
Guide de l'utilisateur
Novembre 2011
1.0 Introduction
L'Enquête sur les personnes ayant une maladie chronique au Canada (EPMCC) est une enquête transversale qui permet de recueillir des renseignements sur l'expérience des Canadiens qui souffrent de problèmes de santé chroniques. Parrainée par l'Agence de la santé publique du Canada (ASPC), l'EPMCC est réalisée tous les deux ans et traite de deux maladies chroniques par cycle d'enquête. L'enquête de 2011 portait sur le diabète et les problèmes respiratoires, soit l'asthme et la maladie pulmonaire obstructive chronique (MPOC).
La population cible de l'EPMCC est l'ensemble de la population canadienne vivant dans un logement privé dans les dix provinces. Les résidents des trois territoires, les personnes vivant sur les réserves indiennes, les résidents d'institutions, ainsi que les membres à temps plein des Forces armées canadiennes sont exclus de l'enquête. L'EPMCC de 2011 a été menée auprès de personnes de 20 ans ou plus atteintes de diabète, de personnes de 12 ans ou plus atteintes d'asthme et de personnes de 35 ans ou plus atteintes d'une MPOC.
L'EPMCC de 2011 a comporté deux périodes de collecte des données, soit octobre et novembre 2010 ainsi que mars et avril 2011.
Le présent document a pour but de faciliter la manipulation du fichier maître de l'EPMCC et de décrire la méthodologie utilisée.
Pour toute question concernant les ensembles de données et leur utilisation ou des totalisations spéciales, s'adresser à :
Services personnalisés à la clientèle, Division de la statistique de la santé: 613–951-1746
Courriel: statcan.hd-ds.statcan@statcan.gc.ca
2.0 Contexte
L'Enquête sur les personnes ayant une maladie chronique au Canada (EPMCC) est une enquête de suivi de l'Enquête sur la santé dans les collectivités canadiennes (ESCC), laquelle est une enquête transversale annuelle permettant de recueillir des données sur l'état de santé, l'utilisation des services de soins de santé et les déterminants de la santé pour la population canadienne. Comme l'ESCC compte sur un vaste échantillon et relève plusieurs maladies chroniques diagnostiquées, elle sert à la fois de base de sondage pour l'EPMCC et de source de renseignements complémentaires sur la santé et les caractéristiques sociodémographiques.
L'objectif central de l'EPMCC est de recueillir des données sur les expériences des personnes qui vivent avec une maladie chronique, y compris sur le diagnostic de problème de santé chronique, les soins reçus de professionnels de la santé, la consommation de médicaments et l'autogestion du problème de santé chronique.
L'enquête a été parrainée par l'Agence de la santé publique du Canada.
3.0 Objectif
L'objectif de l'EPMCC est de fournir des données sur les répercussions des maladies chroniques sur les personnes, ainsi que sur la façon dont les personnes qui ont une maladie chronique gèrent leur problème de santé. Plus particulièrement, l'enquête visait à :
- Déterminer l'impact des conditions de santé chroniques envers la qualité de vie
- De fournir plus d'information pour savoir comment les gens gèrent leurs conditions de santé chroniques
- Identifier les comportements liés à la santé influençant les effets de la maladie
- D'identifier les barrières à l'autogestion des conditions de santé chroniques
4.0 Contenu de l'enquête
La présente section décrit le processus de consultation utilisé pour élaborer le contenu de l'enquête et résume le contenu final qui sera inclus dans l'EPMCC.
Le contenu de l'EPMCC a été élaboré à la suite d'un processus permanent de consultation entre la Division de la statistique de la santé de Statistique Canada et l'Agence de la santé publique du Canada (ASPC), avec la contribution importante de membres de groupes consultatifs d'experts dans les domaines du diabète et des problèmes respiratoires. La sélection du contenu a été fondée sur les objectifs et les besoins de données précisés par l'ASPC. Les membres de l'équipe de projet de l'ASPC ont été consultés régulièrement tout au long de l'élaboration et de la mise à l'essai des questionnaires de l'EPMCC. Le processus de consultation a abouti à deux questionnaires : 1) un sur le diabète ; et 2) un sur les problèmes respiratoires.
Un sommaire décrivant chacun des modules des questionnaires sur le diabète et les problèmes respiratoires figure à la section 4.2.
4.1 Essais qualitatifs
Comme il est indiqué précédemment, l'EPMCC de 2011 comprend deux questionnaires distincts : un sur le diabète et un sur les problèmes respiratoires. Ceux-ci ont été élaborés par Statistique Canada, en collaboration avec l'ASPC. Des groupes d'experts dans les domaines du diabète et des problèmes respiratoires ont également été consultés durant l'élaboration du contenu. Les questionnaires ont ensuite été traduits par la Division des langues officielles et de la traduction de Statistique Canada. Les deux questionnaires (en anglais et en français) ont été mis à l'essai par le Centre de ressources en conception de questionnaires (CRCQ), à partir d'interviews individuelles.
On a procédé à des essais qualitatifs pour évaluer le contenu et l'enchaînement des questionnaires de l'EPMCC. Ceux-ci ont été administrés en personne aux répondants. Les interviews individuelles ont porté sur les quatre étapes du processus cognitif de réponse : compréhension de la question et des catégories de réponse, rappel/recherche des renseignements demandés, réflexion au sujet de la réponse et décision quant aux données à déclarer, et réponse.
Les essais qualitatifs ont été menés en février 2010. Les essais en anglais on été effectués à Toronto et ceux en français à Montréal. La base de sondage utilisée pour sélectionner les répondants des interviews était celle de l'ESCC de 2009. Au total, 36 participants ont pris part à l'essai, représentant un échantillon de personnes qui ont déclaré dans leur interview de l'ESCC avoir reçu un diagnostic de diabète, de l'asthme, de la bronchite chronique, ou de la maladie pulmonaire obstructive chronique (MPOC) d'un médecin ou d'un autre professionnel de la santé. Toutes les interviews qualitatives ont été menées par des intervieweurs formés au CRCQ et observées par des membres de l'équipe de projet de l'EPMCC, y compris des employés de la Division de la statistique de la santé de Statistique Canada et de l'ASPC. Certains des principaux résultats des essais qualitatifs sont abordés ci-après.
Principaux résultats du questionnaire sur le diabète :
En général, les participants ont estimé que le questionnaire était simple et facile à comprendre. Pour certaines questions, des répondants ont indiqué qu'ils n'étaient pas certains de la terminologie utilisée. Par exemple, un grand nombre de répondants n'ont pas compris le terme « test A1C » avant qu'on leur ait lu une note d'explication. Des répondants ont eu de la difficulté à comprendre certaines questions du module Faire face et soutien, particulièrement en français.
Après les essais qualitatifs, on a décidé de supprimer les cinq premières questions du module Faire face et soutien et de renommer ce dernier Soutien et bien-être. On a également décidé de supprimer plusieurs questions sur les difficultés d'accès à des soins de santé et aux équipes soignantes en diabète.
Principaux résultats du questionnaire sur les problèmes respiratoires :
Dans l'ensemble, les participants ont estimé que le questionnaire sur les maladies respiratoires était précis et facile à comprendre. Certains répondants ont eu l'impression que le questionnaire s'adressait aux personnes ayant des problèmes respiratoires graves. On a observé qu'il était plus facile pour les répondants d'indiquer la couleur de leur inhalateur que le type (de soulagement ou de contrôle), de sorte qu'on a insisté sur cet aspect dans la formation de l'intervieweur.
Le principal changement apporté à la suite des essais qualitatifs a été d'utiliser le nom de la maladie respiratoire du répondant dans le texte dynamique du questionnaire au lieu du terme « problèmes respiratoires ». Le module Historique de l'usage du tabac a été allongé et le module Coût des médicaments a été supprimé.
4.2 Contenu du questionnaire final
Cette section fait état des modules qui constituent le contenu des questionnaires sur le diabète et les problèmes respiratoires de l'EPMCC. Le questionnaire sur le diabète comprenait 15 modules, et celui sur les problèmes respiratoires, 17 modules.
Le diabète
- GENX
- État de santé général : Le module sur l'état de santé général sert à recueillir des données sur l'autoévaluation de la santé, la satisfaction à l'égard de la vie,l'autoévaluation de la santé mentale et l'autoévaluation du stress. Ce module est le même que celui utilisé dans l'ESCC.
Le but était de mettre les répondants à l'aise avant de leur poser des questions particulières sur leur diabète. - CNDX
- Confirmation du diagnostic du diabète : Ce module sert à confirmer que le répondant a reçu un diagnostic de diabète d'un professionnel de la santé ainsi qu'à demander le type de diabète. En plus, ce module est utilisé afin d'identifier et d'éliminer à la sélection les femmes qui ont été diagnostiquées avec le diabète que durant leur grossesse. La question de sélection a été modifiée à partir du module Problèmes de santé chroniques de l'ESCC. Les autres questions sont nouvelles.
Si le répondant déclare qu'il ne fait pas de diabète, une question de suivi est posée pour essayer de déterminer pourquoi il y a une différence entre ce qu'il a déclaré dans l'ESCC et dans l'EPMCC. Même si le répondant dit qu'il ne fait pas de diabète parce que la maladie est contrôlée par des médicaments ou des modifications du mode de vie, il va participer à l'enquête. L'enquête s'intéresse aux expériences des personnes qui peuvent contrôler leurs problèmes de santé en prenant des médicaments ou en modifiant leur mode de vie. - XHUX
- Utilisation des services de soins de santé : Le module Utilisation des services de soins de santé pose des questions aux répondants au sujet du professionnel de la santé qui est principalement responsable du traitement de leur diabète et leur demande si, au cours des 12 derniers mois, ils ont consulté une variété de professionnels de la santé, ainsi que s'ils ont rencontré des problèmes quant aux soins continue pour leur diabète.
- CODX
- Surveillance clinique : Dans ce module, on pose aux répondants des questions au sujet des tests et des examens administrés couramment par les professionnels de la santé pour surveiller le diabète et ses complications. Le module comprend des questions sur la fréquence des tests ainsi que sur leurs résultats.
Les résultats des tests et les mesures prises pourront être utilisés pour déterminer dans quelle mesure le diabète du répondant est bien contrôlé. - MEDX
- Consommation de médicaments : Dans ce module, on pose aux répondants des questions au sujet des médicaments sur ordonnance, y compris les injections d'insuline, pris pour contrôler le taux de sucre dans le sang, la tension artérielle et le taux de cholestérol dans le sang. On leur demande également s'ils suivent les prescriptions du médecin concernant la prise des médicaments et s'ils prennent des remèdes à base de plantes ou des remèdes naturopathiques pour traiter leur diabète.
Divers facteurs de risque modifiables sont associés au diabète (p. ex., régime alimentaire, contrôle du poids, consommation d'alcool) et les chercheurs veulent savoir si des changements apportés à de telles variables concernant le « style de vie » sont liés à un taux réduit de consommation de médicaments sur ordonnance chez les personnes souffrant de diabète. - ICDX
- Couverture d'assurance : Dans ce module, on demande aux répondants s'ils ont une assurance qui couvre en partie ou en totalité les frais de médicaments sur ordonnance, le coût du matériel pour la surveillance de la glycémie et les coûts des soins dentaires ainsi que des soins de la vue.
Le coût de médicaments sur ordonnance, des fournitures pour la surveillance de la glycémie, des soins dentaires et des soins de la vue peut empêcher certaines personnes de prendre les médicaments qui leur sont prescrits, d'autosurveiller leur glycémie et d'obtenir des soins préventifs. - CLDX
- Recommandations cliniques : Ce module contient une série de questions sur les choses qu'un médecin ou un autre professionnel de la santé a pu suggérer au répondant pour l'aider à gérer son diabète.
Ces questions visent à permettre de déterminer dans quelle mesure les médecins suivent les lignes directrices sur les pratiques exemplaires de traitement du diabète, s'ils parlent à leurs patients de l'importance de leur régime alimentaire, de l'exercice, de contrôle du poids, etc. - SMDX
- Autogestion : Le module Autogestion contient des questions sur les mesures que les répondants peuvent prendre pour gérer leur diabète. Le module porte sur les activités qui sont reconnues comme étant importantes pour la gestion du diabète (p. ex., le régime alimentaire, l'exercice et le contrôle du poids). Des questions de suivi permettant de mesurer les obstacles au changement sont posées aux répondants qui ne mènent pas actuellement des activités considérées comme des facteurs de risque modifiables dans le cas du diabète, plus précisément le régime alimentaire, l'exercice et le contrôle du poids.
Les questions sont semblables à celles contenues dans le module Recommandations cliniques et ils visent à déterminer la mesure dans laquelle les répondants suivent les lignes directrices sur les pratiques exemplaires en matière de traitement de leur diabète. - MODX
- Auto surveillance : Ce module contient des questions sur la surveillance du diabète qu'un répondant fait lui-même en dehors du cabinet d'un professionnel de la santé. Les sujets comprennent la fréquence de l'auto surveillance de la glycémie, la fréquence de la surveillance de la tension artérielle et la fréquence des examens des pieds pour voir s'ils présentent des plaies ou des irritations.
- DCDX
- Complications du diabète : Ce module contient des questions sur les problèmes de santé et les complications associées au diabète. Les problèmes de santé comprennent les cataractes, l'insuffisance rénale, l'hypertension artérielle, etc. Le problème doit avoir été diagnostiqué par un professionnel de la santé.
Le nombre de complications dont souffre le répondant peut être une indication de la gravité de son diabète ou de la mesure dans laquelle celui-ci est bien contrôlé. - RADX
- Limitation des activités : Ce module comporte une série de questions concernant la limitation des activités quotidiennes ou habituelles au cours des douze derniers mois, en raison du diabète.
Combinées aux renseignements obtenus durant le reste de l'interview, les réponses à ce module peuvent être utilisées pour comparer les personnes qui déclarent des limitations des activités attribuables au diabète et celles qui n'ont pas de telles limitations. De concert avec le module sur les complications du diabète, ce module aidera à identifier les personnes éprouvant des symptômes de diabète plus sévères.
Les personnes ayant plus de complications et de limitations des activités afficheront probablement des différences pour des variables telles que l'utilisation des services de santé et la consommation de médicaments, par rapport aux personnes ayant moins de complications et de limitations. - RWDX
- Limitation des activités liées au travail : Ce module vise à identifier les répondants qui ont dû modifier leur travail rémunéré à cause du diabète. Le module contient des questions sur la vie professionnelle du répondant, y compris sa situation d'emploi actuelle et passée ainsi que sur les changements qu'il a apportés à son travail à cause de son diabète.
- SWDX
- Soutien et bien-être : Il a été démontré que le soutien de la famille et des amis et le fait de pouvoir faire face à des émotions comme le stress sont d'une grande aide aux personnes qui souffrent de diabète.
Ce module contient des questions sur l'autoévaluation par le répondant du soutien social qu'il reçoit et sur l'aide dont il a déjà pu avoir besoin sur le plan émotionnel ou de la santé mentale pour l'aider à gérer son diabète. - PADX
- Activation des patients : Ce module contient une série de questions qui visent à déterminer dans quelle mesure les répondants jouent un rôle dans le traitement de leur diabète et s'ils sont sûrs de pouvoir faire face aux problèmes et complications éventuels.
- ADMX
- Administration : Ce module a pour but de demander aux répondants la permission de jumeler les renseignements provenant de l'EPMCC avec leurs réponses à l'ESCC de 2010. Ensuite, on leur demande si cette information peut être partagée avec nos partenaires de partage des données.
Les problèmes respiratoires
- GENX
- État de santé général : Le module sur l'état de santé général sert à recueillir des données sur l'autoévaluation de la santé, la satisfaction à l'égard de la vie, l'autoévaluation de la santé mentale et l'autoévaluation du stress. Ce module est le même que celui utilisé dans l'ESCC.
Le but visé était de mettre les répondants à l'aise avant de leur poser des questions particulières sur leur(s) problème(s) respiratoire(s). - DHRX
- Diagnostic et antécédents familiaux : Ce module sert à confirmer que le répondant a déjà reçu un diagnostic d'asthme ou de bronchite chronique/d'emphysème/de MPOC d'un professionnel de la santé.
Aux répondants qui indiquent qu'ils n'ont pas un problème respiratoire, nous posons une autre question pour déterminer pourquoi la réponse qu'ils ont donnée à l'ESCC ne concorde pas avec celle donnée à l'EPMCC. Ceux qui déclarent qu'ils se sentent mieux ou qu'ils prennent des médicaments pour contrôler leurs problèmes respiratoires vont continuer répondre à l'enquête.
L'enquête s'intéresse aux expériences des personnes qui peuvent contrôler leur maladie grâce à des médicaments ou à une modification de leur mode de vie.
Ce module contient aussi des questions sur l'âge au moment du diagnostic, le type de maladie respiratoire et si le répondant a des parents en ligne directe qui ont déjà reçu un diagnostic d'asthme, de bronchite chronique, d'emphysème ou de MPOC. - SSRX
- Symptômes et sévérité : Les questions dans ce module portent sur la fréquence et la sévérité des principaux symptômes d'asthme et de MPOC.
De concert avec le module sur la limitation des activités, ce module aidera à identifier les personnes éprouvant des symptômes respiratoires plus sévères. Les personnes ayant des symptômes plus sévères et plus de limitations des activités différeront vraisemblablement pour des variables comme l'utilisation des services de soins de santé et la consommation de médicaments, comparativement aux personnes dont les symptômes sont moins sévères. - TRRX
- Déclencheurs : Les questions dans ce module portent sur les choses qui déclenchent chez le répondant ses symptômes d'asthme ou de MPOC ou qui les aggravent. Une liste de déclencheurs courants est lue aux répondants et ces derniers doivent indiquer ceux qui les affectent.
- HURX
- Utilisation des services de soins de santé : Ce module a trait aux contacts que les répondants ont eus avec divers professionnels de la santé au sujet de leur asthme ou de leur MPOC au cours des 12 derniers mois. On leur demande également le nombre total de leurs visites chez un médecin, le nombre de visites au service d'urgence et le nombre de nuits qu'ils ont passées à l'hôpital à cause de leur asthme ou MPOC au cours des 12 derniers mois.
- MERX
- Consommation de médicaments : Ce module contient des questions sur la consommation actuelle du répondant de médicaments sur ordonnance pour l'asthme ou la MPOC. Il vise à recueillir des renseignements détaillés sur les deux principaux types d'inhalateurs utilisés pour traiter ces maladiesrespiratoires (de soulagement ou de contrôle) ainsi que sur l'utilisation de corticostéroïdes et d'antibiotiques, traitements utilisés dans les cas plus graves. Le module contient également des questions sur les raisons pour lesquelles le répondant ne prend pas de médicaments sur ordonnance pour son asthme ou sa MPOC et sur le respect des prescriptions du médecin concernant la prise de médicaments.
- HCRX
- Problème de santé : Dans ce module, on pose aux répondants des questions au sujet de problèmes de santé qui sont associés aux maladies respiratoires comme l'apnée du sommeil, l'ostéoporose et l'insuffisance cardiaque. Les maladies sur lesquelles des questions sont posées varient selon l'âge du répondant.
- ALRX
- Allergies : Dans ce module, on pose aux répondants des questions au sujet de leurs allergies et on leur demande si elles ont été traitées. Nous nous intéressons seulement aux allergies qui ont été diagnostiquées par un professionnel de la santé à la suite de tests d'allergie.
- RARX
- Limitation des activités : Ce module comprend une série de questions qui visent à déterminer si les activités quotidiennes ou habituelles du répondant ont été limitées au cours des douze derniers mois à cause de son asthme ou de sa MPOC.
Combinées aux renseignements obtenus durant le reste de l'interview, les réponses à ce module peuvent être utilisées pour comparer les personnes qui déclarent des limitations des activités attribuables à l'asthme ou à la MPOC et celles qui n'ont pas de telles limitations.
De concert avec le module sur les complications associées aux maladies respiratoires, ce module aidera à identifier les personnes éprouvant des symptômes plus sévères. Les personnes ayant plus de complications et de limitations des activités afficheront probablement des différences pour des variables telles que l'utilisation des services de santé et la consommation de médicaments, par rapport aux personnes ayant moins de complications et de limitations. - RWRX
- Limitation des activités liées au travail : Ce module vise à identifier les répondants qui ont dû modifier leur travail rémunéré à cause de leur maladie respiratoire.
Ce module comprend un certain nombre de questions sur la vie professionnelle du répondant, y compris sa situation d'activité actuelle et dans le passé, les changements qu'il a apportés à son travail à cause de sa maladie respiratoire et son exposition à la poussière, à la fumée ou aux gaz au travail. - RERX
- Limitation des activités éducatives : Ce module vise à identifier les répondants qui ont dû modifier leurs activités éducatives à cause de leur maladie respiratoire.
Les questions de ce module sont posées uniquement aux répondants de moins de 50 ans et portent seulement sur les activités scolaires actuelles. - RVRX
- Limitation des activités de bénévolat : Ce module vise à identifier les répondants qui ont dû modifier leurs activités bénévoles à cause de leur maladie respiratoire.
Le module comprend un certain nombre de questions sur la situation du répondant au regard du bénévolat, actuel et passé, et les changements qu'il a apportés à ses activités bénévoles à cause de sa maladie respiratoire. - SMRX
- Autogestion : Le module Autogestion contient des questions sur les choses qu'un médecin ou un professionnel de la santé a pu suggérer au répondant pour l'aider à gérer ses problèmes respiratoires. On demande également au répondant s'il a fait ces choses pour aider à gérer son asthme ou sa MPOC. Le module porte sur un certain nombre d'activités et de changements qui sont reconnus comme étant importants pour la gestion des maladies respiratoires (p. ex., consulter un éducateur spécialisé en asthme ou en MPOC ou modifier son environnement à la maison).
Ces questions revêtent de l'intérêt pour les chercheurs qui veulent savoir si les professionnels de la santé recommandent certaines activités et si les personnes atteintes d'asthme ou de MPOC modifient ou non leur comportement et leur environnement après avoir reçu leur diagnostic. - SWRX
- Soutien et bien-être : Il a été démontré que le soutien de la famille et des amis et le fait de pouvoir faire face à des émotions comme le stress sont d'une grande aide aux personnes qui souffrent d'asthme et de MPOC.
Ce module contient des questions sur l'autoévaluation par le répondant du soutien social qu'il reçoit et sur l'aide dont il a déjà pu avoir besoin sur le plan émotionnel ou de la santé mentale pour l'aider à gérer son asthme ou sa MPOC. Il contient également des questions supplémentaires à l'intention des répondants qui souffrent de MPOC, auxquels on demande s'ils ont discuté des soins qu'ils souhaitent recevoir en cas d'hospitalisation et au fur et à mesure que leur maladie progresse. - SHRX
- Historique de l'usage du tabac : Dans ce module, on pose aux répondants des questions au sujet de l'usage de la cigarette au cours de leur vie.
Les questions portent sur la durée de leur consommation quotidienne ou occasionnelle de cigarettes et sur le nombre de cigarettes fumées. Ce module vise à calculer le nombre de « paquets-années », qui est le nombre de cigarettes fumées quotidiennement multiplié par le nombre d'années d'usage du tabac divisé par 20. Ce calcul est utilisé par les chercheurs et les médecins pour déterminer l'intensité de l'exposition au tabac d'une personne au cours de sa vie. - SCRX
- Arrêt de l'usage du tabac : Dans ce module, on pose aux répondants qui fument des questions au sujet de leur intention de cesser de fumer dans un avenir rapproché, et on leur demande s'ils ont reçu des conseils ou de l'information de leur médecin au sujet de l'abandon du tabac et s'ils ont tâché de cesser de fumer au cours des 12 mois précédents, ainsi que d'indiquer les méthodes qu'ils peuvent avoir utilisées pour cesser de fumer. On leur pose également des questions au sujet de leur exposition à la fumée secondaire à la maison.
- ADMX
- Administration : Ce module a pour but de demander aux répondants la permission de jumeler les renseignements provenant de l'EPMCC avec leurs réponses à l'ESCC de 2010. Ensuite, on leur demande si cette information peut être partagée avec nos partenaires de partage des données.
Les répondants âgés de 12 et 13 ans répondent d'abord aux questions eux-mêmes. Puis, nous demandons au parent ou au tuteur s'il donne aussi la permission de partager et de jumeler les données. Pour le couplage et le partage des données, il faut l'autorisation à la fois du répondant et d'un de ses parents ou de son tuteur.
5.0 Plan d'échantillonnage
5.1 Population cible
La population cible de l'Enquête sur les personnes ayant une maladie chronique au Canada (EPMCC) de 2011 est l'ensemble de la population canadienne des dix provinces vivant dans un logement privé et souffrant de l'un des problèmes de santé suivants :
- Asthme (sauf les personnes ayant également une MPOC) et âgées de 12 ans ou plus au 31 décembre 2010
- Diabète (sauf les femmes faisant du diabète seulement durant la grossesse) et âgées de 20 ans ou plus au 31 décembre 2010
- MPOC (y compris les personnes souffrant également d'asthme) et âgées de 35 ans ou plus au 31 décembre 2010.
Ces problèmes de santé devaient avoir été diagnostiqués par un professionnel de la santé. Ont été exclus du champ de l'enquête les habitants des trois territoires, les personnes vivant sur les réserves indiennes, sur les terres de la Couronne ou dans des établissements institutionnels, les membres à temps plein des Forces canadiennes et les habitants de certaines régions éloignées. Ces exclusions représentent environ 2 % de l'ensemble de la population canadienne.
5.2 Domaines d'intérêt
L'EPMCC vise à produire des estimations fiables au niveau national selon le groupe d'âge et le sexe. Les groupes d'âge visés diffèrent selon le problème de santé, comme suit :
- Pour l'asthme (sauf les personnes ayant également une MPOC) : 12 à 24 ans, 25 à 39 ans, 40 à 54 ans et 55 ans et plus
- Pour le diabète (sauf les femmes faisant du diabète seulement durant la grossesse) : 20 à 64 ans et 65 ans et plus
- Pour la MPOC (y compris les personnes souffrant également d'asthme) : 35 ans et plus
Toutefois, comme l'échantillon de l'EPMCC de 2011 à été sélectionné à partir de l'Enquête sur la santé dans les collectivités canadiennes (ESCC) de 2010, la taille de l'échantillon de l'EPMCC a été limitée par le nombre de répondants de l'ESCC ayant ces problèmes. Par conséquent, il est possible que la taille de l'échantillon soit insuffisante dans le cas de certains groupes d'âge qui devront être regroupés aux fins de l'analyse.
5.3 Base de sondage
Dans le cadre de l'EPMCC de 2011, on a utilisé l'ESCC de 2010 pour sélectionner l'échantillon. L'EPMCC repose sur un plan d'échantillonnage à deux phases, la première correspondant à l'échantillon de l'ESCC et la deuxième, à celui de l'EPMCC.
L'échantillon de l'ESCC est sélectionné à partir de plusieurs bases de sondage. La première est une base aréolaire conçue pour l'Enquête sur la population active (EPA). La deuxième est une liste de numéros de téléphone. Environ la moitié de l'échantillon de l'ESCC est sélectionnée à partir de la base aréolaire et l'autre moitié, à partir de la liste. Pour des renseignements plus détaillés sur le processus d'échantillonnage de l'ESCC, voir le Guide de l'utilisateur de l'ESCC de 2010.
5.4 Taille et répartition de l'échantillon
Afin de produire des estimations fiables au niveau national selon le groupe d'âge et le sexe, les répondants de l'ESCC ont été stratifiés selon le problème de santé, le groupe d'âge et le sexe. Étant donné que les groupes d'âge d'intérêt diffèrent selon le problème de santé et que certaines unités avaient plus d'un problème de santé (p. ex. l'asthme ainsi que le diabète), les groupes d'âge utilisés aux fins de la stratification et de la répartition se situent à l'intersection des groupes d'âge énumérés à la section 5.2.
Afin de réduire le fardeau de réponse, il a été décidé que tous les répondants échantillonnés recevraient un seul questionnaire. Les personnes ayant deux problèmesNote de bas de page 1 de santé ont reçu de façon aléatoire un questionnaire correspondant à l'un de leurs problèmes de santé. La répartition de l'échantillon par questionnaire a été effectuée par groupes d'âge et sexe en proportion du nombre de répondants de l'ESCC de 2010 pour chaque problème de santé.
On a procédé à des exclusions avant la sélection de l'échantillon. Des unités ont été exclues si elles avaient été complétées par procuration ou encore si n'avaient pas donné l'autorisation de partager ou jumeler leurs données provenant de l'ESCC. Ces exclusions représentaient 13 % de l'échantillon de première phase et ont été prises en compte à l'étape de l'estimation, étant donné qu'elles font partie de la population d'intérêt.
Étant donné les nombres relativement peu importants de répondants de l'ESCC ayant chacun des trois problèmes de santé, la décision a été précise d'inclure toutes ces unités dans l'échantillon de l'EPMCC de 2011. En fin de compte, après exclusion de certaines unités pour des raisons d'ordre pratique et affectation d'un seul questionnaire aux unités ayant deux problèmes de santé, l'échantillon de personnes souffrant d'asthme comprenait 3 650 unités, l'échantillon de personnes souffrant de diabète comprenait 3 747 unités et l'échantillon de personnes ayant une MPOC comprenait 1 733 unités. Les tableaux 5.1, 5.2 et 5.3 montrent les tailles d'échantillon pour chacun des trois problèmes de santé selon le groupe d'âge et le sexe :
| Strate (Sexe, groupe d'âge) | L'EPMCC 2011 taille de l'échantillon | |
|---|---|---|
| Femmes | 12 à 24 ans | 512 |
| Femmes | 25 à 39 ans | 544 |
| Femmes | 40 à 54 ans | 427 |
| Femmes | 55+ ans | 708 |
| Total Femmes | 2 191 | |
| Hommes | 12 à 24 ans | 504 |
| Hommes | 25 à 39 ans | 325 |
| Hommes | 40 à 54 ans | 272 |
| Hommes | 55+ ans | 357 |
| Total Hommes | 1 459 | |
| Total | 3 650 | |
| Strate (Sexe, groupe d'âge) | L'EPMCC 2011 taille de l'échantillon | |
|---|---|---|
| Femmes | 20 à 64 ans | 769 |
| Femmes | 65 ans et plus | 1 086 |
| Total Femmes | 1 855 | |
| Hommes | 20 à 64 ans | 875 |
| Hommes | 65 ans et plus | 1 017 |
| Total Hommes | 1 892 | |
| Total | 3 747 | |
| Strate (Sexe, groupe d'âge) | L'EPMCC 2011 taille de l'échantillon | |
|---|---|---|
| Femmes | 35 ans et plus | 1 078 |
| Hommes | 65 ans et plus | 655 |
| Total | 1 733 | |
6.0 Collecte des données
La collecte de l'EPMCC s'est déroulée en octobre et novembre 2010 ainsi qu'au mois du mars et avril 2011. Au cours de la période de collecte, on a mené au total 6 573 interviews valides au moyen de la méthode d'interviews téléphoniques assistées par ordinateur (ITAO).
6.1 Interview assistée par ordinateur
L'interview assistée par ordinateur (IAO) offre deux grands avantages par rapport aux autres méthodes de collecte des données. D'abord, la technique est étayée d'un système de gestion des cas et d'une fonctionnalité de transmission de données. Le système de gestion des cas enregistre automatiquement l'information de gestion importante sur chaque tentative visant un cas particulier et produit des rapports aux fins de la gestion du processus de collecte. L'IAO comporte aussi un ordonnanceur automatique d'appels, c'est–à–dire un système central qui optimise l'horaire des rappels et le calendrier des rendez–vous utilisés pour appuyer la collecte par ITAO.
Le système de gestion des cas achemine les applications de questionnaire et les fichiers d'échantillons du Bureau central de Statistique Canada aux bureaux régionaux de collecte (dans le cas de l'ITAO). Les données destinées au Bureau central sont acheminées en sens inverse. Par souci de confidentialité, les données sont encodées avant la transmission. Elles sont ensuite désencodées une fois sauvegardées sur un ordinateur sécurisé distinct, sans accès à distance.
Deuxièmement, l'IAO permet de concevoir une interview personnalisée à l'intention de chaque répondant en fonction de leurs caractéristiques particulières et de leurs réponses à l'enquête. Notamment, l'application :
- saute automatiquement les questions qui ne s'appliquent pas au répondant;
- applique automatiquement des règles de vérification pour repérer les réponses incohérentes ou non incluses dans la fourchette de valeurs permises et affiche des messages–guides à l'écran quand une entrée est invalide, ce qui permet au répondant de recevoir une rétroaction immédiate et à l'intervieweur, de corriger toute incohérence;
- personnalise automatiquement le libellé des questions, y compris les périodes de référence et les pronoms, en fonction de facteurs comme l'âge et le sexe du répondant, la date de l'interview et les réponses aux questions précédentes.
6.2 Développement de l'application de l'EPMCC
Pour l'EPMCC, on a eu recours à une application d'ITAO. Celle–ci comprenait des composantes d'entrée, de contenu et de sortie.
Les composantes Entrée et Sortie comprennent des séries standard de questions conçues pour permettre à l'intervieweur de prendre contact avec le répondant, de confirmer la participation de ce dernier, de procéder au dépistage (au besoin) et de déterminer l'état du cas. La composante de contenu de l'enquête comprenait les modules du questionnaire sur le diabète et les problèmes respiratoires de l'EPMCC, qui constituent la partie principale de l'application. L'élaboration de l'application de l'ITAO et la mise à l'essai ont commencé en avril 2010. Il y avait trois étapes d'essai interne : essai modulaire, essai intégré et essai de bout en bout.
L'essai modulaire consiste à mettre à l'essai indépendamment chaque module de contenu afin de vérifier que les instructions « passez à », la logique d'enchaînement et le texte, dans les deux langues officielles, sont spécifiés correctement. Les instructions « passez à » et la logique d'enchaînement entre modules ne sont pas testées à cette étape, car chaque module est considéré comme un questionnaire autonome. Quand plusieurs responsables des essais ont vérifié tous les modules, ces derniers sont regroupés avec les composantes Entrée et Sortie pour former une application intégrée. Cette nouvelle application intégrée passe alors à l'étape suivante des essais.
L'essai intégré porte sur l'ensemble des modules testés à l'étape précédente, regroupés en applications intégrées avec les composantes Entrée et Sortie. Cette deuxième étape d'essai a permis de s'assurer que des renseignements clés, comme l'âge et le sexe, étaient transmis du fichier d'échantillon aux composantes d'entrée, de sortie et de contenu de l'enquête des applications. Elle a en outre permis de confirmer que les variables qui influent sur l'enchaînement des questions sont transmises correctement de module en module à l'intérieur de la composante du contenu. Étant donné qu'à cette étape, le fonctionnement de l'application est essentiellement identique à ce qu'il sera sur le terrain, tous les scénarios possibles auxquels feront face les intervieweurs sont simulés, afin de s'assurer qu'ils fonctionnent bien. Ces scénarios servent à tester divers aspects des composantes d'entrée et de sortie, y compris la prise de contact, la confirmation qu'il s'agit du bon répondant, la question de savoir si un cas fait partie du champ de l'enquête et la prise de rendez-vous.
L'essai de bout en bout situe l'application entièrement intégrée dans un environnement de collecte simulé. L'application est chargée dans des ordinateurs connectés à un serveur d'essai. Ensuite, des données sont recueillies, transmises et extraites en temps réel, comme cela se ferait sur le terrain. Cette dernière étape des essais permet d'expérimenter tous les aspects techniques de la saisie, de la transmission et de l'extraction des données pour chacune des applications de l'EPMCC. Il s'agit aussi de la dernière occasion de déceler des erreurs dans les composantes Entrée, Contenu de l'enquête et Sortie.
6.3 Formation des intervieweurs
En octobre 2010 et au mois de mars 2011, des représentants de la Division de la planification et de la gestion de la collecte de Statistique Canada ont visité les quatre bureaux régionaux participant à la collecte des données de l'EPMCC (Halifax, Sherbrooke, Sturgeon Falls et Edmonton). Les visites visaient à former les gestionnaires de projet et les équipes d'intervieweurs des bureaux régionaux au sujet des modules du diabète et les problèmes respiratoires de l'EPMCC. Des membres de l'équipe de projet de l'EPMCC de la Division de la statistique de la santé ont aussi participé aux séances de formation, en vue de présenter de l'information concernant le contexte et l'élaboration de l'EPMCC et d'offrir un soutien additionnel, ainsi que de préciser les questions et préoccupations soulevées.
L'objet de ces séances était de permettre aux intervieweurs d'être confortable avec l'utilisation de l'application de l'EPMCC, ainsi que de familiariser ceux-ci avec le contenu. La formation était centrée sur les sujets suivants :
- les buts et objectifs de l'enquête
- la méthodologie de l'enquête
- les fonctionnalités des applications
- l'examen du contenu du questionnaire, y compris des exercices
- la simulation d'interviews difficiles et de situations de non–réponse
- la gestion de l'enquête.
La formation visait en priorité à réduire au minimum les cas de non–réponse. À cette fin, les intervieweurs ont participé à des exercices qui consistaient à persuader des répondants réticents de participer à l'enquête.
6.4 L'interview
Les personnes dans l'échantillon de l'enquête ont été interviewées par la méthode d'ITAO à partir d'une centrale d'appels. Un intervieweur principal affecté à la même centrale d'appels assurait la surveillance des intervieweurs.
De nombreuses techniques, y compris les suivantes, ont été mises en œuvre afin de parvenir à un taux de réponse optimal :
Lettre d'introduction
Avant le début de la période de collecte, les ménages échantillonnés ont reçu des lettres d'introduction qui expliquaient l'objet de l'enquête. Elles énonçaient notamment l'importance de l'enquête et offraient des exemples de l'utilisation prévue des données tirées de l'EPMCC.
On ne disposait pas de données sur l'adresse postale pour tous les répondants de l'ESCC de 2010. Dans les cas où les adresses postales n'étaient pas disponibles, on n'a pas envoyé de lettres d'introduction.
Prise de contact
Les intervieweurs ont reçu l'instruction de faire toutes les tentatives raisonnables pour obtenir les interviews. Lorsque l'appel avait eu lieu à un moment inopportun, l'intervieweur fixait le moment d'un rappel qui convenait au répondant. De nombreux rappels ont été effectués, à divers moments de la journée et à des jours différents.
Lorsqu'un répondant n'était plus disponible au numéro de téléphone recueilli dans l'ESCC de 2010, on a procédé au dépistage. Afin de dépister les répondants, on a communiqué avec les personnes ressources identifiées par le répondant dans l'ESCC de 2010 pour obtenir le nouveau numéro de téléphone du répondant.
Conversion des cas de refus
Aux personnes qui refusaient dès le premier contact de participer à l'enquête, le bureau régional envoyait une lettre insistant sur l'importance de l'enquête et de la collaboration du répondant. Ensuite, un intervieweur principal, un surveillant de projet ou un autre intervieweur rappelait le répondant pour essayer de le convaincre de l'importance de sa participation à l'enquête.
Obstacles linguistiques
Pour parer au problème de langue susceptible de nuire aux interviews, les bureaux régionaux embauchent des intervieweurs qui parlent un grand nombre de langues. Au besoin, les cas étaient transférés à un intervieweur capable de remplir le questionnaire dans la langue voulue.
Interviews par procuration
Les interviews par procuration n'étaient pas permises pour l'EPMCC.
6.5 Opération sur le terrain
Il y a eu deux périodes de collecte de l'EPMCC, chaque période s'est étendue sur six semaines. La moitié de l'échantillon fut collecté lors de chacune des périodes de collectes. Les bureaux régionaux ont reçu l'instruction d'interviewer 40% de cas pendant les deux premières semaines de chaque période de collecte, les quatre semaines suivantes étant consacrées aux interviews restantes et au suivi des cas de non–réponse.
Il incombait au superviseur du projet, à l'intervieweur principal et à l'équipe de soutien technique du bureau régional de s'occuper de la transmission des cas au Bureau central. Tous les cas achevés ont été transmis chaque nuit au Bureau central de Statistique Canada.
6.6 Contrôle de la qualité et gestion de la collecte
Durant le cycle de collecte des données de l'EPMCC, plusieurs méthodes ont été appliquées pour s'assurer de la qualité des données et de l'optimisation de la collecte. Elles comportaient, entre autres, des mesures internes de vérification du rendement de l'intervieweur et les rapports quotidiens de contrôle des diverses cibles de collecte et de la qualité des données.
Les intervieweurs par ITAO ont été sélectionnés au hasard pour la validation. Cette dernière comportait la surveillance des interviews téléphoniques par des intervieweurs principaux en vue de s'assurer que l'intervieweur suivait les techniques et procédures prévues (c.-à-d. qu'il lisait le libellé des questions tel qu'il figurait dans les applications, qu'il ne posait pas de question pour susciter des réponses, etc.). De plus, les membres de l'équipe d'enquête du bureau central ont rendu visite à plusieurs bureaux région aux afin d'observer la collecte au début de chaque période de collecte.
Les responsables ont produit une série de rapports visant à contrôler et à gérer efficacement les objectifs de collecte, ainsi qu'à mettre à jour les problèmes posés par la collecte. Des rapports cumulatifs ont été produits quotidiennement et comprenaient les taux de réponse, les taux de refus et les taux d'unités hors du champ de l'enquête. Les taux de couplage et de partage ont été calculés chaque semaine.
Par ailleurs, des rapports personnalisés ont été établis et utilisés pour examiner des questions particulières de qualité des données qui se sont posées au cours de la collecte.
Parmi les problèmes qui se sont posés au cours de la collecte des données de l'EPMCC de 2009 figurait un taux d'unités hors du champ de l'enquête plus élevé que prévu. On a donc inclus dans le questionnaire de 2011 une série de questions de suivi s'adressant aux répondants ayant déclaré ne pas avoir reçu un diagnostic de diabète, d'asthme ou de MPOC. Ces questions visaient à repérer les répondants qui avaient reçu un diagnostic, mais qui n'éprouvaient plus de symptômes ou qui pouvaient gérer leur maladie grâce des médicaments ou à une modification de leur mode de vie. On a ainsi réduit le nombre d'unités hors champ.
Pour l'EPMCC de 2011, seule la MPOC a affiché un taux d'unités hors champ plus élevé que prévu. La question de l'ESCC servant à identifier les répondants ayant une MPOC est : Êtes-vous atteint de bronchite chronique, d'emphysème ou d'une maladie pulmonaire obstructive chronique ou MPOC? Après la collecte des données de l'EPMCC, on a examiné les notes et les commentaires relatifs aux cas ayant été codés comme étant hors champ afin de mieux comprendre pourquoi des répondants ont déclaré être atteints d'une MPOC lors de l'ESCC, mais ne l'ont pas fait lors de l'EPMCC. Il semble qu'il y a eu une certaine confusion au sujet du terme « bronchite chronique » pour certains répondants. Nombre d'entre eux ont confondu cette maladie avec la bronchite d'origine bactérienne ou virale et ont déclaré être atteints de « bronchite chronique » lors de l'ESCC et ont donc été inclus dans l'échantillon de l'EMPCC.
L'incidence des cas hors champ sur la pondération et la qualité des données sera examinée aux chapitres 8 et 9 respectivement.
7.0 Traitement des données
7.1 Vérification
La vérification des données a été exécutée en grande partie par l'application d'interview assistée par ordinateur (IAO) durant la collecte des données. Les intervieweurs ne pouvaient pas entrer de valeurs hors norme et les erreurs d'enchaînement faisaient l'objet de l'instruction de contrôle programmée « passez à ». Par exemple, l'IAO s'assurait de ne pas poser au répondant les questions non pertinentes.
En réponse à certaines données incompatibles ou inhabituelles, on a signalé des messages d'avertissement, mais sans prendre de mesures correctrices au moment de l'interview. On a plutôt mis au point, le cas échéant, des versions révisées à appliquer après la collecte des données au bureau central. Les incohérences ont été le plus souvent corrigées en attribuant à l'une ou aux deux variables en question la valeur « non déclaré ».
7.2 Codage
On a fourni des catégories de réponses précodées pour toutes les variables appropriées. Les intervieweurs ont reçu une formation durant laquelle ils ont appris à classer les réponses recueillies dans la catégorie appropriée.
Dans les cas où la réponse donnée par le répondant ne pouvait être assignée facilement à une catégorie existante, l'intervieweur pouvait choisir la catégorie « Autre ».
7.3 Création de variables dérivées et de variables groupées
Pour faciliter l'analyse des données, on a dérivé un certain nombre de variables à partir des éléments disponibles sur le questionnaire de l'EPMCC. Le cinquième caractère du nom des variables dérivées est en général un « D » ou un « G ». Dans certains cas, les variables dérivées sont simples, donnant lieu à un regroupement des catégories de réponses. Dans d'autres cas, on a combiné plusieurs variables pour en créer une nouvelle. La Documentation sur les variables dérivées (VD)fournit des détails sur la façon de dériver ces variables plus complexes. Pour de plus amples renseignements concernant la nomenclature, veuillez vous référer à la section 11.3.
7.4 Pondération
Le principe de base de l'estimation dans un échantillon aléatoire comme celui de l'EPMCC repose sur le fait que chaque personne représente, en plus d'elle-même, plusieurs autres personnes qui ne font pas partie de l'échantillon. Par exemple, dans un échantillon aléatoire simple de 2 % de la population, chaque personne en représente 50.
L'étape de détermination des facteurs de pondération donne lieu au calcul du poids d'échantillonnage de chaque personne échantillonnée. Ce poids apparaît dans le fichier de microdonnées à grande diffusion et doit servir à extraire des estimations de l'enquête. Par exemple, si l'on doit évaluer le nombre de personnes ayant déjà pris des injections d'insuline pour leur diabète, on le fait en choisissant dans l'échantillon les enregistrements des personnes qui présentent cette caractéristique et en faisant la somme des facteurs de pondération que représentent ces enregistrements.
Vous trouverez les détails sur la façon dont on calcule les poids d'échantillonnage au chapitre 8.
8.0 Pondération
Pour garantir que les estimations produites à partir des données d'enquête soient représentatives de la population couverte et non seulement de l'échantillon comme tel, l'utilisateur doit incorporer les poids de sondage dans ses calculs. Un poids de sondage est attribué à chaque personne incluse dans l'échantillon final, qui se compose de toutes les personnes faisant partie du champ de l'enquête ayant répondu à l'enquête. Intuitivement, le poids correspond au nombre de personnes dans la population de l'enquête représentées par le répondant.
Comme il est décrit au chapitre 5, la base de sondage de l'EPMCC se compose des répondants à l'ESCC de 2010. Le point de départ du processus de pondération de l'EPMCC est donc le fichier de partage de l'ESCC de 2010. Pour plus de renseignements sur ce poids, consulter le Guide de l'utilisateur des données de l'ESCC de 2010.
8.1 Ajustement des poids de sondage
Le tableau 8.1 donne un aperçu des divers ajustements qui font partie de la stratégie de pondération de l'EPMCC de 2011, dans l'ordre où ils sont appliqués.
Table 8.1 Étape de pondération pour l'EPMCC
- CD 1 Ajustement lié à la procuration et au couplage
- CD 2 Ajustement lié aux critères de sélection
- CD 3 Ajustement des unités hors champ de l'EPMCC
- CD 4 Ajustement des non-réponse à l'EPMCC
- CD 5 Ajustement (final) lié au partage et au couplage
- CD 6 Winsorisation
- CD 7 Poststratification
8.1.1 Ajustement lié à la pondération et au couplage
La première étape de pondération de l'EPMCC a consisté à supprimer les unités de l'ESCC dans les territoires, car elles ne faisaient pas partie de la population cible. L'étape suivante a consisté à procéder à un ajustement pour tenir compte du fait que certains répondants de l'ESCC avaient été exclus de l'EPMCC pour des raisons d'ordre pratique, même s'ils faisaient partie de la population cible. Les motifs de leur exclusion se présentent comme suit :
- Les personnes ayant refusé le couplage de leurs données de l'ESCC de 2010 ont été exclues. L'un des objectifs de l'EPMCC était de coupler les réponses données à l'EPMCC avec celles à l'ESCC de 2010 et de fournir les fichiers couplés aux partenaires de l'enquête. En l'absence de leur permission de procéder à ce couplage, il n'y avait pas de raison de mener l'enquête auprès de ces répondants de l'ESCC.
- Les personnes pour lesquelles l'interview de l'ESCC de 2010 a été effectuée par procuration ont été exclues, car on ne pouvait pas répondre au questionnaire de l'EPMCC par procuration.
Comme ces répondants de l'ESCC faisaient partie de la population d'intérêt, des ajustements ont été apportés pour allouer leurs poids aux répondants de l'ESCC restants.
Le processus d'ajustement débute avec les poids de partage de l'ESCC de 2010 et, dans chaque cellule (définie comme étant l'intersection du problème de santé, du groupe d'âge, du sexe et de la région), l'ajustement est calculé comme suit :

Le poids wgtCD1 est calculé comme étant wgts3*adjCD1, où wgts3 est le poids de partage final de l'ESCC de 2010. Après calcul de l'ajustement, les unités exclues sont supprimées du fichier.
8.1.2 Ajustement lié aux critères de sélection de l'EPMCC
Dans le plan d'échantillonnage de l'EPMCC, les répondants de l'ESCC ont été stratifiés selon le groupe d'âge et le sexe (voir le chapitre 5). Dans chaque strate (groupe d'âge par sexe), une personne pouvait souffrir d'un seul problème de santé (asthme, MPOC ou diabète) ou de deux problèmes de santé (MPOC et diabète ou asthme et diabète). Les personnes souffrant de MPOC et d'asthme ont été considérées comme ayant seulement une MPOC. Toutes les personnes considérées comme ayant un seul problème de santé ont été sélectionnées pour participer à l'EPMCC et aucun ajustement de poids n'a été nécessaire. Pour réduire le fardeau de réponse pour les personnes ayant deux problèmes de santé, chaque unité échantillonnée ne pouvait recevoir qu'un seul questionnaire. Par conséquent, il a fallu apporter des ajustements de poids. L'ajustement pour les unités souffrant de deux problèmes de santé a été calculé comme suit.



Pour les répondants ayant reçu le questionnaire sur l'asthme, le poids a été calculé comme étant wgtCD2a=wgtCD1*adjCD2a. De même, pour les répondants ayant reçu le questionnaire sur la MPOC, le poids a été calculé comme étant wgtCD2c=wgtCD1*adjCD2c et pour ceux ayant reçu le questionnaire sur le diabète, il a été calculé comme étant wgtCD2d = wgtCD1*adjCD2d.
8.1.3 Ajustement lié aux unités hors du champ de l'EPMCC
Après la collecte, les unités ont été classées en deux groupes principaux, soit les cas résolus et les cas non résolus. Les cas résolus sont les unités où on a communiqué avec le répondant de l'ESCC et il a été confirmé qu'il souffrait encore ou ne souffrait plus du problème de santé (dans le champ de l'enquête ou hors du champ de l'enquête). Les unités hors du champ de l'enquête ont été supprimées du fichier. Les cas non résolus sont les unités avec lesquelles il est impossible de communiquer de sorte qu'on ne peut savoir si elles sont dans le champ de l'enquête ou hors du champ de l'enquête. Par conséquent, on a utilisé des modèles logistiques (fondés sur les cas résolus) pour estimer la probabilité qu'un cas non résolu soit dans le champ de l'enquête. On a ensuite utilisé cette probabilité pour ajuster les poids.
Le poids des unités non résolues ayant reçu le questionnaire sur l'asthme a été calculé comme étant wgtCD3a=wgtCD2a*p_inscope, où p_inscope est la probabilité prédite qu'une unité soit dans le champ de l'enquête. De même, le poids pour les unités ayant reçu le questionnaire sur la MPOC a été calculé comme étant wgtCD3c = wgtCD2c*p_inscope et celui pour les unités ayant reçu le questionnaire sur le diabète, comme étant wgtCD3d = wgtCD2d*p_inscope. Cet ajustement a eu pour effet de réduire le poids total des unités non résolues selon le nombre prédit d'unités hors du champ de l'enquête qu'elles représentent dans la population. Les unités restent dans le fichier et sont traitées au moment de l'ajustement pour tenir compte de la non-réponse.
8.1.4 Ajustement lié à la non-réponse à l'EPMCC
Il convient de souligner qu'ici tous les cas non résolus étaient considérés comme des non-répondants puisque leurs poids ont été ajustés pour tenir compte du fait qu'ils étaient hors du champ de l'enquête. De même, tous les cas résolus qui restaient (unités dans le champ de l'enquête) représentaient des répondants. Des modèles logistiques utilisant principalement des variables auxiliaires de l'ESCC ont été construits pour prédire les probabilités d'être considérés comme répondants. Des groupes de réponses homogènes (GRH) ont été créés à partir des probabilités prédites. Pour s'assurer que l'ajustement pour la non-réponse ne modifie pas le nombre estimé de personnes souffrant d'un problème de santé au niveau de la strate ou à l'échelle régionale, les GRH ont été créés dans chaque strate par région.
L'ajustement a été calculé à l'intérieur de chaque GRH, comme suit :



Le poids de l'asthme wgtCD4a a été calculé comme étant wgtCD3a*adjCD4a. De même, le poids de la MPOC wgtCD4c a été calculé comme étant wgtCD3c*adjCD4c et le poids du diabète wgtCD4d a été calculé comme étant wgtCD3d*adjCD4d. Après l'ajustement, les unités non répondantes ont été supprimées du fichier.
8.1.5 Ajustement lié au partage et au couplage
Seuls les renseignements relatifs aux personnes ayant accepté le partage et le couplage de leurs données de l'EPMCC seront diffusés. On note que 99 % des répondants à l'EPMCC de 2011 ont consenti au partage et au couplage de leurs données. Comme les personnes ayant refusé le partage ou le couplage de leurs données se trouvent toujours dans la population d'intérêt, des ajustements ont été apportés pour allouer les poids des personnes n'ayant pas consenti au partage ou au couplage leurs données aux unités restantes. La probabilité qu'un répondant accepte le partage et le couplage de ses données de l'EPMCC a été prédite à l'aide d'un modèle de régression logistique. Des groupes de réponses homogènes (GRH) ont été créés à partir des probabilités prédites, de la même façon que celle décrite à la section 8.1.4.
L'ajustement a été calculé à l'intérieur de chaque GRH, comme suit :



Ici, le poids wgtCD5a pour les répondants ayant reçu le questionnaire sur l'asthme qui ont accepté le partage et le couplage de leurs données de l'EPMCC a été calculé comme étant wgtCD4a*adjCD5a. De même, le poids wgtCD5c pour la MPOC a été calculé comme étant wgtCD4c*adjCD5c et le poids wgtCD5d pour le diabète a été calculé comme étant wgtCD4d*adjCD5d. Après l'ajustement, les répondants ayant refusé le partage ou le couplage de leurs données de l'EPMCC de 2011 ont été supprimés du fichier.
8.1.6 Winsorisation
À la suite à la série d'ajustements des poids, il est possible que certaines unités se retrouvent avec des poids se démarquant de ceux d'autres unités dans le même domaine d'intérêt. Ces unités peuvent représenter une forte proportion de leur strate ou influer fortement sur la variance. Afin d'éviter cette situation, le poids de ces unités aberrantes est ajusté à la baisse selon une méthode appelée « winsorisation » semblable à celle utilisée par l'ESCC. Après la winsorisation, les poids pour l'asthme, la MPOC et le diabète deviennent wgtCD6a, wgtCD6c, et wgtCD6d, respectivement.
8.1.7 Poststratification
La poststratification est utilisée pour s'assurer que le nombre total estimatif de personnes souffrant des problèmes de santé correspond aux chiffres avant la winsorisation selon la strate et la région. À chaque intersection de strate et région, on a calculé les facteurs d'ajustement suivants :



Le poids final pour l'asthme, wgtCD7a, a été calculé comme étant wgtCD6a*adjCD7a. De même, le poids final pour la MPOC, wgtCD7c, a été calculé comme étant wgtCD6c*adjCD7c et le poids final pour le diabète, wgtCD7d, a été calculé comme étant wgtCD6d*adjCD7d. Les poids wgtCD7a, wgtCD7c et wgtCD7d correspondent au poids final de l'EPMCC de 2011 qui se trouve sous le nom de la variable WTSX_S.
8.2 Poids bootstraps
Des poids bootstrap coordonnés sont utilisés pour l'EPMCC en raison de la dépendance de cette dernière à l'égard de l'échantillon de l'ESCC de 2010. Ainsi, le point de départ du calcul des poids bootstrap de l'EPMCC a été les 500 répliques tirées du fichier de poids bootstrap partagé de l'ESCC de 2010. Chaque réplique bootstrap a été corrigée en utilisant les sept ajustements énumérés au tableau 8.1.
9.0 Qualité des données
9.1 Cas hors du champ de l'enquête
Les taux d'unités hors champ de l'EPMCC varient selon le problème de santé. Ils sont de 7 % pour l'asthme, de 18 % pour la MPOC et de 3 % pour le diabète. Plusieurs raisons peuvent expliquer que des unités soient devenues hors du champ de l'enquête :
- Des répondants ont été classés comme ayant le problème de santé lors de l'ESCC, alors qu'ils n'auraient pas dû l'être. Par exemple, un certain nombre de personnes ont déclaré que leur problème de santé n'avait pas été diagnostiqué par un professionnel de la santé, alors qu'un tel diagnostic est l'une des exigences pour participer à l'EPMCC.
- Des répondants ont dit qu'ils ne souffraient pas du problème de santé parce qu'ils ne présentaient plus aucun symptôme.
- Des répondants ont appris, après avoir participé à l'ESCC, à répondre négativement à certaines questions, sachant qu'ils seraient ainsi écartés de l'enquête. Dans un certain sens, ces cas peuvent être considérés comme des cas de refus.
À cause du taux élevé de cas hors du champ de l'enquête, le nombre total de personnes atteintes du problème de santé dans l'ESCC n'est pas le même que dans l'EPMCC. C'est particulièrement vrai pour le problème de la MPOC. L'ESCC a probablement inclus un certain nombre de répondants qui ont déclaré avoir le problème de santé, mais qui en réalité ne l'ont pas (faux positifs). Cependant, l'EPMCC a sans doute exclu certaines personnes qui avaient réellement le problème de santé, mais qui ont dit ne pas l'avoir pour éviter de participer à l'enquête (faux négatifs). Le choix de l'enquête auquel avoir recours dépend des besoins de chaque utilisateur. Par exemple, l'ESCC fournit une série chronologique des taux de prévalence de problèmes de santé, pendant que l'EPMCC est une enquête menée une seul fois. En outre, les données de l'ESCC peuvent servir à l'examen des comorbidités avec d'autres maladies ou affections. En revanche, l'EPMCC permet d'obtenir des mesures détaillées relatives à la qualité de vie et des comportements ayant une incidence sur la santé chez les personnes souffrant de maladies chroniques.
9.2 Taux de réponse
Au total, 9 130 personnes ont été sélectionnées pour prendre part à l'EPMCC de 2011, soit 3 650 pour le questionnaire sur l'asthme, 1 733 pour le questionnaire sur la MPOC et 3 747 pour le questionnaire sur le diabète.
Pour le questionnaire sur l'asthme, 238 unités ont été jugées hors champ parmi les cas résolus (unités ayant été contactées et ayant pu être classées comme étant ou non dans le champ de l'enquête). Parmi les cas non résolus (unités n'ayant pas été contactées, de sorte qu'il était impossible de déterminer si elles étaient ou non dans le champ de l'enquête), le modèle logistique prévoyait 68 unités hors champ. Pour en savoir plus sur l'utilisation du modèle logistique, se reporter à la section 8.1.3. Donc, il y avait au total 306 unités hors champ modélisées. Parmi les 3 344 unités admissibles modélisées, 2 507 ont participé à l'enquête et ont accepté le partage de leurs données avec nos partenaires et le couplage de leurs réponses avec celles de l'ESCC. Il en résulta donc un taux de réponse de 75,0 %. Le tableau 9.1 ci-dessous, présente un résumé des taux de réponse de l'EPMCC selon le groupe d'âge et le sexe pour le questionnaire sur l'asthme.
| Sexe | Groupe d'âge | Échantillon sélectionné | Nombre d'unités admissibles modélisées | Taux d'unités admissibles modélisées (%) | Répondants | Taux de réponse (%) |
|---|---|---|---|---|---|---|
| Féminin | 12 à 24 ans | 512 | 483 | 94,3 | 321 | 66,5 |
| Féminin | 25 à 39 ans | 544 | 511 | 93,9 | 360 | 70,5 |
| Féminin | 40 à 54 ans | 427 | 397 | 93,0 | 289 | 72,8 |
| Féminin | 55+ ans | 708 | 648 | 91,5 | 566 | 87,3 |
| Total Féminin | 2 191 | 2 039 | 93,1 | 1 536 | 75,3 | |
| Masculin | 12 à 24 ans | 504 | 459 | 91,1 | 331 | 72,1 |
| Masculin | 25 à 39 ans | 326 | 294 | 90,2 | 197 | 67,0 |
| Masculin | 40 à 54 ans | 272 | 247 | 90,8 | 185 | 74,9 |
| Masculin | 55+ ans | 357 | 305 | 85,4 | 258 | 84,6 |
| Total Masculin | 1 459 | 1 305 | 89,4 | 971 | 74,4 | |
| Total | 3 650 | 3 344 | 91,6 | 2 507 | 75,0 | |
Pour le questionnaire sur la MPOC, 315 unités ont été jugées hors champ parmi les cas résolus (unités ayant été contactées et ayant pu être classées comme étant ou non dans le champ de l'enquête). Parmi les cas non résolus (unités n'ayant pas été contactées, de sorte qu'il était impossible de déterminer si elles étaient ou non dans le champ de l'enquête), le modèle logistique prévoyait 57 unités hors champ. Donc, il y avait au total 372 unités hors champ modélisées. Parmi les 1 361 unités admissibles modélisées, 1 133 ont participé à l'enquête et ont accepté le partage de leurs données avec nos partenaires et le couplage de leurs réponses avec celles de l'ESCC. Il en résulta donc un taux de réponse de 83,2 %. Le tableau 9.2 ci-dessous, présente un résumé des taux de réponse de l'EPMCC selon le groupe d'âge et le sexe pour le questionnaire sur la MPOC.
| Sexe | Groupe d'âge | Échantillon sélectionné | Nombre d'unités admissibles modélisées | Taux d'unités admissibles modélisées (%) | Répondants | Taux de réponse (%) |
|---|---|---|---|---|---|---|
| Féminin | 35 ans et plus | 1 078 | 870 | 80,7 | 728 | 83,7 |
| Masculin | 35 ans et plus | 655 | 491 | 75,0 | 405 | 82,5 |
| Total | 1 733 | 1 361 | 78,5 | 1 133 | 83,2 | |
Pour le questionnaire sur le diabète, 129 unités ont été jugées hors champ parmi les cas résolus (unités ayant été contactées et ayant pu être classées comme étant ou non dans le champ de l'enquête). Parmi les cas non résolus (unités n'ayant pas été contactées, de sorte qu'il était impossible de déterminer si elles étaient ou non dans le champ de l'enquête), le modèle logistique prévoyait 28 unités hors champ. Donc, il y avait au total 157 unités hors champ modélisées. Parmi les 3 590 unités admissibles modélisées, 2 933 ont participé à l'enquête et ont accepté le partage de leurs données avec nos partenaires et le couplage de leurs réponses avec celles de l'ESCC. Il en résulta donc un taux de réponse de 81,7 %. Le tableau 9.3 ci-dessous, présente un résumé des taux de réponse de l'EPMCC selon le groupe d'âge et le sexe pour le questionnaire sur le diabète.
| Sexe | Groupe d'âge | Échantillon sélectionné | Nombre d'unités admissibles modélisées | Taux d'unités admissibles modélisées (%) | Répondants | Taux de réponse (%) |
|---|---|---|---|---|---|---|
| Féminin | 20 à 64 ans | 769 | 735 | 95,6 | 589 | 80,1 |
| Féminin | 65ans et plus | 1 086 | 1 042 | 95,9 | 874 | 83,9 |
| Total Féminin | 1 855 | 1 777 | 95,8 | 1 463 | 82,3 | |
| Masculin | 20 à 64 ans | 875 | 841 | 96,1 | 678 | 80,6 |
| Masculin | 65 ans et plus | 1 017 | 972 | 95,6 | 792 | 81,5 |
| Total Masculin | 1 892 | 1 813 | 95,8 | 1 470 | 81,1 | |
| Total | 3 747 | 3 590 | 95,8 | 2 933 | 81,7 | |
9.3 Interprétation des données
Comme l'EMPCC de 2011 est une enquête de suivi visant à recueillir des données supplémentaires auprès d'un groupe cible de répondants de l'ESCC de 2010, la population observée est la même pour les deux enquêtes. Toutefois, les périodes de référence sont différentes. La période de référence de l'ESCC de 2010 est l'année civile 2010, alors que les données de l'EPMCC reflètent la situation de cette même population en octobre et novembre 2010 ou en mars et avril 2011, selon que l'unité faisait partie de la première ou deuxième vague de la collecte. Dans la plupart des cas, cette différence entre les périodes de référence ne nuit pas à la comparaison des données de l'ESCC et de l'EPMCC. L'interprétation des estimations fondées sur les données de l'EPMCC doit donc tenir compte de la période de référence si l'on estime que celle-ci a une incidence sur les réponses des répondants.
9.4 Erreurs relatives à l'enquête
Les estimations issues de l'enquête reposent sur un échantillon de personnes. Elles auraient pu être légèrement différentes si on avait procédé par dénombrement complet au moyen du même questionnaire et si on avait eu recours aux mêmes intervieweurs, superviseurs, méthodes de traitement, etc. que pour l'enquête. L'écart entre les estimations découlant de l'échantillon et celles que donnerait un dénombrement complet réalisé dans des conditions semblables est appelé erreur d'échantillonnage de l'estimation.
Presque toutes les étapes des opérations d'enquête peuvent comporter des erreurs qui n'ont pas rapport à l'échantillonnage. Il arrive que les intervieweurs comprennent mal les instructions, que les enquêtés répondent incorrectement aux questions, que les réponses soient mal saisies ou que des erreurs surviennent durant le traitement et la totalisation des données. Voilà des exemples d'erreurs non dues à l'échantillonnage.
Sur un grand nombre d'observations, les erreurs aléatoires auront peu d'effet sur les estimations issues de l'enquête. Toutefois, les erreurs systématiques contribuent à biaiser les estimations. On a consacré beaucoup de temps et d'efforts à réduire les erreurs non dues à l'échantillonnage. Afin de contrôler la qualité des données, on a prévu des mesures d'assurance de la qualité à chacune des étapes du cycle de collecte et de traitement des données. Ces mesures consistaient à recourir à des intervieweurs hautement qualifiés, à former intensément les intervieweurs au déroulement de l'enquête et du questionnaire, à les observer au travail pour cerner les problèmes liés à la conception du questionnaire ou à l'incompréhension des instructions, à prévoir le nécessaire pour éviter le plus possible les erreurs de saisie et à effectuer des contrôles pour vérifier la logique du traitement.
9.4.1 Base de sondage
L'EPMCC 2011 était un supplément de l'Enquête sur la santé dans les collectivités canadiennes 2010 (ESCC), cette dernière étant principalement fondée sur une base aréolaire et une base de sondage téléphonique. La couverture de l'EPMCC 2011 devrait donc être la même que celle de l'ESCC dans les dix provinces; l'EPMCC n'inclue pas les habitants des trois territoires. Pour les dix provinces, il est peu probable que la sous couverture produise tout biais significatif dans les données de l'enquête.
9.4.2 Non-réponse
L'effet de la non-réponse sur les résultats de l'enquête constitue une source importante d'erreurs non dues à l'échantillonnage dans les enquêtes. L'ampleur de la non-réponse varie de non-réponse partielle (l'absence de réponse à une ou plusieurs questions) à une non-réponse complète. Dans le cas de l'EPMCC 2011, seulement les cas complétés ont été conservés. Il est à mentionner qu'une fois l'interview débutée, les répondants complétaient généralement l'enquête. Il y a eu non-réponse complète lorsque l'intervieweur a été incapable d'entrer en contact avec la personne sélectionnée pour participer à l'enquête ou qu'elle a refusé de le faire. On a traité les cas de non-réponse complète en corrigeant les poids des personnes qui ont répondu à l'enquête afin de compenser pour ceux qui n'y ont pas répondu.
Il est important de noter que les interviews de l'EPMCC ont eu lieu plusieurs mois après les interviews de l'ESCC 2011. Certains des cas n'ont pu être rejoints durant l'EPMCC dû au fait qu'ils ont déménagé ou changé de numéro de téléphone. La stratégie d'avoir deux périodes de collecte de données (octobre et novembre 2010 ainsi que mars et avril 2011) a réduit ce risque. Pour les cas non résolus (non rejoints) on a utilisé des modèles logistiques pour estimer la proportion d'unités dans le champ et la proportion d'unités hors champs (voir la section 8.1.3 pour avoir de plus amples détails).
9.4.3 Mesure de l'erreur d'échantillonnage
Puisqu'il est inévitable que des estimations établies à partir d'une enquête-échantillon (ou par sondage) soient sujettes à une erreur d'échantillonnage, une saine pratique de la statistique exige que les chercheurs fournissent aux utilisateurs une certaine indication de l'importance de cette erreur d'échantillonnage. Cette section de la documentation renferme un aperçu des mesures de l'erreur d'échantillonnage dont Statistique Canada se sert couramment et que le Bureau conseille vivement aux utilisateurs qui produisent des estimations à partir de ce fichier de microdonnées d'employer également.
La base pour mesurer l'importance potentielle des erreurs d'échantillonnage est l'erreur-type des estimations calculées à partir des résultats d'une enquête. En raison, cependant, de la diversité des estimations pouvant être produites à partir d'une enquête, l'erreur-type d'une estimation est habituellement exprimée en fonction de l'estimation à laquelle elle se rapporte. La mesure résultante, appelée coefficient de variation (CV) d'une estimation, s'obtient en divisant l'erreur-type de l'estimation par l'estimation elle-même et s'exprime en pourcentage de l'estimation.
Par exemple, supposons que d'après les résultats de l'enquête, on estime que 45,1% des Canadiennes et des Canadiens, au cours des 12 dernières mois, ont vu ou consulté un professionnel de la santé pour une maladie chronique et l'on constate que l'erreur-type de cette estimation est de 0,009. Le coefficient de variation de l'estimation est donc calculé comme suit :

Le chapitre 10 contient plus de détails sur le calcul du coefficient de variation.
10.0 Lignes directrices pour la totalisation, l'analyse et la diffusion
Cette section de la documentation décrit les lignes directrices que doivent suivre les utilisateurs pour totaliser, analyser, publier ou diffuser de toute autre façon des données tirées du fichier de données de l'enquête. Ces lignes directrices devraient leur permettre de reproduire les chiffres déjà publiés par Statistique Canada et de produire des chiffres non encore publiés conformes aux lignes directrices établies.
10.1 Lignes directrices pour l'arrondissement d'estimations
Afin que les estimations destinées à la publication, ou à toute autre forme de diffusion, qui sont calculées à partir de ces fichiers de données correspondent à celles produites par Statistique Canada, nous conseillons vivement aux utilisateurs de respecter les lignes directrices qui suivent en ce qui concerne leur arrondissement :
- les estimations qui figurent dans le corps d'un tableau statistique doivent être arrondies à la centaine près par la méthode d'arrondissement classique. Selon cette méthode, si le premier ou le seul chiffre à supprimer se situe entre 0 et 4, le dernier chiffre retenu ne change pas. Si le premier ou le seul chiffre à supprimer se situe entre 5 et 9, on augmente d'une unité (1) la valeur du dernier chiffre retenu. Par exemple, si l'on veut arrondir à la centaine près de la façon classique une estimation dont les deux derniers chiffres sont compris entre 00 et 49, il faut les remplacer par 00 et ne pas modifier le chiffre précédent (le chiffre des centaines). Si les deux derniers chiffres sont compris entre 50 et 99, il faut les remplacer par 00 et augmenter d'une unité (1) le chiffre précédent;
- les totaux partiels de marge et les totaux de marge des tableaux statistiques doivent être calculés à partir de leurs éléments correspondants non arrondis, puis arrondis à leur tour à la centaine près selon la méthode d'arrondissement classique;
- les moyennes, les proportions, les taux et les pourcentages doivent être calculés à partir d'éléments non arrondis (c'est–à–dire les numérateurs et (ou) dénominateurs), puis arrondis à une décimale par la méthode d'arrondissement classique. Si l'on veut arrondir une estimation à un seul chiffre décimal par cette méthode et que le dernier ou le seul chiffre à supprimer se situe entre 0 et 4, le dernier chiffre à retenir ne change pas. Si le premier ou le seul chiffre à supprimer se situe entre 5 et 9, on augmente d'une unité (1) le dernier chiffre à retenir;
- les sommes et les différences d'agrégats (ou de rapports) doivent être calculées à partir de leurs éléments correspondants non arrondis, puis arrondies à leur tour à la centaine près (ou à la décimale près) selon la méthode d'arrondissement classique;
- si, en raison de contraintes d'ordre technique ou autre, on applique une autre méthode que l'arrondissement classique, si bien que les estimations qui seront publiées ou diffusées de toute autre façon diffèrent des estimations correspondantes publiées par Statistique Canada, il est vivement conseillé à l'utilisateur d'indiquer la raison de ces divergences dans le ou les documents à publier ou à diffuser;
- des estimations non arrondies ne doivent être publiées ou diffusées de toute autre façon en aucune circonstance. Des estimations non arrondies donnent l'impression d'être beaucoup plus précises qu'elles ne le sont en réalité.
10.2 Lignes directrices pour la pondération de l'échantillon en vue de la totalisation
Le plan d'échantillonnage utilisé pour cette enquête n'est pas autopondéré. Autrement dit, le poids d'échantillonnage n'est pas le même pour toutes les personnes qui font partie de l'échantillon. Même pour produire des estimations simples, y compris des tableaux statistiques ordinaires, l'utilisateur doit employer le poids d'échantillonnage approprié. Si les poids appropriés ne sont pas utilisés, les estimations calculées à partir des fichiers de données ne peuvent pas être considérées comme représentatives de la population visée par l'enquête et ne correspondront pas à celles produites par Statistique Canada.
L'utilisateur ne doit pas non plus perdre de vue qu'en raison du traitement réservé au champ du poids, certains progiciels ne permettent pas d'obtenir des estimations qui coïncident exactement avec celles de Statistique Canada.
10.2.1 Définitions : Estimations de type nominal, estimations quantitatives
Avant d'exposer la façon de totaliser et d'analyser les données de l'enquête, il est bon de décrire les deux grandes catégories d'estimations ponctuelles des caractéristiques de la population qui peuvent être produites d'après le fichier de données.
Estimations de type nominal :
Les estimations de type nominal sont des estimations du nombre ou du pourcentage de personnes qui, dans la population visée par l'enquête, possèdent certaines caractéristiques ou rentrent dans une catégorie particulière. La fréquence à laquelle une personne ressent des douleurs articulaires est un exemple de ce type d'estimation. Une estimation du nombre de personnes possédant une caractéristique particulière ou manifestant un comportement particulier peut aussi être considérée comme une estimation d'un agrégat.
Exemple de question de type nominal :
À quelle fréquence est-ce que votre professionnel de la santé vérifie votre tension artérielle lors de vos rendez-vous associés au diabète? (CODX_04)
Toujours
Souvent
Parfois
Rarement
Jamais
Estimations quantitatives :
Les estimations quantitatives sont des estimations de totaux ou de moyennes, de médianes ou d'autres mesures de tendance centrale de quantités qui ont trait à tous les membres de la population observée ou à certains d'entre eux.
Un exemple d'estimation quantitative est l'âge moyen à laquelle les personnes reçoivent leur premier diagnostique d'asthme. Le numérateur correspond à l'estimation de l'âge à laquelle les personnes reçoivent leur premier diagnostique de l'asthme et le dénominateur, à l'estimation du nombre de personnes qui font de l'asthme.
Exemple de question quantitative :
Quel âge aviez-vous quand on a diagnostiqué pour la première fois que vous faisiez de l'asthme? (DHRX_07)
Âge lors du diagnostic
10.2.2 Totalisation d'estimations de type nominal
Les estimations du nombre de personnes présentant une caractéristique particulière peuvent être calculées d'après le fichier de données en totalisant les poids finals des enregistrements de toutes les personnes possédant la caractéristique d'intérêt.
Pour obtenir les proportions et les rapports de la forme 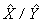 on doit :
on doit :
- additionner les poids finals des enregistrements contenant la caractéristique voulue pour le numérateur (
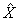 );
); - faire la somme des poids finals des enregistrements contenant la variable étudiée pour obtenir le dénominateur (
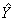 ); ensuite
); ensuite - diviser l'estimation du numérateur par celle du dénominateur
10.2.3 Totalisation d'estimations quantitatives
Pour obtenir l'estimation d'une somme ou d'une moyenne pour une variable quantitative, on procède aux étapes suivantes (seule l'étape (a) est nécessaire pour obtenir l'estimation pour une somme):
- multiplier la valeur de la variable étudiée par le poids final, puis faire la somme de cette quantité pour tous les enregistrements visés pour obtenir le numérateur (
);
- faire la somme des poids finals des enregistrements contenant la variable étudiée pour obtenir le dénominateur (
); ensuite
- diviser l'estimation du numérateur par celle du dénominateur.
Par exemple, pour obtenir l'estimation de l'âge moyen au moment du diagnostic de l'asthme, il faut d'abord calculer le numérateur (
) en faisant la somme du produit de la valeur de la variable DHRX_07 et du poids WTSX_S. Le dénominateur (
) est obtenu en additionnant le poids final des enregistrements comportant une valeur de « 2 » à la variable CONFLAG. Diviser (
) par (
) pour obtenir l'âge moyen au moment du diagnostic de l'asthme.
10.3 Lignes directrices pour l'analyse statistique
l'EPMCC se fonde sur un plan de sondage complexe qui prévoit une stratification et un échantillonnage à plusieurs degrés, ainsi que la sélection des répondants avec probabilités inégales. L'utilisation des données provenant d'une enquête aussi complexe pose des difficultés aux analystes, car le choix des méthodes d'estimation et de calcul de la variance dépend du plan de sondage et des probabilités de sélection.
Nombre de méthodes d'analyse intégrées aux progiciels statistiques permettent d'utiliser des poids, mais la signification et la définition de ces derniers peuvent différer de celles applicables dans le contexte d'une enquête par sondage. Par conséquent, si les estimations calculées au moyen de ces progiciels sont souvent exactes, les variances n'ont, quant à elles, pratiquement aucune signification.
Dans le cas de nombreuses méthodes d'analyse (par exemple la régression linéaire, la régression logistique, l'analyse de la variance), une méthode permet de rendre plus significatifs les résultats produits par les progiciels standard. Elle consiste à rééchelonner les poids qui figurent dans les enregistrements de façon à ce que le poids moyen soit égal à un (1). Les résultats produits par les progiciels standard sont ainsi plus raisonnables puisque, même s'ils ne reflètent toujours pas la stratification et la mise en grappes du plan d'échantillonnage, ils tiennent compte de la sélection avec probabilités inégales. On peut effectuer cette transformation en utilisant dans l'analyse un poids égal au poids original divisé par la moyenne des poids originaux pour les unités échantillonnées (personnes) qui contribuent à l'estimation en question.
10.4 Lignes directrices pour la diffusion
Avant de diffuser et/ou publier des estimations tirées du fichier de données, l'utilisateur doit déterminer le nombre de répondants dans l'échantillon qui ont la caractéristique d'intérêt (p. ex., le nombre de répondants ayant l'arthrite et souffrant de douleur articulaire). Si ce nombre est inférieur à 30, l'estimation non pondérée ne doit pas être diffusée, quelle que soit la valeur de son coefficient de variation. Pour les estimations pondérées basées sur des échantillons d'au moins 30 personnes, l'utilisateur doit calculer le coefficient de variation de l'estimation arrondie et suivre les lignes directrices qui suivent.
| Type d'estimation | CV (en %) | Lignes directrices |
|---|---|---|
| Acceptable | 0,0 ≤ CV ≤ 16,6 | On peut envisager une diffusion générale non restreinte des estimations. Aucune annotation particulière n'est nécessaire. |
| Marginal | 16,6 < CV ≤ 33,3 | On peut envisager une diffusion générale non restreinte des estimations, en y joignant une mise en garde aux utilisateurs quant à la variabilité d'échantillonnage élevée liée aux estimations. Les estimations de ce genre doivent être identifiées par la lettre E (ou d'une autre manière similaire). |
| Inacceptable | CV > 33,3 | Statistique Canada recommande de ne pas publier d'estimations dont la qualité est inacceptable. Toutefois, si l'utilisateur choisit de le faire, il doit les marquer de la lettre F (ou d'un autre identificateur semblable) et les diffuser avec l'avertissement suivant: "Nous avisons l'utilisateur que…(précisez les données)…ne répondent pas aux normes de qualité de Statistique Canada pour ce programme statistique. Les conclusions tirées de ces données ne sauraient être fiables et seront fort probablement erronées. Ces données et toute conclusion qu'on pourrait en tirer ne doivent pas être publiées. Si l'utilisateur choisit de les publier, il est tenu de publier également le présent avertissement." |
10.5 Variances et coefficients de variation
Le calcul des coefficients de variation exacte n'est pas une tâche aisée, car il n'existe aucune formule mathématique simple permettant de tenir compte de tous les aspects de la base de sondage et de la pondération de l'EPMCC. Il faut donc recourir à d'autres méthodes, comme des méthodes de rééchantillonnage, pour estimer les mesures de précision. Parmi ces méthodes, celle du bootstrap est recommandée pour l'analyse des données de l'EPMCC.
Le calcul des coefficients de variation (ou de toute autre mesure de précision) par la méthode du bootstrap nécessite l'accès à des renseignements qui sont considérés confidentiels.
Pour le calcul des coefficients de variation, il est conseillé d'utiliser la méthode du bootstrap. Un programme macro, appelé « Bootvar », a été développé afin de permettre aux utilisateurs d'appliquer plus facilement cette méthode. Le programme Bootvar est offert en formats SAS et SPSS, et est constitué de macros qui calculent les variances de totaux, de ratios, de différences entre ratios, et de régressions linéaires et logistiques
Certains progiciels statistiques standard permettent d'intégrer les poids d'échantillonnage aux analyses, mais, souvent, les variances produites ne tiennent pas bien compte de la stratification et de la mise en grappes de l' échantillon, contrairement à celles obtenues grâce au programme de calcul de la variance exacte.
11.0 Utilisation du fichier
Cette section débute par la description du fichier maître et de la variable de poids de ce fichier et donne des explications sur la façon de l'utiliser dans les totalisations. Vient ensuite l'explication des règles d'attribution des noms de variables employées pour l'EPMCC.
11.1 Fichier de données
L'EPMCC comporte deux fichiers de données distincts, l'un pour le diabète et l'autre pour les problèmes respiratoires. Ces fichiers ont tous deux été couplés aux fichiers de données de l'ESCC 2010.
Puisque les variables provenant des deux enquêtes figurent dans le même fichier de données, il est important que les utilisateurs connaissent les variables qu'ils utilisent dans leurs analyses. Par exemple, les renseignements concernant certaines variables démographiques (âge, sexe et province de résidence) ont été recueillis sur l'ESCC et l'EMPCC. Les utilisateurs des données devraient par conséquent savoir quelles variables ils utilisent pour s'assurer que leurs estimations sont cohérentes. Plus de renseignements sur la façon de faire la distinction entre les variables de l'EMPCC et de l'ESCC figurent aux sections 11.3 et 11.4.
Contrairement aux autres fichiers de données de l'ESCC, l'EPMCC ne comporte pas de fichier principal distinct du fichier de partage. Le fichier de données de l'EPMCC comprend plutôt uniquement les répondants qui ont accepté que leurs données de l'EPMCC soient couplées aux données de l'ESCC de 2010. En outre, seuls les répondants qui ont accepté le partage des données couplées avec les partenaires sont inclus dans le fichier de données.
Les données sont accessibles de diverses façons, qui sont décrites dans les sections suivantes.
11.1.1 Partenaires du partage
Les partenaires du partage ont accès aux données en vertu des modalités des accords de partage. Ces fichiers de partage comprennent uniquement les données de répondants qui ont accepté de partager leurs données avec les partenaires de Statistique Canada. Les partenaires de partage de l'EPMCC sont l'Agence de la santé publique du Canada (qui parraine l'enquête), Santé Canada et certains ministères provinciaux de la santé. Statistique Canada demande également aux répondants résidant au Québec leur permission de partager leurs données avec l'Institut de la Statistique du Québec. Statistique Canada ne fournit le fichier de partage qu'à ces organisations. Les identificateurs personnels sont retirés des fichiers de partage pour préserver la confidentialité des répondants. Les utilisateurs de ces fichiers doivent au préalable confirmer qu'ils ne divulgueront en aucun temps de l'information susceptible d'identifier un répondant à l'enquête.
11.1.2 Centres de données de recherche
Le Programme des Centres de données de recherche (CDR) permet aux chercheurs d'utiliser les données d'enquête dans un environnement sécuritaire dans plusieurs universités au Canada. Les chercheurs doivent soumettre des propositions de recherche qui, une fois acceptées, leur donneront accès aux CDR. Pour plus de renseignements, consultez la page web suivante : CDR.
11.1.3 Totalisations personnalisées
Une façon de donner accès au fichier de données consiste à offrir aux utilisateurs l'option de demander au personnel des Services à la clientèle de la Division de la statistique de la santé de préparer des totalisations personnalisées. Ce service est offert contre recouvrement des coûts. Il permet aux utilisateurs qui ne savent pas se servir des logiciels de totalisation d'obtenir des résultats personnalisés. Les résultats sont filtrés pour s'assurer qu'ils sont conformes aux normes de confidentialité et de fiabilité avant d'être diffusés. Pour plus de renseignements, s'adresser aux Services à la clientèle, au 613–951–1746, ou par courriel, à statcan.hd-ds.statcan@statcan.gc.ca.
11.2 Utilisation de la variable de poids
La variable de poids WTSX_S représente le poids d'échantillonnage utilisé dans l'EPMCC. Pour un répondant donné, ce poids d'échantillonnage peut être interprété comme étant le nombre de personnes que le répondant représente dans la population. Il doit être utilisé en tout temps dans les calculs d'estimations statistiques, afin de permettre l'inférence à l'échelle de la population. La production de résultats non pondérés n'est pas recommandée. La répartition de l'échantillon, de même que les détails du plan de sondage, peuvent entraîner des résultats biaisés qui ne représentent pas correctement la population. Pour une description plus détaillée du calcul de ce poids, consulter le chapitre 8 sur la pondération.
11.3 Règles d'affectations des noms des variables
Pour l'EPMCC, on a adopté des règles d'affectation des noms des variables qui permettent d'utiliser et d'identifier facilement les données en se fondant sur le module et les conditions. Les règles d'affectation des noms des variables satisfont à l'obligation de restreindre les noms de variables à un maximum de huit caractères afin de faciliter leur utilisation dans les produits logiciels analytiques.
11.3.1 Structure des composantes du nom des variables dans l'EPMCC
Chacun des huit caractères du nom d'une variable fournit des renseignements sur le type de données que contient la variable.
- Positions 1-2 :
- Référence du module (p. ex., SS – Symptômes et sévérité, ME – Consommation de médicaments, et HU – Utilisation des services de soins de santé)
- Position 3 :
- Référence propre au questionnaire (D = diabète, R = problèmes respiratoires).
- Position 4 :
- Référence à l'Enquête sur les personnes ayant une maladie chronique au Canada (X)
- Position 5 :
- Type de variable (_ – question, D – variable dérivée)
- Positions 6-8 :
- Numéro de la question
Par exemple : la variable correspondant à la question 1, module de l'utilisation des services de soins de santé, questionnaire sur les problèmes respiratoires, EPMCC (HURX_01) :
- Position 1-2 :
- HU Tiré du module Utilisation des services de soins de santé
- Position 3 :
- R Composante du questionnaire sur les problèmes respiratoires
- Position 4 :
- X EPMCC
- Position 5 :
- _ Tiret de soulignement (_ = données recueillies)
- Position 6-8 :
- 01 Numéro de question (et option de réponse au besoin)
On se sert des valeurs suivantes pour la composante du nom de la variable correspondant à la section du questionnaire :
| GEN | État de santé général (utilisé pour les questionnaires sur le diabète et sur les problèmes respiratoires) |
|---|---|
| CN | Confirmation du diagnostic et antécédents familiaux |
| SS | Symptômes et sévérité |
| TR | Déclencheurs |
| CO | Surveillance clinique |
| HU | Utilisation des services de soins de santé |
| ME | Consommation de médicaments |
| IC | Couverture d'assurance |
| HC | Problèmes de santé |
| AL | Allergies |
| CL | Recommendations cliniques |
| RA | Limitation des activités |
| RW | Limitation des activités liées au travail |
| RE | Limitation des activités éducatives |
| RV | Limitation des activités de bénévolat |
| SM | Autogestion |
| MO | Auto surveillance |
| SW | Soutien et bien-être |
| SH | Historique de l'usage du tabac |
| SC | Arrêt de l'usage du tabac |
| DC | Complications du diabète |
| PA | Activation des patients |
| ADM | Administration (utilisé pour les questionnaires sur le diabète et sur les problèmes respiratoires) |
La troisième position du nom de la variable est un D si le module appartient au questionnaire sur le diabète ou un R si le module appartient au questionnaire sur les problèmes respiratoires. Un certain nombre de modules figurent dans les deux questionnaires, mais les questions diffèrent pour le diabète et les problèmes respiratoires.
11.3.3 Position 4: Cycle et nom de l'enquête
Le X se retrouvant à la quatrième position de la variable indique que cette variable fait partie de l'EPMCC.
| - | Variable collectée | Variable qui figure directement sur le questionnaire. |
|---|---|---|
| C | Variable codée | Variable codée à partir d'une ou de plusieurs variables collectées (par exemple, code de la Classification type des industries (CTI)). |
| D | Variable dérivée | Variable calculée d'après une ou plusieurs variables collectées ou codées, ordinairement pendant le traitement au Bureau central (p. ex., indice de l'état de santé). |
| F | Variable indicatrice | Variable calculée à partir d'une ou de plusieurs variables collectées (comme variable dérivée), mais ordinairement par l'application informatique de collecte des données, aux fins de son utilisation ultérieure durant l'interview (p. ex., indicateur de travail). |
| G | Variable groupée | Variables collectées, codées, supprimées ou dérivées, agrégées en un groupe (p. ex., groupes d'âge). |
11.3.5 Positions 6-8: Nom de la variable
En général, les trois dernières positions correspondent à la numérotation de la variable qui figure sur le questionnaire. On supprime la lettre « Q » utilisée pour représenter le mot "question" et on présente tous les numéros de question au moyen d'un groupe de deux chiffres. Par exemple, la question Q01A d'un questionnaire devient simplement 01A, et la question Q15 devient simplement 15.
Quand certaines questions comportent plusieurs réponses, la position finale dans la séquence du nom de la variable correspond à une lettre. Pour ce genre de questions, de nouvelles variables sont créées dans le but de différencier un « oui » d'un « non » pour chaque possibilité de réponse. Par exemple, si la question Q2 possède 4 réponses possibles, les nouvelles questions seront Q2A pour la première possibilité, Q2B pour la deuxième, Q2C pour la troisième et ainsi de suite. Si les options 2 et 3 seulement sont choisies, Q2A = Non, Q2B = Oui, Q2C = Oui et Q2D = Non.
11.4 Structure des composantes du nom des variables dans l'ESCC
Comme les fichiers de données de l'EPMCC ont été couplés à ceux de l'ESCC, il est important de pouvoir faire la distinction entre les deux enquêtes. Les règles d'attribution de noms de variables de l'EPMCC et de l'ESCC sont très similaires. La seule exception étant que pour l'EPMCC, un X figure à la position quatre pour indiquer que la variable vient de cette enquête.
Par exemple, la variable d'âge figure dans l'ESCC ainsi que dans l'EPMCC. Voici à quoi ressemble son nom dans les deux enquêtes :
EPMCC : DHHX_AGE
ESCC : DHH_AGE
Ainsi, si la même variable figure dans l'EPMCC et dans l'ESCC, il est important de veiller à ce que la bonne variable soit spécifiée dans l'analyse.
Notes
- Note de bas de page 1
-
Selon les définitions des problèmes de santé, aucun membre de l'échantillon de l'EPMCC ne pouvait être classé comme souffrant à la fois d'asthme et de MPOC. Par conséquent, les répondants pouvaient être classés au plus sous deux problèmes de santé, soit MPOC et diabète ou asthme et diabète.