667 | 487 | 73,0 | 487 | 422 | 86,7 | 63,3 | 1 113 | 866 | 77,8 | 866 | 738 | 85,2 | 66,3 | 65,2 |
Annexe F – (2009–2010) – Répartition de l’échantillon par région sociosanitaire et par base de sondage de l’ESCC
| Géographie | Base aréolaire | Bases téléphoniques | Combiné | |||
|---|---|---|---|---|---|---|
| Province/ Territoires–Région socio–sanitaire |
Nombre attendu de répondants | taille d’échantillon brute | Nombre attendu de répondants | taille d’échantillon brute | Nombre attendu de répondants | taille d’échantillon brute |
| Canada | ||||||
| Total | 64 228 | 95 175 | 67 258 | 116 344 | 131 486 | 211 519 |
| Terre-Neuve-et-Labrador | ||||||
| Total | 1 946 | 2 788 | 2 064 | 3 174 | 4 010 | 5 962 |
| 1011 | 786 | 1 129 | 834 | 1 290 | 1 620 | 2 419 |
| 1012 | 456 | 673 | 484 | 734 | 940 | 1 407 |
| 1013 | 413 | 559 | 437 | 668 | 850 | 1 227 |
| 1014 | 291 | 428 | 309 | 482 | 600 | 910 |
| Île-du-Prince-Édouard | ||||||
| Total | 972 | 1 613 | 1 030 | 1 934 | 2 002 | 3 547 |
| 1101 | 173 | 310 | 183 | 352 | 356 | 662 |
| 1102 | 446 | 746 | 474 | 866 | 920 | 1 612 |
| 1103 | 353 | 557 | 373 | 716 | 726 | 1 273 |
| Nouvelle-Écosse | ||||||
| Total | 2 445 | 3 742 | 2 596 | 3 924 | 5 041 | 7 666 |
| 1201 | 384 | 586 | 407 | 632 | 791 | 1 218 |
| 1202 | 310 | 465 | 330 | 506 | 640 | 971 |
| 1203 | 349 | 502 | 371 | 576 | 720 | 1 078 |
| 1204 | 340 | 618 | 360 | 538 | 700 | 1 156 |
| 1205 | 407 | 541 | 433 | 660 | 840 | 1 201 |
| 1206 | 655 | 1 030 | 695 | 1 012 | 1 350 | 2 042 |
| Nouveau-Brunswick | ||||||
| Total | 2 500 | 3 830 | 2 650 | 4 008 | 5 150 | 7 838 |
| 1301 | 485 | 744 | 515 | 786 | 1 000 | 1 530 |
| 1302 | 471 | 791 | 499 | 780 | 970 | 1 571 |
| 1303 | 456 | 742 | 484 | 748 | 940 | 1 490 |
| 1304 | 262 | 389 | 278 | 414 | 540 | 803 |
| 1305 | 243 | 356 | 257 | 382 | 500 | 738 |
| 1306 | 335 | 451 | 355 | 514 | 690 | 965 |
| 1307 | 248 | 357 | 262 | 384 | 510 | 741 |
| Québec | ||||||
| Total | 11 394 | 16 039 | 12 895 | 22 776 | 24 289 | 38 815 |
| 2401 | 582 | 755 | 618 | 970 | 1 200 | 1 725 |
| 2402 | 609 | 849 | 647 | 1 074 | 1 256 | 1 923 |
| 2403 | 899 | 1 306 | 953 | 1 574 | 1 852 | 2 880 |
| 2404 | 779 | 1 038 | 827 | 1 242 | 1 606 | 2 280 |
| 2405 | 599 | 922 | 637 | 1 010 | 1 236 | 1 932 |
| 2406 | 1 507 | 2 206 | 1 599 | 2 984 | 3 106 | 5 190 |
| 2407 | 626 | 983 | 664 | 1 134 | 1 290 | 2 117 |
| 2408 | 582 | 747 | 618 | 926 | 1 200 | 1 673 |
| 2409 | 582 | 795 | 618 | 1 180 | 1 200 | 1 975 |
| 2410 | 0 | 0 | 800 | 2 424 | 800 | 2 424 |
| 2411 | 582 | 815 | 618 | 1 070 | 1 200 | 1 885 |
| 2412 | 702 | 938 | 744 | 1 330 | 1 446 | 2 268 |
| 2413 | 650 | 942 | 690 | 1 200 | 1 340 | 2 142 |
| 2414 | 696 | 961 | 740 | 1 224 | 1 436 | 2 185 |
| 2415 | 738 | 1 068 | 783 | 1 332 | 1 521 | 2 400 |
| 2416 | 1 261 | 1 715 | 1 339 | 2 102 | 2 600 | 3 817 |
| Ontario | ||||||
| Total | 21 428 | 31 763 | 22 951 | 40 056 | 44 379 | 71 819 |
| 3526 | 413 | 598 | 437 | 742 | 850 | 1 340 |
| 3527 | 393 | 577 | 417 | 676 | 810 | 1 253 |
| 3530 | 791 | 1 184 | 839 | 1 354 | 1 630 | 2 538 |
| 3531 | 330 | 479 | 350 | 586 | 680 | 1 065 |
| 3533 | 476 | 720 | 518 | 940 | 994 | 1 660 |
| 3534 | 375 | 577 | 397 | 718 | 772 | 1 295 |
| 3535 | 461 | 700 | 489 | 884 | 950 | 1 584 |
| 3536 | 684 | 982 | 726 | 1 186 | 1 410 | 2 168 |
| 3537 | 801 | 1 248 | 849 | 1 490 | 1 650 | 2 738 |
| 3538 | 456 | 680 | 484 | 844 | 940 | 1 524 |
| 3539 | 287 | 419 | 303 | 562 | 590 | 981 |
| 3540 | 388 | 491 | 412 | 698 | 800 | 1 189 |
| 3541 | 490 | 820 | 520 | 922 | 1 010 | 1 742 |
| 3542 | 422 | 575 | 448 | 806 | 870 | 1 381 |
| 3543 | 461 | 668 | 489 | 798 | 950 | 1 466 |
| 3544 | 728 | 1 145 | 772 | 1 274 | 1 500 | 2 419 |
| 3546 | 743 | 1 043 | 787 | 1 292 | 1 530 | 2 335 |
| 3547 | 388 | 611 | 412 | 790 | 800 | 1 401 |
| 3549 | 369 | 637 | 423 | 875 | 792 | 1 512 |
| 3551 | 995 | 1 547 | 1 055 | 1 706 | 2 050 | 3 253 |
| 3552 | 364 | 488 | 386 | 594 | 750 | 1 082 |
| 3553 | 1 297 | 1 852 | 1 376 | 2 492 | 2 673 | 4 344 |
| 3554 | 316 | 426 | 334 | 514 | 650 | 940 |
| 3555 | 413 | 627 | 437 | 792 | 850 | 1 419 |
| 3556 | 364 | 551 | 386 | 602 | 750 | 1 153 |
| 3557 | 364 | 550 | 386 | 686 | 750 | 1 236 |
| 3558 | 504 | 690 | 536 | 862 | 1 040 | 1 552 |
| 3560 | 1 036 | 1 534 | 1 191 | 2 231 | 2 227 | 3 765 |
| 3561 | 524 | 812 | 556 | 956 | 1 080 | 1 768 |
| 3562 | 592 | 914 | 720 | 1 288 | 1 312 | 2 202 |
| 3563 | 243 | 397 | 257 | 458 | 500 | 855 |
| 3565 | 743 | 1 111 | 787 | 1 274 | 1 530 | 2 385 |
| 3566 | 566 | 747 | 602 | 944 | 1 168 | 1 691 |
| 3568 | 694 | 995 | 736 | 1 268 | 1 430 | 2 263 |
| 3570 | 917 | 1 286 | 972 | 1 786 | 1 889 | 3 072 |
| 3595 | 2 040 | 3 081 | 2 162 | 4 166 | 4 202 | 7 247 |
| Manitoba | ||||||
| Total | 3 642 | 5 086 | 3 858 | 6 246 | 7 500 | 11 332 |
| 4610 | 1 024 | 1 412 | 1 086 | 1 644 | 2 110 | 3 056 |
| 4615 | 272 | 388 | 288 | 444 | 560 | 832 |
| 4620 | 243 | 329 | 257 | 470 | 500 | 799 |
| 4625 | 291 | 382 | 309 | 496 | 600 | 878 |
| 4630 | 335 | 540 | 355 | 612 | 690 | 1 152 |
| 4640 | 388 | 501 | 412 | 594 | 800 | 1 095 |
| 4645 | 345 | 470 | 365 | 556 | 710 | 1 026 |
| 4660 | 258 | 370 | 272 | 438 | 530 | 808 |
| 4670 | 243 | 352 | 257 | 458 | 500 | 810 |
| 4685 | 243 | 341 | 257 | 534 | 500 | 875 |
| Saskatchewan | ||||||
| Total | 3 503 | 5 020 | 4 217 | 8 290 | 7 720 | 13 310 |
| 4701 | 291 | 376 | 309 | 490 | 600 | 866 |
| 4702 | 291 | 423 | 309 | 512 | 600 | 935 |
| 4703 | 258 | 369 | 272 | 444 | 530 | 813 |
| 4704 | 601 | 848 | 639 | 1 032 | 1 240 | 1 880 |
| 4705 | 301 | 431 | 319 | 488 | 620 | 919 |
| 4706 | 640 | 908 | 680 | 1 062 | 1 320 | 1 970 |
| 4707 | 262 | 423 | 278 | 426 | 540 | 849 |
| 4708 | 252 | 357 | 268 | 414 | 520 | 771 |
| 4709 | 316 | 508 | 334 | 604 | 650 | 1 112 |
| 4710 | 291 | 378 | 309 | 532 | 600 | 910 |
| 4714 | 0 | 0 | 500 | 2 286 | 500 | 2 286 |
| Alberta1 | ||||||
| Total | 5 920 | 9 028 | 6 280 | 10 560 | 12 200 | 19 588 |
| 4821 | 495 | 686 | 525 | 842 | 1 020 | 1 528 |
| 4822 | 403 | 528 | 427 | 674 | 830 | 1 202 |
| 4823 | 1 354 | 2 039 | 1 436 | 2 350 | 2 790 | 4 389 |
| 4824 | 679 | 1 054 | 721 | 1 204 | 1 400 | 2 258 |
| 4825 | 432 | 587 | 458 | 736 | 890 | 1 323 |
| 4826 | 1 271 | 2 020 | 1 349 | 2 298 | 2 620 | 4 318 |
| 4827 | 524 | 821 | 556 | 990 | 1 080 | 1 811 |
| 4828 | 452 | 710 | 478 | 816 | 930 | 1 526 |
| 4829 | 310 | 585 | 330 | 650 | 640 | 1 235 |
| Colombie-Britannique | ||||||
| Total | 7 808 | 12 013 | 8 287 | 13 984 | 16 095 | 25 997 |
| 5911 | 296 | 451 | 314 | 550 | 610 | 1 001 |
| 5912 | 301 | 430 | 319 | 502 | 620 | 932 |
| 5913 | 572 | 747 | 608 | 1 014 | 1 180 | 1 761 |
| 5914 | 485 | 689 | 515 | 820 | 1 000 | 1 509 |
| 5921 | 504 | 752 | 536 | 858 | 1 040 | 1 610 |
| 5922 | 737 | 1 107 | 783 | 1 294 | 1 520 | 2 401 |
| 5923 | 776 | 1 145 | 824 | 1 408 | 1 600 | 2 553 |
| 5931 | 413 | 580 | 438 | 730 | 851 | 1 310 |
| 5932 | 776 | 1 283 | 824 | 1 560 | 1 600 | 2 843 |
| 5933 | 529 | 937 | 562 | 1 032 | 1 091 | 1 969 |
| 5941 | 655 | 958 | 696 | 1 138 | 1 351 | 2 096 |
| 5942 | 510 | 726 | 541 | 824 | 1 051 | 1 550 |
| 5943 | 258 | 430 | 272 | 408 | 530 | 838 |
| 5951 | 316 | 584 | 335 | 636 | 651 | 1 220 |
| 5952 | 413 | 674 | 438 | 734 | 851 | 1 408 |
| 5903 | 267 | 518 | 284 | 476 | 551 | 994 |
| Yukon | ||||||
| 6001 | 950 | 1 517 | 250 | 738 | 1 200 | 2 255 |
| Territoires du Nord-Ouest | ||||||
| 6101 | 1 020 | 1 642 | 180 | 654 | 1 200 | 2 296 |
| Nunavut | ||||||
| 6201 | 700 | 1 092 | 0 | 0 | 700 | 1 092 |
|
||||||
| Géographie | Base aréolaire | Bases téléphoniques | Combiné | |||
|---|---|---|---|---|---|---|
| Province/ Territoires RLISS |
Nombre attendu de répondants | taille d’échantillon brute | Nombre attendu de répondants | taille d’échantillon brute | Nombre attendu de répondants | taille d’échantillon brute |
| Ontario | ||||||
| Total | 21 428 | 31 763 | 22 952 | 40 056 | 44 379 | 71 819 |
| 3501 | 1 504 | 2 061 | 1 596 | 2 772 | 3 100 | 4 833 |
| 3502 | 2 487 | 3 654 | 2 635 | 4 434 | 5 122 | 8 088 |
| 3503 | 1 206 | 1 710 | 1 278 | 2 046 | 2 484 | 3 756 |
| 3504 | 2 521 | 3 738 | 2 673 | 4 508 | 5 194 | 8 246 |
| 3505 | 1 032 | 1 484 | 1 093 | 1 966 | 2 125 | 3 450 |
| 3506 | 1 082 | 1 548 | 1 148 | 2 004 | 2 230 | 3 552 |
| 3507 | 1 050 | 1 675 | 1 115 | 2 164 | 2 165 | 3 839 |
| 3508 | 1 369 | 1 929 | 1 453 | 2 706 | 2 822 | 4 635 |
| 3509 | 2 047 | 3 039 | 2 169 | 3 808 | 4 216 | 6 847 |
| 3510 | 1 274 | 1 984 | 1 352 | 2 360 | 2 626 | 4 344 |
| 3511 | 1 996 | 2 972 | 2 118 | 3 458 | 4 114 | 6 430 |
| 3512 | 967 | 1 446 | 1 130 | 2 119 | 2 097 | 3 565 |
| 3513 | 1 932 | 2 970 | 2 048 | 3 548 | 3 980 | 6 518 |
| 3514 | 961 | 1 552 | 1 143 | 2 163 | 2 104 | 3 715 |
Annexe G – (2009–2010) –Taux de réponse par région sociosanitaire et par base de sondage de l’ESCC et Taux de réponse par réseau local d’intégration des services de santé (RLISS) et par base de sondage de l’ESCC en Ontario
Signes conventionnels dans les tableaux
| Géographie | Base aréolaire | Bases téléphoniques | Combiné | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Province/Territoires – Région socio-sanitaire |
Nombre ménages cibles | Nombre ménages répondus | Taux de réponses ménages | Nombre–personnes sélectionnées | Nombre–réponses | Taux de réponses personnes | Taux de réponses | Nombre ménages cibles | Nombre ménages réponses | Taux de réponses ménages | Nombre personnes sélectionnées | Nombre réponses | Taux de réponses personnes | Taux de réponses | Taux de réponses combiné |
| Canada | |||||||||||||||
| Total | 80 206 | 66 694 | 83,2 | 66 694 | 60 924 | 91,3 | 76,0 | 92 465 | 73 147 | 79,1 | 73 147 | 63 946 | 87,4 | 69,2 | 72,3 |
| Terre-Neuve-et-Labrador | |||||||||||||||
| Total | 2 269 | 1 990 | 87,7 | 1 990 | 1 840 | 92,5 | 81,1 | 2 663 | 2 245 | 84,3 | 2 245 | 1 928 | 85,9 | 72,4 | 76,4 |
| 1011 | 942 | 800 | 84,9 | 800 | 726 | 90,8 | 77,1 | 1 104 | 933 | 84,5 | 933 | 799 | 85,6 | 72,4 | 74,5 |
| 1012 | 506 | 457 | 90,3 | 457 | 420 | 91,9 | 83,0 | 601 | 500 | 83,2 | 500 | 431 | 86,2 | 71,7 | 76,9 |
| 1013 | 460 | 417 | 90,7 | 417 | 396 | 95,0 | 86,1 | 563 | 479 | 85,1 | 479 | 425 | 88,7 | 75,5 | 80,3 |
| 1014 | 361 | 316 | 87,5 | 316 | 298 | 94,3 | 82,5 | 395 | 333 | 84,3 | 333 | 273 | 82,0 | 69,1 | 75,5 |
| Île-du-Prince-Édouard | |||||||||||||||
| Total | 1 261 | 1 065 | 84,5 | 1 065 | 961 | 90,2 | 76,2 | 1 338 | 1 103 | 82,4 | 1 103 | 952 | 86,3 | 71,2 | 73,6 |
| 1101 | 207 | 182 | 87,9 | 182 | 166 | 91,2 | 80,2 | 115 | 86 | 74,8 | 86 | 72 | 83,7 | 62,6 | 73,9 |
| 1102 | 601 | 494 | 82,2 | 494 | 439 | 88,9 | 73,0 | 721 | 595 | 82,5 | 595 | 514 | 86,4 | 71,3 | 72,1 |
| 1103 | 453 | 389 | 85,9 | 389 | 356 | 91,5 | 78,6 | 502 | 422 | 84,1 | 422 | 366 | 86,7 | 72,9 | 75,6 |
| Nouvelle-Écosse | |||||||||||||||
| Total | 3 027 | 2 572 | 85,0 | 2 572 | 2 325 | 90,4 | 76,8 | 3 204 | 2 706 | 84,5 | 2 706 | 2 387 | 88,2 | 74,5 | 75,6 |
| 1201 | 438 | 412 | 94,1 | 412 | 383 | 93,0 | 87,4 | 501 | 419 | 83,6 | 419 | 376 | 89,7 | 75,0 | 80,8 |
| 1202 | 388 | 330 | 85,1 | 330 | 306 | 92,7 | 78,9 | 409 | 350 | 85,6 | 350 | 314 | 89,7 | 76,8 | 77,8 |
| 1203 | 380 | 318 | 83,7 | 318 | 302 | 95,0 | 79,5 | 445 | 373 | 83,8 | 373 | 338 | 90,6 | 76,0 | 77,6 |
| 1204 | 468 | 408 | 87,2 | 408 | 376 | 92,2 | 80,3 | 435 | 369 | 84,8 | 369 | 322 | 87,3 | 74,0 | 77,3 |
| 1205 | 456 | 385 | 84,4 | 385 | 347 | 90,1 | 76,1 | 529 | 434 | 82,0 | 434 | 376 | 86,6 | 71,1 | 73,4 |
| 1206 | 897 | 719 | 80,2 | 719 | 611 | 85,0 | 68,1 | 885 | 761 | 86,0 | 761 | 661 | 86,9 | 74,7 | 71,4 |
| Nouveau-Brunswick | |||||||||||||||
| Total | 3 057 | 2 605 | 85,2 | 2 605 | 2 351 | 90,2 | 76,9 | 3 285 | 2 803 | 85,3 | 2 803 | 2 484 | 88,6 | 75,6 | 76,2 |
| 1301 | 622 | 497 | 79,9 | 497 | 448 | 90,1 | 72,0 | 644 | 547 | 84,9 | 547 | 489 | 89,4 | 75,9 | 74,0 |
| 1302 | 585 | 488 | 83,4 | 488 | 454 | 93,0 | 77,6 | 644 | 557 | 86,5 | 557 | 494 | 88,7 | 76,7 | 77,1 |
| 1303 | 558 | 481 | 86,2 | 481 | 440 | 91,5 | 78,9 | 615 | 543 | 88,3 | 543 | 489 | 90,1 | 79,5 | 79,2 |
| 1304 | 326 | 275 | 84,4 | 275 | 245 | 89,1 | 75,2 | 329 | 277 | 84,2 | 277 | 249 | 89,9 | 75,7 | 75,4 |
| 1305 | 287 | 262 | 91,3 | 262 | 228 | 87,0 | 79,4 | 309 | 271 | 87,7 | 271 | 237 | 87,5 | 76,7 | 78,0 |
| 1306 | 388 | 362 | 93,3 | 362 | 330 | 91,2 | 85,1 | 429 | 357 | 83,2 | 357 | 306 | 85,7 | 71,3 | 77,8 |
| 1307 | 291 | 240 | 82,5 | 240 | 206 | 85,8 | 70,8 | 315 | 251 | 79,7 | 251 | 220 | 87,6 | 69,8 | 70,3 |
| Québec | |||||||||||||||
| Total | 14 002 | 11 529 | 82,3 | 11 529 | 10 752 | 93,3 | 76,8 | 18 091 | 14 204 | 78,5 | 14 204 | 12 383 | 87,2 | 68,4 | 72,1 |
| 2401 | 599 | 555 | 92,7 | 555 | 529 | 95,3 | 88,3 | 767 | 630 | 82,1 | 630 | 553 | 87,8 | 72,1 | 79,2 |
| 2402 | 716 | 613 | 85,6 | 613 | 585 | 95,4 | 81,7 | 880 | 730 | 83,0 | 730 | 655 | 89,7 | 74,4 | 77,7 |
| 2403 | 1 237 | 986 | 79,7 | 986 | 931 | 94,4 | 75,3 | 1 375 | 1 094 | 79,6 | 1 094 | 965 | 88,2 | 70,2 | 72,6 |
| 2404 | 886 | 762 | 86,0 | 762 | 714 | 93,7 | 80,6 | 1 074 | 870 | 81,0 | 870 | 784 | 90,1 | 73,0 | 76,4 |
| 2405 | 735 | 566 | 77,0 | 566 | 524 | 92,6 | 71,3 | 828 | 692 | 83,6 | 692 | 631 | 91,2 | 76,2 | 73,9 |
| 2406 | 1 951 | 1 449 | 74,3 | 1 449 | 1 339 | 92,4 | 68,6 | 2 604 | 1 843 | 70,8 | 1 843 | 1 533 | 83,2 | 58,9 | 63,1 |
| 2407 | 829 | 675 | 81,4 | 675 | 620 | 91,9 | 74,8 | 941 | 759 | 80,7 | 759 | 680 | 89,6 | 72,3 | 73,4 |
| 2408 | 618 | 547 | 88,5 | 547 | 509 | 93,1 | 82,4 | 800 | 655 | 81,9 | 655 | 573 | 87,5 | 71,6 | 76,3 |
| 2409 | 675 | 591 | 87,6 | 591 | 566 | 95,8 | 83,9 | 817 | 624 | 76,4 | 624 | 530 | 84,9 | 64,9 | 73,5 |
| 2410 | . | . | . | . | . | . | . | 964 | 775 | 80,4 | 775 | 682 | 88,0 | 70,7 | 70,7 |
| 2411 | 685 | 631 | 92,1 | 631 | 589 | 93,3 | 86,0 | 825 | 638 | 77,3 | 638 | 543 | 85,1 | 65,8 | 75,0 |
| 2412 | 829 | 734 | 88,5 | 734 | 687 | 93,6 | 82,9 | 1 102 | 873 | 79,2 | 873 | 769 | 88,1 | 69,8 | 75,4 |
| 2413 | 860 | 675 | 78,5 | 675 | 625 | 92,6 | 72,7 | 1 057 | 809 | 76,5 | 809 | 686 | 84,8 | 64,9 | 68,4 |
| 2414 | 850 | 690 | 81,2 | 690 | 639 | 92,6 | 75,2 | 1 054 | 827 | 78,5 | 827 | 719 | 86,9 | 68,2 | 71,3 |
| 2415 | 958 | 764 | 79,7 | 764 | 696 | 91,1 | 72,7 | 1 091 | 854 | 78,3 | 854 | 745 | 87,2 | 68,3 | 70,3 |
| 2416 | 1 574 | 1 291 | 82,0 | 1 291 | 1 199 | 92,9 | 76,2 | 1 912 | 1 531 | 80,1 | 1 531 | 1 335 | 87,2 | 69,8 | 72,7 |
| Ontario | |||||||||||||||
| Total | 27 207 | 22 290 | 81,9 | 22 290 | 20 163 | 90,5 | 74,1 | 33 503 | 25 846 | 77,1 | 25 846 | 22 332 | 86,4 | 66,7 | 70,0 |
| 3526 | 537 | 469 | 87,3 | 469 | 432 | 92,1 | 80,4 | 590 | 475 | 80,5 | 475 | 416 | 87,6 | 70,5 | 75,2 |
| 3527 | 530 | 438 | 82,6 | 438 | 377 | 86,1 | 71,1 | 549 | 437 | 79,6 | 437 | 380 | 87,0 | 69,2 | 70,2 |
| 3530 | 1 080 | 872 | 80,7 | 872 | 791 | 90,7 | 73,2 | 1 179 | 920 | 78,0 | 920 | 775 | 84,2 | 65,7 | 69,3 |
| 3531 | 427 | 367 | 85,9 | 367 | 337 | 91,8 | 78,9 | 488 | 388 | 79,5 | 388 | 337 | 86,9 | 69,1 | 73,7 |
| 3533 | 608 | 544 | 89,5 | 544 | 506 | 93,0 | 83,2 | 711 | 551 | 77,5 | 551 | 492 | 89,3 | 69,2 | 75,7 |
| 3534 | 488 | 397 | 81,4 | 397 | 354 | 89,2 | 72,5 | 592 | 470 | 79,4 | 470 | 406 | 86,4 | 68,6 | 70,4 |
| 3535 | 472 | 383 | 81,1 | 383 | 339 | 88,5 | 71,8 | 611 | 504 | 82,5 | 504 | 442 | 87,7 | 72,3 | 72,1 |
| 3536 | 917 | 747 | 81,5 | 747 | 671 | 89,8 | 73,2 | 1 041 | 815 | 78,3 | 815 | 696 | 85,4 | 66,9 | 69,8 |
| 3537 | 1 094 | 835 | 76,3 | 835 | 742 | 88,9 | 67,8 | 1 258 | 944 | 75,0 | 944 | 807 | 85,5 | 64,1 | 65,9 |
| 3538 | 594 | 511 | 86,0 | 511 | 445 | 87,1 | 74,9 | 682 | 539 | 79,0 | 539 | 465 | 86,3 | 68,2 | 71,3 |
| 3539 | 355 | 318 | 89,6 | 318 | 299 | 94,0 | 84,2 | 438 | 359 | 82,0 | 359 | 316 | 88,0 | 72,1 | 77,6 |
| 3540 | 414 | 389 | 94,0 | 389 | 374 | 96,1 | 90,3 | 538 | 421 | 78,3 | 421 | 374 | 88,8 | 69,5 | 78,6 |
| 3541 | 700 | 535 | 76,4 | 535 | 466 | 87,1 | 66,6 | 694 | 554 | 79,8 | 554 | 497 | 89,7 | 71,6 | 69,1 |
| 3542 | 480 | 402 | 83,8 | 402 | 374 | 93,0 | 77,9 | 648 | 519 | 80,1 | 519 | 452 | 87,1 | 69,8 | 73,2 |
| 3543 | 556 | 467 | 84,0 | 467 | 425 | 91,0 | 76,4 | 697 | 553 | 79,3 | 553 | 491 | 88,8 | 70,4 | 73,1 |
| 3544 | 974 | 787 | 80,8 | 787 | 734 | 93,3 | 75,4 | 1 107 | 857 | 77,4 | 857 | 740 | 86,3 | 66,8 | 70,8 |
| 3546 | 920 | 769 | 83,6 | 769 | 710 | 92,3 | 77,2 | 1 096 | 849 | 77,5 | 849 | 742 | 87,4 | 67,7 | 72,0 |
| 3547 | 478 | 411 | 86,0 | 411 | 359 | 87,3 | 75,1 | 551 | 431 | 78,2 | 431 | 367 | 85,2 | 66,6 | 70,6 |
| 3549 | 535 | 390 | 72,9 | 390 | 344 | 88,2 | 64,3 | 712 | 566 | 79,5 | 566 | 492 | 86,9 | 69,1 | 67,0 |
| 3551 | 1 425 | 1 050 | 73,7 | 1 050 | 929 | 88,5 | 65,2 | 1 493 | 1 170 | 78,4 | 1 170 | 1 022 | 87,4 | 68,5 | 66,9 |
| 3552 | 449 | 380 | 84,6 | 380 | 367 | 96,6 | 81,7 | 535 | 428 | 80,0 | 428 | 381 | 89,0 | 71,2 | 76,0 |
| 3553 | 1 666 | 1 409 | 84,6 | 1 409 | 1 236 | 87,7 | 74,2 | 2 157 | 1 636 | 75,8 | 1 636 | 1 348 | 82,4 | 62,5 | 67,6 |
| 3554 | 389 | 345 | 88,7 | 345 | 333 | 96,5 | 85,6 | 437 | 359 | 82,2 | 359 | 319 | 88,9 | 73,0 | 78,9 |
| 3555 | 499 | 424 | 85,0 | 424 | 387 | 91,3 | 77,6 | 587 | 455 | 77,5 | 455 | 405 | 89,0 | 69,0 | 72,9 |
| 3556 | 493 | 405 | 82,2 | 405 | 360 | 88,9 | 73,0 | 515 | 395 | 76,7 | 395 | 344 | 87,1 | 66,8 | 69,8 |
| 3557 | 420 | 395 | 94,0 | 395 | 356 | 90,1 | 84,8 | 544 | 428 | 78,7 | 428 | 380 | 88,8 | 69,9 | 76,3 |
| 3558 | 611 | 503 | 82,3 | 503 | 461 | 91,7 | 75,5 | 737 | 576 | 78,2 | 576 | 511 | 88,7 | 69,3 | 72,1 |
| 3560 | 1 188 | 939 | 79,0 | 939 | 848 | 90,3 | 71,4 | 1 872 | 1 462 | 78,1 | 1 462 | 1 274 | 87,1 | 68,1 | 69,3 |
| 3561 | 643 | 563 | 87,6 | 563 | 492 | 87,4 | 76,5 | 749 | 589 | 78,6 | 589 | 540 | 91,7 | 72,1 | 74,1 |
| 3562 | 782 | 595 | 76,1 | 595 | 535 | 89,9 | 68,4 | 1 129 | 883 | 78,2 | 883 | 769 | 87,1 | 68,1 | 68,2 |
| 3563 | 147 | 125 | 85,0 | 125 | 117 | 93,6 | 79,6 | 392 | 304 | 77,6 | 304 | 260 | 85,5 | 66,3 | 69,9 |
| 3565 | 979 | 808 | 82,5 | 808 | 742 | 91,8 | 75,8 | 1 126 | 880 | 78,2 | 880 | 781 | 88,8 | 69,4 | 72,4 |
| 3566 | 660 | 583 | 88,3 | 583 | 536 | 91,9 | 81,2 | 780 | 632 | 81,0 | 632 | 564 | 89,2 | 72,3 | 76,4 |
| 3568 | 853 | 693 | 81,2 | 693 | 640 | 92,4 | 75,0 | 1 128 | 853 | 75,6 | 853 | 714 | 83,7 | 63,3 | 68,3 |
| 3570 | 1 175 | 955 | 81,3 | 955 | 858 | 89,8 | 73,0 | 1 573 | 1 160 | 73,7 | 1 160 | 973 | 83,9 | 61,9 | 66,6 |
| 3595 | 2 669 | 2 087 | 78,2 | 2 087 | 1 887 | 90,4 | 70,7 | 3 567 | 2 484 | 69,6 | 2 484 | 2 060 | 82,9 | 57,8 | 63,3 |
| Manitoba | |||||||||||||||
| Total | 4 363 | 3 689 | 84,6 | 3 689 | 3 358 | 91,0 | 77,0 | 4 624 | 3 883 | 84,0 | 3 883 | 3 467 | 89,3 | 75,0 | 75,9 |
| 4610 | 1 297 | 1 016 | 78,3 | 1 016 | 901 | 88,7 | 69,5 | 1 420 | 1 202 | 84,6 | 1 202 | 1 075 | 89,4 | 75,7 | 72,7 |
| 4615 | 358 | 291 | 81,3 | 291 | 270 | 92,8 | 75,4 | 357 | 305 | 85,4 | 305 | 273 | 89,5 | 76,5 | 75,9 |
| 4620 | 269 | 240 | 89,2 | 240 | 223 | 92,9 | 82,9 | 275 | 235 | 85,5 | 235 | 208 | 88,5 | 75,6 | 79,2 |
| 4625 | 354 | 305 | 86,2 | 305 | 278 | 91,1 | 78,5 | 384 | 334 | 87,0 | 334 | 298 | 89,2 | 77,6 | 78,0 |
| 4630 | 376 | 325 | 86,4 | 325 | 297 | 91,4 | 79,0 | 406 | 341 | 84,0 | 341 | 312 | 91,5 | 76,8 | 77,9 |
| 4640 | 463 | 410 | 88,6 | 410 | 379 | 92,4 | 81,9 | 477 | 401 | 84,1 | 401 | 346 | 86,3 | 72,5 | 77,1 |
| 4645 | 409 | 373 | 91,2 | 373 | 335 | 89,8 | 81,9 | 437 | 356 | 81,5 | 356 | 326 | 91,6 | 74,6 | 78,1 |
| 4660 | 269 | 235 | 87,4 | 235 | 220 | 93,6 | 81,8 | 337 | 277 | 82,2 | 277 | 247 | 89,2 | 73,3 | 77,1 |
| 4670 | 283 | 245 | 86,6 | 245 | 228 | 93,1 | 80,6 | 295 | 239 | 81,0 | 239 | 210 | 87,9 | 71,2 | 75,8 |
| 4685 | 285 | 249 | 87,4 | 249 | 227 | 91,2 | 79,6 | 236 | 193 | 81,8 | 193 | 172 | 89,1 | 72,9 | 76,6 |
| Saskatchewan | |||||||||||||||
| Total | 4 108 | 3 616 | 88,0 | 3 616 | 3 413 | 94,4 | 83,1 | 5 484 | 4 491 | 81,9 | 4 491 | 4 036 | 89,9 | 73,6 | 77,7 |
| 4701 | 316 | 305 | 96,5 | 305 | 299 | 98,0 | 94,6 | 385 | 322 | 83,6 | 322 | 292 | 90,7 | 75,8 | 84,3 |
| 4702 | 368 | 328 | 89,1 | 328 | 313 | 95,4 | 85,1 | 429 | 346 | 80,7 | 346 | 307 | 88,7 | 71,6 | 77,8 |
| 4703 | 282 | 256 | 90,8 | 256 | 250 | 97,7 | 88,7 | 358 | 288 | 80,4 | 288 | 258 | 89,6 | 72,1 | 79,4 |
| 4704 | 736 | 664 | 90,2 | 664 | 607 | 91,4 | 82,5 | 853 | 687 | 80,5 | 687 | 619 | 90,1 | 72,6 | 77,2 |
| 4705 | 310 | 282 | 91,0 | 282 | 272 | 96,5 | 87,7 | 388 | 322 | 83,0 | 322 | 293 | 91,0 | 75,5 | 80,9 |
| 4706 | 780 | 634 | 81,3 | 634 | 586 | 92,4 | 75,1 | 945 | 772 | 81,7 | 772 | 682 | 88,3 | 72,2 | 73,5 |
| 4707 | 292 | 256 | 87,7 | 256 | 249 | 97,3 | 85,3 | 334 | 278 | 83,2 | 278 | 254 | 91,4 | 76,0 | 80,4 |
| 4708 | 279 | 251 | 90,0 | 251 | 238 | 94,8 | 85,3 | 309 | 267 | 86,4 | 267 | 244 | 91,4 | 79,0 | 82,0 |
| 4709 | 435 | 360 | 82,8 | 360 | 339 | 94,2 | 77,9 | 443 | 359 | 81,0 | 359 | 331 | 92,2 | 74,7 | 76,3 |
| 4710 | 310 | 280 | 90,3 | 280 | 260 | 92,9 | 83,9 | 357 | 301 | 84,3 | 301 | 265 | 88,0 | 74,2 | 78,7 |
| 4714 | . | . | . | . | . | . | . | 683 | 549 | 80,4 | 549 | 491 | 89,4 | 71,9 | 71,9 |
| Alberta | |||||||||||||||
| Total | 7 641 | 6 281 | 82,2 | 6 281 | 5 634 | 89,7 | 73,7 | 8 568 | 6 809 | 79,5 | 6 809 | 5 984 | 87,9 | 69,8 | 71,7 |
| 4831 | 1 024 | 862 | 84,2 | 862 | 812 | 94,2 | 79,3 | 1 204 | 989 | 82,1 | 989 | 889 | 89,9 | 73,8 | 76,3 |
| 4832 | 1 769 | 1 482 | 83,8 | 1 482 | 1 362 | 91,9 | 77,0 | 1 968 | 1 549 | 78,7 | 1 549 | 1 345 | 86,8 | 68,3 | 72,4 |
| 4833 | 1 373 | 1 111 | 80,9 | 1 111 | 1 005 | 90,5 | 73,2 | 1 529 | 1 229 | 80,4 | 1 229 | 1 079 | 87,8 | 70,6 | 71,8 |
| 4834 | 1 754 | 1 372 | 78,2 | 1 372 | 1 170 | 85,3 | 66,7 | 1 940 | 1 526 | 78,7 | 1 526 | 1 347 | 88,3 | 69,4 | 68,1 |
| 4835 | 1 721 | 1 454 | 84,5 | 1 454 | 1 285 | 88,4 | 74,7 | 1 927 | 1 516 | 78,7 | 1 516 | 1 324 | 87,3 | 68,7 | 71,5 |
| Colombie-Britannique | |||||||||||||||
| Total | 10 000 | 8 215 | 82,2 | 8 215 | 7 485 | 91,1 | 74,9 | 11 138 | 8 581 | 77,0 | 8 581 | 7 553 | 88,0 | 67,8 | 71,1 |
| 5911 | 382 | 331 | 86,6 | 331 | 307 | 92,7 | 80,4 | 432 | 329 | 76,2 | 329 | 304 | 92,4 | 70,4 | 75,1 |
| 5912 | 328 | 297 | 90,5 | 297 | 276 | 92,9 | 84,1 | 371 | 297 | 80,1 | 297 | 264 | 88,9 | 71,2 | 77,3 |
| 5913 | 659 | 593 | 90,0 | 593 | 562 | 94,8 | 85,3 | 869 | 688 | 79,2 | 688 | 615 | 89,4 | 70,8 | 77,0 |
| 5914 | 557 | 488 | 87,6 | 488 | 447 | 91,6 | 80,3 | 613 | 486 | 79,3 | 486 | 434 | 89,3 | 70,8 | 75,3 |
| 5921 | 651 | 539 | 82,8 | 539 | 483 | 89,6 | 74,2 | 656 | 520 | 79,3 | 520 | 454 | 87,3 | 69,2 | 71,7 |
| 5922 | 990 | 819 | 82,7 | 819 | 764 | 93,3 | 77,2 | 1 096 | 822 | 75,0 | 822 | 712 | 86,6 | 65,0 | 70,8 |
| 5923 | 1 015 | 844 | 83,2 | 844 | 780 | 92,4 | 76,8 | 1 162 | 886 | 76,2 | 886 | 766 | 86,5 | 65,9 | 71,0 |
| 5931 | 479 | 395 | 82,5 | 395 | 370 | 93,7 | 77,2 | 589 | 430 | 73,0 | 430 | 353 | 82,1 | 59,9 | 67,7 |
| 5932 | 1 060 | 782 | 73,8 | 782 | 741 | 94,8 | 69,9 | 1 209 | 842 | 69,6 | 842 | 726 | 86,2 | 60,0 | 64,7 |
| 5933 | 617 | 492 | 79,7 | 492 | 377 | 76,6 | 61,1 | 822 | 609 | 74,1 | 609 | 535 | 87,8 | 65,1 | 63,4 |
| 5941 | 846 | 691 | 81,7 | 691 | 633 | 91,6 | 74,8 | 923 | 728 | 78,9 | 728 | 647 | 88,9 | 70,1 | 72,4 |
| 5942 | 616 | 522 | 84,7 | 522 | 490 | 93,9 | 79,5 | 668 | 548 | 82,0 | 548 | 494 | 90,1 | 74,0 | 76,6 |
| 5943 | 355 | 287 | 80,8 | 287 | 272 | 94,8 | 76,6 | 330 | 268 | 81,2 | 268 | 246 | 91,8 | 74,5 | 75,6 |
| 5951 | 457 | 370 | 81,0 | 370 | 325 | 87,8 | 71,1 | 460 | 371 | 80,7 | 371 | 335 | 90,3 | 72,8 | 72,0 |
| 5952 | 577 | 436 | 75,6 | 436 | 383 | 87,8 | 66,4 | 580 | 469 | 80,9 | 469 | 414 | 88,3 | 71,4 | 68,9 |
| 5953 | 411 | 329 | 80,0 | 329 | 275 | 83,6 | 66,9 | 358 | 288 | 80,4 | 288 | 254 | 88,2 | 70,9 | 68,8 |
| Yukon | |||||||||||||||
| 6001 | 1 236 | 1 095 | 88,6 | 1 095 | 1 026 | 93,7 | 83,0 | 329 | 277 | 84,2 | 277 | 256 | 92,4 | 77,8 | 81,9 |
| Territoires du Nord-Ouest | |||||||||||||||
| 6101 | 1 245 | 1 065 | 85,5 | 1 065 | 988 | 92,8 | 79,4 | 238 | 199 | 83,6 | 199 | 184 | 92,5 | 77,3 | 79,0 |
| Nunavut | |||||||||||||||
| 6201 | 790 | 682 | 86,3 | 682 | 628 | 92,1 | 79,5 | . | . | . | . | . | . | . | 79,5 |
| Géographie | Base aréolaire | Bases téléphoniques | Combiné | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Province/ Territoires – RLISS |
Nombre ménages cibles | Nombre ménages réponses | Taux de réponses ménages | Nombre personnes sélectionnées | Nombre réponses | Taux de réponses personnes | Taux de réponses | Nombre ménages cibles | Nombre ménages réponses | Taux de réponses ménages | Nombre personnes sélectionnées | Nombre réponses | Taux de réponses personnes | Taux de réponses | Taux de réponses combiné |
| Ontario | |||||||||||||||
| Total | 27 207 | 22 290 | 81,9 | 22 290 | 20 163 | 90,5 | 74,1 | 33 503 | 25 846 | 77,1 | 25 846 | 22 332 | 86,4 | 66,7 | 70,0 |
| 3501 | 1 747 | 1 484 | 84,9 | 1 484 | 1 388 | 93,5 | 79,5 | 2 314 | 1 793 | 77,5 | 1 793 | 1 540 | 85,9 | 66,6 | 72,1 |
| 3502 | 3 172 | 2 713 | 85,5 | 2 713 | 2 553 | 94,1 | 80,5 | 3 679 | 2 915 | 79,2 | 2 915 | 2 561 | 87,9 | 69,6 | 74,6 |
| 3503 | 1 536 | 1 307 | 85,1 | 1 307 | 1 196 | 91,5 | 77,9 | 1 755 | 1 391 | 79,3 | 1 391 | 1 246 | 89,6 | 71,0 | 74,2 |
| 3504 | 3 317 | 2 664 | 80,3 | 2 664 | 2 390 | 89,7 | 72,1 | 3 806 | 2 943 | 77,3 | 2 943 | 2 543 | 86,4 | 66,8 | 69,3 |
| 3505 | 1 300 | 1 076 | 82,8 | 1 076 | 926 | 86,1 | 71,2 | 1 693 | 1 263 | 74,6 | 1 263 | 1 037 | 82,1 | 61,3 | 65,6 |
| 3506 | 1 476 | 1 241 | 84,1 | 1 241 | 1 121 | 90,3 | 75,9 | 1 761 | 1 348 | 76,5 | 1 348 | 1 128 | 83,7 | 64,1 | 69,5 |
| 3507 | 1 352 | 1 042 | 77,1 | 1 042 | 965 | 92,6 | 71,4 | 1 799 | 1 270 | 70,6 | 1 270 | 1 075 | 84,6 | 59,8 | 64,7 |
| 3508 | 1 789 | 1 443 | 80,7 | 1 443 | 1 298 | 90,0 | 72,6 | 2 379 | 1 732 | 72,8 | 1 732 | 1 447 | 83,5 | 60,8 | 65,9 |
| 3509 | 2 537 | 2 074 | 81,8 | 2 074 | 1 860 | 89,7 | 73,3 | 3 084 | 2 372 | 76,9 | 2 372 | 2 018 | 85,1 | 65,4 | 69,0 |
| 3510 | 1 682 | 1 374 | 81,7 | 1 374 | 1 210 | 88,1 | 71,9 | 1 930 | 1 527 | 79,1 | 1 527 | 1 345 | 88,1 | 69,7 | 70,7 |
| 3511 | 2 624 | 2 087 | 79,5 | 2 087 | 1 872 | 89,7 | 71,3 | 2 910 | 2 286 | 78,6 | 2 286 | 2 014 | 88,1 | 69,2 | 70,2 |
| 3512 | 1 060 | 827 | 78,0 | 827 | 745 | 90,1 | 70,3 | 1 748 | 1 356 | 77,6 | 1 356 | 1 183 | 87,2 | 67,7 | 68,7 |
| 3513 | 2 298 | 1 973 | 85,9 | 1 973 | 1 760 | 89,2 | 76,6 | 2 804 | 2 201 | 78,5 | 2 201 | 1 934 | 87,9 | 69,0 | 72,4 |
| 3514 | 1 317 | 985 | 74,8 | 985 | 879 | 89,2 | 66,7 | 1 841 | 1 449 | 78,7 | 1 449 | 1 261 | 87,0 | 68,5 | 67,8 |
Nota
- 1999.Carnet de route de l’information sur la santé – Répondre aux besoins, Santé Canada, Statistique Canada. page 3.
- 1999.Initiative du carnet de route… Lancer le processus. Institut canadien d’information sur la santé/Statistique Canada. ISBN 1-895581-70-2. page19.
- À moins qu’un module optionnel soit sélectionné par l’ensemble des régions sosiosanitaires du Canada au cours d’une même période de collecte, ce qui n’est jamais produit à ce jour.
- La correspondance entre les 5 nouvelles RS et les 9 RS définies lors de l’échantillonnage est la suivante : RS 4831 (4821 et 4822), RS 4832 (4823), RS 4833 (4824 et 4825), RS 4834 (4826) et RS 4835 (4827, 4828 et 4829).
- A l’exception de 2 régions socio-sanitaires utilisant la base de sondage à composition aléatoire (CA) seulement (section 5.4.3) et les 3 territoires utilisant seulement la base aréolaire et la base de sondage à composition aléatoire (sections 5.4.1 et 5.4.3).
- Statistique Canada (2008).Méthodologie de l’enquête sur la population active du Canada. Statistique Canada numéro 71-526-XIE au catalogue.
- Pour réduire les coûts de listage, le processus de sélection a été répété jusqu’à 3 fois dans les UPE déjà choisies , pour certaines régions urbaines seulement. Il s’agit par contre de cas d’exception.
- Au Nunavut, pour des raisons d’ordre opérationnel inhérentes aux collectivités éloignées, seulement les 10 communautés les plus grandes sont couvertes par l’enquête soient Iqaluit, Cambridge Bay, Baker Lake, Arviat, Rankin Inlet, Kugluktuk, Pond Inlet, Cape Dorset, Pangnirtung et Igloolik.
- Norris, D.A., Paton, D.G. (1991), L’Enquête sociale générale canadienne: bilan des cinq premières années.Techniques d’enquête (Statistique Canada, Catalogue 12-001); 17, pp. 245-260.
- Statistique Canada (1998).Méthodologie de l’enquête sur la population active du Canada. Statistique Canada numéro 71-526-XPB au catalogue.
- Norris, D.A. et Paton, D.G. (1991). L’Enquête sociale générale canadienne: bilan des cinq premières années.Techniques d’enquête. 17, 245-260.
- Skinner, C.J. et Rao, J.N.K. (1996). Estimation in Dual Frame Surveys with Complex Designs.Journal of the American Statistical Association. 91, 433, 349-356.
- Sautory O. CALMAR 2: A New Version of the CALMAR Calibration Adjustment Program. Proceedings of Statistics Canada Symposium (Statistics Canada, Catalogue no. 11-522-XCB), 2003.
- Parmi les unités sélectionnées au départ, certaines ne font pas parti du champ de l’enquête. Ce sont par exemples des logements vacants ou démolis, des logements non-résidentiels ou encore des numéros de téléphones non-valides tels les numéros sans service ou non-résidentiels. Ces unités sont identifiées pendant la collecte, autrement elles auraient été excluses lors de la sélection. Ces unités ne sont pas considérées dans le calcul des taux de réponse.
- Du mot anglais flag.