
Extraction de tendances temporelles à partir d’images satellitaires
Par : Kenneth Chu, Statistique Canada
La Division de la science des données de Statistique Canada a récemment terminé un certain nombre de projets de recherche visant à évaluer l’efficacité d’une technique statistique appelée analyse en composantes principales fonctionnelles (ACPF) comme méthode d’ingénierie des caractéristiques afin d’extraire les tendances temporelles des données des séries chronologiques de satellites radar à synthèse d’ouverture (RSO).
Ces projets ont été réalisés en collaboration avec la Division de l’agriculture et la Division de la statistique de l’énergie et de l’environnement de Statistique Canada, ainsi qu’avec le Centre national de recherche faunique (CNRF) d’Environnement et Changement climatique Canada. Ces projets ont utilisé les données de Sentinel-1. Sentinel-1 est une constellation de satellites radar du programme Copernicus de l’Agence spatiale européenne. Elle recueille des données d’imagerie RSO qui capturent des renseignements sur les structures de la surface terrestre de la zone imagée. Sentinel-1 assure une couverture mondiale tout au long de l’année et dans toutes les conditions météorologiques de la zone imagée. Les données ne sont pas influencées par l’alternance du jour et de la nuit, ont une haute résolution spatiale (environ 10 m x 10 m) et une fréquence fixe de capture des données tous les 12 jours pour chaque zone imagée. Par conséquent, les données de Sentinel-1 conviennent parfaitement aux études scientifiques, car les structures de la surface de la Terre contiennent des renseignements importants.
Nos résultats suggèrent que l’ACPF pourrait être un outil très efficace pour extraire numériquement les tendances temporelles saisonnières saisies dans une série chronologique d’images de Sentinel-1 à grande échelle et de manière très granulaire. Le présent article présente un sommaire de la méthode fondée sur l’ACPF et de ses résultats d’extraction des caractéristiques à partir des séries chronologiques saisonnières de Sentinel-1.
Motivation
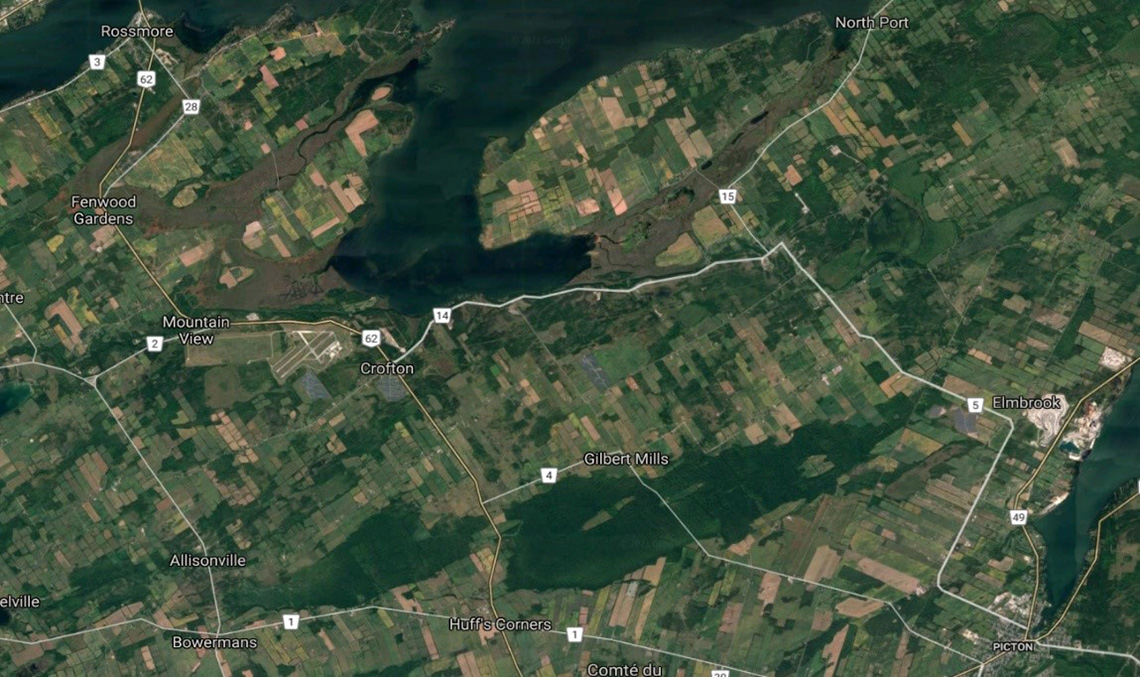
Je vais me concentrer sur l’une des zones d’étude de la recherche, à savoir la région de la baie de Quinte en Ontario, située près de Belleville. L’objectif de ce projet est de donner une classification plus précise des zones humides. Ce qui suit est une image satellitaire optique (plutôt qu’une image satellitaire radar) de la région de la baie de Quinte, téléchargée depuis Google Maps.
Figure 1: Image satellitaire optimale de la baie de Quinte, Ontario. Téléchargée depuis Google Maps.
Description - Figure 1
Image satellitaire optimale de la baie de Quinte, Ontario, située au centre en haut de l’image. Le reste montre un étalement généralement rural de la zone environnante et comprend plusieurs cantons ainsi que les autoroutes qui les relient. Les cantons représentés sont les suivants (dans le sens des aiguilles d’une montre, à partir du haut à gauche) : Rossmore, Fenwood Gardens, Mountain View, Crofton, Elmbrook, Picton, Gilbert Mills, Huff’s Corners, Bowermans et Allisonville.
Dans la Figure 1, notez la grande étendue d’eau au centre supérieur de l’image et les champs agricoles rectangulaires. Notez également l’île près du centre supérieur et la voie d’eau qui la sépare du continent.
Examinez ensuite la Figure 2, qui est une carte de la couverture terrestre de la région de la baie de Quinte.
Figure 2: Carte de la couverture terrestre de la baie de Quinte, ON. Cette image est créée à partir de données des séries chronologiques saisonnières de 2019 du RADARSAT-2 (Banks et al., 2019). Les couleurs indiquent les différents types de couverture terrestre : Le bleu indique l’eau, le rose indique les eaux peu profondes, le cyan montre les marais, le rouge indique les forêts, le vert correspond aux marécages et le marron indique des terres agricoles.

Description - Figure 2
Carte de la couverture terrestre de la baie de Quinte, ON, à partir des données des séries chronologiques de 2019 de RADARSAT-2. Les couleurs indiquent les différents types de couverture terrestre. La baie de Quinte est bleue, indiquant la présence d’eau, et se trouve principalement au centre supérieur de l’image. Le contour de la baie de Quinte est en cyan, ce qui indique une zone marécageuse, et comprend quelques points roses, indiquant des eaux peu profondes. La zone terrestre environnante est principalement rouge, ce qui dénote une zone forestière, et deux taches semi-grandes au centre inférieur de l’image sont vertes, faisant ressortir une zone marécageuse
La figure 3 est un rendu rouge, vert, bleu (RVB) des trois premiers scores des composantes principales fonctionnelles (CPF) calculés à partir des données des séries chronologiques de Sentinel-1 de 2019 pour la région de la baie de Quinte. Notez la remarquable granularité et le haut degré de concordance avec la carte de couverture terrestre de la Figure 2.
Figure 3: Rendu RVB des trois premiers scores de CPF calculés à partir des données des séries chronologiques de Sentinel-1 de 2019 pour la région de la baie de Quinte.

Description - Figure 3
Carte de la couverture terrestre de la baie de Quinte. Les couleurs indiquent les différents types de couverture terrestre. La baie de Quinte est bleue, indiquant la présence d’eau. Le contour de la baie de Quinte est rose et la zone terrestre environnante est principalement orange. Cette image est semblable au rendu de la figure 2
La carte de la couverture terrestre de la figure 2 a été créée à partir des données des séries chronologiques de 2019 de RADARSAT-2 (l’un des satellites d’observation de la Terre RSO de l’Agence spatiale canadienne), à l’aide de la méthodologie décrite dans Banks et al. (2019). Elle est bien corroborée par la réalité du terrain recueillie par des observations sur le terrain. Une observation notable ici est que la voie d’eau qui sépare l’île au centre supérieur de l’image et le continent contient en fait deux types de zones humides – les marais en cyan et les eaux peu profondes en rose. Ces deux types de zones humides ne sont pas faciles à distinguer sur la figure 1. L’article rapporte que les données des séries chronologiques saisonnières du RSO contiennent suffisamment de renseignements pour la classification des terres humides, mais la méthodologie décrite comporte un haut degré de prise de décision manuelle informée par des connaissances d’experts (p. ex. les saisies de données pour quelles dates ou statistiques à utiliser, etc.).Cette méthode demandait beaucoup de travail et la façon d’automatiser cette méthodologie et de l’appliquer à l’échelle régionale, provinciale ou pancanadienne n’était pas claire.
Le projet de la baie de Quinte a été motivé par la recherche d’une méthodologie automatisable et efficace pour extraire numériquement les tendances temporelles des séries chronologiques saisonnières RSO afin de faciliter les tâches de classification de la couverture terrestre en aval.
Principaux résultats : Visualisation des caractéristiques extraites par ACPF
L’ACPF peut être une méthodologie puissante pour extraire les tendances dominantes d’une collecte de séries chronologiques (Wang et al. 2016). Nous avons donc réalisé une étude de faisabilité sur l’utilisation de l’ACPF comme technique d’extraction de caractéristiques pour les séries chronologiques saisonnières RSO au niveau du pixel. Les caractéristiques qui en résultent sont des scores CPF au niveau du pixel. Nos résultats préliminaires suggèrent que la méthodologie fondée sur l’ACPF pourrait être remarquablement efficace. La figure 3 est le rendu RVB des trois premiers scores CPF (le premier score CPF est le canal rouge, le deuxième score CPF est le vert, le troisième score CPF est le bleu (Wikipédia 2022)); calculés à partir des données des séries chronologiques de Sentinel-1 de 2019 pour la baie de Quinte. Notez la remarquable granularité de la figure 3 et son niveau élevé de concordance avec la figure 2. Cela suggère fortement que les caractéristiques extraites fondées sur l’ACPF peuvent faciliter de manière importante les tâches de classification de la couverture terrestre en aval. La suite du présent article expliquera comment la figure 3 a été générée à partir des données des séries chronologiques de Sentinel-1.
Aperçu de la procédure d’extraction des caractéristiques fondée sur l’ACPF
Voici un aperçu de la procédure :
- Un sous-ensemble d’emplacements/pixels a été soigneusement et stratégiquement sélectionné dans la zone d’étude de la baie de Quinte.
- Leurs séries chronologiques de Sentinel-1 respectives ont été utilisées pour éduquer un moteur d’extraction des caractéristiques fondées sur l’ACPF.
- Le moteur d’extraction des caractéristiques fondé sur l’ACPF a ensuite été appliqué aux séries temporelles de Sentinel-1 de chaque emplacement/pixel de toute la zone de la baie de Quinte. La sortie de chaque série temporelle est une séquence ordonnée de nombres appelés scores CPF pour l’emplacement/pixel correspondant. Ces scores sont en ordre décroissant de la variabilité expliquée par leur CPF correspondante.
- La figure 3 ci-dessus est le rendu RVB des trois premiers scores CPF des données des séries chronologiques de 2019 de Sentinel-1.
Les données de formation
La collecte de données de formation (à partir des emplacements/pixels de la région de la baie de Quinte) a été soigneusement et stratégiquement choisie pour contenir des propriétés précises.
- Les emplacements de la formation étaient répartis dans toute la zone d’étude de la baie de Quinte.
- Les types de couverture terrestre étaient connus sur la base d’observations antérieures sur le terrain.
- Six types de couverture terrestre étaient représentés dans la collecte de formation : eau, eau peu profonde, marais, marécage, forêt et terres agricoles.
- La collecte de formation était bien équilibrée entre les types de couverture terrestre, car chaque type de couverture terrestre contenait exactement 1000 emplacements/pixels (à l’exception des eaux peu profondes, qui en comptaient 518).
- Les six types de couverture terrestre représentés dans la collecte de formation sont complets, car chaque emplacement/pixel de la zone d’étude de la baie de Quinte est couvert par l’un de ces six types de couverture terrestre.
Les données de Sentinel-1 ont deux polarisations – transmission verticale et réception verticale (VV), et transmission verticale et réception horizontale (VH). Ces deux polarisations peuvent être considérées comme deux variables observées mesurées par les satellites de Sentinel-1.
Les différentes structures de la surface de la Terre sont détectées avec des sensibilités différentes en polarisations. Par exemple, la diffusion des surfaces rugueuses, comme celles causées par un sol nu ou l’eau, est plus facilement détectée dans la polarisation VV. D’autre part, la diffusion volumique, généralement causée par les feuilles et les branches d’un couvert forestier, est plus facilement détectée dans les polarisations VH et HV. Enfin, un type de diffusion appelé à double réflexion, couramment causée par les bâtiments, les troncs d’arbres ou la végétation inondée, est plus facilement détecté dans la polarisation HH (NASA, 2022). Pour la suite de cet article, nous nous concentrerons sur la polarisation VV.
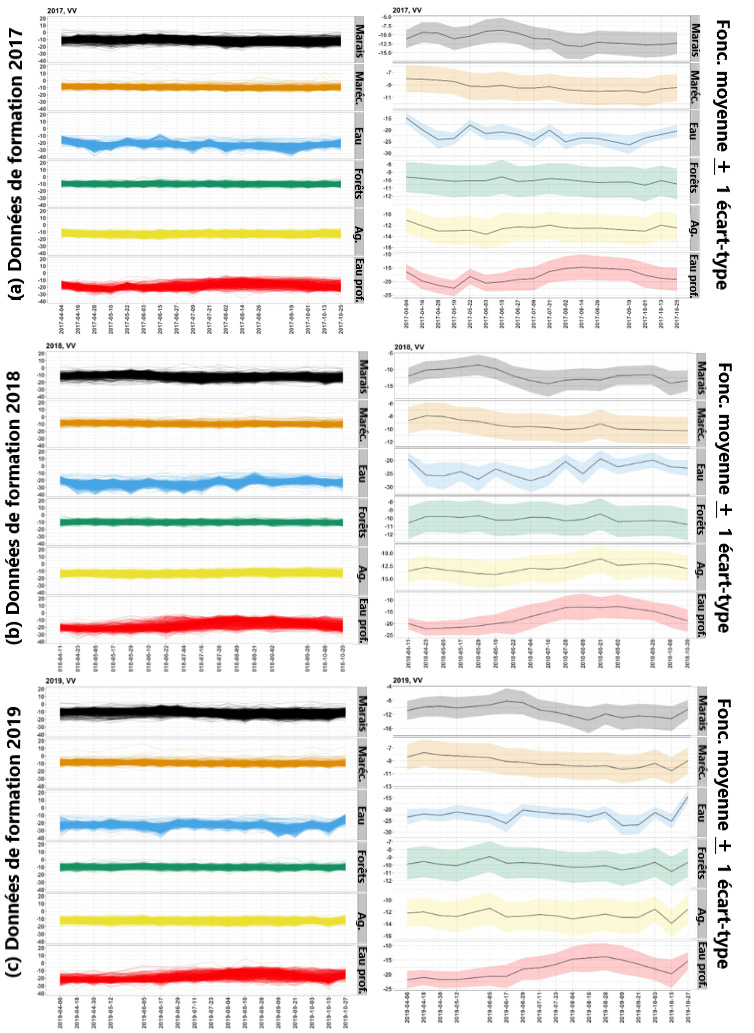
Figure 4: Données des séries chronologiques VV de Sentinel-1 pour les sites de formation et les diagrammes en ruban correspondants pour une visualisation facile des tendances temporelles. (a) : Données de 2017. Groupe du panneau gauche : Tracés linéaires des données des séries chronologiques VV de Sentinel-1 regroupés par type de couverture terrestre connu. Groupe du panneau droit : Graphiques en ruban correspondants, la courbe noire de chaque panneau indiquant la courbe moyenne particulière au panneau, et le ruban indiquant un écart-type au-dessus et au-dessous de la courbe moyenne particulière au panneau. (b), (c) : Données de 2018 et 2019, respectivement.
Description - Figure 4
Chaque panneau correspond à l’un des six types de zones humides pour 2017, 2018 et 2019 : marais, marécage, eau, forêt, agriculture et eau peu profonde. Chaque panneau contient 1000 séries chronologiques de formation, correspondant à 1000 emplacements de formation distincts, à l’exception du panneau inférieur, qui ne comporte que 518 séries chronologiques. L’axe horizontal affiche les dates d’observation. Elles sont espacées de 12 jours, sauf les écarts occasionnels.
Les quatre points suivants sont observés pour les données des séries chronologiques pour 2017, 2018 et 2019 :
- Observation 1 : La collecte des dates d’observation peut changer d’une année à l’autre, de même que les écarts.
- Observation 2 : L’eau et l’eau peu profonde ont en moyenne des valeurs plus faibles que le reste des types de zones humides.
- Observation 3 : Le diagramme en ruban des eaux peu profondes montre une tendance distincte qui commence à être faible au début de la saison de croissance et qui culmine ensuite à la fin du mois d’août.
- Observation 4: D’après le graphique en ruban des marais, on constate que les marais présentent à peu près la tendance opposée à celle des eaux peu profondes, à savoir qu’ils commencent par une valeur élevée qui redescend plus tard dans la saison].
Analyse en composantes principales fonctionnelles
Nous donnons une explication conceptuelle de l’ACPF en la comparant à l’analyse en composantes principales ordinaires (ACPO).
L’ACPO est :
- Supposons un ensemble fini (des points de données) est donné.
- Trouver des directions orthogonales , plus précisément, des sous-espaces unidimensionnels dans le long desquels présente la plus grande variabilité, la deuxième plus grande, la troisième plus grande, et ainsi de suite. Ici, l’orthogonalité est définie par le produit interne standard (produit scalaire) sur . Pour chaque sous-espace orthogonal unidimensionnel, choisir un vecteur unitaire dans ce sous-espace. Les vecteurs unitaires mutuellement orthogonaux résultants sont les composantes principales ordinaires et elles forment une base orthonormale pour .
- Réécrire chaque , en matière de composantes principales ordinaires. Les coefficients de cette combinaison linéaire sont les scores des composantes principales ordinaires de par rapport aux composantes principales ordinaires.
En quoi l’ACPF (plus précisément, la version particulière de l’ACPF que nous avons utilisée) diffère-t-elle de l’ACPO?
- L’espace vectoriel de dimension finie est remplacé par un sous-espace (éventuellement de dimension infinie) des fonctions intégrables en définies sur un certain intervalle (de temps) .
- Le produit interne standard sur est remplacé par le produit interne inner product sur F, c.-à-d. pour ,
Pourquoi l’ACPF peut-elle saisir des tendances temporelles?
- La raison en est que la « géométrie » de l’intervalle est intégrée dans la définition même du produit interne . Plus concrètement, le processus d’intégration des fonctions sur intègre des renseignements sur l’ordre et la distance entre chaque paire de points temporels.
- Cette « conscience » de la géométrie de l’intervalle permet à son tour au produit interne de saisir des renseignements sur les tendances temporelles.
Procédure générale pour appliquer l’ACPF à des données de séries chronologiques
- Supposons qu’un ensemble fini de séries chronologiques observées soit défini sur un ensemble commun de points temporels dans un certain intervalle de temps p. ex. dans la saison de croissance d’une certaine année civile), où et sont respectivement le point temporel commun initial et final.
- Interpoler chaque série temporelle donnée dans pour obtenir une fonction définie sur . On obtient un ensemble fini de fonctions définies sur l’intervalle commun , dont chacune est une interpolation d’une des séries chronologiques observées originales dans .
Remarque : Les B-splines sont un choix courant de techniques d’interpolation à cette fin (Schumaker, 2022). - Calculer la fonction moyenne globale et une séquence ordonnée de composantes principales fonctionnelles pour la collecte de fonctions (interpolations de séries chronologiques dans dans son ensemble. Notez que chaque CPF est elle-même une fonction définie sur (Wang et al. 2016).
Ensuite, pour chaque fonction dans , exprimez-la comme une combinaison linéaire des CPF. Les coefficients de cette combinaison linéaire sont les scores des CPF de la fonction donnée par rapport aux CPF.
Par conséquent, les fonctions dans , le CPF et les scores CPF peuvent être organisées comme suit :
Plus le nombre de CPF est important, plus les approximations ci-dessus devraient être précises.
- Nous considérons que la fonction moyenne globale et la séquence ordonnée de CPF sont ce qui a été appris des fonctions en utilisant le mécanisme de l’ACPF.
- Enfin, notons qu’une fois que la fonction moyenne globale et les CPF de ont été calculés (ou « apprises »), elles peuvent être utilisées pour calculer les scores de nouvelles fonctions définies sur , en particulier pour les interpolations de nouvelles séries chronologiques. C’est cette observation qui permet d’utiliser le mécanisme de l’ACPF comme une technique d’ingénierie des caractéristiques.
Déroulement des opérations d’extraction de caractéristiques fondées sur l’ACPF
Nous expliquons comment les scores des CPF qui sous-tendent la figure 3 ont été calculés dans le projet de la baie de Quinte.
- Comme décrit précédemment, une collecte d’emplacements/pixels « de formation » de la zone d’étude de la baie de Quinte a été méticuleusement choisie, comme décrit précédemment.
- Les données des séries chronologiques de Sentinel-1 pour 2017, 2018 et 2019 ont été extraites pour chaque emplacement/pixel de formation dans . Nous désignons la collecte des séries chronologiques résultantes par .
- Chaque série temporelle dans a été interpolée à l’aide de B-splines. Nous désignons la collecte de fonctions résultante par .
- La fonction moyenne globale et l’ensemble des composantes principales fonctionnelles ont été calculés (« appris ») à partir de en utilisant le mécanisme de l’ACPF. Ce mécanisme de l’ACPF a été mis en œuvre sous la forme de l’ensemble R fpcFeatures (actuellement, uniquement pour un usage interne au CNRF et à Statistique Canada).
- La série temporelle de Sentinel-1 de 2017 pour chacun des emplacements/pixels hors formation de la zone d’étude de la baie de Quinte a été interpolée avec des B-splines. Pour chacune des interpolations des B-spline résultantes, les scores CPF par rapport aux composantes principales fonctionnelles apprises ont été calculés. Cela s’applique également aux séries chronologiques Sentinel-1 hors formation de 2018 et 2019.
- Les scores CPF résultants sont considérés comme les caractéristiques extraites pour chaque emplacement/pixel. Ces caractéristiques extraites peuvent être utilisées pour des tâches d’analyse ou de traitement en aval, comme la visualisation (p. ex. le rendu RVB), la classification de la couverture terrestre, la détection des changements d’utilisation du sol, etc.
Ce déroulement des opérations d’extraction de caractéristiques fondées sur l’ACPF est illustré à la figure 5.
Figure 5: Schéma du déroulement des opérations d’extraction de caractéristiques fondée sur

Description - Figure 5
Le diagramme des caractéristiques des CPF commence par un carré pour les nouvelles données des séries chronologiques qui alimentent l’ensemble R, qui contient CPF 1, CPF 2, etc. Un carré pour des données des séries chronologiques de formation qui alimentent également l’ensemble R. Ensuite, le paquet R indique l’étape suivante, à savoir les caractéristiques ou le score CPF. Puis, des caractéristiques extraites sont générées, lesquelles peuvent être utilisées dans des tâches de traitement ou d’analyse en aval, p. ex. la visualisation par le rendu RVB, la classification de l’utilisation du sol, la détection des changements d’utilisation du sol
Les composantes principales fonctionnelles calculées
Si vous vous souvenez, le soi-disant « moteur d’extraction de caractéristiques fondé sur l’ACPF entraîné » n’est en fait que la fonction de moyenne globale et la séquence ordonnée de CPF (fonctions définies sur un intervalle de temps commun) calculées à partir des données de formation. La figure 6 présente les sept premières CPF calculées à partir des données des séries chronologiques de Sentinel-1 VV de formation pour 2017, 2018 et 2019 de la zone d’étude de la baie de Quinte.
Figure 6: Représentations graphiques des sept premières composantes principales fonctionnelles comme fonctions du temps.

Description - Figure 6
Sept graphiques linéaires des CPF calculés à partir des données des séries chronologiques de Sentinel-1 de 2017, 2018 et 2019. Dans chaque panneau, l’axe horizontal représente « l’indice des dates » où 1 correspond au jour de l’an, 2 correspond au 2 janvier, et ainsi de suite. L’axe vertical représente la valeur des scores CPF respectifs. CPF 1 – Variabilité saisie = 85,044 %; CPF 2 – Variabilité saisie = 7,175 %; CPF 3 – Variabilité saisie = 2,229 %; CPF 4 – Variabilité saisie = 1,677 %; CPF 5 – Variabilité saisie = 1,407 %; CPF 6 – Variabilité saisie = 1,162 %; CPF 7 – Variabilité saisie = 0,917 %. Une explication plus détaillée est donnée ci-dessous.
Ce sont des représentations graphiques des sept premières CPF en fonction du temps. Le panneau (en comptant à partir du haut) visualise la CPF. Rappelons que chaque CPF est, avant tout, une fonction (continue) du temps, considérée comme un vecteur dans un certain espace vectoriel des fonctions de (intégrable en ) définies sur un certain intervalle de temps.
Dans chaque panneau, la courbe grise indique la courbe moyenne des interpolations splines de toutes les séries chronologiques VV (sur tous les lieux de la formation et pour les années 2017, 2018 et 2019). Les CPF s’avèrent être des vecteurs propres d’une certaine carte linéaire (liée à la « variance » de l’ensemble de données d’apprentissage) de à elle-même (Wang et al. 2016). Dans chaque panneau, la courbe orange représente la fonction obtenue en ajoutant à la courbe moyenne (en gris) le multiple scalaire de la composante principale fonctionnelle , où est la valeur propre correspondant à . La courbe bleue est obtenue en soustrayant le même multiple de de la courbe moyenne. Notez également que la première composante principale explique environ 85,04 % de la variabilité des données de formation (série chronologique VV), la deuxième composante explique environ 7,18 %, et ainsi de suite.
Ensuite, notez que la première composante principale fonctionnelle ressemble à une ligne horizontale (courbe orange dans le panneau supérieur); elle capture la caractéristique la plus dominante dans les séries chronologiques de formation, qui se révèle être la grande différence quasi constante dans les valeurs VV entre les séries chronologiques de l’eau/eau peu profonde et celles du reste des types de couverture terrestre (autre que l’eau). Cette grande différence quasi constante est clairement observable dans les tracés en ligne et en ruban des figures 4, 5 et 6.
Enfin, il faut noter que la deuxième composante principale fonctionnelle (courbe orange dans le deuxième panneau) présente un creux en début de saison et un pointe en fin de saison, ce qui permet de saisir la tendance des eaux peu profondes, comme on peut l’observer dans les diagrammes en ruban des eaux peu profondes des figures 4, 5 et 6.
Les deux premiers scores CPF des données de formation
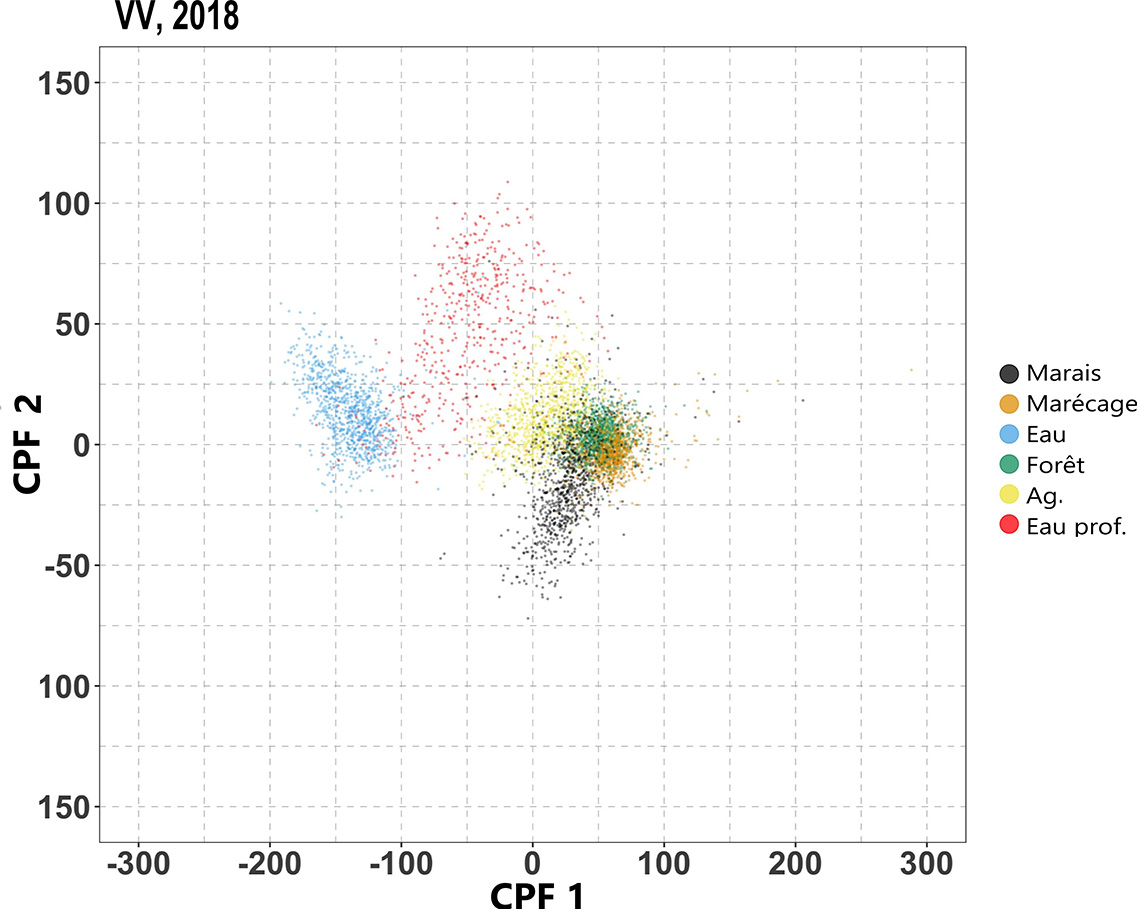
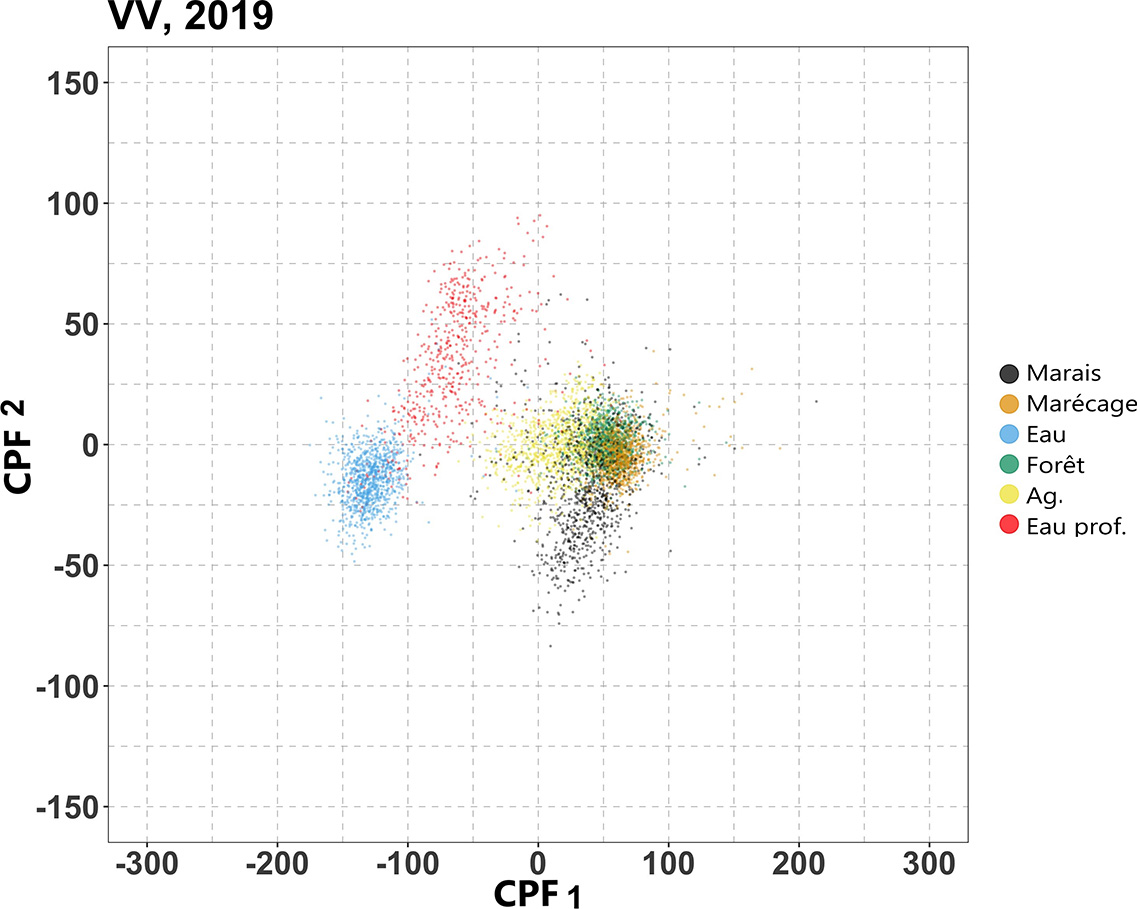
Nous montrons ici les nuages de points du premier score CPF par rapport au second pour les données de formation. Observez la bonne séparation des emplacements de formation de l’eau et de l’eau peu profonde de ceux des autres types de couverture terrestre, et observez également la cohérence de cette séparation d’une année à l’autre.
Figure 7: Scores CPF de 2017 – formation

Description - Figure 7
Nuage de points du premier score CPF par rapport au second pour les données des séries temporelles de formation pour 2017, 2018 et 2019.Les scores CPF résultants sont considérés comme les caractéristiques extraites. Chaque point de données de ce graphique correspond à un emplacement de la formation, la couleur indiquant le type de zone humide. Les axes horizontaux et verticaux correspondent respectivement aux premier et second scores CPF dérivés des séries chronologiques VV. Nous insistons sur le fait que, bien que chaque graphique ne montre que les scores des séries temporelles de formation correspondante pour l’année, les scores CPF ont été calculés simultanément pour toutes les séries chronologiques VV pour toutes les années et tous les types de zones humides.
Les points de données sont partiellement regroupés par type de zone humide; en particulier, l’eau et les eaux peu profondes se séparent très bien des autres types de zones humides. La séparation horizontale (qui est la dimension correspondant à la première CPF) entre l’eau/eau peu profonde et le reste. Cela représente la grande différence verticale entre l’eau/eau peu profonde et les autres types de zones humides non aquatiques au regard des valeurs VV originales (voir figure 4). La première CPF saisit cette grande différence verticale constante tout au long de la saison de végétation, ce qui explique pourquoi la première CPF ressemble à une ligne plate (courbe orange qui apparaîtrait dans le panneau supérieur de la figure 6).
Rappelons également que la deuxième CPF présente une tendance qui ressemble à celle des eaux peu profondes (comme le montrent les tracés en ruban dans les panneaux inférieurs de la figure 4 par rapport à la courbe orange dans le deuxième panneau de la figure 6). Rappelons également que le marais présente en gros la tendance inverse (comme indiqué dans le panneau supérieur de la figure 4 par rapport à la courbe bleue du second panneau de la figure 6). La deuxième CPF saisit la tendance affichée par les eaux peu profondes et, par conséquent, dans ce nuage de points, ce sont les emplacements de formation en eaux peu profondes (rouge) qui s’étendent significativement dans la direction verticale positive. En revanche, comme le marais présente à peu près la tendance inverse, les emplacements de formation pour les marais (en noir) s’étendent significativement vers le bas dans le présent nuage de points.
Contrôle d’intégrité : approximation de la série temporelle de formation originale par l’ACPF.
Étant donné que l’ACPF repose sur l’approximation de séries chronologiques de données de formation individuelles en tant que combinaisons linéaires d’une séquence de CPF (elles-mêmes des fonctions) qui sont apprises à partir des séries chronologiques des données de formation en tant que groupe :
Pour évaluer l’adéquation de l’ACPF à un ensemble particulier de données des séries chronologiques, il est prudent d’examiner dans quelle mesure les approximations fondées sur l’ACPF peuvent réellement se rapprocher des données des séries chronologiques originales.
La figure 12 montre six séries chronologiques de données de formation de Sentinel-1 choisies au hasard et leurs approximations par l’ACPF pour donner une impression de la qualité de l’ajustement des approximations de l’ACPF.
Figure 8: Approximations par l’ACPF de six séries chronologiques de données de formation.



Description - Figure 8
Approximations par l’ACPF de six séries chronologiques de données de formation. Dans chaque panneau, l’axe horizontal représente « l’indice des dates » où 1 correspond au jour de l’an, 2 correspond au 2 janvier, et ainsi de suite. L’axe vertical représente la valeur de la variable VV dans les données de Sentinel-1. Les points noirs sont les points de données des séries chronologiques originales. La courbe bleue est l’interpolation B-spline. La courbe rouge est l’approximation de l’ACPF à sept termes de l’interpolation B-spline (courbe bleue), où le « sept termes » signifie ici que l’approximation de l’ACPF est la somme de la fonction moyenne globale et d’une combinaison linéaire. Panneau 1 – année 2017, emplacement : -77,210217019792_43,8920257051607; Panneau 2 – année 2017, emplacement : -77,2997875102733_44,0678018892809; Panneau 3 – année 2018, emplacement : -77,2373431411184_44,1006434402341; Panneau 4 – année 2018, emplacement : -77,2691161641941_43,9610969253399; Panneau 5 – année 2019, emplacement : -77,2663596884513_43,950887882021; Panneau 6 – année 2019, emplacement : -77,3141305185843_44,1218009272802
Travaux à venir
- Cet article présente la technique d’ingénierie des caractéristiques fondée sur l’ACPF pour les données saisonnières des séries chronologiques de Sentinel-1. Rappelons toutefois que le but ultime est la classification des zones humides. La recherche de suivi immédiat consiste à appliquer certaines techniques de classification « de base » (p. ex. une forêt aléatoire) aux caractéristiques extraites fondées sur l’ACPF (c.-à-d. les scores CPF) et à examiner les précisions qui en résultent.
- La plupart des techniques de classification de base, comme la forêt aléatoire, ignorent les relations spatiales entre les emplacements/pixels. Si les techniques de base se révèlent insuffisamment précises, vous pouvez envisager des techniques de classification plus sophistiquées qui tentent de prendre en compte les relations spatiales, p. ex. en imposant des contraintes qui favorisent les emplacements/pixels proches pour avoir le même type de couverture terrestre prédit. L’une de ces techniques est le champ aléatoire de Markov caché, qui traite la tâche de classification de la couverture terrestre comme un problème de segmentation d’image non supervisée.
- Il a fallu environ 45 minutes pour générer la figure 3, en l’exécutant dans 16 fils parallèles sur un seul ordinateur virtuel x86 64-conda-linux-gnu (64 bits), sur un nuage informatique commercial, avec 28 Go de mémoire, en utilisant le système d’exploitation Ubuntu 20.04.2 LTS et R version 4.0.3 (2020– 10-10). Toutefois, la figure 3 ne couvre que la zone d’étude de la baie de Quinte, qui est une zone minuscule comparée à la province de l’Ontario ou à l’ensemble du Canada. L’utilisation des mêmes ressources informatiques que celles mentionnées ci-dessus pour exécuter le flux de travail d’extraction de caractéristiques fondées sur l’ACPF nécessiterait environ trois semaines pour l’Ontario et plusieurs mois pour l’ensemble du Canada. Plusieurs années de données de Sentinel– 1 pour l’ensemble du Canada auront une empreinte de stockage de plusieurs douzaines de téraoctets. D’un autre côté, on aimerait bien, à terme, mettre en place un système de classification pancanadien des terres humides (presque entièrement) automatisé. L’informatique répartie (informatique en nuage ou grappes de calcul à haute performance) sera nécessaire pour déployer un tel déroulement des opérations capable de traiter de tels volumes de données dans un délai raisonnable. Une étude de suivi est en cours pour déployer ce déroulement des opérations sur la plate-forme nuagique de Google (Google Cloud Platform (GCP)) pour l’ensemble de la Colombie-Britannique. Nous prévoyons que le temps d’exécution du déploiement du GCP pour l’ensemble de la Colombie-Britannique, divisé en centaines de tâches de calcul simultanées, sera inférieur à 3 heures. En outre, nous mentionnons que, en raison de la nature vectorielle des calculs de l’ACPF, une mise en œuvre du GPU devrait en théorie être possible, ce qui pourrait accélérer encore davantage les calculs de manière spectaculaire. Un article scientifique sur les résultats et les méthodologies de cette série de projets est en préparation et sera bientôt publié dans une revue à comité de lecture.
- Comme nous l’avons mentionné, les changements saisonniers des structures de la surface de la Terre, saisis sous forme de tendances temporelles dans les données des séries chronologiques de Sentinel-1, sont des variables prédictives utiles pour la classification des zones humides. Toutefois, pour pouvoir utiliser les données correctement et à grande échelle, il faut être conscient d’un certain nombre de problèmes potentiels. Par exemple, les utilisateurs de données doivent être bien informés des artefacts de mesure qui peuvent être présents dans de telles données, de la façon de détecter leur présence et de la façon de les corriger, si nécessaire. Nous prévoyons également que les tendances temporelles varieront (p. ex. en raison des variations naturelles, des cycles climatiques, du changement climatique), tant d’une année à l’autre que dans l’espace. La question de savoir comment tenir compte des variations spatiotemporelles des tendances temporelles de Sentinel-1 lors de la conception et de la mise en œuvre d’un déroulement des opérations pancanadien.
- Rappelons que nous nous sommes concentrés exclusivement sur la polarisation VV dans les données de Sentinel-1, bien que nous ayons déjà mentionné que les données de Sentinel-1 présentent une polarisation supplémentaire, à savoir VH. Les différentes polarisations sont sensibles aux différents types de structures au niveau du sol (NASA, 2022). En outre, Sentinel-1 est une constellation de satellites RSO en bande C (c.-à-d. avec une fréquence de signal radar d’environ 5,4 GHz), ce qui signifie notamment que Sentinel-1 mesure, très approximativement, des structures au niveau du sol d’une taille d’environ 5,5 cm. Toutefois, il existe d’autres satellites RSO qui ont des fréquences de signal différentes qui ciblent donc des structures au niveau du sol de tailles différentes (NASA, 2022). Il sera très intéressant de voir si les données RSO avec des fréquences de signal différentes, et mesurées dans des polarisations différentes, pourront être combinées afin d’améliorer de manière importante l’utilité de ces données.
Références
- BANKS, S., WHITE, L., BEHNAMIAN, A., CHEN, Z., MONTPETIT, B., BRISCO, B., PASHER, J., AND DUFFE, J. Wetland classification with multi-angle/temporal sar using random forests. Remote Sensing 11, 6 (2019).
- EUROPEAN SPACE AGENCY. Sentinel-1 Polarimetry. https://sentinel.esa.int/web/sentinel/user-guides/sentinel-1-sar/product-overview/polarimetry (le contenu de cette page est en anglais). Accédé : 2022-02-10.
- NASA. What is Synthetic Aperture Radar? https://earthdata.nasa.gov/learn/ backgrounders/what-is-sar (le contenu de cette page est en anglais). Accédé : 2022-02-10.
- SCHUMAKER, L. Spline Functions: Basic Theory, third ed. Cambridge Mathematical Library. Cambridge Mathematical Library, 2007.
- WANG, J.-L., CHIOU, J.-M., AND MU¨LLER, H.-G. Functional data analysis. Annual Review of Statistics and Its Application 3, 1 (2016), 257–295.
- WIKIPEDIA. RGB color model. https://en.wikipedia.org/wiki/RGB_color_model (le contenu de cette page est en anglais). Accédé : 2022-02-10.
All machine learning projects at Statistics Canada are developed under the agency's Framework for Responsible Machine Learning Processes that provides guidance and practical advice on how to responsibly develop automated processes.

Si vous avez des questions à propos de cet article ou si vous souhaitez en discuter, nous vous invitons à notre nouvelle série de présentations Rencontre avec le scientifique des données où le(s) auteur(s) présenteront ce sujet aux lecteurs et aux membres du RSD.
mercredi, le 14 septembre
14 h 00 à 15 h 00 p.m. HAE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données. À bientôt !
- Date de modification :