
Série sur les développements en matière d’apprentissage automatique : troisième numéro
Par : Nicholas Denis, Statistique Canada
Les sujets de ce numéro :
- La modélisation générative avancée désormais disponible pour les données tabulaires
- Il suffit de remplir les cases vides
- L’utilisation d’autoencodeurs masqués pour l’imputation de données tabulaires
La modélisation générative avancée désormais disponible pour les données tabulaires
Les modèles probabilistes de diffusion de débruitage peuvent être appliqués à tout ensemble de données tabulaires et être utilisés pour traiter tout type de caractéristique afin de générer des données synthétiques qui peuvent parfois être plus efficaces que les données réelles.
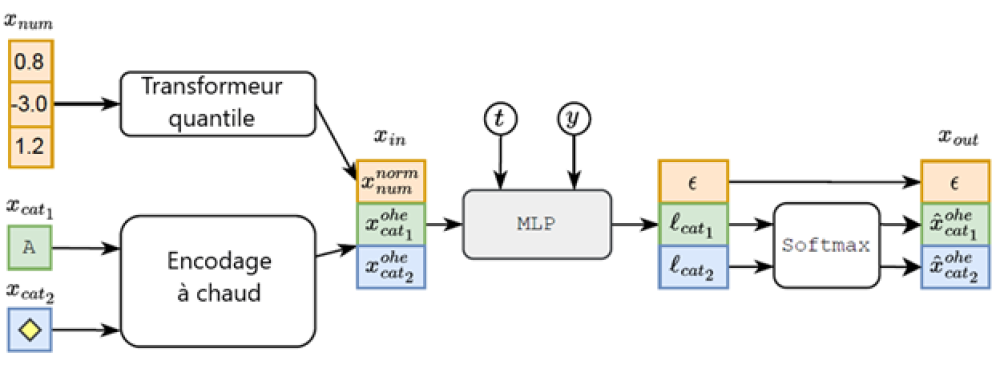
Figure 1 : Schéma TabDDPM pour le problème de classification; t, y, et l désignent respectivement un pas de temps de diffusion, une étiquette de classe et des logits.
Données passant par le schéma TabDDPM. Une instance de données tabulaires, x, est composée de caractéristiques numériques (num) et catégorielles (cat). Les caractéristiques numériques sont transformées à l'aide du transformeur quantile, et les caractéristiques catégorielles sont soumises à un encodage 1 parmi n (à chaud). Le processus de bruit direct est calculé et corrompt l'entrée transformée à un pas de temps, t, qui est utilisé comme entrée dans TabDDPM. TabDDPM est un perceptron multicouche (MLP) et est conditionné par le pas de temps de diffusion, t, et l'étiquette de classe, y. La sortie de TabDDPM est le bruit estimé ajouté aux caractéristiques numériques, ε, et les caractéristiques catégorielles estimées non corrompues (originales) à encodage à chaud.
La figure contient les éléments suivants :
- Transformeur quantile (: 0.8, -3.0, 1.2)
- avance jusqu’à 3.
- Encodage à chaud (, )
- avance jusqu’à 3.
- X dans (, ),
- avance jusqu’à 4.
- MLP
- t avance jusqu’à 4.
- Y avance jusqu’à 4.
- avance jusqu’à 5.
- , ,
- avance jusqu’à 7.
- , avance jusqu’à 6.
- Softmax
- De avance jusqu’à 7.
- De avance jusqu’à 7.
- X out ( , , )
Quoi de neuf? Les modèles probabilistes de diffusion de débruitage (DDPM) produisent des résultats remarquables dans la génération de texte-image (p. ex. Imagen, Stable Diffusion, DALL-E 2) et ont été appliqués à des ensembles de données tabulaires. Cela a permis de générer des instances de données tabulaires synthétiques comprenant des caractéristiques numériques et catégorielles.
Comment cela fonctionne-t-il? Un DDPM typique utilise un processus de bruit gaussien direct et un processus de débruitage inverse (acquis) pour transformer un bruit pur échantillonné à partir d'une distribution normale multivariée standard en une instance de données synthétiques. De même, les données tabulaires avec modèles de diffusion (TabDDPM - en anglais seulement) comprennent également un processus de diffusion multinomial qui permet d'appliquer le DDPM aux caractéristiques catégorielles, ordinales et booléennes que l'on trouve généralement dans les données tabulaires.
Pourquoi cela fonctionne-t-il? Pour un examen rapide des modèles DDPM et du processus de diffusion gaussien, veuillez consulter la Série sur les développements en matière d'apprentissage automatique : deuxième numéro. Ici, nous nous concentrerons sur le processus de diffusion multinomial :
- Faites en sorte que soit une variable à encodage à chaud de K dimensions (catégories).
- Un processus de diffusion directe, , sur des pas de temps T, s’écrit comme suit :
où , est un schéma de bruit.
- Le postérieur est bien défini, et le processus de diffusion inverse est estimé à l’aide d’un réseau neuronal : Le réseau peut maximiser la limite inférieure variationnelle (divergences KL dans le processus de diffusion inverse).
- Les caractéristiques numériques sont transformées à l’aide du transformeur quantile et les caractéristiques catégorielles (ordinales, booléennes, etc.) sont transformées en encodages à chaud. Des modèles de diffusion gaussiens et multinomiaux sont formés sur chaque type de caractéristique, respectivement.
Résultats : Plusieurs modèles génératifs de base sont comparés, dont des réseaux antagonistes génératifs (RAG) et un autoencodeur variationnel (AEV), spécialement conçu pour les ensembles de données tabulaires. Quinze ensembles de données tabulaires différents sont utilisés. Les auteurs utilisent une approche formalisée et normalisée pour évaluer la qualité des données synthétiques générées par un modèle génératif, appelée efficacité en matière d'apprentissage automatique. Cette approche mérite d'être expliquée en détail pour toute personne qui s'intéresse à l'évaluation de la qualité des ensembles de données synthétiques.
Tout d'abord, les données réelles sont ajustées à un classificateur CatBoost (en anglais seulement) en utilisant un budget d'optimisation des hyperparamètres fixe et un outil d'optimisation des hyperparamètres appelé Optuna (en anglais seulement). Une fois les hyperparamètres optimaux trouvés, un modèle CatBoost est entraîné en utilisant les données synthétiques. Le score F1 du modèle, évalué en fonction de données réelles, est appelé le score d'efficacité en matière d'apprentissage automatique. Cette valeur mesure la qualité des données synthétiques par leur capacité à être utilisées à la place des données réelles pour les tâches d'apprentissage automatique en aval.
- TabDDPM a généré de meilleurs résultats que les autres approches d'apprentissage profond dans 14 ensembles de données sur 15.
- Sur 5 des 15 ensembles de données, un modèle CatBoost entraîné sur des données synthétiques provenant de TabDDPM a obtenu une précision de test plus élevée qu'un modèle CatBoost entraîné sur des données réelles.
Pourquoi est-ce important? Les DDPM produisent des données synthétiques réalistes dans d'autres modalités. L'échantillonnage d'instances de données tabulaires synthétiques de grande qualité peut avoir des applications dans l'augmentation des données, en générant et communiquant des versions synthétiques d'ensembles de données de nature délicate qui peuvent garantir la confidentialité, l'imputation et l'équilibre des ensembles de données déséquilibrés par classe.
Mais... Lorsqu'elle a été testée, la technique de suréchantillonnage synthétique des minorités (SMOTE -en anglais seulement) a systématiquement donné de meilleurs résultats que le TabDDPM, bien qu'il s'agisse d'une technique plus ancienne et plus simple qui génère de nouvelles instances de données en prenant des combinaisons convexes d'instances de données dans l'ensemble de données. De plus, l'entraînement de TabDDPM est coûteux au chapitre des calculs, en particulier avec son approche d'optimisation des hyperparamètres Optuna.
Notre avis : Avec un accès à une GPU (unité de traitement graphique) pour l'entraînement du modèle, TabDDPM est un excellent moyen de générer des données tabulaires synthétiques de grande qualité et restera une base solide pour les améliorations futures des DDPM tabulaires.
Il suffit de remplir les cases vides
Les chercheurs en intelligence artificielle de Facebook ont obtenu des performances de pointe sur l'ensemble de données ImageNet-1K en appliquant aux ensembles de données de vision par ordinateur la même tâche de préentraînement que celle appliquée aux modèles de langage.
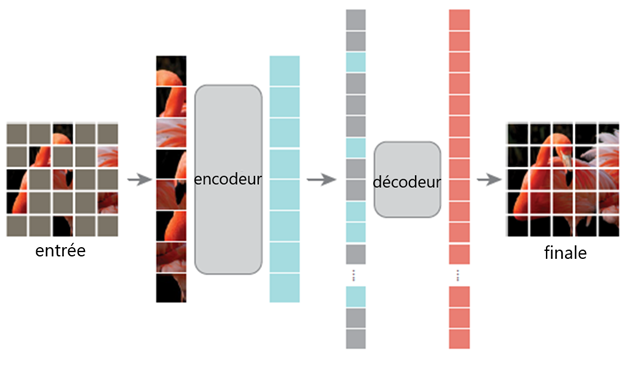
Figure 2 : Architecture d'un autocodeur masqué, dans laquelle 75 % des blocs de pixels sont masqués, puis reconstruits comme tâche de préentraînement.
Une image de l'architecture d'un autoencodeur masqué.
Image d'entrée d'un flamant rose pixellisé, dont la plupart des pixels sont grisés. Transmission à l'encodeur avec tous les pixels non masqués. Transmission au décodeur avec les pixels masqués seulement. Transmission à la cible finale, une image du flamant rose pixelisée sans pixels masqués].
Quoi de neuf? Les autoencodeurs masqués (AEM) combinent l'architecture Vision Transfer (ViT) et la tâche de préentraînement de prédiction de jetons masqués de modèles de langage de type BERT ((en anglais seulement) Bidirectional Encoder Representations from Transformers, ou Représentations d'encodeur bidirectionnel à partir de réseaux autoattentifs) pour produire des performances de pointe sur diverses tâches et ensembles de données de vision par ordinateur.
Comment cela fonctionne-t-il? Les modèles de langage de type BERT encodent et représentent le langage naturel en exécutant une tâche de préentraînement de modèle de langage masqué. Lorsqu'on reçoit une grande quantité de données textuelles, une phrase est introduite dans le modèle, dans laquelle 15 % des jetons de mots d'entrée sont masqués. En déduisant correctement les mots masqués, les modèles de type BERT capturent la sémantique des entrées textuelles, ce qui les rend utilisables pour des tâches de traitement du langage naturel en aval, comme la classification de textes. L'AEM utilise la même approche, mais au lieu de masquer les mots, 75 % des blocs de pixels de l'image sont masqués et reconstruits.
Pourquoi cela fonctionne-t-il? L'AEM utilise une architecture d'encodeur et décodeur asymétrique. L'encodeur et le décodeur sont tous deux des modèles autoattentifs. Comme 75 % des blocs de l'image sont masqués, seuls 25 % sont traités par l'encodeur, ce qui le rend plus efficace sur le plan informatique que les ViT traditionnels pour l'apprentissage supervisé standard. Le décodeur présente également une architecture à plus petite échelle et reconstruit les blocs masqués. En réduisant au minimum la perte de reconstruction, le modèle apprend à extraire des renseignements globaux sur une image, y compris les zones masquées, uniquement à partir des pixels des zones « visibles ». Une fois le préentraînement terminé, le décodeur est éliminé, et l'encodeur agit comme un modèle préentraîné qui peut être utilisé tel quel pour transformer les entrées en vue d'une classification linéaire ou qui peut être affiné.
Résultats :
- L'utilisation de l'ensemble de données ImageNet-1K (IN1K), le préentraînement de l'AEM, puis l'affinage pour 50 époques ont permis d'obtenir une précision supérieure à celle du précédent modèle de pointe entièrement supervisé.
- En utilisant diverses architectures ViT standard, l'AEM a systématiquement donné de meilleurs résultats que les techniques de préentraînement supervisé de pointe précédentes, notamment dans l'ensemble de données IN1K pour la classification, dans l'ensemble de données COCO pour la détection d'objets et la segmentation d'instances, ainsi que dans l'ensemble de données ADE20k pour la segmentation sémantique.
- Lors de l'évaluation de l'apprentissage par transfert, l'AEM a dépassé tous les résultats précédents sur le plan de la précision de pointe pour divers ensembles de données iNaturalist et Places, dans certains cas de jusqu'à 8 %.
Notre avis : Les techniques de préentraînement deviennent de plus en plus puissantes et peuvent désormais surpasser les paradigmes d'apprentissage supervisé standard. L'AEM n'est pas seulement impressionnant par ses résultats, mais aussi par sa simplicité. Cet article ne s'appuie pas sur des fonctions ou éléments surajoutés; l'architecture ViT de base est utilisée, et des améliorations importantes des résultats sont attendues en utilisant des architectures autoattentives de vision avancées.
Bien qu'elle soit relativement récente, la technologie des AEM a été appliquée aux données spatiotemporelles, aux données multimodales et aux données tabulaires, et elle est appelée à rester à des fins allant au-delà du préentraînement pour l'apprentissage supervisé. Elle a été utilisée pour l'imputation de données et peut être utilisée pour l'apprentissage partiellement supervisé. Des modèles d'AEM préentraînés peuvent également être téléchargés et utilisés en visitant Github Facebookresearch/mae (en anglais seulement)
L'utilisation d'autoencodeurs masqués pour l'imputation de données tabulaires
Les chercheurs transforment un imputeur en imputeur. Comment, que dites-vous?
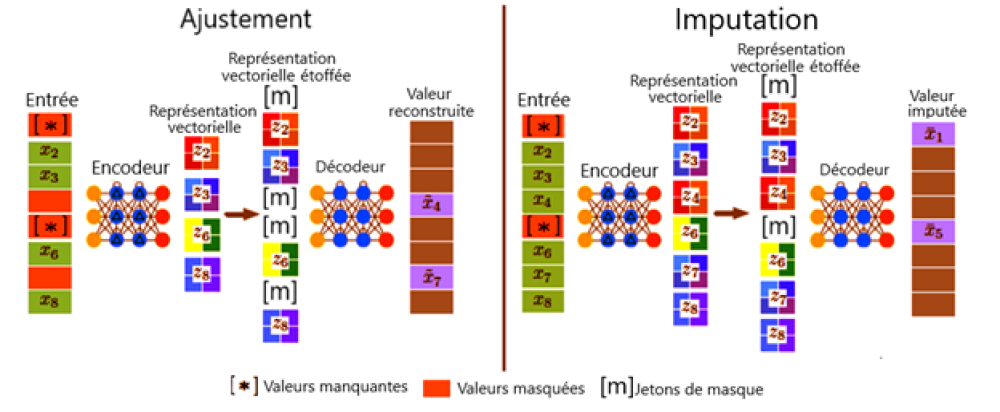
Figure 3 : Cadre général de ReMasker.
Au cours de l'étape d'ajustement, pour chaque entrée, en plus de ses valeurs manquantes, un autre sous-ensemble de valeurs (valeurs remasquées) est sélectionné aléatoirement et masqué. L'encodeur est appliqué aux valeurs restantes pour générer sa représentation vectorielle, qui est étoffée au moyen de jetons masqués et traitée par le décodeur pour reconstruire les valeurs remasquées. Au cours de l'étape d'imputation, le modèle optimisé est appliqué pour prédire les valeurs manquantes.
Étape d'ajustement :
Entrée, encodeur, représentation vectorielle, passage à la représentation vectorielle étoffée, décodeur et valeur reconstruite.
Étape d'imputation :
Entrée, encodeur, représentation vectorielle, passage à la représentation vectorielle étoffée, décodeur et valeur imputée.
Quoi de neuf? Comme nous l'avons expliqué ci-dessus, les AEM sont entraînés pour imputer les données manquantes. Les chercheurs ont décidé de faire l'impensable et d'appliquer des AEM aux données tabulaires afin d'imputer les données manquantes.
Comment cela fonctionne-t-il? L'AEM et la tâche de prédiction de jeton masqué ont été développés à l'origine pour préentraîner un encodeur qui pourrait être affiné pour la classification en aval. Dans l'exécution initiale de l'AEM, le décodeur était écarté après le préentraînement. Dans ReMasker, l'encodeur et le décodeur sont conservés, puis appliqués aux valeurs manquantes réelles de l'ensemble de données pour déduire leurs valeurs.
Pourquoi cela fonctionne-t-il? ReMasker est entraîné avec un ensemble de données tabulaires comportant des valeurs manquantes réelles. Pendant l'entraînement, chaque entrée est masquée par un mécanisme de masquage et produit une entrée avec un mélange de valeurs visibles, de valeurs masquées et de valeurs manquantes. Les valeurs visibles entrent dans l'encodeur (architecture autoattentive), et les jetons de sortie sont combinés avec des jetons de masque assimilables et des encodages positionnels remplaçant les caractéristiques masquées et manquantes. Ceux-ci passent ensuite par le décodeur (architecture autoattentive). Le modèle déduit alors la valeur originale des caractéristiques masquées, mais pas les valeurs manquantes réelles.
Au moment du test, aucun masquage supplémentaire n'a été utilisé, et les instances de données avec des caractéristiques manquantes sont appliquées à ReMasker pour déduire les valeurs manquantes. Tout comme les auteurs de l'article original sur l'AEM l'indiquent, l'encodeur apprend à représenter l'information globale d'une image à partir des blocs de pixels visibles. Les auteurs de l'article sur ReMasker affirment que l'encodeur apprend une représentation « invariante par rapport aux valeurs manquantes » des données. Ce faisant, ReMasker apprend à représenter les instances de données tabulaires d'une manière discriminante qui est robuste par rapport aux caractéristiques manquantes.
Résultats : Les auteurs ont effectué des expériences à l'aide de 12 ensembles de données tabulaires provenant du référentiel d'apprentissage automatique de l'UCI (en anglais seulement), ont envisagé trois mécanismes différents pour échantillonner les valeurs manquantes et ont comparé ReMasker avec 13 techniques d'imputation de pointe. Les mesures de performance comprenaient la racine de l'erreur quadratique moyenne des valeurs imputées par rapport aux valeurs réelles, la distance de Wasserstein des données imputées par rapport aux données réelles et l'aire sous la courbe des caractéristiques opérationnelles de réception (AUROC), pour mesurer l'efficacité des données imputées pour les tâches de classification en aval.
- ReMasker a systématiquement égalé ou surpassé presque toutes les approches d'imputation de base, la plupart du temps ou tout le temps.
- L'approche d'imputation la plus proche était HyperImpute, une nouvelle approche d'imputation de pointe qui utilise un ensemble de méthodes d'imputation et sélectionne le meilleur modèle d'imputation pour chaque colonne d'un ensemble de données.
- Les preuves empiriques semblent indiquer que les performances de ReMasker augmentent lorsque la taille de l'ensemble de données augmente, et lorsque le nombre de caractéristiques augmente.
- ReMasker est robuste par rapport à la quantité de valeurs manquantes, affichant des performances constantes de 10 % à 70 % de caractéristiques manquantes.
- Puisque HyperImpute est une approche d'assemblage, les auteurs ont inclus ReMasker comme modèle de base possible dans HyperImpute et ont montré qu'il produisait une amélioration supérieure des résultats de HyperImpute.
- Pour tester leur hypothèse selon laquelle l'application du préentraînement de l'AEM sur des données tabulaires permet à l'encodeur d'apprendre des représentations des données « invariantes par rapport aux valeurs manquantes », les auteurs ont calculé l'alignement du noyau centré entre les encodages des données complètes et les encodages des données avec des valeurs manquantes entre 10 % et 70 %. Ils ont constaté que la similarité était robuste et ne diminuait que légèrement à mesure que la proportion de caractéristiques manquantes augmentait, ce qui confirme leur hypothèse.
Quel est le contexte? Les ensembles de données du monde réel contiennent des données manquantes pour de nombreuses raisons. L'utilisation de données pour les modèles d'apprentissage automatique, les statistiques officielles ou l'inférence de toute sorte doit aborder la question de savoir comment utiliser ou non les données avec des valeurs manquantes. L'imputation est importante et constitue un domaine de recherche actif au sein de la communauté de l'apprentissage automatique et de celle des méthodes statistiques.
Notre avis : Étant donné que la technique de préentraînement de l'AEM exécute explicitement l'imputation, ce n'était qu'une question de temps avant qu'un chercheur ne teste son application pour l'imputation sur des ensembles de données tabulaires. Il s'agit d'une bonne première exploration de la façon dont l'AEM peut être utilisé à de telles fins.
Rencontre avec le scientifique des données

Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Jeudi, le 16 mars
De 14 00 h à 15 30 h, HE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données.
À bientôt!
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
- Date de modification :