
Classification de texte des offres d’emploi dans la fonction publique
Par Dominic Demers et Jessica Lachance, Commission de la fonction publique du Canada
Introduction
La Commission de la fonction publique (CFP) est un organisme indépendant dont le mandat est de promouvoir et de protéger une fonction publique impartiale, fondée sur le mérite et représentative de tous les Canadiens. Parmi ses nombreuses responsabilités, la CFP supervise également plus de 50 000 activités d'embauche qui relèvent de la Loi sur l'emploi dans la fonction publique (LEFP), chaque année.
Ce riche environnement de données comprend plus d'un million de curriculum vitæ et 8 000 offres d'emploi par an. Certaines données sont structurées, comme le nom de l'organisation ou le groupe et le niveau du poste. Cependant, la plupart des données sur les ressources humaines (RH) recueillies par la CFP ne sont pas structurées. Les données non structurées, comme les offres d'emploi ou les questions de présélection, peuvent être utilisées à des fins d'analyse.
La Direction des services de données et de l'analyse de la CFP est responsable des demandes de données, des études statistiques, des enquêtes, des modèles de prévision et des outils de visualisation des données pour les activités de dotation et de recrutement qui relèvent de la LEFP.
Le présent article donne un aperçu de deux techniques de traitement du langage naturel (TLN) utilisées par notre équipe pour extraire des renseignements précieux de deux zones de texte ouvertes, à savoir les variables Exigences en matière d'études et Zone de sélection. Nous expliquons également comment nous les avons utilisées par la suite pour alimenter l'Outil de prévision de candidatures, un outil de visualisation des données qui fait état d'offres d'emploi.
Outil de prévision de candidatures
En 2019, la CFP a élaboré l'Outil de prévision de candidatures pour aider les gestionnaires et les conseillers en RH du gouvernement du Canada à se préparer aux processus de sélection. Les utilisateurs peuvent sélectionner les caractéristiques d'une offre d'emploi et obtenir une estimation du nombre de candidats, en fonction d'emplois similaires qui ont déjà été annoncés.
La première version de l'outil ne fonctionnait qu'avec les données structurées des offres d'emploi. Cependant, la CFP a reçu des commentaires au sujet de deux zones de texte ouvertes que les utilisateurs souhaitaient exploiter pour obtenir une meilleure estimation du nombre de candidats pour leur processus de sélection. Ces zones comprenaient le niveau d'études dans les qualifications essentielles et, pour les processus internes, des détails sur la zone de sélection, comme le ministère, l'emplacement ou la classification.
Par conséquent, la CFP a utilisé des techniques de classification de texte pour les zones relatives aux études et à la zone de sélection afin de structurer les renseignements en catégories qui alimentent l'Outil de prévision de candidatures. Ces algorithmes ont permis à la CFP de produire des rapports plus précis et utiles.
Classification de texte
La classification de texte est un sous-ensemble de problèmes du TLN. L'objectif de la classification de texte est de prendre les zones de texte ouvertes et d'attribuer à chaque texte une étiquette à partir d'un ensemble limité d'options.
Dans notre cas, nous avons étudié deux modèles différents pour atteindre notre objectif. Pour la variable d'exigences en matière d'études, nous avons utilisé une approche fondée sur des règles employant des expressions courantes. Pour la variable de zone de sélection, nous avons utilisé une approche fondée sur l'apprentissage automatique appelée « Reconnaissance de l'entité désignée ».
Bien que la classification de texte à l'aide d'un modèle quelconque puisse produire de bons résultats, la capacité de l'algorithme à extraire des renseignements du texte n'est pas toujours fiable. Par conséquent, nous avons dû évaluer l'efficacité avec laquelle l'algorithme extrait les renseignements pertinents. Nous avons évalué le modèle à l'aide d'un ensemble de données d'essai et examiné les paramètres pour déterminer la performance du classificateur.
Évaluation des modèles de classification de texte
Pour évaluer la performance de nos algorithmes de classification de texte, nous avons utilisé une matrice de confusion. Il s'agit d'un tableau qui décrit la performance du modèle de classification pour un ensemble de données d'essai pour lesquelles les valeurs « vraies » sont connues.
Le nombre de prévisions exactes et inexactes est résumé dans un tableau et comprend des valeurs de comptage. Le tableau résume également le nombre d'erreurs commises par notre classificateur et, surtout, le type d'erreur.
La matrice de confusion comprend quatre types de combinaisons de valeurs prédites et vraies. Dans notre contexte de classification de texte, l'algorithme fournira une valeur « vraie » (ou « positive ») en cas de prédiction du texte dans le cadre de la classification. Par exemple, si le texte est classé comme « diplôme d'études secondaires », l'algorithme renverra une valeur « vraie » (ou « positive ») pour cette classification.
Les quatre catégories sont décrites ci-dessous.
Figure 1 : Matrice de confusion
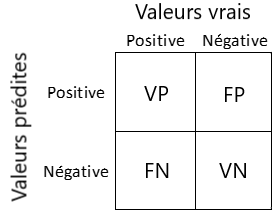
Description - Figure 1: Confusion Matrix
Diagramme quadrant avec quatre combinaisons de valeurs prédites et vraies.
Valeur prédite positive + valeur vraie positive = Vrai positif
Valeur prédite positive + valeur vraie négative = Faux positif
Valeur prédite négative + valeur vraie positive = Faux négatif
Valeur prédite négative + valeur vraie négative = Vrai négatif]
Combinaison Vrai positif (VP) : On prédit que la classification est vraie et cela est exact.
Combinaison Vrai négatif (VN) : On prédit que la classification est fausse et cela est exact.
Combinaison Faux positif (FP) ou erreur de type 1 : On prédit que la classification est vraie, mais cela est inexact.
Combinaison Faux négatif (FN) ou erreur de type 2 : On prédit que la classification est fausse, mais cela est inexact.
À partir de ces combinaisons, nous avons obtenu les mesures de performance suivantes :
- Exactitude : Pourcentage de textes qui ont été catégorisés avec la classification exacte. Sert à déterminer le nombre de classifications que le modèle a prédit correctement.
- Precision : The percentage of texts correctly classified out of the total number of texts classified as positive. Used to determine the proportion of positive identification that were correct.
- Recall : The percentage of actual positive values that are predicted correctly. Used to determine the proportion of actual positives that were correctly identified.
- Score F1 : Moyenne harmonique entre précision et rappel.
Dans le contexte du présent article, ces statistiques seront utilisées pour évaluer le rendement en matière de classification de deux variables, à savoir les variables Exigences en matière d'études et Zone de sélection.
Zone « Exigences en matière d'études »
Conformément à la LEFP, le Secrétariat du Conseil du Trésor a établi des normes de qualification par groupe professionnel ou classification pour l'administration publique centrale. Les normes de qualification définissent les exigences en matière d'études minimales pour chaque groupe professionnel. Les offres d'emploi pour les postes visés par la LEFP doivent inclure ces critères de mérite.
En règle générale, les gestionnaires utilisent la norme de qualification comme leur exigence essentielle. Mais ils peuvent établir des exigences en matière d'études supérieures au besoin. Par exemple, un gestionnaire d'embauche peut exiger qu'un analyste principal des politiques de niveau EC-06 ait une maîtrise, même si l'exigence minimale est un baccalauréat.
On pourrait s'attendre à ce que moins de candidats disposent d'une maîtrise que d'un baccalauréat. L'analyse du niveau d'études nous permettrait de fournir aux utilisateurs de l'Outil de prévision de candidatures des estimations et d'anciennes offres d'emploi plus pertinentes.
Méthode
Il y a un peu plus de 100 normes de qualification pour l'ensemble des groupes professionnels, lesquelles sont également rédigées en langage naturel. Nous avons déterminé que ces normes pouvaient être résumées comme appartenant à l'un des huit niveaux d'études suivants :
- Études secondaires partielles
- Études secondaires
- Études postsecondaires partielles
- Études postsecondaires
- Diplôme professionnel (p. ex. diplôme en droit, en médecine)
- Maîtrise
- Doctorat ou grade supérieur
- Niveau d'études inconnu/hors catégorie
Pour étiqueter les offres d'emploi en fonction du niveau d'études, nous avons utilisé des expressions courantes afin de trouver des phrases clés, que nous avons ensuite étiquetées. Les expressions courantes sont une séquence de caractères qui indiquent une tendance dans le texte. Pour analyser le niveau d'études, nous avons :
- trouvé des phrases clés, à l'aide d'expressions courantes, qui indiquent un type d'études;
- associé ces phrases à un niveau commun d'études;
- étiqueté du texte concernant les exigences en matière d'études avec l'un de ces niveaux communs.
Au total, nous avons utilisé 30 règles différentes pour établir une correspondance entre les descriptions de poste et les huit niveaux d'études. Ces règles ont été créées manuellement, à l'aide d'un processus itératif. Nous avons commencé par des expressions courantes qui saisissent la structure des phrases et les phrases clés utilisées dans de nombreuses normes de qualification. Nous avons ensuite ajouté des règles supplémentaires pour saisir les cas qui ne respectaient pas les normes de qualification.
Voici une représentation visuelle du processus :
Figure 2 : Classification des exigences en matière d'études

Description - Figure 2: Classification des exigences en matière d'études
**Veuillez lire la section *Autres renseignements*
ÉTUDES – EXIGENCES COMMUNES POUR TOUS LES VOLETS
Avoir terminé deux années de formation dans un programme acceptable d'études postsecondaires en informatique, en technologie de l'information, en gestion de l'information ou dans une autre spécialité connexe au poste à doter.
- Les employés nommés pour une période indéterminée qui étaient titulaires d'un poste du groupe CS au 10 mai 1999 et qui ne possèdent pas le niveau d'études prescrit ci-dessus sont réputés satisfaire à la norme minimale d'études de par leurs études, leur formation ou leur expérience. Il s'ensuit qu'ils doivent être reconnus comme ayant satisfait à la norme minimale d'études prescrite quand celle-ci est exigée aux fins de doter des postes du groupe CS.
– Il appartient à un établissement d'enseignement reconnu (p. ex. collège communautaire, cégep ou université) de déterminer si les cours suivis par un candidat correspondent à deux années d'un programme d'études postsecondaires au sein de l'établissement.
IMPORTANT :
– Il incombe aux candidats de fournir une preuve de leurs études. Veuillez noter que votre diplôme original sera exigé pendant le processus.
- Les candidats ayant des titres de compétence étrangers doivent fournir une preuve d'équivalence du Canada. Veuillez consulter le site Web du Centre d'information canadien sur les diplômes internationaux pour obtenir plus de renseignements. Les frais applicables sont à la charge du candidat. Les candidats qui ne sont pas en mesure de fournir la preuve qu'ils possèdent la qualification essentielle demandée seront éliminés du processus.
…années d'études… postsecondaires…
Études postsecondaires partielles
Dans cette image, la première section représente nos données. Le segment mis en évidence en vert indique la partie pertinente du texte liée aux exigences en matière d'études. « Avoir terminé deux années de formation dans un programme acceptable d'études postsecondaires en informatique, en technologie de l'information, en gestion de l'information ou dans une autre spécialité connexe au poste à doter ».
La deuxième section représente la règle qui a été appliquée au texte à l'aide d'expressions courantes. Le texte a été signalé comme contenant l'expression « … années d'études… postsecondaires ».
En raison de cet indicateur et de l'absence d'un indicateur d'une qualification supérieure (p. ex. « grade » ou « doctorat »), cette offre d'emploi a été étiquetée comme exigeant le niveau d'études « Études postsecondaires partielles ».
Évaluation du modèle
Pour évaluer le modèle, nous avons extrait un échantillon de 1 000 offres d'emploi de l'exercice 2019-2020 et avons étiqueté manuellement le niveau d'études correspondant à chaque offre. Le tableau ci-dessous présente la précision, le rappel et le score F1 de notre algorithme fondé sur des règles, pour chacun des huit niveaux d'études.
| Taille de l'échantillon | Précision | Rappel | Score F1 | |
|---|---|---|---|---|
| Niveau d'études inconnu/hors catégorie | 45 | 97,7 % | 95,6 % | 96,6 % |
| Études secondaires partielles | 30 | 100,0 % | 100,0 % | 100,0 % |
| Études secondaires | 418 | 99,3 % | 98,3 % | 98,8 % |
| Études postsecondaires partielles | 72 | 94,4 % | 94,4 % | 94,4 % |
| Études postsecondaires | 391 | 96,0 % | 97,7 % | 96,8 % |
| Diplôme professionnel | 17 | 100,0 % | 88,2 % | 93,8 % |
| Maîtrise | 17 | 83,3 % | 88,2 % | 85,7 % |
| Doctorat ou grade supérieur | 10 | 100,0 % | 90,0 % | 94,7 % |
Résultats
Nous avons appliqué l'algorithme à un total de 18 055 offres d'emploi entre le 1er avril 2016 et le 31 mars 2019. Le tableau suivant présente une répartition des offres d'emploi pour des postes EX-01, par niveau d'études tiré de l'algorithme. Comme l'indiquent les résultats ci-dessous, la grande majorité exigent des études secondaires ou postsecondaires.
| Exigences en matière d'études | Nombre d'offres d'emploi | Total (en %) |
|---|---|---|
| Études postsecondaires | 676 | 83 % |
| Maîtrise | 81 | 10 % |
| Études postsecondaires partielles | 27 | 3 % |
| Niveau d'études inconnu/hors catégorie | 16 | 2 % |
| Études secondaires | 13 | 2 % |
| Diplôme professionnel | 2 | 0 % |
| Total | 815 | 100 % |
À l'aide de cette méthodologie, lorsqu'ils accèdent à l'Outil de prévision de candidatures pour estimer le nombre de demandes d'emploi, les utilisateurs peuvent filtrer les résultats dans ce nouveau champ lié aux études. Par exemple, depuis le 1er avril 2015, 921 postes EX-01 ont été annoncés et ont suscité l'intérêt d'un nombre médian de 30 candidats. Sur ces offres, 806 exigeaient un diplôme d'études postsecondaires et ont suscité l'intérêt d'un nombre médian de 32 candidats.
Zone « Zone de sélection »
Contexte
Conformément au paragraphe 34(1) de la LEFP, en vue de l'admissibilité à tout processus de nomination, une organisation peut limiter la zone de sélection pour les processus d'emploi internes en fixant des critères géographiques, organisationnels ou professionnels. Cette restriction est inscrite dans le champ « Qui est admissible » d'une offre d'emploi.
Une zone de sélection restreinte réduira le bassin de candidats potentiels. Les utilisateurs de l'Outil de prévision de candidatures souhaitaient connaître le nombre de candidats auquel ils pourraient s'attendre s'ils limitaient leur zone de sélection aux employés du niveau mentionné de leur ministère uniquement, par opposition à tous les fonctionnaires au Canada.
Méthode
Notre objectif était d'analyser le contenu de la zone de texte ouverte « Zone de sélection » pour en extraire le ou les ministères, emplacements et niveaux mentionnés en utilisant une technique appelée « reconnaissance de l'entité désignée ». Un modèle de reconnaissance de l'entité désignée est une technique de TLN qui désigne les « entités » dans un bloc de texte, comme les noms propres (nom d'une personne, pays) ou une catégorie de choses (animaux, véhicules).
Dans notre cas, les entités extraites sont les suivantes :
- des organisations (p. ex. « Transports Canada », « la fonction publique fédérale »);
- des emplacements (p. ex. « Canada », « région de l'Atlantique », « dans un rayon de 40 km de Winnipeg [Manitoba] »);
- les classifications des professions (p. ex. « EC-04 », « EX-01 »).
Pour appliquer le modèle de reconnaissance de l'entité désignée, nous avons utilisé spaCy (le contenu de cette page est en anglais seulement), une bibliothèque libre gratuite destinée au traitement avancé du langage naturel dans Python.
L'algorithme de reconnaissance de l'entité désignée de spaCy comprend les entités « ORG » (organisation), « LOC » (localisation) et « GPE » (géopolitique).
Pour réduire la quantité de marquage manuel, nous avons adopté une approche itérative afin de créer notre ensemble de données d'entraînement. Tout d'abord, nous avons utilisé l'algorithme par défaut de spaCy pour marquer un échantillon aléatoire de 1 000 zones de sélection. Nous avons ensuite apporté les changements suivants :
- Fusion des balises « LOC » et « GPE » en une seule balise « LOC »;
- Ajout d'une balise « LEVEL » qui indique les classifications professionnelles;
- Correction de tout autre problème lié aux balises « ORG » et « LOC ».
À partir de là, nous avons créé 200 autres exemples de données d'entraînement, qui ont été ciblés pour inclure des exemples supplémentaires de la balise « LEVEL » et d'autres cas que l'algorithme initial a systématiquement omis de repérer.
Une fois l'ensemble des données d'entraînement mis en place, l'algorithme de reconnaissance de l'entité désignée de spaCy effectue les tâches suivantes :
- Créer un modèle de prédiction en utilisant une partie des données d'entraînement étiquetées.
- Envoyer une version sans étiquette d'une autre partie des données d'entraînement au modèle et prédire les entités.
- Comparer les étiquettes prédites et les étiquettes vraies.
- Mettre à jour le modèle pour représenter les étiquettes inexactes. Le volume de changements entre les modèles est appelé « gradient ».
- Répéter jusqu'à ce que le gradient soit réduit et que les prédictions du modèle changent très peu entre les itérations.
Ce processus a engendré un modèle final qui peut déterminer les différents critères d'une zone de sélection. L'image ci-après illustre un exemple de marquage du modèle effectué.
Figure 3 : Classification de la zone de sélection

Description - Figure 3 : Classification de la zone de sélection
Employés de la fonction publique au niveau PM-04 ou d'une classification équivalente qui occupent un poste dans un rayon de 40 km d'Edmonton (Alberta)
Employés de la fonction publique (ORG) au niveau PM-04 (LEVEL) ou d'une classification équivalente qui occupent un poste dans un rayon de 40 km d'Edmonton (Alberta) [LOC]
En haut de l'image s'affiche le texte complet de la zone de sélection. En bas de l'image, nos trois « entités » sont mis en évidence. « la fonction publique » est marquée par la balise ORG, « PM-04 » par la balise LEVEL et « dans un rayon de 40 km d'Edmonton (Alberta) » par la balise LOC.
Évaluation du modèle
Nous avons évalué le modèle à l'aide d'un échantillon aléatoire de 465 énoncés de la zone de sélection, que nous avons étiquetés manuellement. Le tableau suivant montre les scores de précision et de rappel pour chaque type d'entité.Footnote 1
| Balise d'entité | Précision | Rappel | Score F1 |
|---|---|---|---|
| ORG | 92,6 % | 90,8 % | 91,7 % |
| LOC | 80,2 % | 74,9 % | 77,5 % |
| LEVEL | 95,0 % | 76,0 % | 84,4 % |
Résultats
À l'aide des résultats du modèle, nous avons produit l'analyse exploratoire suivante. Cette analyse est fondée sur 13 362 offres d'emploi internes entre le 1er avril 2016 et le 31 mars 2019.
Figure 4: Diagramme de Venn de la zone de texte ouverte « Zone de sélection », par organisation, groupe professionnel et géographie
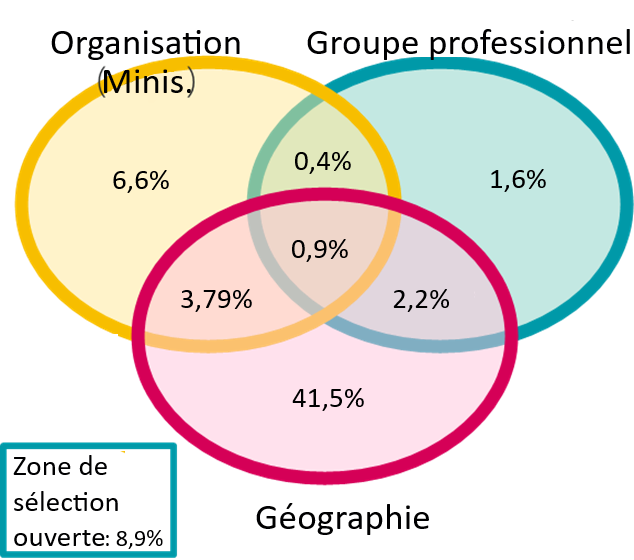
Description - Diagramme de Venn de la zone de texte ouverte « Zone de sélection », par organisation, groupe professionnel et géographie
Diagramme de Venn de la zone de texte ouverte « Zone de sélection » divisée en trois.
| Organisation (ministère) = 6,6 % | Part commune des entités Organisation et Groupe professionnel = 0,4 % |
| Groupe professionnel = 1,6 % | Part commune des entités Groupe professionnel et Géographie = 2,2 % |
| Géographie = 41,5 % | Part commune des entités Géographie et Groupe professionnel = 37,9 % |
| Part commune des trois entités : 0,9 % | Zone de sélection ouverte = 8,9 % |
Ce que nous avons constaté, c'est que la plupart des offres d'emploi internes utilisent au moins l'un des filtres décrits dans la LEFP et que la plupart des zones de sélection comportant un filtre géographique étaient pour les « personnes employées dans la fonction publique qui occupent un poste dans la région de la capitale nationale (RCN) ».
Cependant, nous avons constaté que certaines zones de sélection sont plus difficiles à analyser. En voici quelques exemples :
1) Employés de Transports Canada qui occupent un poste à Calgary, Edmonton, Saskatoon, Winnipeg, Whitehorse, Yellowknife ou Churchill.
2) En cas de nombre insuffisant de candidats, les personnes employées dans la fonction publique qui occupent un poste à moins de 40 km de Winnipeg (Manitoba) ou à moins de 40 km d'Edmonton ou de Calgary (Alberta) pourraient être prises en compte sans que le poste soit annoncé de nouveau. Par conséquent, les candidats dans cette zone de sélection élargie sont encouragés à poser leur candidature.
Notre modèle a donné de bons résultats, mais en raison de critères multiples, nous avons décidé d'utiliser notre analyse avec un ensemble plus vaste de catégories. Auparavant, dans l'Outil de prévision de candidatures, les utilisateurs pouvaient seulement choisir une « offre d'emploi interne » ou une « offre d'emploi externe ». Maintenant, les offres d'emploi internes que les utilisateurs peuvent choisir sont plus précises. Ils ont le choix entre les offres d'emploi suivantes:
- Offres d'emploi internes, ouvertes à tous les fonctionnaires
- Offres d'emploi internes, ouvertes aux fonctionnaires de la RCN
- Offres d'emploi internes (autres zones de sélection)
En ajoutant ces fonctionnalités à notre modèle, nous l'avons amélioré, de sorte qu'il permette aux utilisateurs de rechercher un ensemble plus restreint d'offres d'emploi pour trouver celles qui correspondent à leur processus de sélection prévu.
Conclusion
Les zones de texte ouvertes sont un excellent moyen de recueillir des renseignements et ne devraient pas être exclues des formulaires ou des enquêtes. Elles servent à recueillir des réponses fourre-tout lorsque les questions ne permettent pas aux utilisateurs de fournir des renseignements dans un ensemble de choix prédéfini.
Mais cette souplesse se fait au détriment de l'exactitude des classifications. Les systèmes de classification peuvent générer les bonnes prédictions (valeurs vraies positives et vraies négatives), mais peuvent aussi produire les mauvaises (valeurs fausses positives et fausses négatives). La validation croisée du rendement de votre algorithme sera essentielle afin de déterminer si les classifications sont suffisamment précises à des fins de production de rapports.
Le présent article a exposé des méthodes qui visent à structurer les renseignements tirés des zones de texte ouvertes aux fins de production de rapports dans l'Outil de prévision de candidatures. Les catégories provenant des zones « Zone de sélection » et « Exigences en matière d'études » ont été utilisées pour remplir des menus déroulants permettant aux utilisateurs d'améliorer leurs résultats de recherche.
Nous vous encourageons à consulter l'Outil de prévision de candidatures ou nos autres outils de visualisation des données dans le Centre de visualisations des données de la CFP.

Si vous avez des questions à propos de cet article ou si vous souhaitez en discuter, nous vous invitons à notre nouvelle série de présentations Rencontre avec le scientifique des données où le(s) auteur(s) présenteront ce sujet aux lecteurs et aux membres du RSD.
mardi, le 18 octobre
14 h 00 à 15 h 00 p.m. HAE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données. À bientôt !
- Date de modification :